目录
[5.1 List类型](#5.1 List类型)
[5.2 List类型的常见命令](#5.2 List类型的常见命令)
[6.1 Set类型](#6.1 Set类型)
[6.2.1 对单个集合的操作命令](#6.2.1 对单个集合的操作命令)
[7.1 SortedSet类型](#7.1 SortedSet类型)
[7.2 sortedset类型的常见命令](#7.2 sortedset类型的常见命令)
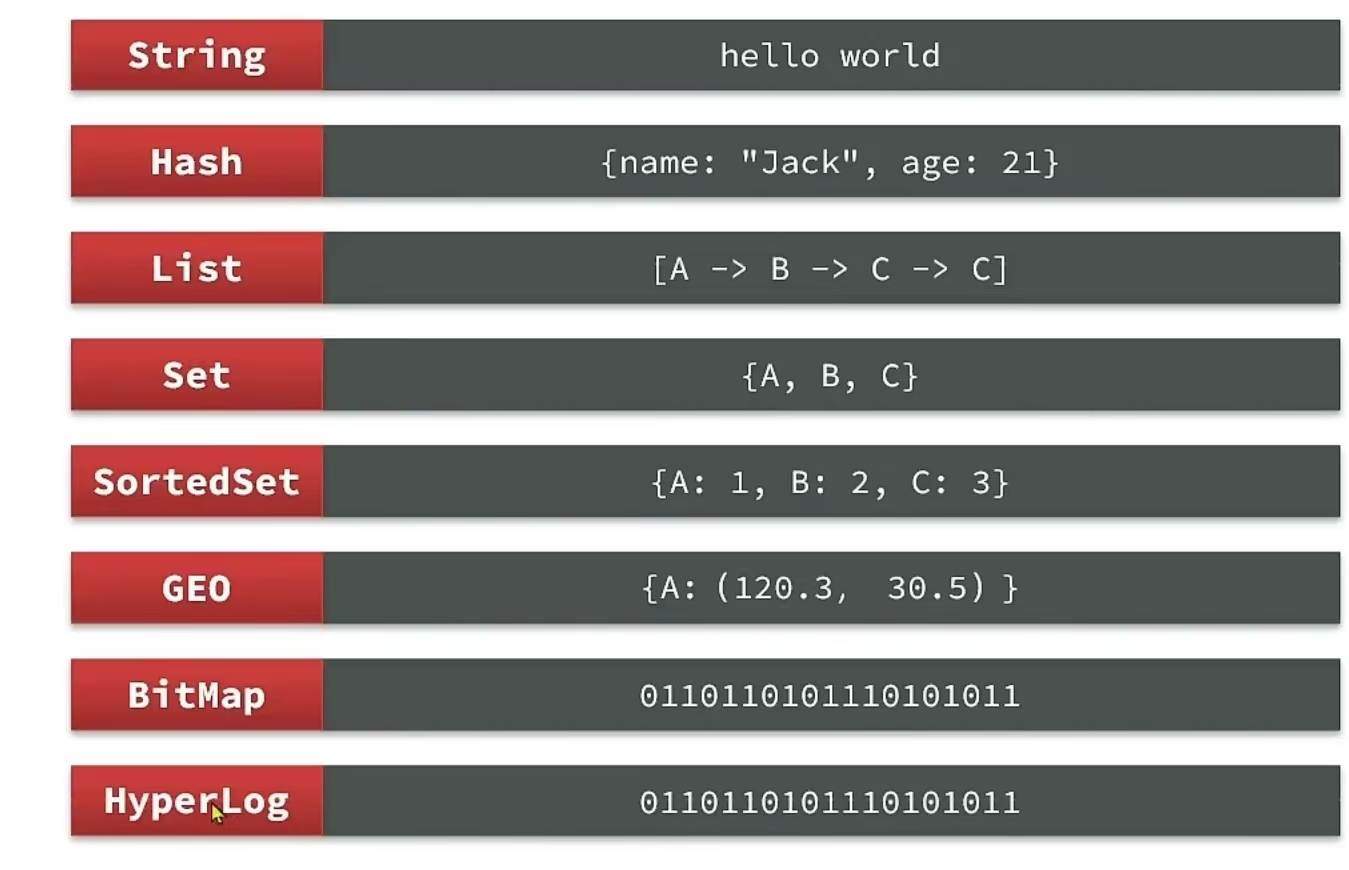
1、redis数据结构介绍
redis是一个key-value类型的数据库,key一般是String类型。
但value的类型多种多样:
前五种比较常见string、hash、list、set、sortedset
1.1命令学习方式
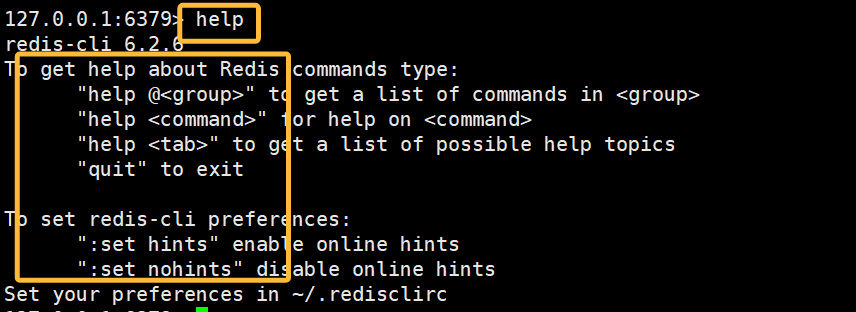
1.1.1命令行查询
