转自深入GPU硬件架构及运行机制 - 0向往0 - 博客园,基本上是其理解。
一、GPU概述
1.1 GPU是什么?
GPU 全称是Graphics Processing Unit,图形处理单元。它的功能最初与名字一致,是专门用于绘制图像和处理图元数据的特定芯片,后来渐渐加入了其它很多功能。
1.2 GPU的功能
现代GPU除了绘制图形外,还担当了很多额外的功能,综合起来如下几方面:
-
图形绘制。
这是GPU最传统的拿手好戏,也是最基础、最核心的功能。为大多数PC桌面、移动设备、图形工作站提供图形处理和绘制功能。
-
物理模拟。
GPU硬件集成的物理引擎(PhysX、Havok),为游戏、电影、教育、科学模拟等领域提供了成百上千倍性能的物理模拟,使得以前需要长时间计算的物理模拟得以实时呈现。
-
海量计算。
计算着色器及流输出的出现,为各种可以并行计算的海量需求得以实现,CUDA就是最好的例证。
-
AI运算。
近年来,人工智能的崛起推动了GPU集成了AI Core运算单元,反哺AI运算能力的提升,给各行各业带来了计算能力的提升。
-
其它计算。
音视频编解码、加解密、科学计算、离线渲染等等都离不开现代GPU的并行计算能力和海量吞吐能力。
1.3 GPU与CPU的区别
一、核心设计目标
-
CPU(中央处理器) :
主打 通用性和串行处理能力,旨在高效处理复杂、多样的任务(如操作系统指令、逻辑判断、单线程程序等),强调 "快而全",能应对各种类型的计算需求。
-
GPU(图形处理器) :
主打 并行处理能力,最初为图形渲染设计(如 3D 建模、光影计算),擅长同时处理大量重复、简单的计算任务(如图元渲染、像素计算),强调 "多而快",适合高吞吐量的并行运算。
二、架构差异
| 维度 | CPU | GPU |
|---|---|---|
| 核心数量 | 核心数较少(常见 4-32 核,服务器级最多数百核) | 核心数极多(主流 GPU 可达数千甚至数万核,如 NVIDIA H100 有 18432 个 CUDA 核心) |
| 核心复杂度 | 每个核心结构复杂,包含完整的控制单元、缓存(L1/L2/L3)、分支预测器等,支持复杂逻辑运算 | 每个核心(如 CUDA 核心、流处理器)结构简单,控制单元少,缓存较小,专注于基础算术运算(如浮点计算) |
| 缓存设计 | 缓存容量大(从几 MB 到数十 MB,服务器级可达数百 MB),注重数据快速访问以减少延迟 | 缓存容量小(通常几 MB 到几十 MB),依赖外部显存(如 GDDR6、HBM3),更关注内存带宽 |
| 线程管理 | 支持少量线程(如每个核心同时处理 1-2 线程),依赖线程调度切换应对延迟 | 支持海量线程(如单 GPU 可同时运行数万线程),通过线程并行掩盖内存访问延迟 |
三、处理方式差异
-
CPU:串行优先,延迟敏感
CPU 的运算单元(ALU)数量少,但每个单元可执行复杂逻辑(如分支判断、循环跳转),且通过多级缓存和分支预测优化单线程效率。例如:执行一段包含大量
if-else的代码时,CPU 能快速处理逻辑判断,而 GPU 处理此类任务效率极低。 -
GPU:并行优先,吞吐量敏感
GPU 的运算单元(流处理器)数量极多,但单个单元功能简单,适合执行无依赖的重复计算。例如:渲染一张 1920×1080 的图像时,每个像素的颜色计算相互独立,GPU 可同时让数千个核心分别计算不同像素,效率远高于 CPU。
四、典型应用场景
| 场景 | 更依赖 CPU | 更依赖 GPU |
|---|---|---|
| 日常操作 | 操作系统运行、文件管理、网页浏览(逻辑控制为主) | - |
| 图形渲染 | - | 3D 游戏(顶点计算、像素着色)、影视特效(光线追踪)、UI 渲染 |
| 科学计算 | 复杂数学建模(如微分方程求解)、逻辑推理 | 大规模数据并行计算(如机器学习训练、流体动力学模拟、密码破解) |
| 多任务处理 | 同时运行多个程序(如边听歌边写文档),依赖任务调度 | - |
| AI 与深度学习 | 模型推理(轻量化场景)、数据预处理 | 模型训练(如神经网络反向传播)、大规模推理(如 GPT 类大模型) |
五、通俗类比
- CPU 像 "全能办公室主任":负责安排任务、处理突发情况、协调各部门工作,虽然手下人不多,但能应对各种复杂问题。
- GPU 像 "大型工厂流水线":手下有数千名工人,每个人只负责重复一个简单步骤(如拧螺丝),虽然单个工人能力有限,但整体能快速完成海量重复工作。
总结
CPU 是 "通用计算核心",擅长复杂逻辑和串行任务;GPU 是 "并行计算引擎",擅长海量重复计算。两者并非替代关系,而是协同工作(如游戏中,CPU 处理游戏逻辑,GPU 负责画面渲染),共同支撑计算机的高效运行。
二、GPU运行机制
2.1 DrawCall过程
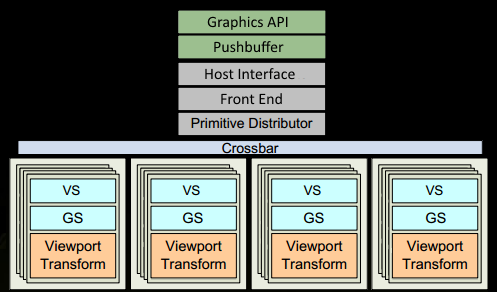
1、程序通过图形API(DX、GL、WEBGL)发出drawcall指令,指令会被推送到驱动程序,驱动会检查指令的合法性,然后会把指令放到GPU可以读取的Pushbuffer中。
2、经过一段时间或者显式调用flush指令后,驱动程序把Pushbuffer的内容发送给GPU,GPU通过主机接口(Host Interface)接受这些命令,并通过前端(Front End)处理这些命令。
3、在图元分配器(Primitive Distributor)中开始工作分配,处理indexbuffer中的顶点产生三角形分成批次(batches),然后发送给多个GPCs。这一步的理解就是提交上来n个三角形,分配给这几个PGC同时处理。
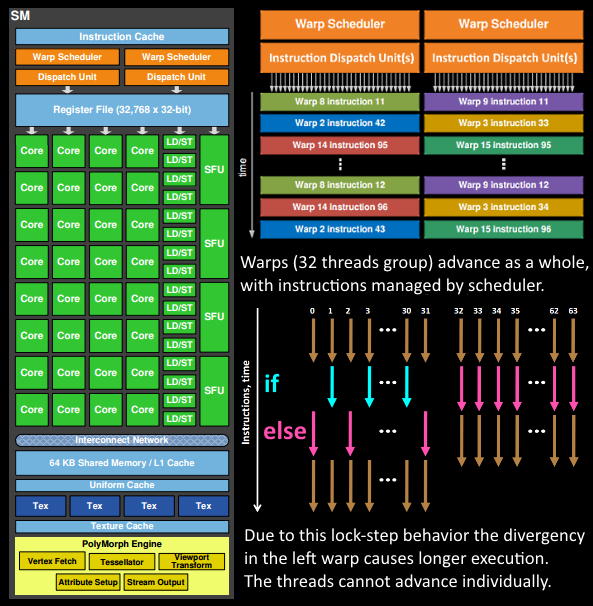
4、在GPC中,每个SM中的Poly Morph Engine负责通过三角形索引(triangle indices)取出三角形的数据(vertex data),即图中的Vertex Fetch模块。
5、在获取数据之后,在SM中以32个线程为一组的线程束(Warp)来调度,来开始处理顶点数据。Warp是典型的单指令多线程(SIMT,SIMD单指令多数据的升级)的实现,也就是32个线程同时执行的指令是一模一样的,只是线程数据不一样,这样的好处就是一个warp只需要一个套逻辑对指令进行解码和执行就可以了,芯片可以做的更小更快,之所以可以这么做是由于GPU需要处理的任务是天然并行的。
6、SM的warp调度器会按照顺序分发指令给整个warp,单个warp中的线程会锁步(lock-step)执行各自的指令,如果线程碰到不激活执行的情况也会被遮掩(be masked out)。被遮掩的原因有很多,例如当前的指令是if(true)的分支,但是当前线程的数据的条件是false,或者循环的次数不一样(比如for循环次数n不是常量,或被break提前终止了但是别的还在走),因此在shader中的分支会显著增加时间消耗,在一个warp中的分支除非32个线程都走到if或者else里面,否则相当于所有的分支都走了一遍,线程不能独立执行指令而是以warp为单位,而这些warp之间才是独立的。
7、warp中的指令可以被一次完成,也可能经过多次调度,例如通常SM中的LD/ST(加载存取)单元数量明显少于基础数学操作单元。
8、由于某些指令比其他指令需要更长的时间才能完成,特别是内存加载,warp调度器可能会简单地切换到另一个没有内存等待的warp,这是GPU如何克服内存读取延迟的关键,只是简单地切换活动线程组。为了使这种切换非常快,调度器管理的所有warp在寄存器文件中都有自己的寄存器。这里就会有个矛盾产生,shader需要越多的寄存器,就会给warp留下越少的空间,就会产生越少的warp,这时候在碰到内存延迟的时候就会只是等待,而没有可以运行的warp可以切换。
