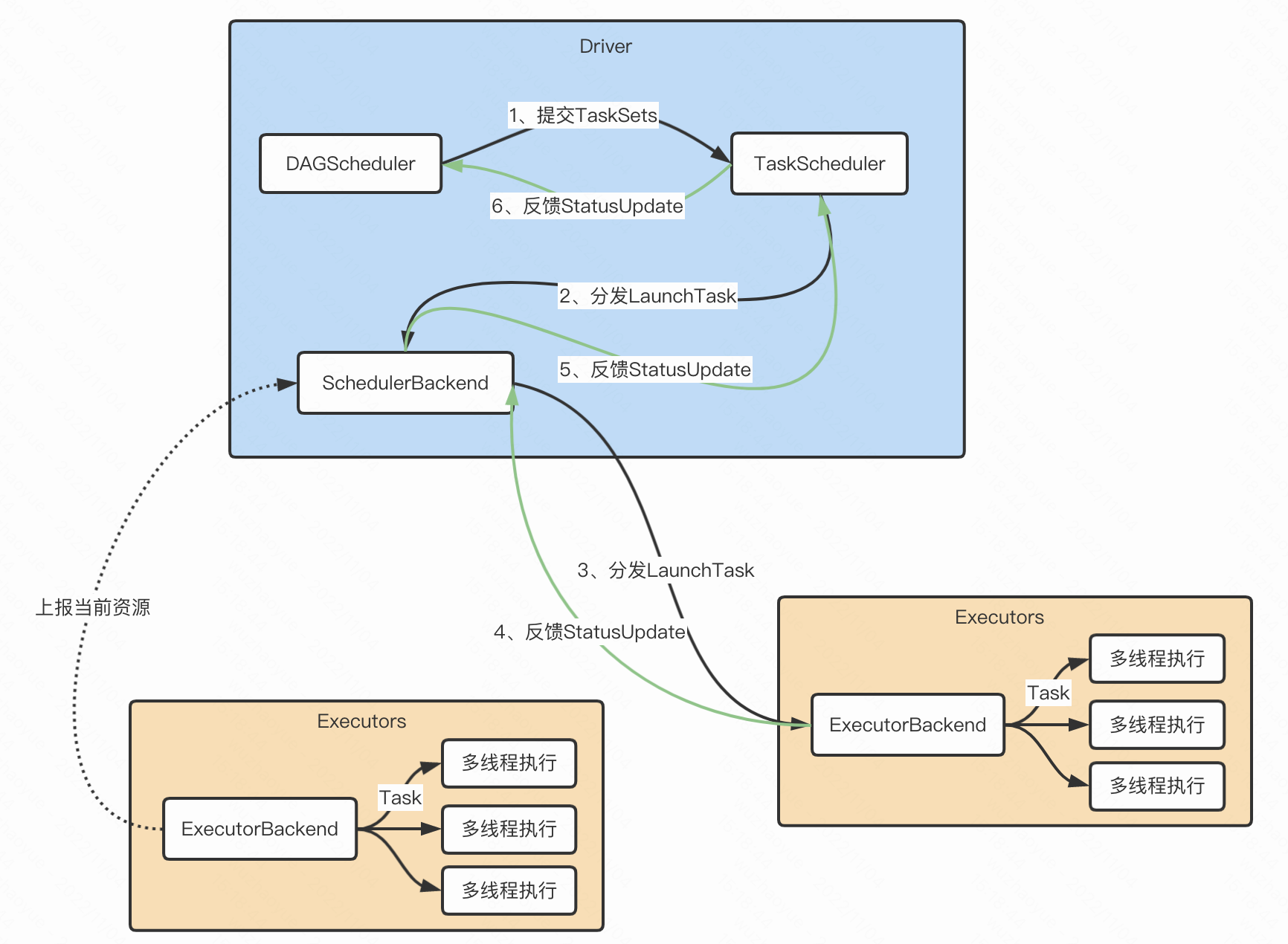
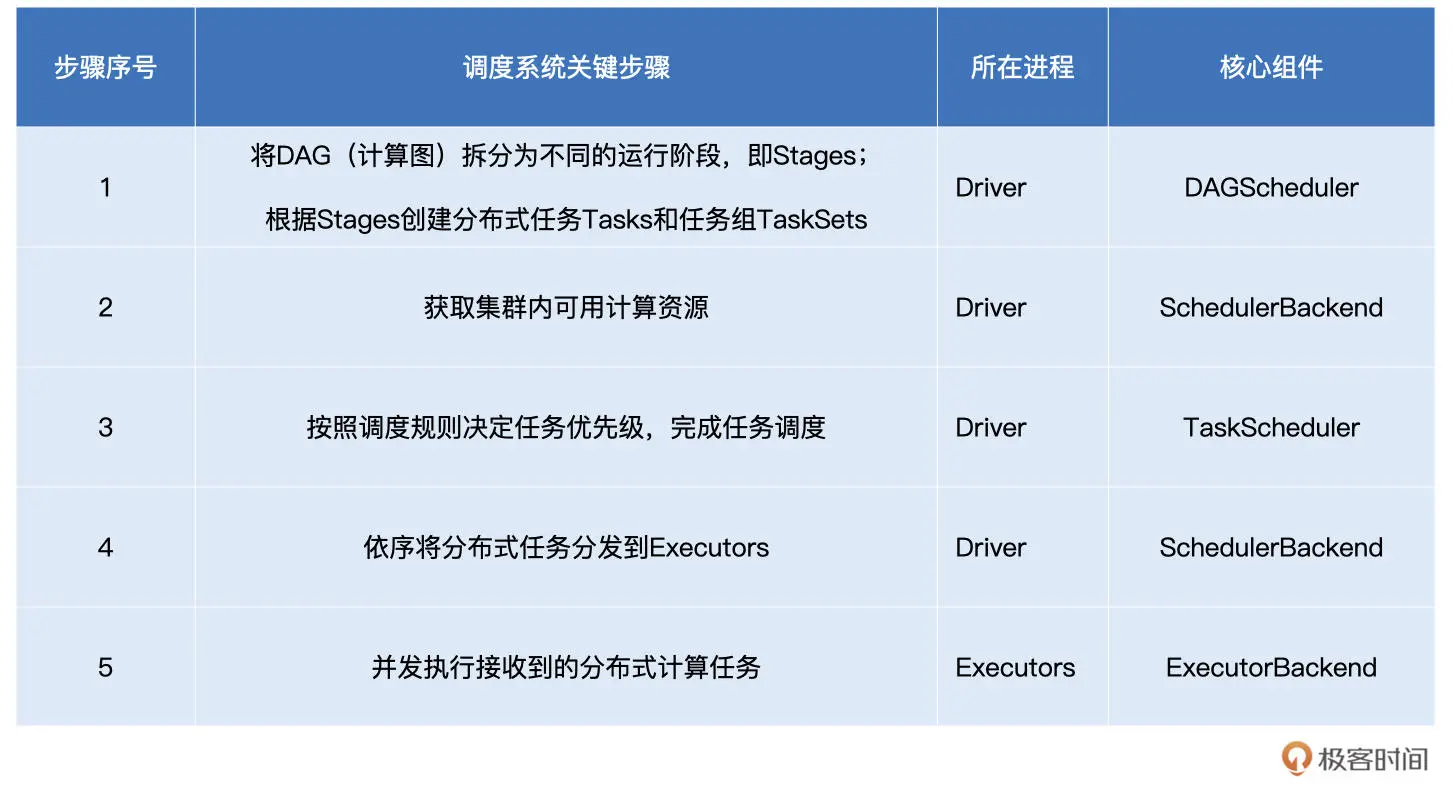
一、Spark架构设计
二、Spark常用算子
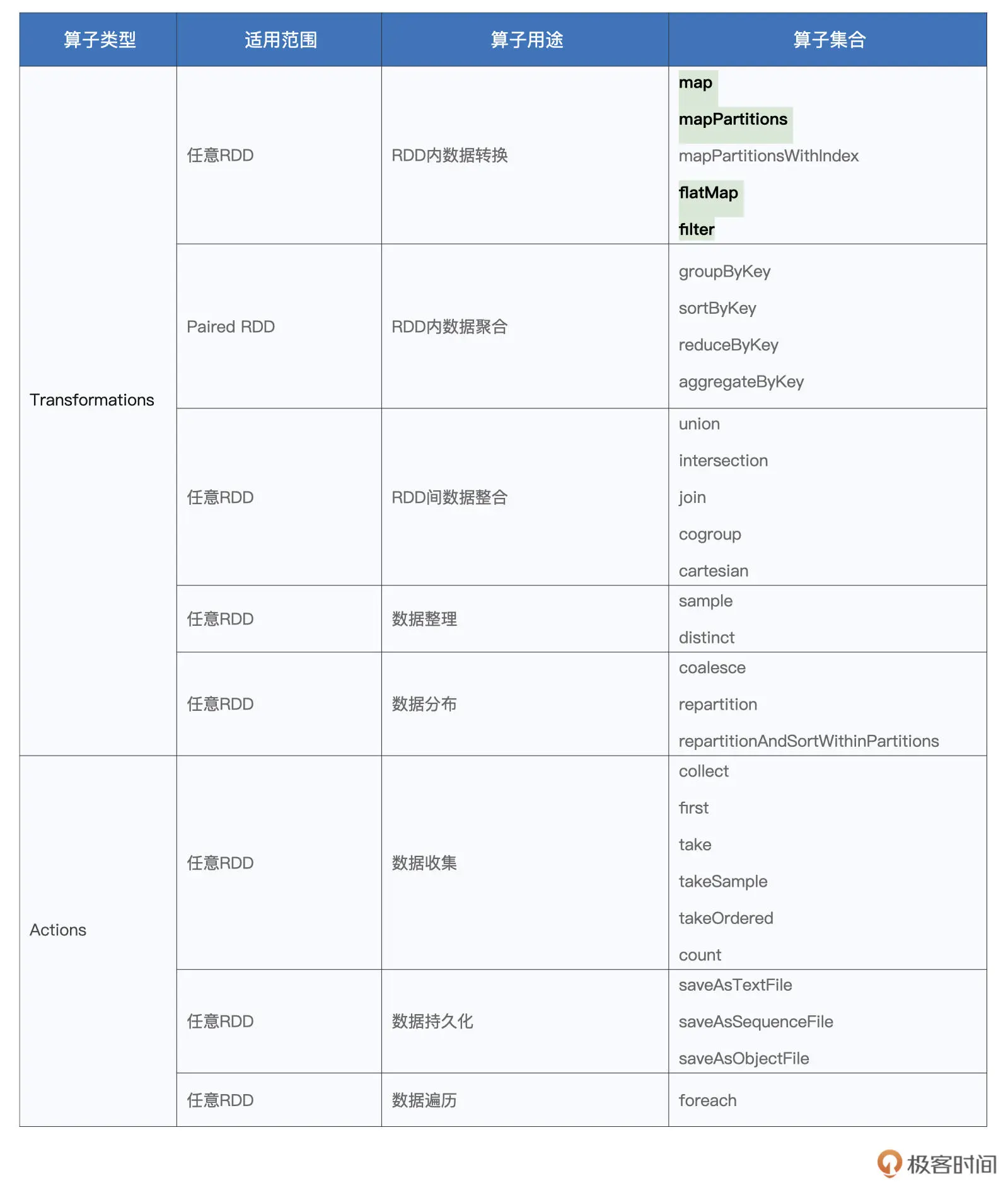
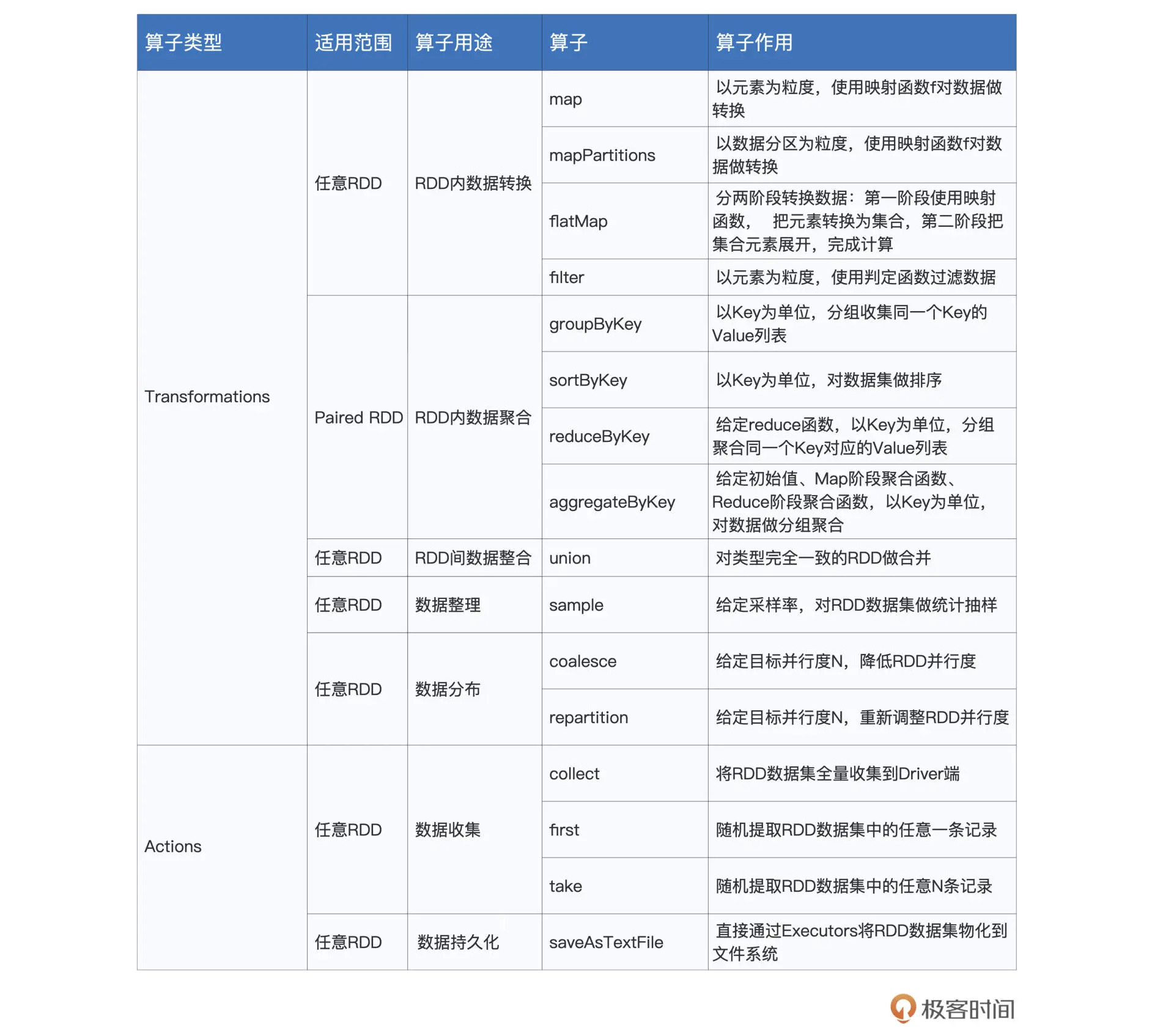
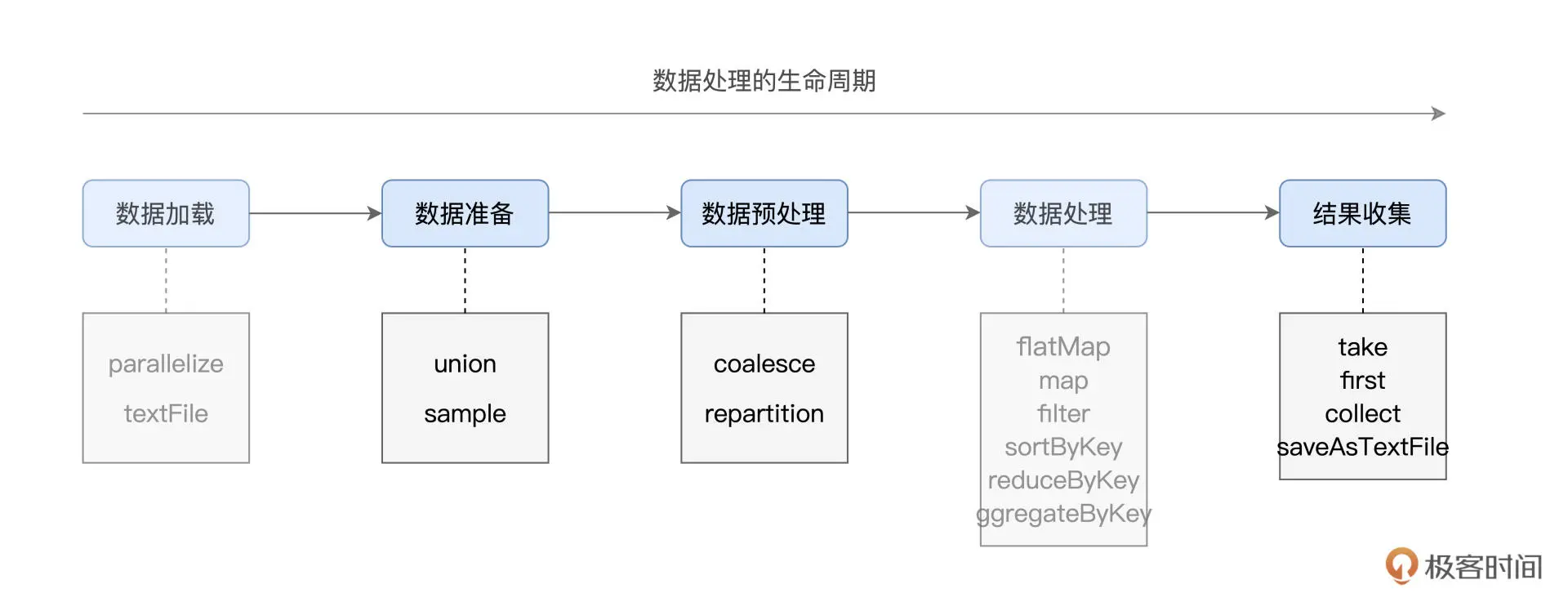
tips1: 数据处理的生命周期
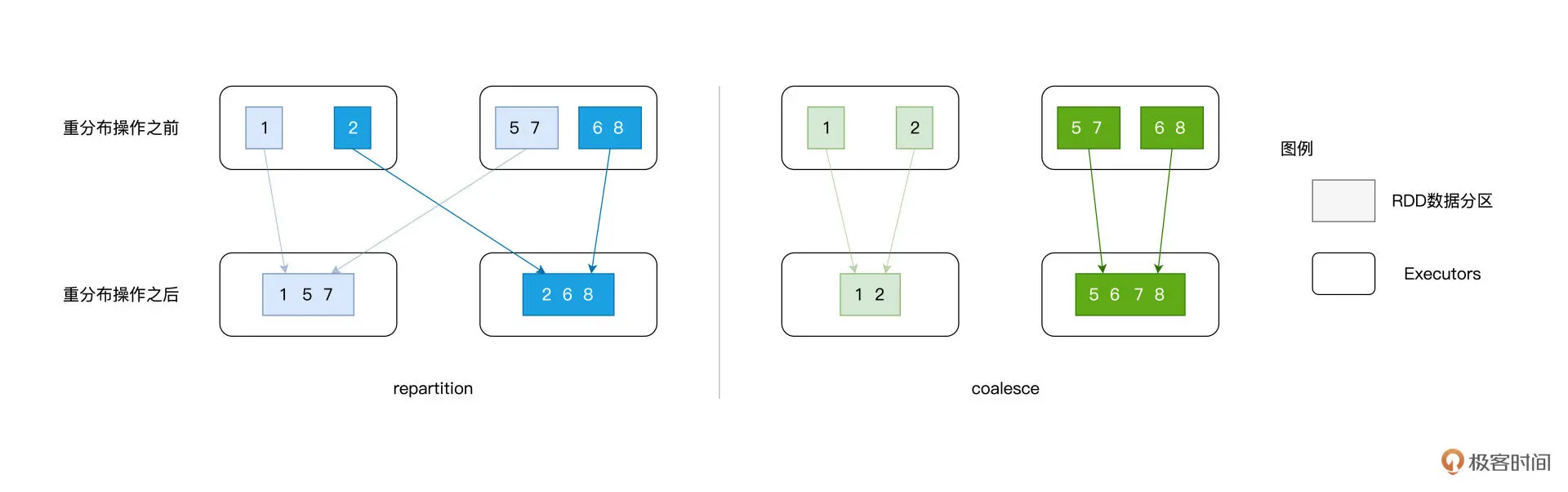
tips2: repartition vs coalesce区别:
- 可以使用 repartition 算子随意调整(提升或降低)RDD 的并行度,而 coalesce 算子则只能用于降低 RDD 并行度
- repartitionrepartition的计算过程都是先哈希、再取模,得到的结果便是该条数据的目标分区索引。对于绝大多数的数据记录,目标分区往往坐落在另一个 Executor、甚至是另一个节点之上,所以避免不了shuffle
- coalesce在降低并行度的计算中,它采取的思路是把同一个 Executor 内的不同数据分区进行合并(只会在当前进程内进行数据合并),不会存在shuffle
参考:https://time.geekbang.org/column/article/423131
三、Shuffle机制
Shuffle 的本意是扑克的"洗牌",在分布式计算场景中,它被引申为集群范围内跨节点、跨进程的数据分发
Map 阶段与 Reduce 阶段,通过生产与消费 Shuffle 中间文件的方式,来完成集群范围内的数据交换。换句话说,Map 阶段生产 Shuffle 中间文件,Reduce 阶段消费 Shuffle 中间文件,二者以中间文件为媒介,完成数据交换
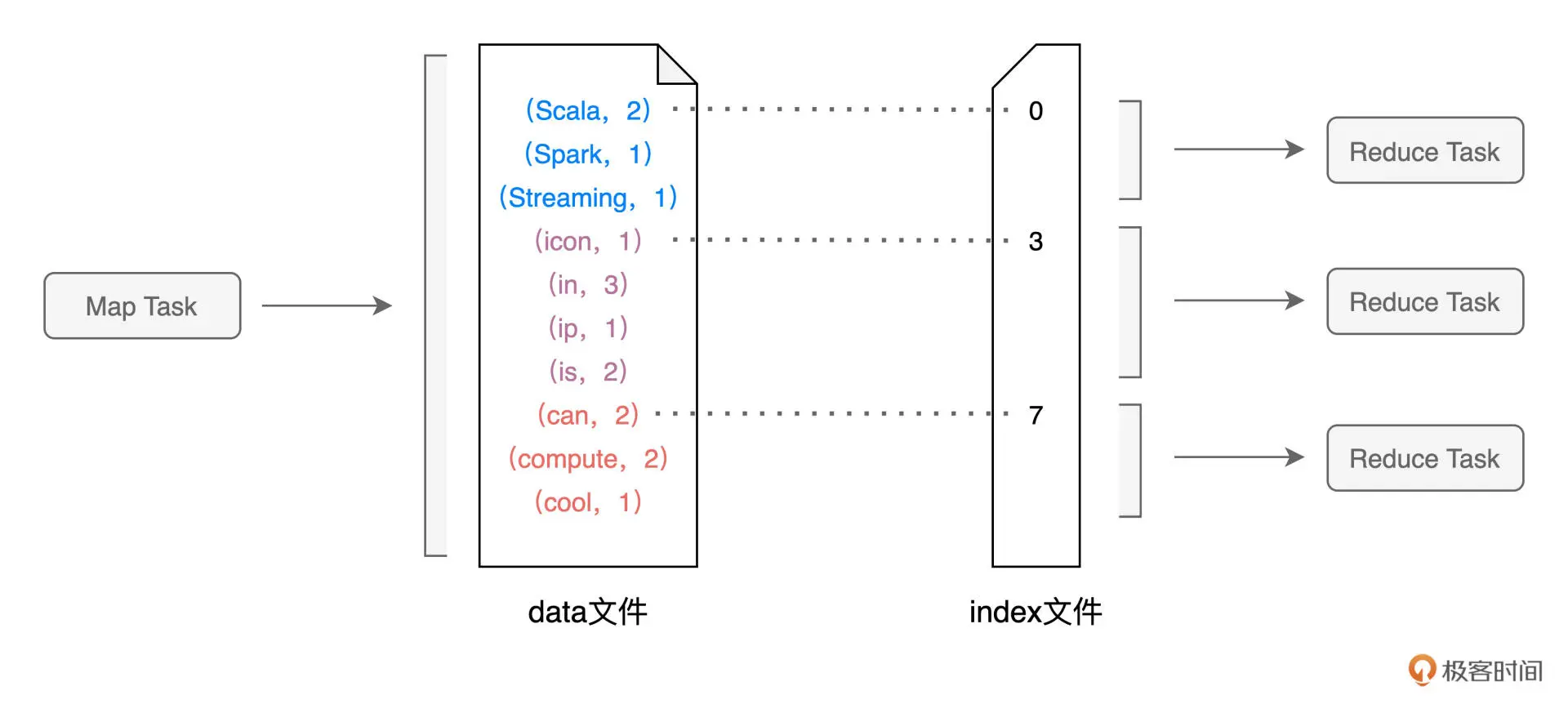
在 Map 执行阶段,每个Map Task都会生成包含 data 文件与 index 文件的 Shuffle 中间文件。Shuffle 文件的生成,是以 Map Task 为粒度的,Map 阶段有多少个 Map Task,就会生成多少份(注意:这里是份,不是个) Shuffle 中间文件
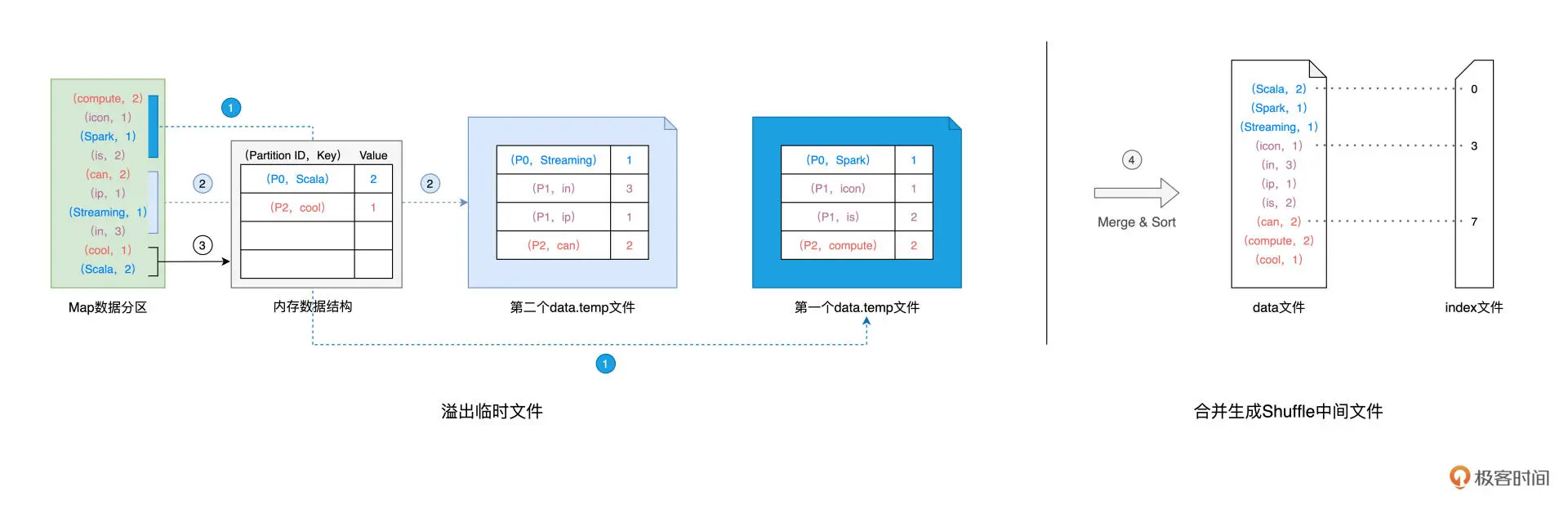
Shuffle Write:在生成中间文件的过程中,Spark 会借助一种类似于 Map 的数据结构,来计算、缓存并排序数据分区中的数据记录。Spark 读取分区内容并向 Map 结构中插入数据,直到 Map 结构被灌满而溢出,如此往复,直到数据分区中所有的数据记录都被处理完毕。对所有临时文件和内存数据结构中剩余的数据记录做归并排序,生成数据文件和索引文件
Shuffle Read:对于所有 Map Task 生成的中间文件,Reduce Task 需要通过网络从不同节点的硬盘中下载并拉取属于自己的数据内容。不同的 Reduce Task 正是根据 index 文件中的起始索引来确定哪些数据内容是"属于自己的"。
分区计算公式:P = Hash(Record Key) % N;N是reduce task数量,P是reduce task的分区编号,每个reduce task根据各自的分区编号拉取中间文件
问:假设5个map task,3个reduce task,会生成多少个中间文件?
答:每个map task根据Hash(Record Key)) % 3,生成3个中间文件,共5个map task,最多生成15个中间文件
参考:https://time.geekbang.org/column/article/420399
四、Spark运行时-内存管理及分配
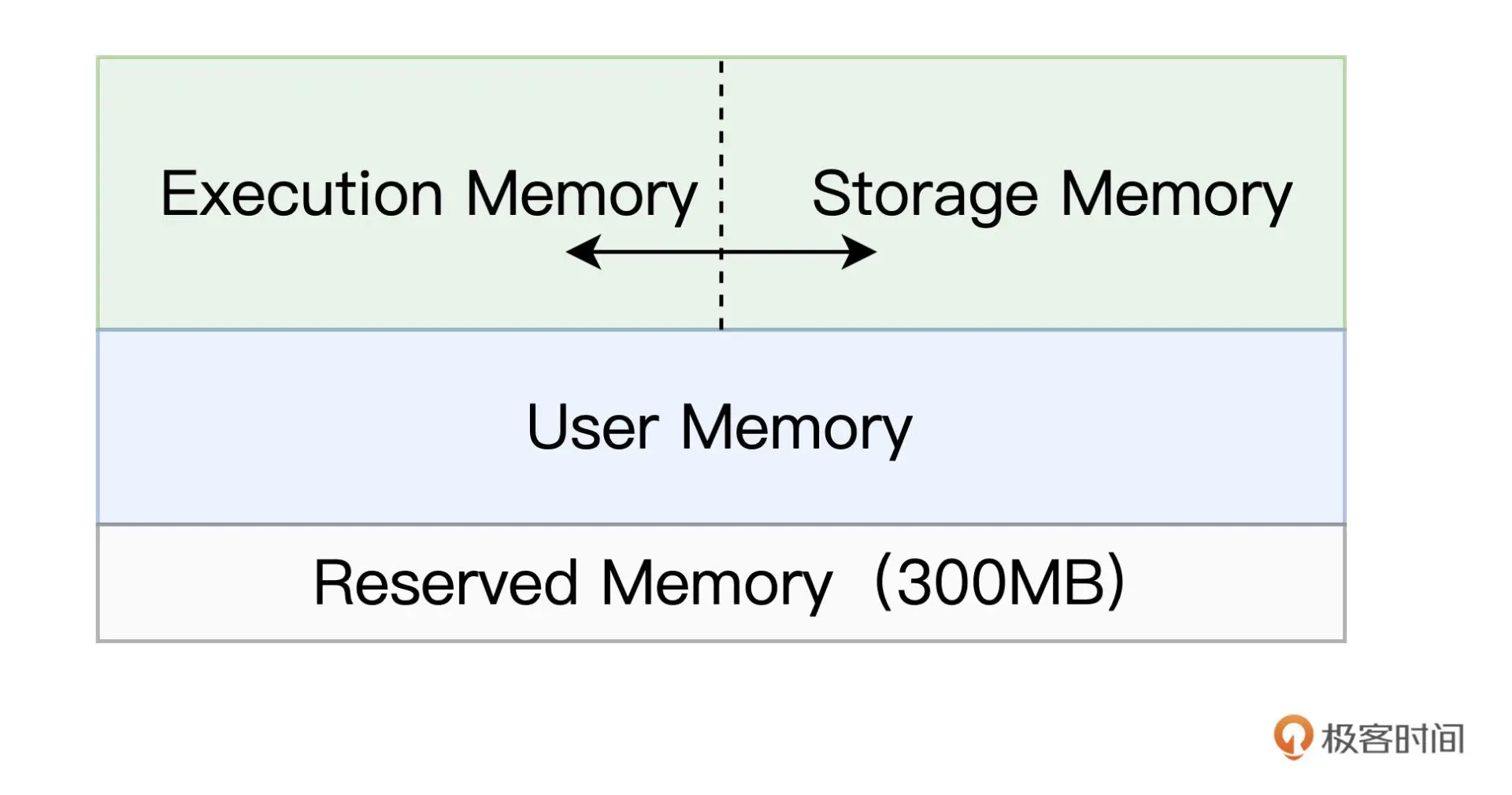
Reserved Memory:固定为 300MB,不受开发者控制,它是 Spark 预留的、用来存储各种 Spark 内部对象的内存区域
User Memory:用于存储开发者自定义的数据结构,例如 RDD 算子中引用的数组、列表、映射等等
Execution Memory:用来执行分布式任务。分布式任务的计算,主要包括数据的转换、过滤、映射、排序、聚合、归并等环节,而这些计算环节的内存消耗,统统来自于 Execution Memory
Storage Memory:用于缓存分布式数据集,比如 RDD Cache、广播变量等等。RDD Cache 指的是 RDD 物化到内存中的副本。在一个较长的 DAG 中,如果同一个 RDD 被引用多次,那么把这个 RDD 缓存到内存中,往往会大幅提升作业的执行性能
在 1.6 版本之后,Spark 推出了统一内存管理模式,在这种模式下,Execution Memory 和 Storage Memory 之间可以相互转化
- 如果对方的内存空间有空闲,双方可以互相抢占;
- 对于 Storage Memory 抢占的 Execution Memory 部分,当分布式任务有计算需要时,Storage Memory 必须立即归还抢占的内存,涉及的缓存数据要么落盘、要么清除;
- 对于 Execution Memory 抢占的 Storage Memory 部分,即便 Storage Memory 有收回内存的需要,也必须要等到分布式任务执行完毕才能释放。
RDD Cache使用
// 按照单词做分组计数
val wordCounts: RDD[(String, Int)] = kvRDD.reduceByKey((x, y) => x + y)
wordCounts.cache // 使用cache算子告知Spark对wordCounts加缓存
wordCounts.count // 触发wordCounts的计算,并将wordCounts缓存到内存
// wordCounts.persist(MEMORY_ONLY) // 或者这样写,比较推荐
// 打印词频最高的5个词汇
wordCounts.map{case (k, v) => (v, k)}.sortByKey(false).take(5)
// 将分组计数结果落盘到文件
val targetPath: String = _
wordCounts.saveAsTextFile(targetPath)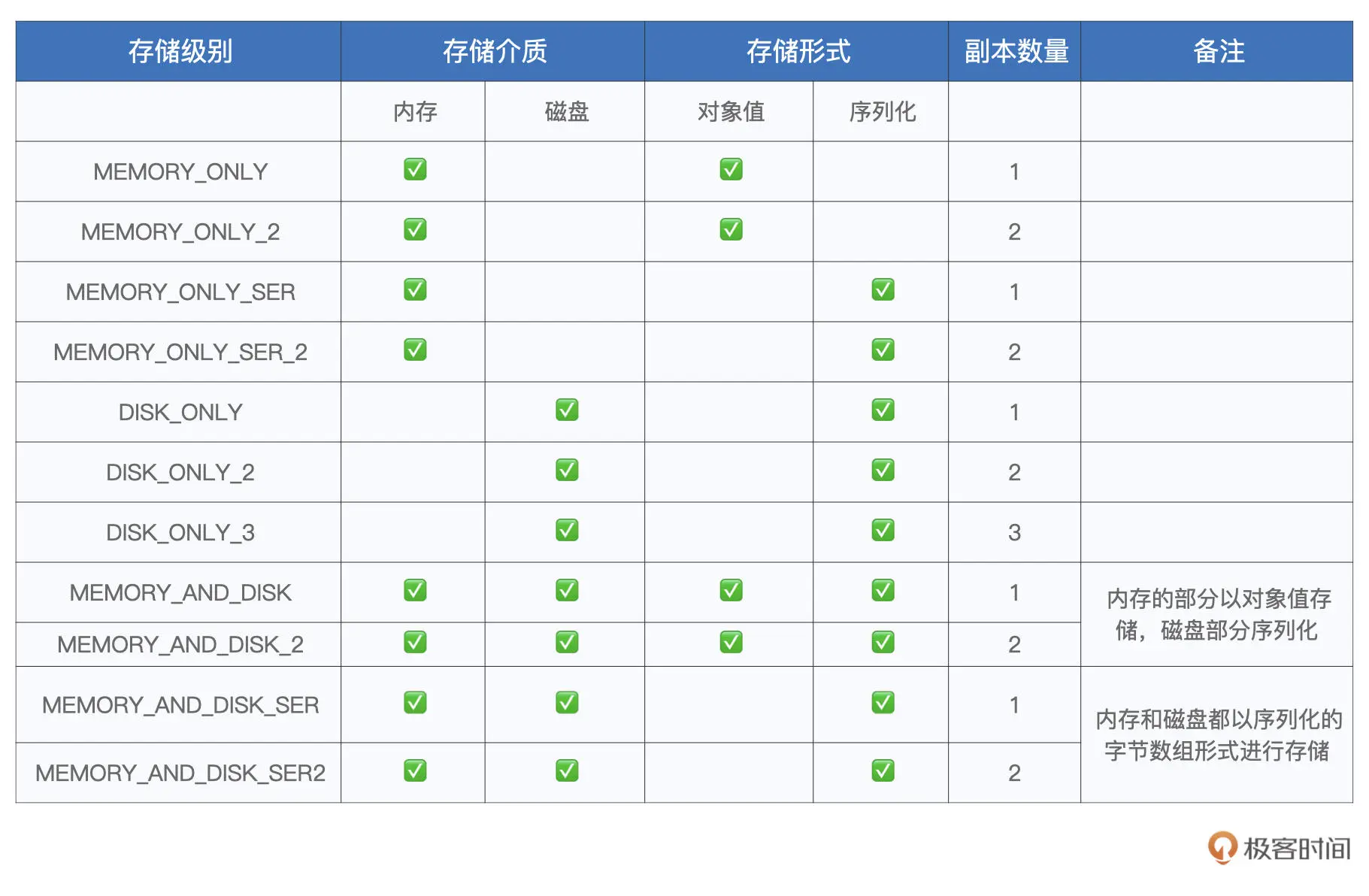