在redis中我们可以通过help来获得命令提示
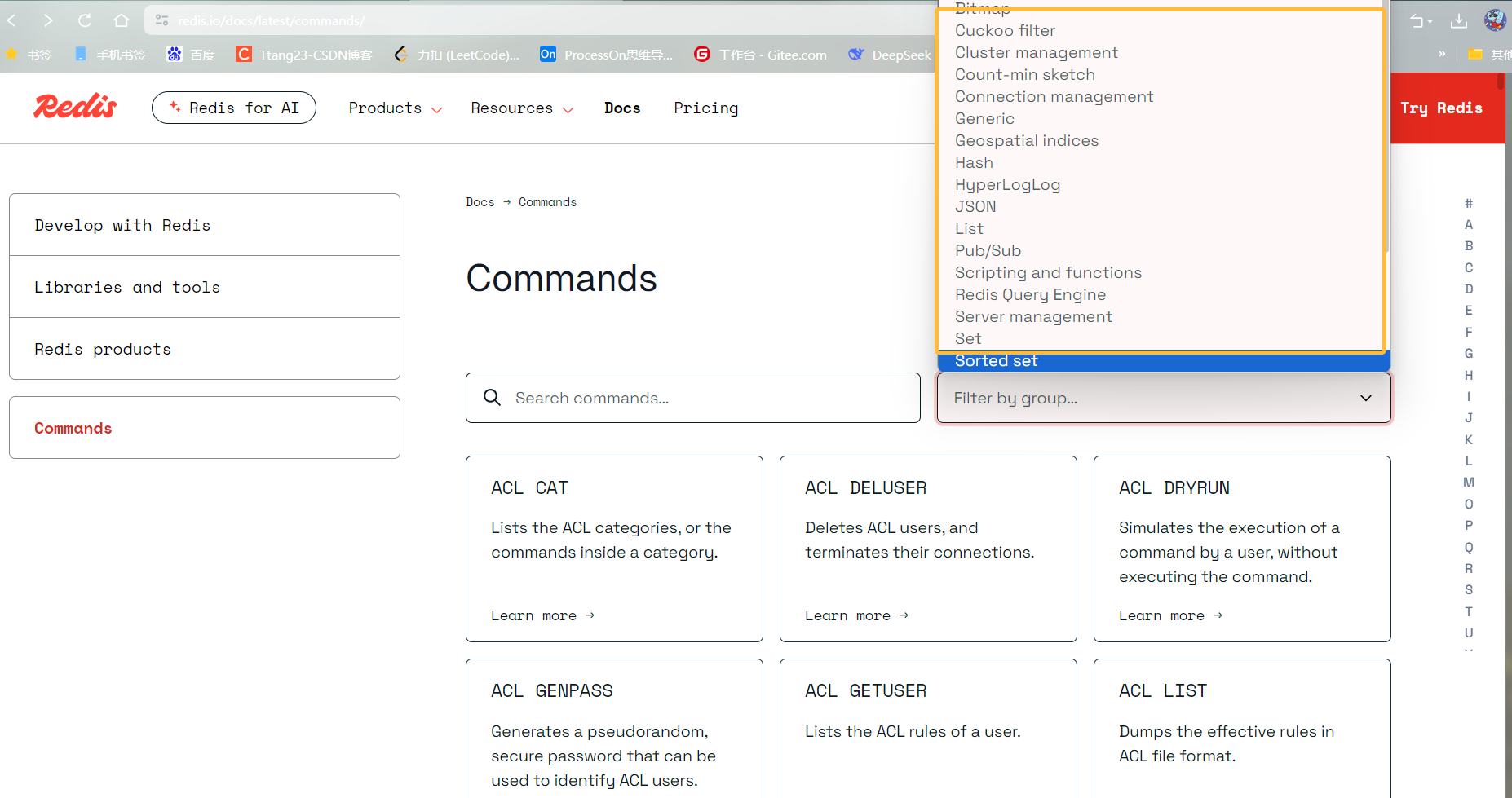
1.1.2官方文档查询方式
官网地址如上我们可以通过group进行命令筛选
2、redis的通用命令
通用命令是指部分数据类型都可以使用的命令
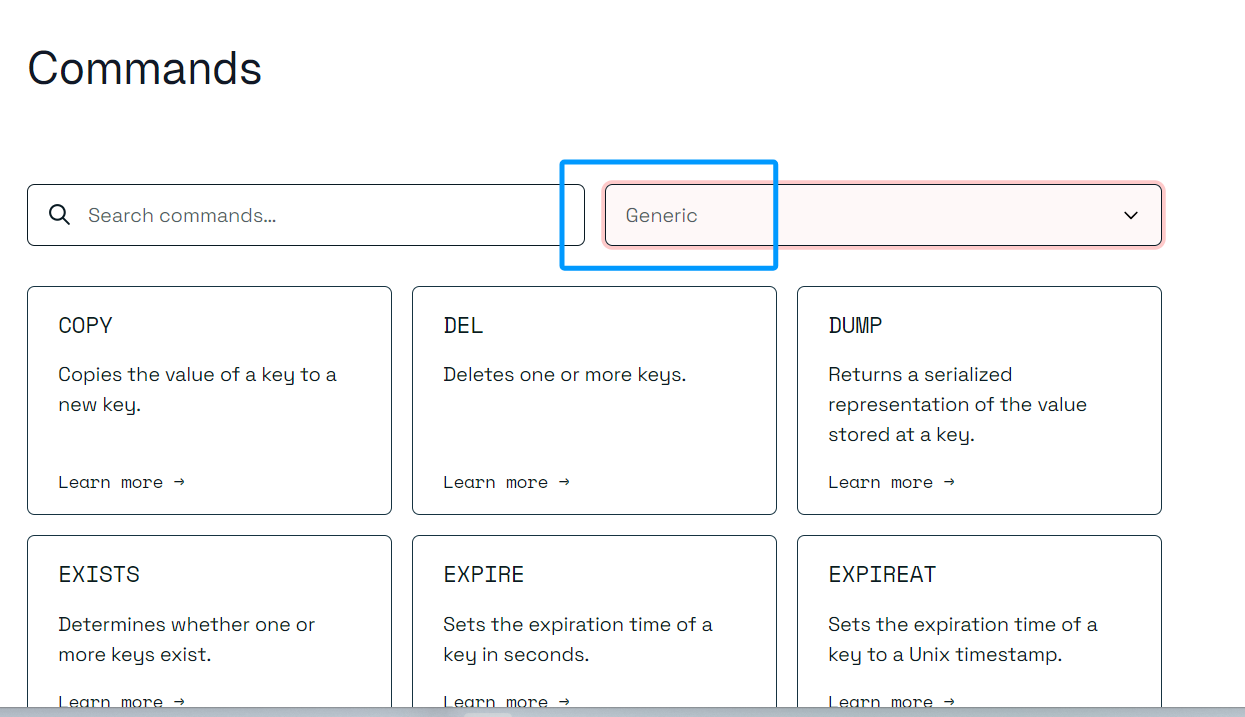
2.1查找常见的通用命令
fit by group选择 generic
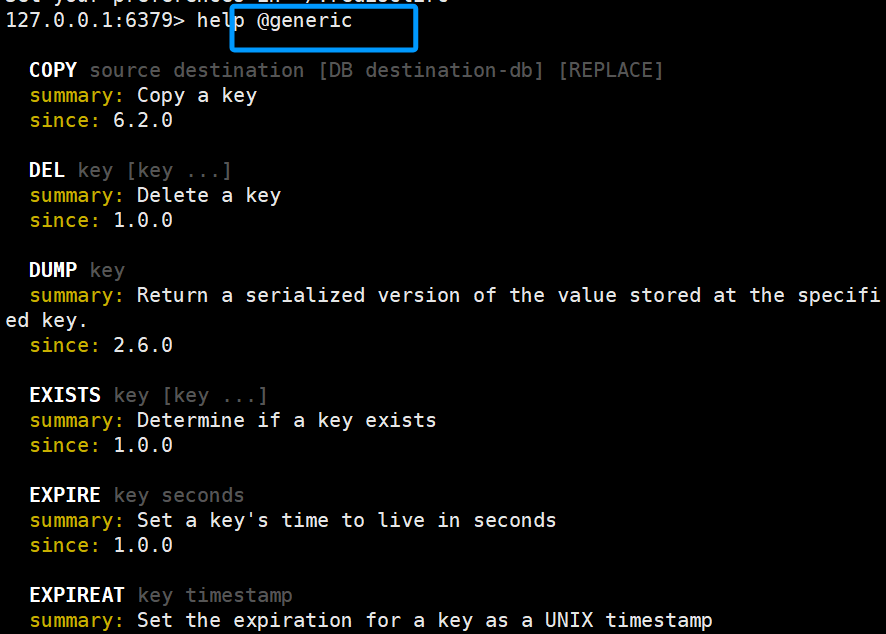
2.2常见的通用命令:
- keys:查看符合模板的所有key
通过help command 查看一个命令的具体用法
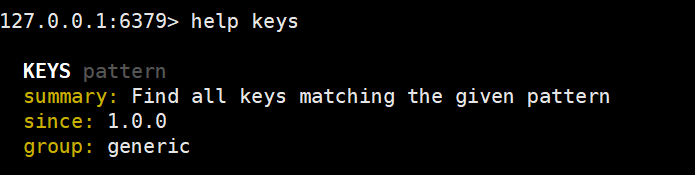
查询所有的key
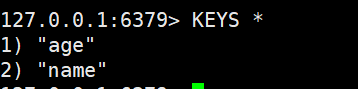
查询所有以a开头的key

