目录
界限、低位地址、高位地址、TooFar、目标大小、空字符结尾、长度
[多字节字符集(MBCS)、宽字符(宽字符串) 和 UTF-8](#多字节字符集(MBCS)、宽字符(宽字符串) 和 UTF-8)
[无界字符串复制(unbounded string copy)](#无界字符串复制(unbounded string copy))
[差一错误(Off-by-One Error )](#差一错误(Off-by-One Error ))
[空结尾错误(null termination error)](#空结尾错误(null termination error))
[字符串截断(string truncation)](#字符串截断(string truncation))
[手动去掉 \n:Passwordstrcspn(Password, "\\n") = '\0';](#手动去掉 \n:Password[strcspn(Password, "\n")] = '\0';)
gets不会限制输入的字符数,读完后将换行符从输入中移除,并自动用空字符(\0)替换它
fgets会限制读取的字符数,会读入换行符;但会截断,截断后会自动添加\0
[问:既然fgets会限制读取的字符数,会读入换行符并且会截断,截断后会自动添加\0 ;那为什么还要 Passwordstrcspn(Password, "\\n") = '\0';](#问:既然fgets会限制读取的字符数,会读入换行符并且会截断,截断后会自动添加\0 ;那为什么还要 Password[strcspn(Password, "\n")] = '\0';)
gets_s会限制读取的字符数,不保留换行符在字符串中;会截断,截断后会自动添加\0
一.导论

(1)安全缺陷
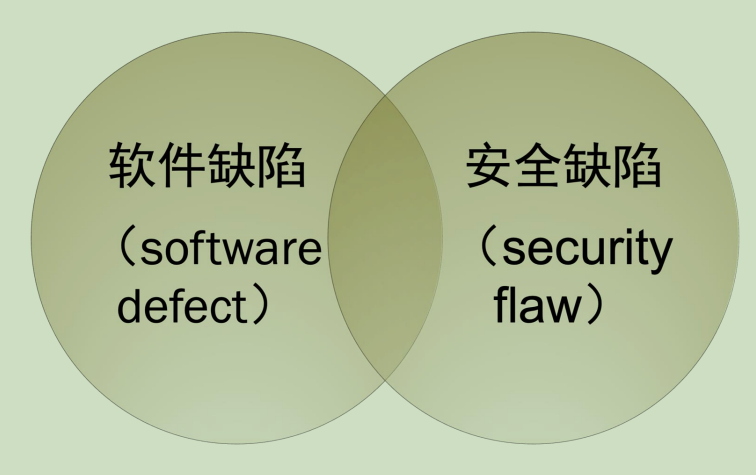
软件缺陷(software defect)指软件在功能、性能、交互等方面与需求 / 预期不符的问题,核心是 "不符合设计或用户期望" 。
安全缺陷(security flaw)聚焦软件安全层面的漏洞 ,即可能被攻击者利用、威胁数据 / 系统安全的问题,核心是 "可被恶意利用的风险"。
(2)漏洞

漏洞和缺陷的关系:
安全缺陷会导致漏洞
每个漏洞至少由一个安全缺陷引起
不是所有安全缺陷都会导致漏洞
在没有安全缺陷的情况下,不可能存在漏洞
安全缺陷是漏洞的必要条件(无缺陷则无漏洞),但非充分条件(有缺陷未必有漏洞)
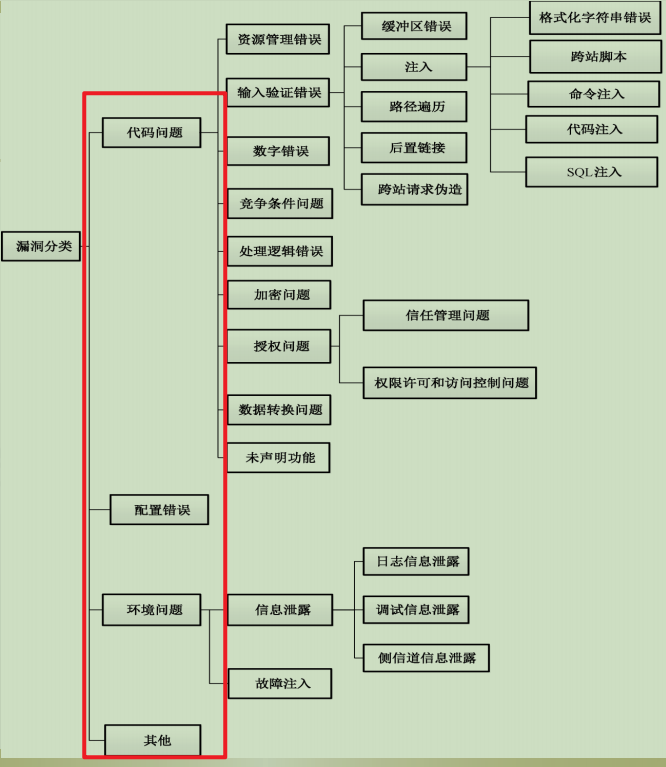
漏洞分类
N-Day漏洞
| 类型 | 零日漏洞(0 - Day) | N - Day 漏洞(如 1 - Day) |
|---|---|---|
| 补丁状态 | 无补丁, 厂商未发现漏洞 | 补丁已发布, 但用户未更新 |
| 攻击窗口 | 漏洞未被公开, 攻击隐蔽性极强 | 攻击者利用用户更新延迟 |
| 防御重点 | 依赖主动防御(如行为监控) | 依赖用户及时安装补丁 |
代码问题、配置错误、环境问题、其他
漏洞利用
方式(病毒、蠕虫、木马)
| 特性 | 蠕虫 | 病毒 | 木马 |
|---|---|---|---|
| 依赖宿主 | × | ✔ | × |
| 传播方式 | 通过网络 自动传播 | 依赖宿主文件, 需要用户触发 | 伪装成合法软 件,诱骗用户 安装 |
| 自我复制 | ✔ | ✔ | × |
| 主要目标 | 快速传播,消 耗资源 | 破坏文件或系统 | 窃取数据或 远程控制 |
造成的安全事件
缓冲区错误类漏洞占比最大,代码问题最突出
(3)产生缺陷、漏洞的原因
与软件缺陷一样,产生软件漏洞的原因,存在于软件生命周期的各个环节
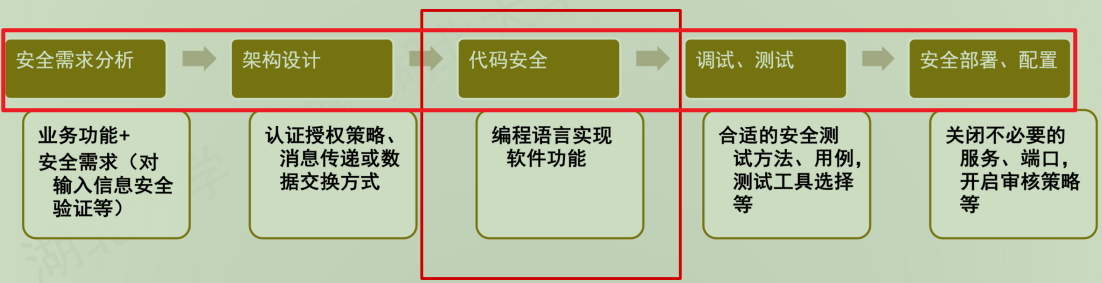
