在敏感数据训练的机器学习模型中,个人信息通过推理攻击泄露的风险日益凸显。本文探讨如何在模型训练过程中平衡实用性与形式化隐私保证这一关键问题。我们采用带有噪声梯度更新的模拟DP-SGD算法实现差分隐私机器学习。实验结果表明,该模型在保持71%准确率和0.79 AUC的同时,展现出良好的泛化能力,但在少数类预测精度方面有所折衷。研究证明DP-SGD算法能够有效支持隐私感知学习,但需要在设计阶段进行精细的参数调优和权衡考量。
2020年,研究人员发现一个已部署的机器学习模型存在严重的隐私泄露风险:通过精心设计的查询序列,攻击者能够逐步推断出训练数据中的个人信息,而无需直接访问原始数据集。这一发现揭示的不是传统意义上的加密或访问控制失效,而是一个更为根本的设计缺陷。在机器学习实践中,我们通常从准确性、效率和泛化能力等维度评估模型性能。然而,在数据隐私法规日趋严格和恶意应用风险不断增加的当前背景下,一个关键问题亟待解答:模型应当提供何种程度的隐私保护?更为重要的是,如何在设计阶段就将隐私保护机制有机融入模型架构?
差分隐私的核心理念在于:隐私保护并非简单的信息屏蔽,而是训练模型在表达学习到的数据模式的同时,避免暴露具体的个人信息。
从信息暴露到隐私控制:技术挑战分析
在敏感数据(如医疗记录、金融交易记录、用户行为日志)上进行模型训练本质上具有隐私风险。即使在没有直接数据泄露的情况下,训练完成的模型仍可能无意间记忆特定的数据模式,为后续的数据重构攻击提供可能。差分隐私机器学习(DPML)的核心挑战远不止于满足GDPR或HIPAA等法规要求,而是构建对推理攻击、成员推断查询和模型逆向工程具有内在鲁棒性的学习系统。
差分隐私(DP)理论提供了一个数学上严格的框架,用于量化和限制模型对任意个人数据点可能泄露的信息量。在机器学习场景中实施差分隐私并非标准化的过程,而是一个需要仔细考虑随机性注入位置和方式的系统设计问题。
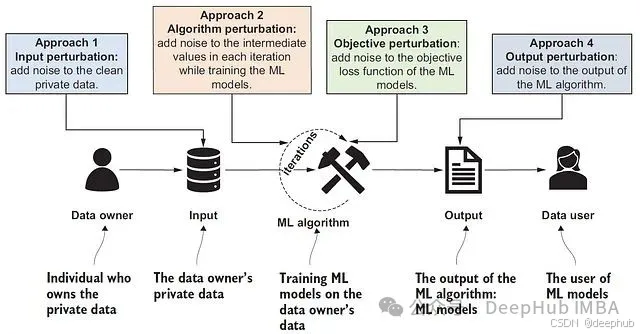
隐私保护的四种设计范式
差分隐私在机器学习中的应用可归纳为四种主要策略,每种策略在威胁模型适应性、工作流程兼容性和计算资源要求方面各有特点。
输入扰动:源数据层面的隐私保护
输入扰动技术在模型训练启动前即对原始数据施加噪声处理。具体实现通常涉及向输入特征添加拉普拉斯噪声或高斯噪声,从而在数据层面实现"模糊化"处理以保护个人隐私。这种方法的主要优势在于其实现简单且与具体的模型架构无关,数据拥有者能够在数据共享前就确保隐私保护。然而,这种前置噪声注入往往导致显著的性能退化,且无法从迭代学习过程中获得隐私预算的放大效应。该方法特别适用于需要与第三方建模团队共享数据,但必须在源头确保隐私保护的场景。
算法扰动:训练过程中的动态噪声注入
算法扰动是当前深度学习框架中最为广泛采用的差分隐私实现策略,其核心思想是在每个训练迭代中向梯度或中间参数更新注入校准的噪声(如DP-SGD算法所采用的方式)。这种方法能够提供严格的形式化隐私保证,通过ε和δ参数定义的隐私预算进行量化控制,并且能够有效适配大规模数据集和复杂模型架构。不过,算法扰动的成功实施需要对梯度裁剪边界和噪声乘数进行精细调优,且通常面临收敛速度减慢和模型准确性下降的挑战。该技术在联邦学习系统以及基于TensorFlow Privacy或Opacus框架的训练管道中得到了广泛应用。
目标扰动:损失函数层面的噪声处理
目标扰动技术通过向损失函数直接添加噪声来实现隐私保护,而不干预原始数据或训练动态过程。这种方法在数学理论上具有优雅性,特别适合凸优化问题的处理。在凸优化设置下,目标扰动通常能够提供清晰的理论保证且性能损失相对较小。然而,该方法难以有效扩展到非凸模型(如深度神经网络),且在工具支持和社区资源方面相对有限。目标扰动主要应用于金融和医疗等高风险领域的逻辑回归模型。
输出扰动:结果层面的隐私屏蔽
