目录
[Chapter9 Exception and Interrupt Handling](#Chapter9 Exception and Interrupt Handling)
[9.1 Exception Handling](#9.1 Exception Handling)
[9.2 Interrupts](#9.2 Interrupts)
[9.3 Interrupt Handling Schemes](#9.3 Interrupt Handling Schemes)
[9.4 Summary](#9.4 Summary)
[Chapter10 Firmware](#Chapter10 Firmware)
[10.1 Firmware and Bootloader](#10.1 Firmware and Bootloader)
[10.2 Example: Sandstone](#10.2 Example: Sandstone)
[10.3 Summary](#10.3 Summary)
[Chapter11 Embedded Operating Systems](#Chapter11 Embedded Operating Systems)
[11.1 Fundamental Components](#11.1 Fundamental Components)
[11.2 Example: Simple Little Operating System](#11.2 Example: Simple Little Operating System)
[11.3 Summary](#11.3 Summary)
[Chapter12 Caches](#Chapter12 Caches)
[12.1 The Memory Hierarchy and Cache Memory](#12.1 The Memory Hierarchy and Cache Memory)
[12.2 Cache Architecture](#12.2 Cache Architecture)
[12.3 Cache Policy](#12.3 Cache Policy)
[12.4 Coprocessor 15 and Caches](#12.4 Coprocessor 15 and Caches)
[12.5 Flushing and Cleaning Cache Memory](#12.5 Flushing and Cleaning Cache Memory)
[12.6 Cache Lockdown](#12.6 Cache Lockdown)
[12.7 Caches and Software Performance](#12.7 Caches and Software Performance)
[12.8 Summary](#12.8 Summary)
[Chapter13 Memory Protection Units](#Chapter13 Memory Protection Units)
[13.1 Protected Regions](#13.1 Protected Regions)
[13.2 Initializing the MPU, Caches, and Write Buffer](#13.2 Initializing the MPU, Caches, and Write Buffer)
[13.3 Demonstration of an MPU system](#13.3 Demonstration of an MPU system)
[13.4 Summary](#13.4 Summary)
[Chapter14 Memory Management Units](#Chapter14 Memory Management Units)
[14.1 Moving from an MPU to an MMU](#14.1 Moving from an MPU to an MMU)
[14.2 How Virtual Memory Works](#14.2 How Virtual Memory Works)
[14.3 Details of the ARM MMU](#14.3 Details of the ARM MMU)
[14.4 Page Tables](#14.4 Page Tables)
[14.5 The Translation Lookaside Buffer](#14.5 The Translation Lookaside Buffer)
[14.6 Domains and Memory Access Permission](#14.6 Domains and Memory Access Permission)
[14.7 The Caches and Write Buffer](#14.7 The Caches and Write Buffer)
[14.8 Coprocessor 15 and MMU Configuration](#14.8 Coprocessor 15 and MMU Configuration)
[14.9 The Fast Context Switch Extension](#14.9 The Fast Context Switch Extension)
[14.10 Demonstration: A Small Virtual Memory System](#14.10 Demonstration: A Small Virtual Memory System)
[14.11 The Demonstration as mmuSLOS](#14.11 The Demonstration as mmuSLOS)
[14.12 Summary](#14.12 Summary)
[Chapter15 The Future of the Architecture](#Chapter15 The Future of the Architecture)
[15.1 Advanced DSP and SIMD Support in ARMv6](#15.1 Advanced DSP and SIMD Support in ARMv6)
[15.2 System and Multiprocessor Support Additions to ARMv6](#15.2 System and Multiprocessor Support Additions to ARMv6)
[15.3 ARMv6 Implementations](#15.3 ARMv6 Implementations)
[15.4 Future Technologies beyond ARMv6](#15.4 Future Technologies beyond ARMv6)
[15.5 Summary](#15.5 Summary)
[Suggested Reading](#Suggested Reading)
Chapter9 Exception and Interrupt Handling
嵌入式系统的核心是异常处理程序。它们负责处理外部系统产生的错误、中断和其他事件。高效的处理程序可以显著提高系统性能。确定一个良好的处理方法的过程可能会复杂、具有挑战性,但也是有趣的。
在本章中,我们将介绍异常处理的理论和实践,特别是在ARM处理器上处理中断的方法。ARM处理器有七种异常类型,可以中止正常的指令顺序执行:数据中止、快速中断请求、中断请求、预取中止、软件中断、复位和未定义指令。
本章分为三个主要部分:
■ 异常处理。异常处理涵盖了ARM处理器处理异常的具体细节。
■ 中断。ARM将中断定义为一种特殊类型的异常。本节讨论了中断请求的使用,以及介绍了与中断处理相关的一些常见术语、特性和机制。
■ 中断处理方案。最后一节提供了一组中断处理方法。每种方法都附带了一个示例实现。
9.1 Exception Handling
异常是指任何需要中止正常顺序执行指令的条件。例如,当ARM核心复位时,当指令获取或内存访问失败时,当遇到未定义指令时,当执行软件中断指令时,或者当外部中断被触发时。异常处理是处理这些异常的方法。
大多数异常都有一个关联的软件异常处理程序------当异常发生时执行的软件例程。例如,数据中止异常将有一个数据中止处理程序。处理程序首先确定异常的原因,然后处理异常。处理可以在处理程序内部进行,也可以通过跳转到特定的服务例程来进行。复位异常是一个特殊情况,因为它用于初始化嵌入式系统。
本节涵盖以下异常处理主题:
■ ARM处理器模式和异常
■ 向量表
■ 异常优先级
■ 链接寄存器偏移量
9.1.1 ARM Processor Exceptions and Modes

表9.1列出了ARM处理器的异常。每个异常都会导致核心进入特定的模式。此外,通过更改cpsr,可以手动进入ARM处理器的任何模式。用户模式和系统模式是唯一不由相应异常进入的两种模式,换句话说,要进入这些模式,必须修改cpsr。当异常引起模式改变时,核心会自动执行以下操作:
■ 将cpsr保存到异常模式的spsr中
■ 将pc保存到异常模式的lr中
■ 将cpsr设置为异常模式
■ 将pc设置为异常处理程序的地址

图9.1显示了异常及其关联模式的简化视图。请注意,当异常发生时,ARM处理器总是切换到ARM状态。
9.1.2 Vector Table
第2章介绍了向量表------一张地址表,ARM核心在引发异常时会跳转到其中的地址。这些地址通常包含以下形式的分支指令:
■ B <address>---此分支指令相对于pc提供一个分支。
■ LDR pc, pc, #offset---此加载寄存器指令将处理程序地址从内存加载到pc。该地址是一个存储在向量表附近的绝对32位值。加载这个绝对字面值会导致在分支到特定处理程序时稍微延迟,因为需要额外的内存访问。但是,您可以分支到内存中的任何地址。
■ LDR pc, pc, #-0xff0---此加载寄存器指令从地址0xfffff030加载特定的中断服务例程地址到pc。当存在向量中断控制器(VIC PL190)时,才会使用此特定指令。
■ MOV pc, #immediate---此移动指令将立即值复制到pc。它允许您跨越整个地址空间,但受限于对齐方式。地址必须是通过右移偶数位得到的8位即时数。
向量表还可以包含其他类型的指令。例如,FIQ处理程序可能从偏移量 +0x1c 处开始。因此,FIQ处理程序可以立即从FIQ向量位置开始,因为它位于向量表的末尾。分支指令使pc跳转到可以处理特定异常的特定位置。

表9.2显示了每个异常的异常、模式和向量表偏移量。
Example 9.1
图9.2展示了一个典型的向量表。未定义指令项是一个分支指令,用于跳转到未定义处理程序。其他向量使用带有LDR加载到pc指令的间接地址跳转。
请注意,FIQ处理程序也使用了LDR加载到pc指令,并没有利用处理程序可以放置在FIQ向量入口位置的优势。
9.1.3 Exception Priorities
异常可以同时发生,因此处理器必须采用优先级机制。表9.3显示了在ARM处理器上发生的各种异常及其关联的优先级。例如,复位异常是最高优先级的异常,在处理器通电时发生。因此,当发生复位时,它优先于所有其他异常。同样,当发生数据中止异常时,它优先于除复位异常以外的所有其他异常。最低的优先级由两个异常共享,即软件中断和未定义指令异常。某些异常还通过在cpsr中设置I或F位来禁用中断,如表9.3所示。

每个异常的处理方式根据表9.3中列出的优先级来进行。以下是对异常及其处理方式的摘要,从最高优先级开始。
复位异常是最高优先级的异常,并且只要它被触发,就会始终被执行。复位处理程序初始化系统,包括设置内存和缓存。在启用IRQ或FIQ中断之前,应初始化外部中断源,以避免适当的处理程序设置之前出现虚假中断的可能性。复位处理程序还必须为所有处理器模式设置堆栈指针。在处理程序的前几条指令中,假定不会发生异常或中断。代码应设计成避免SWI、未定义指令和可能中止的内存访问,即要小心实现处理程序,以避免进一步触发异常。
当内存控制器或MMU指示已访问无效内存地址(例如,对于某个地址没有物理内存)或当前代码尝试读取或写入未具有正确访问权限的内存时,将发生数据中止异常。在数据中止处理程序内部可以引发FIQ异常,因为FIQ异常未被禁用。当完全服务于FIQ后,控制权将返回到数据中止处理程序。
当外部外设将FIQ引脚置为nFIQ时,将发生快速中断请求(FIQ)异常。FIQ异常是最高优先级的中断。核心在进入FIQ处理程序时禁用IRQ和FIQ异常。因此,除非软件重新启用IRQ和/或FIQ异常,否则没有外部源可以中断处理器。希望FIQ处理程序(以及中止、SWI和IRQ处理程序)经过精心设计以有效地处理异常。
当外部外设将IRQ引脚置为nIRQ时,将发生中断请求(IRQ)异常。IRQ异常是第二高优先级的中断。如果既没有FIQ异常也没有数据中止异常发生,则将进入IRQ处理程序。进入IRQ处理程序时,IRQ异常被禁用,并且应在当前中断源被清除之前保持禁用状态。
当尝试提取指令时发生预取中止异常,表示发生了内存错误。当指令在流水线的执行阶段且没有发生更高优先级的其他异常时,会引发此异常。进入处理程序时,IRQ异常将被禁用,但FIQ异常将保持不变。如果启用了FIQ并发生了FIQ异常,则在服务预取中止时可以采取该异常。
当执行SWI指令并且没有标记任何其他更高优先级的异常时,将发生软件中断(SWI)异常。进入处理程序时,cpsr将被设置为超级用户模式。
如果系统使用嵌套的SWI调用,则在跳转到嵌套SWI之前必须存储链接寄存器r14和spsr,以避免链接寄存器和spsr可能被破坏。
当ARM或Thumb指令集之外的指令达到流水线的执行阶段且没有标记任何其他异常时,将发生未定义指令异常。ARM处理器会向协处理器"询问"它们是否能够处理此作为协处理器指令的指令。由于协处理器遵循流水线,因此指令识别可以在核心的执行阶段进行。如果没有协处理器认领该指令,则会引发未定义指令异常。
由于SWI指令和未定义指令不能同时发生(换句话说,正在执行的指令不能同时是SWI指令和未定义指令),它们具有相同的优先级。
9.1.4 Link Register Offsets
当异常发生时,链接寄存器(LR)会根据当前PC设置为特定的地址。例如,当引发IRQ异常时,链接寄存器LR指向上一条已执行指令的地址加上8。必须小心确保异常处理程序不会破坏LR寄存器,因为LR用于从异常处理程序返回。IRQ异常只在当前指令执行后发生,因此返回地址必须指向下一条指令,即LR-4。表9.4提供了不同异常的一些有用地址。

接下来的三个示例展示了从IRQ或FIQ异常处理程序中返回的不同方法。
示例9.2
这个示例展示了从IRQ和FIQ处理程序中返回的典型方法是使用SUBS指令:
bash
handler
<handler code>
...
SUBS pc, r14, #4
; pc=r14-4由于SUB指令末尾有一个S,且PC是目标寄存器,所以CPSR将自动从SPSR寄存器中恢复。
示例9.3
这个示例展示了另一种方法,在处理程序开始时从链接寄存器R14中减去偏移量。
bash
handler
SUB r14, r14, #4
; r14-=4
...
<handler code>
...
MOVS pc, r14
; return服务完成后,通过将链接寄存器R14移动到PC并从SPSR中恢复CPSR来返回到正常执行。
示例9.4
最后一个示例使用中断栈来存储链接寄存器。这种方法首先从链接寄存器中减去一个偏移量,然后将其存储到中断栈中。
bash
handler
SUB r14, r14, #4
; r14-=4
STMFD r13!,{r0-r3, r14}
; store context
...
<handler code>
...
LDMFD r13!,{r0-r3, pc}ˆ
; return为了返回到正常执行,使用LDM指令来加载PC。指令中的^符号强制将CPSR从SPSR中恢复。
9.2 Interrupts
在ARM处理器上有两种类型的中断可用。第一种类型的中断是由外部外围设备引发的异常,即IRQ和FIQ。第二种类型是由特定指令引发的异常,即SWI指令。这两种类型都会暂停程序的正常流程。
在本节中,我们主要关注IRQ和FIQ中断。我们将涵盖以下内容:
■ 分配中断
■ 中断延迟
■ IRQ和FIQ异常
■ 基本中断栈设计和实现
9.2.1 Assigning Interrupts
系统设计人员可以决定哪个硬件外设可以产生哪个中断请求。这个决策可以在硬件或软件(或两者兼有)中实现,具体取决于使用的嵌入式系统。
中断控制器将多个外部中断连接到两个ARM中的一个中断请求。复杂的控制器可以编程,允许外部中断源引发IRQ或FIQ异常。
在分配中断方面,系统设计人员采用了标准的设计实践:
■ 软件中断通常保留用于调用特权操作系统例程。例如,可以使用SWI指令将正在用户模式下运行的程序切换到特权模式。关于SWI处理程序示例,请参阅第11章。
■ 中断请求通常分配给通用中断。例如,定期定时器中断用于强制进行上下文切换,往往是IRQ异常。IRQ异常的优先级较低,中断延迟较高(将在下一节中讨论),而FIQ异常则相反。
■ 快速中断请求通常保留给需要快速响应时间的单个中断源,例如专门用于移动内存块的直接内存访问。因此,在嵌入式操作系统设计中,FIQ异常用于特定应用,将IRQ异常用于更通用的操作系统活动。
9.2.2 Interrupt Latency
在基于中断驱动的嵌入式系统中,必须解决中断延迟的问题,即从外部中断请求信号被触发到特定中断服务例程(ISR)的第一条指令被获取的时间间隔。
中断延迟取决于硬件和软件的组合。系统架构师必须平衡系统设计,以处理多个同时发生的中断源,并尽量最小化中断延迟。如果中断没有及时处理,系统响应时间将变慢。

软件处理程序有两种主要方法来最小化中断延迟。第一种方法是使用嵌套中断处理程序,即使当前正在处理一个现有的中断,也允许进一步的中断发生(参见图9.3)。这通过在中断源得到服务后立即重新启用中断(以防止生成更多的中断),但在中断处理完成之前实现。一旦处理完嵌套中断,就会将控制权交还给原始的中断服务例程。
第二种方法涉及优先级设置。您可以编程中断控制器忽略与您正在处理的中断相同或较低优先级的中断,以便仅有优先级更高的任务才能中断您的处理程序。然后您可以重新启用中断。
处理器会在较低优先级的中断上花费时间,直到出现一个更高优先级的中断。因此,高优先级的中断比低优先级的中断具有更低的平均中断延迟,通过加速关键的时序敏感中断的完成时间来减少延迟。
9.2.3 IRQ and FIQ Exceptions
只有在cpsr中清除了特定中断屏蔽位时,IRQ和FIQ异常才会发生。ARM处理器在处理中断之前会继续执行当前流水线里的执行阶段的指令------这是设计确定性中断处理程序的一个重要因素,因为某些指令需要更多的周期来完成执行阶段。
当未屏蔽中断引起IRQ或FIQ异常时,处理器硬件会经过标准的过程:
-
处理器切换到特定的中断请求模式,这反映了所引发的中断。
-
上一个模式的cpsr保存到新的中断请求模式的spsr中。
-
pc保存在新的中断请求模式的lr中。
-
中断被禁用,即在cpsr中禁用IRQ或同时禁用IRQ和FIQ异常。 这立即停止引发相同类型的另一个中断请求。
-
处理器跳转到向量表中的特定入口。
该过程根据引发的中断类型略有不同。我们将以示例说明两种中断。第一个示例展示了当引发IRQ异常时会发生什么,而第二个示例展示了引发FIQ异常时会发生什么。
示例9.5
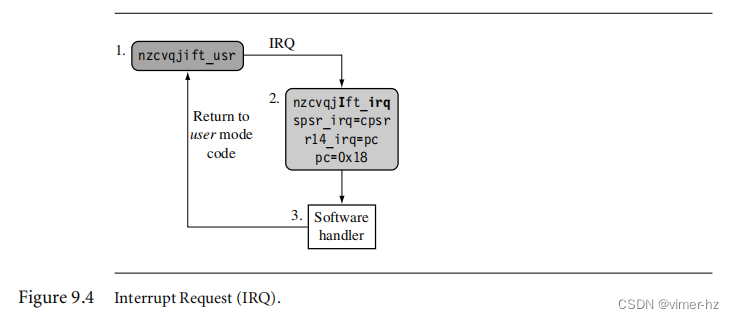
图9.4显示了当处理器处于用户模式时引发IRQ异常时会发生的情况。处理器从状态1开始。在这个示例中,cpsr中的IRQ和FIQ异常位都已启用。
当发生IRQ时,处理器进入状态2。这个转换会自动将IRQ位设置为1,禁止任何进一步的IRQ异常。然而,FIQ异常保持启用,因为FIQ具有更高的优先级,所以当引发低优先级的IRQ异常时,它不会被禁用。cpsr处理器模式切换到IRQ模式。用户模式cpsr会自动复制到spsr_irq中。
当中断发生时,寄存器r14_irq被赋予中断发生时的pc值。然后,pc被设置为向量表中的IRQ入口+0x18的地址。
在状态3中,软件处理程序接管并调用适当的中断服务例程来处理中断来源。完成后,处理器模式回退到状态1中的原始用户模式代码。
示例9.6

图9.5展示了一个FIQ异常的示例。处理器经历了与IRQ异常类似的过程,但是与只屏蔽进一步的IRQ异常不同,处理器还屏蔽了进一步的FIQ异常。这意味着在状态3中进入软件处理程序时,两个中断都被禁用了。
切换到FIQ模式意味着无需保存寄存器r8到r12,因为这些寄存器在FIQ模式下是分段的。这些寄存器可以用来保存临时数据,例如缓冲区指针或计数器。这使得FIQ非常适合处理单源、高优先级、低延迟的中断。
9.2.3.1 Enabling and Disabling FIQ and IRQ Exceptions
ARM处理器核心有一个简单的过程来手动启用和禁用中断,涉及到在处理器处于特权模式下修改cpsr。

表9.5展示了如何启用IRQ和FIQ中断。该过程使用了三条ARM指令。
第一条指令MRS将cpsr的内容复制到寄存器r1中。第二条指令清除IRQ或FIQ掩码位。第三条指令将更新后的内容从寄存器r1复制回cpsr,从而启用中断请求。后缀"_c"标识被更新的位域是cpsr的控制字段位7:0。(更多细节请参考第2章。)表9.6展示了禁用或屏蔽中断请求的类似过程。
重要的是要理解,在MSR指令完成流水线的执行阶段之后,中断请求才会被启用或禁用。在MSR完成这个阶段之前,中断仍然可以被触发或屏蔽。
要同时启用和禁用IRQ和FIQ异常,需要对第二条指令进行轻微修改。数据处理BIC或ORR指令上的立即数值必须更改为0xc0,以启用或禁用两个中断。
9.2.4 Basic Interrupt Stack Design and Implementation
异常处理程序广泛使用堆栈,每种模式都有一个专用的寄存器保存堆栈指针。异常堆栈的设计取决于以下因素:
-
操作系统要求:每个操作系统对堆栈设计都有自己的需求。
-
目标硬件:目标硬件为堆栈在内存中的大小和位置提供了物理限制。
对于堆栈,需要做两个设计决策:
-
位置决定了堆栈在内存映射中开始的位置。大多数基于ARM的系统设计中,堆栈向下扩展,堆栈的顶部位于较高的内存地址。
-
堆栈大小取决于处理程序的类型,是嵌套中断还是非嵌套中断。嵌套中断处理程序需要更多的内存空间,因为堆栈随着嵌套中断的数量而增长。
良好的堆栈设计试图避免堆栈溢出,即堆栈扩展到分配的内存之外,因为这会导致嵌入式系统不稳定。有软件技术可以识别溢出,并在不可修复的内存损坏发生之前采取纠正措施来修复堆栈。两种主要方法是:(1)使用内存保护和(2)在每个程序开始时调用堆栈检查函数。
在启用中断之前,必须设置IRQ模式堆栈,通常是在系统的初始化代码中完成。在简单的嵌入式系统中,了解堆栈的最大大小非常重要,因为在引导程序的初始阶段,固件会预留堆栈大小。

图9.6显示了线性地址空间中两种典型的内存布局。布局A显示了传统的堆栈布局,其中中断堆栈存储在代码段下方。布局B将中断堆栈放置在内存的顶部,用户堆栈上方。布局B相比于布局A的主要优点是,在发生堆栈溢出时不会破坏向量表,因此系统可以在识别到溢出后进行自我纠正。

每种处理器模式都需要设置一个堆栈。这是每次处理器重置时都要执行的操作。图9.7显示了使用布局A的实现方式。为了帮助设置内存布局,声明了一组定义,将内存区域名称映射到绝对地址。
例如,用户堆栈被赋予标签USR_Stack,并设置为地址0x20000。监管员堆栈设置在IRQ堆栈的下方128字节的地址处。
bash
USR_Stack EQU 0x20000
IRQ_Stack EQU 0x8000
SVC_Stack EQU IRQ_Stack-128为了帮助切换到不同的处理器模式,我们声明了一组定义,将每个处理器模式映射到特定的模式位模式。然后可以使用这些标签将cpsr设置为新的模式。
bash
Usr32md EQU 0x10
; User mode
FIQ32md EQU 0x11
; FIQ mode
IRQ32md EQU 0x12
; IRQ mode
SVC32md EQU 0x13
; Supervisor mode
Abt32md EQU 0x17
; Abort mode
Und32md EQU 0x1b
; Undefined instruction mode
Sys32md EQU 0x1f
; System mode为了安全起见,声明了一个定义来禁用cpsr中的IRQ和FIQ异常:
NoInt EQU 0xc0 ; 禁用中断
NoInt通过将屏蔽位设置为1来屏蔽两个中断。
初始化代码从为每个处理器模式设置堆栈寄存器开始。堆栈寄存器r13是在模式切换发生时始终会切换的寄存器之一。代码首先初始化IRQ堆栈。出于安全原因,最好使用NoInt和新模式之间的按位或运算来确保中断已禁用。
每种模式都必须设置堆栈。下面是在处理器内核从复位状态退出时如何设置三个不同堆栈的示例。请注意,由于这是一个基本示例,因此我们没有实现中止、FIQ和未定义指令模式的堆栈。如果需要这些堆栈,则使用非常相似的代码。
■ 监管者模式堆栈------处理器内核以监管者模式启动,因此SVC堆栈设置涉及将寄存器r13_svc加载到由SVC_NewStack指向的地址。对于此示例,该值为SVC_Stack。
bash
LDR r13, SVC_NewStack ; r13_svc
...
SVC_NewStack
DCD SVC_Stack■ IRQ模式堆栈------要设置IRQ堆栈,必须将处理器模式更改为IRQ模式。这是通过将cpsr位模式存储到寄存器r2中实现的。然后将寄存器r2复制到cpsr中,将处理器置于IRQ模式。此操作立即使寄存器r13_irq可见,并且可以将其分配给IRQ_Stack值。
bash
MOV r2, #NoInt|IRQ32md
MSR cpsr_c, r2
LDR r13, IRQ_NewStack ; r13_irq
...
IRQ_NewStack
DCD IRQ_Stack■ 用户模式堆栈------通常,用户模式堆栈是最后设置的,因为当处理器处于用户模式时,没有直接的方法来修改cpsr。另一种方法是强制处理器进入系统模式以设置用户模式堆栈,因为这两种模式共享相同的寄存器。
bash
MOV r2, #Sys32md
MSR cpsr_c, r2
LDR r13, USR_NewStack ; r13_usr
...
USR_NewStack
DCD USR_Stack对于每种模式使用单独的堆栈而不是使用单一堆栈进行处理有一个主要的优势:可以对错误的任务进行调试并与系统的其余部分隔离开来。这样可以更容易地定位和解决特定模式下的问题,同时保持其他模式的稳定性。
9.3 Interrupt Handling Schemes
在本节中,我们将介绍多种不同的中断处理方案,从简单的非嵌套中断处理程序到更复杂的分组优先级中断处理程序。每个方案都以一个通用描述和示例实现的形式呈现。
所涵盖的方案包括以下内容:
■ 非嵌套中断处理程序按顺序处理和服务各个中断。它是最简单的中断处理程序。
■ 嵌套中断处理程序处理多个中断,没有优先级分配。
■ 可重入中断处理程序处理可以优先级排序的多个中断。
■ 优先级简单中断处理程序处理优先级中断。
■ 优先级标准中断处理程序比低优先级中断更快地处理高优先级中断。
■ 优先级直接中断处理程序比低优先级中断更快地处理高优先级中断,并直接进入特定的服务例程。
■ 优先级分组中断处理程序是一种处理按不同优先级分组的中断的机制。
■ 基于VIC PL190的中断服务例程展示了向量中断控制器(VIC)如何改变中断服务例程的设计。
9.3.1 Nonnested Interrupt Handler
//非嵌套中断处理程序
最简单的中断处理程序是非嵌套方式,即在控制权返回到被中断的任务或进程之前,禁用中断。由于非嵌套中断处理程序一次只能处理一个中断,这种形式的处理程序不适用于需要处理多个具有不同优先级的中断的复杂嵌入式系统。

图9.8显示了在实现了简单非嵌套中断处理程序的系统中引发中断时发生的各个阶段:
-
禁用中断 - 当IRQ异常引发时,ARM处理器将禁止进一步发生IRQ异常。处理器模式设置为适当的中断请求模式,并将先前的cpsr复制到新可用的spsr_{interrupt request mode}中。然后,处理器将设置pc指向向量表中正确的条目,并执行指令。该指令将更改pc以指向特定的中断处理程序。
-
保存上下文 - 在进入处理程序代码时,它保存当前处理器模式的非银行寄存器的子集。
-
中断处理程序 - 处理程序然后识别外部中断源并执行适当的中断服务例程(ISR)。
-
中断服务例程 - ISR服务外部中断源并复位中断。
-
恢复上下文 - ISR返回到中断处理程序,中断处理程序恢复上下文。
-
启用中断 - 最后,为了从中断处理程序返回,将spsr_{interrupt request mode}恢复回cpsr。然后将pc设置为引发中断后的下一条指令。
在这个示例中,假设IRQ堆栈已经由初始化代码正确设置。
bash
interrupt_handler
SUB r14,r14,#4
; adjust lr
STMFD r13!,{r0-r3,r12,r14}
; save context
<interrupt service routine>
LDMFD r13!,{r0-r3,r12,pc}ˆ
; return第一条指令将链接寄存器r14_irq设置为返回到被中断的任务或进程的正确位置。根据第9.1.4节的描述,由于流水线的原因,在进入IRQ处理程序时,链接寄存器指向返回地址后四个字节,因此处理程序必须从链接寄存器减去四来补偿这个差异。链接寄存器存储在堆栈上。为了返回到被中断的任务,链接寄存器的内容从堆栈中恢复,并移动到pc寄存器。
注意,由于ATPCS(ARM Procedure Call Standard),也需要保留寄存器r0到r3和寄存器r12。这允许在处理程序内部调用符合ATPCS的子程序。
STMFD指令通过将一部分寄存器保存到堆栈上来保存上下文。为了减少中断延迟,我们只保存了最少数量的寄存器,因为执行STMFD或LDMFD指令的时间与传输的寄存器数量成比例。这些寄存器保存到由寄存器r13_{interrupt request mode}指向的堆栈中。
如果您在系统中使用高级语言,重要的是要了解编译器的过程调用约定,因为它会影响保存的寄存器及其保存顺序。例如,ARM编译器在子程序调用中保留了寄存器r4到r11,因此除非它们将被中断处理程序使用,否则没必要保留它们。如果没有调用C例程,则可能不需要保存所有寄存器。只有在寄存器已经保存到中断堆栈上时,才能安全地调用C函数。
在非嵌套中断处理程序中,不需要保存spsr,因为它不会被后续的中断破坏。
处理程序的最后,LDMFD指令将恢复上下文并从中断处理程序返回。LDMFD指令末尾的^表示cpsr将从spsr中恢复,这仅在同时加载了pc时有效。如果没有加载pc,则^将恢复用户银行寄存器。
在该处理程序中,所有处理都在中断处理程序内完成,并直接返回到应用程序。
一旦进入中断处理程序并保存了上下文,处理程序必须确定中断源。以下代码显示了如何简单确定中断源的示例。IRQStatus是中断状态寄存器的地址。如果无法确定中断源,则可以将控制权传递给另一个处理程序。在本示例中,我们将控制权传递给调试监视器。或者我们也可以忽略该中断。
bash
interrupt_handler
SUB r14,r14,#4
; r14-=4
STMFD sp!,{r0-r3,r12,r14} ; save context
LDR r0,=IRQStatus ; interrupt status addr
LDR r0,[r0]
; get interrupt status
TST r0,#0x0080
; if counter timer
BNE timer_isr
; then branch to ISR
TST r0,#0x0001
; else if button press
BNE button_isr
; then call button ISR
LDMFD sp!,{r0-r3,r12,r14} ; restore context
LDR pc,=debug_monitor ; else debug monitor在上述代码中,有两个中断服务程序(ISR):timer_isr和button_isr。它们分别映射到IRQStatus寄存器中的特定位,分别是0x0080和0x0001。
非嵌套中断处理程序的总结:
-
按顺序处理和服务各个中断。
-
中断延迟较高,在服务中断时无法处理其他发生的中断。
-
优点:相对容易实现和调试。
-
缺点:不能用于处理具有多个优先级中断的复杂嵌入式系统。
9.3.2 Nested Interrupt Handler
嵌套中断处理程序允许在当前调用的处理程序内发生另一个中断。这是通过在处理程序完全服务当前中断之前重新启用中断来实现的。
对于实时系统,这个特性增加了系统的复杂性,但也提高了性能。额外的复杂性引入了可能导致系统故障的微妙时间问题,而这些微妙问题可能极难解决。嵌套中断方法被精心设计,以避免这些类型的问题。这是通过保护上下文恢复不受中断干扰,以防止下一个中断填满堆栈(导致堆栈溢出)或破坏任何寄存器来实现的。
任何嵌套中断处理程序的首要目标是快速响应中断,使处理程序既不等待异步异常,也不强制它们等待处理程序。第二个目标是在处理各种中断的同时,不延迟常规同步代码的执行。
复杂性的增加意味着设计人员必须在效率和安全性之间取得平衡,采用一种防御性的编码风格,假设问题会发生。处理程序必须检查堆栈并在可能的情况下保护寄存器免受破坏。

图9.9展示了一个嵌套中断处理程序。从图中可以看出,与第9.3.1节中描述的简单非嵌套中断处理程序相比,处理程序要复杂得多。
嵌套中断处理程序的入口代码与简单非嵌套中断处理程序相同,只是在退出时,处理程序会测试一个由ISR更新的标志位。该标志位指示是否需要进一步处理。如果不需要进一步处理,则中断服务例程完成,处理程序可以退出。如果需要进一步处理,处理程序可能会执行以下几个操作:重新使能中断和/或进行上下文切换。
重新使能中断涉及从IRQ模式切换到SVC模式或系统模式。在IRQ模式下,不能简单地重新使能中断,因为这可能会导致链接寄存器r14_irq的破坏,特别是在执行BL指令后发生中断的情况下。这个问题将在第9.3.3节中更详细地讨论。
执行上下文切换意味着清空IRQ堆栈,因为只有当IRQ堆栈上有数据时,处理程序才不执行上下文切换。保存在IRQ堆栈上的所有寄存器必须转移到任务的堆栈上,通常是在SVC堆栈上。然后,剩余的寄存器必须保存在任务堆栈上。它们被转移到堆栈上的一个保留内存块,称为堆栈帧。
示例9.9
这个嵌套中断处理程序示例基于图9.9中的流程图。本节的其余部分将逐步介绍处理程序,并详细描述各个阶段。
bash
Maskmd
EQU 0x1f
; processor mode mask
SVC32md
EQU 0x13
; SVC mode
I_Bit
EQU 0x80
; IRQ bit
FRAME_R0
EQU 0x00
FRAME_R1
EQU FRAME_R0+4
FRAME_R2
EQU FRAME_R1+4
FRAME_R3
EQU FRAME_R2+4
FRAME_R4
EQU FRAME_R3+4
FRAME_R5
EQU FRAME_R4+4
FRAME_R6
EQU FRAME_R5+4
FRAME_R7
EQU FRAME_R6+4
FRAME_R8
EQU FRAME_R7+4
FRAME_R9
EQU FRAME_R8+4
FRAME_R10 EQU FRAME_R9+4
FRAME_R11 EQU FRAME_R10+4
FRAME_R12 EQU FRAME_R11+4
FRAME_PSR EQU FRAME_R12+4
FRAME_LR
EQU FRAME_PSR+4
FRAME_PC
EQU FRAME_LR+4
FRAME_SIZE EQU FRAME_PC+4
IRQ_Entry ; instruction
state : comment
SUB r14,r14,#4
; 2 :
STMDB r13!,{r0-r3,r12,r14} ; 2 : save context
<service interrupt>
BL read_RescheduleFlag ; 3 : more processing
CMP r0,#0
; 3 : if processing?
LDMNEIA r13!,{r0-r3,r12,pc}ˆ ; 4 : else return
MRS r2,spsr
; 5 : copy spsr_irq
MOV r0,r13
; 5 : copy r13_irq
ADD r13,r13,#6*4
; 5 : reset stack
MRS r1,cpsr
; 6 : copy cpsr
BIC r1,r1,#Maskmd
; 6 :
ORR r1,r1,#SVC32md
; 6 :
MSR cpsr_c,r1
; 6 : change to SVC
SUB r13,r13,#FRAME_SIZE-FRAME_R4;7: make space
STMIA r13,{r4-r11}
; 7 : save r4-r11
LDMIA r0,{r4-r9}
; 7 : restore r4-r9
BIC r1,r1,#I_Bit
; 8 :
MSR cpsr_c,r1
; 8 : enable IRA
STMDB r13!,{r4-r7}
; 9 : save r4-r7 SVC
STR r2,[r13,#FRAME_PSR] ; 9 : save PSR
STR r8,[r13,#FRAME_R12] ; 9 : save r12
STR r9,[r13,#FRAME_PC]
; 9 : save pc
STR r14,[r13,#FRAME_LR] ; 9 : save lr
<complete interrupt service routine>
LDMIA r13!,{r0-r12,r14}
; 11 : restore context
MSR spsr_cxsf,r14
; 11 : restore spsr
LDMIA r13!,{r14,pc}ˆ
; 11 : return这个示例使用了一个堆栈帧结构。除了堆栈寄存器r13之外,所有寄存器都保存在帧上。寄存器的顺序并不重要,只有FRAME_LR和FRAME_PC应该是帧中的最后两个寄存器,因为我们将使用一条指令返回:
LDMIA r13!, {r14, pc}
根据所使用的操作系统或应用程序的要求,可能还需要将其他寄存器保存到堆栈帧中。例如:
■ 当操作系统需要支持用户模式和SVC模式时,会保存寄存器r13_usr和r14_usr。
■ 当系统使用硬件浮点数时,会保存浮点寄存器。
这个示例中声明了一些预定义的宏。这些宏将cpsr/spsr的各种变化映射到特定的标签(例如I_Bit)。
还声明了一组预定义的宏,将各种帧寄存器引用映射到帧指针偏移量。当重新使能中断并且需要将寄存器存储到堆栈帧中时,这非常有用。在这个示例中,我们将堆栈帧存储在SVC堆栈上。
这个示例处理程序的入口点使用了与简单的非嵌套中断处理程序相同的代码。首先修改链接寄存器r14,使其指向正确的返回地址,然后将上下文和链接寄存器r14保存到IRQ堆栈上。
然后,中断服务例程对中断进行处理。当处理完成或部分完成时,控制权被传递回处理程序。处理程序然后调用一个名为read_RescheduleFlag的函数,该函数确定是否需要进一步处理。如果不需要进一步处理,它会在寄存器r0中返回一个非零值;否则返回零。请注意,我们没有包含read_RescheduleFlag的源代码,因为它是与实现相关的。
然后测试寄存器r0中的返回标志。如果寄存器不等于零,处理程序将恢复上下文并将控制权返回给挂起的任务。
将寄存器r0设置为零,表示需要进一步处理。首先保存spsr,将spsr_irq的副本移动到寄存器r2中。然后处理程序可以在后面的代码中将spsr存储在堆栈帧中。
将寄存器r13_irq指向的IRQ堆栈地址复制到寄存器r0中以备后用。下一步是将IRQ堆栈扁平化(清空)。这通过在栈顶添加6 * 4字节来实现,因为栈是向下增长的,可以使用ADD指令设置栈。
处理程序无需担心IRQ堆栈上的数据被另一个嵌套中断破坏,因为中断仍处于禁用状态,直到IRQ堆栈上的数据恢复完毕后,处理程序才会重新使能中断。
然后处理程序切换到SVC模式;中断仍处于禁用状态。将cpsr复制到寄存器r1并修改以将处理器模式设置为SVC。然后将寄存器r1写回cpsr,并将当前模式更改为SVC模式。新的cpsr的副本留在寄存器r1中供以后使用。
下一阶段是通过扩展栈来创建一个堆栈帧。寄存器r4到r11可以保存在堆栈帧中,这将释放足够的寄存器空间,以便从寄存器r0中还原IRQ堆栈中的其余寄存器。

此阶段,堆栈帧将包含表9.7中显示的信息。不在帧中的唯一寄存器是进入IRQ处理程序时存储的寄存器。
表9.8显示了与现有IRQ寄存器对应的SVC模式下的寄存器。现在处理程序可以从IRQ堆栈检索所有数据,并且可以安全地重新使能中断。

允许重新使能IRQ异常,处理程序已保存了所有重要的寄存器。现在可以完成堆栈帧。表9.9显示了一个完整的堆栈帧,可用于上下文切换或处理嵌套中断。
此阶段可以处理剩余的中断服务。通过将当前任务的控制块中的寄存器r13的当前值保存起来,并从新任务的控制块加载一个新值,可以执行上下文切换。
现在可以返回到被中断的任务/处理程序,或者如果发生了上下文切换,可以返回到另一个任务。
9.3.3 Reentrant Interrupt Handler
//可重入中断处理程序
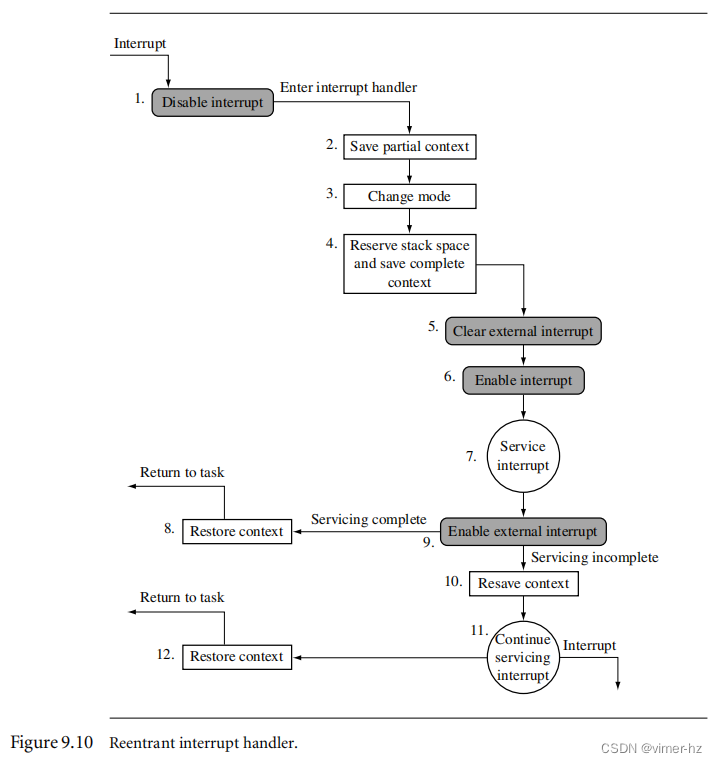
可重入中断处理程序是一种处理多个中断的方法,其中中断根据优先级进行过滤,这对于要求具有较低延迟的高优先级中断非常重要。传统的嵌套中断处理程序无法实现这种优先级过滤。
可重入中断处理程序与嵌套中断处理程序的基本区别在于,可重入中断处理程序在早期阶段重新使能中断,这可以减少中断延迟。在稍后的部分中,将详细描述关于早期重新使能中断的一些问题。
在ARM处理器上,所有中断都必须在SVC、系统、未定义指令或中止模式下进行服务。
如果在中断模式下重新使能中断,并且中断例程执行了BL子程序调用指令,那么子程序的返回地址将设置在寄存器r14_irq中。该地址将随后被中断破坏,中断会覆盖返回地址到r14_irq中。为了避免这种情况,中断例程应该切换到SVC或系统模式。然后,BL指令可以使用寄存器r14_svc来存储子程序的返回地址。在通过cpsr重新使能中断之前,必须通过在中断控制器中设置一个位来禁用中断的源。
这样,可重入中断处理程序可以实现中断的优先级过滤,并且能够减少中断的延迟。这对于要求高可靠性和响应性的系统来说非常重要,特别是在嵌入式系统和实时操作系统中。
如果在处理完成之前在cpsr中重新使能中断,并且未禁用中断源,则会立即重新生成中断,从而导致无限中断序列或竞态条件。大多数中断控制器都有一个中断屏蔽寄存器,允许屏蔽一个或多个中断,但是其余的中断仍然是使能的。
由于中断在SVC模式下服务(例如,在任务的堆栈上),因此中断堆栈未被使用。相反,IRQ堆栈寄存器r13被用来指向一个12字节的数据结构,该结构将用于在中断进入时临时存储一些寄存器。
示例9.10
假设已经设置寄存器r13_irq以指向一个12字节的数据结构,并且不指向标准的IRQ堆栈。诸如IRQ_SPSR之类的偏移量用于指向数据结构内的位置。与所有中断处理程序一样,需要一些标准的定义来修改cpsr和spsr寄存器。
bash
IRQ_R0 EQU 0
IRQ_spsr EQU 4
IRQ_R14 EQU 8
Maskmd EQU 0x1f
; mask mode
SVC32md EQU 0x13
; SVC mode
I_Bit
EQU 0x80
; IRQ bit
ic_Base EQU 0x80000000
IRQStatus EQU 0x0
IRQRawStatus EQU 0x4
IRQEnable EQU 0x8
IRQEnableSet EQU 0x8
IRQEnableClear EQU 0xc
IRQ_Entry ; instruction
state : comment
SUB r14, r14, #4
; 2 : r14_irq-=4
STR r14, [r13, #IRQ_R14] ; 2 : save r14_irq
MRS r14, spsr
; 2 : copy spsr
STR r14, [r13, #IRQ_spsr] ; 2 : save spsr
STR r0, [r13, #IRQ_R0] ; 2 : save r0
MOV r0, r13
; 2 : copy r13_irq
MRS r14, cpsr
; 3 : copy cpsr
BIC r14, r14, #Maskmd ; 3 :
ORR r14, r14, #SVC32md ; 3 :
MSR cpsr_c, r14
; 3 : enter SVC mode
STR r14, [r13, #-8]!
; 4 : save r14
LDR r14, [r0, #IRQ_R14] ; 4 : r14_svc=r14_irq
STR r14, [r13, #4]
; 4 : save r14_irq
LDR r14, [r0, #IRQ_spsr] ; 4 : r14_svc=spsr_irq
LDR r0, [r0, #IRQ_R0] ; 4 : restore r0
STMDB r13!, {r0-r3,r8,r12,r14} ; 4 : save context
LDR r14, =ic_Base
; 5 : int crtl address
LDR r8, [r14, #IRQStatus] ; 5 : get int status
STR r8, [r14, #IRQEnableClear];5: clear interrupts
MRS r14, cpsr
; 6 : r14_svc=cpsr
BIC r14, r14, #I_Bit
; 6 : clear I-Bit
MSR cpsr_c, r14
; 6 : enable IRQ int
BL process_interrupt ; 7 : call ISR
LDR r14, =ic_Base
; 9 : int ctrl address
STR r8, [r14, #IRQEableSet] ; 9 : enable ints
BL read_RescheduleFlag ; 9 : more processing
CMP r0, #0
; 8 : if processing
LDMNEIA r13!, {r0-r3,r8,r12,r14} ; 8 : then load context
MSRNE spsr_cxsf, r14
; 8 : update spsr
LDMNEIA r13!, {r14, pc}ˆ
; 8 : return
LDMIA r13!, {r0-r3, r8} ; 10 : else load reg
STMDB r13!, {r0-r11}
; 10 : save context
BL continue_servicing ; 11 : continue service
LDMIA r13!, {r0-r12, r14} ; 12 : restore context
MSR spsr_cxsf, r14
; 12 : update spsr
LDMIA r13!, {r14, pc}ˆ
; 12 : return处理的开始包括一个普通的中断入口,其中从寄存器r14_irq中减去了4。
现在重要的是为由寄存器r13_irq指向的数据结构中的各个字段分配值。记录的寄存器包括r14_irq、spsr_irq和r0。寄存器r0用于在切换到SVC模式时传递指向数据结构的指针,因为寄存器r0不会被分组保存。这就是为什么不能使用寄存器r13_irq来进行此操作:它在SVC模式下不可见。
将指向数据结构的指针通过将寄存器r13_irq复制到r0中来保存。

