B 站又双叒叕崩了,这次是真炸裂了!6 月 12 日晚 9 点左右,我还在直播呢,突然就看到弹幕都在说 B 站炸了,我立马坐不住了,光速下波,作为一名前大厂程序员,就爱吃大厂的瓜,就爱吃同行的瓜,吃瓜就要在最前线!作为一名技术人员,下面带大家一起吃瓜,也说说我对这个事故的理解。
老规矩,优先推荐看视频版~ https://bilibili.com/video/BV1eDMwzvEy1(服了,被卡了很久审核)
事故情况
这次的事故可不是小打小闹,时间长、异常多、影响面大,关键是还上了各平台的热搜。
从晚上 5 点多开始出现异常,直到 9 - 10 点才陆续恢复,整整折腾了 快 4 个小时 !
你是不是也怀疑自己断网了?
这次的事故现场惨不忍睹啊:
1)主页报错,要么是打不开,要么推荐一些莫名其妙不感兴趣的内容,有朋友反映主页突然出现一堆小姐姐(笑死,正常情况下我也是这样的)
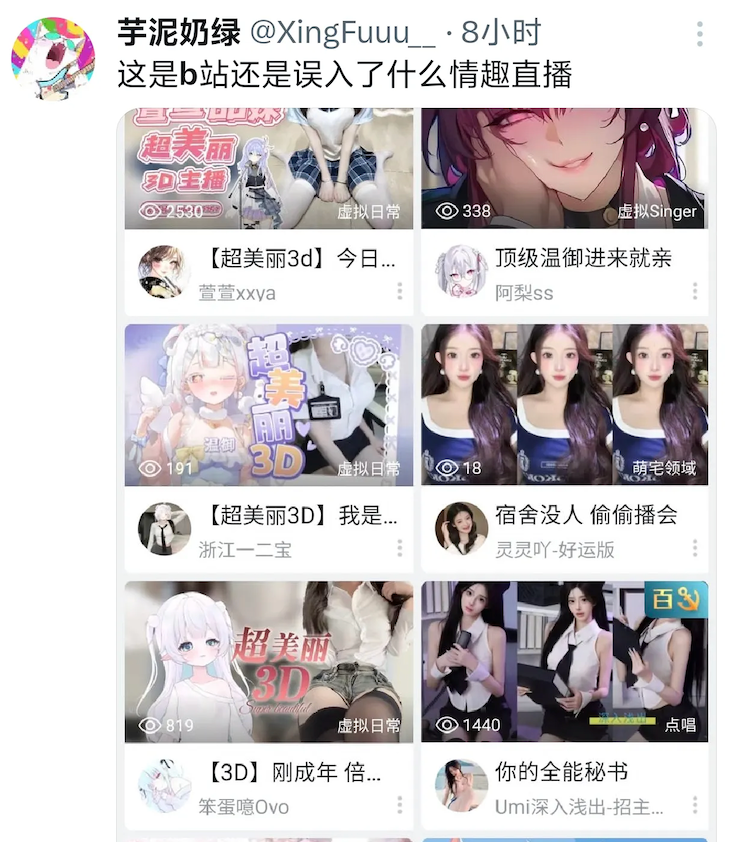
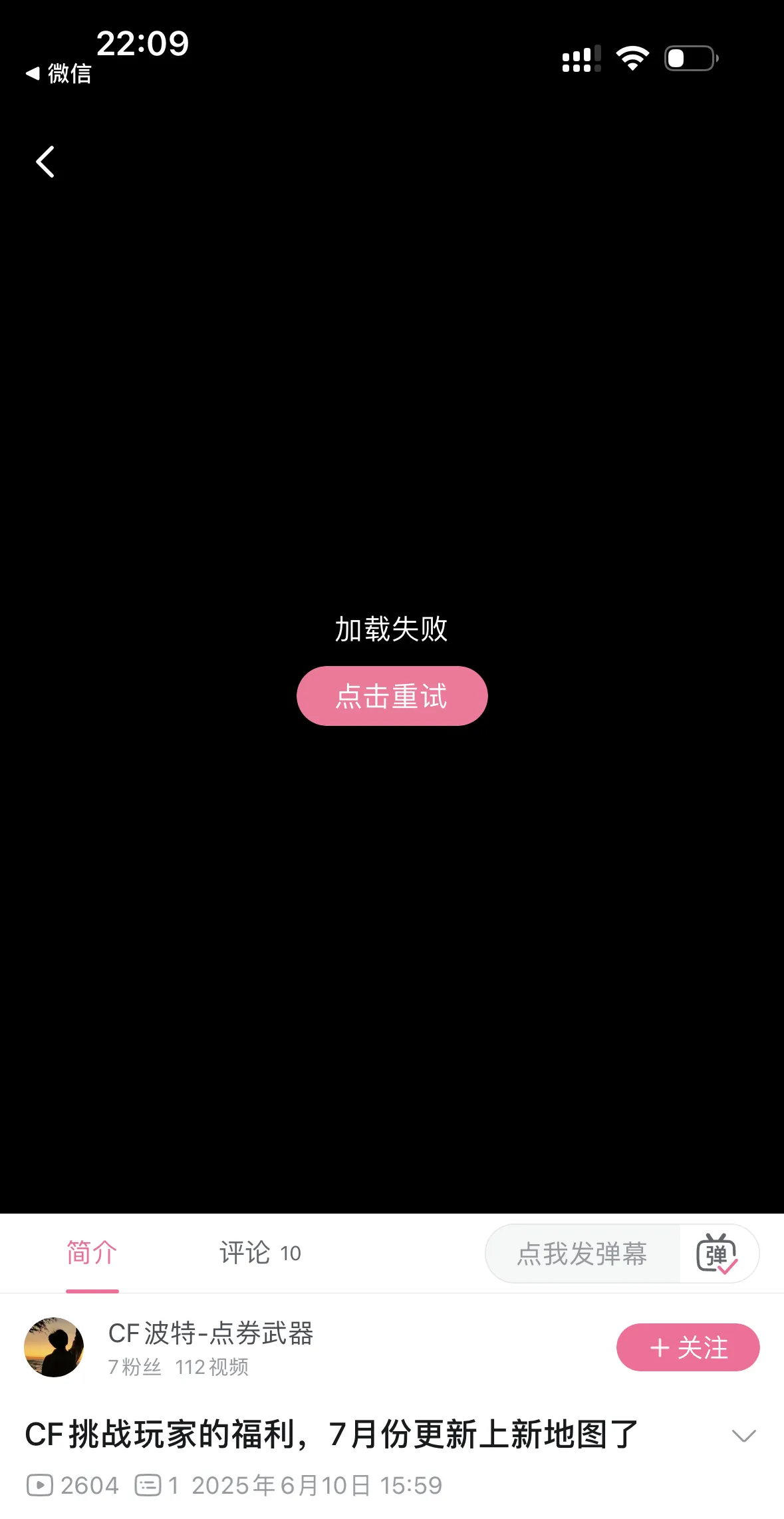