产生软件缺陷、漏洞的原因贯穿软件生命周期各环节:安全需求分析时,若业务功能与安全需求(如输入验证)梳理不全面,易埋下风险;架构设计环节,认证授权策略、消息及数据交换方式的不合理,会使架构存在安全短板;代码安全层面,编程语言实现功能时的编码错误、逻辑缺陷,会直接产生代码级漏洞;调试测试阶段,因安全测试方法、用例不充分或工具选择不当,难全面发现问题;安全部署与配置环节,若未合理关闭冗余服务端口、开启审核策略,也会引入漏洞,让软件暴露于攻击风险
(4)缓解安全问题
首选是找到并修正漏洞
二、字符串

字符串由一个以空(null)字符作为结束的连续字符序列组成,包含此空字符。
(1)软件工程中字符串数据类型
界限、低位地址、高位地址、TooFar、目标大小、空字符结尾、长度
| 字符串数据类型 | 概念中文 | 说明描述 |
|---|---|---|
| Bound | 界限 | 数组中元素的数量。 |
| Lo | 地位地址 | 数组第一个元素的地址。 |
| Hi | 高位地址 | 数组最后一个元素的地址。 |
| TooFar | 越界 | 数组一个 "越界" 元素的地址,即刚好在 Hi 元素之后的那个元素的地址。 |
| Target size(Tsize) | 目标大小 | 等价于用 sizeof 拿到的数组总字节数,比如数组里有 5 个 int 元素(每个 int 占 4 字节 ),Tsize 就是 5 * 4 = 20 字节 。 |
| Null-terminated | 空字符结尾 | 在 Hi(高位地址)位置或其之前,存在空终止符(\0 ) |
| Length | 长度 | 空终止符(\0)之前的字符数量。 |
| 字符串数据类型 | 对应值(基于 hello\0 示例) |
|---|---|
| Bound | 6(元素总数,含 \0 ) |
| Lo | h 的地址 |
| Hi | \0 的地址 |
| TooFar | \0 下一个字节的地址 |
| Target size(Tsize) | 每个字符(包括 \0 )占 1 字节 。共 6 个元素,所以 Tsize = 6 * 1 = 6 字节(也等价于 sizeof(数组名) 的值 ) |
| Null-terminated | 是(存在 \0 ) |
| Length | 5(\0 前有效字符数 ) |
strlen():计算字符串的实际字符数,不包括终止符 '\0'
sizeof():计算字符数组的总长度,包括终止符 '\0
cs
#include <stdio.h>
#include <string.h>
int main() {
// 用字符串字面量初始化字符数组,编译器会自动在末尾加 '\0',数组实际存储:'a' 'b' 'c' '\0'
char str[] = "abc";
size_t len = strlen(str);
size_t size = sizeof(str);
printf("strlen(str) = %zu\n", len);
printf("sizeof(str) = %zu\n", size);
return 0;
}输出结果:
strlen(str) = 3
sizeof(str) = 4
strlen()和.length()是在不同编程语言中用于获取字符串长度的两种不同方式,它们的主要区别如下:
- 所属语言和类型
strlen():是 C 语言标准库中的函数(string.h),用于计算以空字符'\0'结尾的 C 风格字符串的长度。.length():是许多面向对象语言(如 C++、Java、JavaScript、Python 等)中字符串对象的方法或属性,直接返回字符串的字符数。
- 使用方式
strlen():需要传入字符串指针作为参数,例如:C
cschar str[] = "Hello"; size_t len = strlen(str); // 返回5
.length():作为对象的方法调用,例如:C++