处理程序将使用操作cpsr的标准过程将处理器设置为SVC模式。SVC模式下的链接寄存器r14被保存在SVC堆栈上。减去8为堆栈提供了两个32位字的空间。
然后,恢复并将寄存器r14_irq存储在SVC堆栈上。现在,IRQ和SVC的链接寄存器r14都存储在SVC堆栈上。
从传递到SVC模式的数据结构中恢复剩下的IRQ上下文。现在,寄存器r14_svc将包含IRQ模式的spsr。
然后,寄存器被保存到SVC堆栈上。寄存器r8用于保存在中断处理程序中被禁用的中断的中断屏蔽位。它们将在稍后重新启用。
然后禁用中断源。嵌入式系统此时会对中断进行优先级排序,并禁用低于当前优先级的所有中断,以防止低优先级中断锁定高优先级中断。中断优先级排序将在本章后面讨论。
由于中断源已经清除,现在可以安全地重新启用IRQ异常。通过清除cpsr中的i位来实现。请注意,中断控制器仍然禁用外部中断。
现在可以处理中断了。中断处理不应尝试进行上下文切换,因为外部源中断已被禁用。如果在中断处理过程中需要进行上下文切换,则应设置一个标志,稍后由中断处理程序接收。现在可以安全地重新启用外部中断。
处理程序需要检查是否需要进一步处理。如果寄存器r0中的返回值非零,则不需要进一步处理。如果为零,则处理程序恢复上下文,然后将控制权返回到挂起的任务。
现在必须创建一个堆栈帧,以便服务例程可以完成。这是通过恢复一部分上下文,然后将完整的上下文保存回SVC堆栈来实现的。
调用完成中断服务的子例程continue_servicing。此例程未提供,因为它与具体实现有关。
中断例程完成服务后,可以将控制权交还给挂起的任务。
总结: 可重入中断处理程序
■ 处理多个可以优先级排序的中断。
■ 中断延迟低。
■ 优点:处理具有不同优先级的中断。
■ 缺点:趋向于更复杂。
9.3.4 Prioritized Simple Interrupt Handler
非嵌套中断处理程序和嵌套中断处理程序都按先到先服务的顺序处理中断。相比之下,优先级中断处理程序将特定的中断源与优先级级别相关联。优先级级别用于确定中断的处理顺序。因此,较高优先级的中断将优先于较低优先级的中断,这在许多嵌入式系统中是一种特别理想的特性。
处理优先级的方法可以在硬件或软件中实现。对于硬件优先级,处理程序设计更简单,因为中断控制器将提供需要服务的当前最高优先级中断。这些系统在启动时需要更多的初始化代码,因为必须在系统启动之前构建中断和相关优先级级别表;另一方面,软件优先级需要额外的外部中断控制器的帮助。这个中断控制器必须提供一组最小功能,包括能够设置和取消屏蔽、读取中断状态和源。
本节的其余部分将介绍一个软件优先级技术,因为它是一种通用方法,并不依赖于专门的中断控制器。为了描述优先级中断处理程序,我们将介绍一个基于ARM标准中断控制器的虚构中断控制器。该控制器接收多个中断源,并根据特定中断源的使能状态生成IRQ和/或FIQ信号。

图9.11显示了基于可重入中断处理程序的简单优先级中断处理程序的流程图。
示例 9.11
中断控制器有一个寄存器(IRQRawStatus),用于保存原始中断状态-在被控制器屏蔽之前的中断信号状态。IRQEnable寄存器确定了哪些中断被从处理器屏蔽。只能使用IRQEnableSet和IRQEnableClear来设置或清除该寄存器。表9.10显示了中断控制器寄存器名称、与控制器基地址的偏移量、读/写操作以及寄存器的描述。

bash
I_Bit
EQU 0x80
PRIORITY_0 EQU 2
; Comms Rx
PRIORITY_1 EQU 1
; Comms Tx
PRIORITY_2 EQU 0
; Timer 1
PRIORITY_3 EQU 3
; Timer 2
BINARY_0 EQU 1 << PRIORITY_0 ; 1 << 2 0x00000004
BINARY_1 EQU 1 << PRIORITY_1 ; 1 << 1 0x00000002
BINARY_2 EQU 1 << PRIORITY_2 ; 1 << 0 0x00000001
BINARY_3 EQU 1 << PRIORITY_3 ; 1 << 3 0x00000008
MASK_3 EQU BINARY_3
MASK_2 EQU MASK_3+BINARY_2
MASK_1 EQU MASK_2+BINARY_1
MASK_0 EQU MASK_1+BINARY_0
ic_Base EQU 0x80000000
IRQStatus EQU 0x0
IRQRawStatus EQU 0x4
IRQEnable EQU 0x8
IRQEnableSet EQU 0x8
IRQEnableClear EQU 0xc
IRQ_Handler ; instruction
state : comment
SUB r14, r14, #4
; 2 : r14_irq -= 4
STMFD r13!, {r14}
; 2 : save r14_irq
MRS r14, spsr
; 2 : copy spsr_irq
STMFD r13!, {r10,r11,r12,r14} ; 2 : save context
LDR r14, =ic_Base
; 3 : int crtl addr
MOV r11, #PRIORITY_3
; 3 : default priority
LDR r10, [r14, #IRQStatus] ; 3 : load IRQ status
TST r10, #BINARY_3
; 4 : if Timer 2
MOVNE r11, #PRIORITY_3
; 4 : then P3(lo)
TST r10, #BINARY_2
; 4 : if Timer 1
MOVNE r11, #PRIORITY_2
; 4 : then P2
TST r10, #BINARY_1
; 4 : if Comm Tx
MOVNE r11, #PRIORITY_1
; 4 : then P1
TST r10, #BINARY_0
; 4 : if Comm Rx
MOVNE r11, #PRIORITY_0
; 4 : then P0(hi)
LDR r12, [r14,#IRQEnable] ; 4 : IRQEnable reg
ADR r10, priority_masks ; 4 : mask address
LDR r10, [r10,r11,LSL #2] ; 4 : priority value
AND r12, r12,r10
; 4 : AND enable reg
STR r12, [r14,#IRQEnableClear];4: disable ints
MRS r14, cpsr
; 4 : copy cpsr
BIC r14, r14, #I_Bit
; 4 : clear I-bit
MSR cpsr_c, r14
; 4 : enable IRQ ints
LDR pc, [pc, r11, LSL#2] ; 5 : jump to an ISR
NOP
;
DCD service_timer1
; timer1 ISR
DCD service_commtx
; commtx ISR
DCD service_commrx
; commrx ISR
DCD service_timer2
; timer2 ISR
priority_masks
DCD MASK_2
; priority mask 2
DCD MASK_1
; priority mask 1
DCD MASK_0
; priority mask 0
DCD MASK_3
; priority mask 3
...
service_timer1
STMFD r13!, {r0-r9}
; 6 : save context
<service routine>
LDMFD r13!, {r0-r10}
; 7 : restore context
MRS r11, cpsr
; 8 : copy cpsr
ORR r11, r11, #I_Bit
; 8 : set I-bit
MSR cpsr_c, r11
; 8 : disable IRQ
LDR r11, =ic_Base
; 8 : int ctrl addr
STR r12, [r11, #IRQEnableSet] ; 8 : enable ints
LDMFD r13!, {r11, r12, r14} ; 9 : restore context
MSR spsr_cxsf, r14
; 9 : set spsr
LDMFD r13!, {pc}ˆ
; 9 : return大多数中断控制器还具有相应的寄存器用于 FIQ 异常,并且甚至允许将个别中断源连接到发送到核心的特定中断信号上。因此,通过对控制器进行编程,可以使特定的中断源引发 IRQ 或 FIQ 异常。
这些寄存器相对于内存中的基地址进行偏移。表 9.10 显示了从中断控制器基地址 `ic_Base` 开始的各个寄存器的所有偏移量。请注意,偏移量 `0x08` 同时用于 `IRQEnable` 和 `IRQEnableSet`。
在中断控制器中,每个位与特定的中断源相关联(参见图 9.12)。例如,位 2 与串行通信的接收中断源相关联。

PRIORITY_x 定义了四个中断源的优先级,用于示例中,其中 PRIORITY_0 是最高优先级中断,PRIORITY_3 是最低优先级中断。
BINARY_x 定义了每个优先级级别的位模式。例如,对于 PRIORITY_0 中断,二进制模式将是 0x00000004(或 1 乘以 2)。对于每个优先级级别,都有一个相应的掩码,用于屏蔽与或低于该优先级的所有中断。例如,MASK_2 将屏蔽来自 Timer2(优先级为 3)和 CommRx(优先级为 2)的中断。
中断控制器寄存器的定义也已列出。ic_Base 是基地址,其余的定义(例如,IRQStatus)都是相对于该基地址的偏移量。
优先级中断处理程序从标准进入开始,但首先只存储 IRQ 链接寄存器到 IRQ 栈上。
接下来,处理程序获取 spsr 并将内容放入寄存器 r14_irq,并释放一组寄存器以用于处理优先级。
处理程序需要获取中断控制器的状态。这可以通过将中断控制器的基地址加载到寄存器 r14,并将寄存器 r10 加载为 ic_Base(寄存器 r14)偏移 IRQStatus(0x00)来实现。
然后,处理程序需要通过测试状态信息来确定最高优先级中断。如果特定的中断源与优先级级别匹配,则将优先级级别设置在寄存器 r11 中。该方法从最低优先级开始,依次比较中断源与所有设置的优先级级别,直到最高优先级。
在此代码片段之后,寄存器 r14_irq 将包含中断控制器的基地址,寄存器 r11 将包含最高优先级中断的位号。现在重要的是禁用低优先级和相等优先级中断,以便高优先级中断仍然可以中断处理程序。
请注意,这种方法更具确定性,因为发现优先级所需的时间始终相同。
要设置控制器中的中断屏蔽位,处理程序必须确定当前的 IRQ enable 寄存器,并获取优先级屏蔽表的起始地址。priority_masks 在处理程序末尾定义。
寄存器 r12 现在将包含当前的 IRQ enable 寄存器,寄存器 r10 将包含优先级表的起始地址。为了获取正确的掩码,将寄存器 r11 左移两位(使用移位器左移 #2)。这将使地址乘以四,并加上优先级表的起始地址。
寄存器 r10 包含新的掩码。下一步是使用掩码清除低优先级中断,通过将掩码与寄存器 r12(IRQEnable 寄存器)进行二进制 AND 运算,然后通过将新的掩码存储到 IRQEnableClear 寄存器中来清除位。
现在可以通过清除 cpsr 中的 i 位来启用 IRQ 异常。
最后,处理程序需要通过修改寄存器 r11(其中仍包含最高优先级中断)和 pc 来跳转到正确的服务例程。将寄存器 r11 左移两位(乘以四),并将其加到 pc 上,使处理程序可以通过直接加载服务例程的地址到 pc 中来跳转到正确的例程。
跳转表必须跟随加载PC指令。在跳转表和操作PC指令之间有一个NOP指令,因为PC将指向两条指令之后(或八个字节)。优先级屏蔽表按照中断源位的顺序排列。每个中断服务例程(ISR)都遵循相同的入口风格。下面是针对timer1中断服务例程的示例。
在上面的头部之后插入ISR。完成ISR后,必须重置中断源并将控制传递回被中断的任务。
处理程序在重新打开中断之前必须禁用IRQs。现在可以将外部中断恢复到其原始值,这是可能的,因为服务例程没有修改寄存器r12,所以它仍然包含原始值。
为了返回到被中断的任务,恢复上下文,并将原始SPSR复制回SPSR_IRQ。
优先级简单中断处理程序总结:
-
处理具有优先级的中断。
-
低中断延迟。
-
优点:确定性的中断延迟,因为首先确定优先级级别,然后在屏蔽较低优先级中断后调用服务例程。
-
缺点:处理低优先级服务例程的时间与处理高优先级服务例程的时间相同。
9.3.5 Prioritized Standard Interrupt Handler
延续优先级简单中断处理程序,下一个处理程序增加了一层复杂性。优先级简单中断处理程序通过测试所有中断来确定最高优先级,这是一种效率低下的确定优先级的方法,但它具有确定性,因为每个中断优先级确定所需的时间相同。

另一种方法是在确定最高优先级中断时尽早跳转(见图9.13),即在确定优先级后立即设置PC并进行跳转。这意味着针对优先级标准中断处理程序的代码中的识别部分比优先级简单中断处理程序更复杂。该识别部分将确定优先级,并立即跳转到一个处理低优先级中断屏蔽的例程,然后通过跳转表再次跳转到适当的ISR。
示例9.12:
优先级标准中断处理程序的起始部分与优先级简单中断处理程序相同,但是会更早地拦截具有更高优先级的中断。寄存器r14被赋予指向中断控制器基地址,并将中断控制器状态寄存器的值加载到寄存器r10中。为了使处理程序可以重定位,将PC指向的当前地址记录到寄存器r11中。
bash
I_Bit
EQU 0x80
PRIORITY_0 EQU 2
; Comms Rx
PRIORITY_1 EQU 1
; Comms Tx
PRIORITY_2 EQU 0
; Timer 1
PRIORITY_3 EQU 3
; Timer 2
BINARY_0
EQU 1 << PRIORITY_0 ; 1 << 2 0x00000004
BINARY_1
EQU 1 << PRIORITY_1 ; 1 << 1 0x00000002
BINARY_2
EQU 1 << PRIORITY_2 ; 1 << 0 0x00000001
BINARY_3
EQU 1 << PRIORITY_3 ; 1 << 3 0x00000008
MASK_3
EQU BINARY_3
MASK_2
EQU MASK_3+BINARY_2
MASK_1
EQU MASK_2+BINARY_1
MASK_0
EQU MASK_1+BINARY_0
ic_Base
EQU 0x80000000
IRQStatus EQU 0x0
IRQRawStatus EQU 0x4
IRQEnable EQU 0x8
IRQEnableSet EQU 0x8
IRQEnableClear EQU 0xc
IRQ_Handler ; instruction
state : comment
SUB r14, r14, #4
; 2 : r14_irq -= 4
STMFD r13!, {r14}
; 2 : save r14_irq
MRS r14, spsr
; 2 : copy spsr_irq
STMFD r13!,{r10,r11,r12,r14} ; 2 : save context
LDR r14, =ic_Base
; 3 : int crtl addr
LDR r10, [r14, #IRQStatus] ; 3 : load IRQ status
MOV r11, pc
; 4 : copy pc
TST r10, #BINARY_0
; 5 : if CommRx
BLNE disable_lower
; 5 : then branch
TST r10, #BINARY_1
; 5 : if CommTx
BLNE disable_lower
; 5 : then branch
TST r10, #BINARY_2
; 5 : if Timer1
BLNE disable_lower
; 5 : then branch
TST r10, #BINARY_3
; 5 : if Timer2
BLNE disable_lower
; 5 : then branch
disable_lower
SUB r11, r14, r11
; 5 : r11=r14-copy of pc
LDR r12,=priority_table ; 5 : priority table
LDRB r11,[r12,r11,LSR #3] ; 5 : mem8[tbl+(r11 >> 3)]
ADR r10, priority_masks ; 5 : priority mask
LDR r10, [r10,r11,LSL #2] ; 5 : load mask
LDR r14, =ic_Base
; 6 : int crtl addr
LDR r12, [r14,#IRQEnable] ; 6 : IRQ enable reg
AND r12, r12, r10
; 6 : AND enable reg
STR r12, [r14,#IRQEnableClear] ; 6 : disable ints
MRS r14, cpsr
; 7 : copy cpsr
BIC r14, r14, #I_Bit
; 7 : clear I-bit
MSR cpsr_c, r14
; 7 : enable IRQ
LDR pc, [pc, r11, LSL#2] ; 8 : jump to an ISR
NOP
;
DCD service_timer1
; timer1 ISR
DCD service_commtx
; commtx ISR
DCD service_commrx
; commrx ISR
DCD service_timer2
; timer2 ISR
priority_masks
DCD MASK_2
; priority mask 2
DCD MASK_1
; priority mask 1
DCD MASK_0
; priority mask 0
DCD MASK_3
; priority mask 3
priority_table
DCB PRIORITY_0
; priority 0
DCB PRIORITY_1
; priority 1
DCB PRIORITY_2
; priority 2
DCB PRIORITY_3
; priority 3
ALIGN现在可以通过比较最高优先级和最低优先级来测试中断源。第一个与中断源匹配的优先级确定传入中断的优先级,因为每个中断都有预设的优先级。一旦匹配成功,处理程序就可以跳转到屏蔽低优先级中断的例程。
为了禁用相同或更低优先级的中断,处理程序进入一个例程,首先使用寄存器r11和链接寄存器r14中的基地址计算优先级级别。在SUB指令之后,寄存器r11将包含值4、12、20或28。这些值对应于中断的优先级乘以8再加上4。然后将寄存器r11除以8并加上优先级表的地址。LDRB指令执行后,寄存器r11将等于其中一个优先级中断号(0、1、2或3)。
可以使用左移两位的技术将优先级掩码确定为寄存器r10加上的值,该值包含优先级掩码的地址。中断控制器的基地址被复制到寄存器r14_irq中,并用于获取控制器中的IRQEnable寄存器并将其放入寄存器r12中。寄存器r10包含新的掩码。下一步是使用此掩码清除低优先级中断,方法是对掩码和r12(IRQEnable寄存器)执行二进制AND并将结果存储到IRQEnableClear寄存器中。现在可以通过清除cpsr中的i位来启用IRQ异常。
最后,处理程序需要通过修改r11(仍包含最高优先级中断)和pc来跳转到正确的服务例程。将寄存器r11左移两位(将r11乘以4)并将其添加到pc中,使处理程序能够通过直接将服务例程的地址加载到pc中跳转到正确的例程。跳转表必须跟随加载pc的指令。跳转表和修改pc的LDR指令之间有一个NOP,因为pc指向前两个指令(或八个字节)。
请注意,优先级掩码表按照中断位顺序排列,优先级表按照优先级顺序排列。
总结:优先级标准中断处理程序
-
相对于低优先级中断,处理高优先级中断的时间更短。
-
中断延迟较低。
-
优点:对待高优先级中断更加紧急,无需重复设置外部中断掩码的代码。
-
缺点:由于该处理程序需要进行两次跳转,因此会有一定的时间损耗,每次跳转时都会清空流水线。
9.3.6 Prioritized Direct Interrupt Handler
优先级直接中断处理程序和优先级标准中断处理程序之间的一个区别是,一些处理过程被移到了各个中断服务例程(ISR)中。这些移动的代码用于屏蔽低优先级中断。每个ISR都必须根据特定优先级屏蔽低优先级中断,该优先级可以是一个固定的数字,因为优先级已经在之前确定过了。
第二个区别是,优先级直接中断处理程序直接跳转到相应的ISR。每个ISR在修改cpsr重新启用中断之前负责禁用低优先级中断。这种类型的处理程序相对简单,因为屏蔽是由各个ISR完成的,但是由于每个中断服务例程实际上执行相同的任务,会有一小部分代码重复。
例如,bit_x定义将中断源与中断控制器中的位位置相关联,在ISR内部帮助屏蔽低优先级中断。保存上下文后,需要将ISR表的基地址加载到寄存器r12中。一旦为中断源确定了优先级,该寄存器将用于跳转到正确的ISR。
bash
I_Bit
EQU 0x80
PRIORITY_0 EQU 2
; Comms Rx
PRIORITY_1 EQU 1
; Comms Tx
PRIORITY_2 EQU 0
; Timer 1
PRIORITY_3 EQU 3
; Timer 2
BINARY_0 EQU 1 << PRIORITY_0
; 1 << 2 0x00000004
BINARY_1 EQU 1 << PRIORITY_1
; 1 << 1 0x00000002
BINARY_2 EQU 1 << PRIORITY_2
; 1 << 0 0x00000001
BINARY_3 EQU 1 << PRIORITY_3
; 1 << 3 0x00000008
MASK_3 EQU BINARY_3
MASK_2 EQU MASK_3+BINARY_2
MASK_1 EQU MASK_2+BINARY_1
MASK_0 EQU MASK_1+BINARY_0
ic_Base EQU 0x80000000
IRQStatus EQU 0x0
IRQRawStatus EQU 0x4
IRQEnable EQU 0x8
IRQEnableSet EQU 0x8
IRQEnableClear EQU 0xc
bit_timer1 EQU 0
bit_commtx EQU 1
bit_commrx EQU 2
bit_timer2 EQU 3
IRQ_Handler ; instruction
comment
SUB r14, r14, #4
; r14_irq-=4
STMFD r13!, {r14}
; save r14_irq
MRS r14, spsr
; copy spsr_irq
STMFD r13!,{r10,r11,r12,r14} ; save context
LDR r14, =ic_Base
; int crtl addr
LDR r10, [r14, #IRQStatus] ; load IRQ status
ADR r12, isr_table
; obtain ISR table
TST r10, #BINARY_0
; if CommRx
LDRNE pc, [r12, #PRIORITY_0 << 2] ; then CommRx ISR
TST r10, #BINARY_1
; if CommTx
LDRNE pc, [r12, #PRIORITY_1 << 2] ; then CommTx ISR
TST r10, #BINARY_2
; if Timer1
LDRNE pc, [r12, #PRIORITY_2 << 2] ; then Timer1 ISR
TST r10, #BINARY_3
; if Timer2
LDRNE pc, [r12, #PRIORITY_3 << 2] ; then Timer2 ISR
B service_none
isr_table
DCD service_timer1
; timer1 ISR
DCD service_commtx
; commtx ISR
DCD service_commrx
; commrx ISR
DCD service_timer2
; timer2 ISR
priority_masks
DCD MASK_2
; priority mask 2
DCD MASK_1
; priority mask 1
DCD MASK_0
; priority mask 0
DCD MASK_3
; priority mask 3
...
service_timer1
MOV r11, #bit_timer1
; copy bit_timer1
LDR r14, =ic_Base
; int ctrl addr
LDR r12, [r14,#IRQEnable] ; IRQ enable register
ADR r10, priority_masks ; obtain priority addr
LDR r10, [r10,r11,LSL#2] ; load priority mask
AND r12, r12, r10
; AND enable reg
STR r12, [r14, #IRQEnableClear] ; disable ints
MRS r14, cpsr
; copy cpsr
BIC r14, r14, #I_Bit
; clear I-bit
MSR cpsr_c, r14
; enable IRQ
<rest of the ISR>优先级中断是通过首先检查最高优先级中断,然后逐级向下检查来确定的。一旦确定了优先级中断,pcis将被加载为相应ISR的地址。间接地址存储在isr_table的地址加上优先级级别向左移动两位(乘以四)的位置。或者您可以使用条件分支指令BNE。
ISR跳转表isr_table按照最高优先级中断在表的开头排序。
service_timer1条目展示了优先级直接中断处理程序中使用的ISR的示例。每个ISR都是独特的,取决于特定的中断源。
中断控制器的基地址的副本被放入寄存器r14_irq中。这个地址加上一个偏移量用于将IRQEnable寄存器复制到寄存器r12中。
优先级屏蔽表的地址需要被复制到寄存器r10中,以便用于计算实际屏蔽的地址。寄存器r11向左移动两个位置,得到一个偏移量为0、4、8或12。偏移量加上优先级屏蔽表的地址用于将屏蔽加载到寄存器r10中。优先级屏蔽表与前一节中的优先级中断处理程序相同。
寄存器r10将包含ISR屏蔽,寄存器r12将包含当前屏蔽。使用二进制AND操作将两个屏蔽合并。然后使用新的屏蔽配置中断控制器,使用IRQEnableClear寄存器。现在可以通过清除cpsr中的i位来安全地启用IRQ异常。
处理程序可以继续服务当前的中断,除非发生了一个优先级更高的中断,这种情况下该中断将优先于当前的中断。■
总结:优先级直接中断处理程序
■ 在较短时间内处理高优先级中断。直接跳转到特定的ISR。
■ 中断延迟低。
■ 优点:使用单个跳转,节省宝贵的周期进入ISR。
■ 缺点:每个ISR都需要设置外部中断屏蔽机制,以防止低优先级中断中断当前ISR,这会为每个ISR增加额外的代码。
9.3.7 Prioritized Grouped Interrupt Handler
最后,优先级分组中断处理程序与其他优先级中断处理程序不同,因为它设计用于处理大量的中断。这是通过将中断分组并形成一个子集来实现的,然后可以为该子集分配一个优先级级别。
嵌入式系统的设计者必须识别出每个中断源的子集,并为该子集分配一个群组优先级级别。在选择中断源的子集时要小心,因为群组可以决定系统的特性。将中断源进行分组可以降低处理程序的复杂性,因为不需要扫描每个中断来确定优先级级别。如果优先级分组中断处理程序设计良好,它将显著提高整个系统的响应时间。
示例 9.14
此处理程序被设计为具有两个优先级分组。计时器源被分组到群组0中,通信源被分组到群组1中(见表9.11)。群组0中断的优先级高于群组1中断。

bash
I_Bit
EQU 0x80
PRIORITY_0 EQU 2
; Comms Rx
PRIORITY_1 EQU 1
; Comms Tx
PRIORITY_2 EQU 0
; Timer 1
PRIORITY_3 EQU 3
; Timer 2
BINARY_0 EQU 1 << PRIORITY_0 ; 1 << 2 0x00000004
BINARY_1 EQU 1 << PRIORITY_1 ; 1 << 1 0x00000002
BINARY_2 EQU 1 << PRIORITY_2 ; 1 << 0 0x00000001
BINARY_3 EQU 1 << PRIORITY_3 ; 1 << 3 0x00000008
GROUP_0 EQU BINARY_2|BINARY_3
GROUP_1 EQU BINARY_0|BINARY_1
GMASK_1 EQU GROUP_1
GMASK_0 EQU GMASK_1+GROUP_0
MASK_TIMER1 EQU GMASK_0
MASK_COMMTX EQU GMASK_1
MASK_COMMRX EQU GMASK_1
MASK_TIMER2 EQU GMASK_0
ic_Base EQU 0x80000000
IRQStatus EQU 0x0
IRQRawStatus EQU 0x4
IRQEnable EQU 0x8
IRQEnableSet EQU 0x8
IRQEnableClear EQU 0xc
interrupt_handler
SUB r14, r14,#4
; r14_irq-=4
STMFD r13!, {r14}
; save r14_irq
MRS r14, spsr
; copy spsr_irq
STMFD r13!, {r10,r11,r12,r14} ; save context
LDR r14, =ic_Base
; int ctrl addr
LDR r10, [r14, #IRQStatus] ; load IRQ status
ANDS r11, r10, #GROUP_0 ; belong to GROUP_0
ANDEQS r11, r10, #GROUP_1 ; belong to GROUP_1
AND r10, r11, #0xf
; mask off top 24-bit
ADR r11, lowest_significant_bit ; load LSB addr
LDRB r11, [r11, r10]
; load byte
B disable_lower_priority ; jump to routine
lowest_significant_bit
; 0 123456789abcdef
DCB 0xff,0,1,0,2,0,1,0,3,0,1,0,2,0,1,0
disable_lower_priority
CMP r11, #0xff
; if unknown
BEQ unknown_condition
; then jump
LDR r12, [r14, #IRQEnable] ; load IRQ enable reg
ADR r10, priority_mask ; load priority addr
LDR r10, [r10, r11, LSL #2] ; mem32[r10+r11 << 2]
AND r12, r12, r10
; AND enable reg
STR r12, [r14, #IRQEnableClear] ; disable ints
MRS r14, cpsr
; copy cpsr
BIC r14, r14, #I_Bit
; clear I-bit
MSR cpsr_c, r14
; enable IRQ ints
LDR pc, [pc, r11, LSL #2] ; jump to an ISR
NOP
DCD service_timer1
; timer1 ISR
DCD service_commtx
; commtx ISR
DCD service_commrx
; commrx ISR
DCD service_timer2
; timer2 ISR
priority_mask
DCD MASK_TIMER1
; mask GROUP 0
DCD MASK_COMMTX
; mask GROUP 1
DCD MASK_COMMRX
; mask GROUP 1
DCD MASK_TIMER2
; mask GROUP 0GROUP_x定义通过对二进制模式进行二进制OR操作将各种中断源分配到它们的特定优先级级别。GMASK_x定义为分组中断分配掩码。MASK_x定义将每个GMASK_x连接到特定的中断源,然后可以在优先级掩码表中使用。
在保存上下文后,中断处理程序使用中断控制器基地址的偏移量加载IRQ状态寄存器。
然后,处理程序通过对源进行二进制AND操作来确定中断源所属的组别。指令后缀字母S表示更新cpsr中的条件标志。
现在,寄存器r11将包含最高优先级的组别0或1。处理程序现在通过与0xf进行二进制AND操作来屏蔽其他中断源。
最低有效位表的地址随后加载到寄存器r11中。使用寄存器r10中的值(0、1、2或3,参见表9.12)从表的起始位置加载一个字节。

一旦最低有效位位置加载到寄存器r11中,处理程序将跳转到一个例程。
disable_lower_priority中断例程首先检查是否存在虚拟中断(不再存在)。如果中断是虚拟的,则调用unknown_condition例程。然后,处理程序加载IRQEnable寄存器,并将结果放入寄存器r12中。
通过加载优先级掩码表的地址,可以找到优先级掩码,然后将寄存器r11中的数据左移两位。将结果(0、4、8或12)加到优先级掩码地址上。寄存器r10然后包含一个屏蔽,用于禁止提升较低优先级组中断。
下一步是使用屏蔽来清除较低优先级中断,通过在寄存器r10和r12(IRQEnable寄存器)中进行二进制AND操作,然后将结果保存到IRQEnableClear寄存器中以清除位。此时,通过在cpsr中清除i位,现在可以安全地启用IRQ异常。
最后,处理程序通过修改寄存器r11(仍包含最高优先级中断)和pc来跳转到正确的中断服务例程。通过将寄存器r11左移两位并将结果加到pc上,确定ISR的地址。然后将此地址直接加载到pc中。请注意,跳转表必须在LDR指令之后。
由于ARM流水线的存在,NOP指令是必要的。
总结:优先分组中断处理程序
-
机制:处理按不同优先级分组的中断。
-
低中断延迟。
-
优点:在嵌入式系统需要处理大量中断时非常有用,同时减少了响应时间,因为确定优先级级别的过程较短。
-
缺点:确定如何将中断分组在一起。
9.3.8 VIC PL190 Based Interrupt Service Routine
为了充分利用向量中断控制器,必须修改IRQ向量入口。
0x00000018 LDR pc,pc,#-0xff0 ; IRQ pc=mem320xfffff030
这条指令从内存映射位置0xffffff030加载一个ISR地址到pc寄存器中,绕过任何软件中断处理程序,因为可以直接从硬件中获取中断源。它还减少了中断延迟,因为只有一个跳转到特定的ISR。
这里是VIC服务例程的一个示例:
bash
INTON
EQU 0x0000
; enable interrupts
SYS32md EQU 0x1f
; system mode
IRQ32md EQU 0x12
; IRQ mode
I_Bit
EQU 0x80
VICBaseAddr EQU 0xfffff000 ; addr of VIC ctrl
VICVectorAddr EQU VICBaseAddr+0x30 ; isr address of int
vector_service_routine
SUB r14,r14,#4
; r14-=4
STMFD r13!, {r0-r3,r12,r14} ; save context
MRS r12, spsr
; copy spsr
STMFD r13!,{r12}
; save spsr
<clear the interrupt source>
MSR cpsr_c, #INTON|SYS32md ; cpsr_c=ift_sys
<interrupt service code>
MSR cpsr_c, #I_Bit|IRQ32md ; cpsr_c=Ift_irq
LDMFD r13!, {r12}
; restore (spsr_irq)
MSR spsr_cxsf, r12 ; restore spsr
LDR r1,=VICVectorAddr ; load VectorAddress
STR r0, [r1]
; servicing complete
LDMFD r13!, {r0-r3,r12,pc}ˆ ; return该例程在清除中断源之前保存了上下文和spsr_irq。完成后,可以通过清除i位重新启用IRQ异常,并将处理器模式设置为系统模式。然后,服务例程可以在系统模式下处理中断。
完成后,通过设置i位禁用IRQ异常,并将处理器模式切换回IRQ模式。
spsr_irq从IRQ堆栈中恢复,准备好返回到被中断的任务。
然后,服务例程将写入控制器中的VICVectorAddr寄存器。向该地址写入表示优先级硬件已处理完中断。
请注意,由于VIC基本上是一个硬件中断处理程序,在激活之前必须预先将ISR地址数组编程到VIC中。
9.4 Summary
异常改变了指令的正常顺序执行。ARM处理器有七种异常:数据终止异常、快速中断请求异常、中断请求异常、预取终止异常、软件中断异常、复位异常和未定义指令异常。每个异常都有一个关联的处理器模式。当引发异常时,处理器进入特定模式并跳转到向量表中的一个条目。每个异常也有一个优先级级别。
中断是一种特殊类型的异常,由外部设备引起。IRQ异常用于一般操作系统活动。FIQ异常通常保留给单个中断源。中断延迟是从外部中断请求信号引发到特定中断服务例程(ISR)的第一条指令被提取之间的时间间隔。
我们介绍了八种中断处理方案,从非嵌套的简单中断处理程序,用于处理和服务单个中断,到高级的优先级分组中断处理程序,用于处理分组成不同优先级级别的中断。
Chapter10 Firmware
本章讨论基于ARM的嵌入式系统的固件。 因为它通常是在新平台上移植和执行的第一个代码,所以固件是任何嵌入式系统的重要组成部分。 固件可以从完整的软件嵌入式系统到简单的初始化和引导加载程序例程不等。 我们将本章分为两个部分。
第一部分介绍固件。 在本节中,我们定义固件术语并描述了可用于ARM处理器的两种流行行业标准固件包:ARM固件套件和Red Hat的RedBoot。 这些固件包是通用的,可以相对容易和快速地移植到不同的ARM平台上。
第二部分仅关注初始化和引导加载程序过程。 为了帮助处理这个问题,我们开发了一个名为Sandstone的简单示例。 Sandstone旨在初始化硬件、将映像加载到存储器中并将pc的控制权移交给该映像。
我们首先讨论固件,介绍两种常见的ARM固件软件包。
10.1 Firmware and Bootloader
我们意识到工程师之间对术语的使用可能会有所不同,但我们将使用以下定义:
-
固件(firmware)是一种深度嵌入、低级软件,提供硬件和应用程序/操作系统级软件之间的接口。它驻留在只读存储器中,在嵌入式硬件系统通电时执行。固件可以在系统初始化后保持活动状态,并支持基本的系统操作。选择用于特定ARM-based系统的固件取决于具体的应用程序,可能涉及从加载和执行复杂操作系统到简单地将控制权移交给小型微内核。因此,从一个固件实现到另一个固件实现,要求可能差异很大。例如,一个小型系统可能仅需要最少的固件支持来引导一个小型操作系统。固件的主要目的之一是提供一个稳定的机制来加载和引导操作系统。
-
引导加载程序(bootloader)是一个小型应用程序,用于将操作系统或应用程序安装到硬件目标上。引导加载程序仅存在于操作系统或应用程序执行的时候,并且通常包含在固件中。
为了帮助理解不同固件实现的特点,我们有一个常见的执行流程(见表10.1)。现在对每个阶段进行更详细的讨论。

第一阶段是设置目标平台,也就是为引导操作系统准备环境,因为操作系统在操作之前需要特定类型的环境。这个步骤涉及确保平台被正确初始化(例如,确保特定微控制器的控制寄存器位于已知地址或将内存映射更改为预期的布局)。
在同一个可执行文件上运行不同的核心和平台是常见的情况。在这种情况下,固件必须识别和发现它正在运行的确切核心和平台。通常通过读取协处理器15中的寄存器0来识别核心,该寄存器保存处理器类型和制造商名称。有多种方法可以识别平台,从检查一组特定外设的存在到简单地读取预编程芯片。
诊断软件提供了一种快速识别基本硬件故障的实用方法。由于这种软件的特性,它往往针对特定的硬件设备进行优化。
调试能力以模块或监视器的形式提供,为在硬件目标上运行的代码提供软件调试支持。该支持包括以下内容:
-
在RAM中设置断点。断点允许程序中断并检查处理器核心的状态。
-
列出和修改内存(使用peek和poke操作)。
-
显示当前处理器寄存器的内容。
-
将内存反汇编为ARM和Thumb指令助记符。
这些都是交互式功能:可以通过命令行解释器(CLI)或连接到目标平台的专用主机调试器发送命令。
除非固件可以访问内部的硬件调试电路,否则只能通过软件调试机制对RAM映像进行调试。
CLI通常在高级固件实现中可用。它允许您通过在命令提示符处键入命令来更改要引导的操作系统的默认配置。对于嵌入式系统,CLI通常通过主机终端应用程序进行控制。主机和目标之间的通信通常通过串口或网络连接进行。
第二阶段是对硬件进行抽象化。硬件抽象层(HAL)是一个软件层,通过提供一组定义的编程接口来隐藏底层硬件。当切换到新的目标平台时,这些编程接口保持不变,但底层实现会发生变化。例如,两个目标平台可能使用不同的计时器外设。每个外设都需要新的代码来初始化和配置设备。尽管硬件和软件在实现之间可能有很大差异,但HAL编程接口保持不变。
与特定硬件外设通信的HAL软件称为设备驱动程序。设备驱动程序提供一个标准的应用程序编程接口(API),用于读取和写入特定外设。
第三阶段是加载可引导映像。固件执行此操作的能力取决于用于存储映像的介质类型。请注意,并非所有操作系统映像或应用程序映像都需要复制到RAM中。操作系统映像或应用程序映像可以直接从ROM中执行。
ARM处理器通常用于包含闪存ROM的小型设备。常见的功能是简单的闪存ROM文件系统(FFS),允许存储多个可执行映像。
其他媒体设备,如硬盘,则需要固件具有适用于访问硬件的设备驱动程序。访问硬件需要固件了解底层文件系统格式,这使得固件能够读取文件系统,找到包含映像的文件,并将映像复制到内存中。同样,如果映像在网络上,则固件还必须了解网络协议以及以太网硬件。
加载过程必须考虑映像格式。最基本的映像格式是纯二进制格式。纯二进制映像不包含任何标头或调试信息。 ARM系统常用的映像格式是可执行和链接格式(ELF)。该格式最初是为UNIX系统开发的,取代了旧格式称为通用对象文件格式(COFF)。 ELF文件有三种形式:可重定位文件、可执行文件和共享对象。
大多数固件系统必须处理可执行格式。加载ELF映像涉及解密标准ELF标头信息(即执行地址、类型、大小等)。映像也可能被加密或压缩,在这种情况下,加载过程将涉及对映像执行解密或解压缩。
第四个阶段是放弃控制权。这是固件将平台控制权交给操作系统或应用程序的地方。请注意,并非所有固件都放弃控制权;相反,固件可以继续成为平台上的控制软件。设计用于将控制权传递给操作系统的固件,在操作系统获得控制权后可能变得不活动。或者,固件的机器无关层(MIL)或硬件抽象层(HAL)部分可以保持活动状态。该层通过SWI机制公开特定硬件设备的标准应用程序接口。
在ARM系统上放弃控制意味着更新向量表并修改pc。更新向量表涉及修改特定异常和中断向量,以便它们指向专门的操作系统处理程序。必须修改pc,以便它指向操作系统入口点地址。
对于更复杂的操作系统,例如Linux,放弃控制需要向内核传递一个标准数据结构。此数据结构解释内核将运行的环境。例如,一个字段可能包括平台上可用的RAM量,而另一个字段包括正在使用的MMU类型。
我们使用这些定义来描述两个常见的固件套件。
10.1.1 ARM Firmware Suite
ARM开发了一个名为ARM固件套件(AFS)的固件包。AFS专门为基于ARM的嵌入式系统设计。它支持多种板卡和处理器,包括英特尔XScale和StrongARM处理器。这个套件包括两个主要技术:一个名为μHAL(读作"micro-HAL")的硬件抽象层和一个名为Angel的调试监视器。
μHAL提供了一个低级设备驱动框架,可以通过不同的通信设备(例如USB、以太网或串口)进行操作。它还提供了一个标准API。因此,在进行移植时,各种硬件特定部分必须根据μHAL API函数来实现。
这样做的好处是移植过程相对简单,因为你有一个标准的函数框架可以使用。一旦固件移植完成,就可以开始将操作系统移植到新的目标平台上。这个过程的速度取决于操作系统是否利用了移植的μHAL API调用来访问硬件。
μHAL支持以下主要功能:
-
系统初始化:设置目标平台和处理器核心。根据目标平台的复杂性,这可能是一个简单或复杂的任务。
-
轮询串行驱动程序:用于与主机进行基本通信的方法。
-
LED支持:允许控制LED以提供简单的用户反馈。这使得应用程序能够显示操作状态。
-
定时器支持:允许设置周期性中断。对于需要这种机制的抢占式上下文切换操作系统来说,这是必需的。
-
中断控制器:支持不同的中断控制器。
μHAL中的引导监视器包含一个CLI。
第二项技术是Angel,它允许主机调试器与目标平台之间进行通信。它允许您检查和修改内存、下载和执行映像、设置断点,并显示处理器寄存器内容。所有这些控制都通过主机调试器进行。Angel调试监视器必须可以访问SWI和IRQ或FIQ向量。
Angel使用SWI指令提供一组API,允许程序打开、读取和写入主机文件系统。IRQ/FIQ中断用于与主机调试器进行通信。
10.1.2 Red Hat RedBoot
RedBoot是由Red Hat开发的固件工具。它在开放源代码许可下提供,没有版税或预付费用。RedBoot旨在在不同的CPU上执行(例如ARM、MIPS、SH等)。它提供了通过GNU调试器(GDB)进行调试的功能,同时还具备引导加载程序的功能。RedBoot软件核心基于一个HAL。
RedBoot支持以下主要功能:
-
通信:配置可以通过串口或以太网进行。对于串口,使用X-Modem协议与GNU调试器(GDB)进行通信。对于以太网,使用TCP与GDB进行通信。RedBoot支持一系列网络标准,如bootp、telnet和tftp。
-
Flash ROM存储器管理:提供了一组文件系统例程,可以下载、更新和擦除Flash ROM中的映像。此外,这些映像可以是压缩或非压缩的。
-
完整的操作系统支持:支持加载和引导嵌入式Linux、Red Hat eCos和许多其他流行的操作系统。对于嵌入式Linux,RedBoot支持定义在引导时直接传递给内核的参数的能力。
10.2 Example: Sandstone
我们设计Sandstone成为一个最小系统。它只执行以下任务:设置目标平台环境、将可引导映像加载到内存中并将控制权交给操作系统。然而,它仍然是一个真正的工作示例。
实现是针对ARM Evaluator-7T平台的,其中包括一个ARM7TDMI处理器。这个示例向你展示了如何设置一个简单的平台,并将软件负载加载到内存中进行引导。这个负载可以是应用程序或操作系统映像。Sandstone是一个静态设计,在构建过程完成后无法配置。表10.2列出了Sandstone的基本特性。

我们将为你介绍目录布局和代码结构。目录布局展示了源代码的位置以及不同的构建文件所放置的位置。代码结构更注重实际的初始化和引导过程。
请注意,Sandstone完全使用ARM汇编语言编写,是一个可用于初始化目标硬件并在ARM Evaluator-7T上合理范围内引导任何软件的工作代码。
10.2.1 Sandstone Directory Layout
你可以在我们的网站上找到Sandstone。如果你查看Sandstone,你会发现目录结构如图10.1所示。这个结构遵循一个标准的风格,在后续的章节中我们会继续使用。
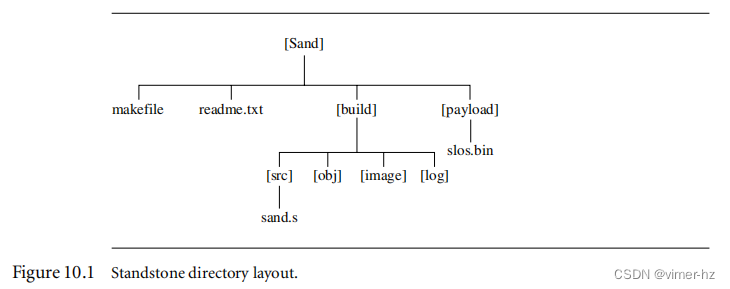
Sandstone的源文件sand.s位于sand/build/src目录下。
汇编器生成的目标文件放置在build/obj目录下。然后将目标文件链接起来,最终的Sandstone映像放置在sand/build/image目录下。这个映像包括了Sandstone代码和负载。负载映像,也就是由Sandstone加载和引导的映像,位于sand/payload目录下。
关于Sandstone构建过程的信息,请查看sand目录下的readme.txt文件。该文件描述了如何为ARM Evaluator-7T构建示例二进制映像。
10.2.2 Sandstone Code Structure
Sandstone由一个单独的汇编文件组成。文件结构被分解为多个步骤,每个步骤对应Sandstone执行流程中的一个阶段(参见表10.3)。

