神经网络学习笔记:第二章 - 神经网络的训练过程
目录
- [1️⃣ 前向传播(Forward Propagation)](#1️⃣ 前向传播(Forward Propagation))
- [2️⃣ 损失函数(Loss Function)](#2️⃣ 损失函数(Loss Function))
- [3️⃣ 反向传播(Backpropagation)](#3️⃣ 反向传播(Backpropagation))
- [4️⃣ 参数更新(Gradient-Descent)](#4️⃣ 参数更新(Gradient-Descent))
- 5️⃣代码实现
- [6️⃣ 前向传播与反向传播的依赖](#6️⃣ 前向传播与反向传播的依赖)
我将会先从理论公式部分讲解各个部分的内容,再进行代码编写的演示
有时我们会发现,我们在实际操作时只需要调用库或调用包就能实现的操作,里面的逻辑十分精妙
虽然我们身处大模型时代,但我们依然需要以求知的精神看待Network learning
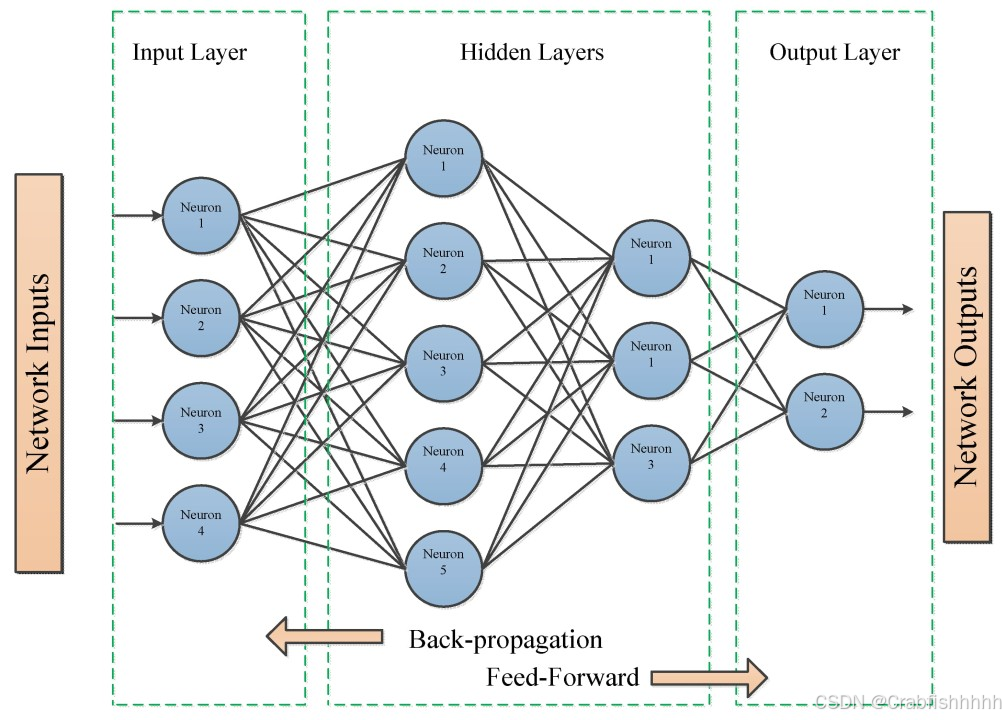
1️⃣ 前向传播(Forward Propagation)
前向传播是神经网络的推理过程:输入数据 → 经过各层网络 → 输出结果(预测值)。
数学表示:
假设有两层网络结构:
- 输入层 x ∈ R n x \in \mathbb{R}^n x∈Rn
- 隐藏层权重 W 1 W_1 W1,偏置 b 1 b_1 b1,激活函数 σ \sigma σ
- 输出层权重 W 2 W_2 W2,偏置 b 2 b_2 b2
h = σ ( W 1 x + b 1 ) y ^ = W 2 h + b 2 h = \sigma(W_1 x + b_1) \\ \hat{y} = W_2 h + b_2 h=σ(W1x+b1)y^=W2h+b2
2️⃣ 损失函数(Loss Function)
损失函数衡量预测值 y ^ \hat{y} y^ 与真实值 y y y 之间的差异。
常用损失函数包括:
-
均方误差(MSE):用于回归问题
L = 1 2 ∑ ( y ^ i − y i ) 2 L = \frac{1}{2} \sum (\hat{y}_i - y_i)^2 L=21∑(y^i−yi)2 -
交叉熵(Cross Entropy):用于分类问题
L = − ∑ y i log ( y ^ i ) L = -\sum y_i \log(\hat{y}_i) L=−∑yilog(y^i)
3️⃣ 反向传播(Backpropagation)
反向传播的目标是通过链式法则,计算每个参数对损失函数的梯度。
简要步骤:
- 计算输出层的误差 δ ( 2 ) \delta^{(2)} δ(2)
- 反向传播至隐藏层,计算 δ ( 1 ) \delta^{(1)} δ(1)
- 用 δ \delta δ 更新参数
链式法则是核心:
d L d W = d L d a ⋅ d a d z ⋅ d z d W \frac{dL}{dW} = \frac{dL}{da} \cdot \frac{da}{dz} \cdot \frac{dz}{dW} dWdL=dadL⋅dzda⋅dWdz
4️⃣ 参数更新(Gradient Descent)
最常见的是梯度下降算法,更新公式:
θ : = θ − η ∂ L ∂ θ \theta := \theta - \eta \frac{\partial L}{\partial \theta} θ:=θ−η∂θ∂L
其中:
- θ \theta θ:参数(如 W W W、 b b b)
- η \eta η:学习率(learning rate)
代码实现:手写前向传播 + 反向传播
python
import numpy as np
# 初始化参数
W1 = np.random.randn(2, 2)
b1 = np.zeros((2, 1))
W2 = np.random.randn(1, 2)
b2 = np.zeros((1, 1))
def sigmoid(x):