cppstd::string str = "Hello"; int len = str.length(); // 返回5两者都是计算字符串的长度(length),即在空终结符\0之前的有效字符数。
字符串编码方式
多字节字符集(MBCS)、宽字符(宽字符串) 和 UTF-8



UTF-8
单字节:0xxxxxxx(7位X)双字节:110xxxxx 10xxxxxx(5位X + 6位X)
三字节:1110xxxx 10xxxxxx 10xxxxxx(4位X + 6位X + 6位X)
四字节:11110xxx 10xxxxxx 10xxxxxx 10xxxxxx(3位X + 6位X + 6位X + 6位X)
(2)C/C++中的字符串
字符串字面值

"
const char s[] = "abc"; //不要指定一个用字符串字面值初始化的字符数组的界限" 意思是,当用像"abc"这样的字符串字面值去初始化char数组时,建议让编译器自动推导数组的大小(即不手动写方括号里的数字) 。因为字符串字面值"abc"在实际存储时,除了包含'a'、'b'、'c'这三个字符,还会自动在末尾添加一个用于标记字符串结束的空符'\0',编译器能准确知晓需要多大的数组来容纳这些内容,手动指定大小容易出错或者显得多余。
关于const char s[4] = "abc";
语法与存储 :这样写在 C 和 C++ 里语法是合法的。因为字符串字面值
"abc"实际存储的是'a'、'b'、'c'、'\0',共 4 个字符,所以用const char s[4]来承载,能正确容纳这些内容,s数组里就会依次是'a'、'b'、'c'、'\0'。存在的问题 :虽然这么写结果可能是对的,但存在隐患。比如,要是后续修改了字符串字面值,把
"abc"改成更长的,比如"abcd",而数组大小还是写死的4,就会因为字符数量(连'\0'是 5 个)超过数组大小,导致数组越界等未定义行为 ;另外,手动写大小也显得冗余,毕竟编译器本就能自动算出来应该开多大的数组。所以才会建议直接用const char s[] = "abc";,让编译器自动处理数组大小。
字符类型
std::string

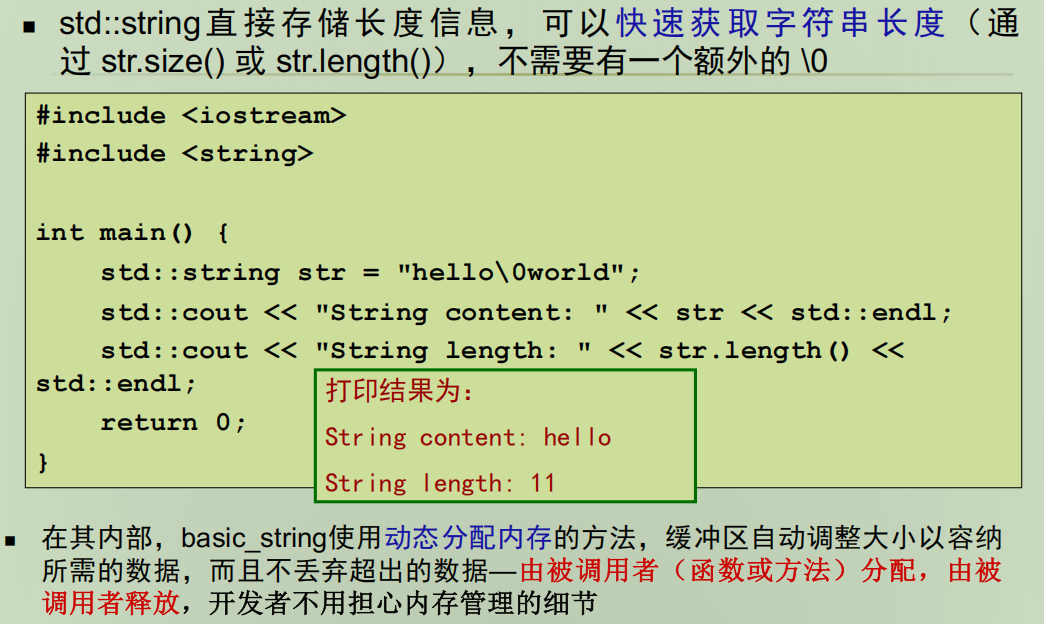
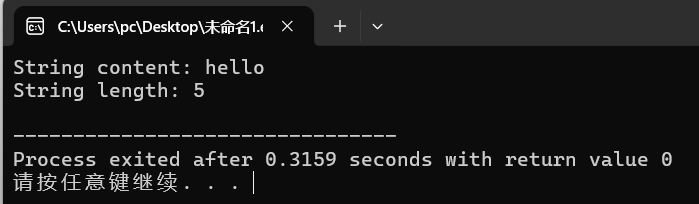
为什么是11???自己执行一遍,发现是5
cpp
#include<iostream>
#include<string>
int main() {
std::string str = "hello\0world";
std::cout << "String content: " << str << std::endl;
std::cout<< "String length: " << str.length() << std::endl;
return 0;
} 
- 字符串的初始化情况 :当使用字符串字面量
"hello\0world"对std::string进行初始化时,\0会被当作字符串结束的标志。所以,str实际上存储的内容仅仅是hello。- 输出内容方面 :
std::cout << str只会输出hello,因为std::string的输出操作是依据已存储的内容,而不是像 C 风格字符串那样依靠空字符来判断结束。- 字符串长度计算 :
str.length()返回的结果是 5,这是因为std::string在计算长度时,统计的是从开始到第一个空字符(初始化时遇到的)之间的字符数量。
关键区别总结
场景 输出内容 长度 原因 C++ std::stringhello5初始化时遇到 \0自动截断,str只包含hello。输出基于内部长度,而非\0。C 风格字符串 ( char[])hello5字符串以 \0结尾,strlen()和printf遇到\0停止。剩余字符world被忽略。为什么输出结果相同?
C++
std::string:
cppstd::string str = "hello\0world"; // 初始化截断为"hello" std::cout << str; // 输出"hello"(长度5)
std::string在初始化时遇到\0就停止解析,因此str内部只存储hello,长度为 5。C 风格字符串:
cschar str[] = "hello\0world"; // 数组实际为 ['h','e','l','l','o','\0','w','o','r','l','d'] printf("%s", str); // 输出"hello"(遇到\0停止)数组包含完整字符,但字符串以第一个
\0结尾,printf和strlen只处理到\0为止。核心差异示例
当显式指定长度时,差异才会体现
cpp// C++ std::string:显式指定长度 std::string str("hello\0world", 11); // 强制包含所有字符(包括\0) std::cout << str.length(); // 输出11 std::cout << str; // 输出"hello"(cout遇到\0停止)
cpp//在 C 风格字符串 中,无法直接 "显式指定长度" 来强制包含 \0 之后的字符, //因为 C 风格字符串的本质是以 \0(空字符)作为结束标志的字符数组, //所有依赖 C 风格字符串的函数(如 printf、strcpy 等)都会在遇到 \0 时停止处理。 char str[11] = {'h','e','l','l','o','\0','w','o','r','l','d'}; printf("%s", str); // 输出"hello",无法显示后续字符总结
- 原始代码输出相同是因为初始化方式(隐式截断)导致两者内容一致。
- 机制不同 :
std::string依赖内部长度,可存储\0;- C 风格字符串依赖
\0,无法存储\0作为有效字符。
std::string str = "helloworld";或者std::string str = "helloworld\0";运行结果:
String content: helloworld
String length: 10
字符常量类型

字符类型-unsigned char的独特属性
存储在 unsigned char 类型对象中的值,会被表示为二进制,并且不会被加上填充位
当需要操作的对象可能是任何类型(如结构体、数组、指针等),并且需要访问该对象的所有二进制位时, unsigned char类型非常有用
任何类型的非二进制位域(non-bit-field)对象都可以复制到unsigned char数组中,并通过逐个字节检查其二进制表示。
cs
//定义一个结构体 MyStruc
struct MyStruct {
int a; //整型成员,通常占 4 字节
float b; //单精度浮点型成员,通常占 4 字节
};
// 1. 初始化结构体对象
// 用初始化列表给结构体成员赋值,a 为 10,b 为 3.14
struct MyStruct obj = {10, 3.14};
// 2. 定义 unsigned char 数组 buffer
// sizeof(obj) 计算结构体对象占用的总字节数,用它作为数组长度,确保能容纳结构体所有二进制数据
unsigned char buffer[sizeof(obj)];
// 3. 将结构体复制到unsigned char 数组中
// memcpy 是 C 标准库函数,作用是从源地址(&obj)拷贝指定字节数(sizeof(obj))的数据到目标地址(buffer)
memcpy(buffer, &obj, sizeof(obj));
// 4. 将二进制数据写入文件
// fwrite 函数用于二进制写文件,参数依次是:数据缓冲区(buffer)、每个数据单元的大小(1 字节,因为 unsigned char 占 1 字节 )
// 数据单元的个数(sizeof(obj),即要写多少个 1 字节单元 )、文件指针(file)
fwrite(buffer, sizeof(unsigned char), sizeof(obj), file);
// 1. 定义并初始化 int 变量 x
int x = 0x12345678;
// 2. 定义 unsigned char 数组 buffer
// sizeof(x) 计算 int 变量占用的字节数(通常 4 字节 ),以此作为数组长度,确保容纳 x 的全部二进制数据
unsigned char buffer[sizeof(x)];
// 3. 将int 复制到unsigned char 数组中
memcpy(buffer, &x, sizeof(x));
// 4. 循环遍历 buffer 数组,逐字节打印二进制内容(以十六进制形式展示 )
// size_t 是无符号整数类型,用于表示对象大小
for (size_t i = 0; i < sizeof(x); i++) {
// %zu 用于输出 size_t 类型的 i;02X 表示以十六进制、取两位(不足两位前面补 0 )、大写形式输出 buffer[i] 的值
printf("Byte %zu: 0x%02X\n", i, buffer[i]);
}输出:
Byte 0: 0x78Byte 1: 0x56
Byte 2: 0x34
Byte 3: 0x12