我们将带你逐步了解这些步骤,尽量避免平台特定的部分。但你应该注意到,有些特定部分是不可避免的(例如,配置系统寄存器和内存重映射)。
Sandstone的初始目标是设置目标平台环境,以便能够提供某种形式的反馈,表明固件正在运行并控制平台。
10.2.2.1 Step 1: Take the Reset Exception
执行从复位异常开始。在默认的向量表中,只需要复位向量入口。这是被执行的第一条指令。从这里的代码可以看出,除了复位向量外,所有的向量都会跳转到一个唯一的虚拟处理程序------一个导致无限循环的跳转指令。假设在Sandstone运行过程中不会发生任何异常或中断。复位向量用于将执行流程转移到第二阶段。
bash
AREA start,CODE,READONLY
ENTRY
sandstone_start
B sandstone_init1 ; reset vector
B ex_und ; undefined vector
B ex_swi ; swi vector
B ex_pabt ; prefetch abort vector
B ex_dabt ; data abort vector
NOP ; not used...
B int_irq ; irq vector
B int_fiq ; fiq vector
ex_und B ex_und ; loop forever
ex_swi B ex_swi ; loop forever
ex_dabt B ex_dabt ; loop forever
ex_pabt B ex_pabt ; loop forever
int_irq B int_irq ; loop forever
int_fiq B int_fiq ; loop foreversandstone_start位于地址0x00000000。
执行步骤1的结果如下:
-
虚拟处理程序已设置完成。
-
控制权被传递给初始化硬件的代码。
10.2.2.2 Step 2: Start Initializing the Hardware
初始化硬件的主要阶段是设置系统寄存器。在访问硬件之前,必须设置这些寄存器。例如,ARM Evaluator-7T拥有一个七段显示器,我们选择将其用作反馈工具,以指示固件处于活动状态。在设置段显示器之前,我们必须将系统寄存器的基地址定位到已知位置。在这种情况下,我们选择了默认地址0x03ff0000,因为这样可以将所有硬件系统寄存器与ROM和RAM分离开来,区分外设和存储器。
因此,所有微控制器内存映射寄存器都位于0x03ff0000的偏移量处。这通过以下代码实现:
bash
sandstone_init1
LDR r3, =SYSCFG ; where SYSCFG=0x03ff0000
LDR r4, =0x03ffffa0
STR r4, [r3]寄存器r3包含默认的系统寄存器基地址,并用于设置新的默认地址,以及其他特定属性,如缓存。寄存器r4包含新的配置。其中,高16位包含新系统寄存器基地址0x03ff的高位地址,低16位包含新的属性设置0xffa0。
设置完系统寄存器基地址后,可以配置段显示器。段显示器硬件用于显示Sandstone的进展。请注意,由于它是硬件特定的,因此不会显示段显示器。
执行步骤2的结果如下:
-
系统寄存器从已知的基地址0x03ff0000被设置。
-
配置了段显示器,以便用于显示进度。
10.2.2.3 Step 3: Remap Memory
硬件初始化的主要活动之一是设置内存环境。Sandstone旨在初始化SRAM并重新映射内存。该过程在系统初始化的早期进行。平台在已知的内存状态下启动,如表10.4所示。

正如您所看到的,当平台上电时,只有闪存ROM被分配了内存映射中的位置。两个SRAM bank(0和1)尚未初始化,因此无法使用。接下来的步骤是引入这两个SRAM bank,并将闪存ROM重新映射到新位置。
//内存包含闪存ROM和SRAM么?
/*内存(Memory)是计算机中用于存储数据和指令的设备。它可以被分为多种类型,包括闪存ROM(Read-Only Memory)和SRAM(Static Random-Access Memory),但内存并不仅限于这两种形式。
闪存ROM是一种非易失性存储器,它用于存储固定的数据和指令,如启动程序、固件和操作系统等。它的内容在断电后仍然能够保持,因此被称为只读存储器。在计算机系统中,闪存ROM通常用于存储固定信息,如引导程序和BIOS(Basic Input/Output System)。
SRAM是一种易失性存储器,它用于临时存储正在被处理的数据和指令。与闪存ROM不同,SRAM的内容在断电后会丢失。SRAM以其高速读写访问和较低的功耗而著称,因此广泛应用于高性能计算机中的高速缓存、寄存器和其他需要快速访问的存储器单元。
除了闪存ROM和SRAM,计算机系统中还存在其他类型的内存,如动态随机访问存储器(DRAM)、扩展内存(Extended Memory)和虚拟内存(Virtual Memory)等。每种类型的内存都具有特定的特点和用途,用于满足不同的存储需求。
总之,内存包含多种类型的存储器,其中闪存ROM用于存储固定信息,而SRAM用于临时存储正在处理的数据和指令。
*/
可以使用以下代码实现:
bash
LDR r14, =sandstone_init2
LDR r4, =0x01800000 ; new flash ROM location
ADD r14, r14, r4
ADRL r0, memorymaptable_str
LDMIA r0, {r1-r12}
LDR r0, =EXTDBWTH
; =(SYSCFG + 0x3010)
STMIA r0, {r1-r12}
MOV pc, r14
; jump to remapped memory
sandstone_init2
; Code after sandstone_init2 executes @ +0x1800000代码的第一部分计算了 sandstone_init2 过程的绝对地址,该地址在重新映射之前由 Sandstone 用于跳转到新的重新映射环境中的下一个过程。第二部分执行内存重新映射操作。新的内存映射数据从 memorymaptable_str 指向的结构中加载到寄存器 R1-R12 中。然后,使用这些寄存器将该结构写入系统配置寄存器偏移量为 0x3010 的内存控制器中。完成后,新的内存映射如表10.5所示生效。您可以看到,SRAM bank 现在可用,并且闪存ROM设置为较高的地址。最后一部分是跳转到固件的下一个过程或阶段。通过利用 ARM 流水线,实现了这个跳转。即使新的内存环境已经生效,下一条指令已经加载到流水线中。可以通过将寄存器 R14(即 sandstone_init2 的地址)的内容移动到 PC 寄存器来调用下一个过程。我们可以在重新映射代码之后立即用一条 MOV 指令实现这个目的。执行第3步骤的结果如下:
-
内存已按照表10.5所示进行了重新映射。
-
PC 现在指向下一步。该地址位于新的重新映射闪存ROM中。

10.2.2.4 Step 4: Initialize Communication Hardware
通信初始化包括配置串口并输出标准的横幅信息。该横幅用于显示固件已经完全功能并且内存已经成功重新映射。由于在 ARM Evaluator-7T 上初始化串口的代码是与硬件相关的,因此在这里没有展示。
串口被设置为9600波特率、无奇偶校验、一位停止位和无流控。如果串口电缆连接到板子上,则主机终端必须使用这些设置进行配置。
执行第4步骤的结果如下:
-
串口已初始化:9600波特率、无奇偶校验、一位停止位和无流控。
-
Sandstone横幅通过串口发送出去:
bash
Sandstone Firmware (0.01)
- platform ......... e7t
- status ........... alive
- memory ........... remapped
+ booting payload ...10.2.2.5 Step 5: Bootloader---Copy Payload and Relinquish Control
最后一个阶段涉及将有效负载复制并放弃对 PC(程序计数器)的控制权,让其控制所复制的负载。这是通过这里展示的代码实现的。代码的第一部分设置了在块复制中使用的寄存器 R12、R13 和 R14。引导加载程序的代码假定有效负载是一个纯二进制图像,不需要进行解密或解压缩。
bash
sandstone_load_and_boot
MOV r13,#0
; destination addr
LDR r12,payload_start_address ; start addr
LDR r14,payload_end_address ; end addr
_copy
LDMIA r12!,{r0-r11}
STMIA r13!,{r0-r11}
CMP r12,r14
BLT _copy
MOV pc,#0
payload_start_address
DCD startAddress
payload_end_address
DCD endAddress目标寄存器 R13 指向 SRAM 开始处,这里是 0x00000000。源寄存器 R12 指向有效负载的起始位置,源结束寄存器 R14 指向有效负载的末尾。使用这些寄存器将有效负载复制到 SRAM 中。
然后,通过将 PC 强制设置为所复制有效负载的入口地址,让控制权转交给有效负载。对于这个特定的有效负载,入口点是地址 0x00000000。现在,有效负载已经控制了系统。
执行第5步骤的结果如下:
-
有效负载已复制到 SRAM,地址为 0x00000000。
-
控制权已经转交 PC = 0x00000000。
-
系统已经完全启动。
串口输出以下内容:
bash
Sandstone Firmware (0.01)
- platform ......... e7t
- status ........... alive
- memory ........... remapped
+ booting payload ...
Simple Little OS (0.09)
- initialized ...... ok
- running on ....... e7t
e7t:10.3 Summary
本章介绍了固件。我们将固件定义为连接硬件与应用程序或操作系统的低级代码。我们还将引导加载程序定义为将操作系统或应用程序加载到内存中并放弃对 PC 的控制的软件。
我们介绍了 ARM 固件套件和 RedBoot。ARM 固件套件仅适用于基于 ARM 的系统。而 RedBoot 则更通用,可以用于其他非 ARM 处理器。
接下来,我们看了一个名为 Sandstone 的固件示例。Sandstone 初始化硬件,然后按照以下步骤加载和启动图像:
-
处理复位异常。
-
开始初始化硬件;设置系统寄存器的基地址,并初始化段显示硬件。
-
重新映射内存;ROM 地址 = 高地址,SRAM 地址 = 0x00000000。
-
初始化串口上的通信硬件输出。
-
引导加载程序将图像加载到 SRAM,并将控制权转交(PC = 0x00000000)。
现在,我们拥有一个完全初始化的 ARM7TDMI 嵌入式系统。
Chapter11 Embedded Operating Systems
本章讨论了嵌入式操作系统(OS)的实现。由于嵌入式操作系统是为特定目的而设计的,所以在历史上,嵌入式操作系统通常简单、时间受限,并且在有限的内存中运行。随着嵌入式硬件的复杂性增加,这种区别随着时间的推移发生了变化。传统上只存在于台式计算机上的功能,例如虚拟内存,已经迁移到了嵌入式系统领域。
由于这是一个庞大的主题,我们将范围限制在构成嵌入式操作系统的基本组件上。我们还在第10章显示的固件示例基础上进行扩展。
本章分为两部分:第一部分介绍构成嵌入式操作系统的基本组件,并注意与 ARM 处理器相关的问题。第二部分介绍了一个名为 Simple Little Operating System (SLOS) 的示例操作系统。SLOS旨在展示基本组件的实现方式。
11.1 Fundamental Components
一个操作系统由一组常见的低级组件组成,每个组件执行指定的动作。这些组件之间的相互作用和功能确定了特定操作系统的特征。
初始化是操作系统中第一个执行的代码,涉及设置内部数据结构、全局变量和硬件。初始化在固件交出控制权后开始。对于硬件初始化,操作系统设置各种控制寄存器,初始化设备驱动程序,并且如果操作系统支持抢占式,则设置一个周期性的中断。
内存处理涉及设置系统和任务堆栈。堆栈的位置决定了可供任务或系统使用的内存量。通常在操作系统初始化期间确定系统堆栈的位置。设置任务堆栈取决于任务是静态还是动态。
静态任务在构建时定义,并包含在操作系统映像中。对于这些任务,堆栈可以在操作系统初始化期间设置。例如,SLOS 是一个基于静态任务的操作系统。
动态任务在操作系统安装和执行后加载和执行,并不属于操作系统映像的一部分。任务创建时设置堆栈(例如,Linux 中的情况)。内存处理的复杂性因操作系统而异。它取决于多个因素,如所选的 ARM 处理器核心、微控制器的功能以及最终目标硬件的物理内存布局。
例子操作系统 SLOS 在第11.2节中使用了静态内存设计。它只是在微控制器内部配置一组寄存器,并设置堆栈的位置。由于没有动态内存管理的形式,你在其中不会找到 malloc() 和 free() 的实现。这些函数通常在标准的 C 库中找到。
处理中断和异常的方法是操作系统架构设计的一部分。你需要决定如何处理各种异常:数据中止、快速中断请求、中断请求、预取中止、复位和软件中断(SWI)。
并非所有的异常都需要处理程序。例如,如果你有一个不使用 FIQ 中断的目标板,那么就不需要特定的 FIQ 处理程序。为未使用的异常提供一个无限循环作为默认处理程序总是更安全的做法。这种方法使得调试变得容易:当程序中断时,很清楚是被陷入到了特定的处理程序中。它也能保护系统免受意外的异常干扰。
像 SLOS 这样的抢占式操作系统需要一个周期性中断,通常由目标硬件上的计数/定时器设备产生。在初始化阶段,操作系统设置周期性中断的频率。通常是通过将指定的值设置到计数/定时器的内存映射寄存器中来实现。
当计数/定时器启动后,它会开始递减这个值。一旦值达到零,就会触发一个中断。该中断然后由周期性中断的适当中断服务例程(ISR)处理。ISR 首先使用新的起始值重新初始化计数/定时器,然后调用调度程序或其他专门的例程。
相比之下,非抢占式操作系统不需要周期性中断,它将使用不同的技术,例如轮询------对设备状态进行持续检查。如果设备状态发生变化,那么特定的操作可以与特定的状态变化相连接。
调度程序是一个确定下一个要执行的任务的算法。有许多可用的调度算法。其中一个最简单的是循环调度算法------按照固定的循环顺序激活任务。调度算法必须在效率、大小和复杂性之间寻找平衡。
一旦调度程序完成,新旧任务必须通过上下文切换进行交换。上下文切换将处理器中所有旧任务的寄存器保存到一个数据结构中。然后将新任务的数据加载到处理器的寄存器中。(有关此过程的更多详细信息,请参阅第11.2.6节。)
最后一个组件是设备驱动程序框架------操作系统用于在不同硬件外设之间提供一致接口的机制。该框架允许将对特定外设的新支持以标准和简单的方式整合到操作系统中。对于应用程序要访问的特定外设,必须有一个特定的设备驱动程序可用。该框架必须提供一种安全的方法来访问外设(例如,不允许多个应用程序同时访问同一个外设)。
11.2 Example: Simple Little Operating System
我们开发了一个小型操作系统,称为Simple Little Operating System (SLOS)。它展示了之前讨论的基本组件如何在一个完整的操作系统中结合在一起。我们选择了ARM7TDMI作为核心,因为它是ARM家族中最简单的核心。我们使用ARM Developers' Suite version 1.2作为开发环境,以及ARM的Evaluator-7T作为目标板。相对而言,将SLOS修改为其他开发环境下构建应该是相对容易的。SLOS使用了第10章中描述的Sandstone固件来加载和执行。
SLOS是一个抢占式操作系统。定期中断激活一个休眠任务。为了简单起见,所有的任务和设备驱动程序都是静态的,也就是说,在系统运行时它们是在构建时创建的,而不是动态创建的。SLOS还提供了一个设备驱动程序框架,详见第11.2.7节。
SLOS被设计为在没有内存管理单元或保护单元的ARM7TDMI核心上执行。假设内存映射已经由初始化代码配置好了(在本例中是Sandstone,在第10章中有介绍)。要求SRAM位于0x00000000到0x00080000之间,并且基本配置寄存器必须设置为地址0x03ff0000。
SLOS被加载到地址0x00000000,其中向量表位于该地址。这也是进入SLOS的入口点。在固件交出控制权时,重要的是ARM处理器处于SVC模式,因为SVC模式是特权模式,因此允许初始化代码通过访问cpsr来改变模式。我们利用这一点在IRQ和系统模式下设置了堆栈。
在当前配置下,SLOS包括三个任务和两个服务例程。任务1和任务2通过使用二进制信号量提供了一个互斥的示例。实现的两个服务例程是周期定时器(必需的)和一个按键中断(可选的)。任务3通过ARM Evaluator-7T的一个串口提供了一个简单的命令行界面。
SLOS中的每个任务都需要有自己的堆栈。所有的任务都在用户模式下运行,因此一个任务可以读取但不能写入cpsr。任务改变为特权模式的唯一方式是使用SWI指令调用。这是调用设备驱动程序函数的机制,因为设备驱动程序可能需要完全访问cpsr。
cpsr可以在任务中被修改,但只能通过更新条件标志位的指令来间接修改。
11.2.1 SLOS Directory Layout
SLOS可以在我们的网站上的第11章目录下找到。SLOS的目录结构类似于Sandstone固件的布局(见图10.1和11.1)。

在slos/build/src目录下有六个子目录,包含了所有操作系统的源文件。slos/build/src/core目录包含了杂项的实用文件,以及命令行解释器(CLI)源代码。
特定平台的代码存储在以该平台名称命名的目录下。例如,Evaluator-7T的代码存储在e7t目录下。
slos/build/src/e7t/devices目录包含了所有设备驱动程序文件,slos/build/src/e7t/events目录包含了处理服务、异常和中断的文件。
最后,slos/build/src/apps目录包含了特定配置的所有应用程序/任务。例如,对于Evaluator-7T实现,有三个应用程序/任务。
11.2.2 Initialization
SLOS的初始化有三个主要阶段:启动、执行进程控制块(PCB)设置代码和执行C语言初始化代码。启动代码设置FIQ寄存器以及系统、SVC和IRQ模式的堆栈。在接下来的阶段中,设置PCB,其中包含每个任务的状态,包括所有的ARM寄存器。它用于在上下文切换期间存储和恢复任务状态。设置代码将进程控制块设置为初始启动状态。最后的C语言初始化阶段调用设备驱动程序、事件处理程序和周期定时器的初始化例程。完成后,可以调用第一个任务。
控制通过复位向量传递给SLOS。向量复位是存放初始化代码起始地址的内存位置。假设固件将处理器置于SVC模式下,允许操作系统初始化代码完全访问cpsr。第一条操作系统指令将pc加载为初始化代码(coreInitialization)的开始地址。从向量表中可以看到,该指令使用相对于pc的地址的加载指令加载一个字。汇编工具已经根据pc和vectorReset地址之间的差值计算出偏移值。
bash
AREA ENTRYSLOS,CODE,READONLY
ENTRY
LDR pc, vectorReset
LDR pc, vectorUndefined
LDR pc, vectorSWI
LDR pc, vectorPrefetchAbort
LDR pc, vectorDataAbort
LDR pc, vectorReserved
LDR pc, vectorIRQ
LDR pc, vectorFIQ
vectorReset
DCD coreInitialize
vectorUndefined DCD coreUndefinedHandler
vectorSWI
DCD coreSWIHandler
vectorPrefetchAbort DCD corePrefetchAbortHandler
vectorDataAbort DCD coreDataAbortHandler
vectorReserved DCD coreReservedHandler
vectorIRQ
DCD coreIRQHandler
vectorFIQ
DCD coreFIQHandler作为初始化过程的一部分,我们使用了FIQ寄存器来实现低级别的调试系统,如下图所示。这些寄存器用于存储状态信息。但并不总是可以使用FIQ寄存器,因为它们可能被用于其他目的。
bash
bringupInitFIQRegisters
MOV r2,r14
; save r14
BL switchToFIQMode ; change FIQ mode
MOV r8,#0
; r8_fiq=0
MOV r9,#0
; r9_fiq=0
MOV r10,#0
; r10_fiq=0
BL switchToSVCMode ; change SVC mode
MOV pc,r2
; return
coreInitialize
BL bringupInitFIQRegisters下一阶段是设置SVC、IRQ和系统基本堆栈寄存器。对于SVC堆栈来说,这很简单,因为处理器已经处于SVC模式。代码如下所示:
bash
MOV sp,#0x80000
; SVC stack
MSR cpsr_c,#NoInt|SYS32md
MOV sp,#0x40000
; user/system stack
MSR cpsr_c,#NoInt|IRQ32md
MOV sp,#0x9000
; IRQ stack
MSR cpsr_c,#NoInt|SVC32md从代码中可以看出,一旦堆栈设置完毕,处理器将切换回SVC模式,以便继续进行剩余的初始化过程。处于特权模式下允许最后的初始化阶段通过清除I位和将处理器更改为用户模式来取消屏蔽IRQ中断。
执行启动代码的结果如下:
-
低级别调试机制已初始化。
-
SVC、IRQ和系统基本堆栈已设置好。
要启动SLOS运行,必须初始化每个任务的PCB。PCB是一个保留的数据结构,保存了整个ARM寄存器集的副本(参见表11.1)。通过将相应任务的PCB数据复制到处理器寄存器中,可以激活任务。

在发生上下文切换之前,必须设置每个任务的PCB,因为切换会将PCB数据传输到r0至r15寄存器和cpsr中。如果未初始化,上下文切换将在这些寄存器中复制垃圾数据。
有四个主要部分的PCB需要初始化:程序计数器(PC)、链接寄存器(LR)、用户模式堆栈和保存的处理器状态寄存器(也就是r13、r14、r15和spsr)针对每个任务进行初始化。
bash
; void pcbSetUp(void *entryAddr, void *PCB, UINT offset);
pcbSetUp
STR r0,[r1,#-4] ; PCB[-4]=C_TaskEntry
STR r0,[r1,#-64] ; PCB[-64]=C_TaskEntry
SUB r0,sp,r2
STR r0,[r1,#-8] ; PCB[-8]=sp-<offset>
MOV r0,#0x50
; cpsr_c
STR r0,[r1,#-68] ; PCB[-68]=iFt_User
MOV pc,lr为了帮助说明这一点,我们提取了初始化PCB的例程。调用pcbSetUp例程来设置任务2和任务3的PCB。寄存器r0是任务的入口地址------标签entryAddr。这是任务的执行地址。寄存器r1是PCB数据结构的地址------标签pcbAddr。该地址指向一个存储任务PCB的内存块。寄存器r2是堆栈偏移量,用于在内存映射中定位堆栈。需要注意的是,任务1不需要初始化,因为它是第一个要执行的任务。
设置PCB的最后一部分是设置当前任务标识符,调度算法使用该标识符确定要执行的任务。
bash
LDR r0,=PCB_CurrentTask
MOV r1,#0
STR r1,[r0]
LDR lr,=C_Entry
MOV pc,lr ; enter the CEntry world在代码片段的末尾,通过将pc设置为例程的起始地址,调用了第一个C例程------C_Entry。
执行PCB设置代码的结果如下:
-
初始化所有三个任务的PCB。
-
将要执行的当前PCB设置为任务1(标识符为0)。
现在,初始化工作交给了C_Entry()例程,该例程可以在build/src/core/cinit.c文件中找到。C_Entry例程调用另一个例程cinit_init()。这个例程用于初始化设备驱动、服务和周期性中断滴答。这里展示了cinit_init()例程的内容。C代码的设计不需要初始化标准C库,因为它不调用任何标准C库函数,例如printf()、fopen()等。
bash
void cinit_init(void)
{
eventIODeviceInit();
eventServicesInit();
eventTickInit(2);
}函数eventIODeviceInit、eventServicesInit和eventTickInit都被调用以初始化操作系统的各个特定部分。你会注意到,eventTickInit有一个参数,值为2。这用于设置周期性滴答事件之间的毫秒数。
初始化完成后,可以启动周期性定时器,如下所示。这意味着在第一个定时器中断之前需要调用任务1。为了允许周期性事件中断处理器,必须启用IRQ并将处理器置于用户模式。完成这一步骤后,将调用任务1的入口点C_EntryTask1的地址。
cpp
int C_Entry(void)
{
cinit_init();
eventTickStart();
__asm
{
MSR cpsr_c,#0x50
}
C_EntryTask1();
return 0;
}如果一切正常,C_Entry例程末尾的返回语句将永远不会执行。此时,所有初始化工作已经完成,操作系统完全可用。
执行所有C初始化代码的结果如下:
-
设备驱动程序被初始化。
-
服务被初始化。
-
周期性定时器滴答被初始化并启动。
-
cpsr中启用了IRQ中断。
-
处理器被置于用户模式。
-
调用了任务1的入口点(即C_EntryTask1)。
11.2.3 Memory Model
我们采用了一个简单的内存模型来设计SLOS。图11.2显示了SLOS的代码部分,包括任务,位于低地址内存中,而IRQ和每个任务的堆栈位于较高地址内存中。SVC堆栈设置在内存的顶部。内存映射中的箭头表示堆栈增长的方向。

//SVC stack
/*
SVC(Supervisor Call)是一种处理器指令,用于在操作系统内核态(supervisor mode)和用户态(user mode)之间进行切换和通信。当用户程序需要执行特权指令或访问受限资源时,会触发一个SVC异常,将控制权传递给操作系统内核。
在处理SVC异常时,操作系统会使用一个称为SVC堆栈(SVC stack)的数据结构来保存相关的上下文信息。SVC堆栈通常是一个专门的内存区域,用于存储异常处理所需的寄存器值、返回地址和其他相关数据。它位于内核的地址空间中,并且在内核模式下可访问。
*/
11.2.4 Interrupts and Exceptions Handling
在这个操作系统的实现中,实际上只使用了三个异常。其他异常会通过转到特定的虚拟处理程序而被忽略,为了安全起见,这些处理程序被实现为无限循环。在完整的实现中,这些虚拟处理程序应该被替换为完整的处理程序。表11.2展示了这三个异常以及它们在操作系统中的使用方式。

11.2.4.1 Reset Exception
重置只在初始化阶段被调用一次。理论上,它可以被再次调用以重新初始化系统,例如作为响应看门狗定时器事件重置处理器。当系统长时间处于非活动状态时,看门狗定时器用于重置系统。
11.2.4.2 SWI Exception
每当应用程序调用设备驱动程序时,调用会通过SWI处理程序机制进行。SWI指令强制处理器从用户模式切换到SVC模式。
以下是核心的SWI处理程序。处理程序的第一个动作是将寄存器r0到r12保存到SVC堆栈中。
接下来的动作是计算SWI指令的地址,并将该指令加载到寄存器r10中。通过屏蔽掉最高的8位,可以获取SWI号码。然后将SVC堆栈的地址复制到寄存器r1中,并在调用SWI C处理程序时作为第二个参数使用。
接着,将spsr复制到寄存器r2,并存储在堆栈中。这仅在出现嵌套的SWI调用时才需要。然后,处理程序跳转到调用C处理程序例程的代码处。
bash
coreSWIHandler
STMFD sp!,{r0-r12,r14} ; save context
LDR r10,[r14,#-4] ; load SWI instruction
BIC r10,r10,#0xff000000 ; mask off the MSB 8 bits
MOV r1,r13
; copy r13_svc to r1
MRS r2,spsr
; copy spsr to r2
STMFD r13!,{r2}
; save r2 onto the stack
BL swi_jumptable ; branch to the swi_jumptable在BL指令之后的代码如下所示,将返回到调用方程序。这通过从堆栈中还原spsr并重新加载所有用户保留的寄存器,包括pc,来实现。
bash
LDMFD r13!,{r2} ; restore the r2 (spsr)
MSR spsr_cxsf,r2 ; copy r2 back to spsr
LDMFD r13!,{r0-r12,pc}ˆ ; restore context and return链接寄存器在BL指令中已经设置。当SWI C处理程序完成时,执行该代码。
bash
swi_jumptable
MOV r0,r10
; move the SWI number to r0
B eventsSWIHandler ; branch to SWI handler在图11.3中显示的C处理程序eventsSWIHandler以寄存器r0包含的SWI号码和寄存器r1指向存储在SVC堆栈上的寄存器的位置被调用。


11.2.4.3 IRQ Exception
IRQ处理程序比SWI处理程序要简单得多。它作为基本的非嵌套中断处理程序实现。处理程序首先保存上下文,然后将中断控制器状态寄存器INTPND的内容复制到寄存器r0中。然后,每个服务例程将寄存器r0与特定的中断源进行比较。如果源和中断匹配,则调用服务例程;否则,将中断视为幻影中断并忽略。
bash
TICKINT EQU 0x400
BUTTONINT EQU 0x001
eventsIRQHandler
SUB r14, r14, #4
; r14_irq-=4
STMFD r13!, {r0-r3, r12, r14} ; save context
LDR r0,INTPND
; r0=int pending reg
LDR r0,[r0]
; r0=memory[r0]
TST r0,#TICKINT
; if tick int
BNE eventsTickVeneer
; then tick ISR
TST r0,#BUTTONINT
; if button interrupt
BNE eventsButtonVeneer ; then button ISR
LDMFD r13!, {r0-r3, r12, pc}ˆ ; return to task对于已知的中断源,会调用中断修饰程序来处理事件。下面的代码展示了一个定时器修饰程序的示例。从示例中可以看出,修饰程序包括调用两个例程:第一个是重置定时器的eventsTickService(特定于平台的调用),第二个是调用调度器的kernelScheduler,而调度器则会进行上下文切换。
bash
eventsTickVeneer
BL eventsTickService ; reset tick hardware
B kernelScheduler
; branch to scheduler在IRQ堆栈上没有对寄存器r4到r12的要求,因为调度算法和上下文切换处理了所有寄存器的细节。
11.2.5 Scheduler
在SLOS中使用的低级调度器或分发器是一个简单的静态轮转算法,如下的伪代码所示。这里的"静态"表示任务仅在操作系统初始化时创建。在SLOS中,任务既不能在操作系统处于活动状态时创建,也不能被销毁。
cpp
task t=0,t';
scheduler()
{
t' = t + 1;
if t' = MAX_NUMBER_OF_TASKS then
t' = 0 // the first task.
end;
ContextSwitch(t,t')
}如前所述,在初始化阶段,当前活动任务t(PCB_CurrentTask)被设置为0。当周期性的时钟中断发生时,新的任务t'是通过当前任务t加1来计算得到的。如果任务编号等于任务限制(MAX_NUMBER_OF_TASKS),则任务t'将被重置为起始值0。
表11.3列出了调度器使用的标签以及它们在算法中的用法的描述。这些标签用于调度器的以下过程和代码:

-
通过加载PCB_CurrentTask的内容获取当前任务ID。
-
使用PCB_CurrentTask作为索引在PCB_Table中找到当前任务对应的PCB地址。
-
使用第2步获取的地址更新PCB_PtrCurrentTask的值。
-
使用轮转算法计算新的任务t'的ID。
-
将新的任务t'的ID存储到PCB_CurrentTask中。
-
通过使用更新后的PCB_CurrentTask作为索引在PCB_Table中找到下一个任务PCB的地址。
-
将下一个任务PCB存储到PCB_PtrNextTask中。
调度下一个任务t'的代码如下:
bash
MaxNumTasks EQU 3
FirstTask EQU 0
CurrentTask
LDR r3,=PCB_CurrentTask ; [1] r3=PCB_CurrentTask
LDR r0,[r3]
; r0= current Task ID
LDR r1,=PCB_Table ; [2] r1=PCB_Table address
LDR r1,[r1,r0,LSL#2] ; r1=mem32[r1+r0 << 2]
LDR r2,=PCB_PtrCurrentTask ; [3] r2=PCB_PtrCurrentTask
STR r1,[r2]
; mem32[r2]=r1 : task addr
; ** PCB_PtrCurrentTask - updated with the addr of the current task
; ** r2 = PCB_PtrCurrentTask address
; ** r1 = current task PCB address
; ** r0 = current task ID
NextTask
ADD r0,r0,#1
; [4] r0 = (CurrentTaskID)+1
CMP r0,#MaxNumTasks ; if r0==MaxNumTasks
MOVEQ r0,#FirstTask ; then r0 = FirstTask (0)
STR r0,[r3]
; [5] mem32[r3]=next Task ID
LDR r1,=PCB_Table ; [6] r1=PCB_Table addr
LDR r1,[r1,r0,LSL#2] ; r1=memory[r1+r0 << 2]
LDR r0,=PCB_PtrNextTask ; [7] r0=PCB_PtrNextTask
STR r1,[r0]
; memory[r0]=next task addr执行调度器后的结果如下:
* PCB_PtrCurrentTask指向当前活动PCB的地址。
* PCB_PtrNextTask指向下一个活动PCB的地址。
* PCB_CurrentTask存储下一个任务的标识符的值。
11.2.6 Context Switch
利用调度器产生的更新信息,上下文切换将当前活动任务t与下一个任务t'进行交换。为了实现这一点,上下文切换将活动分为两个阶段,如图11.4所示。第一阶段涉及将处理器寄存器保存到由PCB_PtrCurrentTask指向的当前任务t的PCB中。第二阶段从由PCB_PtrNextTask指向的下一个任务t'的PCB中加载寄存器的数据。

//看起来每个task都有对应的PCB
现在我们将带您了解上下文切换的两个阶段的过程和代码,首先详细介绍保存当前上下文的过程,然后再加载新的上下文。
11.2.6.1 Save the Current Context
第一阶段是保存活动任务t的当前寄存器。所有任务都在用户模式下执行,因此必须保存用户模式寄存器。以下是该过程:
-
我们必须从堆栈中恢复寄存器r0到r3和r14。这些寄存器属于当前任务。
-
然后,使用寄存器r13指向当前任务PCB的偏移量为-60的位置。这个偏移量允许两条指令更新整个PCB。
-
第一阶段的最后一个动作是存储所有的用户模式寄存器r0到r14。这可以通过一条指令完成。请记住,符号ˆ表示存储多个指令作用于用户模式寄存器。第二条存储指令保存spsr和返回的链接寄存器。
将寄存器保存到PCB的代码如下:
bash
Offset15Regs EQU 15*4
handler_contextswitch
LDMFD r13!,{r0-r3,r12,r14} ; [1.1] restore registers
LDR r13,=PCB_PtrCurrentTask ; [1.2]
LDR r13,[r13]
; r13=mem32[r13]
SUB r13,r13,#Offset15Regs ; r13-=15*Reg:place r13
STMIA r13,{r0-r14}ˆ
; [1.3] save user mode registers
MRS r0, spsr
; copy spsr
STMDB r13,{r0,r14}
; save r0(spsr) & r14(lr)保存当前上下文的结果如下:
-
IRQ堆栈被重置,并保存到PCB_IRQStack中。
-
任务t的用户模式寄存器被保存到当前PCB中。
11.2.6.2 Load the Next Context
上下文切换的第二阶段涉及将任务t'的PCB转移到用户模式的保护寄存器中。完成后,程序必须将控制权交给新的任务t'。以下是该过程:
-
加载并将寄存器r13定位在新的PCB起始处偏移量为-60的位置。
-
首先加载寄存器spsr和链接寄存器。然后加载下一个任务的寄存器r0到r14。寄存器r14是用户模式的寄存器r14,而不是指令中的ˆ所示的IRQ寄存器r14。
-
然后从PCB_IRQStack中恢复IRQ堆栈。
-
通过将寄存器r14中保存的地址复制到pc,并更新cpsr,来恢复执行新的任务。
从PCB加载寄存器的代码如下:
bash
LDR r13,=PCB_PtrNextTask ; [2.1] r13=PCB_PtrNextTask
LDR r13,[r13]
; r13=mem32[r13] : next PCB
SUB r13,r13,#Offset15Regs ; r13-=15*Registers
LDMDB r13,{r0,r14} ; [2.2] load r0 & r14
MSR spsr_cxsf, r0 ; spsr = r0
LDMIA r13,{r0-r14}ˆ ; load r0_user-r14_user
LDR r13,=PCB_IRQStack ; [2.3] r13=IRQ stack addr
LDR r13,[r13]
; r13=mem32[r13] : reset IRQ
MOVS pc,r14
; [2.4] return to next task加载下一个上下文的结果如下:
-
上下文切换完成。
-
下一个任务的寄存器被加载到用户模式寄存器中。
-
IRQ堆栈被还原为在进入IRQ处理程序之前的原始设置。
11.2.7 Device Driver Framework
设备驱动框架(DDF)使用SWI指令来实现。DDF保护操作系统免受应用程序直接访问硬件的影响,并为任务提供统一的标准接口。为了访问特定设备,任务必须首先获得一个唯一的标识号(UID)。通过调用open宏或eventsIODeviceOpen来实现这一目的。该宏会直接转换成设备驱动的SWI指令。UID用于检查是否有其他任务已经访问了相同的设备。
打开设备驱动的任务代码是:
cpp
device_treestr *host;
UID serial;
host = eventIODeviceOpen(&serial,DEVICE_SERIAL_E7T,COM1);
if (host==0)
{
/* ...error device driver not found...*/
}
switch (serial)
{
case DEVICE_IN_USE:
case DEVICE_UNKNOWN:
/* ...problem with device... */
}该示例展示了使用设备驱动框架打开串行设备。一组宏将参数转换为寄存器r1到r3。然后,这些寄存器通过SWI机制传递给设备驱动函数。在该示例中,只有由r1指向的值,即&serial,实际上被更新。该值用于返回UID。如果返回的值为零,则表示发生了错误。
下面的代码显示了如何将宏eventIODeviceOpen转换为单个SWI指令调用:
bash
PRE
r0 = Event_IODeviceOpen (unsigned int)
r1 = &serial (UID *u)
r2 = DEVICE_SERIAL_E7T (unsigned int major)
r3 = COM1 (unsigned int minor)
SWI 5075
POST
r1 = The data pointed to by the UID pointer is updatedSWI接口被用作在任务在非特权模式下执行时切换到特权模式的方法。这允许设备驱动程序完全访问cpsr。图11.5显示了调用设备驱动函数时实际的模式变化。从图中可以看出,设备驱动程序本身在系统模式下执行(特权模式)。

一旦执行了SWI指令,处理器就会进入SVC模式,并且IRQ中断会自动禁用。只有当处理器切换到系统模式时,中断才会重新启用。唯一的例外是在初始化阶段调用设备驱动函数时,此时中断将保持禁用状态。
11.3 Summary
在ARM处理器上执行的嵌入式操作系统的基本组件如下:
■ 初始化:设置操作系统使用的所有内部变量、数据结构和硬件设备。
■ 内存管理:组织内存以容纳内核及要执行的各种应用程序。
■ 所有中断和异常都需要一个处理程序。对于未使用的中断和异常,必须安装一个虚拟处理程序。
■ 预置定时器:对于抢占式操作系统,需要定期定时器。定时器产生一个中断,导致调度程序被调用。
■ 调度程序:是确定要执行的新任务的算法。
■ 上下文切换:保存当前任务的状态,并加载下一个任务的状态。
这些组件在名为Simple Little Operating System(SLOS)的操作系统中得到了体现:
■ 初始化:设置SLOS的所有功能,包括银行模式堆栈、每个应用程序的进程控制块(PCB)、设备驱动程序等。
■ 内存模型:SLOS内核放置在低内存中,每个应用程序都有自己的存储区域和堆栈。微控制器系统寄存器放置在ROM和SRAM之外。
■ 中断和异常:SLOS仅使用三个事件,分别是Reset、SWI和IRQ。所有其他未使用的中断和异常都有一个虚拟处理程序安装。
■ 调度程序:SLOS实现了一个简单的轮转调度程序。
■ 上下文切换:首先将当前上下文保存到一个PCB中,然后从另一个PCB中加载下一个任务的上下文。
■ 设备驱动框架:这保护操作系统免受应用程序直接访问硬件的影响。
Chapter12 Caches
缓存是位于处理器核心和主内存之间的一种小型、快速的存储器阵列,用于存储最近引用的主内存的部分内容。处理器尽可能使用缓存而不是主内存,以提高系统性能。缓存的目标是减少处理器核心由于慢速内存而产生的内存访问瓶颈。
常与缓存一起使用的是写缓冲区,它是一个非常小的先进先出(FIFO)存储器,位于处理器核心和主内存之间。写缓冲区的目的是解放处理器核心和缓存存储器,使其不受写入主内存的缓慢写入时间的影响。
单词"缓存"是法语,意思是"隐藏的存储空间"。当应用于ARM嵌入式系统时,这个定义非常准确。缓存存储器和写缓冲区硬件添加到处理器核心时被设计为对软件代码执行透明,因此以前编写的软件不需要重新编写以在缓存的核心上使用。缓存和写缓冲区都有额外的控制硬件,自动处理代码和数据在处理器和主内存之间的移动。然而,了解处理器的缓存设计的细节可以帮助您创建在特定ARM核心上运行更快的程序。
由于本章的大部分内容都是关于缓存如何使程序运行更快的精彩事物,所以会产生一个问题:"在系统中使用缓存是否会带来任何缺点?"答案是肯定的。主要的缺点是确定程序的执行时间的困难。为什么这是一个问题,很快就会明显。
由于缓存存储器只占主内存的很小一部分,在程序执行过程中,缓存很快就会填满。一旦满了,缓存控制器会频繁地从缓存存储器中逐出现有的代码或数据,以为新的代码或数据腾出更多空间。这个逐出过程往往是随机发生的,有些数据保留在缓存中,而其他数据则被移除。因此,在任何给定的时刻,一个值可能存储在缓存中,也可能不在。
由于数据可能存在或不存在于缓存中的任何时间点,一个例程的执行时间由于使用直接从缓存内存中读取数据与从主内存加载缓存行之间的时间差异而略有变化。
因此,在这种情况下,我们首先展示缓存在标准内存层次结构中的位置,并介绍引用局部性原理,以解释为什么缓存可以提高系统性能。然后我们概述一般的缓存架构,并定义了一组ARM社区常用的术语。本章最后以示例代码结束,展示如何清除和刷新缓存,并将代码和数据段锁定在缓存中。
12.1 The Memory Hierarchy and Cache Memory
在第一章中,我们介绍了计算机系统中的内存层次结构。图12.1回顾了部分信息,以展示缓存和写缓冲区在层次结构中的位置。

内存层次结构的最内层是处理器核心。这种内存与处理器紧密耦合,在很多方面很难将其视为与处理器分离的部分。这种内存被称为寄存器文件。这些寄存器是处理器核心的一部分,并在系统中提供最快的内存访问。
在主要级别上,内存组件通过专用的芯片内接口连接到处理器核心。在这个级别上,我们可以找到紧密耦合的内存(TCM)和一级缓存。稍后我们会详细讨论缓存。
主存也位于主要级别上。它包括易失性组件,如SRAM和DRAM,以及非易失性组件,如闪存。主存的目的是在系统运行程序时存储这些程序。
下一个级别是辅助存储,即大型、慢速、相对廉价的大容量存储设备,如硬盘驱动器或可移动存储器。此级别还包括来自外围设备的数据,其特点是访问时间极长。辅助存储用于存储不适合主存的非常大的程序的未使用部分以及当前未执行的程序。
值得注意的是,内存层次结构既取决于体系结构设计,也取决于周围的技术。例如,TCM和SRAM都是相同的技术,但在体系结构布局上有所不同:TCM位于芯片上,而SRAM位于电路板上。
缓存可以嵌入到层次结构的任何级别,在内存组件之间存在显著的访问时间差异时。只要存在这样的差异,缓存就可以提高系统性能。缓存存储器系统将存储在较低层次的信息临时移动到较高层次。
图12.1包括一级(L1)缓存和写缓冲区。L1缓存是一组高速芯片内存,临时存放来自较慢层次的代码和数据。缓存存储这些信息以减少访问指令和数据所需的时间。写缓冲区是一个非常小的FIFO缓冲区,支持从缓存向主存进行写操作。
图中没有显示二级(L2)缓存。L2缓存位于L1缓存和较慢的内存之间。L1和L2缓存也被称为一级和二级缓存。

图12.2显示了缓存与主存系统和处理器核心的关系。图的上半部分显示了一个没有缓存的系统的块图。主存由处理器核心直接访问,使用处理器核心支持的数据类型。图的下半部分显示了一个带有缓存的系统。缓存存储器比主存快得多,因此可以快速响应核心的数据请求。缓存与主存的关系涉及在较慢的主存和较快的缓存之间传输小块数据。这些数据块被称为缓存行。写缓冲区充当临时缓冲区,释放缓存存储器中的可用空间。缓存以高速将缓存行传输到写缓冲区,然后写缓冲区以较慢的速度将其传输到主存。
12.1.1 Caches and Memory Management Units
如果有一个带有缓存的核心支持虚拟内存,它可以位于核心和内存管理单元(MMU)之间,或位于MMU和物理内存之间。缓存在MMU之前或之后的放置决定了缓存所在的地址空间以及程序员如何看待缓存存储系统。图12.3显示了这两种缓存之间的差异。

逻辑缓存以虚拟地址空间存储数据。逻辑缓存位于处理器和MMU之间。处理器可以直接从逻辑缓存访问数据,无需经过MMU。逻辑缓存也被称为虚拟缓存。
物理缓存使用物理地址存储内存。物理缓存位于MMU和主存之间。对于处理器访问内存,MMU必须先将虚拟地址转换为物理地址,然后缓存存储器才能向核心提供数据。
带有MMU的ARM缓存核心在ARM7到ARM10系列处理器(包括Intel StrongARM和Intel XScale处理器)中使用逻辑缓存。ARM11处理器系列使用物理缓存。关于MMU操作的更多信息,请参阅第14章。
//ARM11处理器属于ARMv6系列。
缓存提供性能改进的原因是因为计算机程序以非随机方式执行。可预测的程序执行是缓存系统成功的关键。如果程序对内存的访问是随机的,缓存对整体系统性能的改进将很小。参考局部性原理解释了缓存内存对系统性能改进的原因。这个原理指出计算机软件程序经常运行一些小循环代码,反复操作数据内存的局部部分。
在内存中重复使用相同的代码或数据,或者非常接近的代码或数据,是缓存提高性能的原因。当首次访问时,通过将引用的代码或数据加载到更快的内存中,后续的访问将快得多。正是对较快内存的重复访问改善了性能。
缓存在时间和空间上利用了这种重复的局部引用。如果是时间上的引用,则称为时间局部性。如果是地址上的邻近引用,则称为空间局部性。
//ARMv8系列处理器使用的是物理缓存还是逻辑缓存?
ARMv8系列处理器使用的是物理缓存。
12.2 Cache Architecture
ARM处理器在其带有缓存的核心中使用了两种总线架构,分别是冯·诺依曼(Von Neumann)和哈佛(Harvard)。冯·诺依曼和哈佛总线架构在核心和内存之间指令和数据路径的分离上存在差异。为支持这两种架构,使用了不同的缓存设计。
在使用冯·诺依曼架构的处理器核心中,有一个单一的用于指令和数据的缓存。这种类型的缓存被称为统一缓存。统一缓存内存包含了指令和数据值。
哈佛架构通过分离指令和数据总线来提高整个系统的性能,但是支持这两个总线需要两个缓存。在使用哈佛架构的处理器核心中,有两个缓存:指令缓存(I-cache)和数据缓存(D-cache)。这种类型的缓存被称为分离缓存。在分离缓存中,指令存储在指令缓存中,数据值存储在数据缓存中。
我们通过图12.4展示了统一缓存的基本架构来介绍缓存的基本架构。缓存的两个主要元素是缓存控制器和缓存存储器。缓存存储器是一个专用的内存数组,以称为缓存行的单位访问。缓存控制器使用处理器发出的地址的不同部分来选择缓存存储器的部分。我们将首先介绍缓存存储器的架构,然后再详细介绍缓存控制器的细节。