参考:https://time.geekbang.org/column/article/422400
五、Spark运行时-数据存储与管理
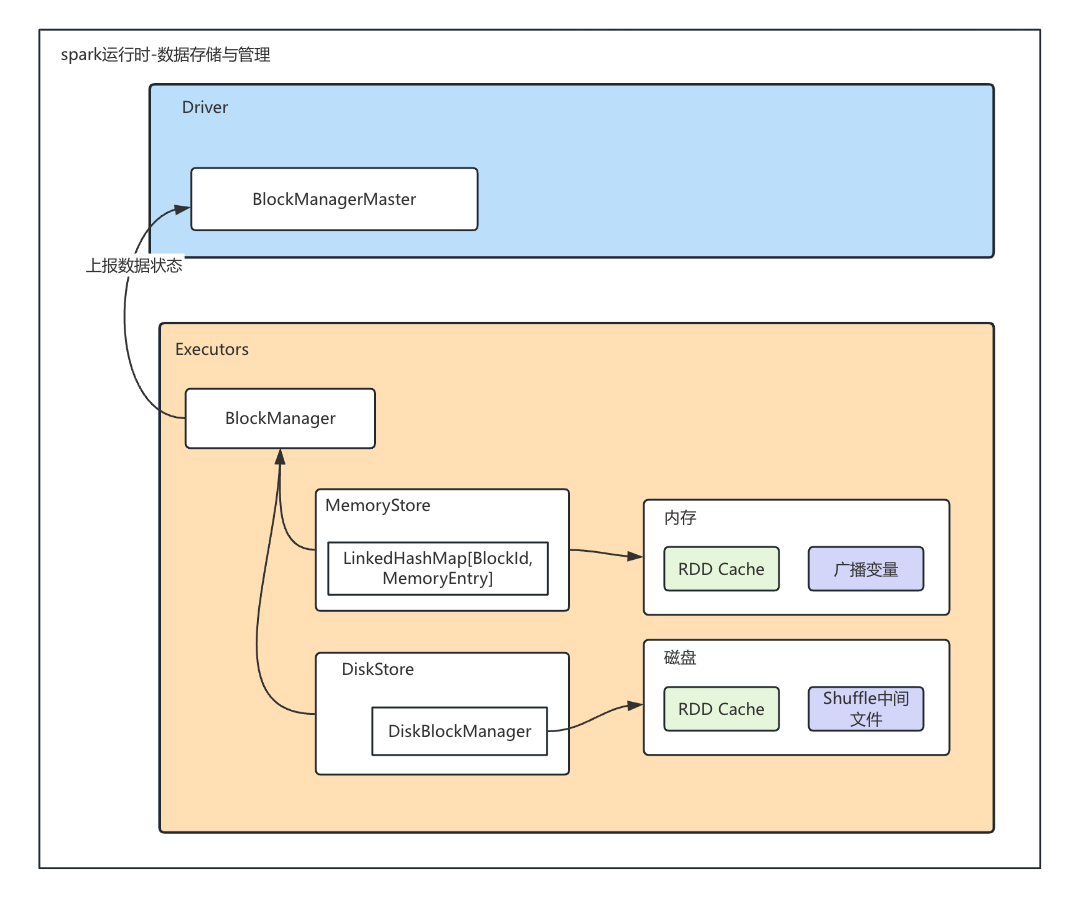
BlockManagerMaster 负责与BlockManager交互,获取每个节点的数据信息
BlockManager 通过 MemoryStore 来完成内存的数据存取。MemoryStore 通过一种特殊的数据结构:LinkedHashMap 来完成 BlockId 到 MemoryEntry 的映射。其中,BlockId 记录着数据块的元数据,而 MemoryEntry 则用于封装数据实体
BlockManager 通过 DiskStore 来实现磁盘数据的存取与访问。DiskStore 并不直接维护元数据列表,而是通过 DiskBlockManager 这个对象,来完成从数据库到磁盘文件的映射,进而完成数据访问