半监督学习(SSL)的目标是借助未标记数据辅助训练,以期获得比仅用带标签的监督学习范式更好的效果。但是,SSL的前提是数据分布需满足某些假设。否则,SSL可能无法提升监督学习的效果,甚至会因误导性推断降低预测准确性。
半监督学习的相关假设包括:Self-training assumption ,Co-training assumption ,Generative model assumption ,Cluster assumption ,Low-density separation ,Manifold assumption:
-
自训练假设:自训练模型的预测,尤其是高置信度的预测,往往是正确的。当该假设成立时,这些高置信度预测可视为真实标签。
-
聚类假设:若两点 x1 和 x2 属于同一簇,则它们应属于同一类别。该假设指的是,单一类别的数据倾向于形成一个簇,且当数据点可通过不经过任何低密度区域的短曲线连接时,它们属于同一类簇。根据该假设,决策边界不应穿过高密度区域,而应位于低密度区域。因此,学习算法可利用大量未标记数据调整分类边界。
-
低密度分离假设:决策边界应位于低密度区域,而非穿过高密度区域。低密度分离假设与聚类假设密切相关。我们可以从另一角度理解聚类假设:类别由低密度区域分隔。因为高密度区域的决策边界会将一个簇分割为两个不同类别,这会违背聚类假设。
以上翻译了文献1中的部分内容,具体内容请看原文献。总的来说,自训练假设 是用带标签训练模型,训练好的模型用于预测未标注的数据,由此获得了相应的伪标签。聚类假设 和低密度分离假设基本上相同,均认为决策边界位于低密度区域。
低密度分离假设的直观理解
低密度分离假设是半监督学习中一个核心且重要的理论前提。它描述了数据在特征空间中的分布特性,并为许多半监督学习方法(如熵最小化)提供了为什么利用未标记数据有效的理论依据。
如下图,当决策边界位于低密度区域时,模型对输入的数据有确定性的预测(低熵),表明意这个点位于某个类别的高密度簇内部,远离边界。
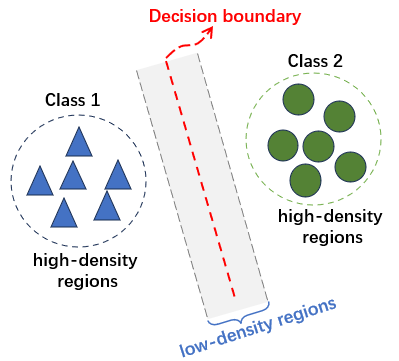
当未标记的数据处于决策边界附近,模型难以对这些未标记的数据进行分类,即做出高熵(不确定)的预测。
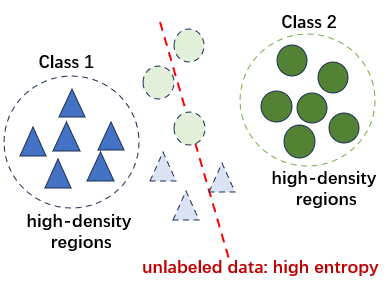
因此,熵最小化损失函数惩罚模型对未标记数据点做出高熵(不确定)的预测,强迫模型对这些点也必须给出低熵(自信、确定)的预测。表现为:
- 调整内部表示 (Feature Learning): 让特征空间中原本靠近的不同类别点变得更容易区分(拉开距离),在它们之间创造出低密度间隙。
- 移动决策边界 (Boundary Adjustment): 把边界从当前穿过的、可能还是高密度混杂区(或高密度区边缘)的地方,推离到旁边数据更稀疏的低密度区域。
参考:
1 Yang, Xiangli, et al. "A survey on deep semi-supervised learning." IEEE transactions on knowledge and data engineering 35.9 (2022): 8934-8954.