目录
- 写在前面
- CUDA的作用
- [GPU Driver 和 CUDA 以及cuDNN的关系](#GPU Driver 和 CUDA 以及cuDNN的关系)
- 如何进行CUDA多版本管理
-
- [1. GPU驱动安装](#1. GPU驱动安装)
- [2. CUDA的安装与环境变量配置](#2. CUDA的安装与环境变量配置)
-
- [CUDA Toolkit目录结构(环境变量配置的原理)](#CUDA Toolkit目录结构(环境变量配置的原理))
- [CUDA Toolkit环境变量配置](#CUDA Toolkit环境变量配置)
- [3. 深度学习相关库(cuDNN)](#3. 深度学习相关库(cuDNN))
- 4.CUDA多版本管理(重点)
- 总结
写在前面
看了市面上很多的技术博客教人怎么安装GPU、CUDA、以及Pytorh等,有些讲的看似很详细但实际上到头来只是教会了表面,对最重要的CUDA toolkit目录管理,还有各种环境变量配置的讲解也是一带而过。这篇文章将结合我的实践,总结梳理一下安装与使用CUDA的方法,以及如何在一台主机上安装管理多个版本的CUAD Toolkit。
CUDA的作用
CUDA的全称为:Compute Unified Device Architecture ,即统一计算设备架构,从这个名称不难看出,CUDA的作用就是使用GPU进行运算。
千万不要小瞧了这个功能,现在大家觉得用显卡进行计算是一件再正常不过的事情,但是在从前,显卡的主要功能就如同它的名字一样,主要是计算机用来显示图像,以及图形处理加速用的,用户无法对其编程,让其进行定制的计算。
直到后来NVIDIA 推出了并行计算平台和编程模型(即CUDA),才允许开发者直接利用 NVIDIA GPU 的强大计算能力进行通用计算(GPGPU)大大提升了计算机的计算能力,为人工智能的蓬勃发展奠定了基础。
学习本篇前,你需要有一张Nvidia的显卡。注意现在市面上AMD的显卡一般只用于娱乐,而Nvidia的显卡由于CUDA的加持,可以用于各种深度学习框架的加速(tensorflow与Pytorch)。
GPU Driver 和 CUDA 以及cuDNN的关系
