一、操作系统简介
1.1 计算机系统的组成结构
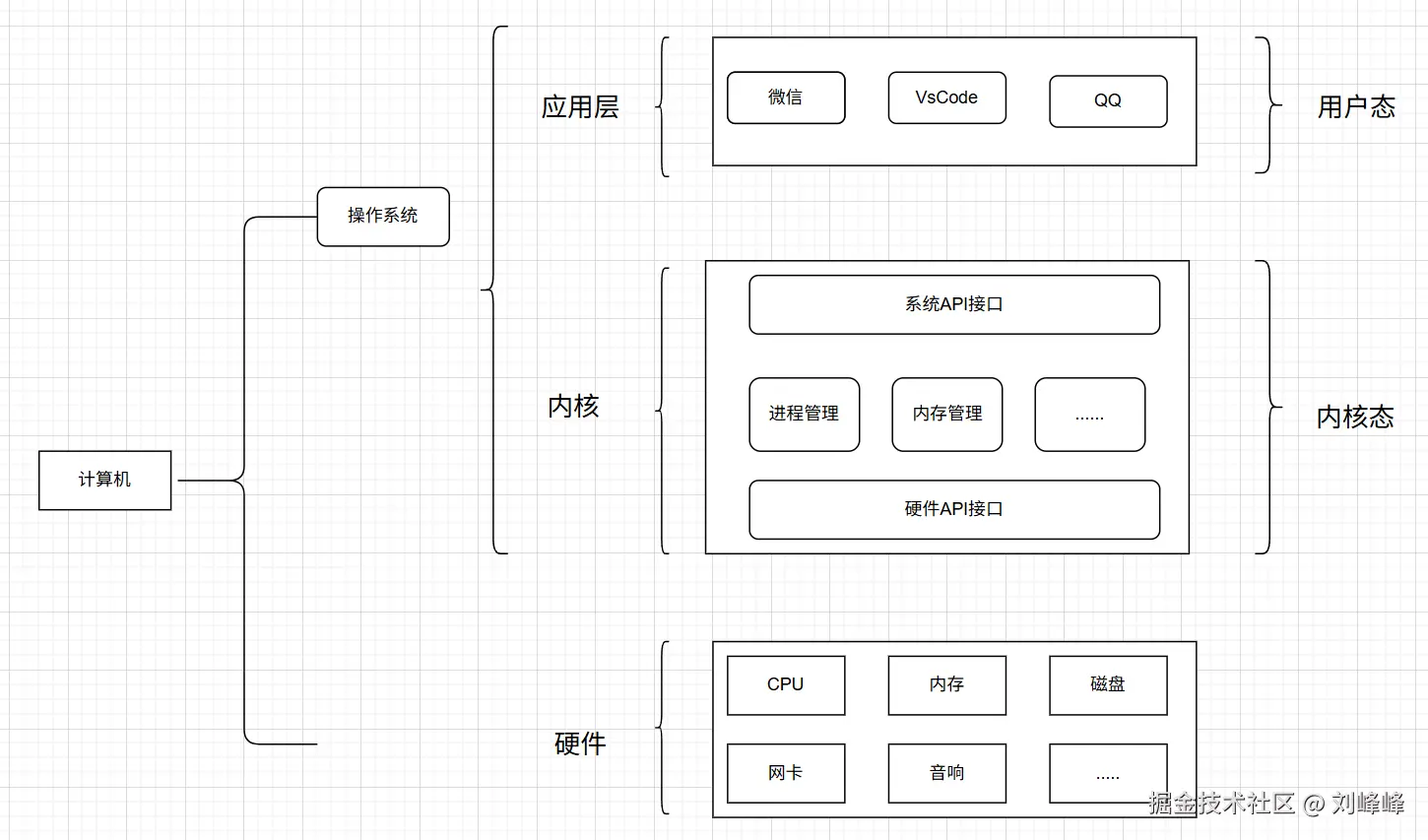
现代计算系统一般由以下几个部分组成:
- 应用程序:用户使用的程序,如浏览器、数据库、编译器等
- 操作系统内核(kernel):操作系统的底层部分,直接与硬件打交道提供进程管理、内存管理、文件系统、网络协议栈等核心功能
- 硬件资源:如磁盘、网卡、内存、CPU等
我们无法直接与硬件对话,因此所有的读写磁盘、发包通信等IO操作,都必须通过内核完成这也是 IO 操作通常涉及系统调用和内核交互 的原因
1.2 内核空间与用户空间
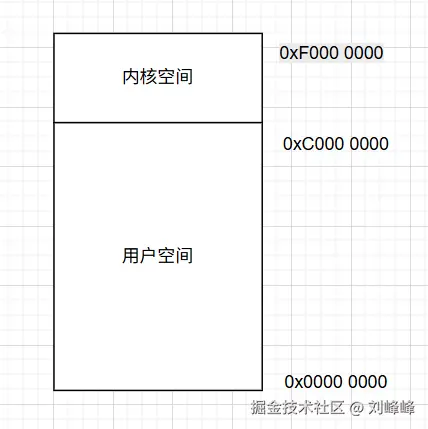
操作系统采用 虚拟地址空间 的机制来管理内存对32位操作系统来说,总地址空间为4GB,通常划分为:
- 用户空间(0x00000000 ~ 0xBFFFFFFF):应用程序只能访问的区域;
- 内核空间(0xC0000000 ~ 0xFFFFFFFF):操作系统内核的专属区域,用户程序无法随意访问;
这种机制保护了操作系统内核的完整性,即使用户程序崩溃,也不会影响内核的运行用户程序如果要访问内核空间,必须通过 系统调用(system call) 显式请求,只有在切换到内核态后才可执行对内核空间的操作
1.3 内核态与用户态
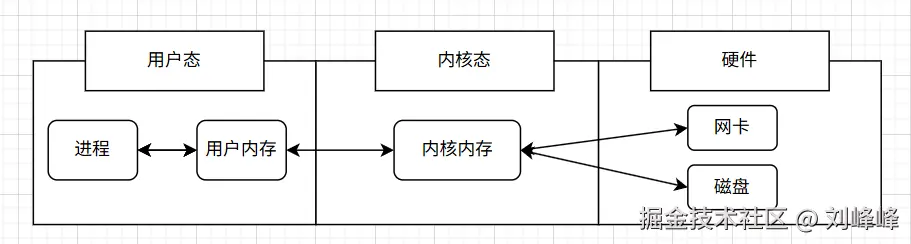
- 内核态(kernel mode):这时,进程直接运行在内核空间中,可以执行任意指令
- 用户态(user mode):这时,进程运行在用户空间,只能使用受限的指令
进程在调用系统调用(如创建线程、发起IO操作)时,会从 用户态切换到内核态 ,在内核处理完成后,又切换回用户态这个过程称作 上下文切换(context switch),每次切换都会造成性能的开销
二、IO的分类
我们常说的 IO 操作,通常指的是数据从外部设备(比如硬盘、网卡)传输到程序(用户空间)的过程,分为以下几个阶段:
- 用户空间 <-> 内核空间
- 内核空间 <-> 外部设备(如磁盘、网络)
2.1 网络IO 与 磁盘IO
-
网络IO:
- 数据到达网卡;
- 数据被读入内核缓冲区(socket buffer);
- 最终通过系统调用读入用户空间;
-
磁盘IO:
- 应用通过系统调用向内核申请文件读写;
- 内核向磁盘请求数据;
- 数据被读入内核缓冲区;
- 再复制到用户空间;
网络IO与磁盘IO有一个共同点:即它们都涉及内核与设备之间的等待过程,这段时间可能会相对较长,尤其是网络延迟较大或磁盘访问较慢的情况下
2.2 同步IO 与 异步IO
- 同步IO(Synchronous I/O) :