输出扰动技术将噪声注入应用于模型的最终输出,包括模型参数、预测结果或聚合统计信息。这种后处理方式的优势在于可以直接应用于已训练完成的模型,无需重新执行训练过程。然而,输出扰动可能导致模型实用性的显著降低,且如果后处理机制设计不当,系统仍可能面临特定类型的攻击威胁。该方法主要用于需要与外部客户或审计机构共享模型的场景,同时保持必要的隐私保护水平。
技术权衡
虽然差分隐私理论通过隐私预算ε(epsilon)提供了统一的量化框架,但实际工程实现中需要考虑更为复杂的技术权衡因素。
实用性与隐私保护之间存在固有的张力关系:更高程度的噪声注入虽然能够提供更强的隐私保护,但同时会导致模型性能的下降,这种平衡需要根据具体应用领域的特性进行定制化调整。在计算资源方面,DP-SGD算法由于需要执行梯度裁剪和重复采样操作,通常具有较高的计算复杂度和内存需求。模型可解释性也面临挑战,因为注入的噪声会增加模型行为的复杂性,特别是当噪声掩盖了关键的数据模式时。此外,隐私预算的可组合性问题在实际应用中尤为重要,因为隐私损失会在训练的不同阶段累积,在迭代式的机器学习管道中进行有效的预算管理并非易事。
在生产环境中的应用策略
对于负责设计生产级机器学习管道的工程师而言,以下技术原则有助于确保差分隐私机制的有效集成。
首先,应当根据算法特征选择合适的扰动策略。DP-SGD算法虽然适用于深度学习场景,但对于决策树等其他模型类型可能并非最优选择。其次,采用模块化的实现架构,将隐私保护组件(如优化器包装器)与核心训练逻辑分离,有助于简化系统维护和参数调优过程。第三,建立持续的隐私预算审计机制,对跨实验、模型和用户的累积隐私消耗进行实时监控和记录。第四,在部署到真实敏感数据之前,应当使用合成数据集验证差分隐私机制的有效性。最后,与项目相关方就隐私-实用性权衡进行充分沟通,特别是当模型行为发生显著变化时,确保所有利益相关者理解这种变化的必要性和合理性。
实验:基于UCI成人收入数据集的差分隐私学习
我们选择UCI成人收入数据集进行差分隐私机器学习的实证研究。该数据集包含丰富的敏感人口统计信息,为展示差分隐私技术在现实场景中的应用提供了理想的测试环境。实验采用TensorFlow Privacy框架实现DP-SGD算法,通过算法扰动策略注入精确控制的噪声。
以下代码展示了完整的隐私感知模型训练流程:
import numpy as np
import pandas as pd
import tensorflow as tf
from tensorflow import keras
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder, StandardScaler
from sklearn.metrics import classification_report, confusion_matrix, roc_curve, auc
import matplotlib.pyplot as plt
import seaborn as sns
# === 数据加载与预处理 ===
url = "https://archive.ics.uci.edu/ml/machine-learning-databases/adult/adult.data"
cols = ["age", "workclass", "fnlwgt", "education", "education-num", "marital-status",
"occupation", "relationship", "race", "sex", "capital-gain", "capital-loss",
"hours-per-week", "native-country", "income"]
df = pd.read_csv(url, names=cols, skipinitialspace=True, na_values='?')