keys命令支持通配符的使用,所以他在底层逻辑上是一个模糊查询, 而Redis又为单线程 数据库。所以不建议在生产环境设备上使用。
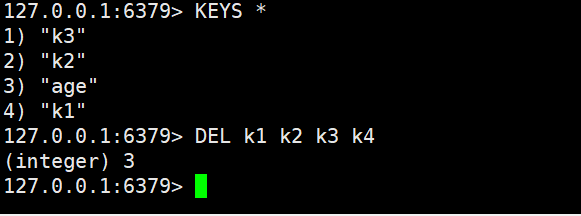
- del:删除某个key
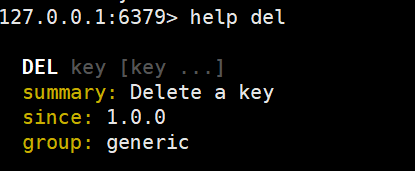
删除name键
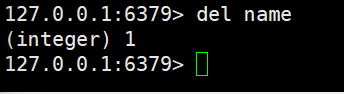
批量删除
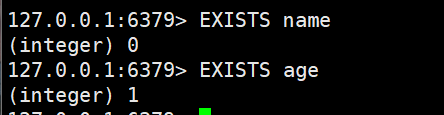
- EXISTS:判断某个key是否存在
判断name和age是否存在
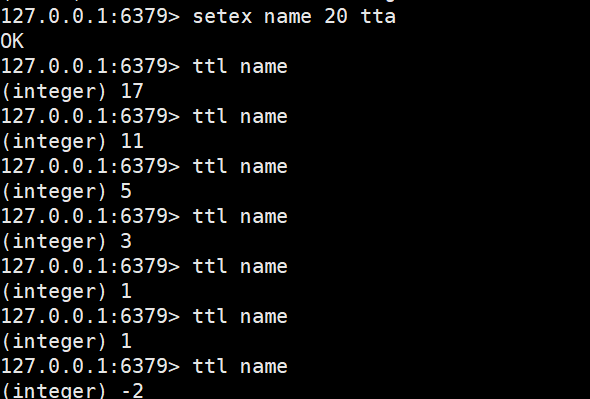
- EXPIRE:给某个key设置有效期,有效期到期时该key会被自动删除
- TTL:查看一个key的剩余有效期
我们可以通过TTL关键字去查看该键的剩余存活时间
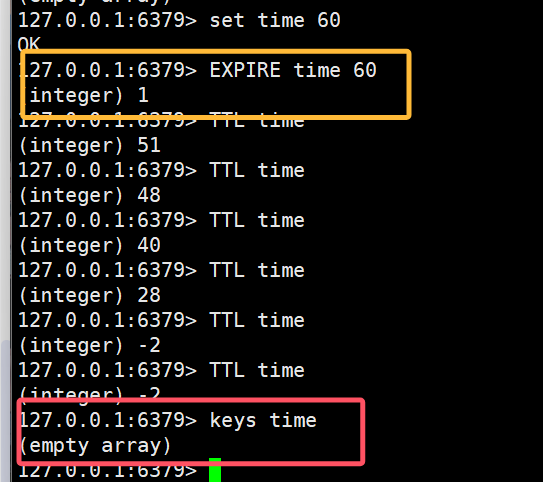
当有效期变为-2时,表示该键被自动删除(TTL为-1时表示该键永久有效)
3、String类型
String类型,即字符串类型,是Redis中最简单的存储类型
其value是字符串,但是字符串又可以分为三种:
-
string:普通字符串
-
int:整数类型,可以做自增自减操作
-
float:浮点类型,可以做自增自减操作
(不论那种类型,底层都是以字节数组形式存储,只不过编码方式不同。字节码或者是直接转为二进制。字符串类型的最大空间不能超过512M)
3.1String类型的常见命令
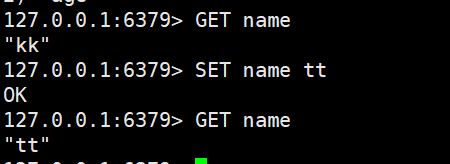
- SET:添加一个键值对,或者是修改一个已经存在的键值对
- GET:根据key获取Sting类型的value
- MSET:批量添加多个Sting类型的键值对
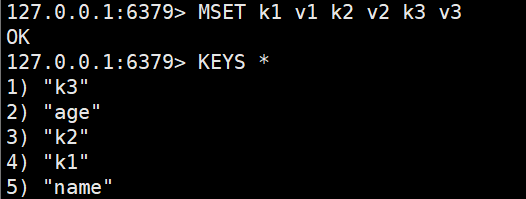
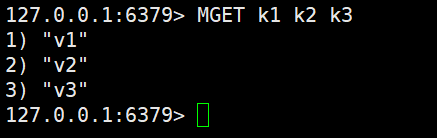
- MGET:根据多个key获取多个Sting类型的value
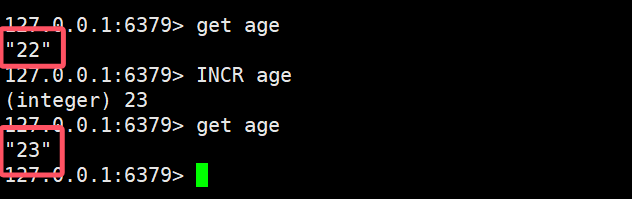
- INCR:让一个整型key自增1
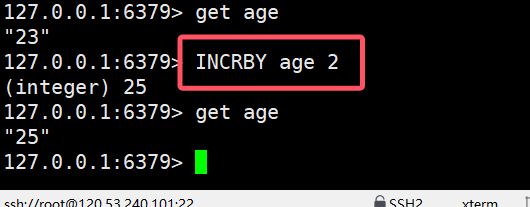
- INCRBY:让一个整型的key自增并确定步长(自减设置步长为负数即可=DECR)
