0.背景描述
公司最近需要在仿真平台上增加一些AI功能,针对于时序数据,想到的肯定是时序数据处理模型,典型的就两大类:LSTM 和 tranformer 。查阅文献,找到一篇中石化安全工程研究院有限公司的文章,题目为《基于TA-ConvBiLSTM的化工过程关键工艺参数预测》,想着对该论文思路进行复现。并与lstm 做对比,看看引入CNN 、时间注意力机制后和双向LSTM 是否对模型预测精度有提升效果。
1.模拟生成数据
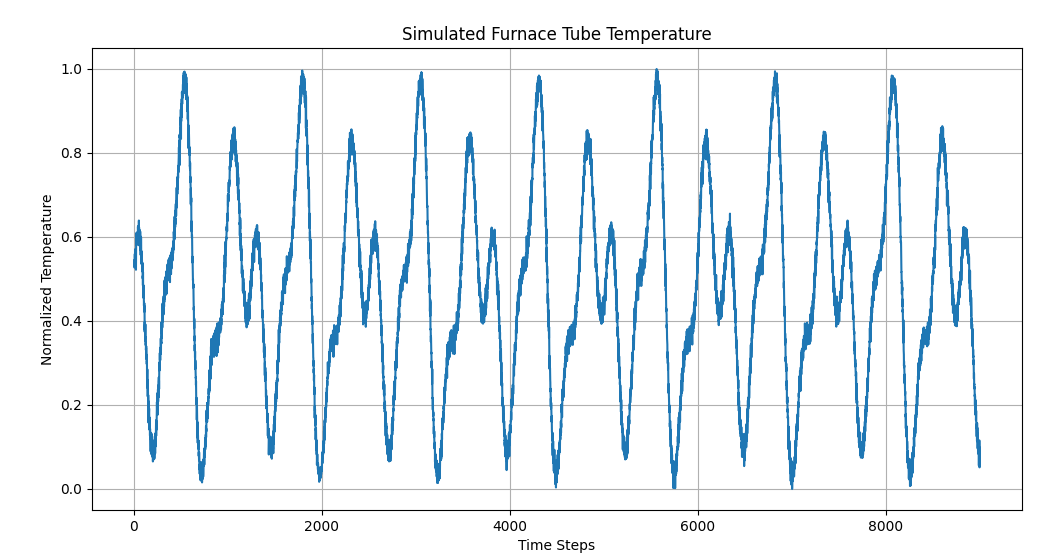
模型训练需要数据,因此,我按照文章要求,模拟生成了一组数据集(9000),74列特征,目标值是某炉温度
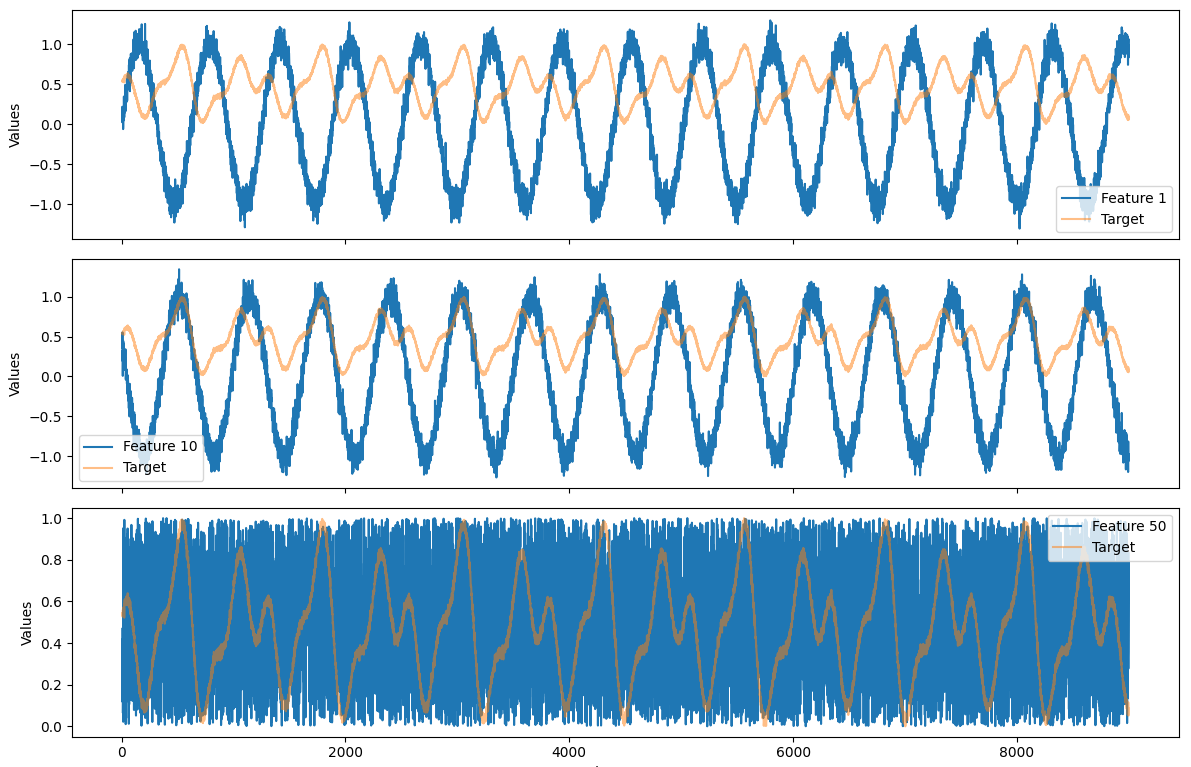
2. 使用xgboost 对特征进行筛选
使用model.feature_importances_ 方法,即可获取重要性排序
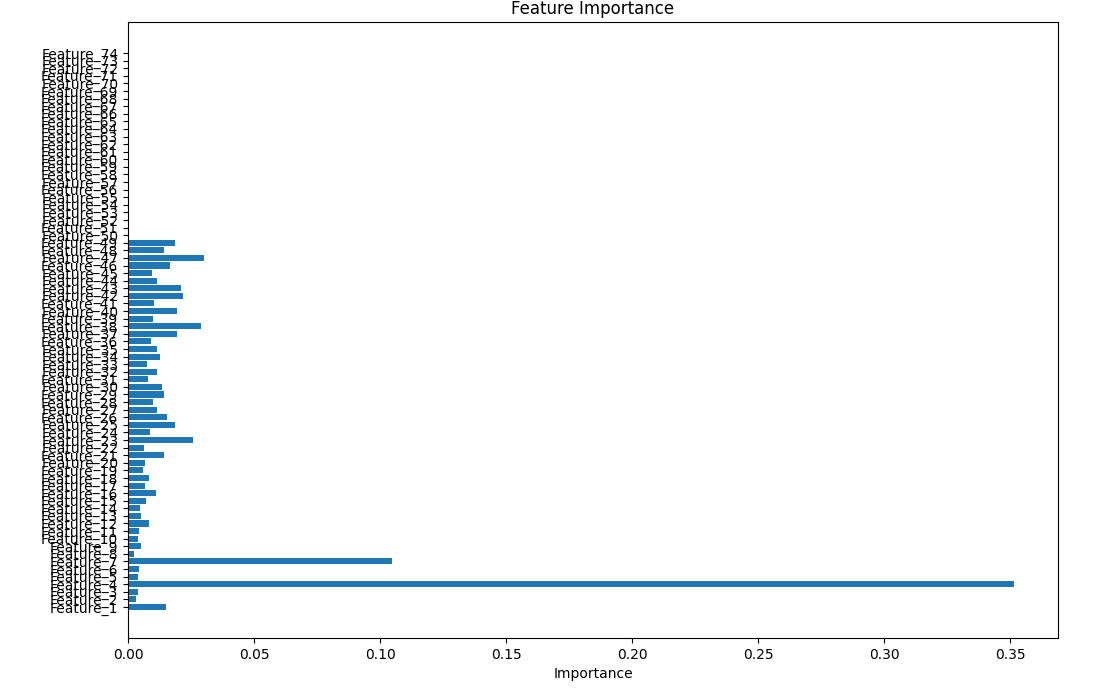
可以看到这些特征中,有49列特征具有相关性,因此,对特征进行选择
3. 使用lstm 进行预测
特征值分别使用
case1 :
选择特征(去掉目标变量和非相关列)
features_df = data.drop('Target','Time_Step','Day_Cycle','Week_Cycle','Target_Lag_1','Target_Lag_2','Target_Lag_3','Target_Lag_4','Target_Lag_5', axis=1)
case2
选择特征(去非相关列)
features_df = data.drop('Time_Step','Day_Cycle','Week_Cycle','Target_Lag_1','Target_Lag_2','Target_Lag_3','Target_Lag_4','Target_Lag_5', axis=1)
case3
选择特征(xgboost 删选出来的特征 + Target)
features_df = data'Feature_4', 'Feature_7', 'Feature_47', 'Feature_38', 'Feature_23', 'Feature_42', 'Feature_43', 'Feature_37', 'Feature_40', 'Feature_49', 'Feature_25', 'Feature_46', 'Feature_26', 'Feature_1' , 'Feature_21', 'Feature_48', 'Feature_29', 'Feature_30', 'Feature_34', 'Feature_27', 'Feature_35', 'Feature_44', 'Feature_32', 'Feature_16', 'Feature_41', 'Feature_39', 'Feature_28', 'Feature_45' , 'Feature_36', 'Feature_24', 'Feature_12', 'Feature_18', 'Feature_31', 'Feature_33', 'Feature_15', 'Feature_17', 'Feature_20', 'Feature_22', 'Feature_19', 'Feature_9', 'Feature_13', 'Feature_14', 'Feature_11', 'Feature_6', 'Feature_3', 'Feature_5', 'Feature_10', 'Feature_2', 'Feature_8', 'Feature_63','Target'
三种情况下,
模型参数
input_size = features_df.shape1
hidden_size = 128 # 32 ->0.2582
num_layers = 2
look_forward = 1
learning_rate = 0.001
num_epochs = 1000
分别测试结果:
case1 :
R² Score: 0.2863155879831444
case2:
R² Score: 0.911497674937094
case3:
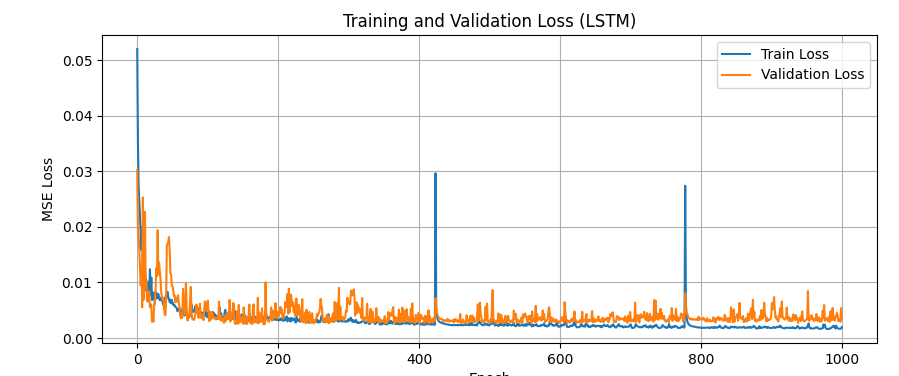

R2 Score: 0.9679
MSE: 0.0017
三种情况下,R2逐渐提升,总结:
1.将目标值作为特征量,能显著提高拟合度;(从0.2->0.9)
2.通过删选去掉冗余特征,在一定程度上提高拟合度。(0.91->0.96)
4. 使用TA-conv-BiLSTM 进行预测
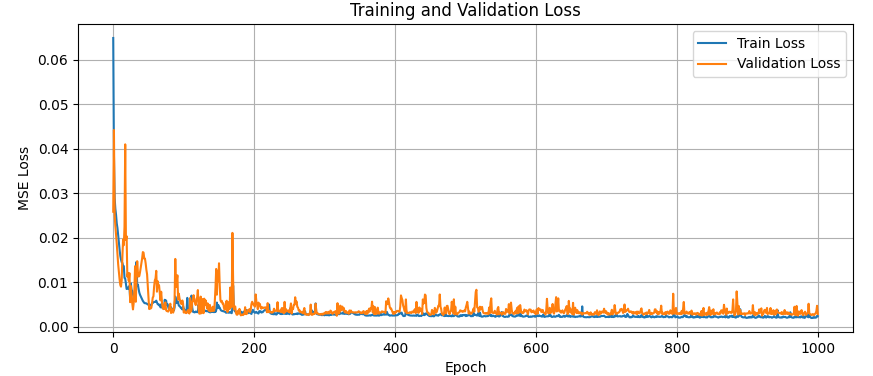
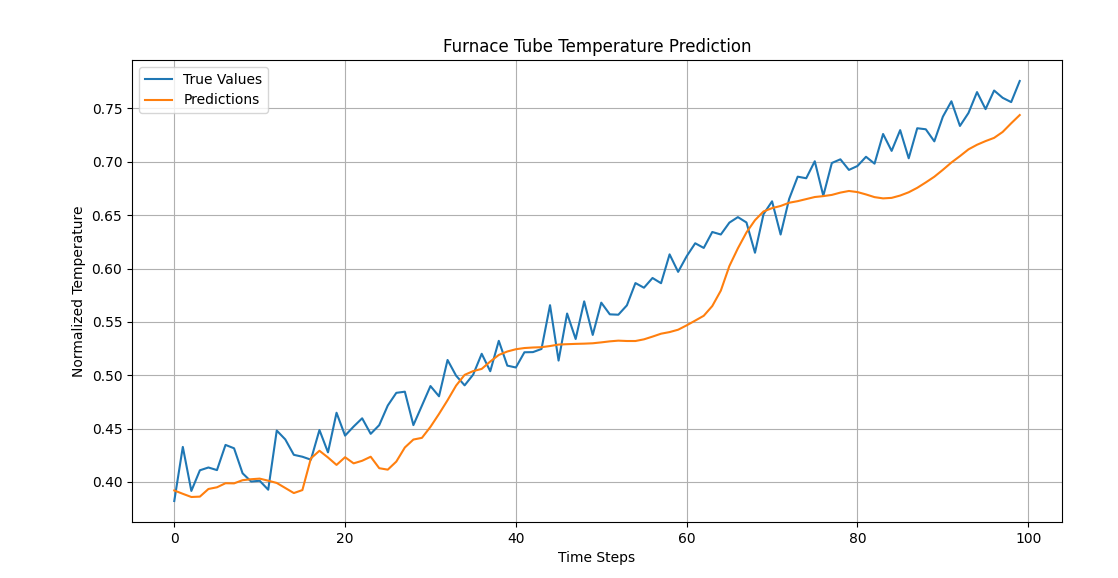
R2 Score: 0.9781
MSE: 0.0012
由此看出,使用TA-ConvBilstm后,拟合度和均方误差都有明显提升