灵枢(Lingshu)作为阿里巴巴达摩院推出的医疗领域多模态大语言模型(MLLM),在医学图像理解、文本推理和报告生成等任务中展现了领先性能。以下是关键信息整合与解读:
核心亮点
-
多模态能力
- 支持医学影像(如X光、CT、MRI)与文本数据的联合理解,实现「视觉-语言」协同推理,在医疗VQA(视觉问答)任务中达到SOTA水平。
-
核心功能
- 医学报告生成:可基于影像数据生成结构化诊断报告。
- 跨模态推理:结合图像特征与临床文本(如病史)进行综合诊断推断。
- 任务兼容性:覆盖分类、定位、描述生成等多种医疗AI任务。
-
技术突破
- 提出分层跨模态对齐机制,通过病灶级视觉特征提取与医学知识注入,解决传统MLLMs在细粒度医学分析中的不足。
- 在MedBench 、MIMIC-CXR等基准测试中超越现有专用模型(如RadFM、Med-PaLM)。
资源导航
| 资源类型 | 链接 |
|---|---|
| 项目官网 | alibaba-damo-academy.github.io/lingshu/ |
| HuggingFace模型库 | HF Collections |
| 技术论文 | arXiv:2506.07044 |
| 评估工具包 | MedEvalKit GitHub |
应用场景示例
- 影像辅助诊断:输入胸部X光片,模型可输出「肺结节位置描述+恶性概率评估」。
- 交互式问诊:医生询问「患者眼底图像是否显示糖尿病视网膜病变?」,模型结合图像与电子病历给出分级建议。
- 教学辅助:自动生成包含鉴别诊断要点的影像案例分析报告。
局限性与未来方向
- 数据偏差:训练数据以常见病为主,罕见病表现需进一步优化。
- 模态扩展:当前版本未纳入超声视频等时序数据,后续版本计划支持动态影像分析。
建议临床用户通过MedEvalKit进行任务适配性测试,并关注HuggingFace库的模型更新(当前提供7B/13B参数版本)。研究团队表示正在推进FDA/CFDA认证相关工作,未来将发布医疗合规部署方案。
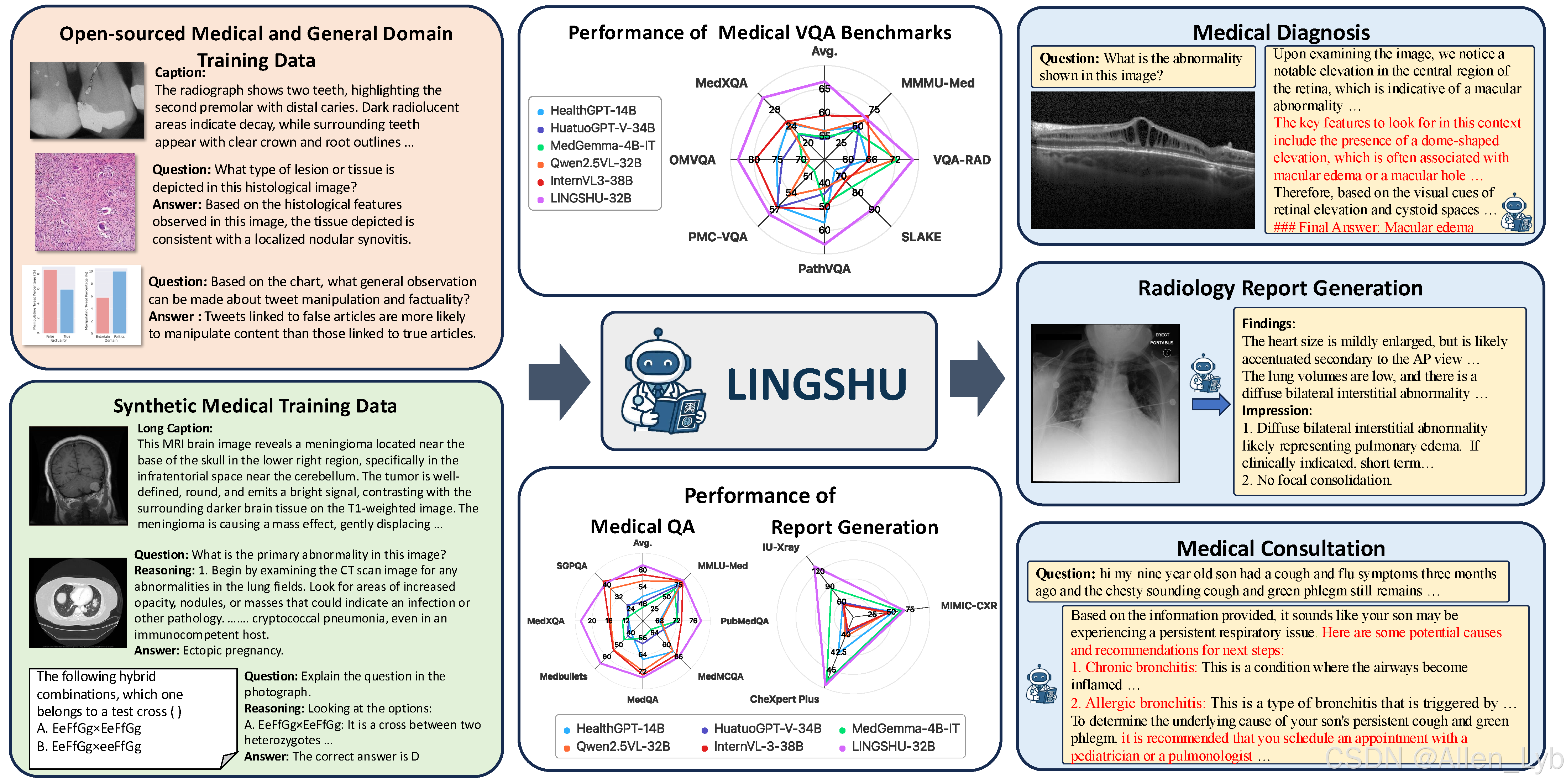
亮点
灵枢模型在大多数医疗多模态/文本质量保证和报告生成任务中,在 7B 和 32 模型大小上都达到了 SOTA。
在大多数多模态质量保证和报告生成任务中,灵枢-32B 优于 GPT-4.1 和 Claude Sonnet 4。