- INCRBYFLOAT:让一个浮点型的数字进行自增长, 但必须指定步长
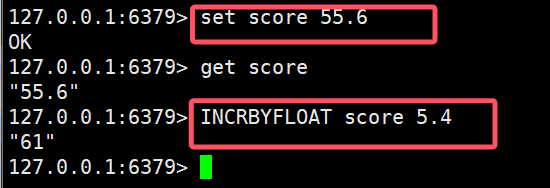
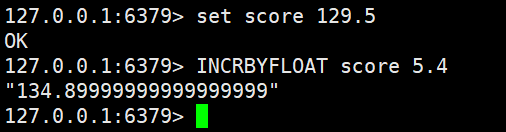
注意!! 这里的score最好介于-128~128之间,否则incrbyfloat会发生位数异常
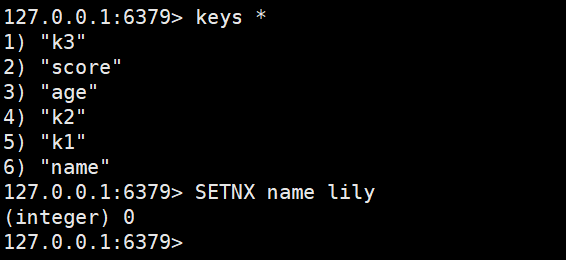
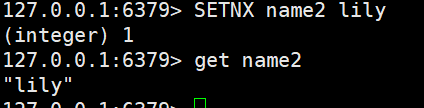
- SETNX:添加一个sting类型的键值对,前提是这个key,不存在,否则不执行
已有------不再新增(分布式锁的实现)
没有------新增(setnx==set .... nx)
- SETEX:添加一个sting类型的键值对,并且指定有效期
(setex==set key value ex seconds)
3.2Key的层级格式
redis中没有table的概念,我们应该如何区分不同类型的key呢?
例如:需要储存用户、商品信息到redis中,有一个用户id是1,有一个商品的id也恰好是1.
3.2.1Key的结构
Redis允许有多个单词形成层级结构,多个单词之间用**":"** 隔开,格式如下:
项目名:业务名:类型:id
tang:user:1
tang:product:1格式并不固定,可根据自己的需求删除或添加词条
如果Value是一个java对象,则可以将对象序列化为JSON字符串后储存
实践一下,我们把这几个键存一下
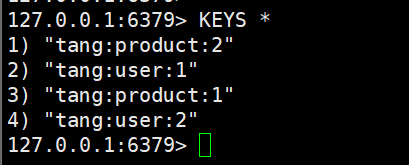
打开图形化界面,我们可以看到 :
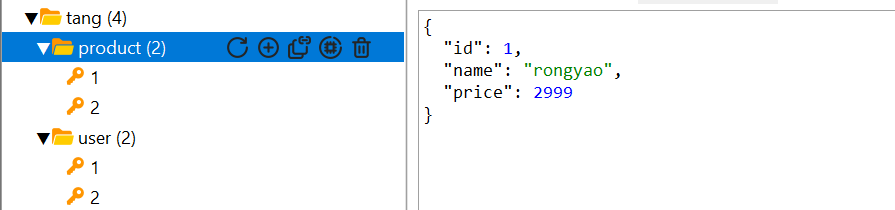
这样就实现了key的分级存储
4、Hash类型
4.1Hash类型
hash类型,也叫散列,其value就是一个无序字典,类似于java中的hashmap结构。
String结构是将对象序列化为JSON格式的字符串后储存, 需要修改某个对象的某个字段时很不方便,要不覆盖,要不删除重写。
在hash结构中value部分变为了 字段:值 的结构
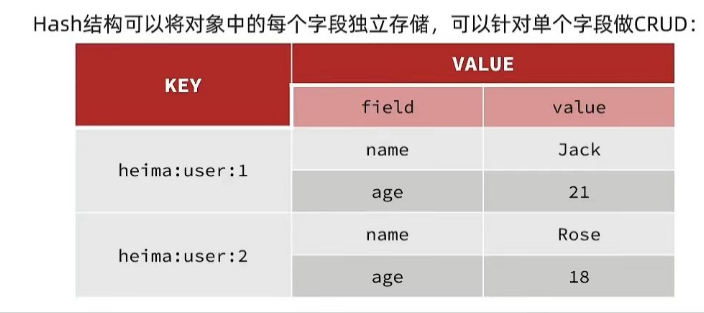
这样就可以独立表示某个字段,修改某一个字段时对其他字段没有任何影响,十分灵活
4.2Hash类型常见命令
- HSET key feild value:添加或修改hash类型key的field的值

打开图形化界面工具
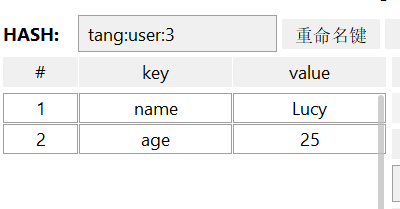
修改(没有添加或删除字段,返回值就是0)

- HGET key feild:获取hash类型key的field的值

- HMSET:批量添加多个hash类型key的field的值

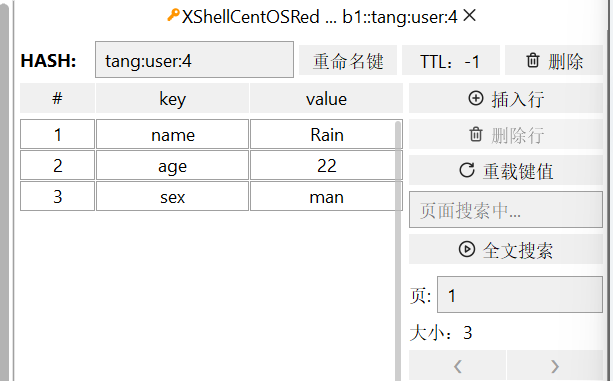
注意!! 官方文档上说明Redis4.0.0版本后hmset已经被弃用,可以用HSET直接代替HMSET

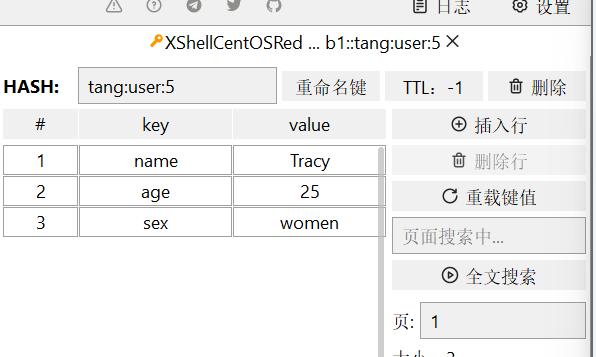
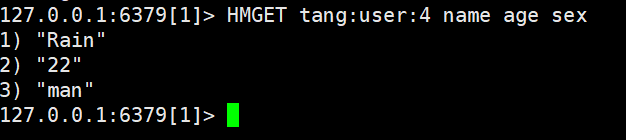
- HMGET:批量获取****多个hash类型key的field的值
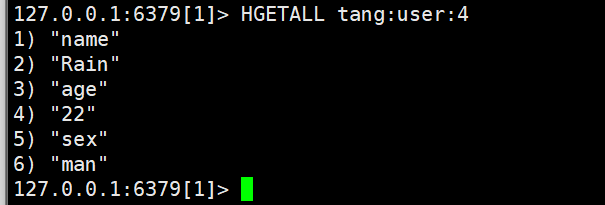
- HGETALL:获取一个hash类型的key的所有 field和value的值
可以理解为java中HashMap.entrySet
- HKEYS:获取一个hash类型的key的所有field
可以理解为java中HashMap.keySet

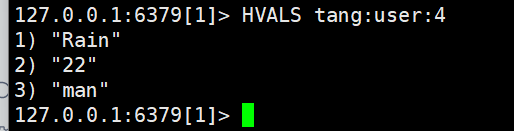
- HVALS:获取一个hash类型的key的所有values
可以理解为java中HashMap.keyValues
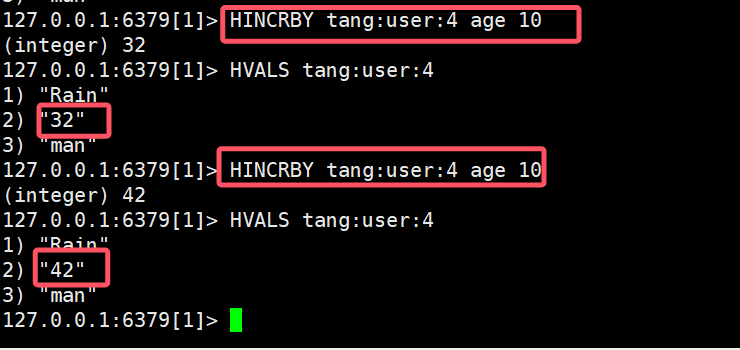
- HINCRBY:让一个hash类型的key的字段值自增长并确定步长
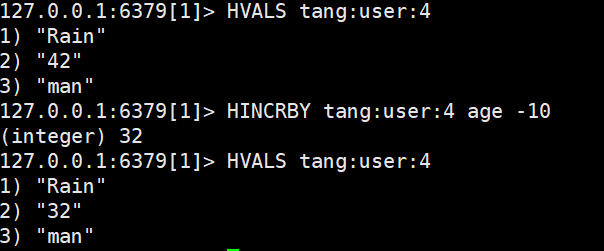
步长确定为负数就是负增长
- HSETNX:添加一个hash类型的key的field的值, 前提是这个field不存在 ,否则不添加
添加失败,因为4已经有这个field了

