目标网站: 全球灾害数据平台
温馨提示: 仅供学习交流使用
|----------------|-------------|
| requests() | lxml |
| pandas | numpy |
| matplotlib | seaborn |
| pprint | |
[本案例所使用的库]
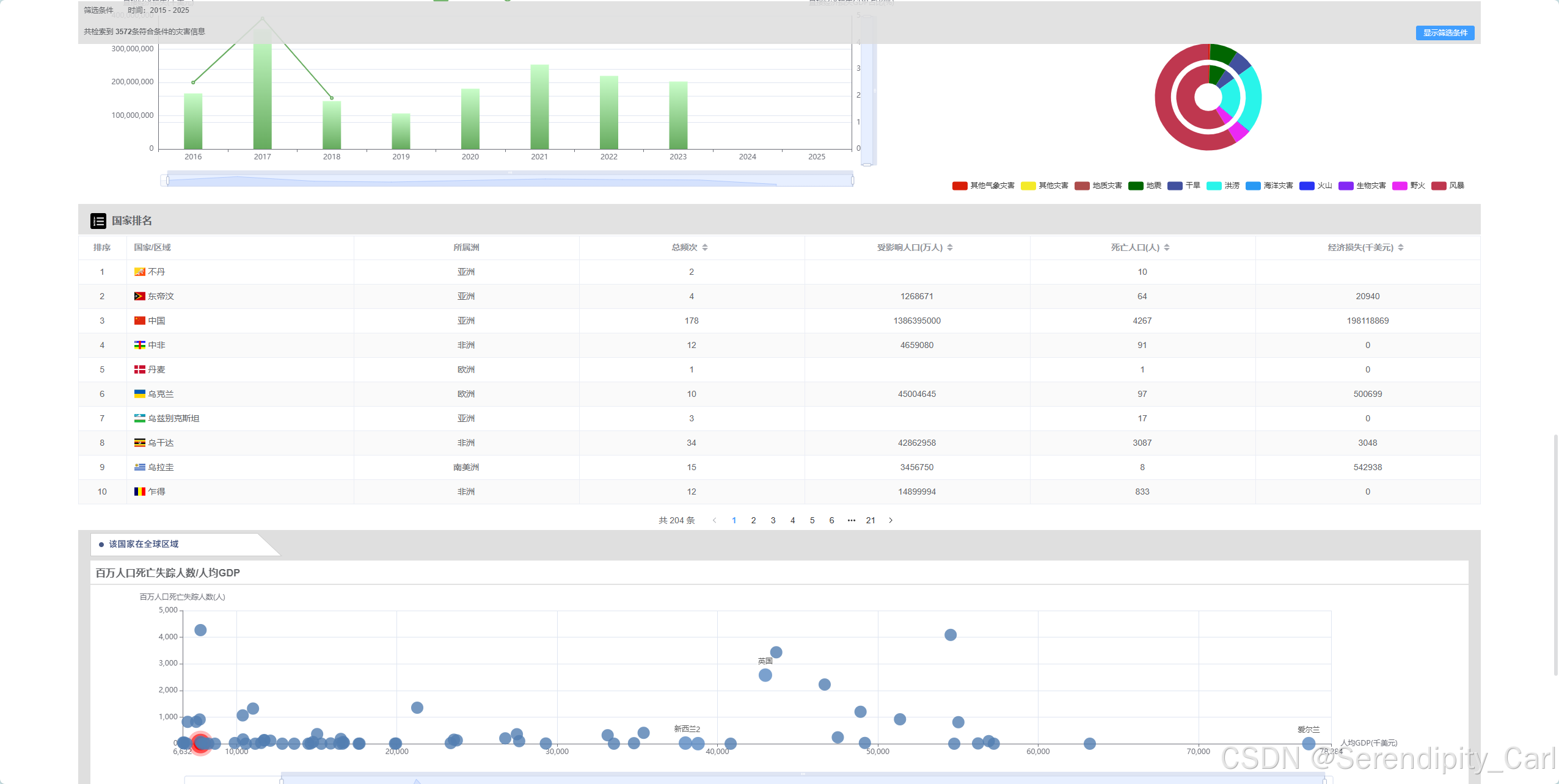
明确需要爬取的内容:
国家地区
所属洲
总频次
受影响人口(万人)
死亡人口(人)
经济损失(千美元)
爬取步骤:
发送请求 模拟浏览器向服务器 发送请求
解析数据 提取想要的数据
保存数据 持久化保存 csv excel 数据库
一.发送请求
确定网页的构造 静态数据 or 动态数据
右击查看网页源代码 Ctrl+F 再搜索框中输入要获取的信息
返回的结果是没有 说明是动态的数据 需要抓包分析
此时 到网页主界面 快捷键(F12) or 右击 检查
点击网络 接着刷新当前界面 或 Ctrl+R(快捷键刷新)
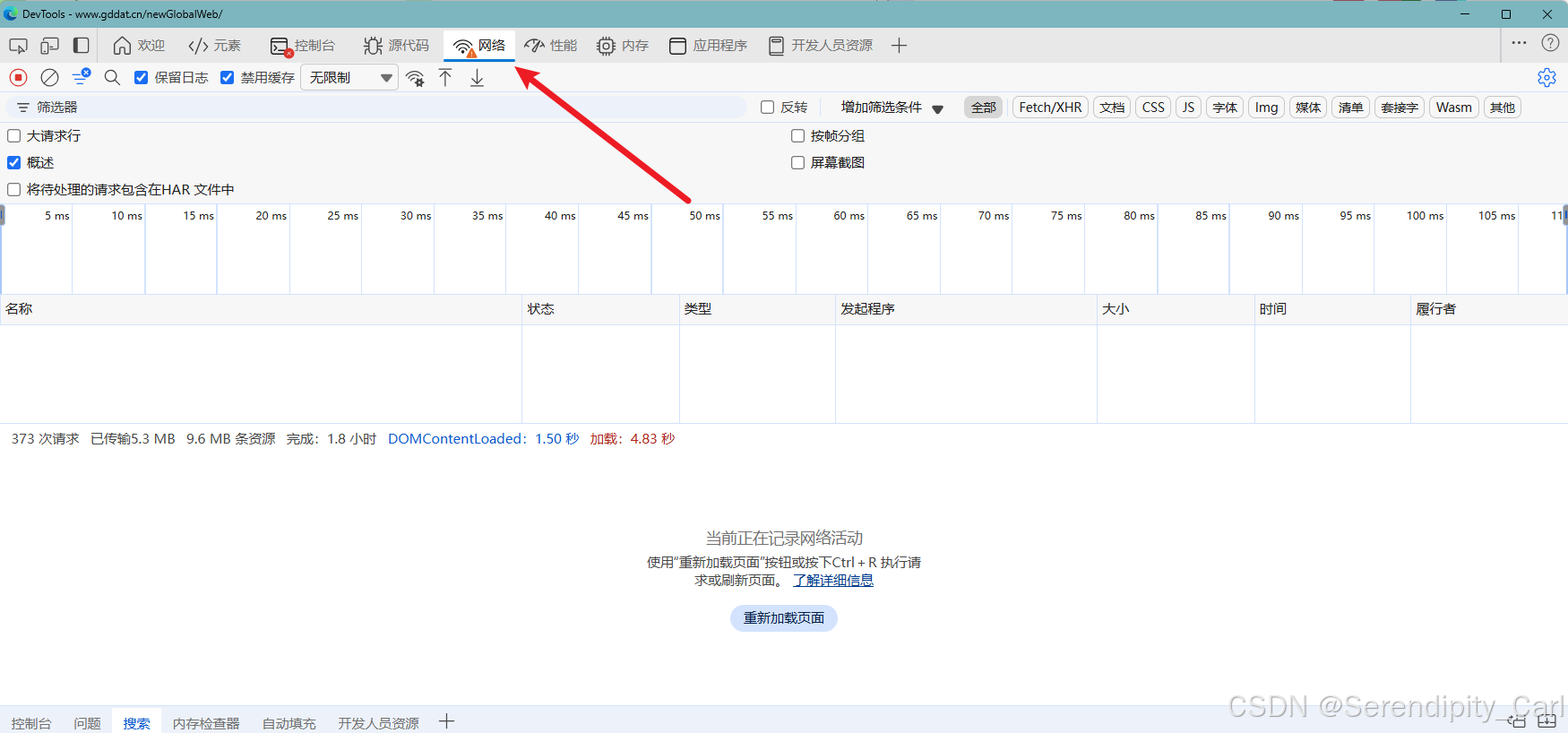
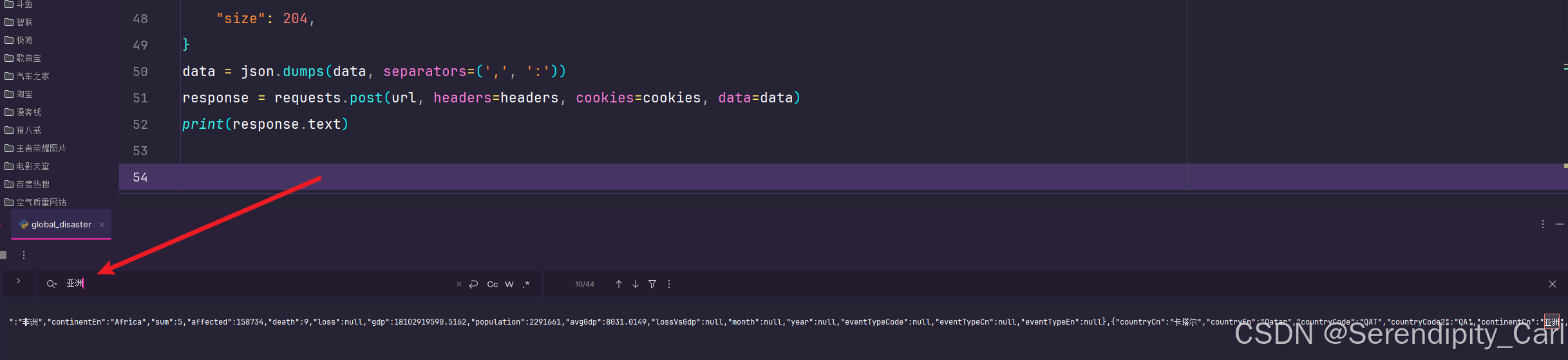
同样地 Ctrl+F 打开搜索框 输入想获取的数据 在返回中的数据包中筛选 找到符合的那个
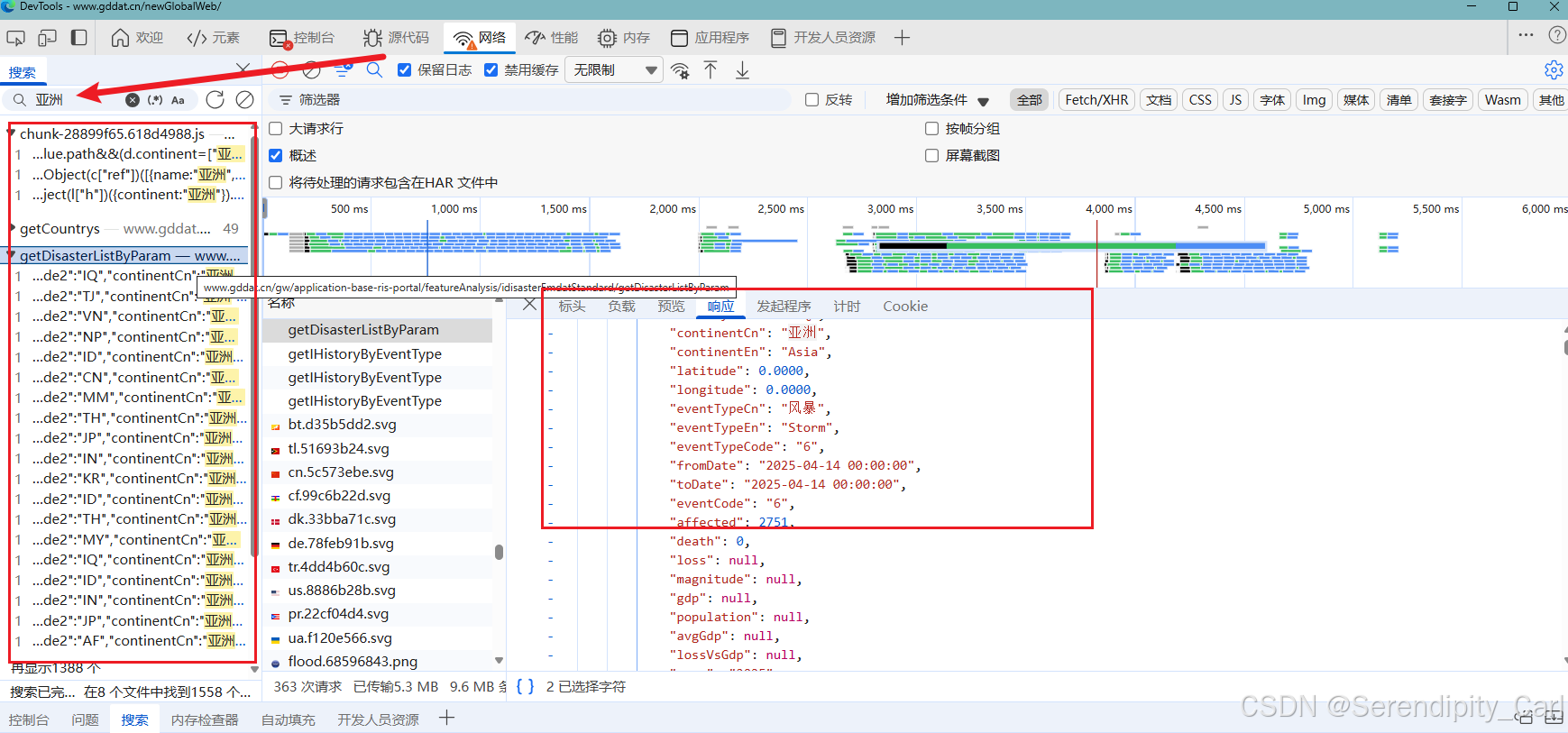
然后 点击标头 这里有请求的一些基本信息 可以查看

我们使用爬虫工具 快速构建 爬虫请求代码
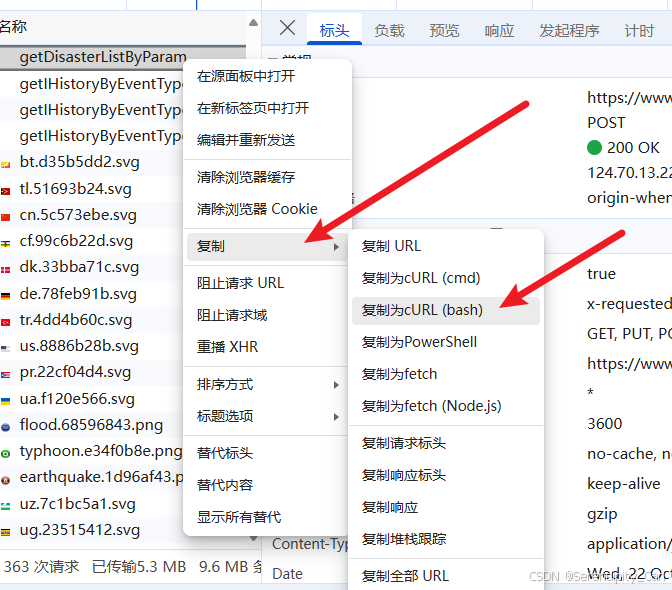
右击相应的数据包 点击复制cURL(bash) 如上图所示 注意是bash
之后打开 工具 爬虫工具库-spidertools.cn
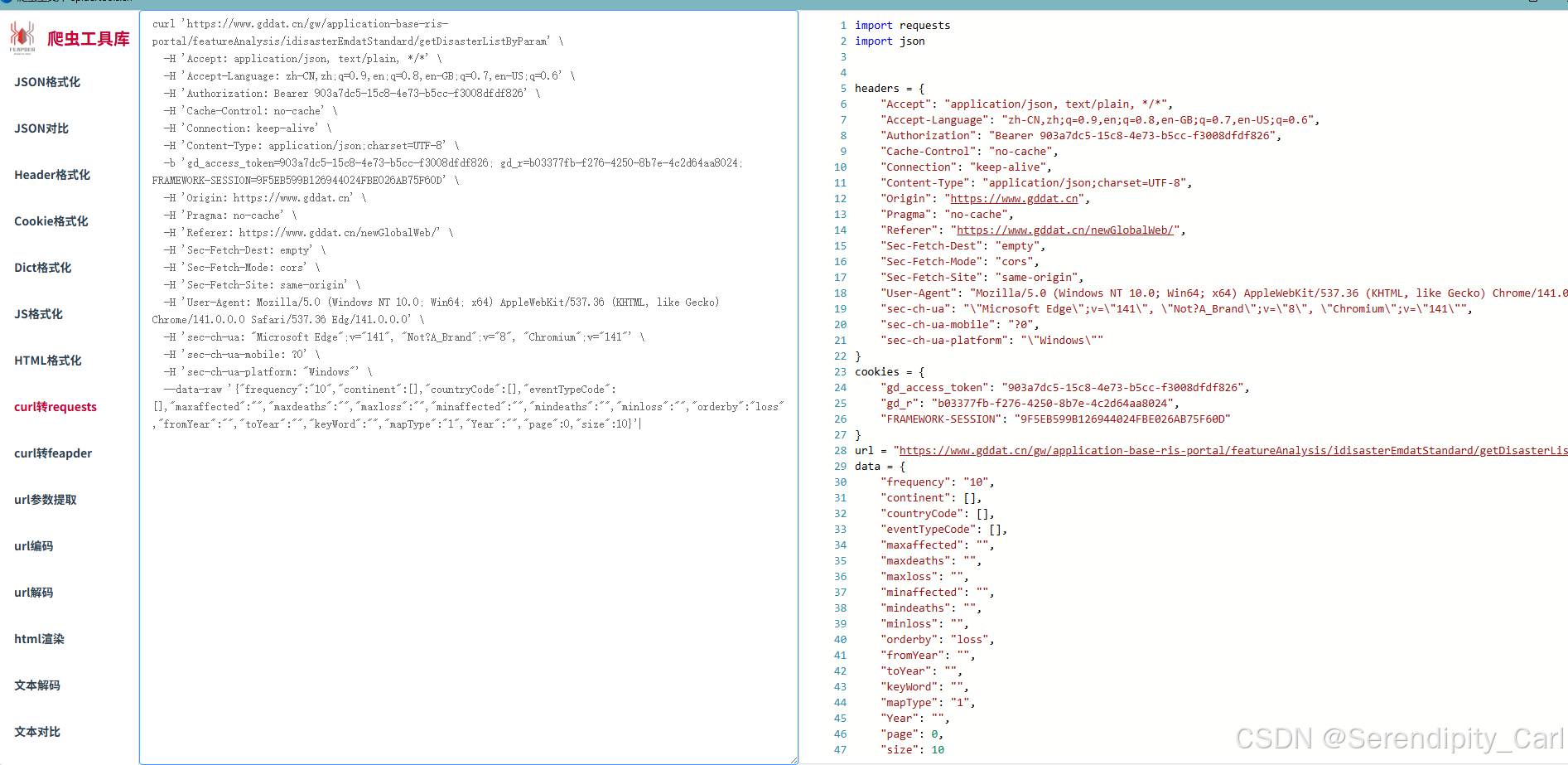