灵枢支持超过 12 种医学影像模式,包括 X 光、CT 扫描、MRI、显微镜、超声波、组织病理学、皮肤镜、眼底、OCT、数字摄影、内窥镜和 PET。
发布
模型权重:灵枢-7B,灵枢-32B
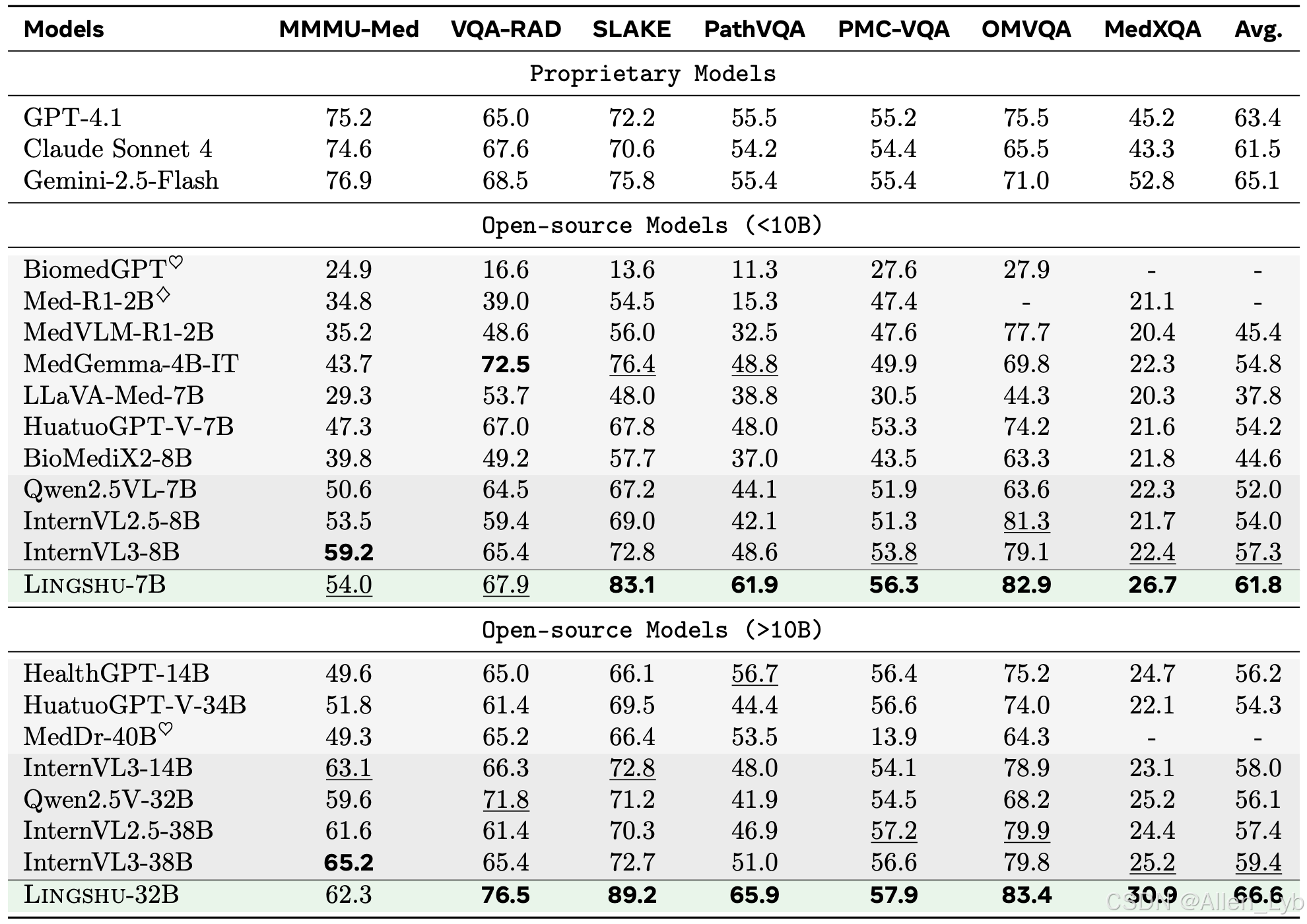
灵枢针对各种医疗模式的视觉问题解答性能
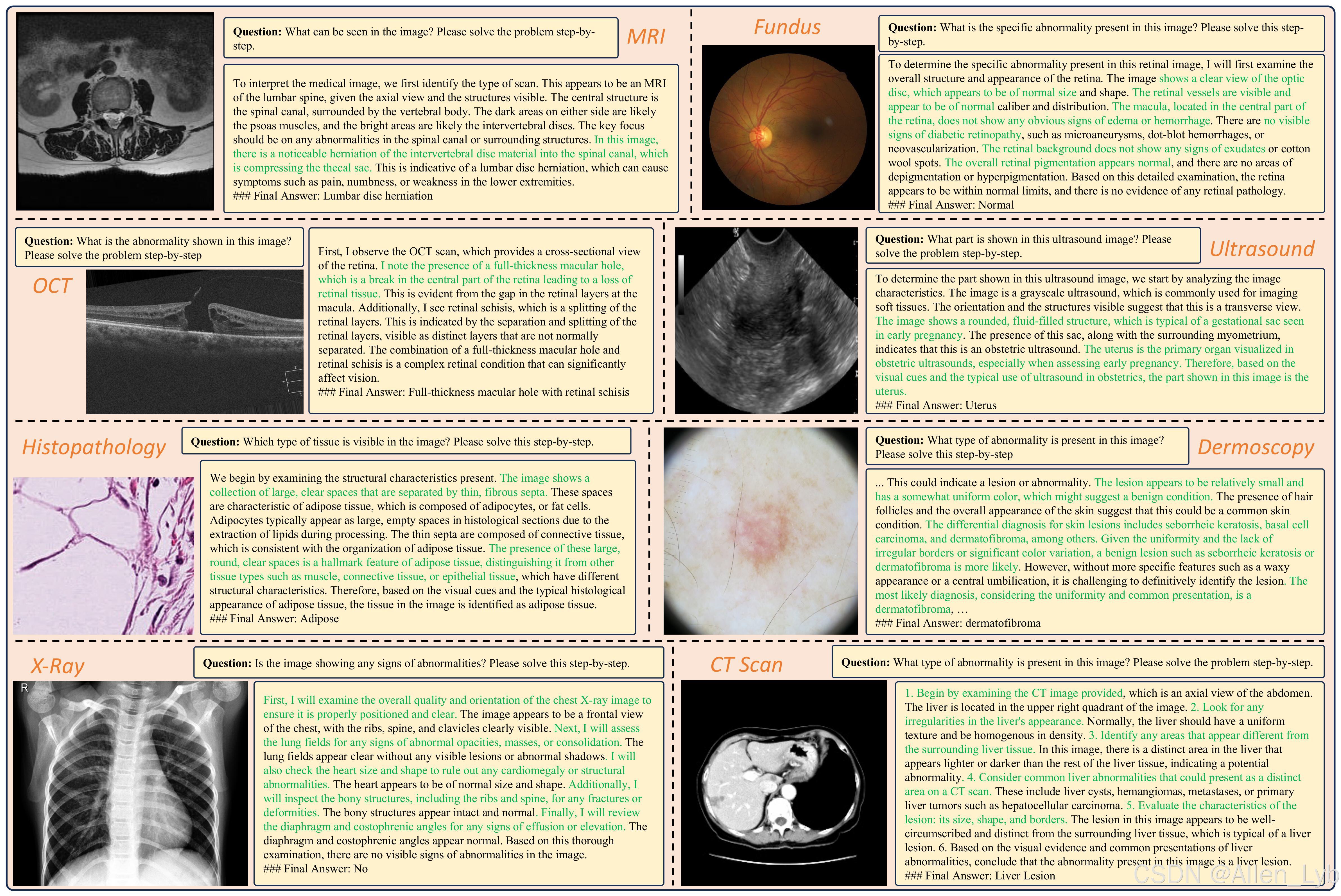
生成医疗报告

公共卫生
 医学知识理解
医学知识理解

医疗视觉问题解答结果
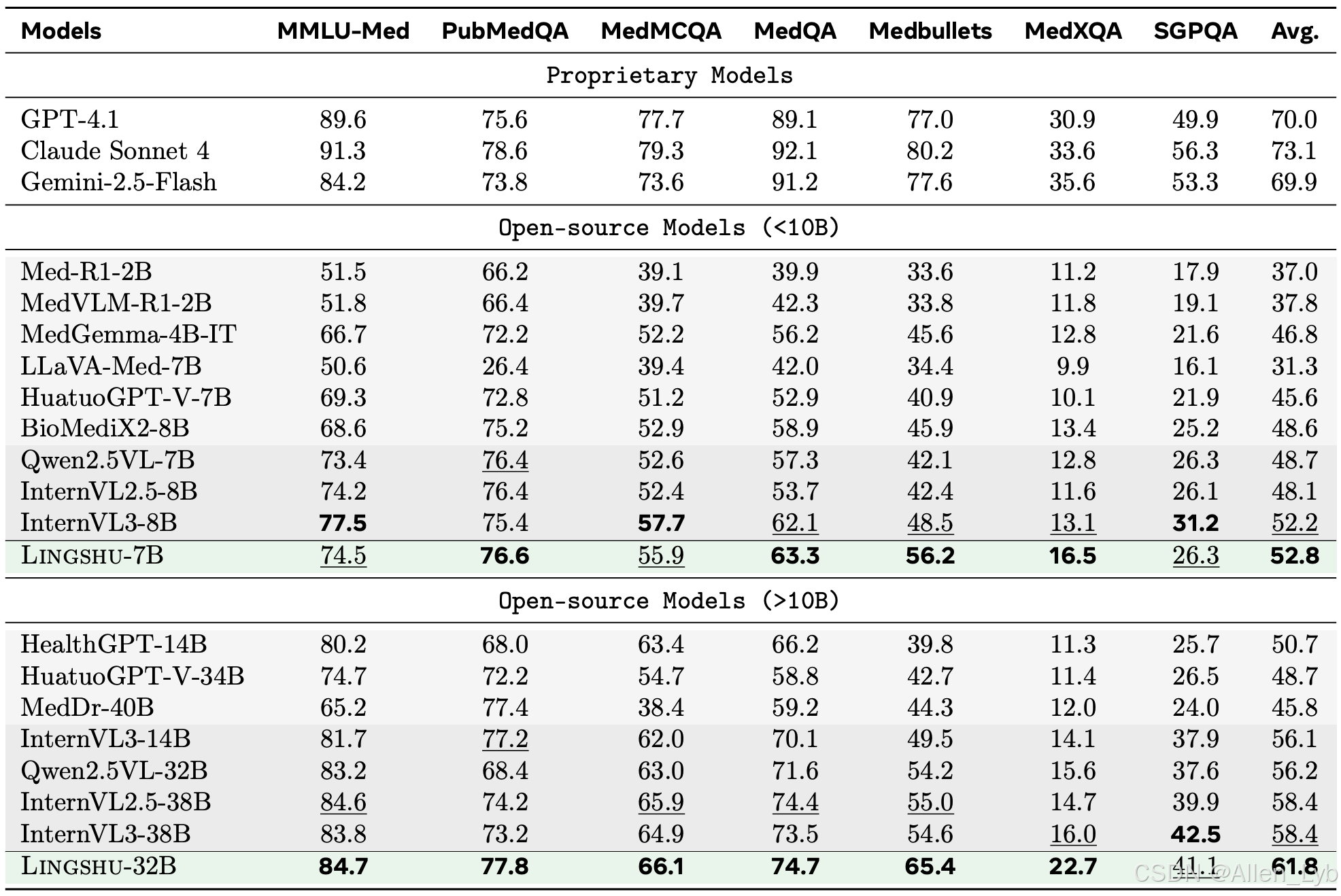
医学文本问题解答结果
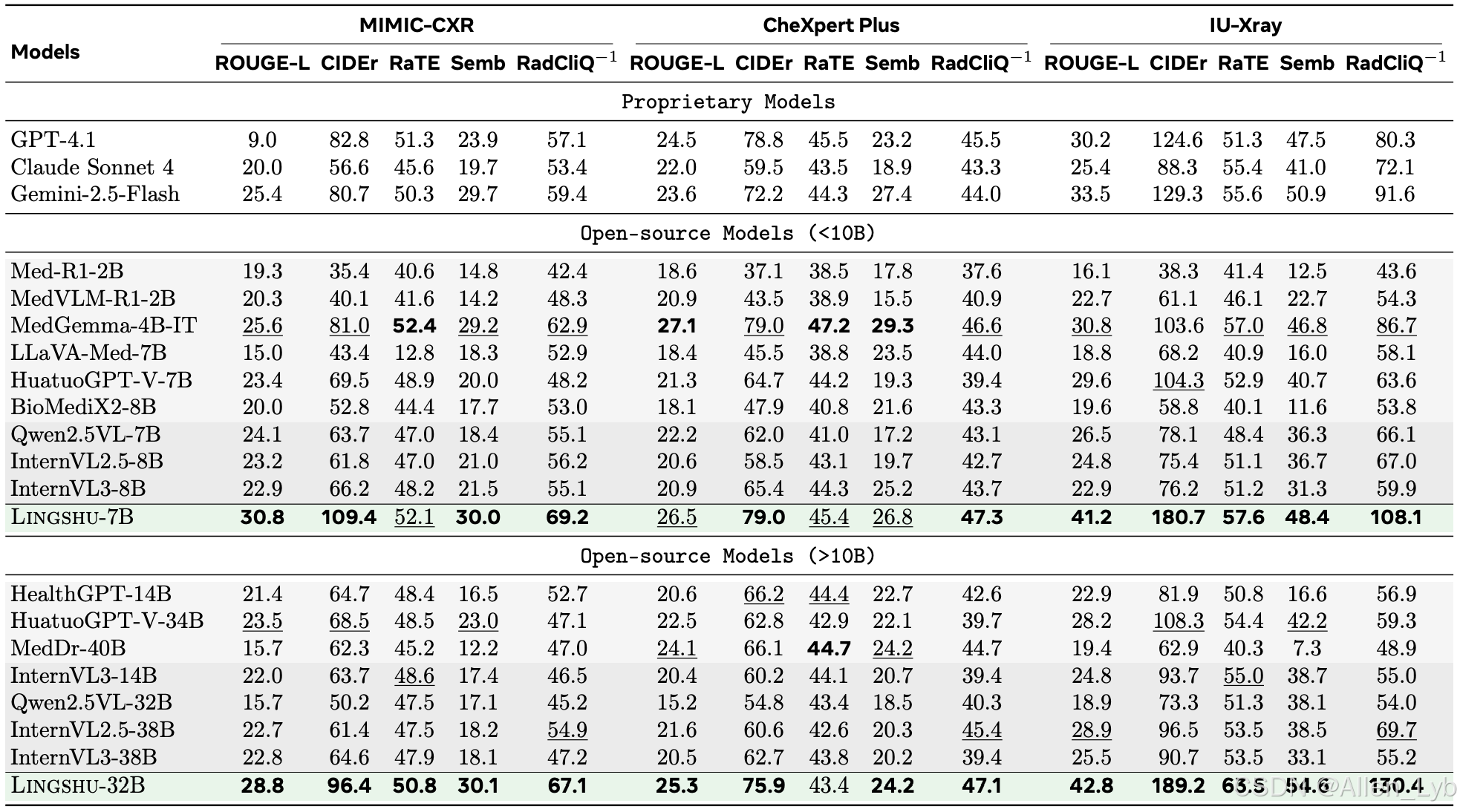
医疗报告生成结果
7B使用方法:
使用transformers
python
from transformers import Qwen2_5_VLForConditionalGeneration, AutoProcessor
from qwen_vl_utils import process_vision_info