return 1 / (1 + np.exp(-x))
def sigmoid_deriv(x):
return sigmoid(x) * (1 - sigmoid(x))
# 前向传播
def forward(x):
z1 = W1 @ x + b1
a1 = sigmoid(z1)
z2 = W2 @ a1 + b2
a2 = sigmoid(z2)
return z1, a1, z2, a2
# 反向传播
def backward(x, y, z1, a1, z2, a2, lr=0.1):
dz2 = a2 - y
dW2 = dz2 @ a1.T
db2 = dz2
dz1 = (W2.T @ dz2) * sigmoid_deriv(z1)
dW1 = dz1 @ x.T
db1 = dz1
# 更新参数
global W1, b1, W2, b2
W2 -= lr * dW2
b2 -= lr * db2
W1 -= lr * dW1
b1 -= lr * db1小结
在训练深度学习模型时,前向传播和反向传播是相互依赖的。
前向传播 将输入数据依次传递经过神经网络,计算输出结果和损失(Loss)。
反向传播 基于损失值,通过链式法则计算每层参数对损失的梯度(∂Loss/∂W)
-
反向传播必须知道前向传播中每一层的中间输出(activation)值,因为计算梯度时需要用到这些结果。
-
前向传播提供损失值(loss)作为反向传播的"起点"。
-
如果前向传播出错,反向传播的梯度方向就不准确,训练将失效。
输入 x
│
▼
前向传播(Forward)
└─> 得到输出 ŷ 和损失 Loss
│
▼
反向传播(Backward)
└─> 计算 ∂Loss/∂W,更新参数
在实际使用中,比如使用 PyTorch 框架训练神经网络时,前向传播和反向传播的调用是自动完成的
python
import torch
import torch.nn as nn
import torch.optim as optim
# 1. 构建一个简单的线性模型
model = nn.Linear(10, 1) # 输入10维,输出1维
loss_fn = nn.MSELoss() # 均方误差损失
optimizer = optim.SGD(model.parameters(), lr=0.01)
# 2. 假设我们有一些输入和标签
x = torch.randn(32, 10) # 32个样本,每个10维
y = torch.randn(32, 1) # 32个目标值
# 3. 前向传播:计算预测值
y_pred = model(x) # 🔹 前向传播
# 4. 计算损失
loss = loss_fn(y_pred, y) # 🔹 得到损失(loss)
# 5. 反向传播:计算梯度
loss.backward() # 🔸 反向传播(自动计算梯度)
# 6. 更新参数
optimizer.step() # 🔸 参数更新
optimizer.zero_grad() # 梯度清零,为下一轮做准备loss.backward() 是触发反向传播的核心。
PyTorch 自动记录前向传播中涉及的运算图(autograd),再通过链式法则自动反推每一层的梯度。
前向传播中每一层的输出会被缓存,用于反向传播计算梯度。
总结
一句话总结:
前向传播是神经网络计算输出预测的过程,它依据 函数复合与链式计算 的原理;
反向传播是通过误差反向传播调整参数的过程,它依据 链式法则与梯度下降 的原理。
🔧 实际应用中:
- 前向传播的代码通常表现为模型的
forward()函数,例如:
python
output = model(input)- 反向传播通过 loss.backward() 自动完成梯度计算,例如:
python
loss = criterion(output, target)
loss.backward()前向传播通常出现在:
项目代码的 模型设计与推理模块 中
作用是生成模型预测的输出结果
反向传播通常出现在:
训练流程中损失计算后的优化步骤
作用是根据损失指标调整模型的可学习参数