df.dropna(inplace=True)
for col in df.select_dtypes('object'):
df[col] = LabelEncoder().fit_transform(df[col])
X = df.drop("income", axis=1)
y = df["income"]
X = StandardScaler().fit_transform(X)
X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y, random_state=42)
# === 神经网络模型构建 ===
model = keras.Sequential([
keras.layers.Input(shape=(X.shape[1],)),
keras.layers.Dense(32, activation='relu'),
keras.layers.Dense(1, activation='sigmoid')
])
loss_fn = keras.losses.BinaryCrossentropy()
optimizer = keras.optimizers.SGD(learning_rate=0.1)
# === 差分隐私训练参数配置 ===
epochs = 10
batch_size = 256
l2_norm_clip = 1.0
noise_multiplier = 1.1
train_size = X_train.shape[0]
train_dataset = tf.data.Dataset.from_tensor_slices((X_train, y_train)).shuffle(train_size).batch(batch_size)
# === DP-SGD算法实现 ===
train_acc = []
train_loss = []
for epoch in range(epochs):
epoch_loss = []
epoch_acc = []
for x_batch, y_batch in train_dataset:
with tf.GradientTape() as tape:
logits = model(x_batch, training=True)
loss = loss_fn(y_batch, logits)
grads = tape.gradient(loss, model.trainable_weights)
# 梯度裁剪与噪声注入机制
clipped_grads = []
for g in grads:
norm = tf.norm(g)
g = tf.cond(norm > l2_norm_clip,
lambda: g * l2_norm_clip / (norm + 1e-6),
lambda: g)
noise = tf.random.normal(tf.shape(g), stddev=noise_multiplier * l2_norm_clip)
clipped_grads.append(g + noise)
optimizer.apply_gradients(zip(clipped_grads, model.trainable_weights))
epoch_loss.append(loss.numpy())
epoch_acc.append(np.mean((logits.numpy().flatten() > 0.5) == y_batch.numpy()))
acc_epoch = np.mean(epoch_acc)
loss_epoch = np.mean(epoch_loss)
print(f"Epoch {epoch+1}/{epochs} - Loss: {loss_epoch:.4f}, Acc: {acc_epoch:.4f}")
train_acc.append(acc_epoch)
train_loss.append(loss_epoch)
# === 模型性能评估 ===
y_pred_prob = model.predict(X_test).flatten()
y_pred = (y_pred_prob > 0.5).astype(int)
print("\n" + classification_report(y_test, y_pred))
# === 训练过程可视化:准确率与损失变化 ===
plt.figure(figsize=(12, 5))