9、一旦warp完成了vertex-shader的所有指令,运算结果会被Viewport Transform模块处理,三角形会被裁剪然后准备栅格化,GPU会使用L1和L2缓存来进行vertex-shader和pixel-shader的数据通信。
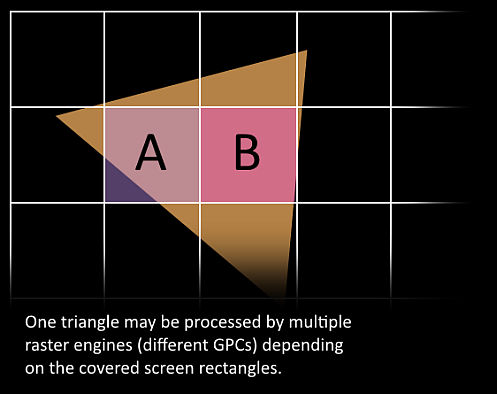
10、接下来这些三角形将被分割,再分配给多个GPC,三角形的范围决定着它将被分配到哪个光栅引擎(raster engines),每个raster engines覆盖了多个屏幕上的tile,这等于把三角形的渲染分配到多个tile上面。也就是像素阶段就把按三角形划分变成了按显示的像素划分了。
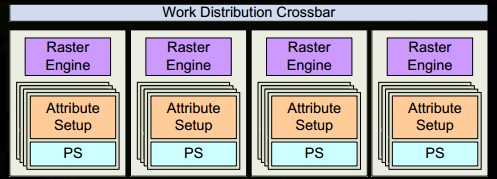
11、SM上的Attribute Setup保证了从vertex-shader来的数据经过插值后是pixel-shade是可读的。
12、GPC上的光栅引擎(raster engines)在它接收到的三角形上工作,来负责这些这些三角形的像素信息的生成(同时会处理裁剪Clipping、背面剔除和Early-Z剔除)。
13、32个像素线程将被分成一组,或者说8个2x2的像素块,这是在像素着色器上面的最小工作单元,在这个像素线程内,如果没有被三角形覆盖就会被遮掩,SM中的warp调度器会管理像素着色器的任务。
14、接下来的阶段就和vertex-shader中的逻辑步骤完全一样,但是变成了在像素着色器线程中执行。 由于不耗费任何性能可以获取一个像素内的值,导致锁步执行非常便利,所有的线程可以保证所有的指令可以在同一点。

15、最后一步,现在像素着色器已经完成了颜色的计算还有深度值的计算,在这个点上,我们必须考虑三角形的原始api顺序,然后才将数据移交给ROP(render output unit,渲染输入单元),一个ROP内部有很多ROP单元,在ROP单元中处理深度测试,和framebuffer的混合,深度和颜色的设置必须是原子操作,否则两个不同的三角形在同一个像素点就会有冲突和错误
流程总结:
2.2 GPU对逻辑的处理
GPU 在处理if else for循环等分支语句时性能会显著下降,核心原因在于其架构设计(SIMT)与分支语句的特性存在天然冲突。具体可从以下几个层面详细解释:
2.2.1、GPU 的核心架构:SIMT(单指令多线程)
GPU 的核心设计目标是高效并行处理大量同质化任务(如矩阵运算、像素渲染等),其核心执行单元采用 "单指令多线程"(SIMT)模型:
- 多个线程被打包成 "线程束(Warp)"(常见大小为 32 线程,如 NVIDIA GPU),同一线程束内的所有线程共享同一条指令流,由同一个指令控制器调度。
- 这意味着:线程束内的所有线程必须同步执行相同的指令(例如同时执行
add、mul等操作),无法像 CPU 那样让单个线程独立执行不同指令。
2.2.2、分支语句导致 "线程束分歧"
if else等分支语句会导致线程束内的线程因条件判断结果不同,执行不同的代码路径(即 "分支分歧"),而 SIMT 架构无法并行处理这种分歧,只能序列化执行分支,从而严重浪费算力。
具体过程如下:
- 当线程束内的线程遇到
if else时,会根据条件分为 "满足条件" 和 "不满足条件" 两组。 - 由于线程束必须同步执行同一条指令,GPU 会先执行其中一个分支(例如
if内的代码),此时不执行该分支的线程会被 "挂起"(闲置); - 执行完第一个分支后,再执行另一个分支(例如
else内的代码),此时原本执行第一个分支的线程被挂起; - 两个分支都执行完后,所有线程再同步继续执行后续代码。
对于for循环,确定循环次数比动态确定性能更好一些。
比如 for(i=1;i<10000;i++) 优于 for(i=1;i<a;i++) a=10,10000