//ARMv8处理器使用的总线架构是冯·诺依曼架构还是哈佛架构?
//应该是分离的哈佛架构
12.2.1 Basic Architecture of a Cache Memory
图12.4的右侧显示了一个简单的高速缓存存储器。它由三个主要部分组成:目录存储区、数据区和状态信息。高速缓存存储器的所有三个部分都存在于每个缓存行中。
高速缓存存储器必须知道缓存行中存储的信息来自主存的哪个位置。它使用目录存储区来保存标识缓存行从主存复制而来的地址。目录条目称为缓存标记。
高速缓存存储器还必须存储从主存读取的数据。这些数据存储在数据区中(参见图12.4)。
高速缓存的大小定义为缓存能够从主存存储的实际代码或数据。不包括在缓存大小内的是支持缓存标记或状态位所需的缓存存储器。
高速缓存存储器中还有状态位以维护状态信息。两个常见的状态位是有效位和脏位。有效位将缓存行标记为活动状态,表示它包含最初来自主存的实时数据,并且当前可供处理器核心按需访问。脏位定义了缓存行是否包含与其在主存中表示的值不同的数据。我们会在第12.3.1节中对脏位进行更详细的说明。
12.2.2 Basic Operation of a Cache Controller
Cache控制器是一种硬件,它自动将代码或数据从主存储器复制到缓存内存。它的任务是自动执行此操作,以使支持的软件无需改变即可在带有缓存和不带缓存的系统上运行。
缓存控制器在将读取和写入内存的请求传递给内存控制器之前拦截这些请求。它通过将请求的地址分成三个字段来处理请求,即标签字段、集合索引字段和数据索引字段。这三个位字段如图12.4所示。
首先,控制器使用地址的集合索引部分来定位可能包含所请求的代码或数据的缓存行。该缓存行包含缓存标签和状态位,控制器使用它们来确定实际存储在其中的数据。
然后,控制器检查有效位以确定缓存行是否活动,并将缓存标签与请求地址的标签字段进行比较。如果状态检查和比较都成功,则为缓存命中。如果状态检查或比较失败,则为缓存未命中。
在缓存未命中的情况下,控制器会将整个缓存行从主存储器复制到缓存内存,并提供所请求的代码或数据给处理器。将缓存行从主存储器复制到缓存内存的过程称为缓存行填充。
在缓存命中的情况下,控制器直接从缓存内存中向处理器提供代码或数据。为此,它继续进行下一步,即使用地址请求的数据索引字段来选择缓存行中的实际代码或数据,并将其提供给处理器。
12.2.3 The Relationship between Cache and Main Memory
了解基本的缓存内存架构和缓存控制器的工作原理,就足够讨论缓存与主存储器之间的关系了。
图12.5显示了主存储器的部分内容临时存储在缓存内存中。该图表示最简单的缓存形式,称为直接映射缓存。在直接映射缓存中,主存储器中的每个地址位置都映射到缓存内存中的一个位置。由于主存储器比缓存内存大得多,因此在主存储器中有很多地址映射到缓存内存中的同一个位置。该图展示了以0x824结尾的地址类别的映射关系。

图中也显示了图12.4中引入的三个位字段。集合索引选择缓存中存储所有以0x824结尾的地址的位置。数据索引选择缓存行中的字/半字/字节,本例中是缓存行中的第二个字。标签字段是与目录存储中的缓存标签值进行比较的地址部分。在这个例子中,每个缓存内存位置对应着主存储器中一百万个可能的位置。在任何给定时间,主存储器的一百万个可能值中只能有一个存在于缓存内存中。标签与缓存标签的比较决定了所请求的数据是否在缓存中,或者表示主存储器中以0x824结尾的另一个位置。
在填充缓存行期间,缓存控制器可能会将加载的数据同时转发给核心,同时将其复制到缓存中;这就是所谓的数据流传输。数据流传输允许处理器在缓存控制器填充缓存行的剩余字时继续执行。
如果该缓存行中存在有效数据,但表示主存储器中的另一个地址块,则整个缓存行将被替换为包含所请求地址的缓存行。作为处理缓存未命中的一部分,删除现有缓存行并替换为包含所请求地址的缓存行的过程称为驱逐(eviction)------将缓存行的内容从缓存返回到主存储器,为需要加载到缓存中的新数据腾出空间。
直接映射缓存是一种简单的解决方案,但它存在一个设计成本,即只有一个位置可用于存储主存储器中的值。直接映射缓存容易受到大量的抖动影响,即在缓存内存中争夺同一位置的软件冲突。抖动的结果是重复加载和替换缓存行。加载和替换是由于程序元素被放置在主存储器中映射到缓存内存中相同缓存行的地址上。

图12.6在图12.5的基础上添加了一个简单的、人为制造的软件过程来演示抖动现象。该过程在一个do-while循环中重复调用两个例程。每个例程具有相同的索引地址;也就是说,这些例程所在的地址在物理内存中映射到缓存内存中的同一位置。在循环的第一次迭代中,例程A在执行时被放置在缓存中。当过程调用例程B时,它会逐个缓存行地将例程A替换出去,同时加载并执行例程B。在第二次循环中,例程A取代了例程B,然后例程B又取代了例程A。反复发生缓存未命中导致了不在运行的例程持续被替换,这就是缓存抖动的情况。
12.2.4 Set Associativity
//组相连

//4路组相连
一些缓存包含一个额外的设计特征,以减少抖动的频率(见图12.7)。这个结构设计特征是将缓存内存分成更小的相等单元,称为路(ways)。图12.7仍然是一个4KB的缓存;然而,集索引现在可以指向多个缓存行,每个路指向一个缓存行。缓存不再是256行的单路,而是由64行的四个路组成。具有相同集索引的四个缓存行被称为同一个集合,这也是"集索引"名称的来源。由集索引指向的缓存行集合被称为关联集。可以将主存中的数据或代码块分配给集中任何一个路中的任意一个,而不会影响程序行为;换句话说,将数据存储在集合内的缓存行中不会影响程序执行。两个连续的主内存块可以作为缓存行存储在同一个路或两个不同的路中。需要注意的重要一点是,来自主内存特定位置的数据或代码块可以存储在属于该集合的任何缓存行中。集合内的值的放置是互斥的,以防止同一代码或数据块同时占用集合中的两个缓存行。

在四路组相联缓存中,主内存到缓存的映射发生了变化。图12.8显示了差异。现在,主内存中的任何一个位置映射到缓存中的四个不同位置。尽管图12.5和图12.8都是4KB的缓存,但有一些值得注意的差异。
标记的位域现在比之前多两位,而集索引的位域减少了两位。这意味着400万个主内存地址现在映射到一个包含四个缓存行的集合,而不是100万个地址映射到一个位置。
映射到缓存的主存区域的大小现在是1KB,而不是4KB。这意味着将缓存行数据块映射到相同集合的可能性现在增加了四倍。这一点可以通过缓存行被驱逐的可能性减少四分之一来抵消。
如果在图12.8所示的四路组相联缓存中运行图12.6中显示的示例代码,抖动的发生频率会很快稳定下来,因为例程A、例程B和数据数组在集合的四个可用位置中可建立了唯一的位置。
/*
例如:
Routine A: 0x000000224
Routine B: 0x000001224
对于直接映射内存来说,Routine B替换Routine A时,必将发生cache miss;
对于四路组相联来说,Routine B替换Routine A时,Routine A的数据如果缓存在四路中的一路,Routine B的数据可以缓存在四路中的另外三路,从而降低cach miss;
*/
12.2.4.1 Increasing Set Associativity
随着缓存控制器的关联度增加,抖动的概率会降低。理想目标是通过设计将任何主内存位置映射到任何缓存行来最大化缓存的关联度。能够实现这一目标的缓存称为全相联缓存。然而,随着关联度的增加,支持它的硬件复杂性也增加。硬件设计师用于增加缓存关联度的一种方法是使用内容可寻址存储器(Content Addressable Memory,CAM)。
CAM使用一组比较器将输入的标记地址与每个有效缓存行中存储的缓存标记进行比较。CAM的工作方式与RAM相反。RAM在给定地址值后产生数据,而CAM在存储器中存在给定数据值时产生一个地址。使用CAM可以同时比较更多的缓存标记,从而增加可以包含在集合中的缓存行数量。在ARM920T和ARM940T处理器核心中,ARM选择使用CAM来定位缓存标记。ARM920T和ARM940T中的缓存是64路组相联的。图12.9显示了ARM940T缓存的框图。缓存控制器将地址标记作为CAM的输入,并且输出选择包含有效缓存行的路。

所请求地址的标记部分被用作同时将输入标记与64个路中存储的所有缓存标记进行比较的四个CAM的输入。如果匹配成功,则缓存数据由缓存内存提供。如果没有匹配,存储器控制器生成一个缺失信号。
控制器使用集索引位启用四个CAM之一。索引的CAM然后在缓存内存中选择一个缓存行,而核心地址的数据索引部分选择所请求的字、半字或字节。
12.2.5 Write Buffers
写缓冲区是一个非常小、快速的FIFO内存缓冲区,临时存储处理器通常要写入主内存的数据。在没有写缓冲区的系统中,处理器直接写入主内存。而在有写缓冲区的系统中,数据以高速写入FIFO,然后再被传输到较慢的主内存。写缓冲区减少了处理器将小块连续数据写入主内存所需的时间。写缓冲区的FIFO位于内存层次结构中与L1缓存相同的级别上,如图12.1所示。
写缓冲区的效率取决于对主内存写入次数与执行的指令数之比。在给定的时间间隔内,如果对主内存的写入次数较低或足够分散于其他处理指令之间,写缓冲区很少会填满。如果写缓冲区没有填满,运行的程序将继续使用缓存内存执行,使用寄存器进行处理,使用缓存内存进行读写,并使用写缓冲区来保存被驱逐的缓存行,直到它们排空到主内存为止。
写缓冲区还改善了缓存性能;这种改善发生在缓存行被驱逐时。如果缓存控制器驱逐了一个脏缓存行,它会将该缓存行写入写缓冲区而不是主内存。因此,新的缓存行数据将更快地可用,并且处理器可以继续从缓存内存中操作。
写入写缓冲区的数据在从写缓冲区传输到主内存之前无法进行读取。同样,被驱逐的缓存行也不能在写缓冲区中进行读取。这是写缓冲区的FIFO深度通常相当小(只有几个缓存行)的原因之一。
一些写缓冲区并不严格遵循FIFO缓冲的原则。例如,ARM10系列支持合并(coalescing),即将写操作合并为一个缓存行。如果它们代表主内存中的同一个数据块,写缓冲区将把新值合并到已存在的缓存行中。合并也称为写合并(write merging)、写折叠(write collapsing)或写组合(write combining)。
//ARMv8处理器支持写缓冲区么?
/*
是的,ARMv8处理器也支持写缓冲区。ARMv8架构引入了一种称为Store Buffer的写缓冲区机制。Store Buffer是一个用于暂时存储处理器写入主内存的数据的缓冲区。它可以将数据以高速写入缓冲区,然后再将其传输到较慢的主内存。
通过使用写缓冲区,ARMv8处理器能够更高效地处理存储指令。当处理器执行存储指令时,数据被写入到Store Buffer中,并且可以立即继续执行后续的指令,而不必等待数据被传输到主内存。这样可以提高系统性能,减少对主内存的访问延迟。
同时,ARMv8架构还支持一种称为Store Buffer Coalescing的优化技术,它可以将多个连续的存储操作合并为一个更大的存储操作,从而减少对Store Buffer和主内存的访问次数,提高整体性能。
总之,ARMv8系列处理器通过引入写缓冲区和相关的优化技术,提供了更高效的存储操作和系统性能。
*/
12.2.6 Measuring Cache Efficiency
有两个术语用于衡量程序的缓存效率:缓存命中率和缓存失效率。缓存命中率是缓存命中次数除以给定时间间隔内的总内存请求次数。该值以百分比表示:

失效率的形式类似:总缓存失效次数除以给定时间间隔内的总内存请求次数,以百分比表示。需要注意的是,失效率也等于100减去命中率。
命中率和失效率可以测量读取、写入或两者皆有,因此这些术语可用于多种性能信息的描述。例如,有读取命中率、写入命中率和其他命中率和失效率的度量方式。
缓存性能测量中使用的另外两个术语是命中时间------访问缓存中的内存位置所需的时间,以及失效惩罚------从主内存加载缓存行所需的时间。
12.3 Cache Policy
有三种策略决定了缓存的运作方式:写入策略、替换策略和分配策略。
写入策略确定了在处理器写操作期间数据存储的位置。替换策略在缓存失效时选择用于下一次行填充的缓存行。分配策略确定了缓存控制器何时分配一个缓存行。
12.3.1 Write Policy---Writeback or Writethrough
//写入策略------写回或写直通
当处理器内核向内存写入数据时,缓存控制器有两种选择的写入策略。控制器可以同时将数据写入缓存和主存储器,并更新两个位置上的值;这种方法被称为写直通(writethrough)。另一种选择是缓存控制器只将数据写入缓存而不更新主存储器,这被称为写回(writeback)或拷贝回写(copyback)。
12.3.1.1 Writethrough
当缓存控制器使用写直通策略时,在写入时如果缓存命中,它会同时将数据写入缓存和主存储器,以确保缓存和主存储器一直保持一致。根据该策略,对于每次写入缓存,缓存控制器都会执行一次写入主存储器的操作。由于需要写入主存储器,写直通策略相比写回策略速度较慢。
12.3.1.2 Writeback
当缓存控制器使用写回策略时,它会将数据写入有效的缓存数据存储器,而不是主存储器。因此,有效的缓存行和主存储器可能包含不同的数据。缓存行保存着最新的数据,而主存储器包含着尚未更新的旧数据。
配置为写回缓存的缓存必须使用缓存行状态信息块中的一个或多个"脏位"(dirty bit)。当写回缓存的控制器向缓存内存写入一个值时,它将脏位设置为"真"。如果处理器在以后的某个时间访问该缓存行,它通过脏位的状态知道该缓存行包含的数据不在主存储器中。如果缓存控制器替换了一个带有脏位的缓存行,它会自动将该缓存行写回主存储器。控制器这样做是为了防止缓存内存中关键信息的丢失,因为主存储器中没有这些信息。
写回缓存相比写直通缓存的一个性能优势在于它频繁使用子程序的临时本地变量。这些变量具有瞬时性质,实际上不需要写入主存储器。一个例子是,当局部变量溢出到缓存的栈中时,因为寄存器文件中没有足够的寄存器来保存该变量。
12.3.2 Cache Line Replacement Policies
在缓存未命中时,缓存控制器必须从可用的缓存行集合中选择一个缓存行来存储来自主存储器的新信息。被选中用于替换的缓存行称为"受害者"。如果受害者包含有效、脏的数据,控制器必须在将新数据复制到受害者缓存行之前,将脏数据从缓存内存写回主存储器。选择和替换受害者缓存行的过程称为驱逐。
缓存控制器实施的策略来选择下一个受害者称为替换策略。替换策略从可用的关联成员集合中选择一个缓存行;也就是说,它选择下一个用于缓存行替换的方式。总结整个过程,集合索引选择可用于组相联的缓存行集合,而替换策略从集合中选择具体的缓存行进行替换。
ARM缓存核心支持两种替换策略,伪随机或循环。
-
循环替换策略简单地选择要替换的集合中的下一个缓存行。选择算法使用一个递增的受害者计数器,该计数器每次缓存控制器分配一个缓存行时递增。当受害者计数器达到最大值时,它会被重置为一个定义的基础值。
-
伪随机替换策略随机选择要替换的集合中的下一个缓存行。选择算法使用非连续递增的受害者计数器。在伪随机替换算法中,控制器通过随机选择增量值并将其添加到受害者计数器来递增该计数器。当受害者计数器达到最大值时,它会被重置为一个定义的基础值。
大多数ARM核心都支持这两种策略(请参阅表12.1以获取ARM核心及其支持的策略的综合列表)。循环替换策略具有更高的可预测性,这在嵌入式系统中是可取的。然而,循环替换策略对内存访问的微小变化会导致性能的大幅变化。为了展示这种性能变化,我们提供了示例12.1。

示例12.1:该示例确定使用循环和随机替换策略执行软件例程所需的时间。测试例程cache_RRtest使用C库头文件time.h中的时钟函数收集时序数据。首先启用循环替换策略并运行定时测试,然后启用随机替换策略并运行相同的测试。
测试例程readSet针对ARM940T专门编写,有意展示使用循环替换策略时缓存行为的最坏情况和突变。
cpp
#include <stdio.h>
#include <time.h>
void cache_RRtest(int times,int numset)
{
clock_t count;
printf("Round Robin test size = %d\r\n", numset);
enableRoundRobin();
cleanFlushCache();
count = clock();
readSet(times,numset);
count = clock() - count;
printf("Round Robin enabled = %.2f seconds\r\n", (float)count/CLOCKS_PER_SEC);
enableRandom();
cleanFlushCache();
count = clock();
readSet(times, numset);
count = clock() - count;
printf("Random enabled = %.2f seconds\r\n\r\n", (float)count/CLOCKS_PER_SEC);
}
int readSet(int times, int numset)
{
int setcount, value;
volatile int *newstart;
volatile int *start = (int *)0x20000;
__asm
{
timesloop:
MOV newstart, start
MOV setcount, numset
setloop:
LDR value,[newstart,#0];
ADD newstart,newstart,#0x40;
SUBS setcount, setcount, #1;
BNE setloop;
SUBS times, times, #1;
BNE timesloop;
}
return value;
}我们编写了readSet例程来填充缓存中的一个集合。该函数有两个参数。第一个参数times是运行测试循环的次数;这个值增加了运行测试所需的时间。第二个参数numset是要读取的集合值的数量;这个值决定了例程加载到同一集合中的缓存行的数量。通过循环使用LDR指令来填充集合中的值,该指令从内存位置读取一个值,然后在每次循环中将地址递增16个字(64字节)。将numset的值设置为64将填充ARM940T中一个集合中的所有可用缓存行。在ARM940T中,一个路有16个字,一个集合有64个缓存行。
下面是两个调用round-robin测试的示例,使用了两种不同的集合大小。第一个调用读取并填充一个包含64个条目的集合;第二个尝试填充一个包含65个条目的集合。
cpp
unsigned int times = 0x10000;
unsigned int numset = 64;
cache_RRtest(times, numset);
numset = 65;
cache_RRtest(times, numset);如下是两个测试的控制台输出。这些测试在使用ARM ADS1.2 ARMulator模拟的ARM940T核心模块上运行,核心时钟速度为50 MHz,内存读取访问时间为100 ns(非连续访问)和50 ns(连续访问)。需要注意的是,循环测试读取65个集合值时的时间变化。
bash
Round Robin test size = 64
Round Robin enabled = 0.51 seconds
Random enabled = 0.51 seconds
Round Robin test size = 65
Round Robin enabled = 2.56 seconds
Random enabled = 0.58 seconds这只是一个极端的例子,但它确实展示了使用循环调度策略和随机替换策略之间的区别。
另一种常见的替换策略是最近最少使用(LRU)。该策略跟踪缓存行的使用情况,并选择最长时间未使用的缓存行作为下一个牺牲者。
ARM的缓存核心不支持最近最少使用的替换策略,尽管ARM的半导体合作伙伴已经将非缓存的ARM核心与他们自己添加的缓存一起集成到他们生产的芯片中。因此,有些基于ARM的产品使用LRU替换策略。
//ARMv8目前使用大都是PLRU替换策略
12.3.3 Allocation Policy on a Cache Miss
//替换策略是要找cache里的一行cacheline被替换,分配策略应该是要找内存里的一行填充到cache里
ARM缓存在缓存未命中后有两种策略来分配一个缓存行。第一种策略被称为"读分配"(read-allocate),第二种策略被称为"读写分配"(read-write-allocate)。
在读分配策略下,只有在从主存储器读取数据时才会在缓存里分配一个缓存行。如果被替换的缓存行包含有效数据,那么在新数据填充到缓存行之前,它会被写回主存储器。
根据这种策略,除非之前已经通过读取主存储器分配了一个缓存行,否则对内存的新数据写入不会更新缓存存储器的内容。如果缓存行包含有效数据,写操作会更新缓存并可能根据缓存写入策略将数据更新到主存储器(如果是写通策略)。如果数据不在缓存中,控制器只会将数据写入主存储器。
//一般read-allocate + write-through
//读分配策略:
//读取操作:分配一个缓存行,替换缓存中的缓存行
//写入操作:不分配缓存行,大前提是缓存未命中,即缓存中没有目的地址的内存,这时缓存控制器只会将数据写入到DDR。
在读写分配策略下,无论是读还是写操作都会在缓存里分配一个缓存行。对主存储器的任何读取或写入操作,如果数据不在缓存中,都会分配一个缓存行。在读取操作时,控制器使用读分配策略;在写操作时,控制器也会分配一个缓存行。如果被替换的缓存行包含有效数据,那么在缓存控制器从主存储器中获取新数据填充到被替换的缓存行之前,该数据会先写回主存储器。如果缓存行无效,它只会进行缓存行填充。在将缓存行从主存储器填充完成后,控制器会将数据写入缓存行内对应的数据位置。如果是写通缓存,缓存核心还会更新主存储器。
//一般read-write-allocate + write-back
//读写分配策略:
//读取操作:分配一个缓存行,替换缓存中的缓存行
//写入操作:分配一个缓存行,替换缓存中的缓存行
ARM7、ARM9和ARM10核心使用读分配策略;Intel XScale支持读分配和写分配策略。表12.1列出了每个核心支持的策略。
12.4 Coprocessor 15 and Caches
有几个协处理器15寄存器专门用于配置和控制ARM缓存核心。表12.2列出了控制缓存配置的协处理器15寄存器。

//"drain write buffer" 可以翻译为 "排空写入"。
//CP15 -> Coprocessor 15
主CP15寄存器c7和c9用于控制缓存的设置和操作。次要的CP15:c7寄存器是只写寄存器,用于清理和刷新缓存。CP15:c9寄存器定义了受害者指针的基地址,该地址决定了锁定在缓存中的代码或数据的行数。我们在接下来的章节中会更详细地讨论这些命令。要了解协处理器15指令和语法的一般用法,请参阅第3.5.2节。
还有其他CP15寄存器会影响缓存操作;这些寄存器的定义取决于核心。这些其他寄存器在第13章的13.2.3和13.2.4节中解释了初始化MPU(内存保护单元),在第14章的14.3.6节中解释了初始化MMU(内存管理单元)。
在接下来的几个章节中,我们将使用表12.2中列出的CP15寄存器来提供清理和刷新缓存、以及将代码或数据锁定在缓存中的示例例程。控制系统通常会在其内存管理活动中调用这些例程。
12.5 Flushing and Cleaning Cache Memory
ARM使用"flush"和"clean"这两个术语来描述对缓存执行的两个基本操作。
//flush -> 刷新cache里的缓存!cache的valid位由1置为0
"Flush缓存"是指刷新其中存储的任何数据。刷新操作只是清除了受影响缓存行中的有效位。整个或部分缓存可能需要刷新,以支持内存配置的更改。有时,"invalidate"一词可以替代"flush"一词。然而,如果某个D-cache的部分配置为使用写回策略,则数据缓存也可能需要清理。
//clean -> 清除cache里的缓存!cache的dirty位由1置为0,dirty
"Clean缓存"是指强制将脏的缓存行中的数据从缓存写回主存,并清除缓存行中的脏位。清理缓存重新建立了缓存内存和主内存之间的一致性,仅适用于使用写回策略的D-cache。
更改系统的内存配置可能需要清理或刷新缓存。需要清理或刷新缓存的原因直接源自于更改访问权限、缓存和缓冲策略,或重新映射虚拟地址等操作。
在执行自修改代码之前,缓存可能还需要进行清理或刷新,特别是在分裂缓存中。自修改代码包括从一个位置简单地复制代码到另一个位置。清理或刷新缓存的需求来源于两种可能的情况:首先,自修改代码可能存储在D-cache中,因此无法将其作为指令从主内存加载。其次,I-cache中的现有指令可能掩盖了写入主内存的新指令。
如果缓存使用写回策略,并且自修改代码被写入主内存,则第一步是将指令作为数据块写入主内存中的某个位置。稍后,程序将跳转到该内存区域,并从该内存区域开始执行指令流。在将代码作为数据首次写入内存时,它可能会被写入缓存而不是主内存;这在ARM缓存中发生,如果缓存中存在表示写入自修改代码位置的有效缓存行。缓存行被复制到D-cache而不是主内存。如果是这种情况,那么当程序跳转到应该存在自修改代码的位置时,它将执行仍然存在的旧指令,因为自修改代码仍然在D-cache中。为了防止这种情况发生,需要清理缓存,将存储为数据的指令强制写入主内存,在那里它们可以作为指令流进行读取。
如果D-cache已经被清理,那么新的指令将存在于主内存中。然而,I-cache也可能存储了对新数据(代码)写入地址的有效缓存行。因此,对复制代码地址处的指令的获取将从I-cache中检索旧代码,而不是从主内存中读取新代码。此时可以刷新I-cache,以防止发生这种情况。
//总之,l-cache和d-cache都要清理缓存,使得cache和主内存同步
12.5.1 Flushing ARM Cached Cores
刷新缓存会使缓存中的内容无效。如果缓存使用写回策略,需要在刷新之前清理缓存,以防止由于刷新过程中数据丢失。
在cache上执行刷新操作有三个CP15:c7命令。第一个命令刷新整个缓存,第二个命令刷新只有I-cache,第三个命令只刷新D-cache。支持这些命令的处理器和内核在表12.3中列出。处理器内核寄存器Rd的值在所有三个MCR指令中都应为零。

我们提供示例12.2来展示如何使用这些指令刷新缓存。该示例可以直接使用,也可以根据系统要求进行定制。该示例包含一个宏,它生成了三个例程(有关使用宏的信息,请参见附录A):
-
flushICache:刷新I-cache。
-
flushDCache:刷新D-cache。
-
flushCache:同时刷新I-cache和D-cache。
这些例程没有输入参数,并可以从C语言中以以下原型进行调用:
void flushCache(void); /* 刷新所有缓存 */
void flushDCache(void); /* 刷新D-cache */
void flushICache(void); /* 刷新I-cache */
MCR是ARM汇编语言中的一条指令,用于将数据从ARM处理器的寄存器传输到协处理器(coprocessor)中。MCR指令的完整写法是:
MCR{cond} {coproc}, {opc1}, Rd, CRn, CRm{, opc2}
其中,cond是条件代码,用于条件执行。coproc是协处理器的编号,opc1和opc2是操作码,指定要执行的操作。Rd是一个通用寄存器,用于传输的数据。CRn和CRm是协处理器中的寄存器序号。
MCR指令允许ARM处理器与协处理器之间进行数据传输和通信。它的具体功能和使用方式取决于协处理器的设计和规范。因此,MCR指令的具体细节会随着不同的协处理器而有所变化。要正确使用MCR指令,需要参考特定协处理器的文档和规范。
示例12.2从根据支持的命令将内核分组开始。我们使用一个名为CACHEFLUSH的宏来帮助创建这些例程。该宏首先将写入CP15:c7:Cm的内核寄存器设置为零。然后,根据所需的缓存操作类型和每个内核中的可用性,插入特定的MCR指令。
bash
IF {CPU} = "ARM720T" :LOR: \
{CPU} = "ARM920T" :LOR: \
{CPU} = "ARM922T" :LOR: \
{CPU} = "ARM926EJ-S" :LOR: \
{CPU} = "ARM940T" :LOR: \
{CPU} = "ARM946E-S" :LOR: \
{CPU} = "ARM1022E" :LOR: \
{CPU} = "ARM1026EJ-S" :LOR: \
{CPU} = "SA-110" :LOR: \
{CPU} = "XSCALE"
c7f RN 0 ; register in CP17:c7 format
MACRO
CACHEFLUSH $op
MOV c7f, #0
IF "$op" = "Icache"
MCR p15,0,c7f,c7,c5,0 ; flush I-cache
ENDIF
IF "$op" = "Dcache"
MCR p15,0,c7f,c7,c6,0 ; flush D-cache
ENDIF
IF "$op" = "IDcache"
IF {CPU} = "ARM940T" :LOR: \
{CPU} = "ARM946E-S"
MCR p15,0,c7f,c7,c5,0 ; flush I-cache
MCR p15,0,c7f,c7,c6,0 ; flush D-cache
ELSE
MCR p15,0,c7f,c7,c7,0 ; flush I-cache & D-cache
ENDIF
ENDIF
MOV pc, lr
MEND
IF {CPU} = "ARM720T"
EXPORT flushCache
flushCache
CACHEFLUSH IDcache
ELSE
EXPORT flushCache
EXPORT flushICache
EXPORT flushDCache
flushCache
CACHEFLUSH IDcache
flushICache
CACHEFLUSH Icache
flushDCache
CACHEFLUSH Dcache
ENDIF最后,我们多次使用宏来创建这些例程。ARM720T具有统一缓存,因此只有flushCache例程可用;否则,该例程会使用宏三次来创建例程。
此示例包含比大多数实现所需的代码更多。然而,它被提供为一个详尽的例程,支持所有当前的ARM处理器核心。您可以使用示例12.2来创建专用于您使用的特定核心的简化例程。我们使用ARM926EJ-S作为模型,演示如何从示例12.2中提取这三个例程。重新编写的版本如下:
bash
EXPORT flushCache926
EXPORT flushICache926
EXPORT flushDCache926
c7f RN 0 ; register in CP15:c7 format
flushCache926
MCR p15,0,c7f,c7,c7,0 ; flush I-cache & D-cache
MOV pc, lr
flushICache926
MCR p15,0,c7f,c7,c5,0 ; flush I-cache
MOV pc, lr
flushDCache926
MCR p15,0,c7f,c7,c6,0 ; flush D-cache
MOV pc, lr如果您使用C语言编写代码,可以进一步简化此代码,并将它们制作成内联函数,这些函数可以被收集并放置在一个include文件中。这些内联函数如下:
cpp
__inline void flushCache926(void)
{
unsigned int c7format = 0;
__asm{ MCR p15,0,c7format,c7,c7,0 }; /* flush I&D-cache */
}
__inline void flushDcache926(void)
{
unsigned int c7format = 0;
__asm{MCR p15,0,c7format,c7,c6,0 } /* flush D-cache */
}
__inline void flushIcache926(void)
{
unsigned int c7format = 0;
__asm{MCR p15,0,c7format,c7,c5,0 } /* flush I-cache */
}本章中的其余示例以ARM汇编语言呈现,并支持所有当前的核心。相同的提取过程可以应用于所提供的例程。
12.5.2 Cleaning ARM Cached Cores
清空缓存是发出命令,强制缓存控制器将所有脏的D-cache行写回主内存。在这个过程中,缓存行中的脏状态位被清除。清空缓存可重新建立缓存内存和主内存之间的一致性,只适用于使用写回策略的D-cache。
有时候,术语写回(writeback)和复制回(copyback)可以用来代替清空(clean)这个术语。因此,强制将缓存写回或复制回主内存与清空缓存是相同的意思。这些术语类似于用来描述缓存写策略的形容词,但在这种情况下,它们描述的是对缓存内存执行的操作。在非ARM世界中,术语刷新(flush)可能被用来表示ARM所称的清空操作。
12.5.3 Cleaning the D-Cache
在撰写本书时,有三种方法用于清空D-cache(见表格12.4);使用的方法取决于处理器的不同,因为不同的核心具有不同的命令集来清空D-cache。

尽管清空缓存的方法可能有所不同,在我们提供的示例中,我们提供了相同的过程调用,以便在所有核心上提供一致的接口。为此,我们为每种方法编写了三个清空整个缓存的例程:
-
cleanDCache:清空整个D-cache。
-
cleanFlushDCache:清空并刷新整个D-cache。
-
cleanFlushCache:清空并刷新I-cache和D-cache。
cleanDCache、cleanFlushDCache和cleanFlushCache这三个例程不需要任何输入参数,并且可以通过以下原型从C语言中调用:
cpp
void cleanDCache(void); /* 清空D-cache */
void cleanFlushDCache(void); /* 清空并刷新D-cache */
void cleanFlushCache(void); /* 清空并刷新I&D-cache */这些示例中的宏是为了尽可能支持多种ARM核心而编写的,不需要进行重大修改。这项工作还产生了一个通用的头文件,用于本示例和本章中其他几个示例。头文件的名称是cache.h,如图12.10所示。


头文件中的所有值都是以对数为底的大小或字段定位器。
如果值是一个定位器,它表示CP15寄存器中一个位域的最低位。例如,常量I7WAY指向CP15:c7:c5寄存器中路选择字段的最低位。为了明确起见,在ARM920T、ARM922T、ARM940T和ARM1022E中,I7WAY的值为26,在ARM926EJ-S、ARM946E-S和ARM1026EJ-S中,该值为30(见图12.11)。以这种格式存储这些值是为了支持对核心寄存器(Rm)进行位操作,当使用MCR指令发出清除命令时,将其移到CP15:Cd:Cm寄存器。
头文件中依赖于核心架构的六个常量如下:
-
CSIZE是缓存大小的以2为底的对数,换句话说,缓存大小为(1 << CSIZE)字节。
-
CLINE是缓存行长度的以2为底的对数,缓存行长度为(1 << CLINE)字节。
-
NWAY是路数,与关联度相同。
-
I7SET是在CP15:c7命令寄存器中将集索引左移的位数。该值还用于在顺序访问缓存时递增或递减CP15:c7寄存器的集索引部分。
-
I7WAY是在CP15:c7命令寄存器中将路索引左移的位数。该值还用于在顺序访问缓存时递增或递减CP15:c7寄存器的路索引部分。
-
I9WAY是在CP15:c9命令寄存器中将路索引左移的位数。该值还用于在顺序访问缓存时递增或递减CP15:c9寄存器的路索引部分。
有两个从核心特定数据计算得出的常量:
-
SWAY是路大小的以2为底的对数。一路的大小将为(1 << SWAY)字节。
-
NSET是每组的缓存行数。这是集索引大小的以2为底的对数。组数将为(1 << NSET)。
12.5.4 Cleaning the D-Cache Using Way and Set Index Addressing
一些ARM核心支持使用路和集索引来清除和刷新单个缓存行,以指定其在缓存中的位置。在表12.5中,可以使用MCR指令清除和刷新缓存行的命令。其中两个命令用于刷新缓存行,一个用于刷新指令缓存行,另一个用于刷新数据缓存行。其余两个命令用于清除D缓存:一个用于清除缓存行,另一个用于清除并刷新缓存行。

每个列出的核心通过路和集索引地址选择一个单独的缓存行。在使用这些指令时,单个处理器核心内所有四个命令的核心寄存器Rd的值相同;然而,寄存器内的位字段格式因处理器而异。对于支持通过路清除和刷新缓存行的核心,CP15:c7:Cm寄存器的格式如图12.11所示。要执行该命令,需要在所需的CP15:c7寄存器格式中创建一个核心寄存器Rd中的值。寄存器的一般格式包括两个位字段:一个选择路,另一个选择路中的集。创建寄存器后,执行相应的MCR指令将核心寄存器Rd移动到CP15:c7寄存器中。
以下示例显示了ARM920T、ARM922T、ARM940T、ARM946E-S和ARM1022E处理器的cleanDCache、cleanFlushDCache和cleanFlushCache过程。

示例12.3
我们使用一个名为CACHECLEANBYWAY的宏来创建使用路和集索引寻址来清除、刷新或清除并刷新缓存的三个过程。
该宏使用头文件cache.h中的常量来构建一个以CP15:c7寄存器格式(c7f)表示的处理器寄存器。第一步是将c7f寄存器设置为零,这将作为执行所选操作的MCR指令的Rd输入值。然后,根据图12.11中的格式,该宏逐个增加c7f寄存器的值,为每个写入的缓存行执行一次。宏在内部循环中递增集索引,在外部循环中递增路索引。使用这些嵌套循环,它会遍历和清除所有路中的所有缓存行。
bash
AREA cleancachebyway , CODE, READONLY ; Start of Area block
IF {CPU} = "ARM920T" :LOR: \
{CPU} = "ARM922T" :LOR: \
{CPU} = "ARM940T" :LOR: \
{CPU} = "ARM946E-S" :LOR: \
{CPU} = "ARM1022E"
EXPORT cleanDCache
EXPORT cleanFlushDCache
EXPORT cleanFlushCache
INCLUDE cache.h
c7f RN 0 ; cp15:c7 register format
MACRO
CACHECLEANBYWAY $op
MOV c7f, #0
; create c7 format 5
IF "$op" = "Dclean"
MCR p15, 0, c7f, c7, c10, 2 ; clean D-cline
ENDIF
IF "$op" = "Dcleanflush"
MCR p15, 0, c7f, c7, c14, 2 ; cleanflush D-cline
ENDIF
ADD c7f, c7f, #1 << I7SET ; +1 set index
TST c7f, #1 << (NSET+I7SET) ; test index overflow
BEQ
BIC c7f, c7f, #1 << (NSET+I7SET) ; clear index overflow
ADDS c7f, c7f, #1 << I7WAY ; +1 victim pointer
BCC %BT5
; test way overflow
MEND
cleanDCache
CACHECLEANBYWAY Dclean
MOV pc, lr
cleanFlushDCache
CACHECLEANBYWAY Dcleanflush
MOV pc, lr
cleanFlushCache
CACHECLEANBYWAY Dcleanflush
MCR p15,0,r0,c7,c5,0 ; flush I-cache
MOV pc, lr
ENDIF12.5.5 Cleaning the D-Cache Using the Test-Clean Command
ARM926EJ-S和ARM1026EJ-S这两个较新的ARM核心具有使用测试清除CP15:c7寄存器来清除缓存行的命令。测试清除命令是一种特殊的清除指令,当在软件循环中使用时,可以高效地清除缓存。ARM926EJ-S和ARM1026EJ-S还支持使用集和路索引进行清除;然而,使用测试清除命令方法清除D缓存更加高效。
我们在以下例程中使用表12.6中的命令来清除ARM926EJ-S和ARM1026EJ-S核心。示例12.4显示了ARM926EJ-S和ARM1026EJ-S处理器的cleanDCache、cleanFlushDCache和cleanFlushCache过程。

示例 12.4
测试清除命令会查找第一个脏缓存行,并将其内容转移到主存中进行清除。如果缓存内还存在其他脏缓存,则Z标志将为零。
bash
IF {CPU} = "ARM926EJ-S" :LOR: {CPU} = "ARM1026EJ-S"
EXPORT cleanDCache
EXPORT cleanFlushDCache
EXPORT cleanFlushCache
cleanDCache
MRC p15, 0, pc, c7, c10, 3 ; test/clean D-cline
BNE cleanDCache
MOV pc, lr
cleanFlushDCache
MRC p15, 0, pc, c7, c14, 3 ; test/cleanflush D-cline
BNE cleanFlushDCache
MOV pc, lr
cleanFlushCache
MRC p15, 0, pc, c7, c14, 3 ; test/cleanflush D-cline
BNE cleanFlushCache
MCR p15, 0, r0, c7, c5, 0 ; flush I-cache
MOV pc, lr
ENDIF为了清除缓存,创建一个使用测试清除命令的软件循环。通过测试Z标志并跳转回重复测试,处理器会循环执行测试,直到D缓存被清除为止。请注意,测试清除命令将程序计数器(r15)作为Rd寄存器输入传递给MCR指令。
12.5.6 Cleaning the D-Cache in Intel XScale SA-110 and Intel StrongARM Cores
英特尔XScale和英特尔StrongARM处理器使用第三种方法来清除其D缓存。英特尔XScale处理器具有一条命令,用于在不进行线填充的情况下分配D缓存中的一行。当处理器执行该命令时,它会设置有效位,并将目录项填充为Rd寄存器提供的缓存标签。当命令执行时,不会从主存传输数据。因此,缓存中的数据在被处理器写入之前是未初始化的。分配命令如表12.7所示,具有清除脏缓存行的有益功能。

英特尔StrongARM和英特尔XScale处理器需要额外的技术来清除其缓存。它们需要一个专门的未使用的缓存主存区域来清除缓存。通过软件设计,将内存块专门用于仅清除缓存。
英特尔StrongARM和英特尔XScale处理器可以通过读取这个固定的内存块来清除,因为它们使用循环置换策略。如果执行一个强制核心按顺序读取与缓存的主数据内存区域大小相等的区域的例程,那么一系列读取将淘汰所有当前的缓存行,并用来自专用刮擦读取区域的数据块替换它们。当读取序列完成时,缓存中将不包含重要数据,因为专用的读取区块中没有有用的信息。在这一点上,可以放心清除缓存而不会丢失有价值的缓存数据。
我们使用这种技术来清除英特尔StrongARM D缓存和英特尔XScale迷你D缓存。以下示例显示了清除英特尔XScale和英特尔StrongARM处理器的cleanDCache、cleanFlushDCache和cleanFlushCache过程。还提供了一个额外的过程,称为cleanMiniDCache,用于清除英特尔XScale处理器中的迷你D缓存。
此示例使用了两个宏,CPWAIT和CACHECLEANXSCALE。CPWAIT宏是在英特尔XScale处理器上使用的一个由三条指令组成的序列,用于确保CP15操作在没有副作用的情况下执行。该宏执行这些指令,以便足够的处理器周期已经完成,以确保CP15命令已完成并且流水线中没有指令。CPWAIT宏为:
bash
MACRO
CPWAIT
MRC p15, 0, r12, c2, c0, 0 ; read any CP15
MOV r12, r12
SUB pc, pc, #4 ; branch to next instruction
MEND宏CACHECLEANXSCALE创建了cleanDCache、cleanFlushDCache和cleanFlushCache这些过程。宏的第一部分设置了例程的物理参数。第一个参数adr是用于清除缓存的专用内存区域的起始虚拟内存地址。第二个参数nl是缓存中的总缓存行数。
bash
IF {CPU} = "XSCALE" :LOR: {CPU} = "SA-110"
EXPORT cleanDCache
EXPORT cleanFlushDCache
EXPORT cleanFlushCache
INCLUDE cache.h
CleanAddressDcache EQU 0x8000 ;(32K block 0x8000-0x10000)
CleanAddressMiniDcache EQU 0x10000 ;(2K block 0x10000-0x10800)
adr RN 0 ; start address
nl RN 1 ; number of cache lines to process
tmp RN 12 ; scratch register
MACRO
CACHECLEANXSCALE $op
IF "$op" = "Dclean"
LDR adr, =CleanAddressDcache
MOV nl, #(1 << (NWAY+NSET))
ENDIF
IF "$op" = "DcleanMini"
LDR adr, =CleanAddressMiniDcache
MOV nl, #(1 << (MNWAY+NSET))
ENDIF
5
IF {CPU} = "XSCALE" :LAND: "$op" = "Dclean"
MCR p15, 0, adr, c7, c2, 5 ; allocate d-cline
ADD adr, adr, #32
; +1 d-cline
ENDIF
IF {CPU} = "SA-110" :LOR: "$op"= "DcleanMini"
LDR tmp,[adr],#32 ; Load data, +1 d-cline
ENDIF
SUBS nl, nl, #1
; -1 loop count
BNE %BT5
IF {CPU} = "XSCALE"
CPWAIT
ENDIF
MEND
cleanDCache
CACHECLEANXSCALE Dclean
MOV pc, lr
cleanFlushDCache
STMFD sp!, {lr}
BL cleanDCache
IF {CPU} = "XSCALE"
BL cleanMiniDCache
ENDIF
MOV r0, #0
MCR p15,0,r0,c7,c6,0 ; flush D-cache
IF {CPU} = "XSCALE"
CPWAIT
ENDIF
LDMFD sp!, {pc}
cleanFlushCache
STMFD sp!, {lr}
BL cleanDCache
IF {CPU} = "XSCALE"
BL cleanMiniDCache
ENDIF
MOV r0, #0
MCR p15,0,r0,c7,c7,0 ; flush I-cache & D-cache
IF {CPU} = "XSCALE"
CPWAIT
ENDIF
LDMFD sp!, {pc}
ENDIF
IF {CPU} = "XSCALE"
EXPORT cleanMiniDCache
cleanMiniDCache
CACHECLEANXSCALE DcleanMini
MOV pc, lr
ENDIF然后,该宏根据需要过滤执行清除操作的命令,适用于两个处理器核心。英特尔XScale处理器使用分配CP15:c7命令来清除D缓存,并读取专用的缓存内存块来清除迷你D缓存。英特尔StrongARM处理器从专用的内存区域读取数据以清除其D缓存。
最后,我们多次使用该宏来创建cleanDCache、cleanFlushDCache、cleanFlushCache和cleanMiniDCache这几个过程。
12.5.7 Cleaning and Flushing Portions of a Cache
ARM核心支持根据主存中的位置引用来清除和刷新单个缓存行。我们将这些命令显示为表12.8中的MCR指令。其中两个命令用于刷新单个缓存行,一个用于刷新指令缓存,另一个用于刷新数据缓存。还有两个命令用于清除数据缓存:一个用于清除单个缓存行,另一个用于清除并刷新单个缓存行。

当使用这些指令时,同一处理器内四个命令的核心寄存器Rd的值是相同的,并且其内容必须是设置CP15:c7寄存器所需的值。然而,CP15:c7寄存器中位值的格式在不同的处理器之间略有不同。图12.12显示了支持通过修改的虚拟地址或物理地址来清除和刷新缓存行的核心的寄存器格式,如果核心具有MMU,则使用修改的虚拟地址,如果核心具有MPU,则使用物理地址。