# We recommend enabling flash_attention_2 for better acceleration and memory saving, especially in multi-image and video scenarios.
model = Qwen2_5_VLForConditionalGeneration.from_pretrained(
"lingshu-medical-mllm/Lingshu-7B",
torch_dtype=torch.bfloat16,
attn_implementation="flash_attention_2",
device_map="auto",
)
processor = AutoProcessor.from_pretrained("lingshu-medical-mllm/Lingshu-7B")
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"image": "example.png",
},
{"type": "text", "text": "Describe this image."},
],
}
]
# Preparation for inference
text = processor.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
image_inputs, video_inputs = process_vision_info(messages)
inputs = processor(
text=[text],
images=image_inputs,
videos=video_inputs,
padding=True,
return_tensors="pt",
)
inputs = inputs.to(model.device)
# Inference: Generation of the output
generated_ids = model.generate(**inputs, max_new_tokens=128)
generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
print(output_text)使用vllm
python
from vllm import LLM, SamplingParams
from qwen_vl_utils import process_vision_info
import PIL
from transformers import AutoProcessor
processor = AutoProcessor.from_pretrained("lingshu-medical-mllm/Lingshu-7B")
llm = LLM(model="lingshu-medical-mllm/Lingshu-7B", limit_mm_per_prompt = {"image": 4}, tensor_parallel_size=2, enforce_eager=True, trust_remote_code=True,)
sampling_params = SamplingParams(
temperature=0.7,
top_p=1,
repetition_penalty=1,
max_tokens=1024,
stop_token_ids=[],
)
text = "What does the image show?"