因为前者可以让GPU明确进行并行调度,后者存在不确定性,无法明确调度,只能串行处理,导致组内其他核心被闲置等待,而GPU处理串行时的能力要弱于CPU。
2.2.3、性能损耗的直观示例
假设一个 32 线程的线程束中,16 个线程满足if条件,16 个不满足:
- 无分支时:32 线程可并行执行,耗时为
T; - 有分支时:需先执行
if分支(16 线程工作,16 线程闲置,耗时T),再执行else分支(16 线程工作,16 线程闲置,耗时T),总耗时变为2T,性能直接减半。
若分支条件更极端(如 1 个线程走if,31 个走else),则性能损耗更严重(接近 32 倍理论损耗)。
2.2.4、与 CPU 的对比:分支处理能力的差异
CPU 处理分支时性能影响较小,原因是:
- CPU 核心为 "单指令单线程"(SISD)或 "多指令多线程"(MIMD),单个核心可独立处理分支,无需等待其他线程;
- CPU 有成熟的 "分支预测" 技术(如动态预测分支走向),可提前预取指令,减少分支带来的停顿。
而 GPU 由于线程束内线程强耦合(必须同步执行),且缺乏高效的分支预测机制(因并行线程数量太大,预测成本极高),因此对分支的容忍度远低于 CPU。
2.2.5、总结
GPU 处理if else性能下降的本质是:SIMT 架构要求线程束内线程同步执行相同指令,而分支语句导致线程束分歧,迫使分支代码序列化执行,导致其组内大量线程被闲置,算力利用率大幅降低。
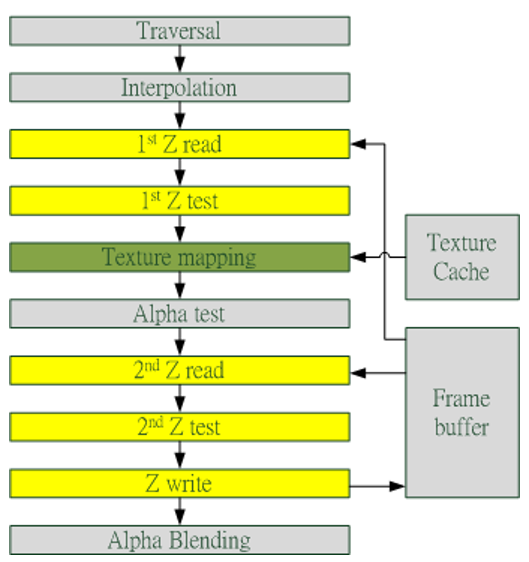
2.3 Early-Z
早期GPU的渲染管线的深度测试是在像素着色器之后才执行(下图),这样会造成很多本不可见的像素执行了耗性能的像素着色器计算。
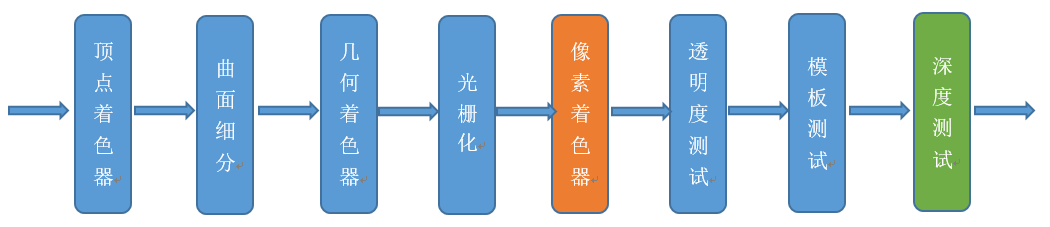
后来,为了减少像素着色器的额外消耗,将深度测试提至像素着色器之前(下图),这就是Early-Z技术的由来。

Early-Z技术可以将很多无效的像素提前剔除,避免它们进入耗时严重的像素着色器。Early-Z剔除的最小单位不是1像素,而是像素块(pixel quad,2x2个像素,详见4.3.6 (#4.3.6 像素块(pixel quad)))
但是,以下情况会导致Early-Z失效:
- 开启Alpha Test:由于Alpha Test需要在像素着色器后面的Alpha Test阶段比较,所以无法在像素着色器之前就决定该像素是否被剔除。
- 开启Tex Kill:即在shader代码中有像素摒弃指令(DX的discard,OpenGL的clip)。
- 关闭深度测试。Early-Z是建立在深度测试看开启的条件下,如果关闭了深度测试,也就无法启用Early-Z技术。
- 开启Multi-Sampling:多采样会影响周边像素,而Early-Z阶段无法得知周边像素是否被裁剪,故无法提前剔除。
- 以及其它任何导致需要混合后面颜色的操作。
此外,Early-Z技术会导致一个问题:深度数据冲突(depth data hazard)。
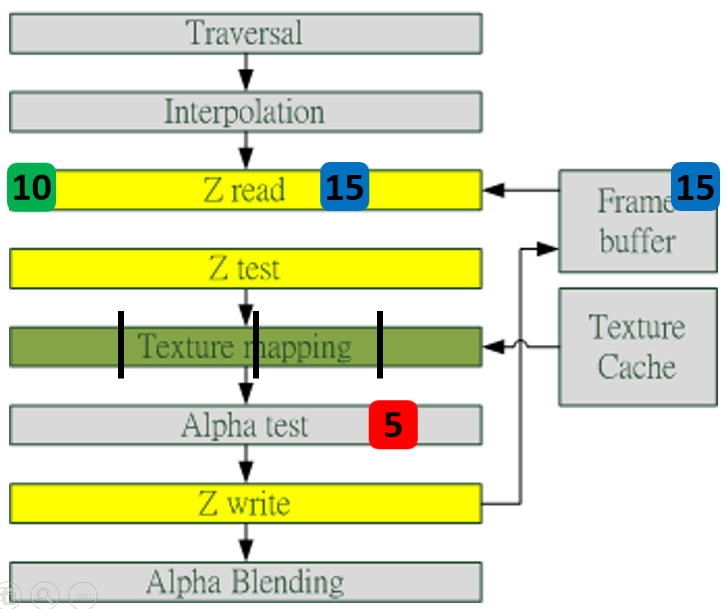
例子要结合上图,假设数值深度值5已经经过Early-Z即将写入Frame Buffer,而深度值10刚好处于Early-Z阶段,读取并对比当前缓存的深度值15,结果就是10通过了Early-Z测试,会覆盖掉比自己小的深度值5,最终frame buffer的深度值是错误的结果。
避免深度数据冲突的方法之一是在写入深度值之前,再次与frame buffer的值进行对比:
2.4 像素块(Pixel Quad)
在像素着色器中,会将相邻的四个像素作为不可分隔的一组,送入同一个SM内4个不同的Core。
为什么像素着色器处理的最小单元是2x2的像素块?
笔者推测有以下原因:
1、简化和加速像素分派的工作。