我们使用这四个命令创建了六个例程,可以清除和/或刷新表示内存区域的缓存行:
-
flushICacheRegion 从I-cache中刷新表示主存区域的缓存行。
-
flushDCacheRegion 从D-cache中刷新表示主存区域的缓存行。
-
cleanDCacheRegion 从D-cache中清除表示主存区域的缓存行。
-
cleanFlushDcacheRegion 清除并刷新表示主存区域的D-cache中的缓存行。
-
flushCacheRegion 同时从I-cache和D-cache中刷新表示主存区域的缓存行。
-
cleanFlushCacheRegion 先清除并刷新D-cache,然后刷新I-cache。
所有这些过程都有两个参数,传递给它们的是主存的起始地址(adr)和区域大小(以字节为单位)(b)。C函数原型如下:
void flushICacheRegion(int *adr, unsigned int b);
void flushDCacheRegion(int *adr, unsigned int b);
void cleanDCacheRegion(int *adr, unsigned int b);
void cleanFlushDcacheRegion(int *adr, unsigned int b);
void flushCacheRegion(int *adr, unsigned int b);
void cleanFlushCacheRegion(int *adr, unsigned int b);
在使用清除缓存区域过程时需要注意。这些过程在小内存区域上的使用效果最好。如果区域的大小是缓存本身大小的数倍,可能更高效地使用提供在12.5.4、12.5.5和12.5.6节的清除缓存过程之一来清除整个缓存。
区域过程仅在一部分ARM核心上可用。图12.12列出了支持根据地址进行清除和刷新的核心。它们也在以下示例代码的开头列出。
示例12.6:
该宏接受输入地址并将其截断到缓存行边界。这种截断总是将地址指向ARM1022E中缓存行的第一个双字(参见图12.12)。然后,该宏接受大小参数,并将其从字节转换为缓存行数。宏使用缓存行数作为计数器变量,循环执行所选的刷新或清除操作,每次循环结束时将地址增加一个缓存行大小。当计数器达到零时退出循环。
bash
IF {CPU} = "ARM920T" :LOR: \
{CPU} = "ARM922T" :LOR: \
{CPU} = "ARM946E-S" :LOR: \
{CPU} = "ARM926EJ-S" :LOR: \
{CPU} = "ARM1022E" :LOR: \
{CPU} = "ARM1026EJ-S" :LOR: \
{CPU} = "XSCALE" :LOR: \
{CPU} = "SA-110"
INCLUDE cache.h
adr RN 0 ; active address
size RN 1 ; size of region in bytes
nl RN 1 ; number of cache lines to clean or flush
MACRO
CACHEBYREGION $op
BIC adr, adr, #(1 << CLINE)-1 ; clip 2 cline adr
MOV nl, size, lsr #CLINE ; bytes to cline
10
IF "$op" = "IcacheFlush"
MCR p15, 0, adr, c7, c5, 1 ; flush I-cline@adr
ENDIF
IF "$op" = "DcacheFlush"
MCR p15, 0, adr, c7, c6, 1 ; flush D-cline@adr
ENDIF
IF "$op" = "IDcacheFlush"
MCR p15, 0, adr, c7, c5, 1 ; flush I-cline@adr
MCR p15, 0, adr, c7, c6, 1 ; flush D-cline@adr
ENDIF
IF "$op" = "DcacheClean"
MCR p15, 0, adr, c7, c10, 1 ; clean D-cline@adr
ENDIF
IF "$op" = "DcacheCleanFlush"
IF {CPU} = "XSCALE" :LOR: \
{CPU} = "SA-110"
MCR p15, 0, adr, c7, c10, 1 ; clean D-cline@adr
MCR p15, 0, adr, c7, c6, 1 ; flush D-cline@adr
ELSE
MCR p15, 0, adr, c7, c14, 1 ; cleanflush D-cline@adr
ENDIF
ENDIF
IF "$op" = "IDcacheCleanFlush"
IF {CPU} = "ARM920T" :LOR: \
{CPU} = "ARM922T" :LOR: \
{CPU} = "ARM946E-S" :LOR: \
{CPU} = "ARM926EJ-S" :LOR: \
{CPU} = "ARM1022E" :LOR: \
{CPU} = "ARM1026EJ-S"
MCR p15, 0, adr, c7, c14, 1 ;cleanflush D-cline@adr
MCR p15, 0, adr, c7, c5, 1 ; flush I-cline@adr
ENDIF
IF {CPU} = "XSCALE"
MCR p15, 0, adr, c7, c10, 1 ; clean D-cline@adr
MCR p15, 0, adr, c7, c6, 1 ; flush D-cline@adr
MCR p15, 0, adr, c7, c5, 1 ; flush I-cline@adr
ENDIF
ENDIF
ADD adr, adr, #1 << CLINE
; +1 next cline adr
SUBS nl, nl, #1
; -1 cline counter
BNE %BT10
; flush # lines +1
IF {CPU} = "XSCALE"
CPWAIT
ENDIF
MOV pc, lr
MEND
IF {CPU} = "SA-110"
EXPORT cleanDCacheRegion
EXPORT flushDCacheRegion
EXPORT cleanFlushDCacheRegion
cleanDCacheRegion
CACHEBYREGION DcacheClean
flushDCacheRegion
CACHEBYREGION DcacheFlush
cleanFlushDCacheRegion
CACHEBYREGION DcacheCleanFlush
ELSE
EXPORT flushICacheRegion
EXPORT flushDCacheRegion
EXPORT flushCacheRegion
EXPORT cleanDCacheRegion
EXPORT cleanFlushDCacheRegion
EXPORT cleanFlushCacheRegion
flushICacheRegion
CACHEBYREGION IcacheFlush
flushDCacheRegion
CACHEBYREGION DcacheFlush
flushCacheRegion
CACHEBYREGION IDcacheFlush
cleanDCacheRegion
CACHEBYREGION DcacheClean
cleanFlushDCacheRegion
CACHEBYREGION DcacheCleanFlush
cleanFlushCacheRegion
CACHEBYREGION IDcacheCleanFlush
ENDIF
ENDIF最后,使用CACHEBYREGION宏,如果内核是仅具有有限命令集的英特尔StrongARM,则创建三个过程;否则对于具有分裂缓存的其余处理器,创建全部六个过程。
12.6 Cache Lockdown
//缓存锁定
缓存锁定是一种功能,可以使程序将时间关键的代码和数据加载到缓存内存中,并标记为不受移除影响。锁定的代码或数据提供更快的系统响应,因为它们保存在缓存内存中。缓存锁定避免了缓存行驱逐过程所造成的执行时间不可预测的问题,这是缓存操作的正常部分。
将信息锁定在缓存中的目的是避免缓存失效的惩罚。但是,由于用于锁定的任何缓存内存都不可用于缓存主存的其他部分,因此有用的缓存大小会减少。
ARM内核为锁定分配了固定的缓存单元。ARM内核在锁定中分配的单元大小是一种方法。例如,一个四路组相联的缓存允许以1/4缓存大小的单元锁定代码或数据。缓存内核始终至少保留一条路用于正常的缓存操作。
一些指令可以作为锁定缓存的候选项,例如向量中断表、中断服务例程或系统广泛使用的关键算法的代码。在数据方面,频繁使用的全局变量是锁定的好候选。
在ARM缓存核心中锁定的数据或代码不会被替换。但是,当清除缓存时,锁定中的信息将丢失,该区域仍然不可用作缓存内存。必须重新运行缓存锁定例程以恢复锁定信息。
//解释下向量中断表:
向量中断表(Vector Interrupt Table)是用于处理中断和异常的数据结构。在某些体系结构(如ARM架构),向量中断表是一个预定义的表,其中每个条目对应于一个特定的中断或异常类型。
当发生中断或异常时,处理器会根据其类型查找相应的向量中断表条目,并跳转到对应的处理程序。每个向量中断表条目通常包含一个指向处理程序的地址,以及其他与中断或异常相关的信息。
向量中断表的设计使得处理器可以高效地识别和处理不同类型的中断和异常。通过将处理程序地址存储在表中,可以实现快速的中断响应和异常处理。
向量中断表的内容和结构可能因处理器架构而异,需要参考具体的处理器文档以了解其详细信息。
12.6.1 Locking Code and Data in Cache
本节介绍了一种在缓存中锁定代码和数据的操作过程。锁定代码和数据在缓存中的典型C调用序列如下所示:
bash
int interrupt_state; /* saves the state of the FIQ and IRQ bits */
int globalData[16];
unsigned int *vectortable = (unsigned int *)0x0;
int wayIndex;
int vectorCodeSize = 212; /* vector table & FIQ handler in bytes*/
interrupt_state = disable_interrupts(); /* no code provided */
enableCache();
/* see Chapters 13(MPU) and 14(MMU) */
flushCache();
/* see code Example 12.2 */
/* Lock Global Data Block */
wayIndex = lockDcache((globalData, sizeof globalData);
/* Lock Vector table and FIQ Handler */
wayIndex = lockIcache((vectortable, vectorCodeSize);}
enable_interrupts(interrupt_state); /* no code provided */首先,禁用中断并启用缓存。禁用中断的过程未显示。flushCache过程是从先前示例中选择的一个;实际使用的调用取决于缓存配置,并且可能还包括清除缓存。
函数lockDCache在D-cache中锁定数据块;类似地,函数lockIcache在I-cache中锁定代码块。
锁定软件程序本身必须位于非缓存的主存储器中。在缓存中锁定的代码和数据必须位于缓存的主存储器中。重要的是,在缓存中锁定的代码和数据在其他地方不存在;换句话说,如果缓存的内容未知,则在加载之前清除缓存。如果核心使用的是写回式D-cache,则清除D-cache。一旦代码和数据加载到缓存中,重新启用中断。
我们为两个函数lockDCache和lockIcache提供了三种不同的代码,因为有三种不同的锁定方法用于在缓存中锁定代码,具体取决于架构实现。第一种方法使用路址寻址技术在缓存中锁定代码和数据。第二种方法使用一组锁定位。在第三种方法中,代码和数据使用特殊分配命令和读取专用主存储器块的组合在缓存中锁定。
表12.9列出了实现两个lockDCache和lockIcache过程的三个示例,使用的方法以及相关处理器。

12.6.2 Locking a Cache by Incrementing the Way Index
ARM920T、ARM926EJ-S、ARM940T、ARM946E-S、ARM1022E和ARM1026EJ-S使用路址寻址和集合索引寻址进行锁定。两个CP15:c9:c0寄存器包含第12.3.2节中描述的受害者计数器重置寄存器。其中一个寄存器控制I-cache,而另一个寄存器控制D-cache。这些寄存器用于选择缓存行内的方式以锁定代码或数据。
写入CP15:c7寄存器的值设置受害者重置值-当它在核心中增加超过方式数时受害者计数器重置为该值。复位值在上电时为零,并且仅在某些部分的缓存用于锁定时,由软件更改。当一部分缓存用于锁定时,用于缓存信息的缓存行数减少了锁定的缓存行数。读取寄存器返回当前的受害者重置值。表12.10显示了读取和写入两个寄存器的MRC和MCR指令。

在读取或写入锁定基地址时,MCR和MRC指令中使用的核心寄存器Rd的格式在不同处理器之间略有不同。每个使用这些指令的处理器的处理器核心Rd寄存器的格式如图12.13所示。为了确保命令正确执行,请确保Rd寄存器的格式与图中所示的匹配。

还需要一条特殊的加载指令来将指令锁定在缓存中。这条特殊的加载指令将主存中一个与缓存行大小相同的块复制到I-cache中的一个缓存行中。命令和指令中使用的Rd寄存器的格式如表12.11和图12.14所示。


以下示例显示了支持增加方式寻址锁定的处理器的lockDCache和lockICache例程。这两个例程的返回值是下一个可用的受害者指针基地址。
示例12.7
例程的第一部分定义了在宏CACHELOCKBYWAY中使用的寄存器。该宏还使用了头文件cache.h中的常量,如图12.10所示。
宏的第一行将地址(adr)对齐到缓存行。接下来的三行使用代码大小(以字节为单位)来确定需要多少个方式才能容纳该代码。然后从CP15:c9:c0中读取I-cache或D-cache当前的受害者指针。
接下来的几行进行一些错误检查,以测试是否溢出缓存以及要加载的代码大小是否为零。
要在ARM940T或ARM946E-S的缓存中锁定代码或数据,必须在锁定一个缓存行中的内存块之前设置锁定位。下一条指令设置该位并将数据写回到CP15:c9:c0。
此时,代码进入一个嵌套循环,外部循环选择方式,内部循环增加方式内的缓存行。
在两个循环的中心,使用预取指令或加载数据命令来将缓存行锁定到缓存中。为了锁定指令,宏将数据写入一个特殊的CP15:c7:c13寄存器,该寄存器从主存中预加载代码段。要锁定数据,只需使用LDR指令读取数据即可。
如果是ARM940T或ARM946E-S,则宏通过清除CP15:c9:c0寄存器中的锁定位退出。对于所有核心,它将受害者指针设置为锁定的代码或数据后下一个可用的方式。
bash
IF {CPU} = "ARM920T" :LOR: \
{CPU} = "ARM922T" :LOR: \
{CPU} = "ARM940T" :LOR: \
{CPU} = "ARM946E-S" :LOR: \
{CPU} = "ARM1022E"
EXPORT lockDCache
EXPORT lockICache
INCLUDE cache.h
adr RN 0 ; current address of code or data
size RN 1 ; memory size in bytes
nw RN 1 ; memory size in ways
count RN 2
tmp RN 2 ; scratch register
tmp1 RN 3 ; scratch register
c9f RN 12 ; CP15:c9 register format
MACRO
CACHELOCKBYWAY $op
BIC adr, adr, #(1 << CLINE)-1 ; align to cline
LDR tmp, =(1 << SWAY)-1 ; scratch = size of way
TST size, tmp
; way end fragment ?
MOV nw, size, lsr #SWAY ; convert bytes to ways
ADDNE nw, nw, #1
; add way if fragment
CMP nw, #0
; no lockdown requested
BEQ %FT2
; exit return victim base
IF "$op" = "Icache"
MRC p15, 0, c9f, c9, c0, 1 ; get i-cache victim
ENDIF
IF "$op" = "Dcache"
MRC p15, 0, c9f, c9, c0, 0 ; get d-cache victim
ENDIF
AND c9f, c9f, tmp ; mask high bits c9f = victim
ADD tmp, c9f, nw ; temp = victim + way count
CMP tmp, #(1 << NWAY)-1 ; > total ways ?
MOVGT r0, #-1
; return -1 if to many ways
BGT %FT1
; Error: cache way overrun
IF {CPU} = "ARM940T" :LOR: {CPU} = "ARM946E-S"
ORR c9f, c9f, #1 << 31 ; put cache in lockdown mode
ENDIF
10
IF "$op" = "Icache"
MCR p15, 0, c9f, c9, c0, 1 ; set victim
ENDIF
IF "$op" = "Dcache"
MCR p15, 0, c9f, c9, c0, 0 ; set victim
ENDIF
MOV count, #(1 << NSET)-1
5
IF "$op" = "Icache"
MCR p15, 0, adr, c7, c13, 1 ; load code cacheline
ADD adr, adr, #1 << CLINE ; cline addr =+ 1
ENDIF
IF "$op" = "Dcache"
LDR tmp1, [adr], #1 << CLINE ; load data cacheline
ENDIF
SUBS count, count, #1
BNE %BT5
ADD c9f, c9f, #1 << I9WAY ; victim pointer =+ 1
SUBS nw, nw, #1
; way counter =- 1
BNE %BT10
; repeat for # of ways
2
IF {CPU} = "ARM940T" :LOR: {CPU} = "ARM946E-S"
BIC r0, c9f, #1 << 31 ; clear lock bit & r0=victim
ENDIF
IF "$op" = "Icache"
MCR p15, 0, r0, c9, c0, 1 ; set victim counter
ENDIF
IF "$op" = "Dcache"
MCR p15, 0, r0, c9, c0, 0 ; set victim counter
ENDIF
1
MOV pc, lr
MEND
lockDCache
CACHELOCKBYWAY Dcache
lockICache
CACHELOCKBYWAY Icache
ENDIF最后,该宏被使用两次来创建lockDCache和lockICache函数。
12.6.3 Locking a Cache Using Lock Bits
ARM926EJ-S和ARM1026EJ-S使用一组锁定位在缓存中锁定代码和数据,如图12.15所示。这两个处理器对于CP15:c9指令有不同的Rd格式,如表12.12所示。从零到三的四个位分别表示这两个处理器中四路组相联缓存中的每一路。如果该位被设置,表示该路已经被锁定,并且如果是I-cache则包含代码,如果是D-cache则包含数据。锁定的路不会替换缓存行,直到它被解锁。清除其中一个L位将解锁相应的路。这种方式的缓存锁定允许系统代码单独选择要锁定或解锁的路。

能够单独选择要锁定的路使得系统中的代码更容易被锁定和解锁。本节中的示例代码实现了一个具有相同编程接口的过程,用于在其他具有缓存的核心中锁定数据。
针对ARM926EJ-S和ARM1026EJ-S处理器的示例lockDCache和lockICache过程具有相同的输入参数。然而,代码大小限制为最大路大小,并且可以被调用多达三次。在示例中,L位3总是专门用于缓存。这不是处理器硬件的限制,而只是为了满足编程接口的需求而对过程调用进行限制。
示例过程如果大小参数为一个字节或更大,则返回被锁定的路的L位。如果大小为零,则返回下一个可用的L位,如果没有可用的方式进行锁定,则返回8。
示例12.8 代码中使用了一个名为CACHELOCKBYLBIT的宏来生成lockDCache和lockICache函数。该宏还使用了头文件cache.h中的常量,如图12.10所示。
该宏首先检查要在缓存中锁定的字节数是否为零。然后将地址adr对齐到缓存行,并确定包含代码所需的缓存行数。
如果过程正在锁定D-cache中的数据,则读取锁定寄存器CP15:c9:c0:0。如果过程正在锁定I-cache中的代码,则读取锁定寄存器CP15:c9:c0:1。结果值放置在核心c9f寄存器中。L位也存储在tmp寄存器中以供后续使用。
bash
IF {CPU} = "ARM926EJ-S" :LOR: \
{CPU} = "ARM1026EJ-S"
EXPORT lockDCache
EXPORT lockICache
EXPORT bittest
INCLUDE cache.h
adr RN 0 ; current address of code or data
size RN 1 ; memory size in bytes
tmp RN 2 ; scratch register
tmp1 RN 3 ; scratch register
c9f RN 12 ; CP15:c9 register format
MACRO
CACHELOCKBYLBIT $op
ADD size, adr, size ; size = end address
BIC adr, adr, #(1 << CLINE)-1 ; align to CLINE
MOV tmp, #(1 << CLINE)-1 ; scratch CLINE mask
TST size, tmp
; CLINE end fragment ?
SUB size, size, adr ; add alignment bytes
MOV size, size, lsr #CLINE ; convert size 2 # CLINE
ADDNE size, size, #1
; add CLINE for fragment
CMP size, #(1 << NSET)-1 ; size to large ?
BHI %FT1
; exit return victim base
IF "$op" = "Icache"
MRC p15, 0, c9f, c9, c0, 1 ; get i-cache lock bits
ENDIF
IF "$op" = "Dcache"
MRC p15, 0, c9f, c9, c0, 0 ; get d-cache lock bits
ENDIF
AND tmp, c9f, #0xf ; tmp = state of Lbits
MOV tmp1, #1
TST c9f, tmp1
; test lock bit 0
MOVNE tmp1, tmp1, LSL #1
TSTNE c9f, tmp1
; test lock bit 1
MOVNE tmp1, tmp1, LSL #1
TSTNE c9f, tmp1
; test lock bit 2
MOVNE tmp1, tmp1, LSL #1
BNE %FT1
; ERROR: no available ways
CMP size, #0
; no lockdown requested
BEQ %FT1
; exit return size =0
MVN tmp1, tmp1
; select L bit
AND tmp1, tmp1, #0xf ; mask off non L bits
BIC c9f, c9f, #0xf ; construct c9f
ADD c9f, c9f, tmp1
IF "$op" = "Icache"
MCR p15, 0, c9f, c9, c0, 1 ; set lock I page
ENDIF
IF "$op" = "Dcache"
MCR p15, 0, c9f, c9, c0, 0 ; set lock D page
ENDIF
5
IF "$op" = "Icache"
MCR p15, 0, adr, c7, c13, 1 ; load code cacheline
ADD adr, adr, #1 << CLINE ; cline addr =+ 1
ENDIF
IF "$op" = "Dcache"
LDR tmp1, [adr], #1 << CLINE ; load data cacheline
ENDIF
SUBS size, size, #1 ; cline =- 1
BNE %BT5
; loop thru clines
MVN tmp1, c9f
; lock selected L-bit
AND tmp1, tmp1, #0xf ; mask off non L-bits
ORR tmp, tmp, tmp1 ; merge with orig L-bits
BIC c9f, c9f, #0xf ; clear all L-bits
ADD c9f, c9f, tmp ; set L-bits in c9f
IF "$op" = "Icache"
MCR p15, 0, adr, c9, c0, 1 ; set i-cache lock bits
ENDIF
IF "$op" = "Dcache"
MCR p15, 0, adr, c9, c0, 0 ; set d-cache lock bits
ENDIF
1
MOV r0, tmp1
; return allocated way
MOV pc, lr
MEND
lockDCache
CACHELOCKBYLBIT Dcache
lockICache
CACHELOCKBYLBIT Icache
ENDIF接下来的七行代码检查 c9f 寄存器,以确定是否有可用的方式来存储代码或数据;如果没有,则退出该例程。如果有可用的方式,则在接下来的四行代码中修改 c9f 格式以选择要锁定数据的方式。然后,c9f 寄存器在 MCR 指令中被使用来选择要锁定的方式。
此时,代码进入一个循环,用锁定的代码或数据填充缓存。如果过程正在锁定 I-cache 中的代码,它执行预取 I-cache 行命令。如果从外部存储器中锁定数据,则清除、刷新并加载一个新的缓存行到 D-cache 中。
宏通过将保存的 L 位与新锁定的页面合并,并使用结果创建一个新的 c9f 寄存器来退出。宏使用 c9f 寄存器在 MCR 指令中设置 CP15:c9:c0 缓存锁定寄存器中的 L 位。
最后,CACHELOCKBYLBIT 宏被使用两次来创建 lockDCache 和 lockICache 函数。
12.6.4 Locking Cache Lines in the Intel XScale SA-110
英特尔 XScale 处理器也具有将代码和数据锁定到缓存中的能力。这种方法需要使用一组 CP15:c9 缓存锁定命令,如表 12.13 所示。CP15:c9:c2 寄存器的格式如图 12.16 所示。它还需要我们在例子 12.5 中使用的 CP15:c7 分配 D-cache 行命令;该命令如表 12.7 所示。

在英特尔 XScale 处理器中,每个缓存集合都有一个专用的轮询指针,每当缓存中增加一个额外的缓存行时,它都会按顺序递增。在一个集合内最多可以锁定 28 个缓存行。尝试在一个集合中锁定超过 28 个缓存行将导致该行被分配但不会被锁定在缓存中。
英特尔 XScale 处理器支持两种在 D-cache 中锁定数据的使用方式。第一种使用方式只是将主存位置锁定到 D-cache 中。在第二种使用方式中,使用分配高速缓存行命令将一部分高速缓存配置为数据 RAM;在这种情况下,分配的高速缓存部分未初始化并需要来自处理器核心的写入以包含有效数据。在我们的示例中,我们将内存初始化为零。
示例 12.9 的第一部分定义了宏 CACHELOCKREGION 中使用的寄存器。该宏还使用了头文件 cache.h 中显示的常量,如图 12.10 所示。
该宏首先将地址(adr)对齐到一个缓存行,并确定包含代码所需的缓存行数。如果过程正在锁定 D-cache 中的数据,则接下来几行会清空写缓冲区并解锁 D-cache。在 D-cache 中锁定数据需要发出一个解锁命令,该命令必须在锁定 D-cache 行之前发出。该宏通过向 CP15:c9:c2:0 寄存器写入 1 来设置此位。
此时,代码进入一个循环,用锁定的代码或数据填充缓存。如果过程正在锁定 I-cache 中的代码,它执行锁定 I-cache 行命令。如果它正在从外部存储器中锁定数据,则清空、刷新并加载一个新的缓存行到 D-cache 中。如果创建数据 RAM,则分配一个 D-cache 行并清空写缓冲区,以防止尝试锁定超过 28 个集合而导致错误。然后,使用 STRD 指令将缓存行初始化为零。
该宏通过在加载缓存时清除缓存锁定 CP15 寄存器上的锁定位,如果它正在锁定 D-cache 数据,则退出。
bash
IF {CPU} = "XSCALE"
EXPORT lockICache
EXPORT lockDCache
EXPORT lockDCacheRAM
INCLUDE cache.h
adr RN 0 ; current address of code or data
size RN 1 ; memory size in bytes
tmp RN 2 ; cpc15:c9 31 (load 5:0 victim pointer)
tmp1 RN 3 ; scratch register for LDR instruction
MACRO
CACHELOCKREGION $op
ADD size, adr, size ; size = end address
BIC adr, adr, #(1 << CLINE)-1 ; align to CLINE
MOV tmp, #(1 << CLINE)-1 ; scratch CLINE mask
TST size, tmp
; CLINE end fragment ?
SUB size, size, adr ; add alignment bytes
MOV size, size, lsr #CLINE ; convert size 2 # CLINE
ADDNE size, size, #1
; add CLINE to hold fragment
CMP size, #0
; no lockdown requested
BEQ %FT1
; exit return size =0
IF "$op" = "Dcache" :LOR: "$op" = "DcacheRAM"
MCR p15, 0, adr, c7, c10, 4 ; drain write buffer
MOV tmp, #1
MCR p15, 0, tmp, c9, c2, 0 ; unlock data cache
CPWAIT
MOV tmp, #0
; even words to zero
ENDIF
IF "$op" = "DcacheRAM"
MOV tmp1, #0 ; init odd words to zero
ENDIF
5
IF "$op" = "Icache"
MCR p15, 0, adr, c9, c1, 0; lock ICache line
ADD adr, adr, #1 << CLINE
ENDIF
IF "$op" = "Dcache"
MCR p15, 0, adr, c7, c10, 1 ; clean dirty line
MCR p15, 0, adr, c7, c6, 1 ; Flush d-cache line
LDR tmp, [adr], #1 << CLINE ; load data cache line
ENDIF
IF "$op" = "DcacheRAM"
MCR p15, 0, adr, c7, c2, 5 ; Allocate d-cache line
MCR p15, 0, adr, c7, c10, 4 ; drain write buffer
STRD tmp, [adr], #8 ; init 2 zero & adr=+2
STRD tmp, [adr], #8 ; init 2 zero & adr=+2
STRD tmp, [adr], #8 ; init 2 zero & adr=+2
STRD tmp, [adr], #8 ; init 2 zero & adr=+2
ENDIF
SUBS size, size, #1
BNE %BT5
IF "$op" = "Dcache" :LOR: "$op" = "DcacheRAM"
MCR p15, 0, adr, c7, c10, 4 ; drain write buffer
MCR p15, 0, tmp, c9, c2, 0 ; lock data cache
CPWAIT
ENDIF
1
MOV r0, #0
MOV pc, lr
MEND
lockICache
CACHELOCKREGION Icache
lockDCache
CACHELOCKREGION Dcache
lockDCacheRAM
CACHELOCKREGION DcacheRAM
ENDIF最后,该宏被使用三次来创建 lockICache、lockDCache 和 lockDCacheRAM 函数。
12.7 Caches and Software Performance
这里有一些简单的规则,可以帮助编写充分利用缓存架构的代码:
-
大多数内存系统的区域都配置为同时启用缓存和写缓冲区,以最大程度地利用缓存架构来减少平均内存访问时间。关于区域和缓存以及写缓冲区在其中操作的更多信息,如果您正在使用带有内存保护单元的ARM处理器核心,请参考第13章;如果您正在使用带有内存管理单元的ARM处理器核心,请参考第14章。
-
内存映射的外设如果它们配置为使用缓存或写缓冲区通常是失败的。最好将它们配置为非缓存和非缓冲的内存,这会强制处理器在每次内存访问时都读取外设设备,而不是使用缓存中可能过期的数据。
-
尽量将频繁访问的数据连续地放置在内存中,记住从主存中获取新数据值的成本需要填充一个缓存行。如果缓存行中的数据在被替换之前只使用一次,性能会很差。将数据放置在相同的缓存行中,可以通过紧密地打包数据来有效地增加缓存命中率,以利用空间局部性。最重要的是将常用例程访问的数据保持在主存中靠近一起。
-
尽量组织数据,使读取、处理和写入以缓存行大小的块为单位操作,其主存较低地址与缓存行的起始地址相匹配。最好的一般方法是保持代码例程的规模小,并将相关数据紧密放置在一起。代码越小,它更有可能具有良好的缓存效率。
-
使用链表在使用缓存时可能会降低程序性能,因为在链表中进行搜索会导致大量的缓存未命中。当从链表访问数据时,程序以比从顺序数组访问数据时更随机的方式获取数据。这个提示实际上适用于搜索任何无序列表。选择搜索数据的方式可能需要对系统进行性能分析。
然而,重要的是记住,系统性能受到其他因素的影响远大于编写高效利用缓存的代码。请参考第5章和第6章了解高效的编程技术。
12.8 Summary
缓存是位于处理器和主内存之间的一块小而快速的存储器阵列。它是一个暂存缓冲区,用于存储最近访问的系统内存的部分内容。处理器尽可能使用缓存内存,而不是系统内存,以提高平均系统性能。
写缓冲区是位于处理器核心和主内存之间的一个非常小的先进先出(FIFO)存储器,有助于将处理器核心和缓存内存从写入主内存所需的慢速写入时间中释放出来。
引用局部性原理指出计算机软件程序经常运行一些小的代码循环,这些代码循环在数据内存的局部区域上重复操作,并解释了为什么使用带有缓存的处理器核心可以显著提高平均系统性能。
ARM社区使用许多术语来描述缓存架构的特性。为了方便起见,我们创建了表12.14,列出了所有当前ARM缓存核心的特性。

缓存行是缓存中的一个基本组件,包含三个部分:目录存储、数据部分和状态信息。缓存标记是指示缓存行从主内存加载的目录条目。缓存中有两个常见的状态位:有效位和脏位。当相关的缓存行包含活动内存时,设置有效位。当缓存使用写回策略并且新数据被写入缓存内存时,脏位激活。
将缓存放置在MMU之前或之后可以是物理的或逻辑的。逻辑缓存放置在处理器核心和MMU之间,在虚拟地址空间中引用代码和数据。物理缓存放置在MMU和主内存之间,使用物理地址引用代码和数据存储器。
直接映射缓存是一种非常简单的缓存架构,其中缓存中的给定主存位置只有一个位置。直接映射缓存容易受到抖动的影响。为了减少抖动,缓存被划分为较小的等单位,称为路(ways)。使用路提供了单个主内存地址的多个存储位置。这些缓存被称为组相联缓存。
核总线架构有助于确定缓存系统的设计。冯·诺伊曼架构使用统一缓存存储代码和数据。哈佛架构使用分割缓存:它有一个用于指令的缓存和一个用于数据的独立缓存。
缓存替换策略决定在缓存未命中时选择哪个缓存行进行替换。配置的策略定义了缓存控制器用于从可用的缓存内存集中选择一个缓存行的算法。被选择用于替换的缓存行被称为牺牲者。ARM缓存核心中提供的两种替换策略是伪随机和循环。
在写入数据到缓存内存时有两种可用的策略。如果控制器只更新缓存内存,则采用写回策略。如果缓存控制器同时写入缓存和主内存,则采用写透策略。
缓存控制器在缓存未命中时使用两种策略来分配缓存行。读分配策略在从主内存读取数据时分配一个缓存行。写分配策略在向主内存写入数据时分配一个缓存行。
ARM将clean一词用于指强制将Data缓存中的数据拷贝回主内存。ARM将flush一词是指使缓存的内容无效。
缓存锁定是一些ARM核心提供的功能。锁定功能允许代码和数据加载到缓存并标记为免受驱逐的。
我们还提供了示例代码,演示了如何清除和刷新ARM缓存核心以及如何在缓存中锁定代码和数据。
Chapter13 Memory Protection Units
一些嵌入式系统使用多任务操作系统或控制系统,并必须确保运行中的任务不会干扰其他任务的操作。系统资源和其他任务免受未经授权访问的保护称为保护,并是本章的主题。
控制对系统资源的访问有两种方法,即不受保护和受保护。不受保护的系统完全依赖软件来保护系统资源。受保护的系统依赖硬件和软件来保护系统资源。控制系统使用的方法选择取决于处理器的能力和控制系统的要求。
不受保护的嵌入式系统在操作过程中没有专门用于执行内存和外设设备使用规则的硬件。在这些系统中,每个任务在访问系统资源时都必须与所有其他任务合作,因为任何一个任务都可能破坏另一个任务的状态。当一个任务无视另一个任务的环境访问限制时,这种合作方案可能导致任务失败。
在不受保护的系统中可能发生任务失败的一个例子是读写串口寄存器进行通信。如果一个任务正在使用该端口,就没有办法阻止另一个任务使用同一个端口。通过系统调用进行协调以提供对端口的访问是成功使用端口的关键。绕过这些调用的任务的未经授权访问可以轻易地干扰通过端口进行的通信。对资源的不良使用可能是无意的,也可能是敌对的。
相比之下,受保护的系统具有专用的硬件来检查和限制对系统资源的访问。它可以强制执行资源所有权。任务必须按照操作环境定义的一组规则行事,并由硬件强制执行,该硬件为在硬件级别监控和控制资源的程序授予特殊权限。受保护的系统能够积极防止一个任务使用另一个任务的资源。与合作实现的软件例程相比,通过硬件主动监视系统提供更好的保护。
ARM提供了几种配备硬件保护系统资源的处理器,通过内存保护单元(MPU)或内存管理单元(MMU)来实现。本章将介绍一款配备MPU的处理器核心,它在多个软件指定的区域上提供硬件保护。下一章将介绍配备MMU的处理器核心,它提供了硬件保护并增加了虚拟内存功能。
在受保护的系统中,需要监控的两个主要资源类别是内存系统和外围设备。由于ARM外围设备通常是内存映射的,MPU使用相同的方法来保护这两种资源。
ARM MPU使用区域来管理系统保护。区域是与内存区域相关联的一组属性。处理器核心将这些属性保存在多个CP15寄存器中,并通过编号来标识每个区域,编号范围在0到7之间。
配置区域的内存边界使用两个属性:起始地址和长度,长度可以是4 KB到4 GB之间的任意二的幂。此外,操作系统为这些区域分配了额外的属性:访问权限以及缓存和写缓冲区策略。对于内存中的区域访问权限设置为读写、只读或禁止访问,并根据当前处理器模式(特权或用户)获得附加权限。区域还具有缓存写策略,用于控制缓存和写缓冲区属性。例如,一个区域可以设置为使用写穿策略访问内存,而另一个区域则作为非缓存和非缓冲区运行。
当处理器访问主存中的区域时,MPU将区域的访问权限属性与当前处理器模式进行比较,以确定采取的操作。如果请求满足区域访问条件,则允许核心读取或写入主存。然而,如果内存请求导致内存访问违规,MPU将生成中止信号。
中止信号被路由到处理器核心,在接收到中止信号后,处理器核心通过处理中止向量异常。然后,中止处理程序确定中止类型,是预取中止还是数据中止,并根据中止类型跳转到适当的服务例程。
要实现一个受保护的系统,控制系统在主存中定义了几个区域。区域可以一次创建并持续存在于嵌入式系统的整个生命周期中,也可以临时创建以满足特定操作的需求,然后移除。如何分配和创建区域是下一节的主题。
13.1 Protected Regions
目前有四个ARM核心包含MPU,它们是ARM740T、ARM940T、ARM946E-S和ARM1026EJ-S。ARM740T、ARM946E-S和ARM1026EJ-S每个核心都包含8个保护区域;ARM940T包含16个(见表13.1)。ARM740T、ARM946E-S和ARM1026EJ-S具有统一的指令和数据区域,使用相同的寄存器来定义数据区域和指令区域的大小和起始地址。在ARM946E-S和ARM1026EJ-S核心中,内存访问权限和缓存策略可以独立配置用于指令和数据访问;在ARM740T中,相同的访问权限和缓存策略被分配给了指令和数据内存。区域与核心是否具有冯·诺依曼体系结构或哈佛体系结构无关。每个区域由0到7之间的标识号引用。

由于ARM940T具有分开控制指令和数据内存的区域,核心可以为指令和数据区域维护不同的大小和起始地址。指令和数据区域的分离导致了这个具有缓存的核心中的8个额外区域。尽管ARM940T中的标识区域号仍然从0到7,但每个区域号都有一对区域,一个数据区域和一个指令区域。
有几个规则来管理区域:
-
区域可以与其他区域重叠。
-
区域被分配了独立于区域权限的优先级号码。
-
当区域重叠时,具有最高优先级号码的区域属性优先于其他区域。优先级仅适用于重叠区域内的地址。
-
区域的起始地址必须是其大小的倍数。
-
区域的大小可以是4 KB到4 GB之间的任何二的幂次数,即以下任一值:4 KB、8 KB、16 KB、32 KB、64 KB,...,2 GB、4 GB。
-
访问一个未定义区域范围的主存将导致中止。如果核心正在获取指令,则MPU生成预取中止;如果内存请求是针对数据的,则生成数据中止。
13.1.1 Overlapping Regions
当一个区域被分配的内存空间的一部分与另一个区域被分配的内存空间重叠时,就会出现重叠区域。重叠区域比非重叠区域在分配访问权限时提供了更大的灵活性。
例如,假设一个小型嵌入式系统具有256 KB的可用内存,起始地址为0x00000000,并且必须保护一个特权系统区域免受用户模式的读写。特权区域的代码、数据和堆栈占用32 KB的区域,从0x00000000开始,包括向量表。剩余的内存分配给用户空间。
使用重叠区域,系统使用两个区域,一个是256 KB的用户区域,另一个是32 KB的特权区域(参见图13.1)。特权区域1被赋予更高的编号,因为它的属性必须优先于用户区域0。

//创建重叠的区域
13.1.2 Background Regions
重叠区域提供的另一个有用功能是背景区域(background region)- 一个低优先级的区域,用于为一个大内存区域分配相同的属性。然后,其他优先级较高的区域被放置在这个背景区域上,以更改定义的背景区域的一个较小子集的属性。因此,较高优先级的区域正在更改背景区域的一个子集的属性。背景区域可以将几个休眠的内存区域屏蔽起来,防止未经授权的访问,同时背景区域的另一部分在受不同区域控制下活动。
例如,如果一个嵌入式系统定义了一个较大的特权背景区域,它可以在这个背景上放置一个较小的非特权区域。较小区域的位置可以在背景区域的不同区域移动,以显示不同的用户空间。当系统将较小的用户区域从一个位置移动到另一个位置时,先前被覆盖的区域将由背景区域保护。因此,用户区域充当窗口,允许访问特权背景的不同部分,但具有用户级别的属性(见图13.2)。

图13.2显示了一个简单的三任务保护方案。区域3定义了活动任务的保护属性,背景区域0在其他任务休眠时控制对它们的访问。当任务1正在运行时,背景区域保护任务2和任务3免受任务1的影响。当任务2正在运行时,任务1和任务3受到保护。最后,当任务3正在运行时,任务1和任务2受到保护。这种工作的原因是区域3的优先级高于区域0,即使区域0具有较高的特权。
在本章末尾的示例代码中,我们使用了一个背景区域来演示一个简单的多任务保护方案。
13.2 Initializing the MPU, Caches, and Write Buffer
为了初始化MPU(Memory Protection Unit,内存保护单元)、缓存和写缓冲区,控制系统必须在目标操作期间定义所需的保护区域。
至少,在启用保护单元之前,控制系统必须定义至少一个数据区域和一个指令区域。保护单元必须在启用缓存和写缓冲区之前或同时启用。
控制系统通过设置主要CP15寄存器C1、C2、C3、C5和C6来配置MPU。表13.2列出了控制MPU运行所需的主要寄存器。

寄存器C1是主要控制寄存器。
通过配置寄存器C2和C3,可以设置各个区域的缓存和写缓冲区属性。
寄存器C5控制区域访问权限。寄存器C6中有8个或16个辅助寄存器,用于定义每个区域的位置和大小。ARM740T、ARM940T、ARM946E-S和ARM1026EJ-S中还有其他配置寄存器,但它们的使用不涉及MPU的基本操作。有关协处理器15寄存器的用法,请参考第3.5.2节。
初始化MPU、缓存和写缓冲区需要以下步骤:
-
使用CP15:C6定义指令和数据区域的大小和位置。
-
使用CP15:C5为每个区域设置访问权限。
-
使用CP15:C2(用于缓存)和CP15:C3(用于写缓冲区)设置每个区域的缓存和写缓冲区属性。
-
使用CP15:C1启用缓存和MPU。
对于这些步骤,后面有一个章节描述了配置每个寄存器所需的协处理器15命令。还有示例代码显示了在初始化过程中完成该步骤的例程中使用的命令。
13.2.1 Defining Region Size and Location
为了定义每个区域的大小和地址范围,嵌入式系统需要写入其中一个八个辅助寄存器,即CP15:C6:C0:0到CP15:C6:C7:0。每个辅助寄存器编号对应于相应的区域编号标识符。
每个区域的起始地址必须对齐到它的大小的倍数的地址。例如,如果一个区域的大小为128 KB,则它可以从任何0x20000的倍数地址开始。区域的大小可以是从4 KB到4 GB的任意二的幂次。

第13.3图和第13.3表中显示了八个辅助寄存器CP15:C6:C0到CP15:C6:C7的位字段和格式。起始地址存储在顶部的位字段31:20中,并且必须是大小位字段5:1的倍数。E字段位0用于启用或禁用区域;也就是说,区域可以被定义和禁用,直到启用位被设置之前,其属性不会被执行。CP15:C6辅助寄存器中未使用的位应设置为零。
要定义区域的大小,可以使用公式size = 2^N+1或查找第13.4表中的值。要设置大小,在CP15:C6寄存器的大小位字段中放置指数值N。N的取值受硬件设计限制,可以是11到31之间的任何整数,表示4 KB到4 GB。二进制值提供了大小条目的精确位字段。确定了区域的大小后,区域的起始地址可以是从公式计算出的大小的任何整数值倍数,或者如果您愿意,可以从第13.4表中获取。区域的大小和起始地址由系统的内存映射和控制系统必须保护的区域决定。本章末尾的演示系统展示了如何在给定系统内存映射的情况下设置区域。

ARM740T、ARM946E-S和ARM1026EJ-S处理器每个都有八个区域。要设置区域的大小和位置,需要对CP15:C6:CX中的辅助寄存器进行写入。例如,设置区域3的起始地址为0x300000,大小为256 KB的指令语法是:
bash
MOV r1, #0x300000;设置起始地址
ORR r1, r1, #0x11 << 1;将大小设置为256 KB
MCR p15, 0, r1, c6, c3, 0核心寄存器r1中填充所需的位字段数据,然后使用MCR指令将其写入CP15辅助寄存器。
ARM940T有八个指令区域和八个数据区域。这些区域需要额外的opcode2修饰符来选择指令区域或数据区域。对于数据区域,opcode2为零;对于指令区域,opcode2为一。
例如,要读取数据和指令区域5的大小和位置,需要两个MRC指令,一个用于指令区域,一个用于数据区域。读取区域大小和起始位置的指令如下:
bash
MRC p15, 0, r2, c6, c5, 0;r2 = base/size 数据区域5
MRC p15, 0, r3, c6, c5, 1;r3 = base/size 指令区域5第一条指令将核心寄存器r2加载为数据区域5的大小和起始地址,第二条指令将核心寄存器r3加载为指令区域5的大小和起始地址。ARM940T是唯一具有单独指令和数据区域的处理器核心。
以下示例13.1代码显示了如何设置区域的起始地址、大小以及启用位。函数regionSet具有以下C原型:
void regionSet(unsigned region, unsigned address, unsigned sizeN, unsigned enable);
该函数具有四个无符号整数输入:要配置的区域,区域的起始地址,编码的区域大小sizeN,以及区域是否启用或禁用。在更改区域属性时,最好禁用该区域,并在更改完成后重新启用它。
为了使此函数适用于四个可用版本的MPU处理器,我们通过使用大小和起始地址信息来配置指令和数据区域,统一了ARM940T区域空间。为此,我们编写了一个名为SET_REGION的宏,其中包含ARM940T和其他核心的两个部分。这样可以使同一个函数支持四个MPU核心。
bash
#if defined( __TARGET_CPU_ARM940T)
#define SET_REGION(REGION) \
/* set Data region base & size */ \
__asm{MCR p15, 0, c6f, c6, c ## REGION,0}\
/* set Instruction region base & size */ \
__asm{MCR p15, 0, c6f, c6, c ## REGION, 1 }
#endif
#if defined(__TARGET_CPU_ARM946E_S) | \
defined(__TARGET_CPU_ARM1026EJ_S)
#define SET_REGION(REGION_NUMBER) \
/* set region base & size */ \
__asm{MCR p15, 0, c6f, c6, c ## REGION_NUMBER, 0 }
#endif
void regionSet(unsigned region, unsigned address,
unsigned sizeN, unsigned enable)
{
unsigned int c6f;
c6f = enable | (sizeN << 1) | address;
switch (region)
{
case 0: { SET_REGION(0); break;}
case 1: { SET_REGION(1); break;}
case 2: { SET_REGION(2); break;}
case 3: { SET_REGION(3); break;}
case 4: { SET_REGION(4); break;}
case 5: { SET_REGION(5); break;}
case 6: { SET_REGION(6); break;}
case 7: { SET_REGION(7); break;}
default: { break; }
}
}代码首先将起始地址、大小sizeN和启用状态合并到名为c6f的无符号整数中。然后,函数根据宏SET_REGION创建的八个regionSet例程之一进行分支,通过写入对应的CP15:c6辅助寄存器,设置区域的起始地址、大小和启用状态。
13.2.2 Access Permission
有两组访问权限方案可供选择,一个是标准集,另一个是扩展集。所有四个核心都支持标准集,它提供了四个级别的权限。更新的ARM946E-S和ARM1026EJ-S支持扩展集,新增了两个级别的权限(参见表13.5)。扩展集的AP(访问权限)位域编码支持12个额外的权限值。到目前为止,只有其中两个位被分配使用。使用未定义的编码将导致不可预测的行为。

为了给一个区域分配访问权限,需要向CP15:c5的一个辅助寄存器进行写入。CP15:c5:c0:0和CP15:c5:c0:1配置标准AP,而CP15:c5:c0:2或CP15:c5:c0:3配置扩展AP。表13.6和图13.4显示了AP寄存器的权限位分配。