image_path = "example.png"
image = PIL.Image.open(image_path)
message = [
{
"role":"user",
"content":[
{"type":"image","image":image},
{"type":"text","text":text}
]
}
]
prompt = processor.apply_chat_template(
message,
tokenize=False,
add_generation_prompt=True,
)
image_inputs, video_inputs = process_vision_info(message)
mm_data = {}
mm_data["image"] = image_inputs
processed_input = {
"prompt": prompt,
"multi_modal_data": mm_data,
}
outputs = llm.generate([processed_input], sampling_params=sampling_params)
print(outputs[0].outputs[0].text)32B使用方法:
使用transformers
python
from transformers import Qwen2_5_VLForConditionalGeneration, AutoProcessor
from qwen_vl_utils import process_vision_info
# We recommend enabling flash_attention_2 for better acceleration and memory saving, especially in multi-image and video scenarios.
model = Qwen2_5_VLForConditionalGeneration.from_pretrained(
"lingshu-medical-mllm/Lingshu-32B",
torch_dtype=torch.bfloat16,
attn_implementation="flash_attention_2",
device_map="auto",
)
processor = AutoProcessor.from_pretrained("lingshu-medical-mllm/Lingshu-32B")
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"image": "example.png",
},
{"type": "text", "text": "Describe this image."},
],
}
]
# Preparation for inference
text = processor.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
image_inputs, video_inputs = process_vision_info(messages)
inputs = processor(
text=[text],
images=image_inputs,
videos=video_inputs,
padding=True,
return_tensors="pt",
)
inputs = inputs.to(model.device)
# Inference: Generation of the output
generated_ids = model.generate(**inputs, max_new_tokens=128)
generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
print(output_text)使用vllm
python
from vllm import LLM, SamplingParams
from qwen_vl_utils import process_vision_info
import PIL
from transformers import AutoProcessor
processor = AutoProcessor.from_pretrained("lingshu-medical-mllm/Lingshu-32B")
llm = LLM(model="lingshu-medical-mllm/Lingshu-32B", limit_mm_per_prompt = {"image": 4}, tensor_parallel_size=2, enforce_eager=True, trust_remote_code=True,)
sampling_params = SamplingParams(
temperature=0.7,
top_p=1,
repetition_penalty=1,
max_tokens=1024,
stop_token_ids=[],
)
text = "What does the image show?"
image_path = "example.png"
image = PIL.Image.open(image_path)
message = [
{
"role":"user",
"content":[
{"type":"image","image":image},
{"type":"text","text":text}
]
}
]
prompt = processor.apply_chat_template(
message,
tokenize=False,
add_generation_prompt=True,
)
image_inputs, video_inputs = process_vision_info(message)
mm_data = {}
mm_data["image"] = image_inputs
processed_input = {
"prompt": prompt,
"multi_modal_data": mm_data,
}
outputs = llm.generate([processed_input], sampling_params=sampling_params)
print(outputs[0].outputs[0].text)免责声明:我们必须指出,尽管我们以开放的方式发布了权重、代码和演示,与其他预训练的语言模型类似,尽管我们在红队测试和安全微调及执行方面做出了最大努力,但我们的模型仍存在潜在风险,包括但不限于不准确、误导或潜在有害的生成。开发人员和利益相关者应在部署前自行进行红队分析并提供相关的安全措施,而且必须遵守和服从当地的管理和法规。在任何情况下,作者均不对因使用发布的权重、代码或演示而引起的任何索赔、损害或其他责任负责。
参考资料: