免责声明:本文仅作分享!!!
# -*- coding: utf-8 -*-
import os
import requests
import urllib.parse
from concurrent.futures import ThreadPoolExecutor
from time import sleep
# 请求的基本 URL 和用户代理
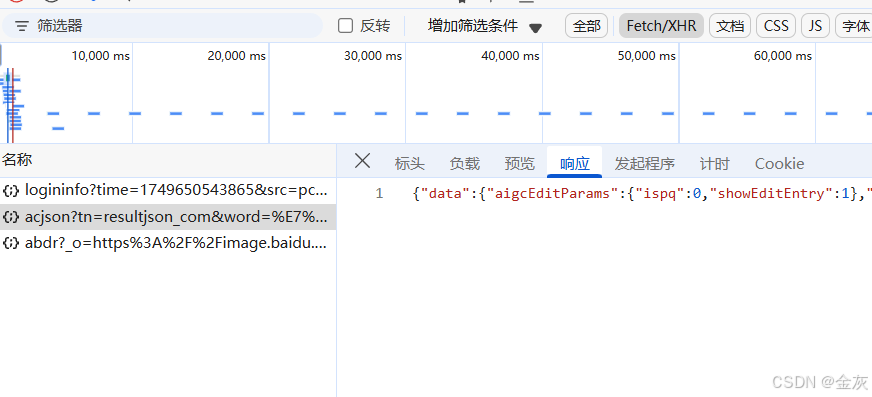
url0 = 'https://image.baidu.com/search/acjson?'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) '
'AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.6261.95 Safari/537.36'
}
# 定义爬虫的主函数
def fetch_image(url, save_dir, image_index):
try:
# 请求图片的JSON数据
response = requests.get(url, headers=headers)
response.raise_for_status()
data = response.json()
# 遍历获取到的图片链接
for i in range(30):
try:
image_url = data['data'][i]['middleURL']
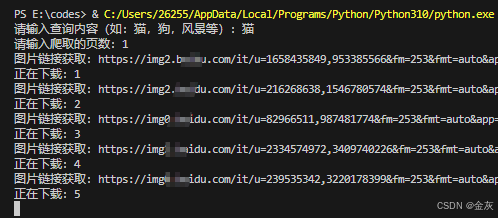
print(f"图片链接获取:{image_url}")
# 下载图片
image_data = requests.get(image_url, headers=headers, timeout=5)
image_data.raise_for_status()
# 图片保存路径
image_path = os.path.join(save_dir, f"{image_index}图片.png")
with open(image_path, 'wb') as file:
file.write(image_data.content)
print(f"正在下载:{image_index}")
image_index += 1
sleep(0.5) # 为了避免请求过快,加入短暂延时
except requests.exceptions.RequestException as e:
print(f"下载图片时发生错误: {e}")
except requests.exceptions.RequestException as e:
print(f"请求图片数据时发生错误: {e}")
# 获取用户输入并验证
def get_user_input():
name = input("请输入查询内容(如:猫,狗,风景等):")
while True:
try:
shnm = int(input('请输入爬取的页数:'))
if shnm <= 0:
raise ValueError("页数必须大于 0")
return name, shnm
except ValueError as e:
print(f"无效输入:{e}, 请重新输入")
# 创建文件夹(如不存在)
def create_directory(dir_name):
if not os.path.exists(dir_name):
os.mkdir(dir_name)
return dir_name
# 主函数
def main():
# 获取用户输入
name, shnm = get_user_input()
save_dir = create_directory(name) # 创建保存图片的文件夹
nums = 120 # 每页返回的图片数量
page_executor = ThreadPoolExecutor(max_workers=5) # 限制最大并发请求数为 5
image_index = 1
for s in range(shnm):
nums += 30 # 每页加30,翻到下一页
data = {
"tn": "resultjson_com", "logid": "", "ipn": "rj", "ct": "201326592", "is": "",
"fp": "result", "fr": "", "word": name, "cg": "head", "queryWord": name,
"cl": "", "lm": "", "ie": "utf-8", "oe": "utf-8",
"adpicid": "", "st": "", "z": "", "ic": "", "hd": "",
"latest": "", "copyright": "", "s": "", "se": "", "tab": "", "width": "",
"height": "", "face": "", "istype": "", "qc": "", "nc": "", "expermode": "",
"nojc": "", "isAsync": "", "pn": nums, "rn": "30", "gsm": "78",
}
da = urllib.parse.urlencode(data) # 将参数转换为 URL 编码
url = url0 + da # 拼接完整的 URL
# 提交请求到线程池
page_executor.submit(fetch_image, url, save_dir, image_index)
page_executor.shutdown(wait=True) # 等待所有线程执行完成
print("爬虫任务完成!")
# 执行主函数
if __name__ == "__main__":
main()