支持扩展权限的处理器也可以运行为标准权限编写的软件。实际使用的权限类型取决于对CP15 AP寄存器的最后一次写入:如果最后一次写入的是标准AP寄存器,则核心使用标准权限;如果最后一次写入的是扩展AP寄存器,则核心使用扩展权限。这是因为对标准AP寄存器的写入也会更新扩展AP寄存器,意味着扩展AP区域条目的高位2:3将被清除。
当使用标准AP时,每个区域在寄存器CP15:c5:c0:0和CP15:c5:c0:1中都有两位。CP15:c5:c0:0设置数据区域的AP,CP15:c5:c0:1设置指令区域的AP。
要读取指令和数据内存的标准AP,需要读取两个寄存器。以下两条MRC指令序列将数据区域内存的AP信息放置在核心寄存器r1中,将指令区域的AP信息放置在寄存器r2中:
MRC p15, 0, r1, c5, c0, 0 ; 标准AP数据区域
MRC p15, 0, r2, c5, c0, 1 ; 标准AP指令区域
当使用扩展AP时,每个区域在寄存器CP15:c5:c0:2和CP15:c5:c0:3中使用四位。核心将八个区域的指令信息存储在一个寄存器中,将数据信息存储在另一个寄存器中。CP15:c5:c0:2设置数据区域的AP,CP15:c5:c0:3设置指令区域的AP。
获取扩展AP的指令和数据区域需要读取两个寄存器。以下两条指令将区域数据AP放置在核心寄存器r3中,将区域指令AP放置在寄存器r4中:
MRC p15, 0, r3, c5, c0, 2 ; 扩展AP数据区域
MRC p15, 0, r4, c5, c0, 3 ; 扩展AP指令区域
我们提供两个示例来演示如何使用访问权限,一个是标准AP,另一个是扩展AP。这些示例使用内联汇编器读写CP15寄存器。
我们提供了两个标准AP例程regionSetISAP和regionSetDSAP,用于设置区域的标准AP位。可以使用以下函数原型从C语言调用它们:
void regionSetISAP(unsigned region,unsigned ap);
void regionSetDSAP(unsigned region,unsigned ap);
第一个参数是区域编号,第二个参数是定义所控制的指令或数据内存的标准AP的两位值。
示例13.2
这两个例程完全相同,唯一的区别是它们读取和写入不同的CP15:c5辅助寄存器;一个写入指令寄存器,另一个写入数据寄存器。该例程对CP15:c5寄存器进行简单的读-修改-写操作,设置指定区域的AP,保持其他区域不变。
bash
void regionSetISAP(unsigned region, unsigned ap)
{
unsigned c5f, shift;
shift = 2*region;
__asm{ MRC p15, 0, c5f, c5, c0, 1 } /* load standard D AP */
c5f = c5f &∼ (0x3 << shift);
/* clear old AP bits */
c5f = c5f | (ap << shift);
/* set new AP bits */
__asm{ MCR p15, 0, c5f, c5, c0, 1 } /* store standard D AP */
}
void regionSetDSAP(unsigned region, unsigned ap)
{
unsigned c5f, shift;
shift = 2*region;
/* set bit field width */
__asm { MRC p15, 0, c5f, c5, c0, 0 } /* load standard I AP */
c5f = c5f &∼ (0x3 << shift);
/* clear old AP bits */
c5f = c5f | (ap << shift);
/* set new AP bits */
__asm { MCR p15, 0, c5f, c5, c0, 0 } /* store standard I AP */
}该例程通过使用移位掩码值来清除指定区域的AP位,并使用ap输入参数设置AP位字段,从而设置指定区域的权限。AP位字段的位置计算为区域大小乘以权限位字段中的位数,即移位变量。通过将ap值进行位移并使用OR操作来修改c5f核心寄存器来设置位字段的值。
我们提供了两个扩展AP例程regionSetIEAP和regionSetDEAP,用于设置区域的扩展AP位。可以使用以下函数原型从C语言调用它们:
void regionSetIEAP(unsigned region, unsigned ap);
void regionSetDEAP(unsigned region, unsigned ap);
第一个参数是区域编号,第二个参数是表示区域控制的指令或数据内存的四位值扩展AP。
示例13.3
这两个例程与标准AP例程完全相同,唯一的区别是它们读取和写入不同的CP15:c5辅助寄存器,并且它们具有四位宽的AP位字段。
bash
void regionSetIEAP(unsigned region, unsigned ap)
{
unsigned c5f, shift;
shift = 4*region;
/* set bit field width */
__asm{ MRC p15, 0, c5f, c5, c0, 3 } /* load extended D AP */
c5f = c5f &∼ (0xf shift);
/* clear old AP bits */
c5f = c5f | (ap
shift);
/* set new AP bits */
__asm{ MCR p15, 0, c5f, c5, c0, 3 } /* store extended D AP */
}
void regionSetDEAP(unsigned region, unsigned ap)
{
unsigned c5f, shift;
shift = 4*region;
/* set bit field width */
__asm{ MRC p15, 0, c5f, c5, c0, 2 } /* load extended I AP */
c5f = c5f &∼ (0xf << shift); /* clear old AP bits */
c5f = c5f | (ap << shift);
/* set new AP bits */
__asm{ MCR p15, 0, c5f, c5, c0, 2 } /* store extended I AP */
}每个例程通过使用移位掩码值来清除指定区域的AP位,并使用ap输入参数设置AP位字段,从而设置指定区域的权限。AP位字段的位置计算为区域大小乘以权限位字段中的位数;这就是移位变量。通过将ap值进行位移并使用OR操作来修改c5f核心寄存器来设置位字段的值。
13.2.3 Setting Region Cache and Write Buffer Attributes
有三个CP15寄存器控制每个核心的缓存和写缓冲区属性。两个寄存器,CP15:c2:c0:0和CP15:c2:c0:1,保存D-cache和I-cache区域属性。第三个寄存器,CP15:c3:c0:0,保存区域写缓冲区属性,并适用于内存数据区域(详见图13.5和表13.7)。

寄存器CP15:c2:c0:1包含所有八个指令区域的缓存配置数据,寄存器CP15:c2:c0:0包含所有八个数据区域的配置数据。这两个寄存器使用相同的位字段编码。
缓存位确定在给定区域内的特定地址是否启用了缓存。在ARM740T和ARM940T中,无论缓存位的状态如何,缓存都会被搜索。如果控制器找到一个有效的缓存条目,它将使用缓存数据而不是外部存储器中的数据。
由于这种缓存行为,当缓存策略从缓存更改为非缓存时,您需要刷新并可能清除区域中的缓存。因此,MPU控制系统在将缓存策略从写通模式更改为非缓存模式时必须始终刷新缓存。在将缓存策略从写回模式更改为非缓存模式时,它必须始终清除并刷新缓存。在将缓存策略从写回模式更改为写通模式时,它还必须清除缓存。有关清除和/或刷新缓存的例程,请参阅第12章。
在ARM946E-S中,如果缓存位为0,则不会从缓存中返回数据,而是执行外部内存访问。这种设计减轻了在禁用缓存时刷新缓存的要求。然而,对于旧区域的清除规则仍然适用。
寄存器CP15:c3:c0:0中的八个区域写缓冲区位用于启用或禁用每个区域的写缓冲区(详见图13.5)。
在配置数据区域时,区域缓存和写缓冲区位共同确定区域的策略。写缓冲区位有两种用途:启用或禁用区域的写缓冲区,并设置区域的缓存写策略。区域缓存位控制写缓冲区位的用途。当缓存位为零时,缓冲区位在值为1时启用写缓冲区,在值为零时禁用写缓冲区。当缓存位设置为1时,缓存和写缓冲区都被启用,缓冲区位确定缓存的写策略。如果缓冲区位为零,区域使用写通策略;如果缓冲区位设置为1,则使用写回策略。表13.8给出了缓存和写缓冲区位的各种状态及其含义的表格视图。有关写回和写通策略的更多详细信息,请参阅第12.3.1节。

我们提供了两个例程来演示如何启用和禁用缓存和写缓冲区。这两个例程使用内联汇编器来读写CP15寄存器。我们将缓存和写缓冲区的控制合并为一个单独的例程调用,以简化系统配置。我们通过控制写策略来引用数据缓存和写缓冲区位,指令缓存位则独立存在。从系统角度来看,将缓存和写缓冲区的状态合并为每个区域的单个值,可以更容易地将区域信息分组到区域控制块中(在第13.3.3节中讨论)。
设置缓存和缓冲区的例程称为regionSetCB,示例13.4显示了其C函数原型如下:
void regionSetCB(unsigned region, unsigned CB);
该例程有两个输入参数。第一个参数region是区域编号,第二个参数CB将区域的指令缓存属性和数据缓存、写缓冲区属性组合起来。第二个参数的格式使用无符号整数的低三位:指令缓存位在位3,数据缓存位在位1,数据缓冲位在位0。
例子13.4中的例程依次设置数据写缓冲区位、数据缓存位和指令缓存位。为此,对于每个位,它读取CP15寄存器,清除旧的位值,设置新的位值,并将该值写回CP15寄存器。
bash
void regionSetCB(unsigned region, unsigned CB)
{
unsigned c3f, tempCB;
tempCB = CB;
__asm{MRC p15, 0, c3f, c3, c0, 0 } /* load buffer register */
c3f = c3f &∼ (0x1 << region); /* clear old buffer bit */
c3f = c3f | ((tempCB & 0x1) << region); /* set new buffer bit */
__asm{MCR p15, 0, c3f, c3, c0, 0 } /* store buffer info */
tempCB = CB >> 0x1;
/* shift to D-cache bit */
__asm{MRC p15, 0, c3f, c2, c0, 0 } /* load D-cache register */
c3f = c3f &∼ (0x1 << region); /* clear old D-cache bit */
c3f = c3f | ((tempCB & 0x1) << region); /* set new D-cache bit */
__asm{MCR p15, 0, c3f, c2, c0, 0 } /* store D-cache info */
tempCB = CB >> 0x2;
/* shift to I-cache bit */
__asm{MRC p15, 0, c3f, c2, c0, 1 } /* load I-cache register */
c3f = c3f &∼ (0x1 << region); /* clear old I-cache bit */
c3f = c3f | ((tempCB & 0x1) << region); /* set new I-cache bit */
__asm{MCR p15, 0, c3f, c2, c0, 1 } /* store I-cache info */
}13.2.4 Enabling Regions and the MPU
初始化过程中还剩下两个步骤。第一个是启用活动区域,第二个是通过启用MPU、缓存和写缓冲区来启用保护单元硬件。
要启用区域,控制系统可以重用在第13.2.1节介绍的regionSet例程。本章末尾的示例13.6展示了regionSet的多次使用。
要启用MPU、缓存和写缓冲区,需要修改CP15:c1:c0:0寄存器(系统控制寄存器)中的位值。在ARM940T、ARM946E-S和ARM1026EJ-S处理器中,MPU、缓存和写缓冲区位在CP15:c1:c0中的位置相同,这使得配置MPU的启用对于这三个核心而言是相同的。图13.6和表13.9显示了启用位的位置。CP15:c1:c0寄存器中有一些在图13.6中未显示的配置位;这些位的目的和位置是特定于处理器的,不是保护系统的一部分。


我们使用在示例13.5中显示的changeControl例程来启用MPU和缓存。然而,changeControl例程可以更改CP15:c1:c0:0寄存器中任意一组值。它具有以下C函数原型:
void controlSet(unsigned value, unsigned mask);
传递的第一个参数是一个无符号整数,包含要更改的位值。第二个参数用于选择要更改的位:1表示更改控制寄存器中的该位,0表示保持该位值不变,不考虑第一个参数中位的状态。
例如,要启用MPU和I-cache,并禁用D-cache,将位12设置为1,位2设置为0,位0设置为1。第一个参数的值应为0x00001001;其余不变的位应为零。要将仅位12、位2和位0选为要更改的值,将掩码值设置为0x00001005。
例程13.5会读取控制寄存器并将值放入一个暂存寄存器中。然后,使用掩码输入清除所有要更改的位,并使用值输入指定的状态赋予它们。最后,该例程将新的控制值写入CP15:c1:c0寄存器。
bash
void controlSet(unsigned value, unsigned mask)
{
unsigned int c1f;
__asm{ MRC p15, 0, c1f, c1, c0, 0 } /* read control register */
c1f = c1f &∼ mask;
/* mask off bit that change */
c1f = c1f | value;
/* set bits that change */
__asm{ MCR p15, 0, c1f, c1, c0, 0 } /* write control register */
}13.3 Demonstration of an MPU system
我们提供了一组例程作为初始化和控制保护系统的构建块。本节使用所描述的例程来初始化和控制一个使用固定内存映射的简单保护系统。
以下是一个演示,使用本章前面部分所介绍的示例来创建一个功能性的保护系统。它提供了一个基础架构,使得三个任务在简单的受保护的多任务系统中运行。我们相信它提供了一个适当的演示ARM MPU硬件背后的概念。它是用C语言编写的,并使用标准访问权限。
13.3.1 System Requirements
该演示系统具有以下硬件特性:
■ 带有MPU的ARM核心
■ 物理内存大小为256 KB,起始地址为0x0,终止地址为0x40000
■ 多个内存映射外设,分布在从0x10000000到0x12000000之间的几兆字节空间上
在这个演示中,所有的内存映射外设被视为需要保护的单一内存区域(参见表13.10)。
该演示系统具有以下软件组件:
■ 系统软件大小小于64 KB。它包括向量表、异常处理程序和用于支持异常的数据栈。系统软件必须对用户模式不可访问;也就是说,用户模式任务必须通过系统调用来运行代码或访问此区域中的数据。
■ 有一个共享软件,大小小于64 KB。它包含常用的库和用于用户任务之间消息传递的数据空间。
■ 系统中有三个控制独立功能的用户任务。这些任务的大小小于32 KB。当这些任务运行时,必须保护它们不被其他两个任务访问。
软件被链接以将软件组件放置在分配给它们的区域中。表13.10显示了示例的软件内存映射。系统软件具有系统级访问权限。共享软件区域可由整个系统访问。任务软件区域包含用户级任务。

13.3.2 Assigning Regions Using a Memory Map
表13.10的最后一列显示了我们分配给内存区域的四个区域。这些区域是使用表中列出的起始地址和代码块和数据块的大小来定义的。图13.7中提供了显示区域布局的内存映射。

区域1是一个背景区域,覆盖整个可寻址内存空间。它是一个特权区域(即不允许用户模式访问)。指令缓存被启用,并且数据缓存采用写透方式操作。该区域具有最低的区域优先级,因为它是分配的最低编号区域。
区域1的主要功能是限制对0x0至0x10000之间的64 KB空间(受保护的系统区域)的访问。区域1还有两个次要功能:它充当背景区域和休眠用户任务的保护区域。作为背景区域,它默认将整个内存空间分配为系统级访问;这样做是为了防止用户任务访问备用或未使用的内存位置。作为用户任务保护区域,它保护休眠任务免受运行任务的不当操作(见图13.7)。
区域2控制对共享系统资源的访问。它的起始地址为0x10000,长度为64 KB。它直接映射到共享系统代码的共享内存空间上。区域2位于受保护区域1的一部分之上,并且会优先于受保护区域1,因为它具有较高的区域编号。区域2允许用户和系统级内存访问。
区域3控制运行任务的内存区域和属性。当控制从一个任务转移到另一个任务,比如在上下文切换期间,操作系统会重新定义区域3,使其覆盖运行任务的内存区域。当区域3被重新定位到新任务时,它将向前一个任务公开区域1的属性。前一个任务成为区域1的一部分,而运行任务成为新的区域3。运行任务无法访问前一个任务,因为它受到区域1属性的保护。
区域4是内存映射的外围系统空间。该区域的主要目的是将该区域设置为不使用缓存和缓冲区。我们不希望输入、输出或控制寄存器受到缓存引起的旧数据问题或使用缓冲写入时涉及的时间或顺序问题的影响(有关在缓存和写缓冲区中使用I/O设备的详细信息,请参见第12章)。
13.3.3 Initializing the MPU
为了组织初始化过程,我们创建了一种称为"Region"的数据类型;它是一个结构体,其成员包含系统操作中使用的区域的属性。当使用MPU时,并不需要这个Region结构体;它只是为了支持演示软件而创建的设计方便。在此演示中,我们称这些数据结构集合为区域控制块(RCB)。
初始化软件使用存储在RCB中的信息来配置MPU中的区域。请注意,RCB中可以定义比物理区域更多的Region结构。例如,区域3是唯一用于任务的区域,但有三个Region结构使用区域3,一个用于每个用户任务。该结构的typedef定义如下:
bash
typedef struct {
unsigned int number;
unsigned int type;
unsigned int baseaddress;
unsigned int size;
unsigned int IAP;
unsigned int DAP;
unsigned int CB;
} Region;Region结构体中有八个值。前两个值描述了该区域本身的特性:它们是分配给该区域的MPU区域号和使用的访问权限类型,即STANDARD或EXTENDED。结构体的其余四个成员是指定区域的属性:区域起始地址baseaddress,区域大小SIZE,访问权限IAP和DAP,以及缓存和缓冲区配置CB。
RCB中的六个Region结构体如下:
bash
/*
REGION NUMBER, APTYPE */
/*
START ADDRESS, SIZE, IAP, DAP, CB */
Region peripheralRegion = {PERIPH, STANDARD,
0x10000000, SIZE_1M, RONA, RWNA, ccb};
Region kernelRegion = {KERNEL, STANDARD,
0x00000000, SIZE_4G, RONA, RWNA, CWT};
Region sharedRegion = {SHARED, STANDARD,
0x00010000, SIZE_64K, RORO, RWRW, CWT};
Region task1Region = {TASK, STANDARD,
0x00020000, SIZE_32K, RORO, RWRW, CWT};
Region task2Region = {TASK, STANDARD,
0x00028000, SIZE_32K, RORO, RWRW, CWT};
Region task3Region = {TASK, STANDARD,
0x00030000, SIZE_32K, RORO, RWRW, CWT};我们创建了一组宏来使RCB中的条目更加易读,如图13.8所示。特别要注意的是,我们使用四个简单的字母组合来输入对数据和指令内存的访问权限。前两个字母表示系统访问权限,后两个字母表示用户访问权限。系统和用户访问权限的两个字母可以是读/写(RW)、只读(RO)或无访问(NA)。


我们还将缓存和缓冲区信息映射到指令缓存和数据缓存策略属性上。第一个字母是C或c,用于启用或禁用该区域的指令缓存。最后两个字母确定数据缓存策略和写缓冲控制。值可以是WT表示写直通(writethrough),或者WB表示写回(writeback)。字母c和b也被支持,并且用于手动配置缓存和缓冲区位。Cb是WT的别名,CB是WB的别名。cB表示不缓存和缓冲,最后cb表示既不缓存又不缓冲。
13.3.4 Initializing and Configuring a Region
接下来,我们提供configRegion例程,它接受RCB中的单个Region结构体条目,并将CP15寄存器填充为描述该区域的数据。
该例程遵循第13.3.3节中列出的初始化步骤。该例程的输入是指向区域的RCB的指针。在例程内部,Region的成员被用作初始化过程中的数据输入。该例程具有以下C函数原型:
void configRegion(Region *region);
示例13.6
此示例初始化保护系统的MPU、缓存和写缓冲区。本章前面介绍的例程在初始化过程中被使用。我们首先实现了第13.2节中列出的初始化MPU、缓存和写缓冲区的步骤。在示例代码中,这些步骤被标记为注释。执行此示例将初始化MPU。
bash
void configRegion(Region *region)
{
/* Step 1 - Define the size and location of the instruction */
/* and data regions using CP15:c6 */
regionSet(region->number, region->baseaddress,
region->size, R_DISABLE);
/* Step 2 - Set access permission for each region using CP15:c5 */
if (region->type == STANDARD)
{
regionSetISAP(region->number, region->IAP);
regionSetDSAP(region->number, region->DAP);
}
else if (region->type == EXTENDED)
{
regionSetIEAP(region->number, region->IAP);
regionSetDEAP(region->number, region->DAP);
}
/* Step 3 - Set the cache and write buffer attributes */
/*
for each region using CP15:c2 for cache */
/*
and CP15:c3 for the write buffer. */
regionSetCB(region->number, region->CB);
/* Step 4 - Enable the caches, write buffer and the MPU */
/* using CP15:c6 and CP15:c1 */
regionSet(region->number, region->baseaddress,
region->size, region->enable);
}13.3.5 Putting It All Together, Initializing the MPU
为了进行演示,我们使用RCB来存储描述所有区域的数据。为了初始化MPU,我们使用一个名为initActiveRegions的顶层例程。该例程在系统启动时针对每个活动区域调用一次。为了完成初始化,该例程还会启用MPU。该例程具有以下C函数原型:
void initActiveRegions();
该例程没有输入参数。
示例13.7
该例程首先针对系统启动时的每个活动区域(kernelRegion、sharedRegion、peripheralRegion和task1Region)分别调用configRegion一次。
在本演示中,任务1是第一个进入的任务。最后调用的例程是controlSet,它启用了缓存和MPU。
bash
#define ENABLEMPU (0x1)
#define ENABLEDCACHE (0x1 << 2)
#define ENABLEICACHE (0x1 << 12)
#define MASKMPU (0x1)
#define MASKDCACHE (0x1 << 2)
#define MASKICACHE (0x1 << 12)
void initActiveRegions()
{
unsigned value,mask;
configRegion(&kernelRegion);
configRegion(&sharedRegion);
configRegion(&peripheralRegion);
configRegion(&task1Region);
value = ENABLEMPU | ENABLEDCACHE | ENABLEICACHE;
mask = MASKMPU | MASKDCACHE | MASKICACHE;
controlSet(value, mask);
}13.3.6 A Protected Context Switch
演示系统现在已经初始化,并且控制系统已经启动了第一个任务。在某个时刻,系统将进行上下文切换以运行另一个任务。RCB包含了当前任务的区域上下文信息,因此在上下文切换过程中不需要保存CP15寄存器中的区域数据。
为了切换到下一个任务,比如任务2,操作系统会将区域3移动到任务2的内存区域上(参见图13.7)。我们重用configRegion例程,在执行当前任务和下一个任务之间的上下文切换代码之前,作为设置的一部分来执行这个功能。传递给configRegion的输入是指向task2Region的指针。以下是相应的汇编代码示例:
bash
STMFD sp!, {r0-r3,r12,lr}
BL configRegion
LDMFD sp!, {r0-r3,r12,pc} ; 返回在C语言中,相同的调用是
configRegion(&task2Region);
13.3.7 mpuSLOS
许多概念和代码示例已经被整合到一个名为mpuSLOS的功能控制系统中。
mpuSLOS是SLOS的内存保护单元变体,其在第11章中进行了描述。它可以在出版商的网站上找到,并实现了与基本SLOS相同的功能,但有一些重要的区别。
■ mpuSLOS充分利用了MPU。
■ 应用程序与内核分别编译和构建,然后合并为单个二进制文件。每个应用程序链接到执行不同的内存区域。
■ 三个应用程序中的每一个都由一个称为静态应用程序加载器的例程加载到大小为32 KB的独立固定区域。该地址是应用程序的执行地址。由于每个区域的大小为32 KB,堆栈指针设置在32 KB的顶部。
■ 应用程序只能通过设备驱动程序调用来访问硬件。如果应用程序尝试直接访问硬件,则会引发数据异常。这与基本的SLOS变体不同,因为当应用程序直接从设备访问时,不会引发数据异常。
■ 跳转到应用程序涉及设置spsr,然后使用MOVS指令将pc更改为指向任务1的入口点。
■ 每次调度程序被调用时,活动区域2会更改以反映新的正在执行的应用程序。
13.4 Summary
处理内存保护有两种方法。第一种方法称为无保护,使用自愿执行的软件控制例程来管理任务交互规则。第二种方法称为受保护,使用硬件和软件来强制执行任务交互规则。在受保护的系统中,硬件通过在访问权限违规时生成异常来保护内存区域,并且软件根据异常例程来处理异常并管理内存资源的控制。
ARM MPU 使用区域作为系统保护的主要构造。一个区域是与一块内存区域相关联的一组属性。区域可以重叠,允许使用背景区域来保护休眠任务的内存区域,以免被当前正在运行的任务非法访问。
初始化 MPU 需要执行几个步骤,其中包括设置各个区域属性的例程。第一步使用 CP15:c6 设置指令和数据区域的大小和位置。第二步使用 CP15:c5 设置每个区域的访问权限。第三步使用 CP15:c2(用于缓存)和 CP15:c3(用于写缓冲区)设置每个区域的缓存和写缓冲区属性。最后一步使用 CP15:c6 启用活动区域,并使用 CP15:c1 启用缓存、写缓冲区和 MPU。
最后,一个演示系统展示了在简单的多任务环境中相互保护的三个任务。该演示系统定义了一个受保护的系统,并展示了如何进行初始化。初始化之后,运行受保护系统的最后一步是在任务切换期间将区域分配更改为下一个任务。这个演示系统被整合到 mpuSLOS 中,提供了一个受保护操作系统的功能性示例。
Chapter14 Memory Management Units
在创建一个多任务嵌入式系统时,有一个简单的方法来编写、加载和运行独立的应用任务是很有意义的。许多现代嵌入式系统使用操作系统,而不是自定义专有的控制系统来简化这个过程。更先进的操作系统使用基于硬件的内存管理单元(MMU)。
MMU 提供的一个关键服务是能够将任务作为独立程序在自己的私有内存空间中运行。在受 MMU 控制的操作系统下运行的任务不需要知道不相关任务的内存需求。这简化了在操作系统控制下运行的各个任务的设计要求。
在第13章中,我们介绍了带有内存保护单元的处理器核心。这些核心具有一个可寻址的物理内存空间。处理器核心在运行任务时生成的地址直接用于访问主存储器,这使得如果使用重叠的地址编译,两个程序同时驻留在主存储器中是不可能的。这使得在嵌入式系统中运行多个任务变得困难,因为每个任务必须在主存储器中运行在一个不同的地址块中。
MMU简化了应用任务的编程,因为它提供了启用虚拟内存所需的资源,这是一个独立于系统上连接的物理内存的额外内存空间。MMU充当一个翻译器,将编译为在虚拟内存中运行的程序和数据的地址转换为实际物理地址,在物理主存储器中存储程序的位置。这个转换过程允许程序在不同的物理内存位置上以相同的虚拟地址运行。
这种对内存的双重视图导致了两种不同的地址类型:虚拟地址和物理地址。虚拟地址在定位程序在内存中时由编译器和链接器分配。物理地址用于访问程序所在的实际主存储器的硬件组件。
ARM提供了几个带有集成MMU硬件的处理器核心,可以高效支持使用虚拟内存的多任务环境。本章的目标是学习ARM内存管理单元的基础知识和支持虚拟内存使用的一些基本概念。
我们首先回顾MPU的保护特性,然后介绍MMU提供的附加功能。我们介绍重新定位寄存器,它保存转换数据,以将虚拟内存地址转换为物理内存地址,并介绍最近地址重新定位的缓存------翻译后备缓冲器(TLB)。然后,我们解释如何使用页和页表来配置重新定位寄存器的行为。
接下来,我们讨论如何通过在虚拟内存中配置页面块来创建区域。我们通过展示如何操作MMU和页表以支持多任务来结束对MMU及其对虚拟内存的支持的概述。
接下来,我们通过针对ARM MMU中的每个组件提供一个部分来呈现配置MMU硬件的详细信息:页表、翻译后备缓冲器(TLB)、访问权限、缓存和写缓冲区、CP15:c1控制寄存器以及快速上下文切换扩展(FCSE)。
我们通过提供演示软件来结束本章,演示如何使用虚拟内存设置嵌入式系统。演示支持在多任务环境中运行的三个任务,并展示如何通过将任务编译为在共同的虚拟内存执行地址上运行并将它们放置在物理内存的不同位置来保护每个任务免受系统中运行的其他任务的干扰。演示的关键部分是展示如何配置MMU来将任务的虚拟地址转换为任务的物理地址,以及如何在任务之间切换。
演示已经集成到第11章介绍的SLOS操作系统中,作为称为mmuSLOS的变体。
14.1 Moving from an MPU to an MMU
在第13章中,我们介绍了带有内存保护单元(MPU)的ARM核心。更重要的是,我们介绍了区域作为一种方便的方式来组织和保护内存。区域可以是活动的或休眠的:活动区域包含当前系统正在使用的代码或数据;休眠区域包含当前未使用但可能在短时间内变为活动状态的代码或数据。休眠区域受到保护,因此对当前运行的任务来说是不可访问的。
MPU具有专用硬件,用于为区域分配属性。表14.1展示了分配给区域的属性。

在本章中,我们假设读者已经理解了第13章介绍的关于内存保护的概念,并且简单地展示如何配置MMU上的保护硬件。
MPU和MMU之间的主要区别是MMU增加了支持虚拟内存的硬件。MMU硬件还通过将表14.1中显示的区域属性从CP15寄存器移动到保存在主存储器中的表格中,扩展了可用区域的数量。
14.2 How Virtual Memory Works
在第13章中,我们介绍了MPU,并展示了一个多任务嵌入式系统,该系统在主存储器中以明显不同的、固定的地址区域编译和运行每个任务。每个任务只在一个进程区域中运行,并且没有任何任务在主存储器中具有重叠的地址。为了运行一个任务,一个保护区域被放置在固定地址的程序上,以便访问由该区域定义的内存区域。保护区域的放置允许任务在其他任务受保护时执行。
在MMU中,即使任务被编译和链接以在主存储器中具有重叠地址的区域中运行,它们仍然可以运行。MMU中的虚拟内存支持使得可以构建一个具有多个虚拟内存映射和单个物理内存映射的嵌入式系统。为了编译和链接构成任务的代码和数据,每个任务都提供了自己的虚拟内存映射。然后,内核层在物理内存中管理多个任务的位置,以便它们在物理内存中具有与其设计用于运行的虚拟位置不同的独特位置。
为了允许任务拥有自己的虚拟内存映射,MMU硬件在到达主存储器之前对处理器核心输出的内存地址进行重新定位和转换。理解转换过程的最简单方法是想象在核心和主存储器之间的MMU中有一个重新定位寄存器。
当处理器核心生成一个虚拟地址时,MMU会获取虚拟地址的高位,并用重定位寄存器的内容替换它们,从而创建一个物理地址,如图14.1所示。
虚拟地址的低部分是一个偏移量,将转换为物理内存中的特定地址。可以使用这种方法进行转换的地址范围受限于虚拟地址的偏移量部分的最大大小。
图14.1显示了一个任务编译为在虚拟内存中的起始地址为0x4000000运行的示例。重定位寄存器将任务1的虚拟地址转换为以0x8000000开始的物理地址。
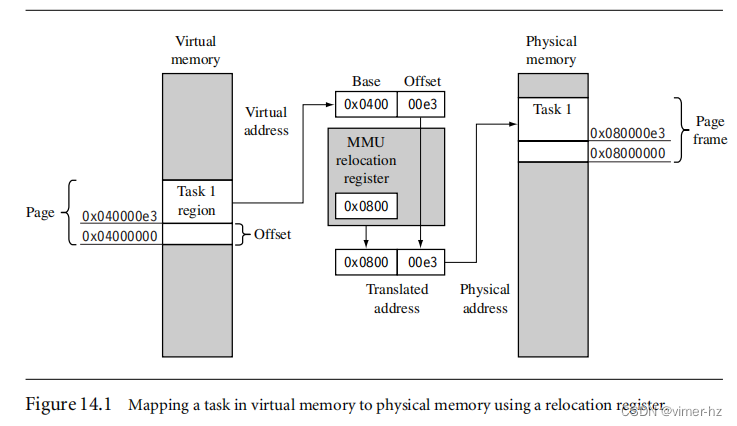
第二个任务编译为在相同的虚拟地址上运行,这里是0x400000,它可以被放置在物理内存中的任何其他0x10000(64KB)的倍数处,并映射到0x400000,只需更改重定位寄存器中的值。
单个重定位寄存器只能转换单个内存区域,这由虚拟地址的偏移量部分中的位数确定。虚拟内存的这个区域称为页。翻译过程指向的物理内存区域称为页帧。
图14.2显示了页面、MMU和页帧之间的关系。ARM MMU硬件具有支持将虚拟内存转换为物理内存的多个重定位寄存器。MMU需要许多重定位寄存器来有效地支持虚拟内存,因为系统必须将许多页面转换为许多页帧。
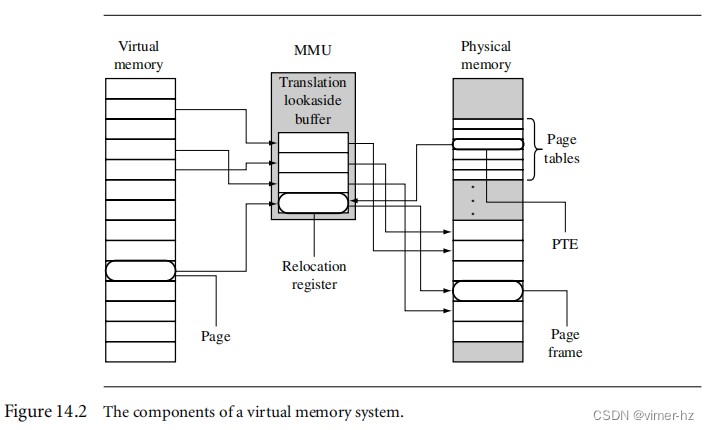
ARM MMU中用于暂时存储翻译的重定位寄存器实际上是一个完全关联的缓存,包含64个重定位寄存器。这个缓存被称为Translation Lookaside Buffer(TLB)。TLB缓存最近访问的页面的翻译结果。
除了具有重定位寄存器之外,MMU还使用主存中的表格来存储描述系统中使用的虚拟内存映射的数据。这些翻译数据的表格称为页表。页表中的一个条目表示将虚拟内存中的一页翻译为物理内存中的页帧所需的所有信息。
//Page Table Entry
页表中的一个页表条目(PTE)包含关于虚拟页的以下信息:用于将虚拟页翻译为物理页帧的物理基地址、分配给该页的访问权限,以及该页的高速缓存和写缓冲区配置。如果参考表14.1,可以看到大多数MPU中的区域配置数据现在都保存在页表条目中。这意味着访问权限、缓存和写缓冲区行为是以页面大小的粒度进行控制的,从而更精细地控制内存的使用。
MMU中的区域是通过将内存中的虚拟页面块分组来在软件中创建的。
14.2.1 Defining Regions Using Pages
在第13章中,我们解释了使用区域来组织和控制用于特定功能(如任务代码、数据或内存输入/输出)的内存区域。在那个解释中,我们将区域显示为MPU架构的硬件组件。在MMU中,区域被定义为页表的组合,并且完全由软件在虚拟内存中的连续页面上进行控制。
由于虚拟内存中的每一页都在页表中有一个对应的条目,一块虚拟内存页面映射到页表中的一组连续条目。因此,区域可以被定义为连续的页表条目集合。区域的位置和大小可以保存在软件数据结构中,而实际的翻译数据和属性信息则保存在页表中。
图14.3显示了一个单一任务具有三个区域的示例:一个用于文本,一个用于数据,第三个用于支持任务堆栈。虚拟内存中的每个区域都映射到物理内存中的不同区域。在该图中,可执行代码位于闪存中,数据区和堆栈区位于RAM中。这种使用区域的方式是支持任务之间共享代码的操作系统的典型示例。
//闪存也算在Physical memory里?
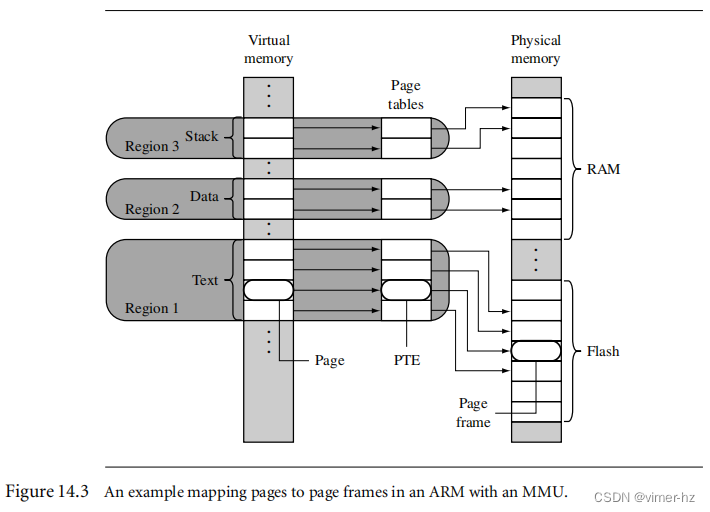
除了主级别1(L1)页表之外,所有页表表示1 MB的虚拟内存区域。如果一个区域的大小大于1 MB或跨越了分隔页表的1 MB边界地址,那么该区域的描述还必须包括页表列表。一个区域的页表将始终从主L1页表中的连续页表条目中派生。然而,物理内存中L2页表的位置不需要连续。页表级别将在第14.4节中有更详细的说明。
14.2.2 Multitasking and the MMU
页表可以存储在内存中,并且不需要映射到MMU硬件上。构建多任务系统的一种方法是创建独立的页表集,每个集合将为一个任务映射一个唯一的虚拟内存空间。要激活一个任务,需要将该任务及其虚拟内存空间的页表集映射到MMU中使用。其他处于非活动状态的页表集表示休眠任务。这种方法使得所有任务都可以保留在物理内存中,并且在上下文切换发生时立即可用。
通过在上下文切换期间激活不同的页表,可以执行具有重叠虚拟地址的多个任务。MMU可以重新定位任务的执行地址,而无需将其移动到物理内存中。任务的物理内存只需通过激活和停用页表来映射到虚拟内存中。图14.4展示了三个任务的三个视图,每个任务都有自己的页表集,并在共同的执行虚拟地址0x0400000下运行。
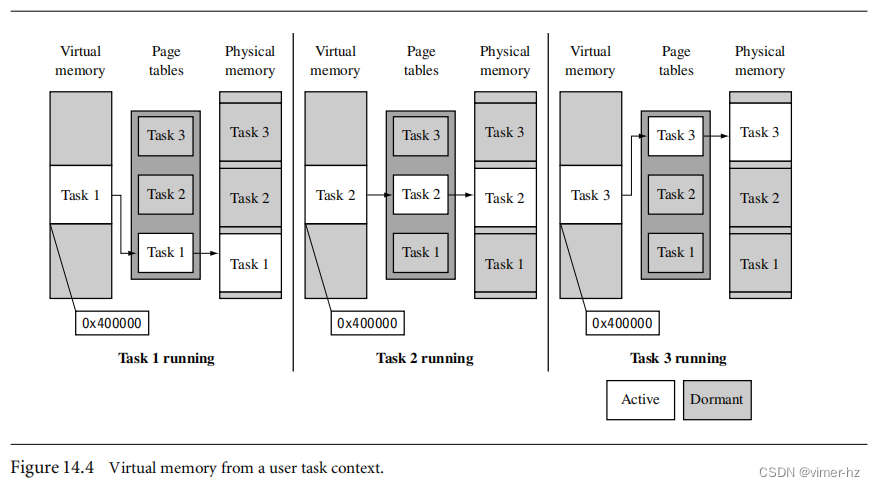
在第一个视图中,任务1正在运行,任务2和任务3处于休眠状态。在第二个视图中,任务2正在运行,任务1和任务3处于休眠状态。在第三个视图中,任务3正在运行,任务1和任务2处于休眠状态。三个视图中的每个虚拟内存都代表了运行任务所见到的内存。物理内存的视图在所有视图中都是相同的,因为它代表真实物理内存的实际状态。
图中还显示了活动和休眠的页表,只有正在运行的任务具有一组活动的页表。休眠任务的页表保持驻留在特权物理内存中,并且对于运行的任务来说是不可访问的。因此,休眠任务完全受到活动任务的保护,因为虚拟内存中没有与休眠任务的映射关系。
当页表被激活或停用时,虚拟到物理地址的映射将发生变化。因此,在激活页表后,访问虚拟内存中的地址可能会突然转换为物理内存中的不同地址。正如在第12章中提到的,ARM处理器核心具有逻辑缓存,并将缓存的数据存储在虚拟内存中。当发生这种转换时,缓存中可能会包含来自旧的页表映射的无效虚拟数据。为确保内存一致性,缓存可能需要进行清理和刷新。TLB(转换查找缓冲器)也可能需要刷新,因为它将缓存旧的转换数据。
//cache里存储的是虚拟内存地址
清理和刷新缓存和TLB的效果会减慢系统操作。然而,清除缓存中的过时代码或数据以及TLB中的过时转换物理地址可以防止系统使用无效数据并避免错误发生。
在上下文切换期间,页表数据不会在物理内存中移动,只有指向页表位置的指针会发生变化。
切换任务需要以下步骤:
-
保存活动任务的上下文并将任务置于休眠状态。
-
清除缓存;如果使用写回策略,则可能需要清理D缓存。
-
刷新TLB以删除当前任务的转换。
-
配置MMU以使用新的页表,将虚拟内存执行区域转换为唤醒任务在物理内存中的位置。
-
恢复唤醒任务的上下文。
-
恢复执行已恢复的任务。
注意:为了减少执行上下文切换所需的时间,在ARM9系列中可以使用写穿策略的缓存。清理数据缓存可能需要对CP15寄存器进行数百次写操作。通过配置数据缓存使用写穿策略,在执行上下文切换时无需清理数据缓存,这将提供更好的上下文切换性能。使用写穿策略可以将这些写操作分散到任务的生命周期中。尽管写回策略可以提供更好的总体性能,但在小型嵌入式系统中使用写穿策略更加简单。这种简化适用于大多数系统在非易失性存储器中使用闪存存储程序,并在系统运行期间将程序复制到RAM中。如果您的系统具有文件系统并使用动态分页,那么是时候切换到写回策略了,因为访问文件系统存储的速度比访问RAM存储慢上数十到数百万倍。
如果在性能分析后发现写穿系统的效率不够,可以使用写回缓存来提高性能。如果您使用的是磁盘驱动器或其他非常慢的辅助存储器,几乎必须使用写回策略。该论点仅适用于使用逻辑缓存的ARM内核。如果存在物理缓存,例如ARM11系列中的情况,当MMU更改其虚拟内存映射时,缓存中的信息仍然有效。使用物理缓存可以消除更改虚拟内存地址时执行缓存管理活动的需要。有关缓存的更多信息,请参阅第12章。
14.2.3 Memory Organization in a Virtual Memory System
通常,页表位于主存储器的一个区域,其中虚拟到物理地址映射是固定的。所谓"固定"是指在正常操作期间,页表中的数据不会改变,如图14.5所示。这个固定的存储区域还包含操作系统内核和其他进程。MMU(包括图14.5中显示的TLB)是在虚拟或物理内存空间之外操作的硬件,其功能是在两个内存空间之间进行地址转换。
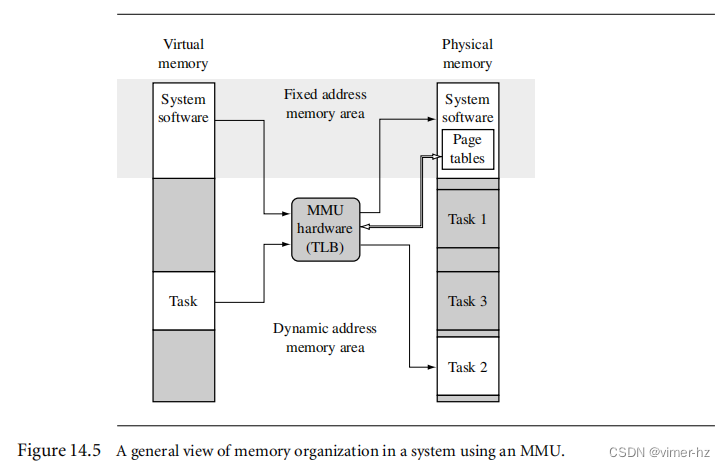
//Virtual memory的System software包含操作系统内核和其他进程是什么意思?,然后再往下是Tasks?
这种固定映射的优势在上下文切换时体现出来。将系统软件放置在固定的虚拟内存位置上,可以消除一些内存管理任务,并消除如果处理器在一个虚拟内存区域中执行,而该区域突然重新映射到不同的物理内存位置,产生的流水线效应。
当两个应用任务之间发生上下文切换时,实际上处理器进行了许多上下文切换。它从用户模式任务切换到内核模式任务,执行实际的上下文数据移动,以准备运行下一个应用任务。然后,它再从内核模式任务切换到下一个上下文的新用户模式任务。
通过在所有用户任务中共享固定虚拟内存区域中的系统软件,系统调用可以直接转到系统区域,而不需要担心需要更改页表来映射内核进程。在所有任务中将内核代码和数据映射到相同的虚拟地址,消除了更改内存映射和需要独立的内核进程来占用时间片的需要。
转到固定的内核内存区域还消除了流水线架构固有的一个问题。如果处理器核心在一个地址会发生变化的内存区域中执行代码,那么核心将从旧的物理内存空间预取多条指令,当新的指令从新映射的内存空间填充流水线时,这些预取的指令将被执行。除非特别注意,从旧的内存映射中仍在流水线中执行的指令可能会破坏程序的执行。
我们建议在执行系统代码时激活页表,并将其放置于一个虚拟地址区域,其中虚拟到物理内存映射永远不会改变。这种方法确保了用户任务之间的安全切换。
许多嵌入式系统不使用复杂的虚拟内存,而只是创建一个"固定"的虚拟内存映射,以整合物理内存的使用。这些系统通常将分散在大地址空间上的物理内存块集合到一个连续的虚拟内存块中。它们通常在初始化过程中创建一个"固定"的映射,而在系统运行过程中该映射保持不变。
14.3 Details of the ARM MMU
ARM MMU执行多个任务:它将虚拟地址转换为物理地址,控制内存访问权限,并确定内存中每个页面的缓存和写缓冲区的个别行为。当MMU被禁用时,所有虚拟地址都一对一地映射到相同的物理地址。如果MMU无法转换地址,则会生成异常中断。MMU只会在转换、权限和域故障时中止。
MMU中的主要软件配置和控制组件包括:
-
页表
-
翻译后备缓冲器(TLB)
-
域和访问权限
-
缓存和写缓冲区
-
CP15:c1控制寄存器
-
快速上下文切换扩展功能
我们将在以下部分介绍这些组件的操作细节和配置方法。
14.4 Page Tables
ARM MMU硬件采用多级页表结构。有两个级别的页表:第一级(L1)和第二级(L2)。
存在一个单独的第一级页表,称为L1主页表,可以包含两种类型的页表项。它可以保存指向第二级页表起始地址的指针,以及用于翻译1 MB页面的页表项。L1主表也称为节页表。
主L1页表将4 GB的地址空间划分为1 MB的节,因此L1页表包含4096个页表项。主表是一个混合表,既充当L2页表的页目录,又充当翻译1 MB虚拟页面(称为节)的页表。如果L1表充当目录,则PTE包含指向表示1 MB虚拟内存的L2粗粒度页表或L2细粒度页表的指针。如果L1主表正在翻译1 MB节,则PTE包含物理内存中1 MB页框的基地址。目录项和1 MB节项可以共存于主页表中。
粗粒度L2页表有256个项,占用1 KB的主存。粗粒度页表中的每个PTE将4 KB的虚拟内存块翻译为4 KB的物理内存块。粗粒度页表支持4 KB或64 KB页面。粗粒度页中的PTE包含指向4 KB或64 KB页框的基地址;如果该条目翻译一个64 KB页面,则每个64 KB页面必须在页表中重复16次。
细粒度L2页表有1024个项,占用4 KB的主存。细粒度页表中的每个PTE将1 KB的内存块翻译为相应的大小。细粒度页表支持1 KB、4 KB或64 KB的虚拟内存页面。这些条目包含物理内存中1 KB、4 KB或64 KB的页框的基地址。如果细粒度表翻译一个4 KB页面,则同一PTE必须在页表中连续重复4次。如果表翻译一个64 KB页面,则同一PTE必须在页表中连续重复64次。
表14.2总结了ARM内存管理单元中使用的三种页表的特性。
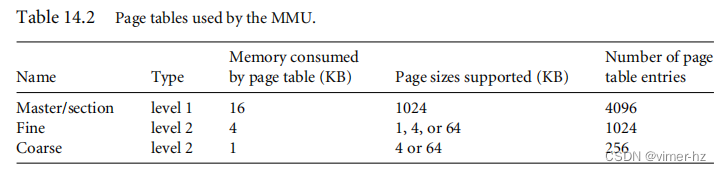
14.4.1 Level 1 Page Table Entries
第一级页表(L1页表)接受四种类型的条目:
■ 一个1 MB节翻译条目
■ 一个指向细粒度L2页表的目录条目
■ 一个指向粗粒度L2页表的目录条目
■ 一个生成中止异常的故障条目
系统通过条目字段中的低两位1:0来确定条目的类型。PTE的格式要求L2页表的地址要对其于其页面大小的倍数。图14.6显示了L1页表中每个条目的格式。
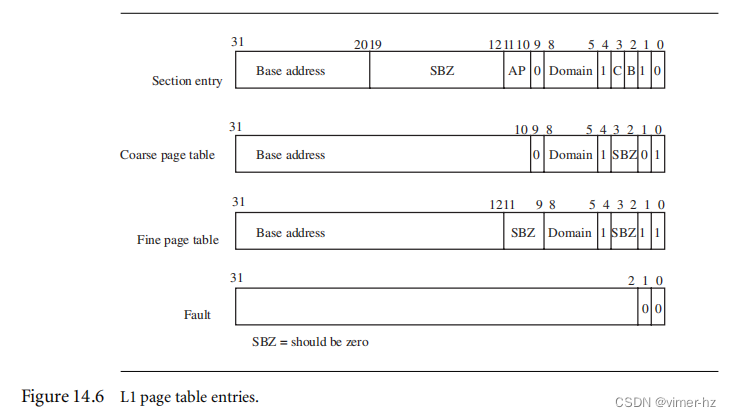
节页表条目指向1 MB的内存节。页表条目的高12位取代虚拟地址的高12位以生成物理地址。节条目还包含域、缓存、缓冲和访问权限属性,我们将在第14.6节中讨论这些属性。
粗粒度页条目包含指向第二级粗粒度页表的基地址的指针。粗粒度页表条目还包含L1表条目所表示的1 MB虚拟内存的域信息。对于粗粒度页,表必须对齐于1 KB的地址倍数。
细粒度页表条目包含指向第二级细粒度页表的基地址的指针。细粒度页表条目还包含L1表条目所表示的1 MB虚拟内存的域信息。细粒度页表必须对齐于4 KB的地址倍数。
故障页表条目会引发内存页故障。故障条件导致预取或数据中止,具体取决于尝试的内存访问类型。
//故障页表条目和page fault有关系么?
L1主页表在内存中的位置通过写入CP15:c2寄存器来设置。
14.4.2 The L1 Translation Table Base Address
CP15:c2寄存器保存着翻译表基地址(TTB),即指向主L1表在虚拟内存中的位置的地址。图14.7显示了CP15:c2寄存器的格式。
例子14.1:
这里有一个名为ttbSet的例程,它设置了主L1页表的TTB。ttbSet例程使用MRC指令写入到CP15:c2:c0:0。该例程使用以下函数原型进行定义:
void ttbSet(unsigned int ttb);
该过程只接受一个参数,即翻译表的基地址。TTB地址必须在内存中16 KB的边界上对齐。
cpp
void ttbSet(unsigned int ttb)
{
ttb &= 0xffffc000;
__asm{MRC p15, 0, ttb, c2, c0, 0 } /* 设置翻译表基地址 */
}14.4.3 Level 2 Page Table Entries
L2页表中有四种可能的条目类型:
■ 大页面条目定义了一个64 KB的物理页框的属性。
■ 小页面条目定义了一个4 KB的物理页框。
■ 微小页面条目定义了一个1 KB的物理页框。
■ 故障页面条目在访问时会生成页面故障终止异常。
图14.8显示了L2页表条目的格式。MMU通过条目字段中的低两位来识别L2页表条目的类型。
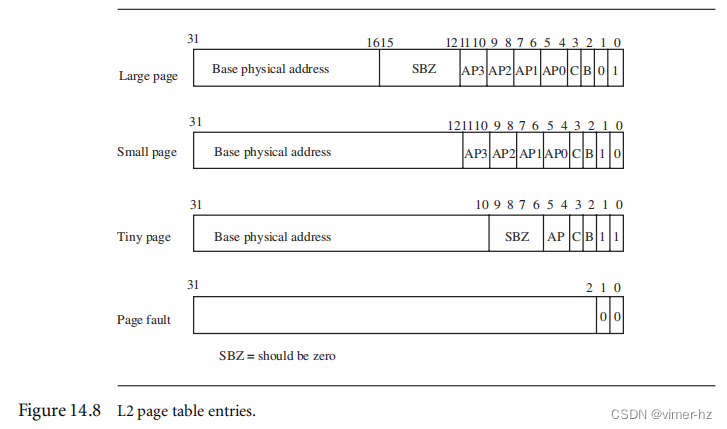
大页面条目包括一个64 KB物理内存块的基地址。该条目还有四组权限位字段,以及页面的缓存和写缓冲属性。每组访问权限位字段代表虚拟内存中页面的四分之一。这些条目可以看作是16 KB的子页面,在64 KB页面内提供了更精细的访问权限控制。
小页面条目保存了一个4 KB物理内存块的基地址。该条目还包括四组权限位字段和页面的缓存和写缓冲属性。每组权限位字段代表虚拟内存中页面的四分之一。这些条目可以看作是1 KB的子页面,在4 KB页面内提供了更精细的访问权限控制。
微小页面条目提供了一个1 KB物理内存块的基地址。该条目还包括一个单独的访问权限位字段和页面的缓存和写缓冲属性。微小页面没有在ARMv6架构中使用。如果您打算创建一个易于迁移至未来架构的系统,我们建议避免在系统中使用1 KB的微小页面。
故障页面条目会生成内存页访问故障。故障条件导致预取或数据中止,具体取决于内存访问类型。
14.4.4 Selecting a Page Size for Your Embedded System
以下是设置系统页面大小的一些建议和提示:
■ 页面大小越小,在给定的物理内存块中会有更多的页框。
■ 页面大小越小,内部碎片化越少。内部碎片化是指页面中未使用的内存区域。例如,一个大小为9 KB的任务可以适应三个4 KB的页面或一个64 KB的页面。在第一种情况下,使用4 KB的页面,有3 KB的未使用空间。而在使用64 KB页面的情况下,有55 KB的未使用页面空间。
■ 页面大小越大,系统加载引用的代码和数据的可能性越高。
■ 大页面在访问次存储增加时效率更高。
■ 随着页面大小增加,每个TLB条目表示的内存区域也增加。因此,系统可以缓存更多的翻译数据,TLB加载整个任务的所有翻译数据的速度更快。
■ 如果使用L2粗页面,每个页表占用1 KB的内存。而每个L2细页面表占用4 KB的内存。每个L2页表可翻译1 MB的地址空间。每个任务的最大页表内存使用量可以通过以下公式计算:
((task size/1 megabyte) + 1) ∗ (L2 page table size) (14.1)
14.5 The Translation Lookaside Buffer
TLB是最近使用的页面翻译的特殊高速缓存。TLB将虚拟页面映射到活动页面帧,并存储限制对页面访问的控制数据。TLB是一个缓存,因此具有受害者指针和TLB行替换策略。在ARM处理器核心中,TLB使用循环轮询算法来选择在TLB未命中时要替换的重定位寄存器。
ARM处理器核心中的TLB没有许多可用于控制其操作的软件命令。TLB支持两种类型的命令:可以刷新TLB,也可以在TLB中锁定翻译。
在内存访问过程中,MMU将虚拟地址的一部分与TLB中缓存的所有值进行比较。如果请求的翻译可用,则为TLB命中,TLB提供物理地址的翻译。
如果TLB中不包含有效的翻译,则为TLB未命中。MMU通过在主存中搜索有效的翻译并将其加载到TLB的64行之一来自动处理TLB未命中。在页表中搜索有效的翻译称为页表遍历。如果存在有效的PTE,则硬件将翻译地址从PTE复制到TLB,并生成用于访问主存的物理地址。如果在搜索结束时在页表中存在故障条目,则MMU硬件会生成中止异常。
在TLB未命中期间,MMU可能要在加载数据到TLB并生成所需的地址翻译之前搜索多达两个页表。未命中的成本通常是一到两个主存访问周期,因为MMU翻译表硬件搜索页表。循环的次数取决于翻译数据所在的页表。如果搜索以L1主页表结束,则发生单级页表遍历;如果搜索以L2页表结束,则发生两级页表遍历。
如果MMU生成中止异常,TLB未命中可能需要额外的多个周期。额外的周期是由于中止处理程序映射请求的虚拟内存而产生的。ARM720T只有一个TLB,因为它具有统一总线架构。ARM920T、ARM922T、ARM926EJ-S和ARM1026EJ-S具有两个TLBs,因为它们使用了哈佛总线架构:一个用于指令翻译,一个用于数据翻译。
14.5.1 Single-Step Page Table Walk
如果MMU正在搜索1MB的分段页,硬件可以通过单步搜索找到该条目,因为1MB的页表条目位于主L1页表中。图14.9展示了对于1MB分段页翻译的L1表的表遍历过程。
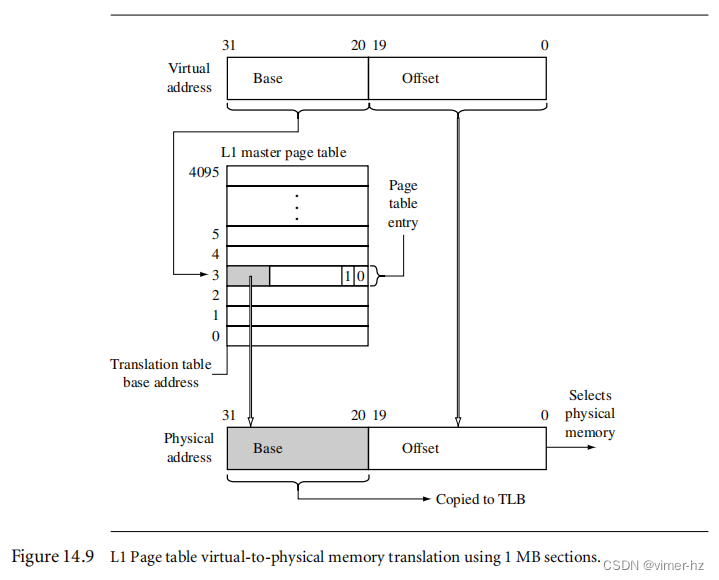
MMU使用虚拟地址的基地址部分,即31:20位,来选择L1主页表中的4096个条目之一。如果1:0位的值是二进制10,则PTE具有一个有效的1MB页面。PTE中的数据被传输到TLB(MMU),并通过将其与虚拟地址的偏移部分组合来翻译物理地址。如果低两位为00,则生成故障。如果是其他两个值中的任意一个,则MMU执行两级搜索。
//注意:发生Page Table Walk的前提是TLB已经未命中了
14.5.2 Two-Step Page Table Walk
如果MMU在搜索大小为1KB、4KB、16KB或64KB的页面时结束搜索,那么页表遍历将需要两个步骤来找到地址转换。图14.10详细描述了保存在粗略L2页表中的两阶段过程。请注意,虚拟地址分为三个部分。
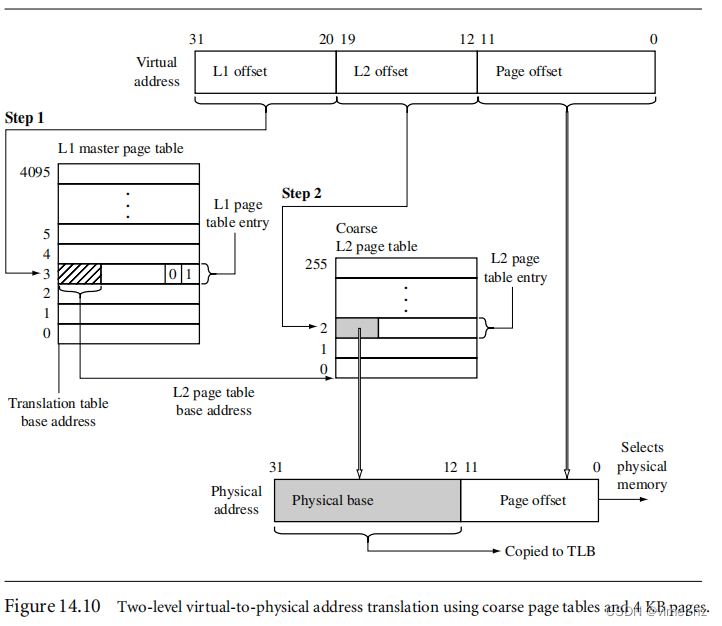
在第一步中,使用L1偏移部分作为索引进入主L1页表,并找到虚拟地址对应的L1 PTE。如果PTE的低两位包含二进制值01,则该条目包含到粗略页的L2页表基地址(参见图14.6)。
在第二步中,将L2偏移与在第一阶段找到的L2页表基地址相结合;得到的地址选择包含页面翻译的PTE。MMU将L2 PTE中的数据传输到TLB,并将基地址与虚拟地址的偏移部分相结合,生成所请求的物理内存地址。
14.5.3 TLB Operations
如果操作系统更改页表中的数据,缓存在TLB中的翻译数据可能不再有效。为了使TLB中的数据无效,核心具有CP15指令来刷新TLB。有几个可用的指令(参见表14.3):一个用于刷新所有TLB数据,一个用于刷新指令TLB,另一个用于刷新数据TLB。TLB也可以逐行刷新。
以下是一个简单的C例程14.2,用于使TLB无效。
cpp
void flushTLB(void)
{
unsigned int c8format = 0;
__asm{MCR p15, 0, c8format, c8, c7, 0 } /* flush TLB */
}14.5.4 TLB Lockdown
ARM920T、ARM922T、ARM926EJ-S、ARM1022E和ARM1026EJ-S支持在TLB中锁定翻译。如果在TLB中锁定了一行,当发出TLB刷新命令时,它将保留在TLB中。我们在表14.4中列出了各种ARM核心可用的锁定命令。用于在MCR指令中锁定TLB中数据的核心寄存器Rd的格式如图14.11所示。


