Deepseek学习笔记
Deepseek R1常见的主要有如下几个常用的参数版本:
1.5B,基本所有电脑都跑的起来,开发的时候小规模调试很方便,你可以用这个来熟悉各种开发语言与其打交道。
7B,对电脑的配置会有一定的要求,通常4090显卡或平果最新的M系列芯片都可以跑,我有一个1650也能勉强跑起来,但明显速度慢很多。
70B,基本能满足企业的应用。成本基本都在百万以内。
671B,传说中的满血版,部署需要大规模硬件投资。常规部署的成本在百万以上,但也有小成本方案,比如8台M4 pro的Mac mini。如果考虑到模型微调这个成本还会成倍增长。
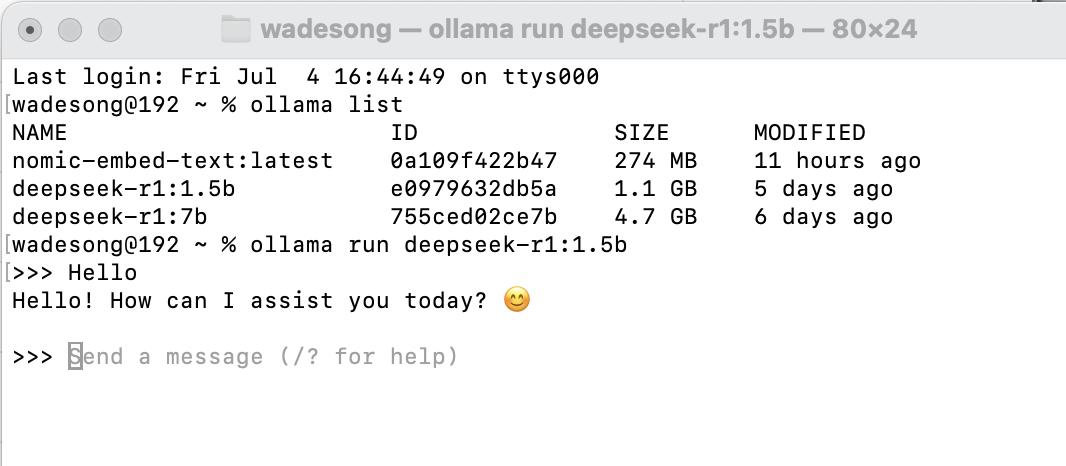
参数的差距会有多大的不同,比如下图我用1.5B,大小写的问题居然就识别不出来。

所以条件足够的话,开发尽量选7B。
模型的知识怎么来的
从官方得到的都是通用大模型,是基于海量的信息训练得来的。如果需要建立垂直领域(或者说某一专业领域)的解决方案,比如医疗,法律或者公司内部文件,可以对模型进行微调或者通过RAG。
RAG个人理解是给大模型之外挂接了一个增量模型。是大模型的一个外部知识库。
它俩的区别可以比作成一个历史考试,前者是闭卷考时,后者是开卷考试。闭卷考试就是经过一个学期的学习,你已经把知识记在了脑子里。而开卷考试,就是你现去查书中去寻找答案。所以你能看到,成绩一般的学了一个学期学生,这么考下来可能跟一个聪明点的小学生开卷考同样的东西,成绩不会差太多。
微调和RAG怎么选
先说一下,这个微调,别看有个微,其牵扯到的资源和成本可不少。
说回考试的例子,如果你想通过闭卷考时那么就需要长时间的学习,但如果是闭卷考时,在了解一定的技巧之上那么你也能顺利的通过考试。可以看到这两种方式的时间成本差异是很大的。
此外模型的微调需要的硬件成本巨高,而且需要大量的专业内知识数据,以及大量的时间(以周甚至月记)。而且微调比较黑盒,结果难以预测。
RAG方案可以快速的给大模型挂接知识,成本低见效快。
即使是你两三个文档的更新,RAG也照样能接待,但微调的话可能合不上成本。
通常对于有海量固定知识的情况适用于模型微调,但是因为其时间很长成本高,很难获取最新的知识,所以可以通过模型微调加RAG补充最新或者经常变化的那部分来解决。
RAG是目前大多数企业采用的方式,当然缺点是如果是海量数据(PB以上)那么会有性能问题。所以常规的方案还是海量数据用模型微调,增量或者经常变化的数据或者信息用RAG。
从另一个角度我问了下豆包,10GB(我也问了100GB的)的资料,微调和RAG哪个更适合,答案是RAG,尤其资料是经常变化的。但到什么级别必须得用微调,这个需要考虑的因素很多,在数据量上没有一个固定的答案。
成熟的应用
公司内的问答。可以把公司内的数据通过RAG读取,然后供所有员工查询。
开发文档规范审查,比如你创建的数据库,是否符合命名规范。
个人知识库,把自己多年沉淀的文档输入知识库,方便自己随时查询。
对于一个程序员:告诉我一个功能怎么实现,或者给我生成一个文档。
对于一个文员:给我生成一篇文章。
对于自媒体:给我写一个关于某某某的文案。
对于我写这篇文章:学习各个知识点,帮我验证一些自己的理解。
总之关于AI的潜力开发空间是很大的,了解了它之后你才会知道在什么场合他能帮到你。
个人怎么玩
不管是苹果还是Windows,先下载Ollama,然后在Ollama里下载对应的Deepseek,这个操作完成后,就可以在命令行下玩问答。但如前面所说,如果是1.5B,那么不要对回答期望太高,如果部署了7B,那么勉强可玩。以上你要是想做开发什么的,足够了。
进一步想玩RAG来搭建个人知识库,可以下载一个anything LLM。这个工具的优点是操作有UI,不需要敲复杂的指令。需要注意的是在ollma里不仅需要pull一个R1模型,还需要pull一个embed模型,然后在anything LLM里配置好就可以了。如果你想尝试本地deepseek能干啥,个人知识库怎么搭建,用这个就够了。
如果你想进阶折腾一下,想大概了解下更专业点的方案,那么在这个基础上就可以自己去折腾RAG方案,比如RAGFLOW或者Dify。这个要下载和配置很多东西,没有点经验的话,按照网络上你能搜到的能搜索到的方法都不一定能走的通。而且又Git又docker的,没点方法有些步骤搞不定。
至于微调的话这个实在太复杂,不建议个人在自己的设备上折腾。