复制右边的代码 到Pycharm中
运行代码 检查想爬取的数据是否在返回的数据中
二. 解析数据
因为返回的是Json格式的数据 需要获取 返回的Json
这里我们可以使用 python 模块 pprint 可以让Json 格式的数据更加美观
python
import pprint
pprint.pprint(response.json())这样输出就会如下图所示
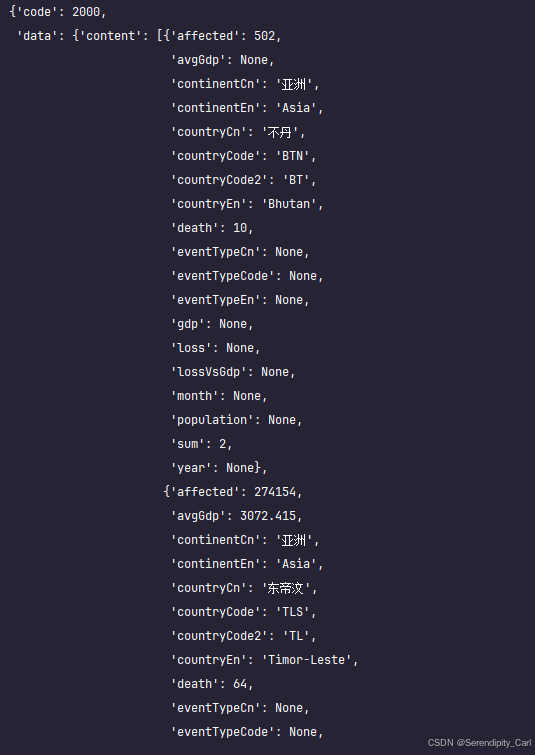
对比页面 找到想要爬取数据的位置 字段名
接着我们从 字典套列表的格式中提取数据 通过键值对取值 For循环遍历列表 取值
python
json_data = response.json()['data']['content']
# 拿到想要的数据
for li in json_data:
country = li['countryCn']
state = li['continentCn']
total = li['sum']
death_people = li['death']
influence_people = li['population']
found_lose = li['loss']
# 可以输出打印 对比数据是否符合三. 保存数据
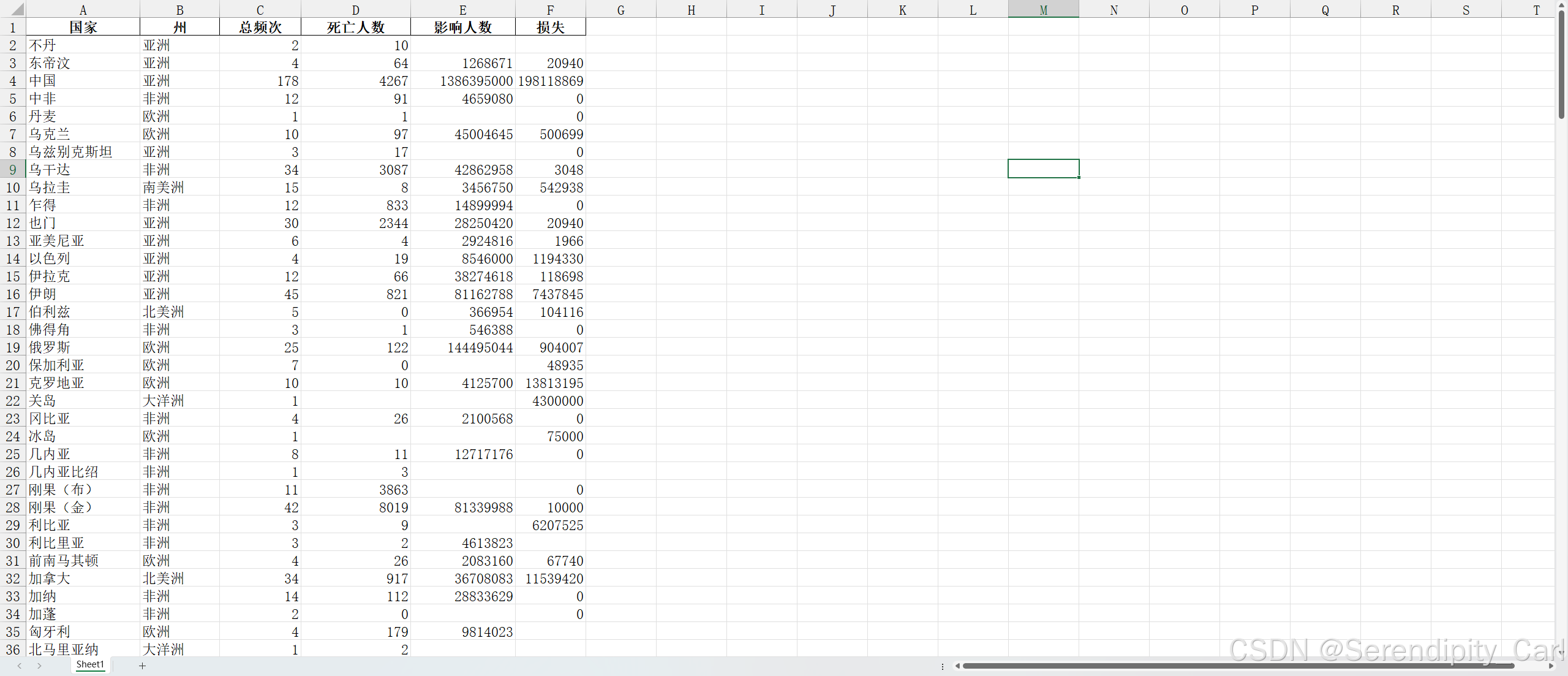
保存数据为 Excel文件
python
# 先将数据存储到 字典中
# 再定义一个列表 将数据添加进去
dit = {
'国家': country,
'州': state,
'总频次': total,
'死亡人数': death_people,
'影响人数': influence_people,
'损失': found_lose
}