5、List类型
5.1 List类型
Redis中的List类型与Java中的LinkedList类似,可以看作是一个双向链表 结构。既可以支持正向检索也可以支持反向检索。
有序
元素可以重复
插入和删除速度快
查询速度一般(逐个遍历去查询)
List类型常用来存储一个有序数据,例如:朋友圈点赞列表,评论列表等。
5.2 List类型的常见命令
- LPUSH key element...:向列表左侧插入一个或多个元素
L,R可以理解为队首队尾的区别
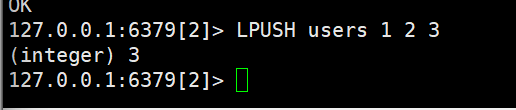
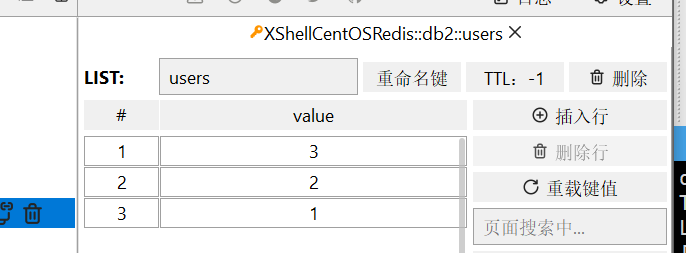
打开图形化界面,我们观察到,最先放入的在最下方(有点类似于栈的样子,但他是队列,上下都能取)
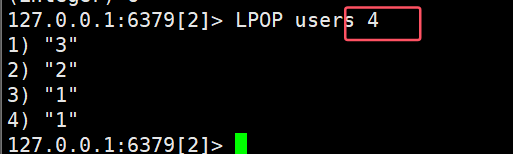
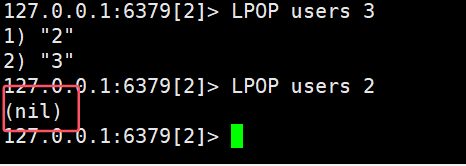
- LPOP key:移除并返回列表左侧被移除的某几个元素,没有则返回nil
(3 2 1 1 2 3)
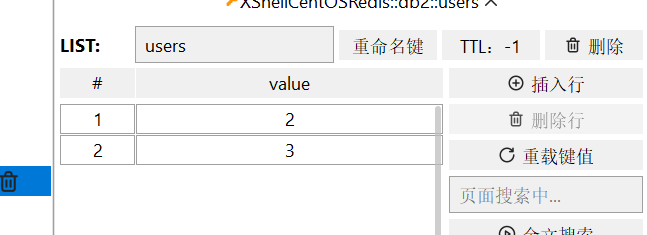
当list中没有元素时,返回nil
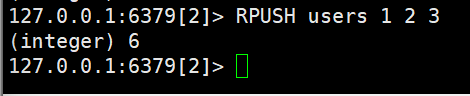
- RPUSH key element...:向列表右侧插入一个或多个元素
与LPOP相反的,RPOP从下往上插入
- RPOP key:移除并返回列表右侧被移除的某几个元素,没有则返回nil
取到4
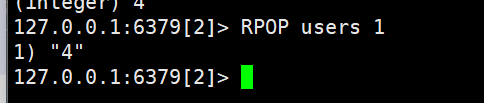
取到之后移除
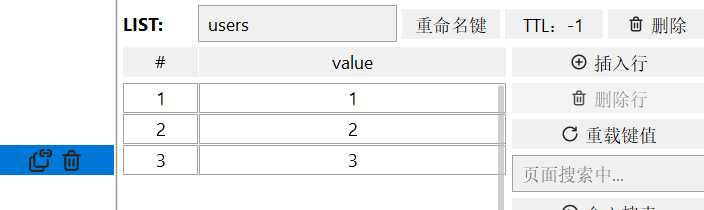
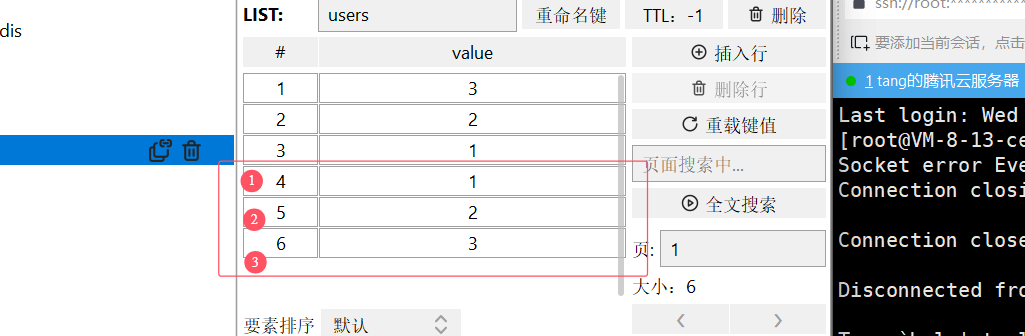
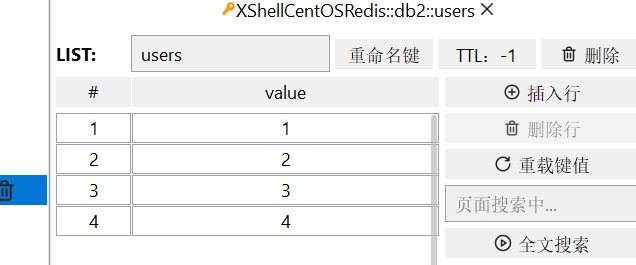
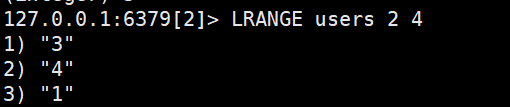
- LRANGE key star end:返回一段角标范围内的所有元素
目前库的样子
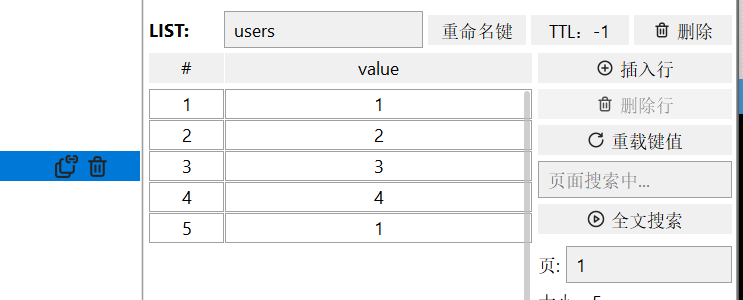
开始编号为0
- BLPOP和BRPOP:与LPOP和RPOP类似,只不过在没有元素时指定等待时间,而不是返回nil
B代表阻塞Block**,**我们来实操一下这个阻塞的过程:
在这里我们开两个窗口
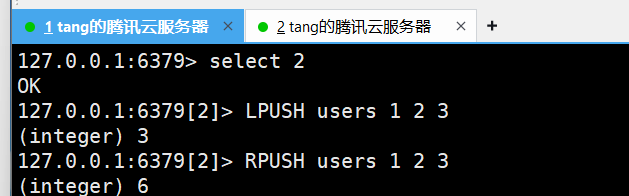
由于没有users2这个key,所以这个窗口会被阻塞在这个位置

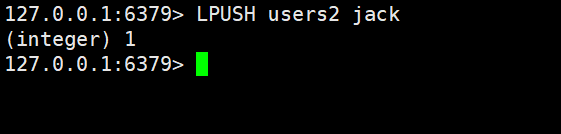
我们在另一个对话框,向users2中放入元素
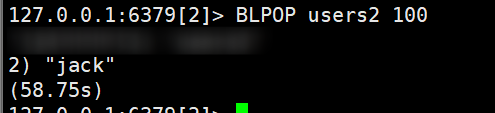
回到刚刚阻塞的窗口,我们发现他取到了,并且报告了用时
5.3List的用法
1)如何利用List结构去模拟一个栈?
栈:先进后出------入口出口在同一边
LPUSH+LPOP
RPUSH+RPOP
2)如何利用List结构去模拟一个队列?
队列:先进先出------入口出口不在同一边
LPUSH+RPOP
RPUSH+LPOP
3)如何利用List结构去模拟一个阻塞队列?
入口出口不在同一边+实现阻塞
LPUSH+BRPOP
RPUSH+BLPOP
6、Set类型
6.1 Set类型
Redis的Set结构和Java中的HashSet相似,可以看作是一个值为null的HashMap。因为也是一个Hash表,因此也具备以下特征:
无序
元素不可重复
查找快
支持交集,并集,差集
6.2Set的常见命令
6.2.1 对单个集合的操作命令
- SADD key member ..:向set中添加一个或多个元素。