- 定义:调用方要一直等待操作结果返回,才会处理后续逻辑;
- 特点:简单直观,但效率不高;
- 所有操作(连接、读写)都是阻塞的,线程必须等待内核完成数据准备和复制
cpp
// 等待IO就绪(主线程被阻塞)
int sockfd = socket(AF_INET, SOCK_STREAM, 0);
connect(sockfd, &server_addr, sizeof(server_addr));
char buffer[1024];
int n = read(sockfd, buffer, sizeof(buffer));
if (n > 0) {
process(buffer);
}- 异步IO(Asynchronous I/O) :
- 定义:调用方发出请求后立即返回,由内核在完成IO时再通知调用方;
- 特点:高效,但逻辑复杂;
同步与异步之间,最明显区别在于 是否等待IO完成后再处理结果
2.3 阻塞IO 与 非阻塞IO
-
阻塞IO(Blocking I/O):
- 调用期间线程会被阻塞,等待操作完成;
- 程序无法做任何其他事,直到操作返回;
cppint fd = open("filename", O_RDONLY); char buffer[1024]; int bytes_read = read(fd, buffer, sizeof(buffer)); // 阻塞态,直到读完 -
非阻塞IO(Non-blocking I/O):
- 不会阻塞线程,返回立即;
- 但内核数据没就绪时,调用会失败并设置错误码为 EAGAIN 或 EWOULDBLOCK;
- 调用方通过轮询等手段继续尝试获取数据,这样线程可以处理其他逻辑;
cppint flags = fcntl(fd, F_GETFL, 0); fcntl(fd, F_SETFL, flags | O_NONBLOCK); int bytes_read = read(fd, buffer, sizeof(buffer)); if (bytes_read < 0 && errno == EAGAIN) { // 数据没准备好,进行其他操作 }
阻塞与非阻塞关注的是 调用方(用户程序)是否将线程挂起,是单线程场景下的性能关键
三、操作系统的五种 IO 模型
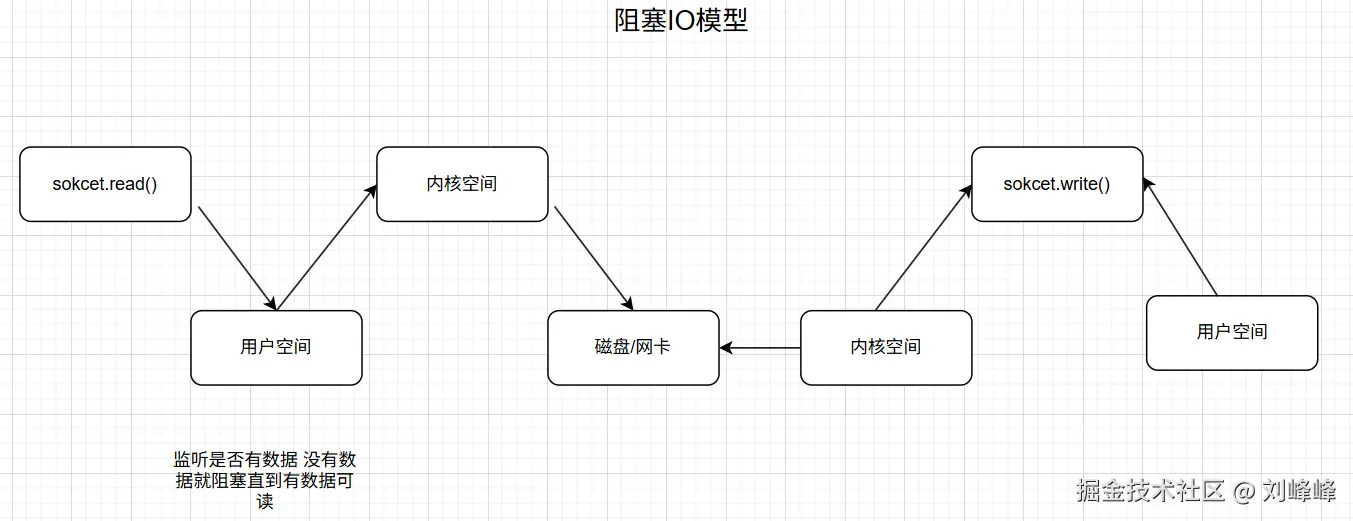
3.1 阻塞 IO(Blocking IO)
流程是:应用发起 IO 请求 → 内核准备数据 → 拷贝数据到用户空间 → 返回
适用场景:低并发、或者对实时性不强的场景;
优点:实现简单,开发理解难度低;
缺点:效率低,一个请求占用一个线程,高并发场景资源浪费严重;
cpp
int main() {
int sockfd = socket(...);
connect(sockfd, ...); // 阻塞
char buffer[1024];
read(sockfd, buffer, 1024); // 阻塞
printf("%s", buffer);
return 0;
}3.2 非阻塞 IO(Non-blocking IO)
同一个线程连续调用 read 操作,每次获取不到数据就返回错误(EAGAIN 或 EWOULDBLOCK),直到内核数据就绪
c
int set_nonblock(int fd) {
int flags = fcntl(fd, F_GETFL, 0);
fcntl(fd, F_SETFL, flags | O_NONBLOCK);
}
int main() {
int sockfd = socket(...);
connect(sockfd, ...); // 非阻塞(需要多次尝试)
set_nonblock(sockfd);
while (1) {
int bytes = read(sockfd, buffer, 1024);
if (bytes == -1) {
if (errno == EAGAIN) continue; // 数据没准备好
} else {
break; // 读取成功,可以处理
}
}
return 0;
}优点 :提升线程使用效率; 缺点:轮询方式浪费CPU资源,必须配和多路复用使用才能有意义
3.3 IO 多路复用
在高并发的环境下,有可能有N个用户同时向应用B发送消息,在这种情况下,如果采用每个请求由一个独立线程处理的模型,系统的线程数将随着并发量的增长而线性增加。当并发量达到一定规模时,过多的线程会导致资源浪费、上下文切换开销剧增,甚至影响系统稳定性
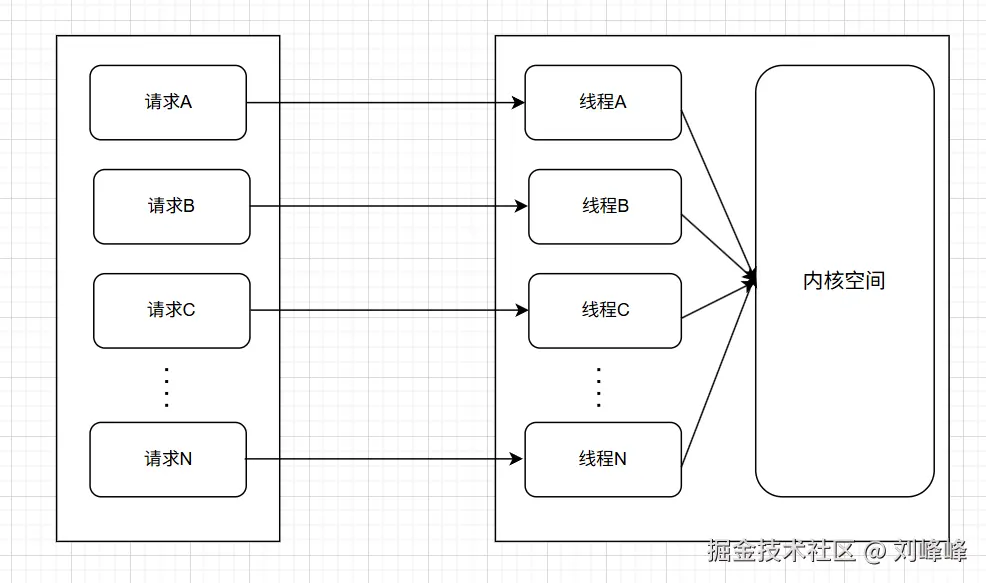 为应对这一问题,可以使用I/O多路复用 机制(如
为应对这一问题,可以使用I/O多路复用 机制(如select、poll或epoll),让一个线程通过系统调用同时监听多个I/O事件的就绪状态。这种模型的核心思想是:通过主动轮询或事件通知机制,监控多个连接的I/O就绪状态,而非为每个连接单独创建线程进行阻塞等待,从而在资源消耗和系统性能之间取得更好的平衡
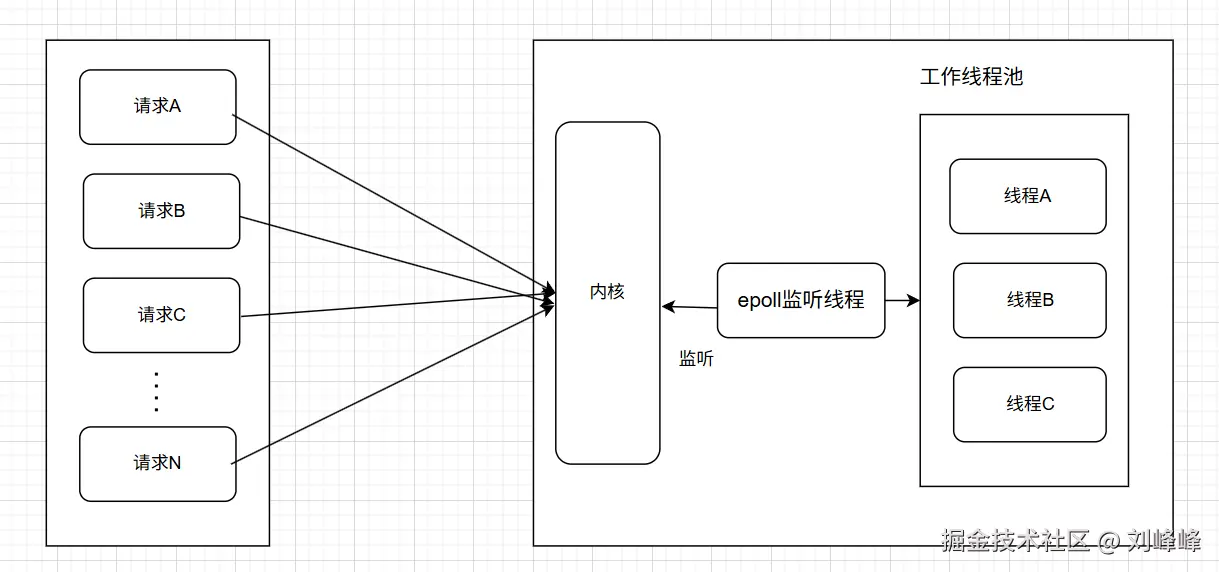
3.3.1 select
select 是最早的多路IO复用接口,用于监控一组文件描述符
c
fd_set read_fds;
FD_ZERO(&read_fds);
FD_SET(sockfd, &read_fds);
struct timeval timeout = { 5, 0 };