根据上面介绍的内容,我们可以知道CUDA只是一套软件系统 。软件系统不能直接作用于显卡上,中间必须通过驱动作为桥梁。另外cuDNN是cuda专门用于深度学习加速的库,专为深度神经网络(DNN)设计,优化了卷积、池化、归一化等核心操作的性能,因此先有的CUDA再有的cuDNN库。
三者关系如下:
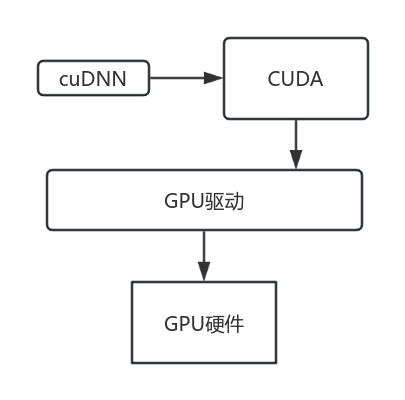
因此我们可以得出结论:
- 底层驱动的版本取决于GPU的具体型号。
- CUDA的版本取决于底层驱动版本。
- cuDNN的版本取决于适配的CUDA版本。
如何进行CUDA多版本管理
1. GPU驱动安装
正常情况下,GPU驱动是默认安装好的。打开命令行,输入如下指令进行查询:
bash
nvidia-smi会打印出如下结果:
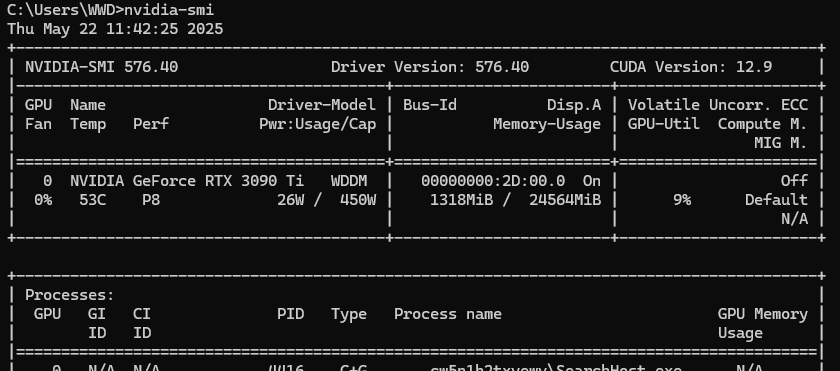
涵盖了GPU的各种信息,这里不过多介绍。最重要的是右上角的CUDA Version,代表着当前驱动支持的最高CUDA版本 。注意不是当前已经安装的cuda版本,是驱动支持的最高的CUDA版本上限。这也不意味着CUDA版本没有下限 。例如我当前的RTX3090ti,是ampere架构的GPU,最低CUDA版本要大于11.1。
如果没有安装Nvidia驱动怎么办?请访问下面的网址,在官网中下载安装对应型号的GPU驱动:
Nvidia驱动下载
对于使用WSL的情况,现在WSL2已经默认安装了GPU驱动了和Windows是一致的,重复安装会导致严重问题。有些人可能用'nvidia-smi'搜不出GPU的版本信息,这有可能是nvidia-smi这个程序放置的位置不对导致的,一般来说nvidia-smi会被放在 /usr/lib/wsl/lib/目录:但是默认搜索的路径是/usr/bin内的,可以创建一个软连接:
ln -s /usr/lib/wsl/lib/nvidia-smi /usr/bin/nvidia-smi这样应该就可以使用命令行调出nvidia-smi了。
2. CUDA的安装与环境变量配置
在安装好GPU驱动后,我们就可以得知CUDA版本的上下限了,根据这个信息去安装适配版本的CUDA Toolkit(CUDA准确来说是一种技术标准,一种架构模型。我们实际下载安装的是CUDA开发软件包,即CUDA Toolkit )。
CUDA Toolkit包含三大部分:
- nvcc 编译器
