一、定义
参数(parameter)
参数 是用来描述总体数据特征的度量
统计量(statistic)
统计量 是用来描述样本数据特征的度量
由试验计算得出,不依赖于任何其他未知的量(特别是不能依赖于总体分布中所包含的未知参数)
参数估计(parameter estimation)
是统计推断的基本问题之一:用样本统计量估计总体的参数
·参数未知的真实
·统计量已知的估计
二、估计类别
点估计(point estimate)
点估计是用样本统计量的某个取值直接作为总体参数𝜃的估计值
用样本均值x直接作为总体均值μ的估计值
用样本方差直接作为总体方差
的估计值
点估计的常用方法
矩估计
最小二乘估计
极大似然估计
最大后验概率
贝叶斯估计
矩估计
原理:大数定律(大量试验中的事件出现频率=它的概率)
最小二乘估计(Least Square Estimate, LSE)

这些内容在我以前的博客中都有,大家可以翻翻目录,点击即可
极大似然估计、最大后验概率估计(MAP),贝叶斯估计
贝叶斯公式:

极大似然估计(MLE)
MLE目标:用似然函数取到最大值时的参数值作为估计值

对数似然函数

最大后验概率估计(MAP)
MLE的目标是:求参数𝜃,使得似然函数最大
MAP的目标是:求参数𝜃,使得似然函数最大
不仅需要似然函数出现的概率大,也需要参数𝜃的先验概率大
整理 MAP 的优化目标为:

一个例题:

大家可自行计算,答案为:
这三种方法如何理解使用:
举例:
假设小江遇到一个计算机难题,碰巧小江有个朋友在大学计算机系当教授,于是他打算找该教授的学生帮忙,那么他该如何寻求帮助呢?
MLE:由以往的考试成绩(对应已有数据)排序(A,B,C....),选出成绩最好的学生A(对应模型中的参数)来解决自己的问题
MAP:仍然选择最好的学生,但是除了考试成绩,他还从老师处得知A,B两人考试中有作弊嫌疑(对应先验),结合该知识,小江选择学生C来解决自己的问题
贝叶斯估计:此时小江不再寻求单个人的帮助,他会要求每个学生都给出一个答案,并结合考试成绩和老师的提醒给每个学生一个权重(参数的分布),对所有答案加权平均得到最后的解答。
误差分析
均方误差( MSE )

均方根误差( RMSE )
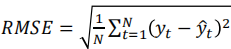
点估计的优良性
无偏性 (unbiasedness)
估计量抽样分布的数学期望等于被估计的总体参数
有效性 (efficiency)
指同一总体参数的两个无偏估计,标准差小的估计量更有效
相合性 (consistency)
相合性是指随着样本容量 𝑛 的不断增加,点估计的值越来越接近被估计的总体参数,即 越来越接近
区间估计
在数据科学中应用较少,大家还是可以参考我概率论的链接查看相关内容
下一节,我们讲述假设检验