# 保存数据 为excel
pd.DataFrame(lis).to_excel('global_disaster.xlsx',index=False)多页爬取 查看请求体里面的data参数 直接 修改 循环即可 我这里写它全部的数据
温馨提示: 它这个 "Authorization" 参数具有时效性 逆向可解决 但不影响我们获取数据
这样就爬取到了我们想要的数据
以下是爬虫部分的全部代码
python
import pprint
import pandas as pd
import requests
import json
headers = {
"Accept": "application/json, text/plain, */*",
"Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6",
"Authorization": "Bearer b81b81e2-da54-4548-ac4f-4504ba437b51",
"Cache-Control": "no-cache",
"Connection": "keep-alive",
"Content-Type": "application/json;charset=UTF-8",
"Origin": "https://www.gddat.cn",
"Pragma": "no-cache",
"Referer": "https://www.gddat.cn/newGlobalWeb/",
"Sec-Fetch-Dest": "empty",
"Sec-Fetch-Mode": "cors",
"Sec-Fetch-Site": "same-origin",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/141.0.0.0 Safari/537.36 Edg/141.0.0.0",
"sec-ch-ua": "\"Microsoft Edge\";v=\"141\", \"Not?A_Brand\";v=\"8\", \"Chromium\";v=\"141\"",
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": "\"Windows\""
}
cookies = {
"你的cookie"
}
url = "https://www.gddat.cn/gw/application-base-ris-portal/featureAnalysis/idisasterEmdatStandard/getIHistoryByCountry"
data = {
"continentCn": "",
"frequency": "10",
"continent": [],
"countryCode": [],
"eventTypeCode": [],
"maxaffected": "",
"maxdeaths": "",
"maxloss": "",
"minaffected": "",
"mindeaths": "",
"minloss": "",
"orderby": "sum",
"fromYear": "",
"toYear": "",
"Year": "",
"page": 0,
"size": 204,
}
data = json.dumps(data, separators=(',', ':'))
response = requests.post(url, headers=headers, cookies=cookies, data=data)
lis = []
json_data = response.json()['data']['content']
for li in json_data:
country = li['countryCn']
state = li['continentCn']