CUDA 程序的专用编译器,支持混合编译主机(CPU)和设备(GPU)代码。CUDA程序一般使用 C/C++ 或者 Fortran 语言的 CUDA 扩展语法。 - CUDA Runtime库
动态链接库,向下对接驱动。提供基础的API来控制GPU执行计算任务,分配显存等。
(编译器+库为一大部分,提供对CUDA程序编译支持)
- 开发调试工具
例如,CUDA-GDB / CUDA-MEMCHECK工具,支持 GPU 代码的调试和内存错误检测。还有Nsight系列工具,用于分析CUDA程序的性能等。 - 加速计算库
也就是我们常用的cuDNN、cuFFT、cuBLAS等库。
CUDA驱动的官网下载在这个链接,进入后按照选项选择合适的版本进行下载:

Windows无脑安装.exe就行了。对于Linux系统(这里以WSL为例),官方推荐的三种办法中,我建议选择runflie(local)进行下载,这个下载完是一个.sh脚本,运行后可以通过交互界面进行安装,除了比较慢外没有什么缺点。
CUDA Toolkit目录结构(环境变量配置的原理)
在默认情况下,cuda toolkit会被安装到以下路径中:
- Windows:
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\vX.Y(X.Y为版本号,如v12.1) - Linux:
/usr/local/cuda-X.Y
在windows中其文件夹目录结构如下:

Linux下为:
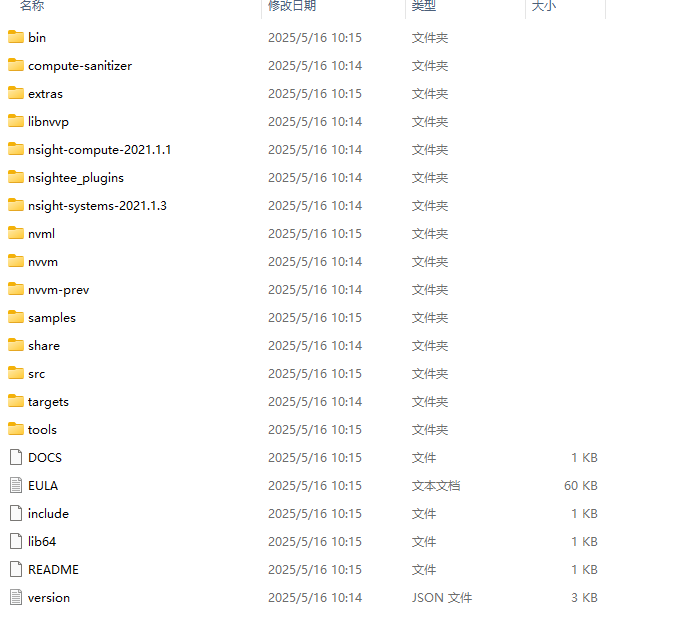
核心子目录与功能
bin/存放CUDA工具链的可执行文件:
nvcc:CUDA编译器(核心编译工具CUDA动态库(如cudart64_12.dll或libcudart.so)
include/包含CUDA编程所需的头文件,如:
cuda_runtime.h:CUDA运行时API头文件
cublas_v2.h:cuBLAS库头文件
device_functions.h:设备端函数定义
lib/(Linux为lib64/)静态库文件(.lib或.a)和动态库文件(.dll或.so):
cudart.lib/libcudart.so:CUDA运行时库
cublas.lib/libcublas.so:基础线性代数库
nvToolsExt.lib:性能分析工具扩展库
nvvm/NVIDIA虚拟化指令集架构(NVVM)相关文件,用于优化CUDA代码的中间表示(LLVM组件)
tools/工具链扩展:
cupti:性能分析工具接口(Profiling Tools Interface)
nsight:调试与性能分析套件(部分版本独立安装)
CUDA Toolkit环境变量配置
各种文章的配置命名千奇百怪,这里就给出一种通用的方法:
- 基础路径配置(保证能cuda运行起来)
- CUDA_PATH 这个环境变量指向CUDA Toolkit的安装
根目录,例如:C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.9 - PATH 这个环境变量指向CUDA 包下的
\bin文件夹,没有配置这个路径将无法用nvcc 编译器。另外也可以包含\libnvvp目录,其中包含NVIDIA Visual Profiler(nvvp)的可执行文件和依赖库,该工具用于分析和优化CUDA程序的性能。 - LD_LIBRARY_PATH (Linux特有)用于添加CUDA的库路径以支持动态链接需要指向 CUDA包下的
lib64文件夹。
解释:windows的CUDA库放在
lib文件夹下,根据Windows系统的默认搜索机制,能直接搜索到,只需要PATH路径配置正确即可。而在Linux中只会默认搜索/usr/lib目录下的库,一种办法是把CUDA的库放到这个目录下,但显然这样做会污染系统库文件。另一种办法就是通过LD_LIBARARY_PATH临时知道第三方库的位置。
windows路径配置如下:
- CUDA_PATH
- Path
linux路径配置如下:
在
.bashrc文件中加入:
export CUDA_PATH=/usr/local/cuda-11.8
export PATH=\$CUDA_PATH/bin:\$PATH
export LD_LIBRARY_PATH=\$CUDA_PATH/lib64:\$LD_LIBRARY_PATH


在集成终端中输入:
bash
nvcc -V即可打印安装的cuda对应版本,说明cuda基础环境配置成功了。
3. 深度学习相关库(cuDNN)
cuDNN的下载连接,进去后根据安装的CUDA版本选择合适的cuDNN库。
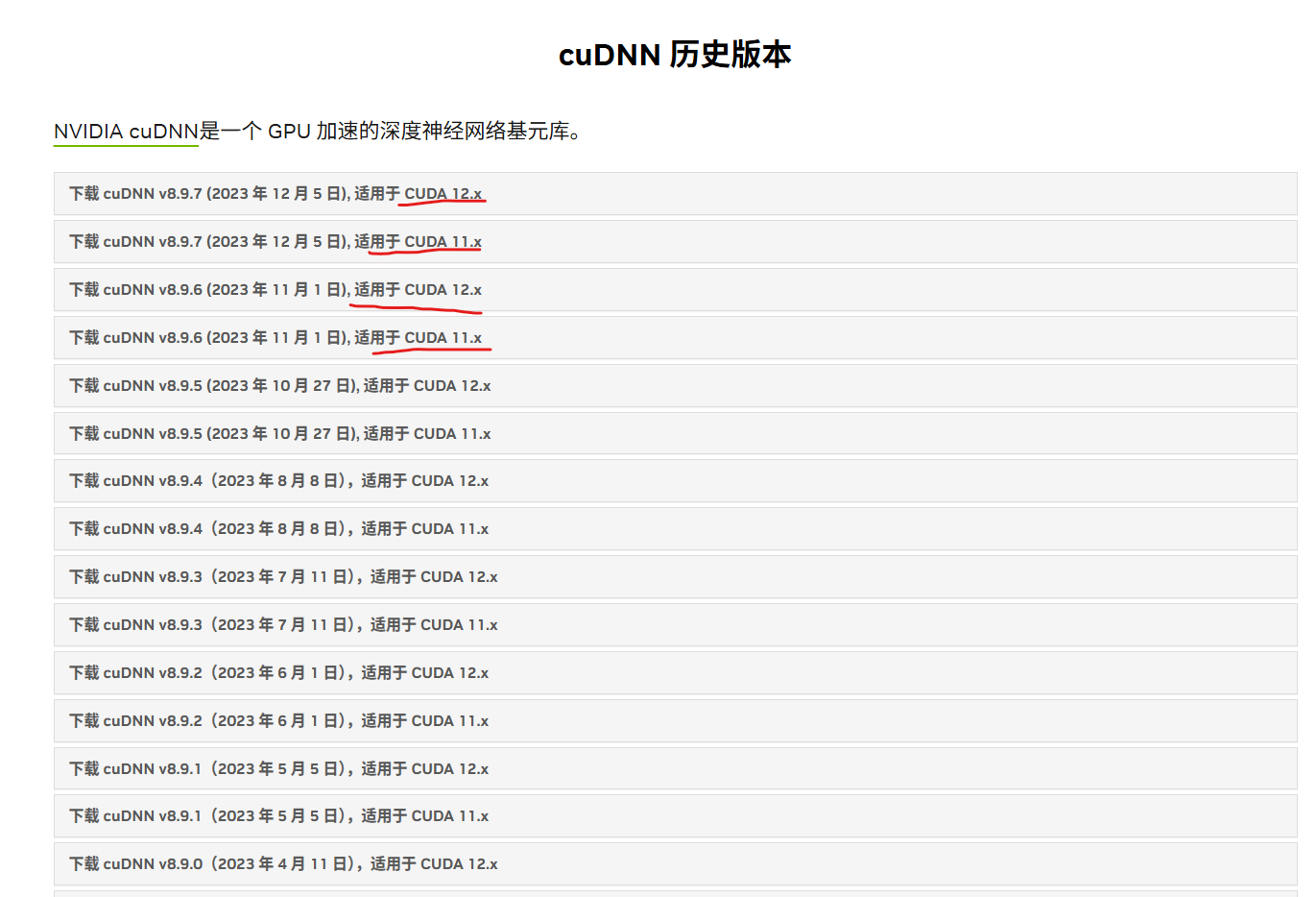
下载完成后你会发现cuDNN不像之前安装CUDA那样有一个安装程序,cuDNN下载下来只是一个库文件 ,包括了库的头文件(include)以及实现(lib64)Windows中还有bin文件夹。如下图:

cuDNN库的安装大体上有两种方法:
- 将cuDNN库中对应的文件夹(lib/lib64、include、bin)移动到CUDA根目录下的对应文件夹(lib/lib64、include、bin)中。这种方法适配性最好,但是无法选择性使用多个cuDNN版本(说实话一般情况下也用不到)
- 在环境变量中指定cuDNN库的头文件和库文件的路径(这种方法可以一个CUDA使用多个版本cuDNN)。
(Linux)在.bashrc中添加:
bash
export CUDNN_HOME=~/cudnn/cuda # cuDNN 解压后的路径
export LD_LIBRARY_PATH=\$CUDNN_HOME/lib64:\$LD_LIBRARY_PATH
export CPATH=\$CUDNN_HOME/include:\$CPATH # 确保头文件能被找到(Windows)中,
右键「此电脑」→「属性」→「高级系统设置」→「环境变量」→ 编辑「系统变量」中的Path,新增以下路径(根据实际路径调整):
D:\cudnn\bin
D:\cudnn\lib\x64
并确保路径位于CUDA相关路径之前,以优先加载自定义cuDNN
对于头文件路径,pytorch等框架会自动搜索头文件(只需要指定bin和lib\x64路径就行了),如果是自己手工编写cuda代码,那么使用nvcc编译的时候应该要使用
-I 'path_to_cudnn'来指定头文件。
验证cuDNN的安装 :
在python中运行:
python
import torch
print(torch.backends.cudnn.version())如果能打印版本信息出来,则说明cuDNN安装成功!
4.CUDA多版本管理(重点)
前面的内容市面上都有,也许我讲的有些复杂大家可以参考其它的一些内容。接下来是关于一台主机上使用和安装多个版本cuda的解决方法。
众所周知,深度学习相关的项目复现百分之九十九都是在Linux系统下进行的,很多开源项目都没有在Windows上的支持以及仅仅只是体验性的支持,因此CUDA多版本切换主要集中在Linux系统上(例如Ubuntu等),但其实Windows上实现思路也是一样的。
主要有两个办法解决:
一、更改CUDA路径
这个方法Linux比Windows更加方面。对于Windows来说,从一个版本的CUDA转到另一个版本需要先下载CUDA库的各种文件,像前面提到的那样。
Windows演示
现在我电脑上安装了cuda的12.8版本,环境变量如下:
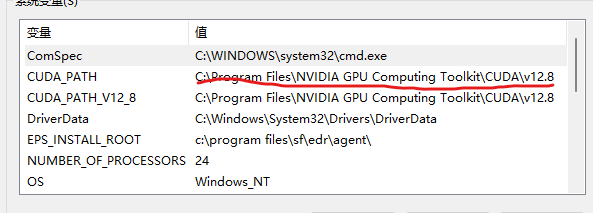
现在,到官网上下载CUDA toolkit 11.3(RTX3090ti最低支持版)
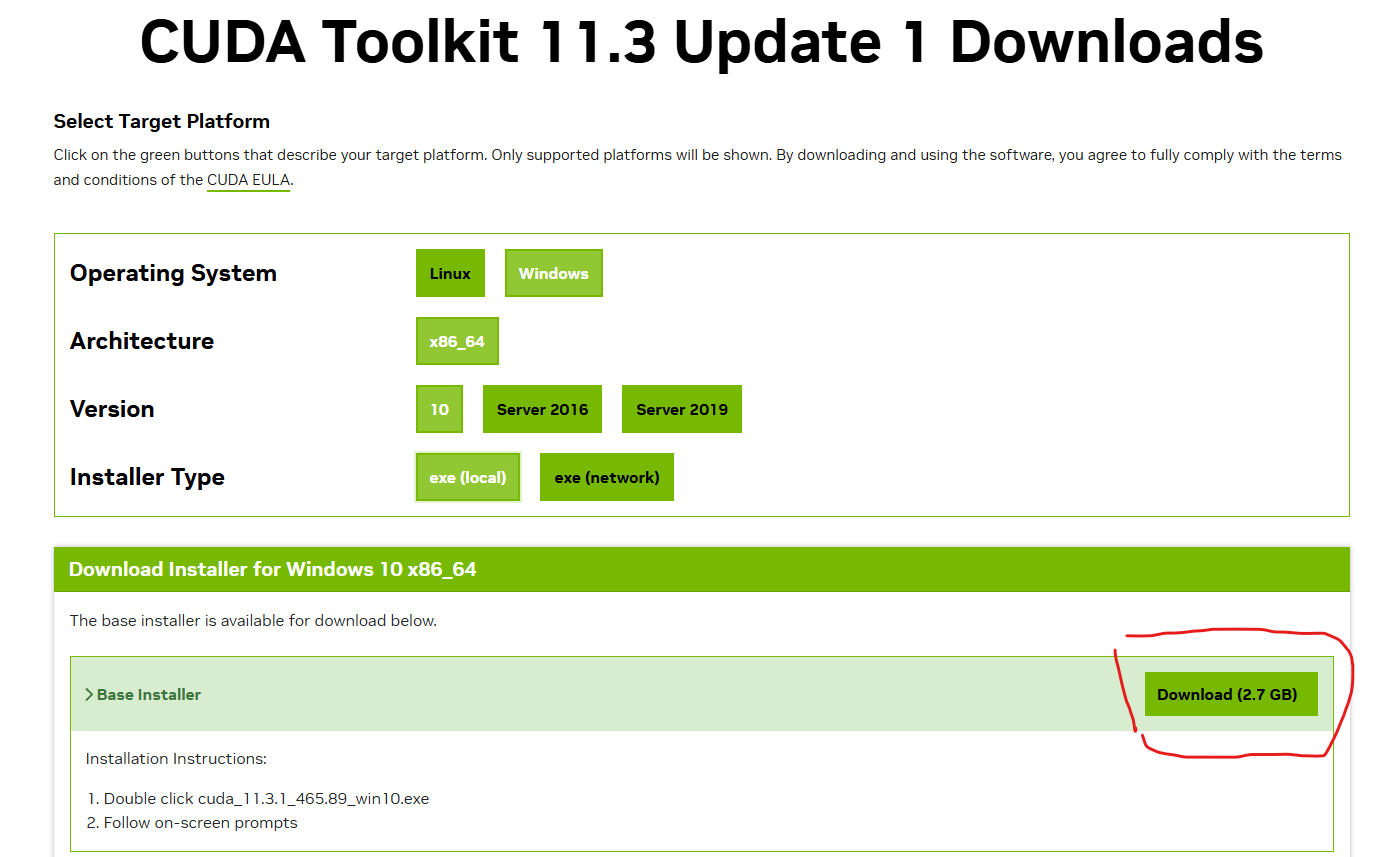
然后执行安装程序:
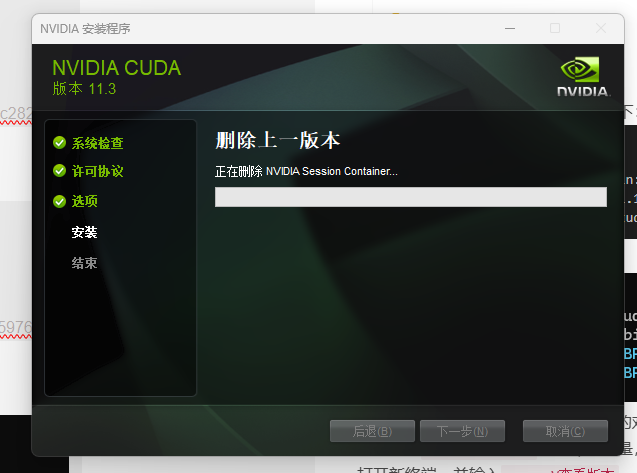
可以看到,程序会自动地处理两个版本之间的兼容性问题。安装完成后可以看到,环境变量也自动改变了:
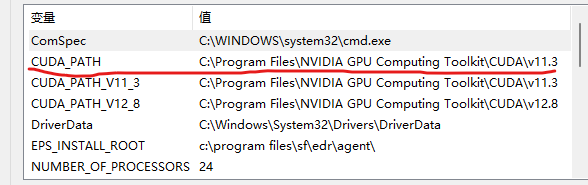
此时在cmd中输入nvcc -V,可以发现cuda版本已经改变:
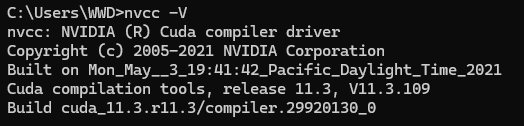
但是事实上之前版本的cuda并没有被删除,打开cuda的文件夹可以发现上个版本的cuda仍然保留:
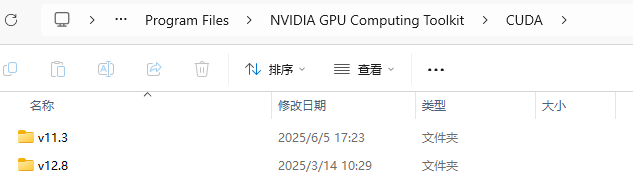
如果此时我们将环境变量中的CUDA_PATH再次改变:
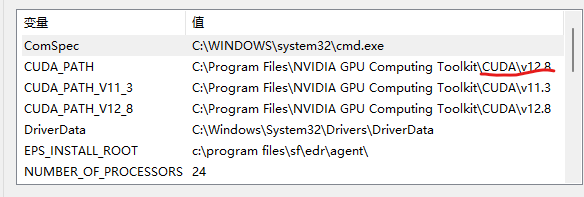
并且在path中将要用的cuda版本路径提前:
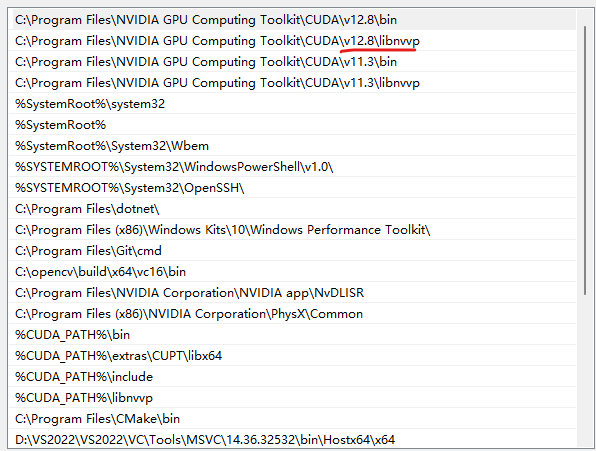
重启终端,再次输入nvcc -V,可以发现cuda版本又变回12.8了
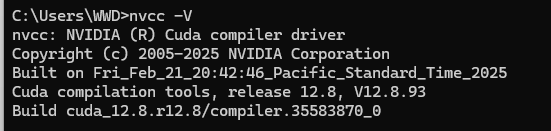
由此可以得出,cuda多版本是可以相互兼容使用的,只要确保环境变量始终指向一个版本就行了
Linux下演示
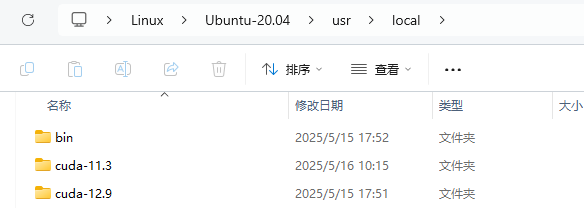
首先下载好cuda包,并将其放置在/usr/local/下,如下图(明显有两个cuda版本了)
再编辑.bashrc文件(路径在用户目录下:home/your_name/.bashrc)

