知识驱动型AI应用场景
知识驱动型AI应用场景式企业级AI智能体的常见抓手。该类型的场景能充分利用大语言模型的自然语言处理能力,相对独立的提供全新的用户体验。落地该场景,可以在有限的预算内大幅提升企业用户对AI技术的信心。
核心原理
知识驱动型场景对应的是知识驱动型AI智能体,其核心是知识库(注意与传统的基于全文检索的知识库做区分)。知识库类似于数据库管理软件,只不过这里的数据换成了相对静态的知识,查询也从等于、不等于、大于、小于、包含等明确的查询条件,变成了基于语义近似性的模糊查询。如在数据库管理软件中,我们无法通过"喵喵"查询到包含有"猫猫"的记录;但在知识库中,这两词因为存在一定的语义相似性,就可以被查询到了。这种查询之所以能够实现,是因为它将文本(也可以是图片、视频、语音等多模态文件,但目前效果最好、最常用的是文字)转换为了多维向量(也称矢量),通过计算向量的距离,就能找到在语义上最接近的匹配值了,整个过程如图1所示。
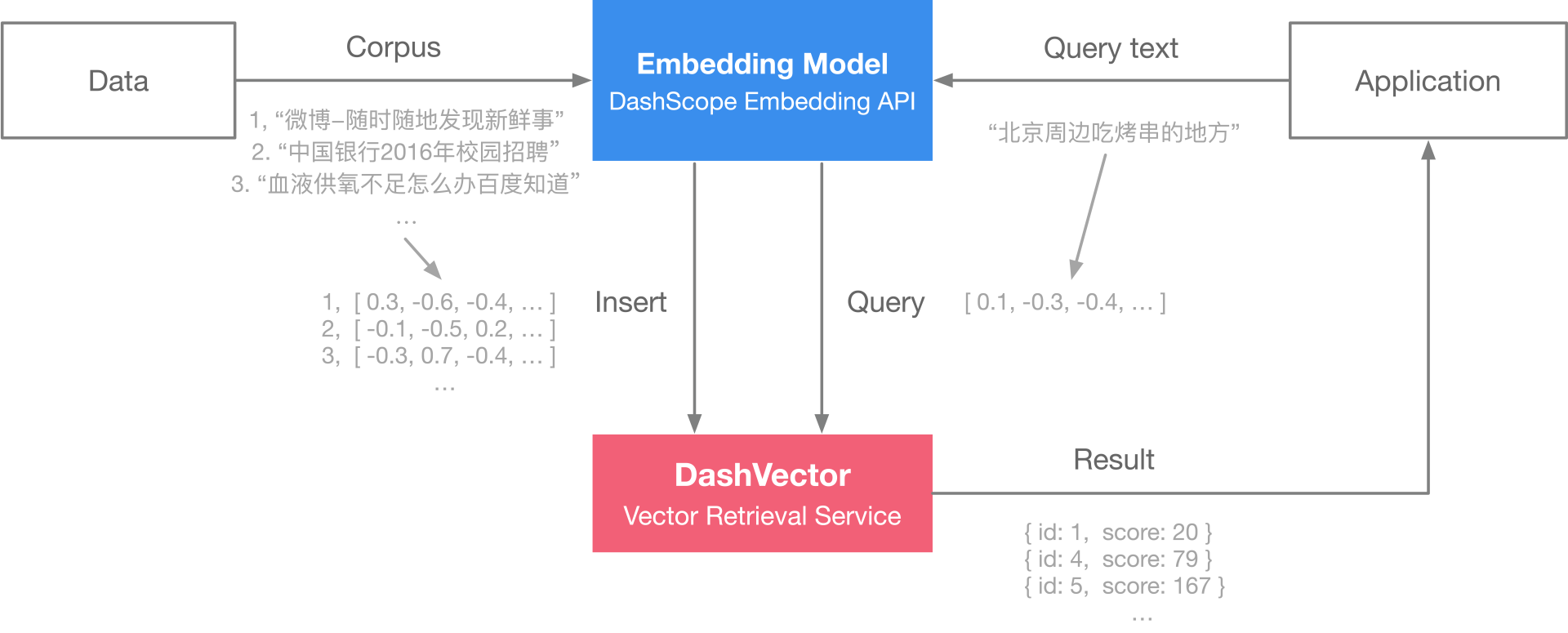
凭借着语义相似性分析能力,知识库大幅扩充了"检索"的范围,从精确匹配变成了更智能的匹配方式,从而为用户带来了更多新体验,催生出了更多知识驱动型AI场景。
典型场景
典型的知识驱动型场景有:
- 知识问答:通过输入文字(或语音转文字)的方式,查询相关的知识内容
- 文本合规:通过输入大段文本,检查其与相关知识内容的匹配程度
通常不被纳入知识驱动型的场景有:
- 图片识别:如基于计算机视觉的生产缺陷检查,此类场景推荐采用判别式AI(特定领域的小模型)实现
- 智能问数:如通过输入文字从数据库中查询高实时性的数据,此类场景推荐采用Text2SQL等范式实现,必要时可引入一个或多个知识驱动型AI智能体承担同近义词分析功能(类似知识问答)
- 实用技巧:规则越模糊,知识驱动型AI越容易获益;规则清晰到满足IFTTT(如果这样就那样),直接将其固化为软件通常是更高效的方案。
RAG模式
知识库通常采用检索增强生成(RAG)范式来实现,如图2所示,技术相对成熟。
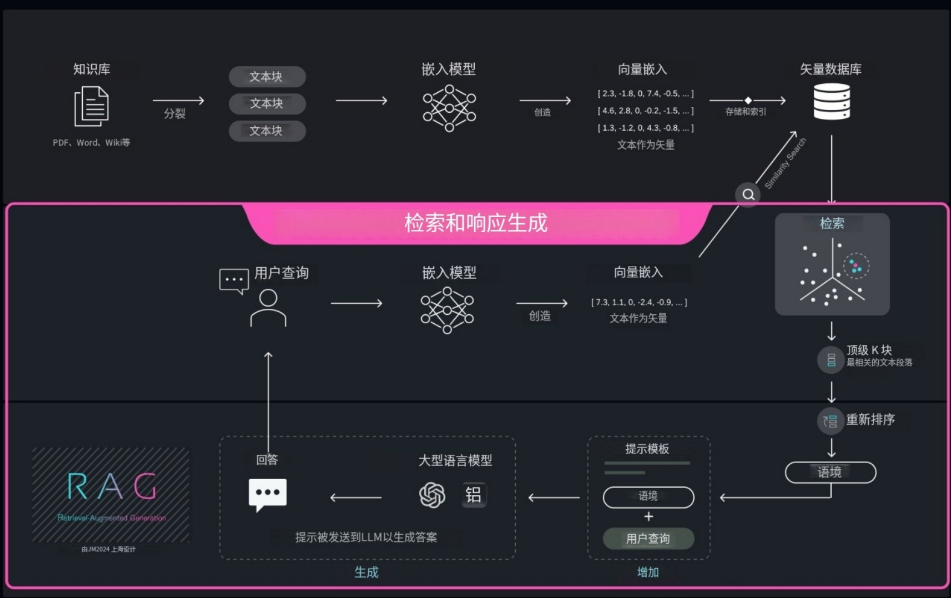
(图2 RAG的基本流程)
在RAG中,我们可以将知识库分为两大板块,分别为知识库的构建和知识库的使用(图2中粉色现况中的区域),先构建再使用。
