文章目录
- [1. 问题描述](#1. 问题描述)
- [2. 最小二乘法](#2. 最小二乘法)
-
- [2.1. 传统最小二乘法](#2.1. 传统最小二乘法)
- [2.2. 总体最小二乘法](#2.2. 总体最小二乘法)
- [2.3. 从概率角度分析总体最小二乘法](#2.3. 从概率角度分析总体最小二乘法)
- [2.4. 鲁棒估计](#2.4. 鲁棒估计)
- [3. RANSAC 算法](#3. RANSAC 算法)
-
- [3.1. 算法原理](#3.1. 算法原理)
- [3.2. 概率公式推导](#3.2. 概率公式推导)
- [3.3. 仿真实验](#3.3. 仿真实验)
课程视频链接:北京邮电大学_计算机视觉_鲁鹏_第三次课_拟合 和 北京邮电大学_计算机视觉_鲁鹏_第4次课_拟合(RANSAC复习,hough)。
1. 问题描述
如下图所示,设二维平面内存在 n n n 个点 { ( x i y i ) } i = 1 n \{ \begin{pmatrix} x_i \\ y_i \end{pmatrix} \}_{i = 1}^{n} {(xiyi)}i=1n,现需构造最优直线模型来拟合该数据集,下面从三种不同的方法来解决这个问题。

对下面所述的各个算法做一个总结图,如下图所示:

2. 最小二乘法
2.1. 传统最小二乘法
最小二乘法(Least Squares, LS)构造最优直线模型 y ^ = m x + b \hat{y} = mx + b y^=mx+b 来拟合二维平面内的点,其目标是最小化所有观测点的残差平方和 ∑ i = 1 n ( y i − y ^ i ) 2 \sum_{i = 1}^{n} (y_i - \hat{y}_i)^2 ∑i=1n(yi−y^i)2,其中残差 e i = y i − y ^ i e_i = y_i - \hat{y}i ei=yi−y^i 表示实际值 y i y_i yi 与模型预测值 y i ^ \hat{y_i} yi^ 的垂直偏差,如下图所示:
 设 E = ∑ i = 1 n ( y i − m x i − b ) 2 E = \sum{i = 1}^{n} (y_i - m x_i - b)^2 E=∑i=1n(yi−mxi−b)2, Y = ( y 1 ⋮ y n ) \mathbf{Y} = \begin{pmatrix} y_1 \\ \vdots \\ y_n \end{pmatrix} Y= y1⋮yn , X = ( x 1 1 ⋮ ⋮ x n 1 ) \mathbf{X} = \begin{pmatrix} x_1 & 1 \\ \vdots & \vdots \\ x_n & 1 \end{pmatrix} X= x1⋮xn1⋮1 , B = ( m b ) \mathbf{B} = \begin{pmatrix} m \\ b \end{pmatrix} B=(mb),则有:
设 E = ∑ i = 1 n ( y i − m x i − b ) 2 E = \sum{i = 1}^{n} (y_i - m x_i - b)^2 E=∑i=1n(yi−mxi−b)2, Y = ( y 1 ⋮ y n ) \mathbf{Y} = \begin{pmatrix} y_1 \\ \vdots \\ y_n \end{pmatrix} Y= y1⋮yn , X = ( x 1 1 ⋮ ⋮ x n 1 ) \mathbf{X} = \begin{pmatrix} x_1 & 1 \\ \vdots & \vdots \\ x_n & 1 \end{pmatrix} X= x1⋮xn1⋮1 , B = ( m b ) \mathbf{B} = \begin{pmatrix} m \\ b \end{pmatrix} B=(mb),则有:
E = ∥ Y − X B ∥ 2 (1) E = \|\mathbf{Y} - \mathbf{X} \mathbf{B} \|^2 \tag{1} E=∥Y−XB∥2(1)现在我们需要求解 B \mathbf{B} B 取什么值时, E E E 取得最小值。对 E E E 进行展开有:
E = ( Y − X B ) T ( Y − X B ) = ( Y T − B T X T ) ( Y − X B ) = Y T Y − Y T X B − B T X T Y + B T X T X B \begin{align*} E &= (\mathbf{Y} - \mathbf{X} \mathbf{B})^T (\mathbf{Y} - \mathbf{X} \mathbf{B}) = (\mathbf{Y}^T - \mathbf{B}^T \mathbf{X}^T) (\mathbf{Y} - \mathbf{X} \mathbf{B}) \\ &= \mathbf{Y}^T \mathbf{Y} - \mathbf{Y}^T \mathbf{X} \mathbf{B} - \mathbf{B}^T \mathbf{X}^T \mathbf{Y} + \mathbf{B}^T \mathbf{X}^T \mathbf{X} \mathbf{B} \end{align*} E=(Y−XB)T(Y−XB)=(YT−BTXT)(Y−XB)=YTY−YTXB−BTXTY+BTXTXB我们需要计算出 ∂ E ∂ B \dfrac{\partial{E}}{\partial{\mathbf{B}}} ∂B∂E,然后根据 ∂ E ∂ B = 0 \dfrac{\partial{E}}{\partial{\mathbf{B}}} = 0 ∂B∂E=0 解出 B \mathbf{B} B。
参考博客:机器学习中的数学理论1:三步搞定矩阵求导,求导步骤如下:
- 求微分 d E dE dE。
d E = − Y T X d B − d ( B T ) X T Y + d ( B T ) X T X B + B T X T X d B = ( B T X T X − Y T X ) d B + ( d B ) T ( X T X B − X T Y ) \begin{align*} dE &= -\mathbf{Y}^T \mathbf{X} d\mathbf{B} - d(\mathbf{B}^T) \mathbf{X}^T \mathbf{Y} + d(\mathbf{B}^T) \mathbf{X}^T \mathbf{X} \mathbf{B} + \mathbf{B}^T \mathbf{\mathbf{X}}^T \mathbf{X} d\mathbf{B} \\ &= (\mathbf{B}^T \mathbf{\mathbf{X}}^T \mathbf{X} - \mathbf{Y}^T \mathbf{X}) d\mathbf{B} + (d \mathbf{B})^T(\mathbf{X}^T \mathbf{X} \mathbf{B} - \mathbf{X}^T \mathbf{Y}) \end{align*} dE=−YTXdB−d(BT)XTY+d(BT)XTXB+BTXTXdB=(BTXTX−YTX)dB+(dB)T(XTXB−XTY) - 计算 t r ( d E ) tr(dE) tr(dE)。
d E = t r ( d E ) = t r ( B T X T X − Y T X ) d B + ( d B ) T ( X T X B − X T Y ) = t r B T X T X − Y T X ) d B + t r ( d B ) T ( X T X B − X T Y ) = t r ( B T X T X − Y T X ) d B + t r ( X T X B − X T Y ) T d B = t r 2 ( B T X T X − Y T X ) d B \begin{align*} dE &= tr(dE) = tr (\\mathbf{B}\^T \\mathbf{\\mathbf{X}}\^T \\mathbf{X} - \\mathbf{Y}\^T \\mathbf{X}) d\\mathbf{B} + (d \\mathbf{B})\^T(\\mathbf{X}\^T \\mathbf{X} \\mathbf{B} - \\mathbf{X}\^T \\mathbf{Y}) \\ &= tr\\mathbf{B}\^T \\mathbf{\\mathbf{X}}\^T \\mathbf{X} - \\mathbf{Y}\^T \\mathbf{X}) d\\mathbf{B} + tr(d \\mathbf{B})\^T (\\mathbf{X}\^T \\mathbf{X} \\mathbf{B} - \\mathbf{X}\^T \\mathbf{Y}) \\ &= tr(\\mathbf{B}\^T \\mathbf{\\mathbf{X}}\^T \\mathbf{X} - \\mathbf{Y}\^T \\mathbf{X}) d\\mathbf{B} + tr(\\mathbf{X}\^T \\mathbf{X} \\mathbf{B} - \\mathbf{X}\^T \\mathbf{Y})\^T d\\mathbf{B} \\ &= tr2(\\mathbf{B}\^T \\mathbf{\\mathbf{X}}\^T \\mathbf{X} - \\mathbf{Y}\^T \\mathbf{X}) d\\mathbf{B} \end{align*} dE=tr(dE)=tr(BTXTX−YTX)dB+(dB)T(XTXB−XTY)=trBTXTX−YTX)dB+tr(dB)T(XTXB−XTY)=tr(BTXTX−YTX)dB+tr(XTXB−XTY)TdB=tr2(BTXTX−YTX)dB - 根据 d E = t r ( ∂ E ∂ B T d B ) dE = tr(\dfrac{\partial{E}}{\partial \mathbf{B}}^T d\mathbf{B}) dE=tr(∂B∂ETdB),求 ∂ E ∂ B \dfrac{\partial{E}}{\partial \mathbf{B}} ∂B∂E。由上述推导可知,
∂ E ∂ B T = 2 ( B T X T X − Y T X ) ⇒ ∂ E ∂ B = 2 ( X T X B − X T Y ) \dfrac{\partial{E}}{\partial \mathbf{B}}^T = 2(\mathbf{B}^T \mathbf{\mathbf{X}}^T \mathbf{X} - \mathbf{Y}^T \mathbf{X}) \Rightarrow \dfrac{\partial{E}}{\partial \mathbf{B}} = 2(\mathbf{X}^T \mathbf{X} \mathbf{B} - \mathbf{X}^T \mathbf{Y}) ∂B∂ET=2(BTXTX−YTX)⇒∂B∂E=2(XTXB−XTY)
从而有: ∂ E ∂ B = 0 ⇒ X T X B = X T Y \dfrac{\partial{E}}{\partial \mathbf{B}} = 0 \Rightarrow \mathbf{X}^T \mathbf{X} \mathbf{B} = \mathbf{X}^T \mathbf{Y} ∂B∂E=0⇒XTXB=XTY因此,非齐次线性方程组 X T X B = X T Y \mathbf{X}^T \mathbf{X} \mathbf{B} = \mathbf{X}^T \mathbf{Y} XTXB=XTY 的解即为所求的 B \mathbf{B} B。
如果 X T X \mathbf{X}^T \mathbf{X} XTX 可逆,则有 B = ( X T X ) − 1 X T Y \mathbf{B} = (\mathbf{X}^T \mathbf{X})^{-1} \mathbf{X}^T \mathbf{Y} B=(XTX)−1XTY。
上述普通线性最小二乘法在直线拟合中存在以下局限性:
无法表示垂直线。 由于模型 y = m x + b y = mx + b y=mx+b 中的斜率 m m m 无法取无穷大值,因此该方法无法拟合严格垂直分布的数据点 (即 x x x 值恒定),此时方程无解。不具有旋转不变性。最小二乘拟合的结果依赖于坐标系的方向。这意味着,对同一组数据点进行坐标旋转变换后,使用相同方法拟合得到的直线会不同。例如,当数据点经过旋转变换后,在图像平面(或任何坐标系)中呈现出垂直分布的状态时(如上一条所述),该方法将完全失效。对异常点较敏感。损失函数为残差平方和,异常点的残差平方项过大,会显著扭曲拟合直线的方向
2.2. 总体最小二乘法
总体最小二乘法(Total Least Squares, TLS)不同于最小二乘法,它基于点到直线的垂线距离 (而非 y y y 值之差)进行拟合,从而有效地解决了前面所述最小二乘法的不足,如下图所示:

从上图可知,总体最小二乘法的解即为齐次线性方程 U T U N = 0 \mathbf{U}^T \mathbf{U} \mathbf{N} = 0 UTUN=0 的解。令 A = U T U \mathbf{A} = \mathbf{U}^T \mathbf{U} A=UTU,这是一个 2 × 2 2×2 2×2 的实对称矩阵,且半正定(其特征值满足 λ 1 , λ 2 ≥ 0 \lambda_1, \lambda_2 ≥ 0 λ1,λ2≥0)。我们从特征值与特征向量的关系( A N = λ i N \mathbf{A} \mathbf{N} = \lambda_i \mathbf{N} AN=λiN)出发,结合实对称矩阵的性质,求解 A N = 0 \mathbf{A} \mathbf{N} = 0 AN=0。实际上,方程的解对应于最小特征值(通常为零或接近零)对应的归一化特征向量。
值得注意的是 ∥ x 1 − x ‾ y 1 − y ‾ ⋮ ⋮ x n − x ‾ y n − y ‾ a b ∥ 2 \left\| \begin{bmatrix} x_1 - \overline{x} & y_1 - \overline{y} \\ \vdots & \vdots \\ x_n - \overline{x} & y_n - \overline{y} \end{bmatrix} \begin{bmatrix} a \\ b \end{bmatrix} \right\|^2 x1−x⋮xn−xy1−y⋮yn−y ab 2 为将所有数据点的中心化坐标 ( x i − x ‾ y i − y ‾ ) \begin{pmatrix} x_i - \overline{x} \\ y_i - \overline{y} \end{pmatrix} (xi−xyi−y) 投影到单位直线法向量 ( a b ) \begin{pmatrix} a \\ b \end{pmatrix} (ab) 上,再求这些投影的平方和。这等价于衡量所有数据点在该法向量方向上的总体偏离程度,如下图所示:
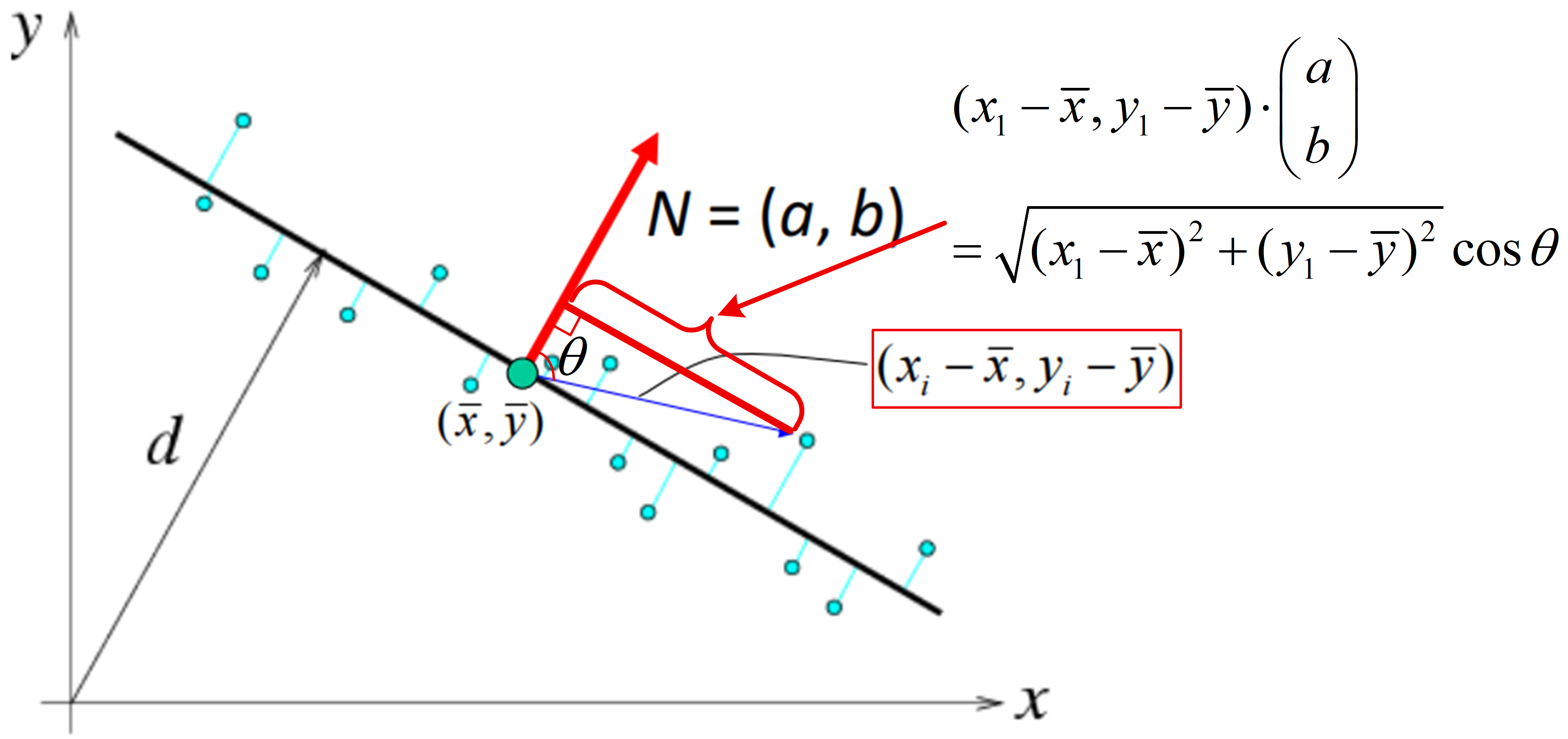
总体最小二乘法解决了最小二乘法无法拟合垂直线的问题,但对异常点依然敏感 。数据中的异常点很容易显著扭曲拟合直线的方向。如下图所示:

2.3. 从概率角度分析总体最小二乘法

如上图所示,我们从概率角度出发推导总体最小二乘法的目标函数 E = ∑ i = 1 n ( a x i + b y i − d ) 2 E = \sum_{i = 1}^{n} (a x_i + b y_i - d)^2 E=∑i=1n(axi+byi−d)2。从概率角度,我们可以认为观测数据点 ( x y ) \begin{pmatrix} x \\ y \end{pmatrix} (xy) 是直线上的真值点 ( u v ) \begin{pmatrix} u \\ v \end{pmatrix} (uv) 叠加上垂直于直线的噪声 ϵ \epsilon ϵ 而产生的,即有:
( x y ) = ( u v ) + ϵ ( a b ) \begin{pmatrix} x \\ y \end{pmatrix} = \begin{pmatrix} u \\ v \end{pmatrix} + \epsilon \begin{pmatrix} a \\ b \end{pmatrix} (xy)=(uv)+ϵ(ab)其中, ϵ \epsilon ϵ 服从均值为 0、方差为 1 的高斯分布,即 ϵ ∼ N ( 0 , 1 ) \epsilon \sim N(0, 1) ϵ∼N(0,1)。
观测到所有数据点的联合概率可以表示为:
P ( x 1 , y 1 , ... , x n , y n ∣ a , b , d ) = ∏ i = 1 n P ( x i , y i ∣ a , b , d ) ∝ ∏ i = 1 n exp ( − ( a x i + b y i − d ) 2 2 σ 2 ) P(x_1, y_1, \ldots, x_n, y_n \mid a, b, d) = \prod_{i=1}^{n} P(x_i, y_i \mid a, b, d) \propto \prod_{i=1}^{n} \exp\left(-\frac{(ax_i + by_i - d)^2}{2\sigma^2}\right) P(x1,y1,...,xn,yn∣a,b,d)=i=1∏nP(xi,yi∣a,b,d)∝i=1∏nexp(−2σ2(axi+byi−d)2)又因为:
∏ i = 1 n exp ( − ( a x i + b y i − d ) 2 2 σ 2 ) = exp ( ∑ i = 1 n − ( a x i + b y i − d ) 2 2 σ 2 ) \prod_{i=1}^{n} \exp\left(-\frac{(ax_i + by_i - d)^2}{2\sigma^2}\right) = \exp\left( \sum_{i = 1}^{n} -\frac{(ax_i + by_i - d)^2}{2\sigma^2} \right) i=1∏nexp(−2σ2(axi+byi−d)2)=exp(i=1∑n−2σ2(axi+byi−d)2)则有:
max P ( x 1 , y 1 , ... , x n , y n ∣ a , b , d ) ⇔ max ∑ i = 1 n − ( a x i + b y i − d ) 2 2 σ 2 ⇔ min ∑ i = 1 n ( a x i + b y i − d ) 2 \max{P(x_1, y_1, \ldots, x_n, y_n \mid a, b, d)} \Leftrightarrow \max{\sum_{i = 1}^{n} -\frac{(ax_i + by_i - d)^2}{2\sigma^2}} \Leftrightarrow \min \sum_{i = 1}^{n} (ax_i + by_i - d)^2 maxP(x1,y1,...,xn,yn∣a,b,d)⇔maxi=1∑n−2σ2(axi+byi−d)2⇔mini=1∑n(axi+byi−d)2
2.4. 鲁棒估计
最小二乘法和总体最小二乘法在处理包含异常值的数据时,容易使拟合直线发生方向偏移。这是因为异常点对参数估计造成的干扰过大。为此, 我们引入鲁棒估计以增强拟合的稳健性。
定义鲁棒函数 ρ ( u ; σ ) = u 2 σ 2 + u 2 \rho(u; \sigma) = \dfrac{u^2}{\sigma^2 + u^2} ρ(u;σ)=σ2+u2u2,其中 u = r i ( x i , θ ) u = r_i(x_i, \theta) u=ri(xi,θ) 代表参数为 θ \theta θ 的数学模型在数据点 x i x_i xi 处的残差值。因此,直线拟合问题可归结为求解模型参数 θ \theta θ,使得 ∑ i = 1 n ρ ( r i ( x i , θ ) ; σ ) \sum_{i = 1}^{n} \rho(r_i(x_i, \theta); \sigma) ∑i=1nρ(ri(xi,θ);σ) 最小化。
我们取不同的 σ \sigma σ 值绘制曲线 ρ ( u ; σ ) \rho(u; \sigma) ρ(u;σ),如下图所示:
 鲁棒函数 ρ \rho ρ 在残差 u u u 较小时近似二次函数,而在 u u u 较大时趋于饱和,从而有效抑制了异常点对直线拟合的影响。
鲁棒函数 ρ \rho ρ 在残差 u u u 较小时近似二次函数,而在 u u u 较大时趋于饱和,从而有效抑制了异常点对直线拟合的影响。
结合上图,分析 σ \sigma σ 取值对直线拟合的影响:
- σ \sigma σ 过小:鲁棒函数 ρ ( u ; σ ) \rho(u; \sigma) ρ(u;σ) 对距离 u u u 的敏感性显著降低,导致不同残差的点具有相近的贡献权重,无法有效区分内点与外点,拟合结果偏离真实模型
- σ \sigma σ 过大:函数 ρ ( u ; σ ) \rho(u; \sigma) ρ(u;σ) 对较大残差的抑制效果减弱,其行为退化为最小二乘法,外点对拟合结果的影响显著增加,失去鲁棒性
值得注意的是:鲁棒估计是一个非线性优化问题 ,必须通过迭代算法求解,无法直接获得解析解。最小二乘解可作为迭代优化的有效初始值 ,显著加速收敛并规避局部最优解。尺度参数 σ \sigma σ 建议取值为残差绝对值的中位数的1.5 倍,即: σ = 1.5 × m e d i a n ( ∣ r i ∣ ) \sigma = 1.5 \times median(|r_i|) σ=1.5×median(∣ri∣)该准则源自统计学理论(Freedman & Peters, 1984),通过自适应调整平衡模型对核心数据与异常值的响应特性。
3. RANSAC 算法
3.1. 算法原理
鲁棒估计在少量异常值场景下表现良好,但当数据中存在大量异常值时,其稳定性可能显著下降。随机抽样一致算法(Random Sample Consensus, RANSAC)通过迭代随机采样和模型一致性验证,为高比例异常值的数据提供了解决方案。