2)视频无法播放,加载失败
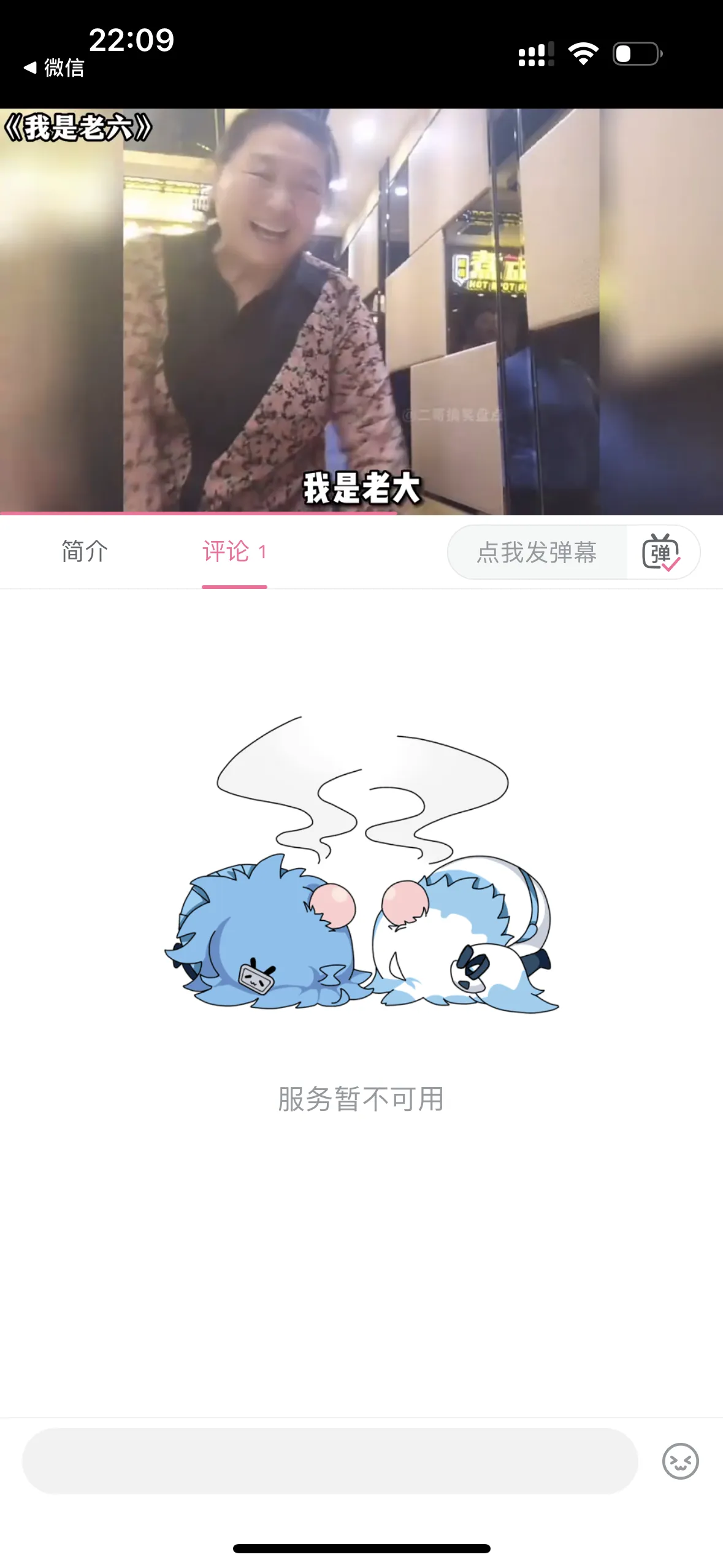
3)评论区无法加载、显示"服务暂不可用"
4)博主的个人主页打不开,UP 主们都慌了

5)我的直播虽然没有中断,但是弹幕时不时就会丢失,观众都跑完了!
6)系统卡了很多次,有网速但是就是进不去

7)最关键的是,有些页面直接出现了 504 错误!

真的可以说是 全链路崩盘 了!
小道消息
据内部人员小道消息称,这次事故是受到公司基建 discovery 故障影响,约有 10% 左右的请求失败;基础架构炸了,在疯狂抢修。。。
个人分析
虽然不是内部人员,但是从专业技术人员的角度,也说说我对这次事故的分析和看法。
首先,这次的事故算是血崩,高低是个 P0 级事故 。对于 B 站这样的大型系统,背后起码有成千上万个服务器对吧?肯定用了微服务架构,把大系统拆分成不同的服务,有的服务专门负责播放视频,有的专门处理评论,有的跑推荐算法。能够同时影响到这些服务的,到底是何方神圣呢?
没错,就是 Service Discovery 服务发现系统 ,听起来很高大上,但其实很好理解。
它就像是一个存储了海量地址信息的导航系统,当用户执行了 B 站的某个操作,比如点击一个视频的时候,其实是向网关服务器发了一个请求,然后网关它要知道把这个请求交给哪个服务器去处理,就需要找到 Discovery 导航系统,获取到服务器的地址信息,然后就可以把请求转发给这台服务器去处理了。
那为什么 Discovery 一崩,整个 B 站就跟着崩了呢?这就是微服务架构的一个特点 ------ 高度依赖服务发现。打个比方,如果 B 站是一个超大型商场,Discovery 就是商场里的导购台和所有的指示牌系统。
想象一下,如果商场里所有的指示牌突然全部黑屏了,导购台的工作人员也被降本增效了,会发生什么?顾客找不到电影院在哪里,找不到餐厅,找不到卫生间,甚至找不到出口!
然后我们再看看那个 504 错误 Gateway Time-out。作为程序员看到这个错误,DNA 动了,我第一反应就是:"这是网关层面的问题!"