核心功能与技术原理:构建
- 原始知识切片:按照知识源文件(包含有特定领域知识的一个或多个文件、网页或数据库中的记录)中内容本身的结构,将其拆解为多条包含有id、文本(仅包含文本内容)、原始内容(包含有文本、图片、音视频等格式的原始记录)和排序权重(质量更高的知识,初始权重通常更高一些)的数据记录并存入关系型数据库,每一个记录通常是存储在数据库中的一行。
- 向量生成:利用向量生成领域的专用大模型(如阿里云百炼的"通用文本向量-v4"),将知识切片中的文本转换为向量(形式为float数组),即文本向量化
- 存入向量库:将向量和对应的数据记录id一起存入专门的向量数据库中
核心功能与技术原理:使用
- 用户查询向量化:类似于构建版块,我们需要将用户输入的文本(或语音转的文字)采用同样的方法转换为向量
- 向量查询:使用上一步转换的向量在向量数据库中查询,获取符合要求(向量距离不超过阈值、总数量不超过阈值)的若干个id
- 文本召回:使用这些id,在文本切片的数据库中查询对应的文本、原始内容和权重
- 重新排序:利用重排序领域的专用大模型(如阿里云百炼的"深度文本重排序"),基于用户输入的原始文字,对文本召回的文本或原始内容进行重新排序。在排序过程中,也可以加入更多预设规则,如针对数据库中存储的权重对专用大模型返回的结果进行二次调整
- 生成最终答案:将排序后的原始内容拼接到提示词模板中,与用户输入的文字一起交给大模型,接收AI的返回结果
- 展示结果:在结果展示阶段,知识驱动场景通常需要在展示AI返回结果的同时,展示相关的知识片段,即原始内容,提升可解释性,满足用户需求。
向量数据库选择
向量数据库不同于传统数据库,需要提供包括向量距离计算、排序、检索等功能。目前主流的向量数据库有独立运行的Qdrant,类似于MySQL,在独立的进程中运行,可以部署到应用服务器以外,更方便扩展;嵌入式运行的Faiss,类似于Guava Cache,运行在当前进程的内存中。前者通常适用于对扩展性和性能上限要求高的互联网场景;后者因为部署更简单,更适用于企业场景。
此外,如果预算充裕、合规性要求相对较弱,采购云平台提供的SaaS版向量数据服务(如阿里云的"向量检索服务 DashVector")也是一种常见的做法。