RANSAC 算法的步骤可以归纳成如下步骤:
- 参数初始化 。需要初始化的参数包括:
- 模型最小样本数 s s s,其中直线拟合需要 2 个点,平面拟合需要 3 个点
- 误差阈值 t t t,用于判定内点的误差容忍度
- 期望置信度概率 p p p 表示算法在随机抽样过程中至少有一次抽到纯内点集(无异常值)的概率,通常 p ≥ 0.99 p ≥ 0.99 p≥0.99
- 初始迭代次数 N N N,后续可自适应更新
- 随机抽样。从数据集中随机选择一组最小样本集,称为 "子集",用于初始化模型。子集的大小由模型类型决定,例如:直线拟合需要至少 2 个点,平面拟合需要至少 3 个点。值得注意的是:选择的样本必须足够小以保证高效性,同时足够大以覆盖模型的基本自由度;
- 模型估计。利用随机选择的子集计算模型的初始参数,例如,对于直线拟合,通过两点计算斜率和截距,对于平面拟合,通过三点计算平面方程;
- 验证一致性 。计算所有数据点与当前模型的误差(例如欧氏距离、残差等)。根据预设的误差阈值 t t t,将误差小于 t t t 的点判定为内点,误差大于 t t t 的点为异常值(outlier),并且统计当前模型支持的内点总数 i n l i e r _ c o u n t inlier\_count inlier_count;
- 迭代优化 。若当前模型的 i n l i e r _ c o u n t inlier\_count inlier_count > 历史最优模型的 b e s t _ i n l i e r _ c o u n t best\_inlier\_count best_inlier_count,更新 b e s t _ i n l i e r _ c o u n t = i n l i e r _ c o u n t best\_inlier\_count = inlier\_count best_inlier_count=inlier_count,并且暂存当前模型参数及内点集合。
计算数据集中异常值的比例 e = M − i n l i e r _ c o u n t M e = \dfrac{M - inlier\_count}{M} e=MM−inlier_count,再根据概率公式 N = log ( 1 − p ) log ( 1 − ( 1 − e ) s ) N = \dfrac{\log(1 - p)}{\log(1 - (1 - e)^s)} N=log(1−(1−e)s)log(1−p) 更新最大迭代次数 N N N,重复执行步骤 2 ∼ 5 2 \sim 5 2∼5,逐步优化模型参数。
迭代的终止条件有两个:- 达到最大迭代次数 N N N;
- 内点数 b e s t _ i n l i e r _ c o u n t best\_inlier\_count best_inlier_count 超过预设阈值;
- 最终优化。用最优模型对应的所有内点,通过最小二乘法等重新估计模型参数(如用所有内点拟合直线)。
上述的步骤可视化如下图:

现在我们来分析在不同外点率 e e e 和抽样点数量 s s s 下,为确保 p = 0.99 p = 0.99 p=0.99,所需的迭代次数 N N N。如下表所示。由表可知:当 s = 2 s = 2 s=2 时,若 e = 10 % e = 10\% e=10%,则 N ≥ 3 N≥3 N≥3,若 e = 50 % e = 50\% e=50%,则 N ≥ 17 N ≥ 17 N≥17。此外,随着 s s s 增大,所需的 N N N 也要相应增大。

总得来说,RANSAC 算法通过随机性和统计验证解决了高噪声环境下的模型拟合问题,实际应用中需根据数据特性调整阈值与迭代策略,以平衡精度与效率。
3.2. 概率公式推导
- 定义变量 。定义如下变量:
- p p p:期望的成功概率,即在 N N N 次迭代中至少有一次成功抽到全内点样本的概率
- e e e:数据集中异常值的比例
- s s s:模型所需最小样本数(如直线拟合需要 2 个点)
- N N N:所需迭代次数
- 计算单次抽样失败的概率 。假设数据集中内点的比例为 1 − e 1 - e 1−e,则单次随机抽样中选择到一个内点的概率为 1 − e 1 - e 1−e。由于抽样是独立的(假设数据集足够大或允许放回抽样),选择 s s s 个样本全部为内点的概率为 ( 1 − e ) s (1 - e)^s (1−e)s,单次抽样失败的概率为 1 − ( 1 − e ) s 1 - (1 - e)^s 1−(1−e)s;