total = li['sum']
death_people = li['death']
influence_people = li['population']
found_lose = li['loss']
dit = {
'国家': country,
'州': state,
'总频次': total,
'死亡人数': death_people,
'影响人数': influence_people,
'损失': found_lose
}
lis.append(dit)
pd.DataFrame(lis).to_excel('global_disaster.xlsx',index=False)数据清洗:

这里我们选择直接将缺失值删除
python
import pandas as pd
# 读取文件
df = pd.read_excel('global_disaster.xlsx')
# 将损失为缺失值的国家名字 展示出来
country_lose = df[df['损失'].isna()]['国家'].tolist()
# 删除缺失值
df.dropna(subset='损失', inplace=True)
# 统计缺失值的数量
total = df['损失'].isna().sum()
# 展示处理后的前五条记录
print(df.head())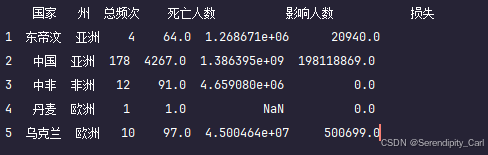

python
state_num = df['州'].unique()没有不符合要求的命名

python
# iqr 处理异常值
lo = df['死亡人数'].quantile(0.25)
up = df['死亡人数'].quantile(0.75)
iqr = up - lo
lower = lo - 1.5 * iqr
upper = up + 1.5 * iqr
# 未清理前的数据长度
before_clean = len(df)
# df = df[(df['死亡人数'] > lower) & (df['死亡人数'] < upper)]
# 异常值 展示
# 异常值
false_death = df[(df['死亡人数'] < lower) | (df['死亡人数'] > upper)]
df['死亡人数'] = np.where(
(df['死亡人数'] < lower) | (df['死亡人数'] > upper),
None,
df['死亡人数']
)
df.dropna(subset='死亡人数',inplace=True)
print(len(df))
# 思路是 将异常值用None值代替 后续删除
python
df['影响人数'] = pd.to_numeric(df['影响人数'], errors='coerce')
df['损失'] = pd.to_numeric(df['损失'], errors='coerce')
# print(df.info())
# print(df.head(5))
python
duplicated = df.duplicated().sum()
df.drop_duplicates(inplace=True)
# print(len(df))
python
df['损失'] = (df['损失'] / 1000000).round(2)
print(df.head())
python
consistent_check = df[(df['总频次'] == 0) & (df['死亡人数'] > 0)]
print(consistent_check)数据可视化:
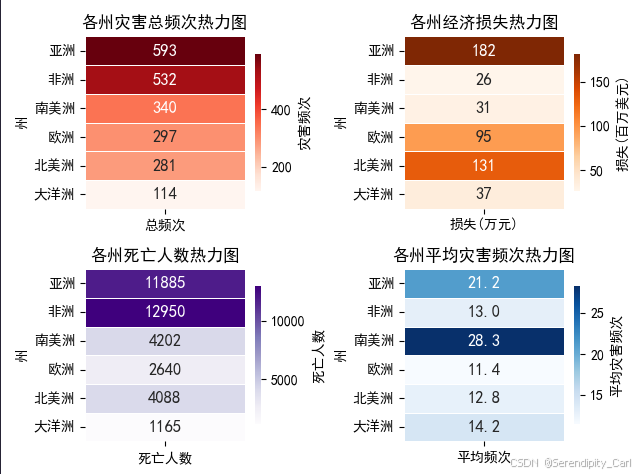
画出各州灾害总频次热力图 经济损失热力图 死亡人数热力图 平均灾害频次热力图
python