多模态向量融合 vs 仅采用文本向量
2025年夏,多个厂家已经推出了支持多模态的向量生成专用大模型(如阿里云百炼的"通用多模态向量"),可以将文本与图片一同生成向量。但从实际测试效果上看,针对文本生成的向量与针对图片生成的向量间存在较大差异,如果一个矢量库中同时有两种来源的向量,两者的向量距离并不能做横向对比,这对于整个知识库的表现将带来更大的不确定性。
基于当前的技术水平,我们不推荐在同一个知识库中同时包含图片向量和文本向量。而是建议采用图片理解领域专用大模型(如阿里云百炼的"通义千问VL-Plus")先将图片转为文字后,再将其融入某个知识切片或作为单独的知识切片处理。
技术限制
该类型场景的实际落地效果主要受知识质量的影响,排序等策略也会存在一定的优化空间,但通常不会成为主要因素。
高质量的知识通常具备以下特征:
- 结构化强:知识有明确的"章节"特征,相关性强的内容聚集在一起,而不是分散在多处。
- 文字化程度高:知识以文字为主,如果涉及到图片或视频,均配套了详细的说明文字,对其进行介绍。
- 无歧义、无冲突:文字表达精确,上下文完整。在同一个领域(知识库)内,经过人工检查,没有明显的歧义或冲突内容。
为了快速提升知识的质量,常见的做法如下:
- 领域细分:根据业务实际情况,将一个知识库拆分为若干个知识库,从而降低发生冲突的风险。尽量避免多领域的知识混在在同一个知识库中,是提升知识质量最简单有效的方案。不过这通常意味着用户需要在使用问答前选择一个或多个领域,体验上大一些折扣,互联网服务通常不会做出这种妥协,但企业软件中这是常态,因为企业中的知识和场景天生具备较强的领域性。
- 知识治理:投入人力对知识进行梳理和校对,在原始知识切片的基础上,对切片中的文本和原始内容进行修改,避免歧义和冲突。该项工作通常作为数据治理项目的一个环节,由专门的公司或团队完成,属于技术含量较低的人力密集型工作。
- 人工扩充:在知识治理过程中,对于缺失的知识内容,可人工进行扩充。需要注意的是,扩充的知识仍然需要满足对知识的质量要求,通常会安排在知识治理工作之前完成。