14.6 Domains and Memory Access Permission
有两种不同的控制方式来管理任务对内存的访问权限:主要控制方式是域(domain),而次要控制方式是在页表中设置的访问权限。
通过隔离内存区域,域控制对虚拟内存的基本访问,当共享一个共同的虚拟内存映射时将一个内存区域与另一个隔离开来。可以将16个不同的域分配给1MB的虚拟内存段,并通过设置主L1 PTE中的域位字段来为段分配域(见图14.6)。
当为一个段分配了一个域时,它必须遵守分配给该域的域访问权限。域访问权限存储在CP15:c3寄存器中,并控制处理器核心对虚拟内存段的访问能力。
CP15:c3寄存器使用两个位来定义每个域的访问权限,用于说明16个可用域的值和含义。表14.5显示了域访问位字段的值和含义。图14.12给出了CP15:c3:c0寄存器的格式,该寄存器存储了域访问控制信息。图中将16个可用域标记为D0到D15。


即使您不使用MMU提供的虚拟内存功能,您仍然可以将这些核心用作简单的内存保护单元:首先,通过直接映射虚拟内存到物理内存,并为每个任务分配一个不同的域,然后使用域将休眠任务的域访问权限设置为"无访问"来保护它们。
14.6.1 Page-Table-Based Access Permissions
PTE中的AP位确定页面的访问权限。AP位显示在图14.6和图14.8中。表14.6展示了MMU如何解释AP位字段中的两个位。
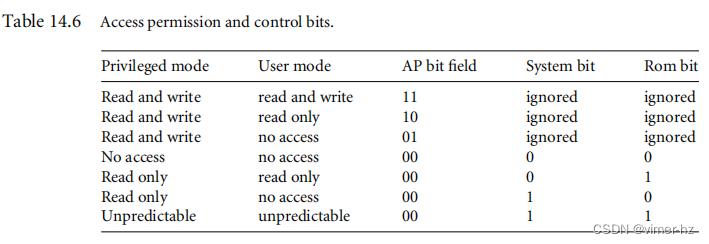
除了PTE中的AP位外,CP15:c1控制寄存器中还有两个位全局地修改对内存的访问权限:系统(S)位和只读(R)位。这些位可用于在操作期间的不同时间段从系统中提取大块内存。
设置S位将所有具有"无访问"权限的页面更改为允许特权模式任务的读访问。因此,通过改变CP15:c1中的单个位,所有标记为无访问的区域都可以立即使用,而无需更改每个PTE中的AP位字段。
改变R位将所有具有"无访问"权限的页面更改为允许特权模式和用户模式任务的读访问。同样,这个位可以加速对大块内存的访问,无需改变大量的PTE。
14.7 The Caches and Write Buffer
我们在第12章介绍了缓存和写缓冲区的基本操作。您可以使用PTE中的两个位来为内存中的每个页面配置缓存和写缓冲区(参见图14.6和图14.8)。在配置指令页时,忽略写缓冲区位,而缓存位确定缓存操作。当该位设置时,页面被缓存;当该位清除时,页面不被缓存。
在配置数据页面时,写缓冲区位有两种用途:启用或禁用页面的写缓冲区,并设置页面缓存的写策略。缓存位控制着写缓冲区位的含义。当缓存位为零时,当写缓冲区位值为1时,缓冲区位启用写缓冲区;当写缓冲区位值为0时,缓冲区位禁用写缓冲区。当缓存位设置为1时,写缓冲区被启用,并且缓冲区位的状态决定了缓存的写策略。如果缓冲区位为0,则页面使用写直通策略;如果缓冲区位被设置,则使用写回策略。请参阅表14.7,该表以表格形式展示了各种缓存和写缓冲区位的状态及其含义。
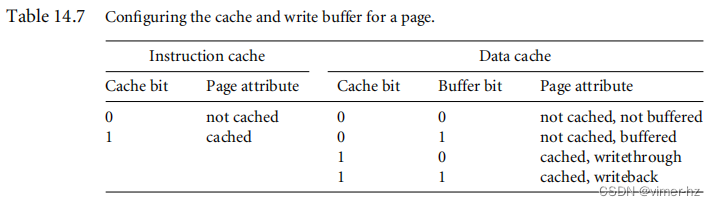
14.8 Coprocessor 15 and MMU Configuration
我们在第12章首次介绍了changeControl过程。示例14.3重新讲解了changeControl过程,该过程用于启用MMU、缓存和写缓冲区。控制MMU操作的控制寄存器值显示在表格14.8和图14.13中。ARM720T、ARM920T和ARM926EJ-S在控制寄存器的相同位置上具有控制MMU启用位0和缓存启用位2。ARM720T和ARM1022E还具有写缓冲区启用位3。ARM920T、ARM922T和ARM926EJS具有分离的指令和数据缓存,需要一个额外的位来启用I-cache,即位12。所有支持MMU的处理器核心都可以将向量表更改为高内存的地址0xffff0000,位13。

对于这三个核心,使能配置的MMU非常相似。要启用MMU、缓存和写缓冲区,您需要在控制寄存器中更改位12、位3、位2和位0。changeControl过程操作寄存器CP15:c1:c0:0,以更改控制寄存器c1中的值。示例14.3提供了一个设置控制寄存器位的小型C例程;它使用以下函数原型进行调用:
void controlSet(unsigned int value, unsigned int mask)
传递给该过程的第一个参数是一个无符号整数,其中包含您想要更改的控制值的状态。第二个参数mask是一个位模式,用于选择需要更改的位。在mask变量中设置为1的位将使CP15:c1c0寄存器中的相应位更改为value输入参数中相同位的值。如果为0,则无论value参数中的位状态如何,都不会更改控制寄存器中的位。
示例14.3 控制过程controlSet设置了CP15:c1中的控制位寄存器。该过程首先读取CP15:r3寄存器,并将其放入变量c1format中。然后,该过程使用输入的掩码值来清除c1format中需要更新的位。更新是通过将c1format与value输入参数进行或操作来完成的。最终更新的c1format被写回到CP15:c1寄存器中,以启用MMU、缓存和写缓冲区。
cpp
void controlSet(unsigned int value, unsigned int mask)
{
unsigned int c1format;
__asm{MRC p15, 0, c1format, c1, c0, 0 } /* read control register */
c1format &= ∼mask;
/* clear bits that change */
c1format |= value;
/* set bits that change */
__asm{MCR p15, 0, c1format, c1, c0, 0 } /* write control register */
}以下是一个调用controlSet过程的代码序列,用于在ARM920T中启用I-cache、D-cache和MMU:
cpp
#define ENABLEMMU 0x00000001
#define ENABLEDCACHE 0x00000004
#define ENABLEICACHE 0x00001000
#define CHANGEMMU 0x00000001
#define CHANGEDCACHE 0x00000004
#define CHANGEICACHE 0x00001000
unsigned int enable, change;
#if defined(__TARGET_CPU_ARM920T)
enable = ENABLEMMU | ENABLEICACHE | ENABLEDCACHE;
change = CHANGEMMU | CHANGEICACHE | CHANGEDCACHE;
#endif
controlSet(enable, change);14.9 The Fast Context Switch Extension
快速上下文切换扩展(FCSE)是MMU中的附加硬件,被认为是一种增强特性,可以提高ARM嵌入式系统的系统性能。FCSE使多个独立任务在内存的固定重叠区域中运行,无需在上下文切换期间清理或刷新缓存或刷新TLB。FCSE的关键特性是消除了清空缓存和TLB的必要性。
如果没有FCSE,从一个任务切换到另一个任务需要改变虚拟内存映射。如果更改涉及到两个具有重叠地址范围的任务,则缓存和TLB中存储的信息会变得无效,系统必须清空缓存和TLB。清空这些组件的过程会增加任务切换的时间,因为核心不仅必须清除无效数据的缓存和TLB,还必须重新从主存中加载数据到缓存和TLB中。
使用FCSE时,在管理虚拟内存时会有额外的地址转换。FCSE使用一个包含进程ID值的特殊重定位寄存器,在到达缓存和TLB之前修改虚拟地址。ARM将第一次转换前的虚拟内存地址称为虚拟地址(VA),将第一次转换后的地址称为修改后的虚拟地址(MVA),如图14.4所示。使用FCSE时,所有修改后的虚拟地址都是活动的。通过使用域访问权限来阻止对休眠任务的访问,来保护任务。我们在下一节中将详细讨论这一点。

在任务之间切换不涉及更改页表;它只需要将新任务的进程ID写入位于CP15中的FCSE进程ID寄存器中。由于任务切换不需要更改页表,所以在切换后缓存和TLB仍然有效,不需要清空。
使用FCSE时,每个任务必须在虚拟地址范围从0x00000000到0x1FFFFFFF的固定虚拟地址范围内执行,并且必须位于不同的32 MB的修改后的虚拟内存区域中。系统共享所有大于0x2000000的内存地址,并使用域来保护任务之间的隔离。当前运行的任务由其当前的进程ID来标识。
要利用FCSE,在编译和链接所有任务以在虚拟内存(VA)的第一个32 MB块中运行并分配唯一的进程ID。然后,使用以下重定位公式将每个任务放置在不同的32 MB修改后的虚拟内存分区中:
MVA = VA + (0x2000000 ∗ process ID) (14.2)
要计算修改后虚拟内存中任务分区的起始地址,可以将VA和任务的进程ID的值置为零,并将这些值代入方程式(14.2)中。
CP15:c13:c0寄存器中保存的值包含当前的进程ID。寄存器中的进程ID位字段宽度为7位,支持128个进程ID。寄存器的格式如图14.15所示。

示例14.4展示了一个小的例程processIDSet,用于设置FCSE中的进程ID。可以使用以下函数原型调用它:
void processIDSet(unsigned value);
示例14.4
该例程接受一个无符号整数作为输入,将其剪辑为七位,并通过将该值乘以0x20000000(32 MB)来对128取模,然后使用MCR指令将结果写入进程ID寄存器。
cpp
void processIDSet(unsigned int value)
{
unsigned int PID;
PID = value << 25;
__asm{MCR p15, 0, PID, c13, c0, 0 } /* write Process ID register */
}14.9.1 How the FCSE Uses Page Tables and Domains
为了有效使用FCSE,系统使用页表来控制区域配置和操作,并使用域来隔离任务。再次参考图14.14,该图显示了从Task 1切换到Task 2的上下文切换前后的内存布局。表14.9显示了创建图14.14所使用的数值细节。

图14.16展示了如何通过更改CP15:c3:c0中域访问寄存器的值从Task 1切换到Task 2。在任务之间切换需要更改进程ID,并在域访问寄存器中添加一个新条目。

表14.9显示Task 1被分配给域 1,而Task 2则被分配给域 2。当从Task 1切换到Task 2时,将域访问寄存器更改为允许对域 2 进行客户端访问,并且对域 1 没有访问权限。这样可以防止Task 2访问Task 1的内存空间。请注意,对于内核域 0,客户端访问权限保持不变。这使得页表可以控制对系统内存区域的访问。
通过使用"共享"域,可以在任务之间共享内存,如图14.16和表14.9中的域 15所示。共享域在图14.15中没有显示。任务可以共享一个允许客户端访问修改后的虚拟内存分区的域。这种共享内存可以被两个任务看到,并且访问权限由映射内存空间的页表项确定。
以下是在使用FCSE时执行上下文切换所需的步骤:
1.保存活动任务的上下文,并将任务置于休眠状态。
2.将待唤醒任务的进程ID写入CP15:c13:c0中。
3.通过写入CP15:c3:c0,将当前任务的域设置为无访问权限,将待唤醒任务的域设置为客户端访问权限。
4.恢复待唤醒任务的上下文。
5.恢复任务的执行。
14.9.2 Hints for Using the FCSE
■ 一个任务的大小有一个固定的最大限制为32MB。
■ 内存管理器必须使用32MB大小的固定分区,且起始地址必须是32MB的倍数。
■ 除非您想为每个任务管理一个异常向量表,否则可以使用CP15寄存器1中的V位将异常向量表放置在虚拟地址0xffff0000处。
■ 您必须定义并使用一个活动域控制系统。
■ 当进程ID从上一个进程空间变化时,核心会获取执行位于第一个32MB块内的两条指令。因此,最好从内存中的"固定"区域切换任务。
■ 如果您使用域来控制任务访问,那么正在运行的任务也会在虚拟内存中以VA + (0x2000000 * 进程ID)的形式出现为别名。
■ 如果您使用域来保护任务之间的隔离,除非愿意在上下文切换时修改级别1页表中的域字段并刷新TLB,否则最多只能同时运行16个任务。
14.10 Demonstration: A Small Virtual Memory System
这是一个小型嵌入式系统的基础原理演示,使用虚拟内存。它设计用于在ARM720T或ARM920T核心上运行。该演示提供了一个静态的多任务系统,展示了运行三个并发任务所需的基础设施。我们使用ARM ADS1.2开发套件编写了这个演示。有很多方法可以改进演示,但它的主要目的是帮助理解底层ARM MMU硬件。演示没有展示分页或交换到辅助存储器的功能。
演示中所有用户任务使用相同的执行区域,这简化了这些任务的编译和链接。每个任务被编译为一个独立的程序,在单个区域中包含文本、数据和堆栈信息。
硬件要求是一个基于ARM的评估板,其中包括一个ARM720T或ARM920T处理器核心。该示例需要从地址0x00000000开始的256 KB RAM,并且需要一种将代码和数据加载到内存中的方法。此外,还有几个内存映射的外设分布在从地址0x10000000到0x20000000的256 MB范围内。
软件要求是一个操作系统基础设施,比如前面章节中提供的SLOS。系统必须支持固定分区多任务处理。该示例仅使用1 MB和4 KB页面。但是,编码示例支持所有的页面大小。任务限制在小于1 MB,因此可以适应单个L2页表。因此,通过更改主L1页表中的单个L2 PTE即可执行任务切换。这种方法比尝试为每个任务创建和维护一整套页表,并在每次上下文切换时更改TTB地址要简单得多。更改TTB以在任务内存映之间切换将需要创建主表和所有L2系统表的三组不同的页表。这还需要额外的内存来存储这些额外的页表。交换单个L2表的目的是消除多组页表中系统信息的重复。减少重复页表的数量减少了运行系统所需的内存。
我们使用七个步骤来设置演示的MMU:
-
定义固定的系统软件区域;此固定区域在图14.5中显示。
-
为三个任务定义三个虚拟内存映射;这些映射的一般布局在图14.4中显示。
-
将步骤1和2中列出的区域定位到物理内存映射中;这是图14.5右侧所示的实现。
-
在页表区域内定义并定位页表。
-
定义用于创建和管理区域和页表的数据结构。这些结构是与实现相关的,特定于示例进行定义。但是,这些结构的一般形式对大多数简单系统来说是一个很好的起点。
-
初始化MMU、缓存和写缓冲区。
-
设置上下文切换例程,以优雅地从一个任务过渡到下一个。
我们将在下面的章节中详细介绍这些步骤。
14.10.1 Step 1: Define the Fixed System Software Regions
操作系统使用四个固定的系统软件区域:0x00000处的专用32 KB内核区域,0x8000处的32 KB共享内存区域,0x10000处的专用32 KB页表区域以及0x10000000处的256 MB外围区域(见图14.17)。我们在初始化过程中定义这些区域,并永远不会再次更改它们的页表。

特权内核区域用于存储系统软件,包括操作系统内核代码和数据。该区域使用固定寻址方式,避免在切换到系统模式上下文时重新映射的复杂性。它还包含了处理FIQ、IRQ、SWI、UND和ABT异常的向量表和堆栈。
共享内存区域位于虚拟内存中的固定地址。所有任务都使用此区域来访问共享的系统资源。共享内存区域包含了共享库以及在上下文切换期间从特权模式切换到用户模式的过渡例程。
页表区域包含五个页表。虽然页表区域大小为32 KB,但系统仅使用20 KB:16 KB用于主表,每个L2表使用1 KB。
外围区域控制系统设备I/O空间。这个区域的主要目的是将此区域设置为不缓存、不缓冲区域。您不希望输入、输出或控制寄存器受到缓存的过期数据问题或使用写缓冲区所涉及的时间序列延迟。此区域还防止用户模式访问外围设备;因此,必须通过设备驱动程序访问这些设备。此区域仅允许特权访问;不允许用户访问。在演示中,这是一个单独的区域,但在更精细的系统中,将定义更多的区域,以提供对各个设备的更细粒度的控制。
14.10.2 Step 2: Define Virtual Memory Maps for Each Task
在三个时间片间隔内运行三个用户任务。每个任务都有相同的虚拟内存映射。
每个任务在其内存映射中看到两个区域:0x400000处的专用32 KB任务区域,以及0x8000处的32 KB共享内存区域(见图14.18)。
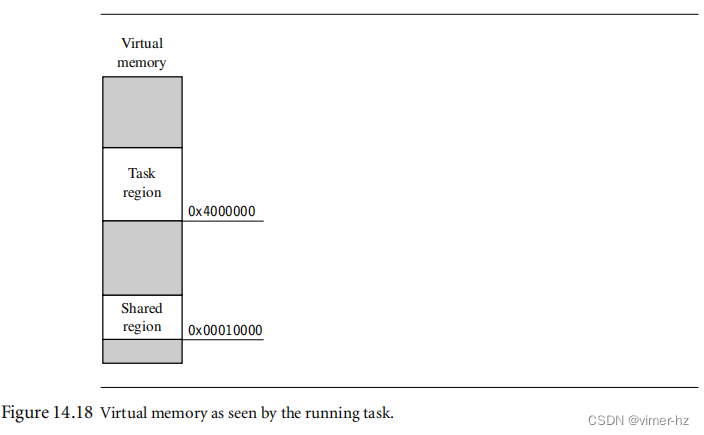
任务区域包含正在运行的用户任务的代码、数据和堆栈。当调度器从一个任务转移到另一个任务时,它必须通过改变L1页表项来重新映射任务区域,使其指向即将运行的任务的L2页表。完成这个映射后,任务区域将指向下一个运行任务的物理位置。
共享区域是一个固定的系统软件区域。其功能在第14.10.1节中描述。
14.10.3 Step 3: Locate Regions in Physical Memory
我们为演示定义的区域必须位于物理内存中不重叠或冲突的地址。表14.10显示了我们在物理内存中定位所有区域及其虚拟地址和大小的位置。该表还列出了每个区域的页面大小选择以及需要翻译的页面数,以支持每个区域的大小。
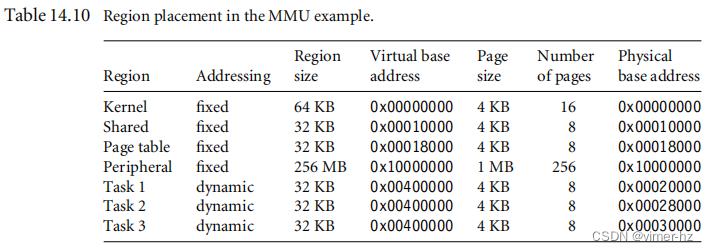
表14.10列出了在系统操作期间使用固定页表的四个区域:内核、共享内存、页表和外围区域。
任务区域在系统运行过程中动态更改页表。任务区域将相同的虚拟地址翻译为不同的物理地址,这取决于正在运行的任务。
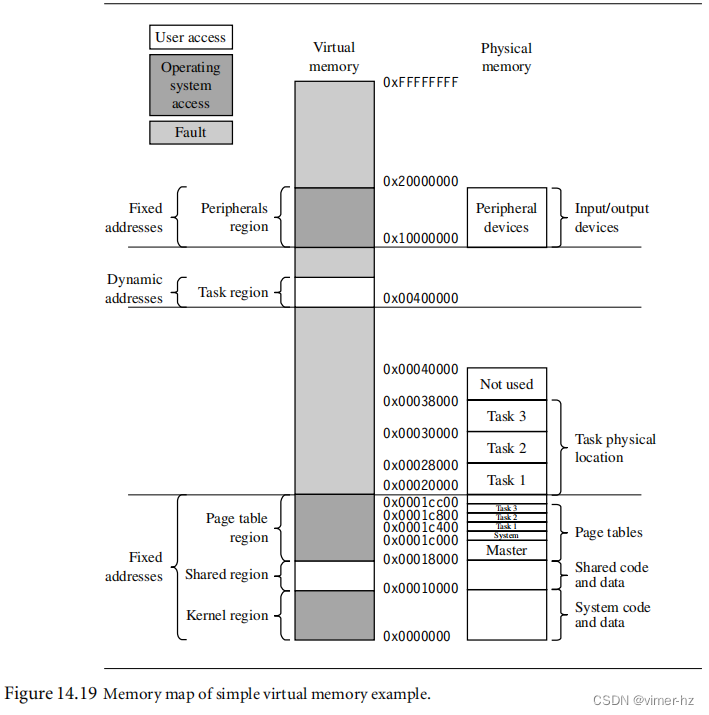
图14.19以图形方式显示了区域在虚拟内存和物理内存中的放置位置。内核、共享内存和页表区域直接映射到物理内存,作为连续页帧块。在此区域之上是专用于三个用户任务的页帧。物理内存中的任务是32 KB的固定分区,也是连续的页帧。稀疏地分布在256 MB的物理内存中的是内存映射的外围I/O设备。
14.10.4 Step 4: Define and Locate the Page Tables
我们先前分配了一个区域来保存系统中的页表。下一步是将实际的页表定位到物理内存的区域内。图14.20显示了页表区域映射到物理内存的近距离细节。这是图14.19中显示的页表的放大图。我们稍微展开了内存,以显示L1主页表和四个L2页表之间的关系。我们还展示了页表中的翻译数据的位置。
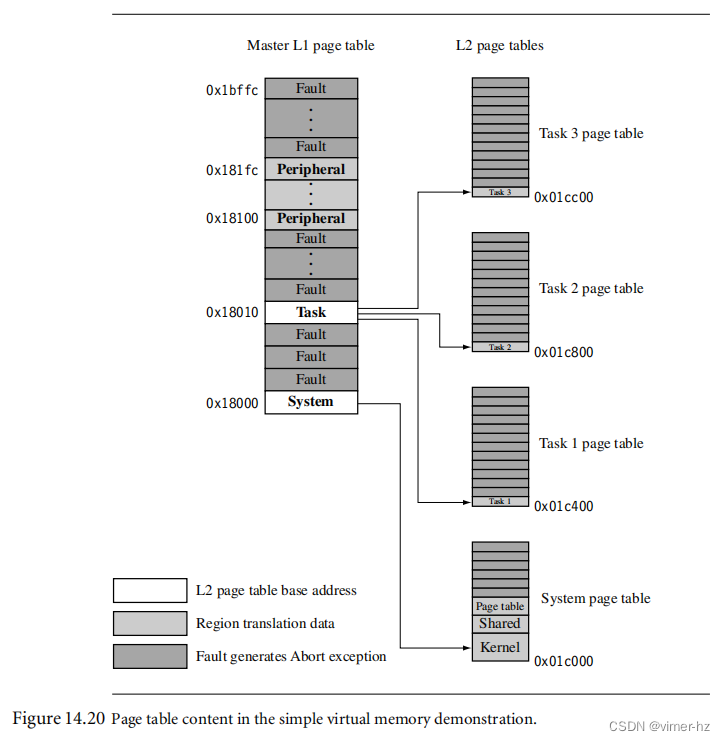
一个主L1页表定位L2表并翻译外围区域的1 MB部分。系统L2页表包含三个系统区域的翻译地址数据:内核区域、共享内存区域和页表区域。有三个任务L2页表,分别映射到三个并发任务的物理地址。
运行时只有五个页表中的三个同时处于活动状态:L1主表、L2系统表和三个L2任务页表中的一个。
调度器通过在上下文切换期间重新映射任务区域来控制哪个任务处于活动状态,哪些任务处于休眠状态。具体而言,在上下文切换期间,位于地址0x18010处的主L1页表项会更改为指向下一个活动任务的L2页表基址。
14.10.5 Step 5: Define Page Table and Region Data Structures
对于这个例子,我们定义了两个数据结构来配置和控制系统。这两个数据结构代表了用于定义和初始化前几节中讨论的页表和区域的实际代码。我们定义了两种数据类型,一种是包含页表数据的Pagetable类型,另一种是定义和控制系统中每个区域的Region类型。
Pagetable结构的类型定义,以及对Pagetable结构成员的描述如下:
cpp
typedef struct {
unsigned int vAddress;
unsigned int ptAddress;
unsigned int masterPtAddress;
unsigned int type;
unsigned int dom;
} Pagetable;■ vAddress标识由段条目或L2页表控制的虚拟内存中1MB部分的起始地址。
■ ptAddress是页表在虚拟内存中的位置。
■ masterPtAddress是父主L1页表的地址。如果该表是L1表,则该值与ptAddress相同。
■ type标识页表的类型,可以是COARSE、FINE或MASTER。
■ dom设置分配给L1表项的1MB内存块的域。
我们使用Pagetable类型来定义系统中使用的五个页表。这些Pagetable结构共同形成了一个页表数据块,我们使用它来管理、填充、定位、识别和设置所有活动和非活动页表的域。在接下来的演示中,我们将称这个Pagetables块为页表控制块(PTCB)。
前面章节中描述的五个Pagetables在图14.20中显示出来,并附带它们的初始化值,它们分别是:
cpp
#define FAULT 0
#define COARSE 1
#define MASTER 2
#define FINE 3
/* Page Tables */
/* VADDRESS, PTADDRESS, PTTYPE, DOM */
Pagetable masterPT = {0x00000000, 0x18000, 0x18000, MASTER, 3};
Pagetable systemPT = {0x00000000, 0x1c000, 0x18000, COARSE, 3};
Pagetable task1PT = {0x00400000, 0x1c400, 0x18000, COARSE, 3};
Pagetable task2PT = {0x00400000, 0x1c800, 0x18000, COARSE, 3};
Pagetable task3PT = {0x00400000, 0x1cc00, 0x18000, COARSE, 3};Region结构的类型定义,以及对Region结构成员的描述如下:
cpp
typedef struct {
unsigned int vAddress;
unsigned int pageSize;
unsigned int numPages;
unsigned int AP;
unsigned int CB;
unsigned int pAddress;
Pagetable *PT;
} Region;■ vAddress是区域在虚拟内存中的起始地址。
■ pageSize是虚拟页的大小。
■ numPages是该区域中页面的数量。
■ AP是区域的访问权限。
■ CB是区域的缓存和写缓冲区属性。
■ pAddress是区域在虚拟内存中的起始地址。
■ *PT是指向包含该区域的Pagetable的指针。
所有的Region数据结构共同形成了第二个数据块,我们使用它来定义系统中使用的区域的大小、位置、访问权限、缓存和写缓冲区操作以及页表位置。在接下来的演示中,我们将称这个Region块为区域控制块(RCB)。
这里有七个Region结构,它们定义了前面章节中描述的区域,并在图14.19中显示出来。以下是RCB中四个系统软件和三个任务区域的初始化值:
cpp
#define NANA 0x00
#define RWNA 0x01
#define RWRO 0x02
#define RWRW 0x03
/* NA = no access, RO = read only, RW = read/write */
#if defined(__TARGET_CPU_ARM920T)
#define cb 0x0
#define cB 0x1
#define WT 0x2
#define WB 0x3
#endif
/* 720 */
#if defined(__TARGET_CPU_ARM720T)
#define cb 0x0
#define cB 0x1
#define Cb 0x2
#define WT 0x3
#endif
/* cb = not cached/not buffered */
/* cB = not Cached/Buffered */
/* Cb = Cached/not Buffered */
/* WT = write through cache */
/* WB = write back cache */
/* REGION TABLES */
/* VADDRESS, PAGESIZE, NUMPAGES, AP, CB, PADDRESS, &PT */
Region kernelRegion
= {0x00000000, 4, 16, RWNA, WT, 0x00000000, &systemPT};
Region sharedRegion
= {0x00010000, 4, 8, RWRW, WT, 0x00010000, &systemPT};
Region pageTableRegion
= {0x00018000, 4, 8, RWNA, WT, 0x00018000, &systemPT};
Region peripheralRegion
= {0x10000000, 1024, 256, RWNA, cb, 0x10000000, &masterPT};
/* Task Process Regions */
Region t1Region
= {0x00400000, 4, 8, RWRW, WT, 0x00020000, &task1PT};
Region t2Region
= {0x00400000, 4, 8, RWRW, WT, 0x00028000, &task2PT};
Region t3Region
= {0x00400000, 4, 8, RWRW, WT, 0x00030000, &task3PT}14.10.6 Step 6: Initialize the MMU, Caches, and Write Buffer
在激活MMU、缓存和写缓冲区之前,它们必须进行初始化。PTCB和RCB保存了这三个组件的配置数据。有五个部分需要初始化MMU:
-
通过用FAULT条目填充它们来初始化主存中的页表。
-
使用映射将区域映射到物理内存,填充页表。
-
激活页表。
-
分配域访问权限。
-
启用内存管理单元和高速缓存硬件。