2、精简SM的架构,减少硬件单元数量和尺寸。
3、降低功耗,提高效能比。
4、无效像素虽然不会被存储结果,但可辅助有效像素求导函数。详见4.6 利用扩展例证。
这种设计虽然有其优势,但同时,也会激化过绘制(Over Draw)的情况,损耗额外的性能。比如下图中,白色的三角形只占用了3个像素(绿色),按我们普通的思维,只需要3个Core绘制3次就可以了。
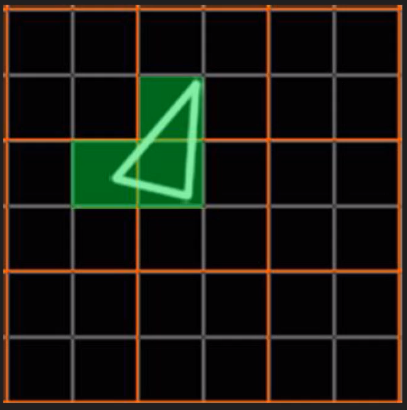
但是,由于上面的3个像素分别占据了不同的像素块(橙色分隔),实际上需要占用12个Core绘制12次(下图)。
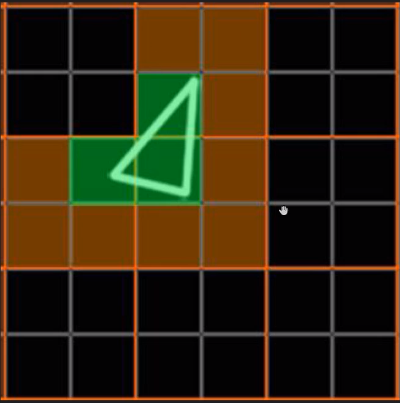
这就会额外消耗300%的硬件性能,导致了更加严重的过绘制情况。
三、GPU资源机制
3.1 内存架构
部分架构的GPU与CPU类似,也有多级缓存结构:寄存器、L1缓存、L2缓存、GPU显存、系统显存。
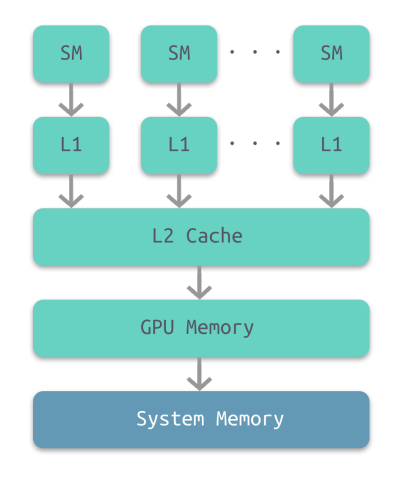
它们的存取速度从寄存器到系统内存依次变慢:
| 存储类型 | 寄存器 | 共享内存 | L1缓存 | L2缓存 | 纹理、常量缓存 | 全局内存 |
|---|---|---|---|---|---|---|
| 访问周期 | 1 | 1~32 | 1~32 | 32~64 | 400~600 | 400~600 |
由此可见,shader直接访问寄存器、L1、L2缓存还是比较快的,但访问纹理、常量缓存和全局内存非常慢,会造成很高的延迟。
上面的多级缓存结构可被称为"CPU-Style",还存在GPU-Style的内存架构:
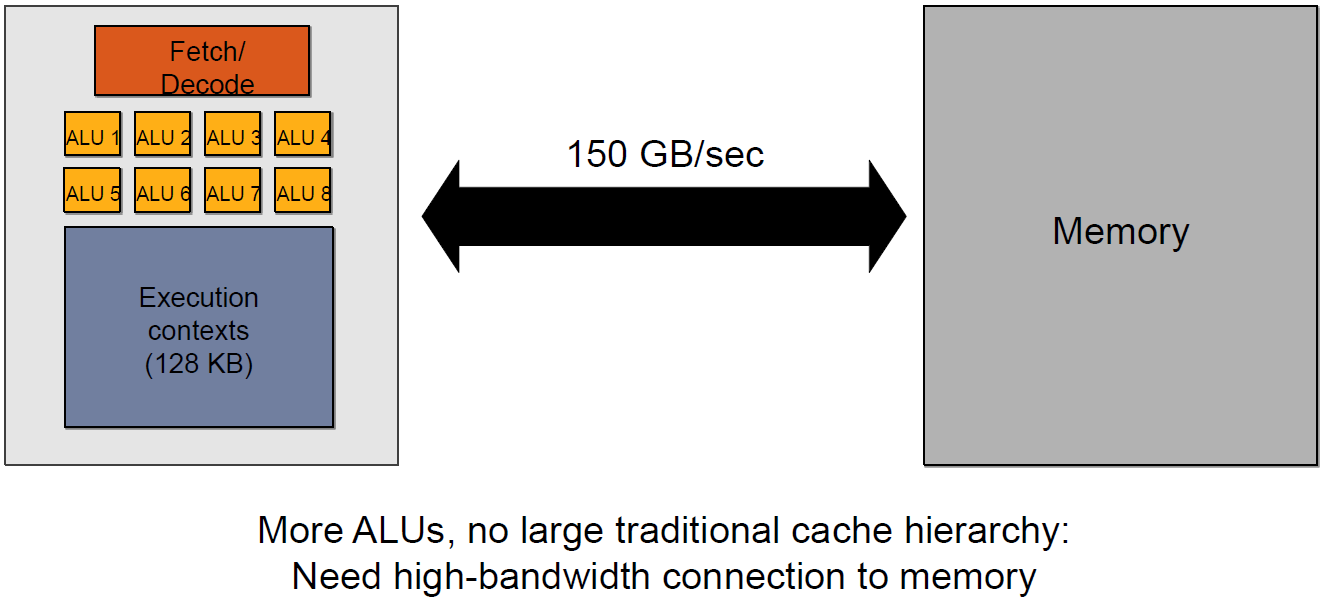
这种架构的特点是ALU多,GPU上下文(Context)多,吞吐量高,依赖高带宽与系统内存交换数据。
3.2 GPU Context和延迟
由于SIMT技术的引入,导致很多同一个SM内的很多Core并不是独立的,当它们当中有部分Core需要访问到纹理、常量缓存和全局内存时,就会导致非常大的卡顿(Stall)。
例如下图中,有4组上下文(Context),它们共用同一组运算单元ALU。
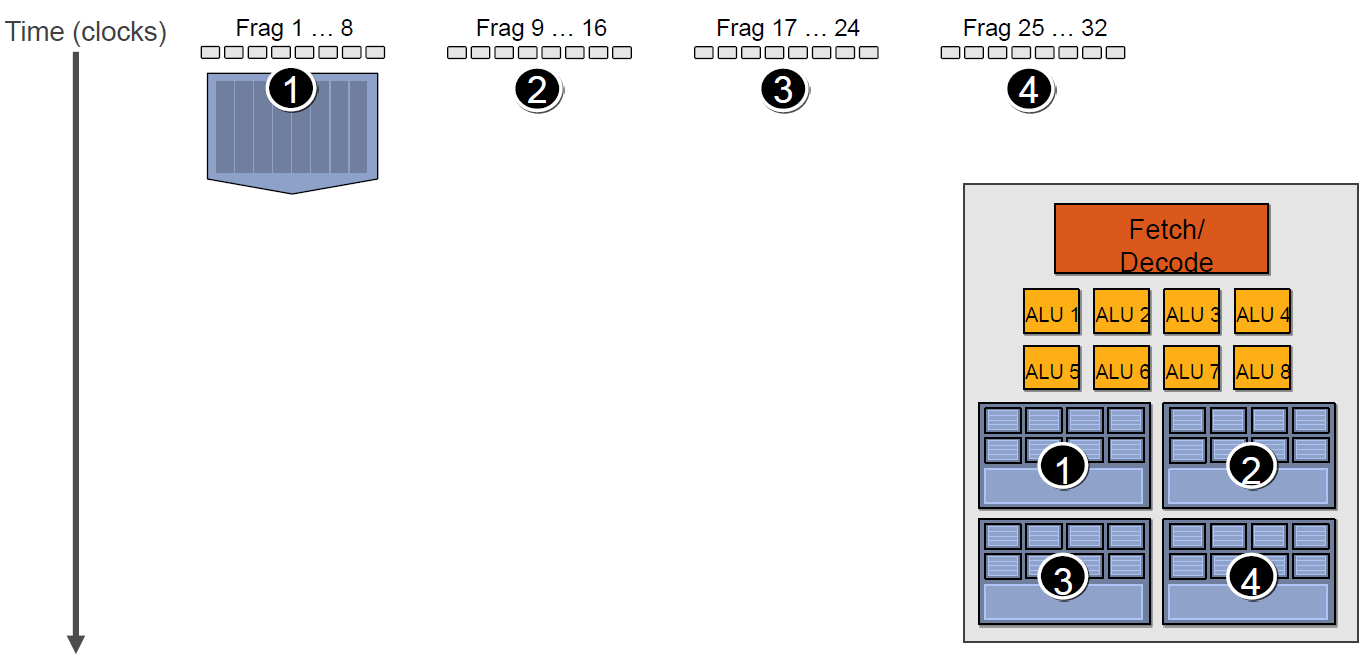
假设第一组Context需要访问缓存或内存,会导致2~3个周期的延迟,此时调度器会激活第二组Context以利用ALU:
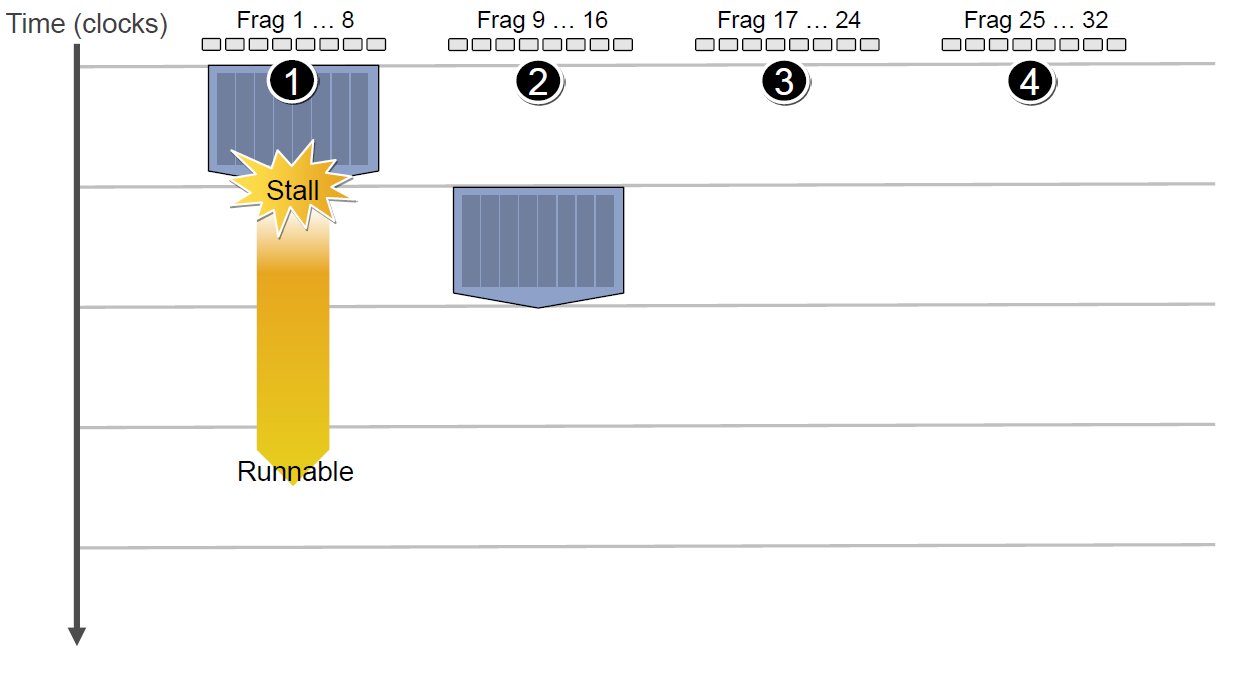
当第二组Context访问缓存或内存又卡住,会依次激活第三、第四组Context,直到第一组Context恢复运行或所有都被激活:
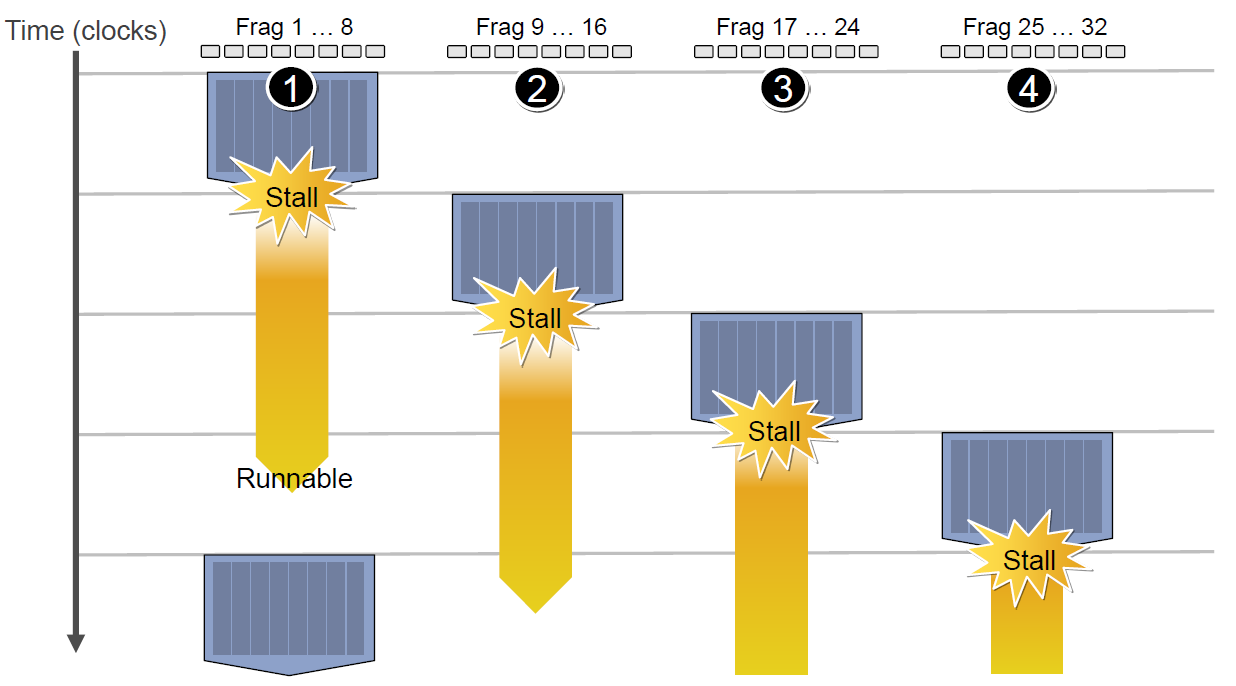
延迟的后果是每组Context的总体执行时间被拉长了:
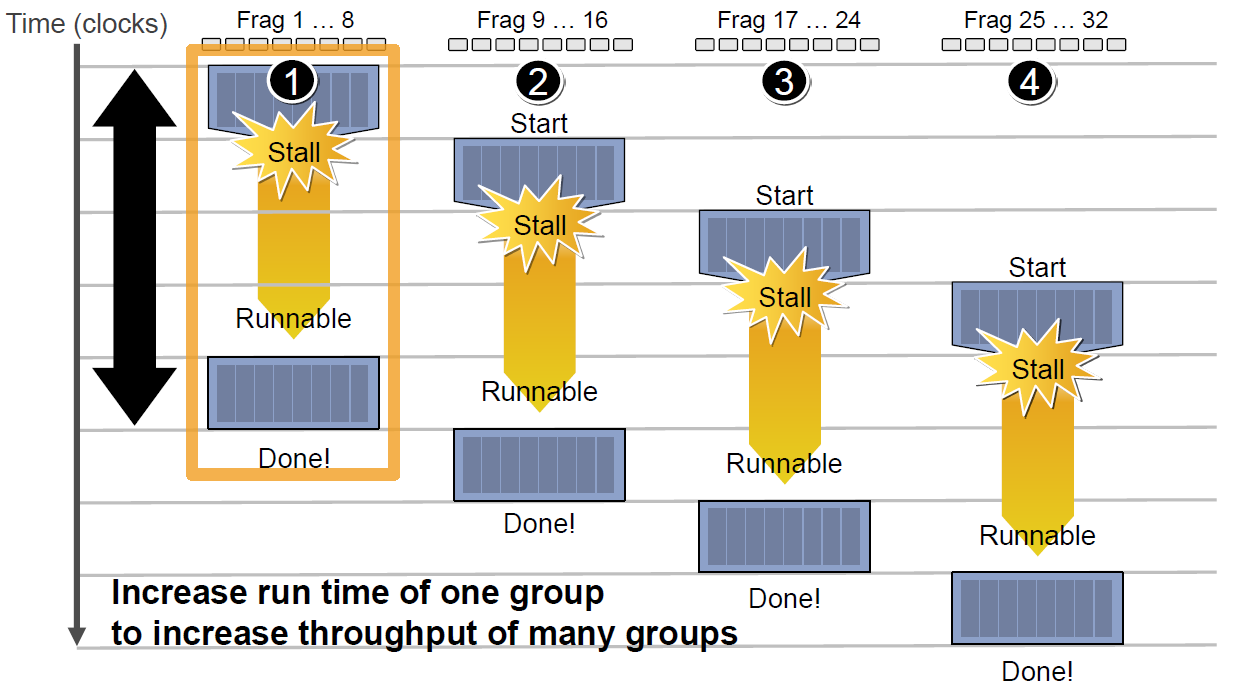
总计一下:当需要访问纹理、常量缓存和全局内存时,由于数据的保护性,导致SM组之间会变成串行处理关系,此时会出现明显的卡顿情况。
为了避免此情况,尽量减少访问。
3.3 CPU-GPU异构系统
根据CPU和GPU是否共享内存,可分为两种类型的CPU-GPU架构:
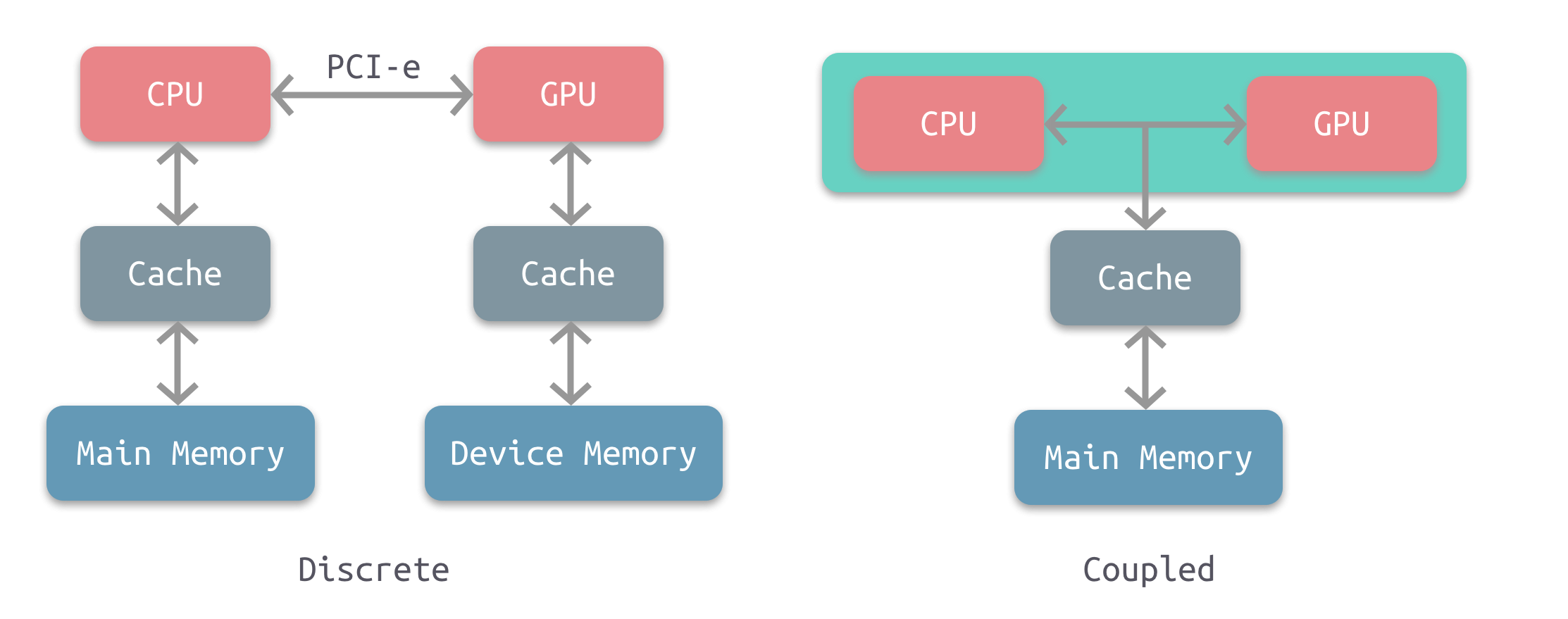
上图左是分离式架构,CPU和GPU各自有独立的缓存和内存,它们通过PCI-e等总线通讯。这种结构的缺点在于 PCI-e 相对于两者具有低带宽和高延迟,数据的传输成了其中的性能瓶颈。目前使用非常广泛,如PC、智能手机等。
上图右是耦合式架构,CPU 和 GPU 共享内存和缓存。AMD 的 APU 采用的就是这种结构,目前主要使用在游戏主机中,如 PS4。