改成:

把上面的路径全都改成要用的cuda包的对应路径。
最后输入source .bashrc生效环境变量,或者重启终端。
打开新终端,并输入nvcc -V查看版本
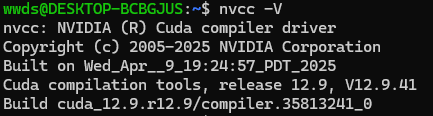
说明已经生效。
Linux软链接的方法(推荐)
如果你使用runfile进行安装你就知道,在.bashrc中,cuda的环境变量配置并不是指向某个具体版本,而是统一的名为cuda的文件夹,如下:

使用file指令查看属性,发现cuda是一个软链接:并连接到cuda-11.3的目录下:

软连接相当于windows中的快捷方式,使用这种方法是很聪明的,cuda在这里仅作为一个符号连接,大小为1kb左右。通过改变软链接的指向可以实现无需修改.bashrc即可改变系统cuda版本。
例如,此时我将软链接指向改为指向cuda12.9:
bash
sudo rm /usr/local/cuda #先删除旧链接
sudo ln -s /usr/local/cuda-12.9/ /usr/local/cuda #创建新链接
ls -l /usr/local/cuda #查看链接关系此时在终端中输入nvcc -V可以发现cuda版本已经改变了,这个过程没有修改.bashrc,也不需要重启终端
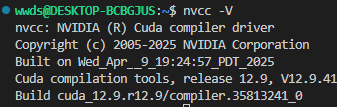
上面的方法是直接更改系统的cuda版本,接下来的方法适用于python深度学习环境对多cuda版本的管理
二、使用Conda进行环境管理(推荐)
anaconda作为python虚拟环境的管理工具,除了可以管理软件包外,还可以隔离cuda环境。
- 激活conda环境
bash
conda activate your_env- 使用conda安装cudatoolkit
bash
conda install cudatoolkit=xx.x 如果你在安装完成后输入nvcc -V会发现cuda的版本还是系统里原来的,这是因为conda版cudatoolkit仅包含运行预编译CUDA程序所需的最小动态链接库(如运行PyTorch/TensorFlow等框架),而官方完整CUDA Toolkit:包含编译器(nvcc)、调试器、头文件等完整开发工具链。