- SREM key member ...:移除set中的指定元素
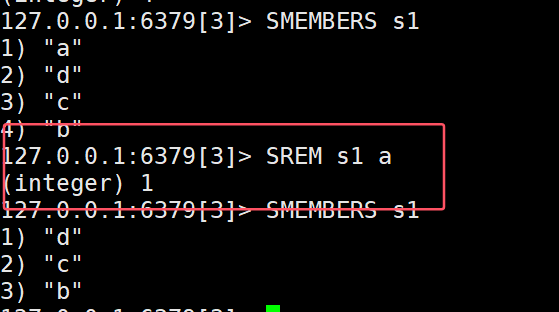
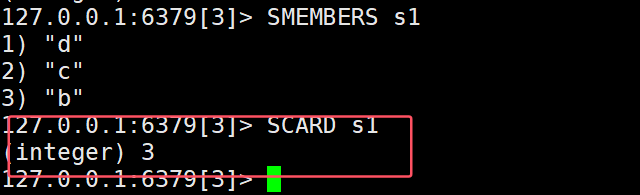
- SCARD key:返回set中的元素个数
CARD(cardinal)
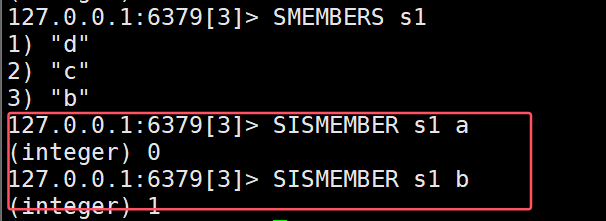
- SISMEMBER key member:判断一个元素是否在set中
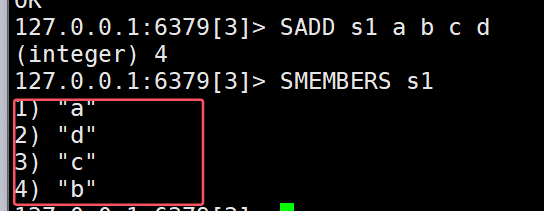
- SMEMBERS:获取set中所有元素
我们会发现所得顺序和我们存入的数据顺序并不一致,这是因为set类型无序的特点
6.2.2对多个集合的操作命令
-
SINTER key1 key2 ...:求key1 key2的交集(共同好友)
-
SDIFF key1 key2 ...:求key1 key2的差集
key1 SDIFF key2
- SUNION key1 key2 ...:求key1 key2的并集
注意重复元素只能出现一次

1)新建key:zs ls

2)计算张三的好友数量

3)计算张三和李四的共同好友

4)查询是张三的好友但不是李四的好友
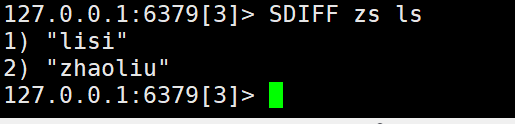
5)张三和李四一共有哪些好友
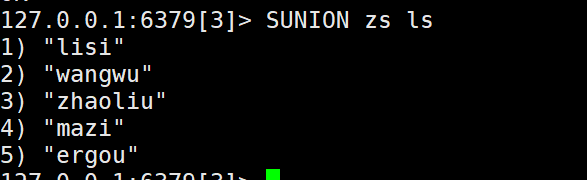
6)判断李四是否是张三的好友

7)判断张三是否是李四的好友

8)将李四从张三好友列表中移除
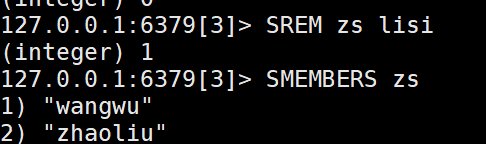
7、SortedSet类型
7.1 SortedSet类型
redis的sortedset类型是一个可排序的Set集合,与Java中的TreeSet有一些相似,但底层的数据结构差别很大。SortedSet中的每个元素都带有一个score属性,可以基于score属性对元素进行排序,底层的实现是一个 跳表加hash表。
可排序
元素不重复
查询速度快
经常被用作实现 排行榜 这样的功能
7.2 sortedset类型的常见命令
这些排序默认是升序,如果想要降序则在需要的命令的Z的后面添加REV即可。
-
ZADD key score member:添加一个或多个元素到sortedset,如果已经存在进行更新
-
ZREM key member:删除sortedset中的一个指定元素
-
ZSCORE key member:获取sortedset中的一个指定元素的score值
-
ZRANK key member:获取sortedset中指定元素的排名
-
ZCARD key:获取sortedset中的元素个数
-
ZCOUNT key min max:统计score值在给定范围内的所有元素个数
-
ZINCRBY key increment member:让sortedset中的指定元素自增,步长为指定的increment值
-
ZRANGE key min max:按照score排序后,获取指定排名范围内的元素( max包括在内 )
-
ZRANGEBYSCORE key min max:按照score排序后,获取指定score范围内的元素
-
ZDIFF\ZINTER\ZUNION:求差集、交集、并集

1)将学生信息添加数据库

2)删除Tom同学

3)获取Amy同学的分数

3)获取Rose同学的排名

排名编号从0开始
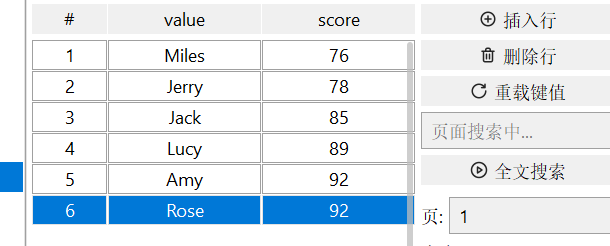
4)查询80分以下的同学数量

5)给Amy同学加2分

6)查出成绩前三名的同学
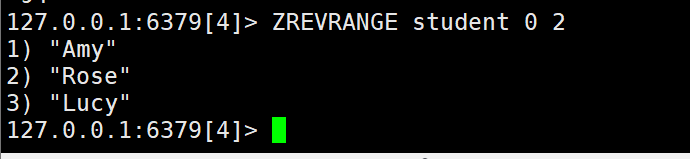
7)返回80分以下的所有同学信息