在存储管理方面,分离式结构中 CPU 和 GPU 各自拥有独立的内存,两者共享一套虚拟地址空间,必要时会进行内存拷贝。对于耦合式结构,GPU 没有独立的内存,与 GPU 共享系统内存,由 MMU 进行存储管理。
3.4 显像机制
-
水平和垂直同步信号
在早期的CRT显示器,电子枪从上到下逐行扫描,扫描完成后显示器就呈现一帧画面。然后电子枪回到初始位置进行下一次扫描。为了同步显示器的显示过程和系统的视频控制器,显示器会用硬件时钟产生一系列的定时信号。
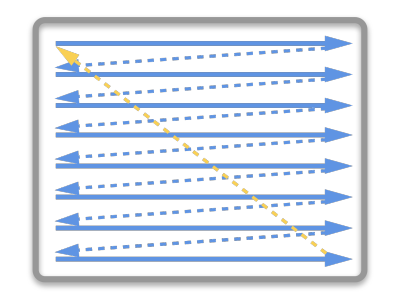
当电子枪换行进行扫描时,显示器会发出一个水平同步信号(horizonal synchronization),简称 HSync
当一帧画面绘制完成后,电子枪回复到原位,准备画下一帧前,显示器会发出一个垂直同步信号(vertical synchronization),简称 VSync。
显示器通常以固定频率进行刷新,这个刷新率就是 VSync 信号产生的频率。虽然现在的显示器基本都是液晶显示屏了,但其原理基本一致。
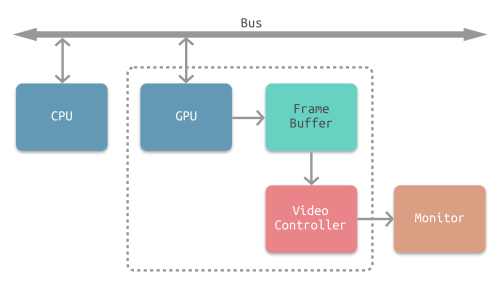
CPU将计算好显示内容提交至 GPU,GPU 渲染完成后将渲染结果存入帧缓冲区,视频控制器会按照 VSync 信号逐帧读取帧缓冲区的数据,经过数据转换后最终由显示器进行显示。
-
双缓冲
在单缓冲下,帧缓冲区的读取和刷新都都会有比较大的效率问题,经常会出现相互等待的情况,导致帧率下降。
为了解决效率问题,GPU 通常会引入两个缓冲区,即 双缓冲机制。在这种情况下,GPU 会预先渲染一帧放入一个缓冲区中,用于视频控制器的读取。当下一帧渲染完毕后,GPU 会直接把视频控制器的指针指向第二个缓冲器。
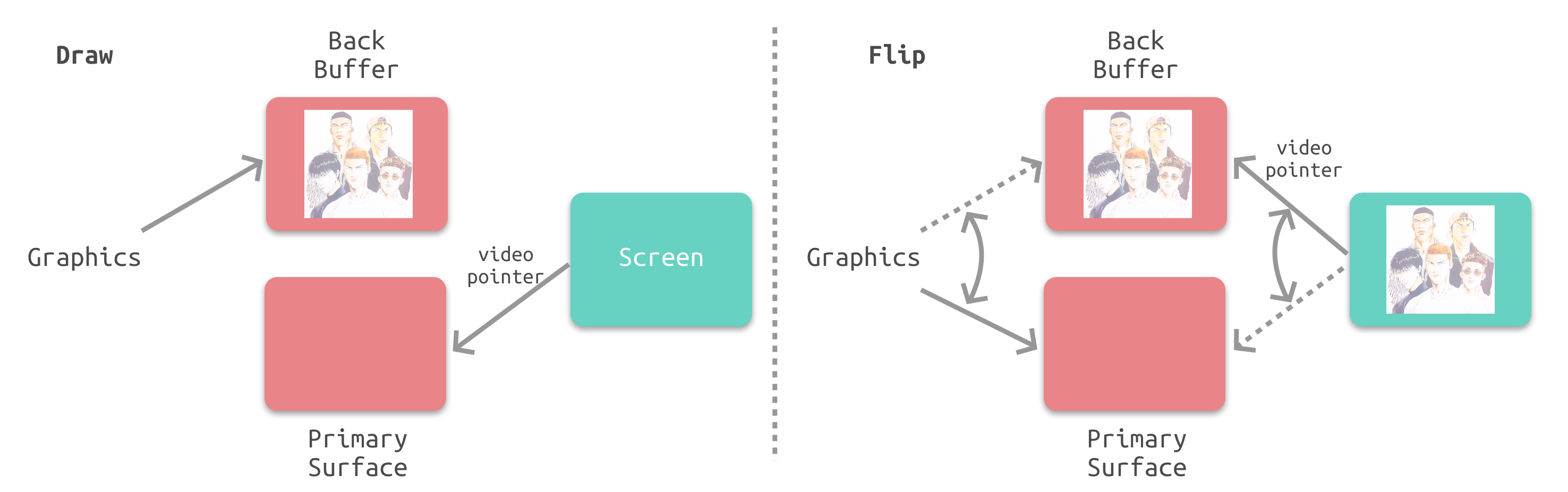
-
垂直同步
双缓冲虽然能解决效率问题,但会引入一个新的问题。当视频控制器还未读取完成时,即屏幕内容刚显示一半时,GPU 将新的一帧内容提交到帧缓冲区并把两个缓冲区进行交换后,视频控制器就会把新的一帧数据的下半段显示到屏幕上,造成画面撕裂现象:

为了解决这个问题,GPU 通常有一个机制叫做垂直同步(简写也是V-Sync),当开启垂直同步后,GPU 会等待显示器的 VSync 信号发出后,才进行新的一帧渲染和缓冲区更新。这样能解决画面撕裂现象,也增加了画面流畅度,但需要消费更多的计算资源,也会带来部分延迟。
四、渲染优化建议
由上章的分析,可以很容易给出渲染优化建议:
-
减少CPU和GPU的数据交换:
- 合批(Batch)
- 减少顶点数、三角形数
- 视锥裁剪
- BVH
- Portal
- BSP
- OSP
- 避免每帧提交Buffer数据
- CPU版的粒子、动画会每帧修改、提交数据,可移至GPU端。
- 减少渲染状态设置和查询
- 例如:
glGetUniformLocation会从GPU内存查询状态,耗费很多时间周期。 - 避免每帧设置、查询渲染状态,可在初始化时缓存状态。
- 例如:
- 启用GPU Instance
- 开启LOD
- 避免从显存读数据
-
减少过绘制:
- 避免Tex Kill操作
- 避免Alpha Test
- 避免Alpha Blend
- 开启深度测试
- Early-Z
- 层次Z缓冲(Hierarchical Z-Buffering,HZB)
- 开启裁剪:
- 背面裁剪
- 遮挡裁剪
- 视口裁剪
- 剪切矩形(scissor rectangle)
- 控制物体数量
- 粒子数量多且面积小,由于像素块机制,会加剧过绘制情况
- 植物、沙石、毛发等也如此
-
Shader优化:
- 避免if、switch分支语句
- 避免
for循环语句,特别是循环次数可变的 - 减少纹理采样次数
- 禁用
clip或discard操作 - 减少复杂数学函数调用
五、转文中的问题
1、GPU是如何与CPU协调工作的?