int num = select(max_fd + 1, &read_fds, NULL, NULL, &timeout);
if (num > 0) {
for (int i = 0; i < max_fd + 1; ++i) {
if (FD_ISSET(i, &read_fds)) {
read(i, buffer, 1024); // 数据就绪,开始读取
}
}
}优点 :跨平台,简单; 缺点:最大连接数有限(32位1024,64位2048),线程轮询时间复杂度为 O(n),效率低下
3.3.2 poll
poll 的实现逻辑与 select 类似,但它没有最大监听fd数量的限制
c
struct pollfd fds[10];
fds[0].fd = sockfd;
fds[0].events = POLLIN;
int num = poll(fds, 10, 5000); // timeout为毫秒
while (num > 0) {
for (int i = 0; i < 10; ++i) {
if (fds[i].revents & POLLIN) {
read(fds[i].fd, ...);
}
}
}优点 :支持大量fd; 缺点:轮询模型,时间复杂度仍为 O(n)
3.3.3 epoll (Linux平台)
epoll 是Linux中用来提高多连接服务器性能的IO监控机制,最大的特点是 持续监听,无需每次提交fd列表
常用调用如下:
c
int epfd = epoll_create(...);
struct epoll_event event;
event.events = EPOLLIN;
event.data.fd = sockfd;
epoll_ctl(epfd, EPOLL_CTL_ADD, sockfd, &event);
struct epoll_event events[MAX_EVENTS];
int num = epoll_wait(epfd, events, MAX_EVENTS, timeout);
for (int i = 0; i < num; ++i) {
read(events[i].data.fd, ...);
}优点:
- 支持大量连接(无理论限制);
- 性能高,监听事件复杂度为 O(1);
- 采用 mmap 机制减少拷贝和复制的开销;
缺点:
- 是Linux平台特有的实现,不跨平台;
- 事件机制增加了代码复杂度;
LT 与 ET 模式(触发方式)
-
LT 模式(Level Triggered):
- 一次事件就绪后,调用 read() 未读完数据,下次再次触发事件;
- 适用于所有应用,但效率略低;
-
ET 模式(Edge Triggered):
- 仅在数据从未就绪变为就绪的"边缘"上触发一次;
- 要求必须一次读完或设置缓冲区处理机制;
- 更高效,但使用起来更复杂;
两种模式示例:
cpp
// ET模式设置
event.events = EPOLLIN | EPOLLET;惊群问题
在 epoll 模型中,如果多个线程同时监听一个fd,当某个事件就绪时,所有监听该fd的线程都会被唤醒(响应事件)只实际有一个线程能处理该事件,大量线程被唤醒后却迅速失败,这是一个性能浪费的问题,被称为惊群问题
在 epoll 中,Linux官方内核(2.6+)已经优化了该问题,解决了多个线程都可以触发事件的问题
3.4 信号驱动 IO(Signal-driven I/O)
这种模型允许用户在发起IO操作后,注册一个信号处理方式(如SIGIO),当数据准备就绪时内核会发送信号通知,通知用户线程进行数据拷贝
cpp
struct sigaction sa;
sa.sa_flags = SA_SIGINFO;
sa.sa_sigaction = handler;
sigaction(SIGIO, &sa, NULL);
fcntl(sockfd, F_SETOWN, getpid());
int flags = fcntl(sockfd, F_GETFL) | O_ASYNC;
fcntl(sockfd, F_SETFL, flags);当读取时:
cpp
void handler(int sig, siginfo_t *si, void *ucontext) {
int fd = si->si_fd;
char buffer[1024];
read(fd, buffer, 1024); // 仍是阻塞式拷贝
}优点:
- 在读取前不会阻塞主线程;
- 通过回调函数处理数据;
缺点:
- 拷贝数据仍然需要手动完成(阻塞),存在同步行为;
- 在多线程中容易产生 惊群问题(Thundering Herd Problem);
3.5 异步 IO
异步I/O 是真正意义上的"非阻塞"模型。在整个 I/O 过程中,包括内核读取数据和将数据拷贝到用户空间的阶段,都不需要应用程序同步地参与或等待
在之前的四种 I/O 模型(阻塞 I/O、非阻塞 I/O、I/O 多路复用、信号驱动 I/O)中,应用程序在读取数据时,通常需要先主动发送请求,询问内核是否有可读的数据,然后再执行实际的读取操作。这种方式本质上仍需要应用层的介入和协调
而在异步 I/O 模型中,应用程序只需向操作系统内核提交一个 I/O 请求,并继续执行后续任务,无需等待。内核在数据准备就绪后,会主动将数据从内核空间复制到用户空间,并通知应用程序任务完成。这与信号驱动模型不同,信号驱动只是通知应用程序"可以开始读写",而具体的 I/O 操作(包括数据复制)仍由应用程序发起