前四个部分配置系统,最后一个部分启用系统。在接下来的章节中,我们提供了执行初始化过程的五个部分的例程;这些例程按功能和示例编号在图14.21中列出。
14.10.6.1 Initializing the Page Tables in Memory
初始化MMU的第一部分是将页表设置为已知状态。最简单的方法是用FAULT页表条目填充页表。使用FAULT条目可以确保在PTCB定义的范围之外不存在有效的转换。通过将所有活动页表中的所有页表条目设置为FAULT,系统将生成一个异常中断,以指示使用PTCB填充的条目稍后才会被填入。
例子14.5
函数mmuInitPT通过使用分配给页表的内存区域并设置FAULT值来初始化页表。它使用以下函数原型进行调用:
void mmuInitPT(Pagetable *pt);
这个例程接受一个参数,即指向PTCB中的Pagetable的指针。
cpp
void mmuInitPT(Pagetable *pt)
{
int index; /* number of lines in PT/entries written per loop*/
unsigned int PTE, *PTEptr; /* points to page table entry in PT */
PTEptr = (unsigned int *)pt->ptAddress; /* set pointer base PT */
PTE = FAULT;
switch (pt->type)
{
case COARSE: {index = 256/32; break;}
case MASTER: {index = 4096/32; break;}
#if defined(__TARGET_CPU_ARM920T)
case FINE: {index = 1024/32; break;} /* no FINE PT in 720T */
#endif
default:
{
printf("mmuInitPT: UNKNOWN pagetable type\n");
return -1;
}
}
__asm
{
mov r0, PTE
mov r1, PTE
mov r2, PTE
mov r3, PTE
}
for (; index != 0; index--)
{
__asm
{
STMIA PTEptr!, {r0-r3} /* write 32 entries to table */
STMIA PTEptr!, {r0-r3}
STMIA PTEptr!, {r0-r3}
STMIA PTEptr!, {r0-r3}
STMIA PTEptr!, {r0-r3}
STMIA PTEptr!, {r0-r3}
STMIA PTEptr!, {r0-r3}
STMIA PTEptr!, {r0-r3}
}
}
return 0;
}mmuInitPT从基本页表地址PTEptr开始,并用FAULT条目填充页表。表的大小通过读取pt->type中定义的Pagetable类型来确定。表类型可以是具有4096个条目的主L1页表,具有256个条目的粗糙L2页表,或具有1024个条目的细致L2页表。
该例程通过使用循环将小块写入内存来填充表格。例程根据页表中的条目数除以每个循环写入的条目数来确定要写入的块数。switch语句选择Pagetable类型,并跳转到设置表索引大小的情况。通过执行填充表的循环来完成过程。请注意__asm关键字用于调用内联汇编程序;这通过使用stmia存储多个指令来减少循环的执行时间。
14.10.6.2 Filling Page Tables with Translations
初始化MMU的第二部分是将RCB中保存的数据转换为页表条目,并将它们复制到页表中。我们提供了几个例程来将RCB中的数据转换为页表条目。第一个高级例程mmuMapRegion确定了页表的类型,然后调用三个例程之一来创建页表条目:mmuMapSectionTableRegion、mmuMapCoarseTableRegion或mmuMapFineTableRegion。
为了方便将来的代码移植,我们建议不使用tiny pages和mmuMapFineTableRegion例程,因为ARMv6架构不使用tiny page。在ARMv6架构中,细粒度页表类型也已被移除,因为没有tiny pages的需要。
下面是四个例程的描述:
-
mmuMapRegion例程确定页表类型并跳转到下面列出的例程之一;示例代码见14.6节。
-
mmuMapSectionTableRegion例程使用section条目填充L1主表;示例代码见14.7节。
-
mmuMapCoarseTableRegion例程使用region条目填充L2粗糙页表;示例代码见14.8节。
-
mmuMapFineTableRegion例程使用region条目填充L2细粒度页表;示例代码见14.9节。
以下是这四个例程的C函数原型列表:
int mmuMapRegion(Region *region);
void mmuMapSectionTableRegion(Region *region);
int mmuMapCoarseTableRegion(Region *region);
int mmuMapFineTableRegion(Region *region);
这四个过程都有一个输入参数,即指向包含生成页表条目所需配置数据的Region结构的指针。
示例14.6中是选择页表类型的高级例程。
cpp
int mmuMapRegion(Region *region)
{
switch (region->PT->type)
{
case SECTION:
/* map section in L1 PT */
{
mmuMapSectionTableRegion(region);
break;
}
case COARSE:
/* map PTE to point to COARSE L2 PT */
mmuMapCoarseTableRegion(region);
break;
}
#if defined(__TARGET_CPU_ARM920T)
case FINE:
/* map PTE to point to FINE L2 PT */
{
mmuMapFineTableRegion(region);
break;
}
#endif
default:
{
printf("UNKNOWN page table type\n");
return -1;
}
}
return 0;
}在Region结构中,包含了指向Pagetable的指针,该Pagetable中包含了区域翻译数据。这个例程确定了页表类型region->PT->type,并调用一个例程将该区域以指定的页表类型的格式映射到页表中。
对于三种类型的页表(section,粗糙和细粒度),分别有各自独立的过程(参见第14.4节)。
以下是其中之一的三个例程,用于将区域数据转换为页表条目。
cpp
void mmuMapSectionTableRegion(Region *region)
{
int i;
unsigned int *PTEptr, PTE;
PTEptr = (unsigned int *)region->PT->ptAddress; /* base addr PT */
PTEptr += region->vAddress >> 20; /* set to first PTE in region */
PTEptr += region->numPages - 1; /* set to last PTE in region */
PTE = region->pAddress & 0xfff00000; /* set physical address */
PTE |= (region->AP & 0x3) << 10; /* set Access Permissions */
PTE |= region->PT->dom << 5; /* set Domain for section */
PTE |= (region->CB & 0x3) << 2; /* set Cache & WB attributes */
PTE |= 0x12;
/* set as section entry */
for (i =region->numPages - 1; i >= 0; i--) /* fill PTE in region */
{
*PTEptr-- = PTE + (i << 20);
/* i = 1 MB section */
}
}mmuMapSectionTableRegion过程首先将一个局部指针变量PTEptr设置为主L1页表的基地址。然后,它使用区域的虚拟起始地址创建一个索引,该索引指向区域页表条目在页表中的位置。这个索引被加到变量PTEptr上,使得PTEptr指向页表中区域条目的起始位置。下一行代码计算出区域的大小,并将该值加到PTEptr上。现在,变量PTEptr指向区域的最后一个PTE。
PTEptr变量设置为区域的末尾,这样我们可以在填充页表条目的循环中使用倒计数器。
接下来,该例程使用Region结构中的值构建一个section页表条目,并将其保存在局部变量PTE中。通过一系列的按位或操作,从起始物理地址、访问权限、域和缓存以及写缓冲区属性构造了这个PTE。PTE的格式如图14.6所示。
现在,PTE中包含了指向区域第一个物理地址及其属性的指针。计数器变量i用于两个目的:作为页表的偏移量,并且加到PTE变量上,以增加页面帧的物理地址转换。请记住,在演示中,所有的区域都映射到物理内存中的连续页面帧。
该过程通过将所有的区域PTE写入页表来结束。它从最后一个翻译条目开始,逐个向前计数到第一个翻译条目。
cpp
int mmuMapCoarseTableRegion(Region *region)
{
int i,j;
unsigned int *PTEptr, PTE;
unsigned int tempAP = region->AP & 0x3;
PTEptr = (unsigned int *)region->PT->ptAddress; /* base addr PT */
switch (region->pageSize)
{
case LARGEPAGE:
{
PTEptr += (region->vAddress & 0x000ff000) >> 12; /* 1st PTE */
PTEptr += (region->numPages*16) - 1; /* region last PTE */
PTE = region->pAddress & 0xffff0000; /* set physical address */
PTE |= tempAP << 10; /* set Access Permissions subpage 3 */
PTE |= tempAP << 8;
/* subpage 2 */
PTE |= tempAP << 6;
/* subpage 1 */
PTE |= tempAP << 4;
/* subpage 0 */
PTE |= (region->CB & 0x3) << 2; /* set cache & WB attributes */
PTE |= 0x1;
/* set as LARGE PAGE */
/* fill in table entries for region */
for (i = region->numPages-1; i >= 0; i--)
{
for (j = 15 ; j >= 0; j--)
*PTEptr-- = PTE + (i << 16); /* i = 64 KB large page */
}
break;
}
case SMALLPAGE:
{
PTEptr += (region->vAddress & 0x000ff000) >> 12; /* first */
PTEptr += (region->numPages - 1);
/* last PTEptr */
PTE = region->pAddress & 0xfffff000; /* set physical address */
PTE |= tempAP << 10; /* set Access Permissions subpage 3 */
PTE |= tempAP << 8;
/* subpage 2 */
PTE |= tempAP << 6;
/* subpage 1 */
PTE |= tempAP << 4;
/* subpage 0 */
PTE |= (region->CB & 0x3) << 2; /* set cache & WB attrib */
PTE |= 0x2;
/* set as SMALL PAGE */
/* fill in table entries for region */
for (i = region->numPages - 1; i >= 0; i--)
{
*PTEptr-- = PTE + (i << 12); /* i = 4 KB small page */
}
break;
}
default:
{
printf("mmuMapCoarseTableRegion: Incorrect page size\n");
return -1;
}
}
return 0;
}该例程首先设置一个名为tempAP的局部变量,用于保存区域中页面或子页面的访问权限。接下来,它将变量PTEptr设置为指向将保存映射区域的页表的基地址。
然后,该过程根据是大页面还是小页面进行处理。这两种情况的算法是相同的,只是PTE的格式和写入页表的方式不同。
此时,变量PTEptr包含L2页表的起始地址。然后,该例程使用区域region->vAddress的起始地址来计算在页表中指向区域第一个条目的索引。将该索引值加到PTEptr上。
接下来一行代码计算出区域的大小,并将该值加到PTEptr上。现在,PTEptr指向区域的最后一个PTE。
然后,该例程根据传入的区域值构建一个大页面或小页面的页表条目变量PTE。该例程使用一系列的按位或操作来从区域中的起始物理地址、访问权限以及缓存和写缓冲区属性构建PTE。请参考图14.8来查看大页面和小页面PTE的格式。
现在,PTE包含指向区域第一个页面帧的物理地址的指针。计数器变量i用于两个目的:首先,它是页表的偏移量;其次,它加到PTE变量上,以修改地址转换位字段,使其指向物理内存中的下一个更低的页面帧。该例程最后通过将所有区域的PTE写入页表来结束。请注意,在LARGEPAGE情况下有一个嵌套的循环:j循环将所需的相同PTE写入粗略页表以映射一个大页面(详见第14.4节)。
示例14.9
这个示例填充了一个细粒度页表的区域翻译信息。细粒度页表在ARM720T中不可用,并在v6架构中已停用。为了与这些变化保持兼容性,我们建议在新项目中避免使用细粒度页表。
cpp
#if defined(__TARGET_CPU_ARM920T)
int mmuMapFineTableRegion(Region *region)
{
int i,j;
unsigned int *PTEptr, PTE;
unsigned int tempAP = region->AP & 0x3;
PTEptr = (unsigned int *)region->PT->ptAddress; /* base addr PT */
switch (region->pageSize)
{
case LARGEPAGE:
{
PTEptr += (region->vAddress & 0x000ffc00) >> 10; /* first PTE*/
PTEptr += (region->numPages*64) - 1;
/* last PTE */
PTE = region->pAddress & 0xffff0000; /* get physical address */
PTE |= tempAP << 10; /* set Access Permissions subpage 3 */
PTE |= tempAP << 8;
/* subpage 2 */
PTE |= tempAP << 6;
/* subpage 1 */
PTE |= tempAP << 4;
/* subpage 0 */
PTE |= (region->CB & 0x3) << 2; /* set cache & WB attrib */
PTE |= 0x1;
/* set as LARGE PAGE */
/* fill in table entries for region */
for (i = region->numPages-1; i >= 0; i--)
{
for (j = 63 ; j >= 0; j--)
*PTEptr-- = PTE + (i << 16); /* i = 64 KB large page */
}
break;
}
case SMALLPAGE:
{
PTEptr += (region->vAddress & 0x000ffc00) >> 10; /* first PTE*/
PTEptr += (region->numPages*4) - 1;
/* last PTE */
PTE = region->pAddress & 0xfffff000; /* get physical address */
PTE |= tempAP << 10; /* set Access Permissions subpage 3 */
PTE |= tempAP << 8;
/* subpage 2 */
PTE |= tempAP << 6;
/* subpage 1 */
PTE |= tempAP << 4;
/* subpage 0 */
PTE |= (region->CB & 0x3) << 2; /* set cache & WB attrib */
PTE |= 0x2;
/* set as SMALL PAGE */
/* fill in table entries for region */
for (i = region->numPages-1; i >= 0; i--)
{
for (j = 3 ; j >= 0; j--)
*PTEptr-- = PTE + (i << 12); /* i = 4 KB small page */
}
break;
}
case TINYPAGE:
{
PTEptr += (region->vAddress & 0x000ffc00) >> 10; /* first */
PTEptr += (region->numPages - 1);
/* last PTEptr */
PTE = region->pAddress & 0xfffffc00; /* get physical address */
PTE |= tempAP << 4;
/* set Access Permissions */
PTE |= (region->CB & 0x3) << 2; /* set cache & WB attribu */
PTE |= 0x3;
/* set as TINY PAGE */
/* fill table with PTE for region; from last to first */
for (i =(region->numPages) - 1; i >= 0; i--)
{
*PTEptr-- = PTE + (i << 10);
/* i = 1 KB tiny page */
}
break;
}
default:
{
printf("mmuMapFineTableRegion: Incorrect page size\n");
return -1;
}
}
return 0;
}
#endif该例程开始设置一个名为tempAP的局部变量,用于保存区域中页面或子页面的访问权限。该例程不支持具有不同访问权限的子页面。接下来,该例程将变量PTEptr设置为指向将保存精细页的区域的页表的基地址。
然后,该例程根据大页面、小页面或微小页面进行处理。这三种情况下的算法是相同的;只是PTE的格式和写入页表的方式不同。
在此时,变量PTEptr包含L2页表的起始地址。然后,该例程使用区域region->vAddress的起始地址来计算在页表中指向区域第一个条目的索引。将该索引值加到PTEptr上。
下一行代码确定区域的大小,并将该值加到PTEptr上。现在,PTEptr指向区域的最后一个PTE。
接下来,该例程根据区域中的值构建一个大页面、小页面或微小页面的PTE。通过一系列的按位或操作,将从区域中的起始物理地址、访问权限以及缓存和写缓冲区属性构建PTE。图14.8显示了大页面、小页面和微小页面的PTE格式。
现在,PTE包含指向第一个页面帧的物理地址的指针,以及区域的属性。计数器变量i用于两个目的:它是页表的偏移量,并且它加到PTE变量上,以修改地址转换,使其指向物理内存中下一个较低的页面帧。该例程通过循环直到将区域的所有PTE映射到页表中来结束。注意,在LARGEPAGE和SMALLPAGE情况下有一个嵌套循环:j循环将所需的相同PTE写入细粒度页表以正确映射给定页面。
14.10.6.3 Activating a Page Table
页表可以存在于内存中,但不被MMU硬件使用。这种情况发生在任务处于休眠状态并且其页表被映射到非活动虚拟内存之外时。然而,任务仍然驻留在物理内存中,因此当发生上下文切换以激活它时,它立即可用。
初始化MMU的第三部分是激活执行位于固定区域的代码所需的页表。
例如14.10
例程mmuAttachPT通过将地址放入CP15:c2:c0寄存器中的TTB来激活L1主页表,或者通过将其基地址放入L1主页表条目中来激活L2页表。
可以使用以下函数原型来调用它:
int mmuAttachPT(Pagetable *pt);
该过程接受一个参数,即要激活并添加从虚拟内存到物理虚拟内存的新转换的Pagetable指针。
cpp
int mmuAttachPT(Pagetable *pt) /* attach L2 PT to L1 master PT */
{
unsigned int *ttb, PTE, offset;
ttb = (unsigned int *)pt->masterPtAddress; /* read ttb from PT */
offset = (pt->vAddress) >> 20; /* determine PTE from vAddress */
switch (pt->type)
{
case MASTER:
{
__asm{ MCR p15, 0, ttb, c2, c0, 0 } ; /* TTB -> CP15:c2:c0 */
break;
}
case COARSE:
{
/* PTE = addr L2 PT | domain | COARSE PT type*/
PTE = (pt->ptAddress & 0xfffffc00);
PTE |= pt->dom << 5;
PTE |= 0x11;
ttb[offset] = PTE;
break;
}
#if defined(__TARGET_CPU_ARM920T)
case FINE:
{
/* PTE = addr L2 PT | domain | FINE PT type*/
PTE = (pt->ptAddress & 0xfffff000);
PTE |= pt->dom << 5;
PTE |= 0x13;
ttb[offset] = PTE;
break;
}
#endif
default:
{
printf("UNKNOWN page table type\n");
return -1;
}
}
return 0;
}该例程的第一步是准备两个变量,即L1主页表的基地址ttb和L1页表中的偏移量offset。从页面表的虚拟地址创建偏移量变量。要计算偏移量,将虚拟地址右移20位以将其除以1 MB。将此偏移量添加到主L1基地址上生成指向表示1 MB区域转换的L1主表内部地址的指针。
该过程使用Pagetable类型pt->type变量将页面表附加到MMU硬件,以切换到附加页面表的情况。下面描述了三种可能的情况。
Master情况附加主L1页表。该例程使用汇编语言的MCR指令将此特殊表附加到CP15:c2:c0寄存器中。
Coarse情况将粗略页表附加到主L1页表。此情况需要将存储在Pagetable结构中的L2页表地址与域和粗略表类型组合起来构建PTE。然后,将PTE写入L1页表,使用先前计算的偏移量。粗略PTE的格式如图14.6所示。
Fine情况将细粒度的L2页表附加到主L1页表。此例程需要将找到在Pagetable结构中存储的L2页表地址与域和细粒度表类型相结合以构建PTE。然后,将PTE写入L1页表,使用先前计算的偏移量。
前几个部分介绍了在初始化MMU时对页表进行条件、加载和激活的例程。最后两个部分设置域访问权限并启用MMU。
14.10.6.4 Assigning Domain Access and Enabling the MMU
初始化MMU的第四部分是配置系统的域访问权限。示例中不使用FCSE,也不需要快速地公开和隐藏大块内存,因此无需在CP:c1:c0寄存器中使用S和R访问控制位。这意味着在页表中定义的访问权限足以保护系统,并且有理由使用域。
然而,硬件要求所有活动内存区域都具有域分配并被授予域访问特权。最小域配置将所有区域放置在同一域中,并将域访问设置为客户机访问。这种域配置使得页表中的访问权限条目成为唯一的活动权限系统。
在本示例中,所有区域都被分配到域3,并具有客户机域访问权限。其他域未使用,并且由L1主页表中未使用的页表条目的错误条目屏蔽。域分配在主L1页表中完成,并在CP15:c3:c0寄存器中定义域访问权限。
示例14.11
domainAccessSet是一个设置域访问控制寄存器CP15:c3:c0:0中16个域的访问权限的例程。可以使用以下函数原型从C中调用它:
void domainAccessSet(unsigned int value, unsigned int mask);
传递给该过程的第一个参数是一个无符号整数,其中包含设置16个域的域访问权限的位字段。第二个参数定义需要更改其访问权限的域。该例程首先读取CP15:r3寄存器,并将其放入变量c3format中。然后,该例程使用输入的掩码值来清除c3format中需要更新的位。更新通过将c3format与valueinput参数进行逻辑或运算来完成。最后,更新后的c3format写回到CP15:c3寄存器中以设置域访问权限。
cpp
void domainAccessSet(unsigned int value, unsigned int mask)
{
unsigned int c3format;
__asm{MRC p15, 0, c3format, c3, c0, 0 } /* read domain register */
c3format &= ∼mask;
/* clear bits that change */
c3format |= value;
/* set bits that change */
__asm{MCR p15, 0, c3format, c3, c0, 0 } /* write domain register */
}启用MMU是MMU初始化过程的第五个也是最后一个部分。例程controlSet(示例14.3)用于启用MMU。建议从一个"固定"的地址区域调用controlSet过程。
14.10.6.5 Putting It All Together: Initializing the MMU for the Demonstration.
例程mmuInit调用在前几节中描述的例程以初始化演示中的MMU。在阅读代码的这一部分时,回顾第14.10.5节中展示的控制块将会有所帮助。
可以使用以下C函数原型调用该例程:
void mmuInit(void)
示例14.12
该示例调用了前面描述的初始化MMU过程的五个例程。这五个部分在示例代码中标记为注释。
mmuInit从初始化页表和映射特权系统区域开始。第一个部分使用对例程mmuInitPT的调用来初始化固定的系统区域。这些调用使用FAULT值填充L1主页表和L2页表。该例程调用mmuInitPT五次:一次用于初始化L1主页表,一次用于初始化系统L2页表,然后再次调用mmuInitPT三次以初始化三个任务页表:
cpp
#define DOM3CLT 0x00000040
#define CHANGEALLDOM 0xffffffff
#define ENABLEMMU 0x00000001
#define ENABLEDCACHE 0x00000004
#define ENABLEICACHE 0x00001000
#define CHANGEMMU 0x00000001
#define CHANGEDCACHE 0x00000004
#define CHANGEICACHE 0x00001000
#define ENABLEWB 0x00000008
#define CHANGEWB 0x00000008
void mmuInit()
{
unsigned int enable, change;
/* Part 1 Initialize system (fixed) page tables */
mmuInitPT(&masterPT); /* init master L1 PT with FAULT PTE */
mmuInitPT(&systemPT); /* init system L2 PT with FAULT PTE */
mmuInitPT(&task3PT); /* init task 3 L2 PT with FAULT PTE */
mmuInitPT(&task2PT); /* init task 2 L2 PT with FAULT PTE */
mmuInitPT(&task1PT); /* init task 1 L2 PT with FAULT PTE */
/* Part 2 filling page tables with translation & attribute data */
mmuMapRegion(&kernelRegion); /* Map kernelRegion SystemPT */
mmuMapRegion(&sharedRegion); /* Map sharedRegion SystemPT */
mmuMapRegion(&pageTableRegion); /* Map pagetableRegion SystemPT */
mmuMapRegion(&peripheralRegion);/* Map peripheralRegion MasterPT */
mmuMapRegion(&t3Region); /* Map task3 PT with Region data */
mmuMapRegion(&t2Region); /* Map task3 PT with Region data */
mmuMapRegion(&t1Region); /* Map task3 PT with Region data */
/* Part 3 activating page tables */
mmuAttachPT(&masterPT); /* load L1 TTB to cp15:c2:c0 register */
mmuAttachPT(&systemPT); /* load L2 system PTE into L1 PT */
mmuAttachPT(&task1PT); /* load L2 task 1 PTE into L1 PT */
/* Part 4 Set Domain Access */
domainAccessSet(DOM3CLT , CHANGEALLDOM); /* set Domain Access */
/* Part 5 Enable MMU, caches and write buffer */
#if defined(__TARGET_CPU_ARM720T)
enable = ENABLEMMU | ENABLECACHE | ENABLEWB ;
change = CHANGEMMU | CHANGECACHE | CHANGEWB ;
#endif
#if defined(__TARGET_CPU_ARM920T)
enable = ENABLEMMU | ENABLEICACHE | ENABLEDCACHE ;
change = CHANGEMMU | CHANGEICACHE | CHANGEDCACHE ;
#endif
controlSet(enable, change);
/* enable cache and MMU */
}第二部分通过调用mmuMapRegion七次来将系统中的七个区域映射到它们的页表中:四次映射内核、共享、页表和外围设备区域,三次映射三个任务区域。mmuMapRegion将控制块中的数据转换为页表项,然后写入页表。
初始化MMU的第三部分是激活启动系统所需的页表。通过调用mmuAttachPT三次完成此操作。首先,它通过将其基地址加载到CP15:c2:c0中的TTB条目中来激活主L1页表。然后,该例程激活L2系统页表。外围设备区域由位于主L1页表中的1MB页组成,在激活主L1表时也会激活该区域。第三部分通过调用mmuAttachPT来激活系统启用后运行的第一个任务,示例中的第一个任务是任务1。
初始化MMU的第四部分是通过调用domainAccessSet来设置域访问权限。所有区域都分配给域3,并将域3的访问权限设置为客户端访问。
mmuInit通过调用controlSet来启用MMU和缓存,从而完成第五部分。
当mmuInit例程完成时,MMU将被初始化并启用。建立多任务演示系统的最后一个任务是定义在两个任务之间进行上下文切换所需的过程步骤。
14.10.7 Step 7: Establish a Context Switch Procedure
在演示系统中,上下文切换相对简单。执行上下文切换有六个步骤:
-
保存当前活动任务的上下文,并将该任务置于休眠状态。
-
刷新缓存;如果使用写回策略,则可能需要清理D缓存。
-
刷新TLB以移除即将退出的任务的翻译信息。
-
配置MMU以使用新的页表,将共享的虚拟内存执行区域翻译为等待唤醒的任务在物理内存中的位置。
-
恢复等待唤醒任务的上下文。
-
恢复已恢复任务的执行。
//这就是执行上下文切换的所有开销啊!!!
执行以上所有步骤所需的例程已在前面的部分中介绍过。我们在这里列出了程序。第1、5和6部分已在第11章中提供;有关更多详细信息,请参考该章节。第2、3和4部分是支持使用MMU进行上下文切换所需的补充部分,并在此处显示了从任务1切换到任务2所需的参数。
cpp
SAVE 要退出任务的上下文;/* 第1部分,在第11章中显示 */
flushCache(); /* 第2部分,在第12章中显示 */
flushTLB(); /* 第3部分,在示例14.2中显示 */
mmuAttachPT(&task2PT); /* 第4部分,在示例14.10中显示 */
RESTORE 要唤醒任务的上下文;/* 第5部分,在第11章中显示 */
RESUME 已恢复任务的执行;/* 第6部分,在第11章中显示 */14.11 The Demonstration as mmuSLOS
许多关于MMU演示代码的概念和示例已经被纳入到一个功能控制系统中,我们称之为mmuSLOS。它是在第11章介绍的SLOS控制系统的扩展。
mpuSLOS是SLOS的内存保护单元扩展,在第13章中进行了描述。我们使用mpuSLOS变体作为mmuSLOS的基本源代码。这三个变体可以在出版商的网站上找到。我们对mpuSLOS代码进行了三个重要的更改:
■ MMU表在mmuSLOS初始化阶段被创建。
■ 应用任务被构建为在0x400000处执行,但加载到不同的物理地址。每个应用任务在以执行地址开始的虚拟内存中执行。堆栈顶部位于距离执行地址偏移32KB的位置。
■ 每次调度程序调用时,MMU表中的活动32KB页面会更改,以反映新的活动应用程序/任务。
14.12 Summary
这一章介绍了内存管理和虚拟内存系统的基础知识。
MMU的一个关键功能是能够将任务作为独立程序在其自己的私有虚拟内存空间中运行。
虚拟内存系统的一个重要特性是地址重定位。地址重定位是将处理器核心发出的地址转换为主存中的不同地址。这个转换由MMU硬件完成。
在虚拟内存系统中,虚拟内存通常分为固定区域和动态区域。在固定区域,页面表中映射的转换数据在正常操作过程中不会改变;而在动态区域中,虚拟内存和物理内存之间的内存映射经常发生变化。
页表包含了虚拟页面信息的描述。一个页表项(PTE)将虚拟内存中的页面转换为物理内存中的页面帧。页表项按照虚拟地址进行组织,并包含了将页面映射到页面帧所需的转换数据。
ARM MMU的功能包括:
■ 读取一级和二级页表,并将其加载到TLB中
■ 在TLB中存储最近的虚拟-物理内存地址转换
■ 执行虚拟-物理地址转换
■ 强制访问权限并配置缓存和写缓冲区
ARM MMU的另一个特殊功能是快速上下文切换扩展。快速上下文切换扩展在多任务环境中提高了性能,因为在上下文切换期间不需要刷新缓存或TLB。
提供了一个小型虚拟内存系统的工作示例,详细介绍了如何设置MMU以支持多任务。设置演示的步骤包括定义在虚拟内存的固定系统软件中使用的区域,为每个任务定义虚拟内存映射,将固定区域和任务区域定位到物理内存映射中,定义并定位页表在页表区域内,定义创建和管理区域和页表所需的数据结构,通过使用定义的区域数据初始化MMU以创建页表项并将其写入页表,并建立上下文切换过程以从一个任务切换到下一个任务。
Chapter15 The Future of the Architecture
1999年10月,ARM开始考虑未来的架构方向,最终演变为ARMv6,并首次应用于名为ARM1136J-S的新产品中。在这个时候,ARM已经设计了许多不同应用的方案,并且需要评估每个方案的未来需求,以及ARM将来可能用于的新应用领域。
随着系统级芯片设计变得越来越复杂,ARM处理器在拥有多个处理单元和子系统的系统中成为中央处理器。特别是便携式和移动计算市场为ARM带来了新的软件和性能挑战。需要解决的问题包括便携设备的数字信号处理(DSP)和视频性能,混合大小端系统(如TCP/IP)的互操作,以及多处理环境中高效的同步。
ARM面临的挑战是要满足所有这些市场需求,并且在计算效率(每瓦的计算能力)方面保持业内的竞争优势。
本章介绍了ARMv6架构中的组件,这些组件是ARM引入的用于解决市场需求的,包括增强的DSP支持和多处理环境支持。该章节还介绍了第一款高性能的ARMv6实现,并且除了ARMv6技术外,还介绍了ARM的最新技术之一------TrustZone。
15.1 Advanced DSP and SIMD Support in ARMv6
在ARMv6项目的早期阶段,ARM考虑如何改进架构中的DSP和媒体处理能力,超越第3.7节中描述的ARMv5E扩展。这项工作与ARM1136J-S工程团队密切合作,该团队正在为产品开发微架构的早期阶段。SIMD(单指令多数据)是一种常用的技术,用于获得相当大的数据并行性,并且在DSP、视频和图形处理算法中特别有效。SIMD对于高代码密度和低功耗非常有吸引力,因为执行的指令数量(因此也是内存系统访问)较少。这种效率的代价是需要以特定的数据块模式计算,从而降低了灵活性;然而,在许多图像和信号处理算法中,这种方法非常有效。
采用了标准的ARM设计理念,即计算效率非常高且功耗非常低,ARM提出了一种简单而优雅的方法,将现有的ARM 32位数据通路切割成四个8位和两个16位切片。与许多现有的SIMD架构不同,这种方法允许将SIMD添加到基础ARM架构中,几乎不增加额外的硬件成本。
ARMv6架构包括这种"轻量级"SIMD方法,几乎不增加额外的复杂性(门数),因此也不增加功耗。同时,新的指令可以将某些算法的处理吞吐量提高一倍(对于16位数据)或四倍(对于8位数据)。与ARM指令集架构中的大多数操作一样,所有这些新的指令都是有条件地执行,如第2.2.6节所述。
您可以在附录A的指令集表中找到所有ARMv6指令的完整描述。
15.1.1 SIMD Arithmetic Operations
表15.1显示了8位SIMD操作的摘要。每个字节的结果是通过对源操作数的每个相应字节切片进行算术运算得到的。

这些8位操作的结果可能需要表示多达9位,具体取决于使用的特定指令,可能会导致环绕或饱和发生。
除了8位SIMD操作外,还有广泛的双16位操作,如表15.2所示。每个半字(16位)的结果是通过对源操作数的每个相应16位切片进行算术运算得到的。
结果可能需要存储17位,在这种情况下,可以使用饱和版本的指令来使其在16位有符号结果范围内环绕或饱和。
SIMD指令的操作数在源寄存器中不总是以正确的顺序找到;为了提高处理这些情况的效率,存在能够交换一个操作数寄存器中的16位字的16位SIMD操作。这些操作在处理在内存中以不同方式对齐的半字时提供了很大的灵活性,并且在处理打包到32位寄存器中的16位复数对时特别有用。如表15.3所示,这些操作有带符号、无符号、饱和带符号和饱和无符号的版本。
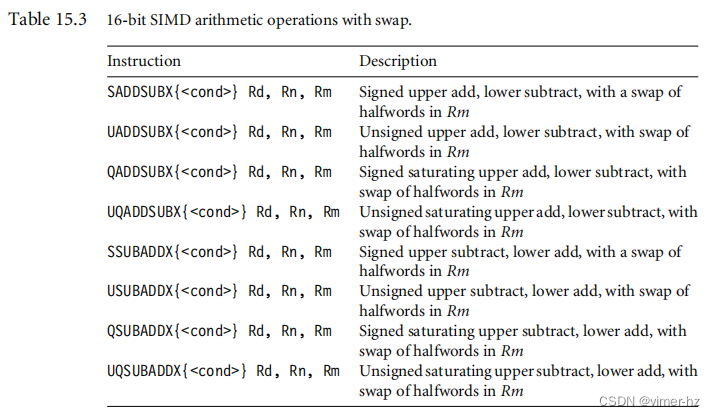
指令助记符中的X表示在应用操作之前将寄存器Rm中的两个半字进行交换,以便进行以下操作:
Rd15:0 = Rn15:0 - Rm31:16
Rd31:16 = Rn31:16 + Rm15:0
引入SIMD操作意味着现在需要一种显示每个SIMD切片通过数据通路的溢出或进位的方式。cpsr寄存器最初在第2.2.5节中描述时被修改,添加了四个额外的标志位来表示数据通路中的每个8位切片。带有GE位的新修改后的cpsr寄存器如图15.1和表15.4所示。每个GE位的功能是数据通路中每个切片的"大于等于"标志。


操作系统已经在上下文切换时保存了cpsr寄存器。在cpsr寄存器中添加这些位对于操作系统对体系结构的支持几乎没有影响。
除了对SIMD数据切片进行基本算术操作外,还需要进行一些操作,允许在数据通路中选择单个数据元素并形成这些元素的新组合。选择指令SEL可以根据相关的GE标志独立地从一个源寄存器Rn或另一个源寄存器Rm中选择每个8位字段。
bash
SEL Rd, Rn, Rm
Rd[31:24] = GE[3] ? Rn[31:24] : Rm[31:24]
Rd[23:16] = GE[2] ? Rn[23:16] : Rm[23:16]
Rd[15:08] = GE[1] ? Rn[15:08] : Rm[15:08]
Rd[07:00] = GE[0] ? Rn[07:00] : Rm[07:00]这些指令与其他SIMD操作一起,可以非常有效地实现Viterbi算法的核心,该算法在通信系统中广泛用于符号恢复。由于Viterbi算法本质上是一种统计最大似然选择算法,因此它也被用于语音和手写识别引擎等领域。Viterbi的核心是一种通常称为加法-比较-选择(ACS)的操作,在许多DSP处理器中都有定制的ACS指令。通过其并行(SIMD)的加法、减法(可用于比较)和选择指令,ARMv6可以实现极为高效的加法-比较-选择操作:
bash
ADD8 Rp1, Rs1, Rb1 ; 路径1 = 状态1 + 分支1(度量更新)
ADD8 Rp2, Rs2, Rb2 ; 路径2 = 状态2 + 分支2(度量更新)
USUB8 Rt, Rp1, Rp2 ; 比较度量值 - 设置SIMD标志
SEL Rd, Rp2, Rp1 ; 选择最佳(最小)度量值这个内核以并行方式在四条路径上执行ACS操作,并在ARM1136J-S上总共需要4个周期。对于使用ARMv5TE指令集编码的相同序列,必须串行执行每个操作,至少需要16个周期。因此,对于8位度量值,ARM1136J-S上的加法-比较-选择函数速度提高了四倍。
15.1.2 Packing Instructions
ARMv6架构包括一组新的打包指令,如表15.5所示,用于从不同源寄存器的16位值对构建新的32位打包数据。第二个操作数可以选择性地进行移位。打包指令特别适用于配对16位值,以便您可以利用之前描述的16位SIMD处理指令。

15.1.3 Complex Arithmetic Support
复数运算在通信信号处理中常被使用,尤其是在变换算法的实现中,比如在第8章中描述的快速傅里叶变换。该章节中讨论的大部分实现细节涉及使用ARMv4或ARMv5E指令集高效实现复数乘法。
ARMv6添加了用于加速复数乘法的新乘法指令,如表15.6所示。如果指定了X后缀,这两个操作都可以选择性地交换源操作数Rs的两个16位半部分的顺序。
示例15.1
在此示例中,Ra和Rb保存具有16位系数的复数,其中实部打包在寄存器的较低半部分,虚部打包在较高半部分。
我们将Ra和Rb相乘,得到一个新的复数Rc。代码假设16位值表示Q15小数部分。以下是针对ARMv6的代码:
bash
SMUSD Rt, Ra, Rb ; real*real--imag*imag at Q30
SMUADX Rc, Ra, Rb ; real*imag+imag*real at Q30
QADD Rt, Rt, Rt ; convert to Q31 & saturate
QADD Rc, Rc, Rc ; convert to Q31 & saturate
PKHTB Rc, Rc, Rt, ASR #16 ; pack resultsCompare this with an ARMv5TE implementation:
bash
SMULBB Rc, Ra, Rb ; real*real
SMULTT Rt, Ra, Rb ; imag*imag
QSUB Rt, Rc, Rt ; real*real-imag*imag at Q30
SMULTB Rc, Ra, Rb ; imag*real
SMLABT Rc, Ra, Rb ; + real*imag at Q30
QADD Rt, Rt, Rt ; convert to Q31 & saturate
QADD Rc, Rc, Rc ; convert to Q31 & saturate
MOV Rc, Rc, LSR #16
MOV Rt, Rt, LSR #16
ORR Rt, Rt, Rc, LSL#16 ; pack results对于ARMv5E而言,需要10个周期,而对于ARMv6而言,只需要5个周期。很明显,对于任何进行非常密集的复杂数学运算的算法,复数乘法的性能可以提高两倍。
15.1.4 Saturation Instructions
饱和算术首次在ARMv5TE架构中引入了E扩展,该扩展是与ARM966E和ARM946E产品一起推出的。ARMv6进一步提供了可以操作32位字和16位半字的个别和更灵活的饱和指令。除了表15.7中显示的这些指令之外,还有已在第15.1.1节中描述的新的饱和算术SIMD操作。

需要注意的是,在这些饱和操作的32位版本中,可以对源寄存器Rm进行可选算术移位,以便在饱和之前进行缩放,从而在同一条指令中完成。
15.1.5 Sum of Absolute Differences Instructions
这两个新指令可能是ARMv6架构中最具应用特定性的指令-USAD8和USADA8。它们用于计算八位值之间的绝对差值,在运动视频压缩算法(如MPEG或H.263)中特别有用,包括通过使用许多绝对差值操作比较块来测量运动的运动估计算法(见图15.2)。

表15.8列出了这些指令。

要比较图像p1中坐标为(x, y)的N×N正方形与N×N正方形p2,我们计算绝对差值的累加和:

要使用新的指令来实现这一点,可以使用以下序列来计算四个像素的绝对差值累加和:
bash
LDR p1,[p1Ptr],#4 ; 从p1加载4个像素
LDR p2,[p2Ptr],#4 ; 从p2加载4个像素
;延迟槽
;延迟槽
USADA8 acc, p1, p2 ; 累加绝对差这种算法与ARMv5TE的实现相比具有巨大的性能优势。仅八位SIMD就可以提高四倍的性能。此外,USADA8操作还包括累加操作。通常在循环之前,使用USAD8操作来进行设置以便开始时存在累加值。
15.1.6 Dual 16-Bit Multiply Instructions
ARMv5TE为ARM引入了相当可观的DSP性能,但ARMv6进一步提升了性能。ARMv6的实现(如ARM1136J)具有双16×16乘法能力,与许多高端专用DSP设备相当。表15.9列出了这些指令。

我们演示了在点积内循环中使用SMLAD作为有符号双乘法的用法:
bash
MOV R0, #0 ; 清零累加器
Loop
LDMIA R2!,{R4,R5,R6,R7} ; 加载8个16位数据项
LDMIA R1!,{R8,R9,R10,R11} ; 加载8个16位系数
SUBS R3,R3,#8 ; 循环计数器减8
SMLAD R0,R4,R8,R0 ; 两次乘法累加
SMLAD R0,R5,R9,R0
SMLAD R0,R6,R10,R0
SMLAD R0,R7,R11,R0
BGT Loop ; 如果还有系数,则继续循环该循环在不使用任何数据阻塞技术的情况下,在10个周期内完成了8次16×16乘法累加。如果一组点积的操作数存储在寄存器中,那么性能接近每个周期的真正双乘法。
15.1.7 Most Significant Word Multiplies
ARMv5TE增加了广泛用于控制、通信等各种DSP算法中的算术操作,并且这些算法旨在使用Q15数据格式。然而,在音频处理应用中,通常16位处理无法描述信号的质量。在这些情况下,通常使用32位值,而ARMv6则添加了一些新的乘法指令,可对Q31格式的值进行操作。 (请回忆第8章中对Q格式算术的详细描述)。这些新指令列在表15.10中。

助记符中的可选{R}允许在生成上32位之前,将固定常量0x80000000添加到64位乘积中。这允许对结果进行有偏舍入。
15.1.8 Cryptographic Multiplication Extensions
在一些密码算法中,非常长的乘法很常见。为了最大化它们的吞吐量,已经添加了一个新的64 + 32 × 32 → 64乘累加操作,以补充已经存在的32 × 32乘法操作UMULL(请参阅表15.11)。

这里是一个使用新指令非常高效的64位×64位乘法的示例.
15.2 System and Multiprocessor Support Additions to ARMv6
随着系统越来越复杂,它们将包含多个处理器和处理引擎。这些引擎可能共享不同的内存视图,甚至使用不同的字节顺序(endianness)。为了支持这些系统中的通信,ARMv6添加了对混合字节序系统的支持、快速异常处理和新的同步原语。
15.2.1 Mixed-Endianness Support
传统上,ARM架构对内存具有小端视图,并且可以在复位时切换到大端模式。这个大端模式将内存系统设置为大端顺序的指令和数据。
正如本章介绍中提到的,ARM芯片已经集成到非常复杂的SoC设备中,处理混合字节序,并且通常在软件中处理小端和大端数据。ARMv6添加了一条新指令来设置大代码序列的数据字节序(请参见表15.12),并且还添加了一些单独的操作指令,以增加处理混合字节序环境的效率。

endian_specifier可以是BE表示大端,或LE表示小端。当程序执行特定字节序数据的操作时,通常会使用SETEND。图15.3显示了单个字节操作指令。

15.2.2 Exception Processing
在操作系统中,将中断或异常的返回状态保存在堆栈上是很常见的。ARMv6添加了表15.13中的指令,以提高这个操作的效率,这在中断/调度驱动的系统中可能非常频繁发生。

15.2.3 Multiprocessing Synchronization Primitives
随着系统级芯片(SoC)架构变得越来越复杂,ARM核心现在常常出现在具有许多处理单元并竞争共享资源的设备中。ARM架构一直以来都有SWP指令用于实现信号量,以确保在这种环境中的一致性。然而,随着SoC变得更加复杂,SWP的某些方面在某些情况下会导致性能瓶颈。回想一下,SWP基本上是一个"阻塞"原语,它锁定了处理器的外部总线,并且使用大部分带宽来等待资源被释放。从这个意义上说,SWP指令被认为是"悲观"的,因为在SWP返回已释放的资源之前,无法进行任何计算。

为了解决这个问题,ARMv6架构添加了新的LDREX和STREX指令(加载和存储独占)。这些指令(表15.14)在使用上非常简单,并通过在内存系统中引入系统监视器来实现。LDREX乐观地将一个值从内存加载到寄存器中,假设在我们处理它的过程中不会有其他内容改变内存中的该值。STREX将一个值存回内存,并返回一个指示,用于判断在原始的LDREX操作和此存储之间内存中的值是否发生了变化。通过这种方式,原语是"乐观"的,即使某个外部设备也可能修改该值,您仍然可以继续处理使用LDREX加载的数据。只有在实际发生外部修改时,该值才会被丢弃并重新加载。
对于系统来说,最大的不同在于处理器不再在系统总线上等待一个可用的信号量,因此系统总线带宽的大部分都可供其他进程或处理器使用。
15.3 ARMv6 Implementations
ARM于2002年12月完成了ARM1136J的开发,并且到目前为止,正在设计采用该核心的消费产品。ARM1136J流水线是迄今为止最复杂的ARM实现。如图15.4所示,它具有一个八级流水线,其中加载/存储和乘法/累加拥有独立的并行流水线。

具有"命中下错"功能的并行加载/存储单元(LSU)允许在加载或存储正在与较慢的内存系统完成时发出操作并继续执行。通过将执行流水线与加载或存储的完成分离,核心可以获得相当大的额外性能,因为内存系统通常比核心速度慢得多。命中下错将此分离扩展到L1-L2内存接口,以便在其他L1命中仍在进行时,可以发生L1缓存不命中并完成L2事务。
微架构中的另一个重要改变是从虚拟标记缓存转向物理标记缓存。传统上,ARM使用的是虚拟标记缓存,其中MMU位于缓存与外部L2内存系统之间。随着ARMv6的推出,这一点发生了改变,现在MMU位于核心与L1缓存之间,因此所有缓存内存访问都使用物理(已经翻译)地址。采用这种方法的一个重要好处是在ARM运行大型操作系统时,上下文切换时缓存刷新大大减少。这种减少的刷新还将降低最终系统的功耗,因为缓存刷新直接导致更多的外部内存访问。预计在某些情况下,这种架构变化将带来高达20%的性能改进。
15.4 Future Technologies beyond ARMv6
在2003年,ARM进一步宣布了包括TrustZone和Thumb-2在内的新技术。尽管这些技术非常新颖,在撰写本文时,它们已被纳入新的微处理器核心。下面简要介绍这些新技术。
15.4.1 TrustZone
TrustZone是一种面向安全性的架构扩展,旨在保护使用消费产品(如手机)进行的交易,将来可能还包括下载音乐或视频等在线交易。它首次在2003年10月引入,当时ARM宣布推出ARM1176JZ-S处理器。
其基本思想是,操作系统(即使是嵌入式设备上的操作系统)现在非常复杂,很难在软件中验证安全性和正确性。ARM解决这个问题的方法是向体系结构添加新的操作"状态",其中只运行一个小型可验证的软件内核,并为更大的操作系统提供服务。微处理器核心则在控制系统外围设备上扮演一个角色,这些设备可能只能通过总线接口上的一些新导出信号对安全"状态"可见。系统状态如图15.5所示。

TrustZone在进行内容下载的设备中非常有用,例如手机或其他带有网络连接的便携设备。目前尚无关于该架构的详细信息对公众公开。
15.4.2 Thumb-2
Thumb-2是一种旨在提高代码密度的架构扩展。它允许将32位的ARM指令与16位的Thumb指令混合使用。这种组合使您既可以享受Thumb的代码密度优势,又可以获得访问32位指令的额外性能优势。
Thumb-2在2003年10月宣布,并将应用于ARM1156T2-S处理器。目前尚无关于该架构的详细信息对公众公开。
15.5 Summary
ARM架构并不是一个静态的常数,而是在不断开发和改进,以适应当今消费设备所需的应用。虽然ARMv5TE架构在为ARM添加一些DSP支持方面非常成功,但ARMv6架构扩展了DSP支持,并增加了对大型多处理器系统的支持。表15.15显示了这些新技术如何映射到不同的处理器核心。

ARM仍然专注于其中一个关键优势------代码密度,并最近宣布了对其流行的Thumb架构的扩展------Thumb-2。在安全方面,对TrustZone的新关注使ARM在这一领域处于领先地位。
预计未来将会有更多创新出现!
Suggested Reading
以下是几本关于高速缓存内存的推荐书籍:
- "The Cache Memory Book" (《高速缓存》)- Jim Handy
这本书是经典之作,提供了对高速缓存设计的详细讨论,涵盖了高速缓存的原理、结构和性能优化等方面。
- "Cache Memory Organization, Placement, and Performance" (《高速缓存组织、放置与性能》)- Gul N. Khan
这本书介绍了高速缓存的组织结构、数据放置策略以及性能评估方法。它提供了一些实用的技巧和策略,帮助读者更好地设计和优化高速缓存系统。
- "High-Performance Computer Architecture" (《高性能计算机体系结构》)- Harold Stone
这本书虽然不仅仅关注高速缓存,但它在计算机体系结构的整体设计中详细探讨了高速缓存的作用和优化方法。它覆盖了诸多相关主题,包括流水线、指令级并行和内存层次结构等。
- "Modern Processor Design: Fundamentals of Superscalar Processors" (《现代处理器设计:超标量处理器基础》)- John Paul Shen, Mikko H. Lipasti
这本书介绍了现代处理器的设计原理和技术,其中也包括对高速缓存的详细讨论。它深入探讨了超标量体系结构的性能优化和高速缓存的关键作用。
这些书籍将为你提供深入了解高速缓存内存的知识,从基础概念到实际设计和优化策略。根据个人的需求和兴趣,你可以选择其中的一本或多本进行阅读和学习。