# 导包
import matplotlib.pyplot as plt
from matplotlib import rcParams
import seaborn as sns
import pandas as pd
df = pd.read_excel('cleaned_global_disaster.xlsx')
# 设置字体 为默认的黑体
rcParams['font.family'] = 'SimHei'
region_summery = df.groupby(['州']).agg({
'总频次': 'sum',
'死亡人数': 'sum',
'损失': 'sum',
'国家': 'count',
}).rename(columns={'国家': '国家数量', '损失': '损失(万元)'}).sort_values(by=['总频次', '损失(万元)'],
ascending=[False, False])
# 画子图
plt.subplot(2, 2, 1)
# annot = True 表示在热力图中显示对应的数值
# fmt = '.0f' 表示将数值类型的格式化为整数
# colormap的缩写 cmap 指定用红色系的颜色映射 Reds
# 设置cbar_Kws 用于设置颜色条的属性
# shrink 用于设置颜色条的大小
# annot_kws 用于设置注解的属性 字体 大小
# linewidths 设置单元格边框
sns.heatmap(region_summery[['总频次']], annot=True, fmt='.0f', cmap='Reds', linewidths=0.5,
annot_kws={'size': 12, 'weight': 'bold'}, cbar_kws={'label': '灾害频次', 'shrink': 0.8})