深度学习框架不需要完整的CUDA的原因就在于运行pytorch等框架并不需要完整的CUDA Toolkit,因为PyTorch/TensorFlow的预编译二进制包已包含CUDA内核代码,运行时仅需调用CUDA动态库(如libcudart.so或cudart64_XX.dll)。
conda install cudatoolkit提供的正是这些核心运行时库,满足框架执行GPU计算的基础需求。
总结
对于Linux:
bash
#cuda-hard
export CUDA_PATH=/usr/local/cuda-11.8
export PATH=\$CUDA_PATH/bin:\$PATH
export LD_LIBRARY_PATH=\$CUDA_PATH/lib64:\$LD_LIBRARY_PATH
#cuda-soft
#sudo rm /usr/local/cuda #先删除旧链接
#sudo ln -s /usr/local/cuda-12.9/ /usr/local/cuda #创建新链接
#ls -l /usr/local/cuda #查看链接关系
export CUDA_PATH=/usr/local/cuda
export PATH=\$CUDA_PATH/bin:\$PATH
export LD_LIBRARY_PATH=\$CUDA_PATH/lib64:\$LD_LIBRARY_PATH
#cuDNN
export CUDNN_HOME=~/cudnn/cuda # cuDNN 解压后的路径
export LD_LIBRARY_PATH=\$CUDNN_HOME/lib64:\$LD_LIBRARY_PATH
export CPATH=\$CUDNN_HOME/include:\$CPATH # 确保头文件能被找到
# 或者放入cuda同名文件夹对于Windows:
安装.exe,更改环境变量即可。
对于anaconda:
bash
#cuda
conda activate your_env
conda install cudatoolkit=xx.x
#cuDNN
conda install cudnn
#Conda 会自动匹配当前 CUDA 版本的 cuDNN
#echo $LD_LIBRARY_PATH 检查路径应该包含Conda 环境下的 cuDNN 库路径(如 ~/miniconda3/lib)