- 实时反馈:主要应用在知识问答场景。与人工扩充类似,在使用的过程中,允许用户对AI返回的结果进行打分,对于哪些用户认可的回答,可将其以"问答对"的形式纳入知识库中,实现常用常新的效果。这种模式下,通常需要配套定期的人工检查机制,确保这些新纳入的问答对是正确、有效的。互联网服务中不推荐这么做,因为我们无法约束和管理用户的行为,可能会出现恶意注入低质量知识的风险;企业软件中,因为记录存在可追溯性,在管理制度的保障下,通常会达到预期的效果。
活字格的技术实现
为了充分展现RAG范式下的知识驱动型AI场景落地,我们使用活字格低代码开发平台构建了一个相对完成的知识库Demo和两个配套的智能应用,架构如图3所示。全部模块,包含知识库均采用活字格实现,无需编码开发。
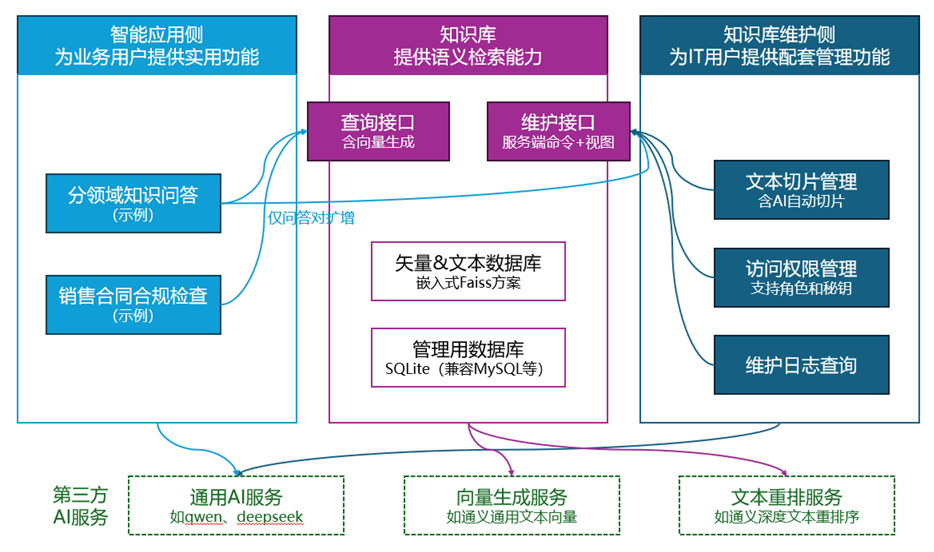
(图3 活字格知识库Demo架构简图)
方案设计
本方案针对企业中最常见的规章制度类场景设计,具有以下设计特征:
- 向量数据库采用嵌入式方案,Faiss
- 文本切片调用兼容主流大模型,如百炼qwen-turbo-latest
- 向量模型采用百炼通用文本向量-v4(支持单纯文本向量,暂不支持多模态向量)
- 文本重排采用百炼深度文本重排序
- 大语言模型兼容主流方案,如百炼qwen-max-latest
- 权限控制(用户)基于活字格内置的RBAC权限方案
- 不提供AI自动扩增,不会基于文本切片生成问答对(通常适用于知识质量较高的场景)
- 支持基于反馈的自动扩增,用户点击"有用"后自动将当前会话,以优选问答的名义添加到知识库(通常适用于企业级场景)
- 对知识库维护,含自动扩增,实时生效
本方案中不包含,但通常需要提供的设计有:
- 将PDF/Word等格式的问题抽取为富文本(包含但不限于md格式或html格式)和文本(由图片理解服务,如百炼"通义千问VL-Max"生成图片的描述信息)
- 支持将富文本(md、html等格式的图片文字混排)作为"原始内容"进行展示
- 根据预设的权重优化"重排序"
技术实现
接下来,我们将按照模块,逐个介绍关键技术实现在活字格工程中所在的位置。
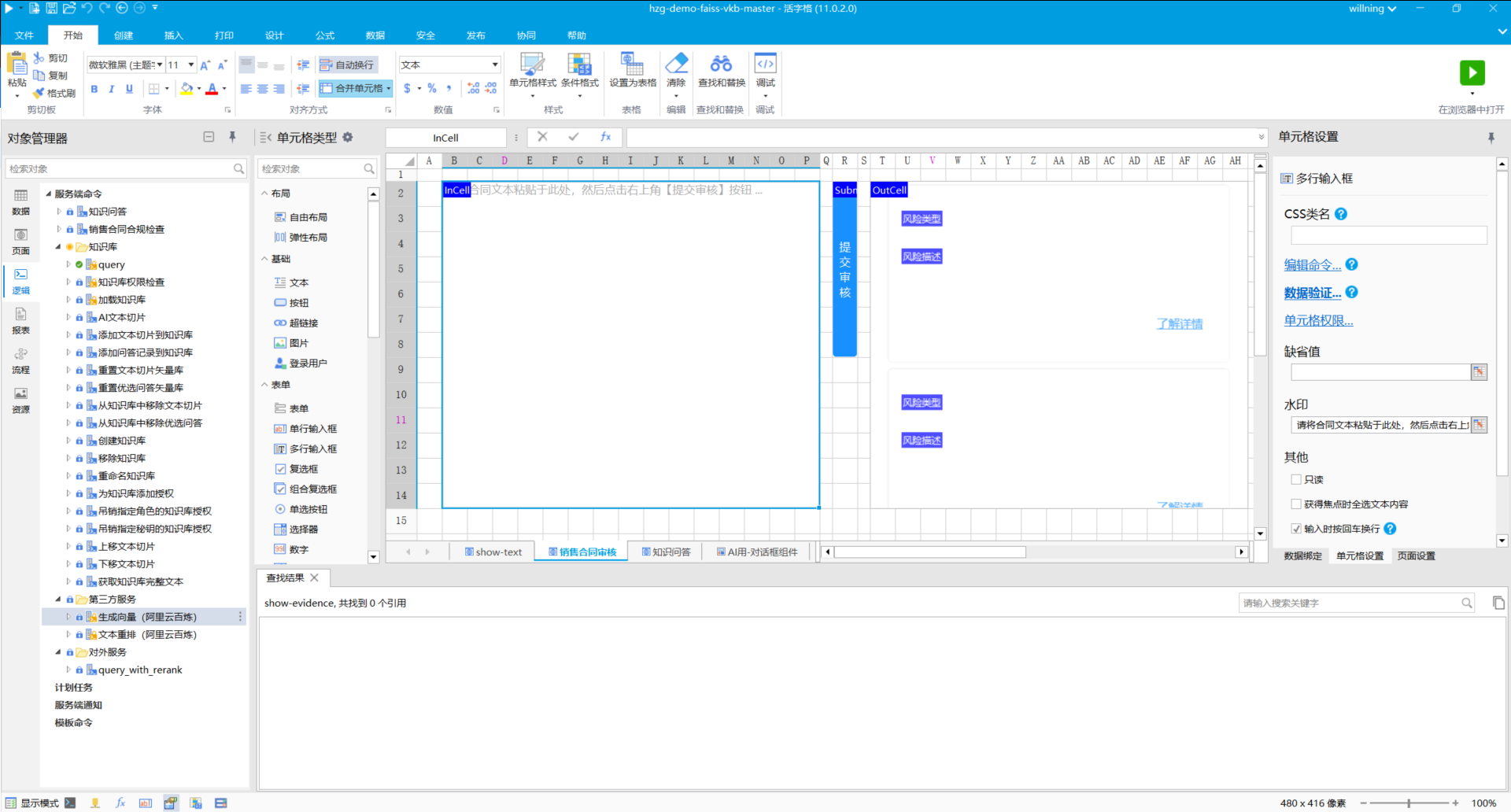
(图4 活字格中实现的知识库示例)
知识库
