本文精读NRC Canada与NYU联合发表的经典综述《A survey of named entity recognition and classification》,解析NERC技术演进脉络与核心方法论
一、为什么命名实体识别(NER)如此重要?
命名实体识别(Named Entity Recognition and Classification, NERC)是信息抽取的关键基石,旨在从文本中识别并分类刚性指示符(rigid designators),包括:
-
经典三类:人名(PER)、地名(LOC)、组织名(ORG)
-
扩展类型:时间表达式(TIME)、货币值(MONEY)、生物医学实体(蛋白质/基因)等
-
开放领域:200+细粒度类型(博物馆、河流、品牌等)
应用场景贯穿互联网核心业务:

二、技术演进:从规则模板到统计学习
1. 规则驱动时代(1991-1996)
-
代表工作:Lisa Rau (1991) 公司名识别系统
-
核心技术:手工编写正则规则+启发式模板
python
# 伪代码示例:早期LOC识别规则
if word.endswith("市") or word.endswith("省"):
tag_as(LOCATION)
if word in ["公司","集团"] and is_capitalized(prev_word):
tag_as(ORGANIZATION)2. 机器学习崛起(1996-2006)
| 方法 | 代表论文 | F1提升关键 |
|---|---|---|
| HMM隐马尔可夫模型 | Bikel et al. (1997) | 序列标注建模 |
| ME最大熵模型 | Borthwick (1998) | 特征概率联合估计 |
| SVM支持向量机 | Asahara & Matsumoto (2003) | 高维特征空间分类 |
| CRF条件随机场 | McCallum & Li (2003) | 当前主流,解决标记偏置 |
📌 关键转折点:MUC-6(1996)首次将NER列为独立评测任务,CONLL-2003推动统计方法普及
三、特征工程:NER系统的灵魂
论文揭示:特征设计比算法选择更重要(Tjong Kim Sang & De Meulder, 2003)
1. 词级别特征(Word-Level)
| 特征类型 | 示例 | 作用 |
|---|---|---|
| 大小写特征 | is_capitalized, ALL_UPPER |
识别专有名词 |
| 数字模式 | \d{4} → 年份 |
捕获时间/货币 |
| 词缀特征 | -ist(职业), -tech(公司) |
跨语言泛化能力 |
| 模式抽象 | "G.M." → "A.A" |
归一化变体表达 |
2. 词典特征(Gazetteers)
-
通用词典:排除常见词干扰(e.g., "May"可能是月份也可能为人名)
-
领域词典:
-
组织名线索:包含"Inc"/"Corp"等后缀
-
地理名线索:包含"河"/"山"等关键字
-
-
模糊匹配技术:
-
编辑距离(Edit Distance)
-
语音编码(Soundex):
"Smith"=S530,"Smyth"=S530
-
3. 文档级特征
-
共现特征:文档中多次出现的实体置信度更高
-
指代消解 :
"苹果公司" → "它" → "这家库比蒂诺的企业" -
元信息:Email发件人、新闻标题位置等
四、三大评估体系对比
通过案例解析不同评测标准(假设5个实体仅识别正确1个):
xml
<!-- 人工标注 -->
<PER>John Briggs Jr</PER> contacted <ORG>Wonderful Stockbrokers Inc</ORG> in <LOC>New York</LOC>
<!-- 系统输出 -->
<LOC>Unlike</LOC> Robert, <ORG>John Briggs Jr</ORG> contacted Wonderful <ORG>Stockbrokers</ORG> Inc...| 评估协议 | 计算方式 | 本例得分 | 特点 |
|---|---|---|---|
| MUC | 分TYPE/TEXT轴部分匹配 | 40% F1 | 允许边界错误 |
| CONLL | 严格完全匹配 | 20% F1 | 工业界常用 |
| ACE | 加权错误代价(类型/边界/漏检) | 31.3% | 最复杂,军事/政府领域主流 |
💡 实践建议:医疗领域适合宽松匹配 (如基因提及即可),金融领域需严格边界
五、语言与领域挑战
1. 多语言支持
-
主流语言:英语、日语(MUC-6)、中文(Chen & Lee, 1996)
-
低资源语言:巴斯克语、宿务语等通过跨语言迁移解决
2. 领域适应性
-
新闻领域:F1可达90%+(MUC-7数据)
-
迁移挑战 :新闻→邮件领域性能下降20-40%(Poibeau & Kosseim, 2001)
-
解决方案:领域自适应(Domain Adaptation)+ 半监督学习
六、突破性进展:半监督与无监督学习
1. 自举法(Bootstrapping)
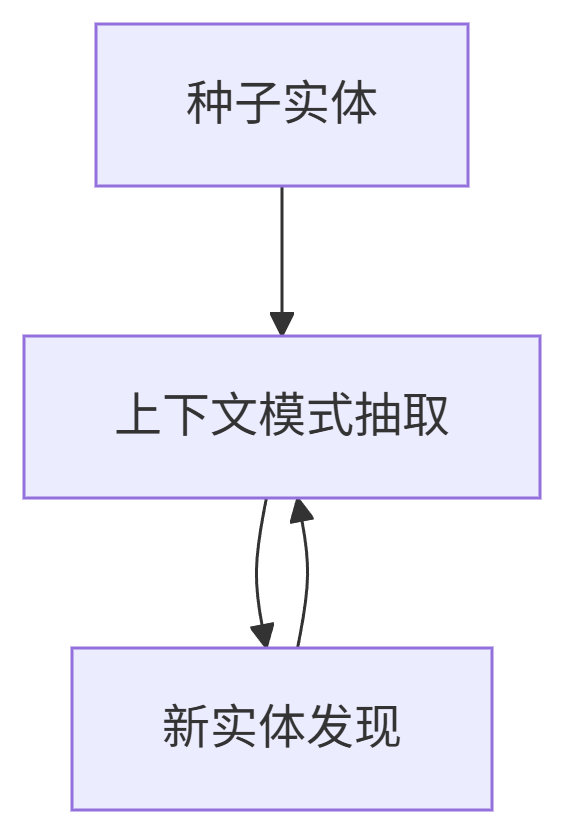
-
经典工作:Brin (1998) 从网页挖掘书名-作者对
-
创新点:Collins & Singer (1999) 联合学习多个类型减少误报
2. 无监督方法
-
分布相似性 :Pasca et al. (2006) 用Lin相似性泛化模式
"X was born in November" → "X was born in {March, October...}" -
跨文档关联:Shinyama & Sekine (2004) 利用新闻同步出现特征
七、对现代NLP的启示
-
特征工程永不落幕:BERT等预训练模型仍需拼接自定义特征(如正则匹配)
-
低资源学习路线:半监督方法在医疗/小语种场景仍不可替代
-
评估指标选择:严格场景用CONLL,宽松场景用ACE加权
🚀 2025年技术衔接:
论文中的CRF已被BERT-CRF架构取代
无监督思想演进为自监督预训练
细粒度实体识别(如200类)成为研究热点
参考文献
Nadeau D., Sekine S. (2006). A Survey of Named Entity Recognition and Classification. Linguisticae Investigationes
实用工具推荐
python
# 中文NLP工具包
pip install hanlp # 支持实体识别与细粒度分类
# 论文复现代码
git clone https://github.com/niderhoff/nlp-tutorials欢迎关注我的专栏获取更多技术解析! 👉 #NER从入门到精通