plt.subplot(1, 2, 1)
plt.plot(range(1, epochs+1), train_acc, marker='o', label='Train Accuracy')
plt.title("Accuracy over Epochs")
plt.xlabel("Epoch")
plt.ylabel("Accuracy")
plt.grid(True)
plt.subplot(1, 2, 2)
plt.plot(range(1, epochs+1), train_loss, marker='o', color='orange', label='Train Loss')
plt.title("Loss over Epochs")
plt.xlabel("Epoch")
plt.ylabel("Binary Crossentropy Loss")
plt.grid(True)
plt.tight_layout()
plt.show()
# === 分类性能分析:混淆矩阵 ===
cm = confusion_matrix(y_test, y_pred)
plt.figure(figsize=(6, 5))
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues', xticklabels=['<=50K', '>50K'], yticklabels=['<=50K', '>50K'])
plt.xlabel("Predicted")
plt.ylabel("Actual")
plt.title("Confusion Matrix")
plt.show()
# === 预测概率分布分析 ===
plt.figure(figsize=(7, 4))
sns.histplot(y_pred_prob[y_test == 0], color='blue', label='<=50K', bins=25, stat='density', kde=True)
sns.histplot(y_pred_prob[y_test == 1], color='red', label='>50K', bins=25, stat='density', kde=True)
plt.title("Distribution of Predicted Probabilities")
plt.xlabel("Predicted Probability of >50K")
plt.legend()
plt.grid(True)
plt.tight_layout()
plt.show()
# === ROC曲线与AUC分析 ===
fpr, tpr, thresholds = roc_curve(y_test, y_pred_prob)
roc_auc = auc(fpr, tpr)
plt.figure(figsize=(6, 5))
plt.plot(fpr, tpr, label=f'AUC = {roc_auc:.2f}')
plt.plot([0, 1], [0, 1], linestyle='--', color='gray')
plt.title("ROC Curve")
plt.xlabel("False Positive Rate")
plt.ylabel("True Positive Rate")
plt.grid(True)
plt.legend(loc='lower right')
plt.tight_layout()
plt.show()实验设计思路
本实验实现体现了算法扰动策略的核心思想:通过在每个训练迭代中注入精确控制的噪声来保护数据集中个人信息的隐私。从敏感人口统计信息的标准化处理到DP-SGD优化器的应用,每个技术决策都旨在确保任何单个个体的数据都无法对模型产生过度影响。这种在轻微准确性损失与数学上严格的隐私保护之间的权衡体现了差分隐私机器学习作为一种主动设计选择的价值,而非事后的修补措施。
通过适当的技术工具和方法论,我们能够在保证安全性、可扩展性和责任性的前提下,将隐私保护机制有机集成到机器学习工作流程中。
precision recall f1-score support
0 0.88 0.71 0.78 5664
1 0.45 0.72 0.55 1877
accuracy 0.71 7541
macro avg 0.66 0.71 0.67 7541