从知识库中查询:服务端命令【query_with_rerank】,完整的知识库查询接口,接收需要查询的知识库ID(每个领域的知识存放在单独的知识库中,如需跨领域查询,可用逗号分隔)和用户查询文本,返回排序后的知识内容,含类型(文本切片/优选问答)、id、原始内容、访问该原始内容的URL(配套知识展示页面使用)。
从知识库中查询(单一知识库、未重排):私有服务端命令【query】,查询功能集中在本服务端命令,包含RAG范式下 "用户查询向量化"、"向量查询"、"文本召回" 三个环节,以及作为基础的向量索引的加载、权限控制等功能。RAG范式的 "重新排序" 环节放在【query_with_rerank】中,以实现跨领域查询时的重排效果。
知识库维护侧
- 前端管理界面:页面下【知识库维护】文件夹中各页面,包含了知识库的创建、重命名与标记删除、知识库权限设置、文本切片的增删改查与重建、优选问答的删除与重置等功能。
- 后端业务逻辑:逻辑下【知识库】文件夹中除【query】外的各服务端命令,承载了前端管理界面的全部业务逻辑。
智能应用侧(知识问答)
- 后端:逻辑下【知识问答】服务端命令。在该服务端命令中,先通过调用【query_with_rerank】从知识库中查询到排序后的相关知识,再通过"AI助手命令"完成RAG范式中的 "生成最终答案" 环节,对数组对象的形式返回。
- 前端:页面下【知识问答】页面、【show-evidence】页面和组件下全部组件,完成RAG范式中的 "展示结果" 环节,包括对话中展示摘要信息,并提供对应的"查看相关内容"按钮,展现知识库的原始内容。
- 优选问答:页面下【AI用-详情页按钮】组件中提供"有用"按钮,页面下【知识问答】页面中AI用-对话框组件的"点击有用"事件处理器中,通过调用【添加问答记录到知识库】服务端命令完成自动扩增。
智能应用侧(销售合同审核)
- 后端:逻辑下【销售合同合规检查】服务端命令。在该服务端命令中,先通过调用【query_with_rerank】从知识库中查询到排序后的相关知识,再通过"AI助手命令"完成RAG范式中的 "生成最终答案" 环节,以JSON文本的形式返回。
- 前端:页面下【销售合同合规检查】页面、【show-text】页面和组件下全部组件,完成RAG范式中的 "展示结果" 环节,包括在右侧检查结果图文列表中展示摘要信息,并提供对应的"查看详情"按钮,展现知识库的原始内容。