答:CPU 与 GPU 的交互是计算机系统中 "通用计算" 与 "并行计算" 协同工作的核心环节,其过程涉及硬件接口、驱动程序、数据传输和任务调度等多个层面。以下是具体的交互机制和流程:
一、硬件连接:物理通信通道
CPU 与 GPU 的交互首先依赖物理接口,数据和指令通过这些通道传输:
-
PCIe 总线(主流) :绝大多数消费级和专业级 GPU(如 NVIDIA 显卡、AMD 显卡)通过PCIe(Peripheral Component Interconnect Express) 与 CPU 连接。PCIe 是一种高速串行总线,当前主流为 PCIe 4.0(带宽约 32GB/s)或 PCIe 5.0(约 64GB/s),负责传输指令、数据和状态信息。
-
集成 GPU(核显) :对于 CPU 内置的 GPU(如 Intel 的 Iris Xe、AMD 的 Radeon Vega 核显),两者共享 CPU 的内存(DDR4/DDR5),通过内部总线(如 Ring Bus)直接通信,延迟更低(无需经过 PCIe)。
-
特殊架构(如异构计算) :部分高端系统(如 AMD 的 APU、NVIDIA 的 Grace Hopper)采用统一内存架构(UMA) 或NVLink,GPU 与 CPU 共享物理内存或通过高速链路直连,进一步提升数据传输效率。
二、驱动程序:软件层的 "翻译官"
硬件交互需要驱动程序(如 NVIDIA 的 CUDA 驱动、AMD 的 Radeon Software)作为中间层,负责将 CPU 的指令 "翻译" 为 GPU 可理解的格式:
-
驱动的核心作用:
-
管理 GPU 硬件资源(如流处理器、显存、计算核心);
-
提供 API 接口(如 OpenGL、DirectX、CUDA、OpenCL),让 CPU 的应用程序(如游戏、渲染软件)能调用 GPU 功能;
-
处理 GPU 的中断信号(如任务完成、错误报告),并反馈给 CPU。
-
三、交互流程:从任务发起至结果返回
CPU 与 GPU 的典型交互过程可分为 4 个步骤,以 "游戏渲染" 为例:
- CPU 发起任务并准备数据
-
CPU 负责处理逻辑任务(如游戏中的角色位置计算、碰撞检测),并确定需要 GPU 执行的并行任务(如渲染一帧画面)。
-
CPU 在系统内存(RAM) 中准备 GPU 所需的数据(如顶点坐标、纹理图片、光照参数),并通过驱动程序向 GPU 发送 "任务指令"(如 "使用这些数据渲染当前帧")。
- 数据从系统内存传输到 GPU 显存
-
GPU 有独立的显存(VRAM,如 GDDR6、HBM3),因带宽远高于系统内存(如 GDDR6 带宽可达 500GB/s 以上),更适合支撑并行计算。
-
CPU 通过 PCIe 总线将系统内存中的数据复制到 GPU 显存(此过程称为 "数据上传"),驱动程序会优化传输效率(如批量传输、压缩数据)。
- GPU 执行任务并反馈状态
-
GPU 接收到指令和数据后,由其控制单元(如 NVIDIA 的 GPC、AMD 的 Shader Engine)调度内部的流处理器(CUDA 核心、RDNA 核心)执行并行计算(如顶点变换、像素着色)。
-
任务执行过程中,GPU 通过 PCIe 向 CPU 发送状态信息(如 "数据接收完成""任务执行中");若出现错误(如显存不足),则发送中断信号通知 CPU 处理。
- GPU 返回结果,CPU 处理后续逻辑
-
GPU 完成任务后,将结果(如渲染好的一帧图像数据)暂存于显存中,通过 PCIe 通知 CPU "任务完成"。
-
CPU 根据需求决定是否将结果从显存传回系统内存(如保存渲染后的图片),或直接由 GPU 输出到显示器(如游戏画面通过 HDMI/DP 接口显示)。
-
CPU 继续处理下一帧的逻辑任务,重复上述流程(游戏中每秒需重复 60 次以上,以保证流畅画面)。
四、关键技术:优化交互效率
由于 CPU 与 GPU 的架构差异(串行 vs 并行)和物理分离(独立内存),交互过程中存在延迟和带宽瓶颈,以下技术用于优化:
-
DMA 传输(直接内存访问):CPU 可通过 DMA 控制器让 GPU 直接读取系统内存数据,无需 CPU 全程参与,减少 CPU 占用。
-
统一内存(Unified Memory):在支持的系统中(如 NVIDIA 的 CUDA Unified Memory、AMD 的 HSA),CPU 和 GPU 可访问同一块 "虚拟内存",无需显式复制数据(驱动自动处理数据迁移),简化编程并减少传输开销。
-
任务批处理:CPU 将多个小任务合并为一个批处理任务发送给 GPU,减少 PCIe 传输次数(每次传输有固定延迟),提升效率。
-
异步计算:CPU 在 GPU 执行任务时,可同时处理其他逻辑(如准备下一帧数据),通过 "异步" 机制隐藏 GPU 的计算时间,避免 CPU 等待造成的效率浪费(如游戏引擎中的多线程渲染管线)。
总结
CPU 与 GPU 的交互是 "软件指令 + 硬件传输" 的协同过程:CPU 作为 "指挥官" 发起任务、准备数据并调度流程,GPU 作为 "并行执行者" 通过高速总线接收任务并高效完成计算,两者通过驱动程序和硬件接口无缝配合,最终实现复杂场景(如游戏、AI 训练)的高效运行。交互效率的核心瓶颈在于数据传输(PCIe 带宽)和任务调度,因此现代系统不断通过硬件升级(如 PCIe 5.0)和软件优化(如统一内存)提升协同能力。
2、GPU也有缓存机制吗?有几层?它们的速度差异多少?
答:有缓存机制,总共6层。
位于核心处的缓存2层,寄存器和共享内存。
L1缓存属于SM组内缓存相对速度较快。
L2缓存位于GPU内部为所有SM组共享,容量略大于L1,速度略慢一些。
等到纹理缓存级,访问速度大幅度下降。
它们的存取速度从寄存器到系统内存依次变慢:
| 存储类型 | 寄存器 | 共享内存 | L1缓存 | L2缓存 | 纹理、常量缓存 | 全局内存 |
|---|---|---|---|---|---|---|
| 访问周期 | 1 | 1~32 | 1~32 | 32~64 | 400~600 | 400~600 |
GPU的缓存容量较小,所以GPU对比CPU不适合储存数据。
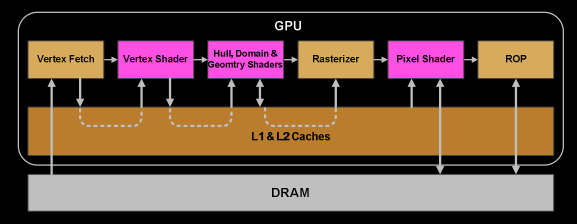
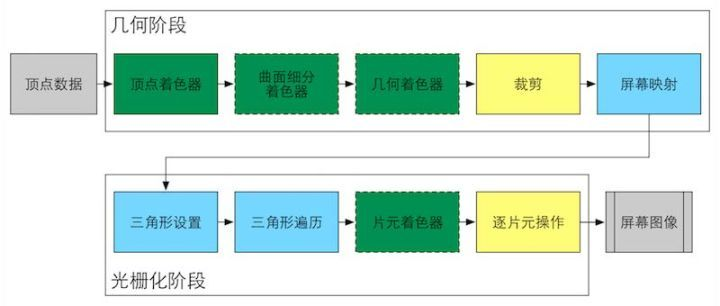
3、GPU的渲染流程有哪些阶段?它们的功能分别是什么?
流程图示在上面:
顶点着色器:对每个顶点进行坐标变换、光照计算等操作。
曲面细分阶段:动态增加几何细节,常用于地形、布料等需要细节变化的场景。
几何着色阶段:处理图元(如点、线、三角形),可生成或销毁图元。
裁剪阶段:将超出视锥体(View Frustum)的图元裁剪,保留可见部分。
屏幕映射阶段:将裁剪空间的坐标转换为屏幕坐标(像素位置)。
光栅化阶段:将 3D 三角形转换为 2D 像素(片元),并为每个片元插值属性(如颜色、深度值、纹理坐标)。
片段着色阶段:计算每个片元的最终颜色,通常包含纹理采样、光照计算等。
输出合并阶段:将计算后的片元颜色与帧缓冲区(Frame Buffer)中的现有颜色合并,执行深度测试、模板测试等。
4、Early-Z技术是什么?发生在哪个阶段?这个阶段还会发生什么?会产生什么问题?如何解决?
答:Early-Z技术可以将很多无效的像素提前剔除,避免它们进入耗时严重的像素着色器。发生在像素着色器之前。会产生深度数据冲突的问题,导致某些片源显示错误。在Early-Z之后再次拿片源深度与Frame Buffer中的深度进行比较。
5、SIMD和SIMT是什么?它们的好处是什么?co-issue呢?
答:SIMD(Single Instruction, Multiple Data)即单指令多数据,是一种并行处理技术。SIMT(Single Instruction, Multiple Threads)即单指令多线程,是 SIMD 的一种扩展形式。
SIMD好处:提高对大规模数据的处理效率。对大量数据执行相同的运算,SIMD 可以显著减少处理时间。
SIMT好处: 提供了更灵活的并行处理方式,它允许线程在执行过程中根据条件进行分支,而不需要像传统 SIMD 那样要求所有数据都执行完全相同的操作。这使得 SIMT 能够更好地适应复杂的应用场景,如游戏中的物理模拟、人工智能算法等,在这些场景中,不同的数据可能需要不同的处理逻辑,但又存在一定的并行性可以利用。
co-issue是为了解决SIMD运算单元无法充分利用的问题。比如合并1D与3D的数据打包执行ADD指令的时候同一个ALU只需一个指令周期完成。
如果其中一个变量既是操作数又是存储数的情况,无法启用co-issue技术。
6、GPU是并行处理的么?若是,硬件层是如何设计和实现的?
答:是并行处理。
GPU 大量的流式多处理器(Streaming Multiprocessor, SM) 组成,每个 SM 是独立的计算单元。
每个 SM 有 2 个 warp 调度器,可同时管理 64 个 warp(2048 线程),通过快速切换线程掩盖内存延迟。
以SIMT进行执行:
- warp 级并行:线程以 32 个为一组(warp),执行相同指令但操作不同数据。例如,32 个线程同时计算 32 个像素的颜色值。
- 分支处理:若 warp 内线程分支不同,硬件通过谓词寄存器和分支同步栈实现部分线程活跃、部分挂起,避免整体停顿。例如,50% 线程执行
if分支时,硬件自动屏蔽另一半线程,保持指令流水线不中断
内存层次优化
- 寄存器:每个线程拥有独立寄存器组,访问延迟仅 1-2 个时钟周期,存储临时变量和中间结果。
- 共享内存:每个 SM 提供 32KB-192KB 共享内存,线程块内线程可快速通信,例如矩阵分块计算时缓存子矩阵。
- 全局内存与缓存:通过 L1/L2 缓存减少全局内存访问压力,L1 缓存与共享内存动态分配(如 NVIDIA Ampere 架构中两者共 96KB)。
实现机制:
- 线程调度与负载均衡
-
线程块分配:GPU 的Giga 线程引擎将线程块分配给 SM,优先选择共享内存已加载数据的 SM,减少数据搬运。
-
warp 动态调度:SM 内的 warp 调度器根据线程状态(如是否等待内存)动态切换执行的 warp。例如,当某个 warp 因访存延迟暂停时,立即切换到另一就绪 warp,确保计算单元持续忙碌。
- 指令分发与执行
-
单指令多线程:每个 warp 的 32 个线程从同一 PC 地址取指令,通过 SIMT 硬件广播指令到所有线程。例如,一条指令可同时更新 32 个像素的透明度。
-
分支预测与谓词执行:简单分支通过谓词寄存器标记活跃线程(如
if (x>0)中,仅满足条件的线程执行后续指令);复杂分支则通过分支同步栈保存状态,确保线程后续合并。
- 硬件加速单元
-
Tensor Cores:专为深度学习设计,支持混合精度矩阵运算(如 FP16×FP16→FP32),单芯片算力可达数百 TOPS。
-
特殊函数单元(SFU):加速超越函数(如 sin、cos)计算,避免通用核心处理的低效。
- 内存访问优化
-
合并访存:线程按连续地址访问全局内存时,硬件自动合并请求为一次事务,提升带宽利用率。例如,32 个线程访问连续 32 个 float 数据时,仅需一次 64 字节事务。
-
纹理与常量缓存:优化图形渲染中的纹理采样和常量数据读取,例如顶点着色器中重复使用的光照参数可通过常量缓存加速。
总结
GPU 通过多 SM 架构 、SIMT 执行模型 、高速内存层次 和动态线程调度 实现了大规模并行处理。其硬件设计的核心思想是通过数量换取速度------ 用大量相对简单的计算核心和线程级并行性,在数据密集型任务中达到远超 CPU 的吞吐量。理解这些机制(如 warp 调度、共享内存使用、合并访存)是优化 GPU 程序的关键,而硬件厂商(如 NVIDIA、AMD)则通过持续创新(如 Tensor Cores、HBM)进一步推动并行计算的极限。
7、GPC、TPC、SM是什么?Warp又是什么?它们和Core、Thread之间的关系如何?
答:
GPC:图形处理集群,是 GPU 的最高层级结构,包含多个 TPC、纹理单元、L2 缓存等。
一个 GPU 包含多个 GPC(如 NVIDIA GTX 1080 有 4 个 GPC),每个 GPC 包含多个 TPC。
TPC:纹理处理集群,是 GPC 的子单元,包含多个 SM、纹理单元和 L1 缓存。
一个 GPC 包含 2-4 个 TPC(如 GTX 1080 每个 GPC 有 2 个 TPC),每个 TPC 包含多个 SM。
SM:流多处理器,是 TPC 的核心计算单元,包含多个 CUDA 核心(或 AMD 的计算单元)、寄存器、共享内存、L1 缓存等。
一个 TPC 包含 1-4 个 SM(如 GTX 1080 每个 TPC 有 4 个 SM),每个 SM 可同时处理多个 warp。
Wrap:线程束,是 SM 调度和执行的最小单元,由32 个线程组成(NVIDIA GPU)。
一个 SM 可同时管理多个 warp,但同一时刻仅执行 1-2 个 warp 的指令。
Core:一个 SM 包含数十到数百个 Core(如 RTX 4090 每个 SM 有 128 个 CUDA 核心),多个 Core 可并行执行同一 warp 的指令。
Thread:线程被组织成线程块(Thread Block),每个线程块包含 32-1024 个线程;线程块被分配到 SM 上执行,线程块内的线程被划分为多个 warp。
8、顶点着色器(VS)和像素着色器(PS)可以是同一处理单元吗?为什么?
答:可以是同一单元,因为 GPU 是统一着色器架构设计的。
硬件根据实时负载,将 VS 和 PS 任务分配给空闲的计算单元,无需像早期 GPU 那样静态划分专用的 VS/PS 单元。
9、像素着色器(PS)的最小处理单位是1像素吗?为什么?会带来什么影响?
答:不是1像素,而是2x2像素。
这是 GPU 为平衡纹理采样效率、抗锯齿支持和并行计算特性而设计的硬件优化
- 正面影响:性能与功能提升
-
纹理采样效率:通过共享相邻像素的纹理数据,减少纹理缓存访问次数,降低带宽压力。例如,4K 分辨率(3840×2160)下,2×2 块可减少约 75% 的纹理重复读取。
-
抗锯齿支持:硬件原生适配 MSAA、FXAA 等抗锯齿技术,无需额外的复杂逻辑即可处理多采样点。
-
计算连贯性:相邻像素的光照、阴影计算通常具有相似性(如同一物体表面),2×2 块可共享中间结果(如光照强度),减少冗余计算。
- 负面影响:边缘像素的额外开销
-
"过度计算" 问题:当渲染小物体(如 1 像素宽的线条)或边缘像素时,2×2 块中可能只有 1-2 个像素有效,其余像素属于 "无效计算",浪费约 50%-75% 的算力。
-
透明度处理复杂:对于 Alpha 测试(如
discard语句),若 2×2 块中部分像素被丢弃,硬件仍需执行完整块的计算,再通过掩码屏蔽无效像素,导致效率下降(这也是discard会影响性能的原因之一
10、Shader中的if、for等语句会降低渲染效率吗?为什么?
答:会降低效率,因为存在分支分歧。由于SIMD的特性,每个ALU的数据不一样。会导致Wrap组内大量核心出现闲置等待情况,使GPU的并行效率大大降低
11、如下图,渲染相同面积的图形,三角形数量少(左)的还是数量多(右)的效率更快?为什么?
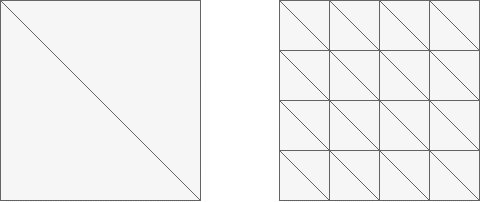
答:左边更快。顶点处理和光栅化的 "固定开销" 随三角形数量增加而线性增长,而片段处理开销(总像素数)基本不变。因此,减少三角形数量可显著降低前两阶段的计算压力,提升整体渲染效率。
12、GPU Context是什么?有什么作用?
答:是 GPU 执行渲染或计算任务时所需的状态集合与资源环境,类似于 CPU 中 "进程上下文" 的概念(保存进程运行时的寄存器、内存映射等状态)。
作用:支持多任务并发和状态隔离,其核心价值在于隔离性 和**可切换性。**是现代 GPU 高效处理图形渲染、通用计算等多样化任务的基础
13、造成渲染瓶颈的问题很可能有哪些?该如何避免或优化它们?
答:
1.CPU瓶颈。
DrawCall过高。非渲染计算抢占CPU资源。顶点处理复杂。
减少DrawCall。使用合批技术,GPU Instance技术,LOD分级远处降低模型顶点,剔除优化,模型本身尽可能减少顶点数。Unity还可以使用SRP Batcher技术减少CPU上的压力
2.GPU瓶颈。
细分瓶颈:
- 带宽受限:纹理采样、帧缓冲读写频繁,显存带宽不足。
- 计算受限:像素着色器复杂(如多光源、高分辨率后处理)。
- 内存带宽:纹理数据过大,频繁从显存读取数据
纹理压缩,使用ETC/ASTC 等压缩格式。对于个别辅助类的纹理,如遮罩图,可以采用单色纹理。
使用LOD分级,对于远处模糊模型使用小尺寸的纹理。
减少场景光源数量,降低光源计算原理。
可以使用延迟渲染,将光照计算推迟到 G-Buffer 阶段。但场景内的物体就只能使用不透明物体了,否则有误差。
避免Alpha测试,discard这样的语句会破坏Z-early优化,优先使用 Alpha 混合或预计算 Alpha Mask。
避免在shader中写入if else这样的语句,会导致GPU性能下降。如果非要使用for循环,需要给for循环数量写入一个确切的定值。尽可能减少GPU分支分歧。
shader中在满足效果的情况下使用低精度的数值进行计算,如half代替float。