%02X:用于输出无符号整数(如 bufferi)的十六进制表示,并按以下规则格式化:0:不足宽度时补前导零(如 05 而非 5)。
2:宽度至少为 2 位。
X:输出大写十六进制字母(如 A-F)
计算字符串大小
大小(size):分配给数组的字节数(等于sizeof(array))。
计数(count):在数组中的元素数目。
长度(length):在空终结符\0之前的字符数。
cs
#include <stdio.h>
#include <string.h>
int main() {
// 定义一个包含5个字符和1个终止符的字符数组
char arr[6] = "hello";
// 1. 大小(size):数组占用的总字节数
size_t size = sizeof(arr);
// 2. 计数(count):数组中的元素数目
size_t count = sizeof(arr) / sizeof(arr[0]);
// 3. 长度(length):终止符 '\0' 前的字符数
size_t length = strlen(arr);
printf("数组内容: %s\n", arr);
printf("大小(size): %zu 字节\n", size);
printf("计数(count): %zu 个元素\n", count);
printf("长度(length): %zu 个字符\n", length);
return 0;
}char arr\[\] = "hello";或者char arr6 = "hello";
数组内容: hello
大小(size): 6 字节
计数(count): 6 个元素
长度(length): 5 个字符
char arr7 = "hello";数组内容: hello
大小(size): 7 字节
计数(count): 7 个元素
长度(length): 5 个字符
宽字符串使用wchar_t类型表示;窄字符串使用char类型表示
char是 单字节字符类型 ,通常占1 个字节(8 位) ;sizeof(char)=1
wchar_t是宽字符类型,字节数不固定,因标准、编译器和平台而异Windows 上 :
sizeof(wchar_t)=2Linux、macOS 上:
sizeof(wchar_t)=4
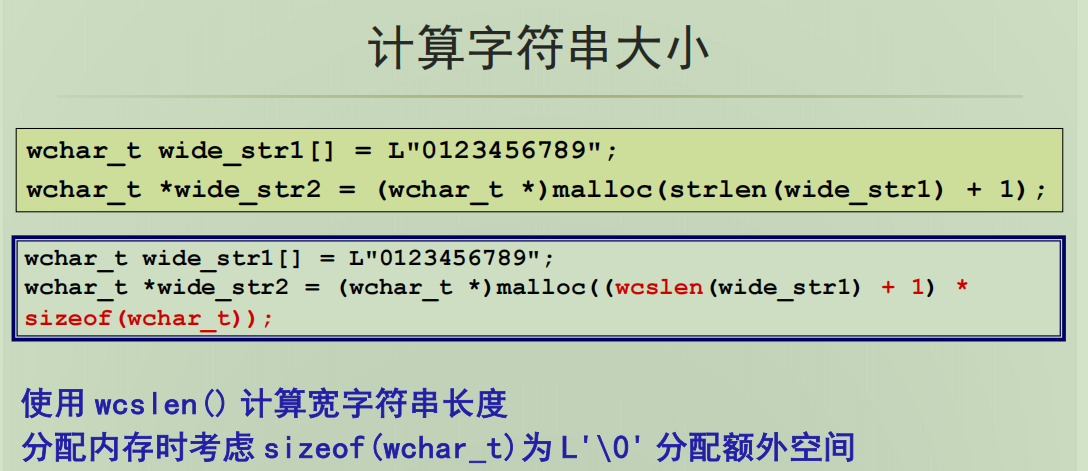
wchar_t *wide_str2 = (wchar_t *)malloc(strlen(wide_str1) + 1);这行代码试图为宽字符串动态分配内存,但存在错误。
strlen函数用于计算普通字符串(char类型字符串)的长度,不能直接用于宽字符串。对于宽字符串,应该使用wcslen函数来计算长度。因此,这里使用strlen会导致分配的内存空间不足,无法正确存储宽字符串。
wchar_t *wide_str2 = (wchar_t *)malloc((wcslen(wide_str1) + 1) * sizeof(wchar_t));
wcslen(wide_str1) + 1是为了给宽字符串结尾的空宽字符L'\0'预留空间。然后乘以sizeof(wchar_t)是因为malloc函数以字节为单位分配内存,而我们需要分配的是能存储宽字符的内存空间,所以要确保分配的字节数足够存储指定数量的宽字符。
sizeof(wchar_t):转换为字节数
wchar_t类型的大小在不同系统上可能不同:
- Windows:通常是 2 字节(UTF-16 编码)
- Linux/macOS:通常是 4 字节(UTF-32 编码)
malloc函数以 字节 为单位分配内存,因此必须乘以sizeof(wchar_t)- 这个表达式的核心逻辑是:
(字符串长度 + 1个终止符) × 每个宽字符占的字节数 = 所需总字节数
(3)常见的字符串操作错误(安全缺陷)
可以辨析即可
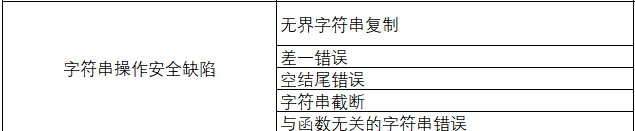
无界字符串复制(unbounded string copy )
差一错误( off-by-one error )
空结尾错误( null termination error )
字符串截断( string truncation )无界字符串复制(unbounded string copy)
本质 :使用
strcpy等无长度限制的字符串复制函数,将源字符串内容复制到目标缓冲区时,不检查目标缓冲区剩余空间,若源字符串长度超过目标缓冲区可容纳的大小,就会发生缓冲区溢出(栈溢出 / 堆溢出等 )。风险:破坏内存布局(覆盖相邻变量、返回地址等 ),可能导致程序崩溃、执行流劫持(如注入恶意代码 ),是栈溢出攻击的典型 "导火索"。
差一错误(Off-by-One Error )
逻辑 :因边界条件处理失误,循环、数组索引或缓冲区操作时,多操作或少操作一个字符。比如本应循环处理
n个字符,却因i <= n而非i < n,导致超出预期范围。影响:可能造成缓冲区溢出(多写一个字符覆盖相邻内存 )、数组越界访问,或字符串截断异常。这类问题较隐蔽(仅差一个字符 ),调试、发现难度高,但可能引发严重内存安全问题。
空结尾错误(null termination error)
- 关键 :C/C++ 等语言中,字符串依赖
\0(空字符 )标识结尾。若操作中丢失、错误处理空字符,会破坏字符串结构。比如:
- 未正确添加
\0,导致字符串后续内存被误读为有效内容,输出 / 处理时出现乱码、逻辑错误;- 错误覆盖
\0位置,使字符串 "变长",超出缓冲区范围引发溢出。- 风险:程序逻辑异常(如字符串比较、拼接出错 ),或因字符串边界失控引发内存安全问题。
字符串截断(string truncation)
场景 :目标缓冲区空间不足时,强行截断字符串(如
strncpy未正确补\0,或业务逻辑直接截断用户输入 )。问题 :截断后字符串可能失去完整语义(如用户密码、关键标识被截断 ),导致功能异常(如登录验证失败 );若截断未妥善处理(如未补
\0),还可能引发空结尾错误、后续内存解析混乱。与函数无关的字符串错误
- 范畴 :不依托特定字符串函数(如
strcpy/strcat),而是因业务逻辑、内存管理等层面的设计缺陷,引发的字符串安全问题。比如:
- 手动拼接字符串时,未计算总长度,导致缓冲区溢出;
- 多线程环境下,字符串共享资源未加锁,并发操作引发数据混乱;
- 对字符串编码(如 UTF-8 转 GBK )处理不当,产生截断、乱码甚至溢出。
- 特点:成因更分散,需结合具体业务逻辑排查,常因开发者对 "字符串全生命周期(创建、处理、销毁 )" 考虑不全引发。
简单归纳:无界字符串复制 :聚焦 "无长度校验的复制操作",直接关联缓冲区溢出;
差一错误 :因 "边界 ±1 失误" 引发,问题隐蔽但危害连锁;
空结尾错误 :围绕
\0字符的丢失 / 破坏,动摇字符串 "结尾标识" 基础;字符串截断 :强调 "内容被截断" 的结果,可能引发功能 / 语义异常;
与函数无关的字符串错误 :脱离特定库函数,因业务 / 逻辑设计缺陷产生,覆盖场景更广。
(4)字符串漏洞及其利用

在 C/C++ 中,字符串常以
\0(空字符)作为结束标志,但输入数据(如用户输入密码)可能包含换行符\n(或其他特殊字符),若未正确处理,会导致 逻辑漏洞 (如密码验证绕过)或 内存问题(如缓冲区溢出)。
IsPasswordOK()这类函数,通常用于验证用户输入的密码是否合法,但如果对输入字符串的边界(如\n、内存分配)处理不当,就会被利用攻击。手动去掉
\n:Password[strcspn(Password, "\n")] = '\0';
问题场景 :
用户输入密码时,输入可能带换行符(如用
fgets()读取时,fgets会把输入的\n一并读入字符串)。而密码验证逻辑通常只认\0前的字符,若保留\n,会导致验证逻辑错误(比如预期密码是123,实际存成123\n,验证时匹配失败)。代码拆解:
strcspn(Password, "\n"):
扫描Password,找到第一个\n的位置 ,返回该位置的索引(比如Password是"123\n45",则返回3,即'\n'的索引)。Password[... ] = '\0';:
把\n所在位置替换成\0,直接截断字符串。比如原字符串是"123\n",处理后变成"123",确保密码验证逻辑正确。
①\n手动换成\0如上面的例子,若函数逻辑依赖
\0作为字符串结束,而输入可能引入\n,则必须主动替换。这是因为不同函数对 "字符串结束" 的定义不同(比如fgets保留\n,但密码验证逻辑只认\0)。② 函数返回指针时,判空再使用
若函数返回动态分配的字符串(如
char* GetPassword()),使用前必须检查是否为NULL:
cschar* pwd = GetPassword(); if (pwd != NULL) { // 安全使用 pwd printf("密码:%s\n", pwd); free(pwd); // 动态内存需释放 } else { // 处理失败逻辑(如内存分配失败) printf("获取密码失败!\n"); }若不判空,直接使用
NULL指针会触发段错误(Segfault)。③ 动态内存记得
free若字符串是动态分配的(如用
malloc、new分配),使用完必须释放,否则会导致 内存泄漏。例如:
cs//在堆内存中分配一块连续的、大小为 100 字节的空间,用于存储字符数据(如字符串)。 //malloc(100) 返回一个 void* 类型的指针,指向新分配内存的起始地址。 //(char*) 强制类型转换:将 void* 转换为 char*,以便赋值给 pwd 变量。 char* pwd = (char*)malloc(100); if (pwd != NULL) { // 使用 pwd ... free(pwd); // 释放内存,避免泄漏 }
gets不会限制输入的字符数,读完后将换行符从输入中移除,并自动用空字符(\0)替换它
解析:
gets会读取换行符\n,但不会将其存入缓冲区 ,而是自动用\0替代。例如,用户输入
abc\n,gets会将Password设为"abc\0",无需手动处理换行符。
cs#include <stdio.h> // 提供标准输入输出函数,如printf、gets、puts #include <string.h> // 提供字符串处理函数,如strcmp #include <stdlib.h> // 提供标准库函数,如exit // 验证用户输入的密码是否正确 // 返回值:如果密码正确返回true(1),否则返回false(0) bool IsPasswordOK(void) { char Password[12]; // 定义长度为12的字符数组存储密码 // 实际只能存储11个字符+1个字符串结束符'\0' gets(Password); // ❗️危险:使用gets函数读取输入 // 该函数无法限制输入长度,可能导致缓冲区溢出 // 攻击者可通过超长输入覆盖相邻内存区域,执行任意代码 // 验证输入的密码是否等于预设密码"goodpass" return 0 == strcmp(Password, "goodpass"); } int main(void) { bool PwStatus; // 存储密码验证结果 puts("Enter password:"); // 提示用户输入密码 PwStatus = IsPasswordOK(); // 调用密码验证函数 // 检查密码验证结果 if (PwStatus == false) { puts("Access denied"); // 密码错误,输出拒绝访问 exit(-1); // 终止程序,返回错误码-1 } puts("Access granted"); // 密码正确,输出访问授权 return 0; // 程序正常结束,返回0 }
虽然
gets函数在读取输入时具有不限制字符数、自动处理换行符的特点,但它在实际编程中存在严重的安全隐患和设计缺陷,因此不建议使用,主要原因如下:1.缓冲区溢出风险(最核心问题)
gets函数无法限制读取的字符数量,当用户输入的字符数超过目标缓冲区的大小时,会导致缓冲区溢出。例如
cschar password[10]; // 假设缓冲区只能存9个字符(+1个\0) gets(password); // 若用户输入"1234567890123"(13个字符),超出的字符会覆盖相邻内存后果:
程序崩溃:覆盖关键内存区域(如函数返回地址、栈帧数据),导致程序异常终止。
安全漏洞:恶意用户可利用缓冲区溢出执行任意代码(如注入病毒或获取系统权限),这是 C 语言中最危险的安全隐患之一。
2.缺乏错误处理机制
gets函数无法区分 "读取成功" 和 "读取失败"(如遇到文件结束符EOF),因为它没有返回值用于判断操作状态。而更安全的函数(如fgets)会返回NULL表示错误,便于开发者处理异常。3.设计上的替代方案更优
C 语言中推荐使用
fgets函数替代gets,其优势如下:
特性 getsfgets字符数限制 无限制,易导致溢出 可指定最大读取字符数 换行符处理 移除换行符并替换为 \0保留换行符在缓冲区中 安全性 高风险 低风险(正确使用时) 错误处理 无返回值判断 返回 NULL表示错误
fgets的正确使用示例
cschar buffer[100]; if (fgets(buffer, sizeof(buffer), stdin) != NULL) { // 处理输入(可能包含换行符,如需移除可手动处理) buffer[strcspn(buffer, "\n")] = '\0'; }
fgets会限制读取的字符数,会读入换行符;但会截断,截断后会自动添加\0
cs#include <stdio.h> // 包含标准输入输出库 #include <stdlib.h> // 包含标准库(如exit函数) #include <string.h> // 包含字符串处理函数(如strcmp, strcspn) // 验证用户输入的密码是否正确 bool IsPasswordOK(void) { char Password[12]; // 定义一个长度为12的字符数组存储密码(最多11个有效字符+1个字符串结束符) // 从标准输入读取最多11个字符(留一个位置给字符串结束符) fgets(Password, sizeof(Password), stdin); // 查找换行符'\n'首次出现的位置,并将其替换为字符串结束符'\0' // 这样可以消除fgets可能读入的换行符 Password[strcspn(Password, "\n")] = '\0'; // 将处理后的用户输入与预设密码"goodpass"进行比较 // 若相同则strcmp返回0,return 0==0 转换为bool类型后为true,否则返回非0值(false) return 0 == strcmp(Password, "goodpass"); } int main(void) { bool PwStatus; // 存储密码验证结果的布尔变量 puts("Enter password:"); // 提示用户输入密码 PwStatus = IsPasswordOK(); // 调用密码验证函数并保存结果 // 检查密码验证结果 if (PwStatus == false) { puts("Access denied"); // 验证失败提示 exit(-1); // 终止程序并返回错误码-1 } puts("Access granted"); // 验证通过提示 return 0; // 程序正常结束返回0 }
问:既然fgets会限制读取的字符数,会读入换行符并且会截断,截断后会自动添加\0 ;那为什么还要 Passwordstrcspn(Password, "\\n") = '\0';
fgets的行为分析
fgets的行为取决于输入内容的长度:
情况 1 :输入的字符数 ≥ 缓冲区大小 - 1 (例如用户输入了 11 个字符到
Password[12]中)
fgets会读取 恰好sizeof(Password)-1个字符 (即 11 个),不会读取换行符 ,并在第 12 个位置(下标 11)自动添加\0。此时
Password的内容是[用户输入的11个字符][\0],没有换行符。情况 2 :输入的字符数 < 缓冲区大小 - 1 (例如用户输入了 5 个字符)
fgets会读取 所有字符 + 换行符\n,并在其后添加\0。
此时Password的内容是[用户输入的5个字符][\n][\0]。
- 为什么需要
strcspn处理换行符?在 情况 2 中,
Password末尾会包含一个换行符\n。如果直接用strcmp与"goodpass"比较,会因为\n的存在导致比较失败(即使密码本身正确)。例如:
- 用户输入
goodpass(回车),Password实际内容是"goodpass\n\0"。strcmp("goodpass\n", "goodpass")返回非零值,验证失败。
strcspn(Password, "\n")的作用:
- 找到
Password中第一个\n的位置,并将其替换为\0。- 如果输入包含换行符(如情况 2),这行代码会移除换行符 ,确保
Password只包含用户实际输入的内容。- 如果输入没有换行符(如情况 1),
strcspn会返回缓冲区大小 - 1(即 11),此时Password[11]已经是\0,这行代码不会改变任何内容。
gets_s() 返回一个指针,如果成功读取,返回的是输入字符串的指针; 如果失败(例如输入超出缓冲区的大小),返回 NULLgets_s会限制读取的字符数,不保留换行符在字符串中; 会截断,截断后会自动添加\0
csbool IsPasswordOK(void) { // 定义一个长度为12的字符数组存储密码(可容纳11个字符和1个字符串结束符) char Password[12]; // 使用安全版本的输入函数gets_s读取密码 // 参数1:目标缓冲区;参数2:缓冲区大小 // 若读取失败(如输入超长或发生错误)返回NULL,此时返回验证失败 if (gets_s(Password, sizeof(Password)) == NULL) { return false; } // 将输入的密码与预设密码"goodpass"进行比较 // 若相同则strcmp返回0,return 0==0 转换为bool类型后为true,否则返回非0值(false) return 0 == strcmp(Password, "goodpass"); }
csbool IsPasswordOK(void) { char *Password = NULL; // 初始化为NULL,由getline动态分配内存 size_t len = 0; // 初始大小为0,getline会设置合适的大小,会自动添加\0 // 使用getline从标准输入读取一行,自动分配内存并设置len // 返回读取的字符数(不含终止符),出错或EOF时返回-1 ssize_t nread = getline(&Password, &len, stdin); // 处理读取失败的情况(如EOF或输入错误) if (nread == -1) { free(Password); // 释放可能已分配的内存 return false; // 返回验证失败 } // 移除字符串末尾的换行符(如果存在) // strcspn返回首个'\n'的位置,将其替换为字符串终止符 Password[strcspn(Password, "\n")] = '\0'; // 安全比较输入的密码与预设密码"goodpass" bool result = (0 == strcmp(Password, "goodpass")); free(Password); // 释放动态分配的内存,防止内存泄漏 return result; // 返回比较结果 }如果输入的行超出了初始缓冲区大小,getline() 会自动调整缓冲区的大小,避免缓冲区溢出。
1、会读入换行符
2、要记得free
3、要记得失败处理
(5)栈溢出攻击(理解记忆,无需死记)

栈溢出攻击
核心逻辑 :程序向栈中缓冲区写入数据时,未检查数据长度,写入内容超出缓冲区边界,覆盖栈中其他关键数据(如返回地址、栈帧基址等 ),破坏程序栈结构,进而劫持程序执行流。比如函数里用
gets这类不安全函数读取用户输入,输入超长就可能触发。代码注入
定义 :攻击者往程序内存空间(如栈、堆)注入自定义恶意代码(像 shellcode ),并想办法让程序执行这些注入的代码,从而获取权限、破坏程序等。
与栈溢出关系 :栈溢出常是代码注入的 "跳板"------ 利用栈溢出覆盖返回地址,让程序跳转到注入的恶意代码区域执行。但现代系统开启
NX/DEP(数据执行保护 )后,直接在栈 / 堆执行注入代码会被阻止,推动了 ROP 等绕过技术发展。
弧注入 Arc Injection: 将控制流转移到程序中已有的代码(如 libc 库中的函数), 而不
是注入新代码shellcode 的攻击手段(漏洞利用的技术)
返回导向编程( ROP )是一种更复杂的攻击方法。
它不用注入代码、 不依赖于直接跳转到一个函数,而是通过精确控制栈上的返回地址, 依次跳转到程序中的多个 现有代码片段( gadgets,通常以 ret 指令 结尾 )逐步执行攻击
(6)防御措施(理解记忆,无需死记)
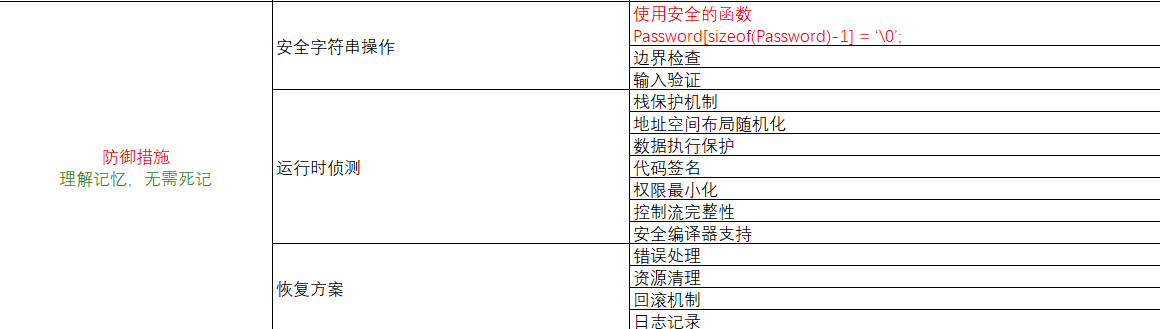
安全字符串操作(预防)

sizeof():计算字符数组的总长度,包括终止符 '\0
如果
Password是字符数组 (如char Password[100];),sizeof(Password)会直接返回数组总长度(这里是100字节 )。
sizeof(Password) - 1数组下标从
0开始,最后一个元素的下标是总长度 - 1 。比如数组长度是
100,最后一个下标是99,确保修改的是数组最后一个位置。
运行时侦测

恢复方案