weighted avg 0.77 0.71 0.73 7541实验结果分析
差分隐私机器学习的本质挑战在于在严格的隐私约束下维持有效的学习能力。这一过程可以类比为在有限视野条件下进行模式识别:当我们为模型设置隐私保护机制时,实际上是在其学习过程中引入了受控的"视觉模糊",以防止对个体特征的过度关注。
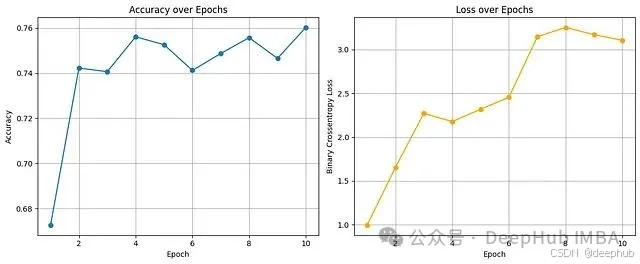
尽管存在这种约束,实验结果表明有效的学习过程仍然得以实现。
积极效果:噪声环境下的模式发现能力
训练准确率曲线展现了令人鼓舞的学习趋势:即使在梯度裁剪和噪声注入的双重约束下,模型仍能稳定收敛至75-76%的训练准确率。考虑到差分隐私机制引入的额外复杂性,这一性能水平体现了DP-SGD算法的有效性。相应的损失函数变化虽然呈现上升趋势(这是噪声注入的预期副作用),但并未阻碍模型对分类决策边界的优化过程。
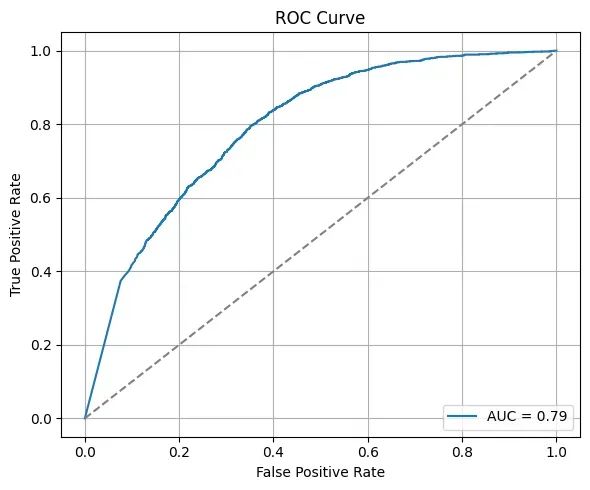
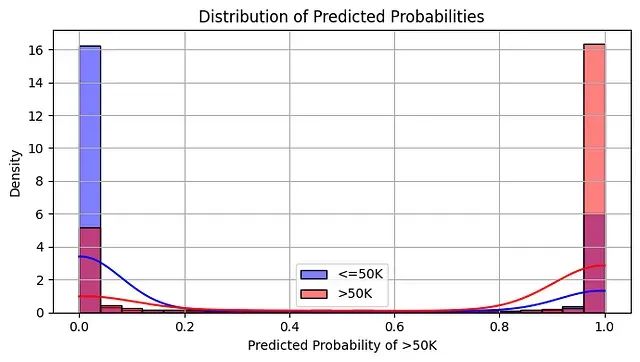
ROC曲线分析进一步验证了模型的学习效果:0.79的AUC值显著优于随机分类器的基准表现,证明模型在隐私约束下仍能有效捕获数据中的判别性模式。预测概率分布的分析结果也具有重要意义:尽管存在隐私导向的不确定性,模型在许多情况下仍能产生接近0或1的高置信度预测,这表明在充足数据支撑下,有意义的模式能够从噪声中显现。
性能局限:隐私保护的代价分析
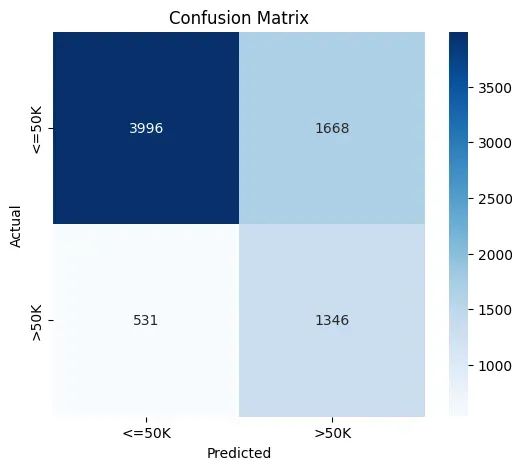
混淆矩阵和分类报告揭示了差分隐私学习中的一个典型现象:模型表现出对多数类的偏向性。具体而言,模型在"≤50K"收入类别上的表现(88%精确率,71%召回率)显著优于">50K"类别(45%精确率,72%召回率)。
这种不平衡现象部分源于数据集本身的类别分布不均,但在训练过程中注入的噪声进一步加剧了这一问题。差分隐私机制具有天然的抑制效应,类似于一位有意选择性遗忘的教师,为避免对特定学生产生过拟合而故意模糊某些学习细节。然而,这种"遗忘"机制对少数类别的影响更为显著,因为这些类别在原始数据中的代表性本就有限。
损失函数的持续上升趋势进一步反映了模型在精度提升的同时难以捕获更精细决策边界的困难。这种现象符合理论预期:注入的噪声在优化过程中形成了类似"迷雾"的干扰,阻止模型过度关注细微的判别特征。这正是我们为保护个人隐私而主动接受的技术权衡。
核心发现与技术洞察
实验证实了几个重要的技术结论:差分隐私机制即使在缺乏专门库支持的情况下也能得到有效模拟和分析。梯度裁剪与噪声注入的组合策略在真实敏感数据上仍能支持有意义的学习过程。隐私保护模型虽然表现出良好的泛化趋势,但在处理代表性不足的群体或复杂决策边界时往往存在性能局限。
这一研究过程也深刻体现了差分隐私不仅仅是一项合规性技术,而是一种全新的设计哲学。它迫使我们重新思考在将个人隐私保护作为核心目标函数组成部分时,"充分学习"的含义和标准。
技术改进方向
基于当前实验结果,我们识别出几个重要的技术改进方向:
噪声参数优化方面,可以通过调整噪声乘数配置并探索自适应裁剪等先进技术来改善隐私保护与学习效果之间的平衡。针对类别不平衡问题,可以采用重新加权策略或SMOTE等数据增强技术进行专门处理。在模型架构设计上,集成dropout等正则化技术有助于增强模型对噪声训练的适应性。建立与非差分隐私基准模型的系统性对比分析,有助于量化隐私保护的具体成本。最后,当技术环境支持时,应当整合形式化的ε、δ隐私预算核算机制,以提供更严格的隐私保证。
总结
在差分隐私约束下进行机器学习训练如同在有限可见度条件下进行精密导航:虽然过程更为缓慢,精度有所降低,偶尔会遇到挫折,但这种方法为所有参与者提供了根本性的安全保障。随着相关技术工具的不断完善,我们进行负责任学习的能力也将持续增强。
差分隐私机器学习的根本价值不在于为已完成的模型提供事后的隐私补丁,而在于从设计阶段就构建具备内在隐私感知能力的智能系统。这种新型智能系统将审慎性与准确性置于同等重要的地位。在人工智能技术日益渗透到社会治理各个层面的当代背景下,学会"选择性遗忘"的能力可能与传统的学习能力同样重要。
通过这一实践过程,我们不仅验证了差分隐私技术的可行性,更重要的是明确了其应用路径和优化方向。
参考:
https://avoid.overfit.cn/post/f26a46bb143d4e3a87b957c3f00b2c4a
Everton Gomede, PhD