- 计算 N 次迭代全部失败的概率 。在 N N N 次独立迭代中,所有迭代均失败的概率为 1 − ( 1 − e ) s N 1 - (1 - e)\^s^N 1−(1−e)sN;
- 计算成功概率的表达式 。要求至少有一次成功的概率为 p p p,即 1 − 1 − ( 1 − e ) s N = p 1 - 1 - (1 - e)\^s^N = p 1−1−(1−e)sN=p;
- 解方程求 N N N 。将方程整理为 1 − p = 1 − ( 1 − e ) s N 1 - p = 1 - (1 - e)\^s^N 1−p=1−(1−e)sN,对两边取对数有 log ( 1 − p ) = N ⋅ log 1 − ( 1 − e ) s \log(1 - p) = N \cdot \log1 - (1 -e)\^s log(1−p)=N⋅log1−(1−e)s,整理可得 N = log ( 1 − p ) log 1 − ( 1 − e ) s N = \dfrac{\log(1 - p)}{\log\left1 - (1 - e)\^s\\right} N=log1−(1−e)slog(1−p)。
3.3. 仿真实验
我们采用 RANSAC 算法进行二维点集的直线拟合仿真实验。为简化代码,我们固定了最大迭代次数。仿真代码如下:
python
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(6)
def generate_data(num_inliers=100, num_outliers=20, slope=0.5, intercept=1.0, noise_level=0.5):
"""
生成带噪声和异常值的数据。
生成 100 个内点(符合直线 y = 0.5x + 1)和 20 个异常值(随机分布)
内点包含高斯噪声,异常值包含更大范围的随机噪声
"""
# 内点
x_inliers = np.random.rand(num_inliers) * 10
y_inliers = slope * x_inliers + intercept + np.random.normal(0, noise_level, num_inliers)
# 异常值(随机噪声)
x_outliers = np.random.rand(num_outliers) * 10
y_outliers = np.random.rand(num_outliers) * 10 + np.random.normal(0, 3, num_outliers)
X = np.hstack((x_inliers, x_outliers))
y = np.hstack((y_inliers, y_outliers))
return X, y
def ransac_line_fitting(X, y, num_iterations=100, threshold=1.0, min_samples=2):
best_model = None
best_inliers = []
for _ in range(num_iterations):
# 随机选择两个点作为样
indices = np.random.choice(len(X), size=min_samples, replace=False)
x_sample = X[indices]
y_sample = y[indices]
# 避免除以零
if x_sample[0] == x_sample[1]:
continue
# 拟合直线模型 y = kx + b
k = (y_sample[1] - y_sample[0]) / (x_sample[1] - x_sample[0])
b = y_sample[0] - k * x_sample[0]
model = (k, b)
# 计算所有点到当前模型的残差
residuals = np.abs(k * X + b - y)
inliers = np.where(residuals < threshold)[0]
# 更新最优模型
if len(inliers) > len(best_inliers):
best_model = model
best_inliers = inliers
# RANSAC 算法拟合直线失败
if len(best_inliers) < 2:
return None, None
# # 使用最优模型的所有内点重新拟合(最小二乘法)
X_best = X[best_inliers]
y_best = y[best_inliers]
A = np.vstack([X_best, np.ones(len(X_best))]).T
k_best, b_best = np.linalg.lstsq(A, y_best, rcond=None)[0]
return (k_best, b_best), best_inliers
def ols_line_fitting(X, y):
A = np.vstack([X, np.ones(len(X))]).T
k_ols, b_ols = np.linalg.lstsq(A, y, rcond=None)[0]
return (k_ols, b_ols)
def plot_results(X, y, best_model, best_inliers, outliers_indices, ols_model):
plt.figure(figsize=(10, 6))
# 绘制 inliers 和 outliers
plt.scatter(X[outliers_indices], y[outliers_indices], label="Outliers", color="red", marker="x")
plt.scatter(X[best_inliers], y[best_inliers], label="Inliers", color="blue", alpha=0.7)
# 绘制 RANSAC 拟合的直线
x_vals = np.array([np.min(X), np.max(X)])
y_vals_ransac = best_model[0] * x_vals + best_model[1]
plt.plot(x_vals, y_vals_ransac, color="green", label="RANSAC Model", linewidth=2)
# 绘制 OLS 拟合的直线
y_vals_ols = ols_model[0] * x_vals + ols_model[1]
plt.plot(x_vals, y_vals_ols, color="orange", label="OLS Model", linestyle="--", linewidth=2)
plt.text(0.05, 0.95, f"RANSAC: y = {best_model[0]:.2f}x + {best_model[1]:.2f}",
transform=plt.gca().transAxes, fontsize=12, verticalalignment='top')
plt.text(0.05, 0.90, f"OLS: y = {ols_model[0]:.2f}x + {ols_model[1]:.2f}",
transform=plt.gca().transAxes, fontsize=12, verticalalignment='top')
plt.legend()
plt.title("RANSAC vs OLS Line Fitting with Outliers")
plt.xlabel("X")
plt.ylabel("Y")
plt.grid(True)
plt.show()
if __name__ == "__main__":
# 生成数据
X, y = generate_data()
# RANSAC 拟合
best_model, best_inliers = ransac_line_fitting(X, y)
# 获取异常值的索引
outliers_indices = np.setdiff1d(np.arange(len(X)), best_inliers)
# 计算 OLS 拟合的直线
ols_model = ols_line_fitting(X, y)
if best_model:
plot_results(X, y, best_model, best_inliers, outliers_indices, ols_model)
else:
print("无法找到合适的模型!")仿真结果如下图所示,可以看出,当异常值较多时,与最小二乘法相比,RANSAC 算法拟合的直线更优。
