kettle工具简谈
Kettle 是 Pentaho 公司开发的开源 ETL (Extract, Transform, Load) 工具,全称为 Pentaho Data Integration (PDI),主要用于数据的抽取、转换、加载和清洗。
核心功能
数据抽取:从多种数据源(数据库、文件、API等)获取数据
数据转换:提供丰富的转换步骤进行数据清洗和处理
数据加载:将处理后的数据加载到目标系统
作业调度:支持复杂的工作流调度和任务编排
附:文章结尾附kettle安装包,请自行下载文章目录
kettle的数据清洗能力
Kettle 提供强大的数据清洗功能:
数据标准化:格式统一、大小写转换等
数据验证:空值检查、范围验证等
数据去重:基于关键字段去除重复记录
数据补全:默认值填充、查找替换等
数据拆分与合并:字段拆分、多表关联等
复杂计算:聚合、排序、排名等
kettle部署流程
1、添加kettle用户(使用普通用户部署)
(1)部署kettle环境时,尽量采用指定账号,切勿使用root等账号,避免出现误删情况。
(2)jdk部署目录及其下所有的文件都授予读可执行的权限 chmod 655 jdk文件部署的目录
(3)使用kettle账号部署
2、部署流程
(1)需要的包:
·jdk1.8 tar 包
·data-integration tar 包
(2)配置jdk变量(如果有的话,可跳过该流程)
#查询是否存在老版本java
bash
rpm -qa |grep java
rpm -e --nodeps
java-1.7.0-openjdk-1.7.0.45-2.4.3.3.el6.x86_64(删除,如果有的话)
使用跟用户root ,在路径/usr/local目录下创建文件夹jdk8 全路径为 /usr/local/jdk8
命令 mkdir /usr/local/jdk8将jdk1.8 tar包复制到该目录下,然后解包 tar -xzvf ./jdk-8u191-linux-x64.tar.gz
解压完成后,配置环境变量(文件为/etc/profile)
顺序 逐次 执行命令 例
bash
echo ' export JAVA_HOME=/usr/local/jdk8/jdk1.8.0_191/' >> /etc/profile;
echo ' export JAVA_BIN=/usr/local/jdk8/jdk1.8.0_191/bin' >> /etc/profile;
echo ' export PATH=$PATH:$JAVA_HOME/bin' >> /etc/profile;
echo ' export CLASS
PATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar' >>
/etc/profile;
echo ' export JAVA_HOME JAVA_BIN PATH CLASSPATH' >> /etc/profile;
source /etc/profile;
执行完成后,检验是否成功,执行
Java -version
如果出现
[root@localhost jdk8]# java -version
java version "1.8.0_191"
Java(TM) SE Runtime Environment (build
1.8.0_191-b12)
Java HotSpot(TM) 64-Bit Server VM (build
25.191-b12, mixed mode)
则说明安装成功(3)、安装data-integration (这个过程开始使用kettle账号操作)
将data-integration 的tar 包或zip 上传到/home/kettle 文件夹下
(4)、 修改/data-integration/spoon.sh文件,增加启动的内存配置。一般设置初始及最大均为4G内存即可。(此时kettle服务已部署完成,部署对应的kettle任务)

cd /home/kettle/data-integration/
chmod +x *.sh
(5)、配置数据源
进入/home/kettle/data-integration/.kettle/目录,修改kettle.properties文件,配置数据源地址。
配置数据源 例mysql(密码要加密配置)
bash
stat.database.ip=127.0.0.1
stat.database.name=test
stat.database.port=3306
stat.database.username=user_name
stat.database.password=pass_word
2be98afc80eca948aa216b97ed8c6fc88密码加密 切换到目录下(有特殊字符需要使用反斜杠转义)
原密码:123456789
加密命令:
sh encr.sh -kettle 123456789

会生成

3、kettle任务部署
(1)kettle整体目录结构(/home/kettle/)

bin目录:存放kettle执行shell脚本
0_kettle_environment_variable.sh:配置java_home、kettle-home、kettle脚本的文件目录、日志级别、日志路径
job目录:存放kettle任务文件,根据数据源存放不同目录

log目录:存入kettle运行日志
log_real_time目录:存放kettle实时同步任务运行日志
(2)任务部署
1、将kettle任务上传至job目录下的对应目录中
2、在bin目录下新建kettle任务执行脚本,设置日志级别,kettle任务入口文件、日志文件
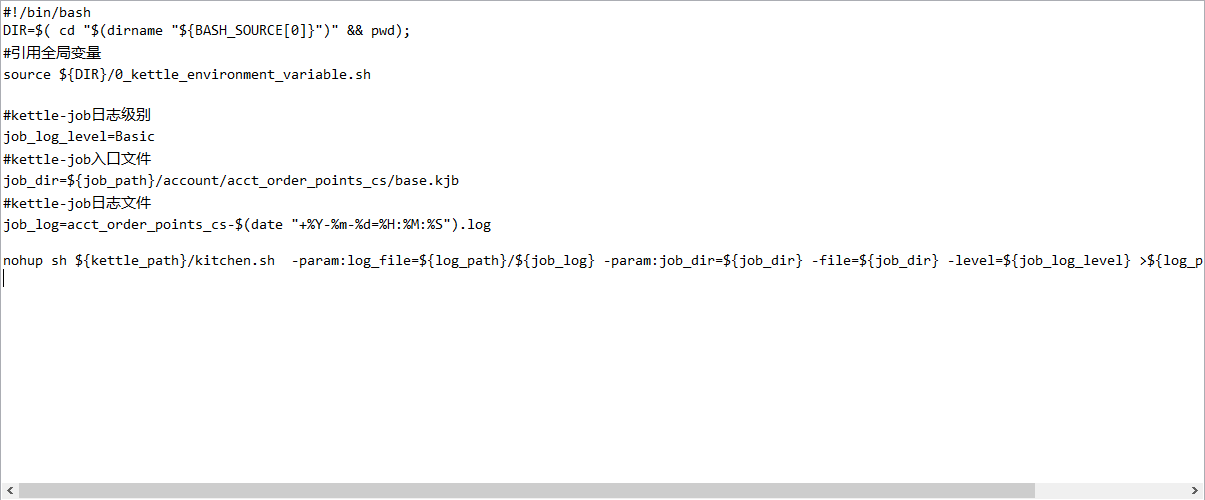
3、添加定时任务
使用crontab-e命令添加定时任务

4、kettle使用的数据库表
kettle数据同步是将数据同步到stat库中的表中
(1)etl_task_config任务配置表
配置任务编码,任务执行时间,数据同步的开始时间,数据同步的结束时间
(2)etl_task_log 任务运行日志记录表
5、kettle任务开发
(1)kettle主体分为Transformation(转换)、job(作业)
(2)job是步骤流,每一个步骤,必须等前面的步骤执行完后面的步骤才可以执行
Transformation是数据流,对数据的同步、数据的处理
(3)kettle任务模板
kettle任务模板分为单库单表模板、分库分表模板
总结
Kettle 以其可视化界面、丰富的功能和活跃的社区支持,成为最流行的开源ETL工具之一,特别适合复杂的数据清洗和同步需求。
[kettle安装包](https://pan.quark.cn/s/dc39ccc4c101)