504 错误是什么呢?就是负责接受和转发请求的网关服务器,在等待后端服务响应的时候超时了。用人话说,就像你给朋友打电话,电话是通了,但是朋友在那边一直不说话,你等啊等,最后实在等不下去了,就挂掉了。
这就更证实了我刚才的分析啊,请求能到达 B 站的大门口,但是门口的接待员找不到或者联系不上里面具体负责的部门来处理请求,等来等去就超时了。
还有一个很有意思的点,据说这次只有 10% 左右的请求失败 。这个数据其实挺有信息量的!为什么不是 100% 都挂了呢?
这说明几个问题:第一,B 站肯定部署了多个 Discovery 服务实例,专业术语叫 集群部署 。就像商场不会只有一个导购台,而是有好几个,其中一部分坏了,其他的还能用。第二,可能有一些 容错机制 在起作用,比如缓存机制,没办法从服务器获取到最新的信息,咱就退而求其次,直接把之前加载过临时存在服务器内的数据返回给用户,这就是为什么有些朋友看到的推荐内容是乱七八糟的。
第三,可能有 降级策略 ,就是当主要的 Discovery 服务不可用时,会启用备用的服务发现机制。
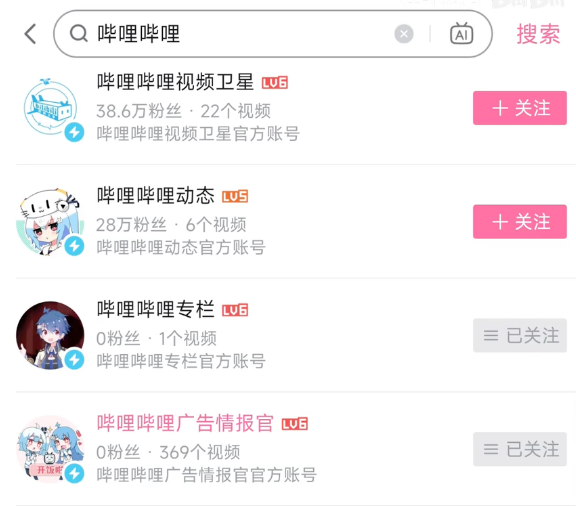
如下图,官方 0 粉丝名场面,本质上也是一种降级(或者缓存):
最后一个现象也很有意思,就是直播没有中断,但是弹幕会时不时丢失。这就体现了微服务架构的特点 ------ 不同的业务域是相对独立的 。
直播服务和弹幕服务虽然都是B站的功能,但是它们在技术架构上可能属于不同的服务集群。直播服务可能有自己独立的服务发现机制,或者它使用的 Discovery 集群比较稳定;而弹幕服务可能更依赖于出故障的那个 Discovery组件。
事故的启示
吃瓜归吃瓜,这次事故也能带给我们程序员一些技术启示:
1)基础设施的重要性:Discovery 这种基础服务,虽然用户看不见,但是一旦出问题,影响面巨大
2)高可用设计的必要性: 5% - 10% 的失败率说明 B 站的容灾设计还是有效的,否则就是 100% 崩溃,所以大家不要再反讽我们 B 站技术总监毛剑大大出品的《B 站高可用架构实践》课了。
3)监控和告警的价值: 能够快速定位到 Discovery 故障,说明监控系统还是给力的。不给力也没办法啊,我们热情友好的 B 友们都是人工监控,这压力给的足足的。
最后
说实话,作为一个程序员,看到这种大厂故障,心情是复杂的。。。
一方面,会有一种 "同行不易" 的感慨。在互联网公司当程序员,最怕的就是半夜被故障电话叫起来,然后开始疯狂排查问题、修复系统。今晚 B 站的技术小哥们肯定是在拼命救火。

另一方面,这也提醒我们,再大的平台也会有故障,技术的世界没有 100% 的完美。
最后,阿 B 咱就是说,这么大的故障,高低得送一波大会员补偿一下是不是?就当给我们这些热情用户一点点打工费嘛。
如果你也是程序员,欢迎在评论区分享你对这次故障的看法;如果你是普通用户,希望我的分析能帮你理解技术故障背后的原理,吃瓜吃的更懂。
记得点赞关注鱼皮,下次大厂出故障,我继续带大家从技术角度吃瓜!好吧,我希望世界和平~