因此,异步 I/O 模型实现了真正的非阻塞,从请求开始到数据处理完成,全程由内核负责,应用程序完全无须阻塞或轮询,从而在高并发、高吞吐的场景下表现出更优异的性能和更低的资源消耗
五、内核态与用户态切换开销
IO操作在并发环境中是一个关键性能点,每一次系统调用(如read()、write()、select()、epoll_wait()等)都会引发用户态 与内核态之间的态切换(context switch),这在高并发场景下会逐渐成为性能瓶颈。因此,根据系统的并发量、资源限制和请求特性,选择合适的IO模型至关重要
**一般场景下的选择建议:
-
少量Socket连接(如几十或几百个) 在这种情况下,阻塞IO(blocking IO) 是足够且简单的选择。每个连接由一个线程处理,虽然存在阻塞等待,但在连接数不多时不会造成大的性能问题,实现成本低,便于调试和维护
-
中等并发、较低吞吐量或操作具有较高延迟(如网络延迟较高、等待时间长) 使用非阻塞IO(non-blocking IO)配合I/O多路复用(如select、poll) 是一个更好的选择。它允许一个线程同时监听多个文件描述符,避免为每个连接创建线程,从而减少了线程切换和资源消耗。应用程序通过轮询或事件机制发现哪个socket可读或可写,再进行相应的处理
-
超大量连接或高吞吐量场景(如数万甚至数十万并发连接) 此时应使用epoll + 事件驱动模型(event-driven model)。
- epoll 是Linux系统提供的高性能I/O多路复用机制,解决了
select和poll在大规模连接时的线性性能瓶颈,通过内核事件表和边缘触发(edge-triggered)方式提供更高效的事件监控 - 事件驱动编程模型(如基于libevent、libuv或Reactor模式)能够让应用程序在数据准备就绪时通过回调方式高效处理,大大降低线程数和资源开销,适用于像Web服务器、即时通讯、流媒体等对性能和连接数要求极高的系统
- epoll 是Linux系统提供的高性能I/O多路复用机制,解决了
-
真正"零阻塞"的场景(高并发 + 大数据量操作) 在这种场景下,异步IO(AIO) 是终极方案。
- 异步IO是操作系统提供的一种机制(如Linux的
io_submit()/io_getevents()接口),应用只需要发出一个IO请求并立即返回,内核在后台完成读取或写入,并主动将数据复制到用户空间或调用回调函数 - 相较于信号驱动IO,异步IO由内核负责整个过程,包括数据准备和数据复制,应用层完全无需参与数据拷贝阶段,真正做到"非阻塞,免等待,全流程异步"
- 异步IO是操作系统提供的一种机制(如Linux的