plt.title('各州灾害总频次热力图')
plt.subplot(2, 2, 2)
sns.heatmap(region_summery[['损失(万元)']],
annot=True,
annot_kws={'size': 12, 'weight': 'bold'},
linewidths=0.5,
fmt='.0f',
cmap='Oranges',
cbar_kws={'label': '损失(百万美元)', 'shrink': 0.8}
)
plt.title('各州经济损失热力图')
plt.subplot(2, 2, 3)
sns.heatmap(region_summery[['死亡人数']],
annot=True,
annot_kws={'size': 12, 'weight': 'bold'},
linewidths=0.5,
fmt='.0f',
cmap='Purples',
cbar_kws={'label': '死亡人数', 'shrink': 0.8}
)
plt.title('各州死亡人数热力图')
plt.subplot(2, 2, 4)
region_summery['平均频次'] = region_summery['总频次'] / region_summery['国家数量']
sns.heatmap(region_summery[['平均频次']],
annot=True,
annot_kws={'size': 12, 'weight': 'bold'},
fmt='.1f',
cmap='Blues',
linewidths=0.5,
cbar_kws={'label': '平均灾害频次', 'shrink': 0.8}
)
plt.title('各州平均灾害频次热力图')
plt.tight_layout()
plt.show()
# print(region_summery)如下图: