前言
selenium 库是一种用于 Web 应用程序测试的工具,它可以驱动浏览器执行特定操作,自动按照脚本代码做出单击、输入、打开、验证等操作,支持的浏览器包括 IE、Firefox、Safari、Chrome、Opera 等。
与 requests 库不同的是,selenium 库是基于浏览器的驱动程序来驱动浏览器执行操作的。且浏览器可以实现网页源代码的渲染,因此通过 selenium 库还可以轻松获取网页中渲染后的数据信息。
一、使用 selenium 库前的准备
1.了解 selenium 库驱动浏览器的原理
浏览器是在浏览器内核基础之上开发而成的,浏览器内核主要负责对网页语法进行解释并渲染(显示)网页。例如 Edge 浏览器使用 Chromium 内核**,**而 QQ 浏览器使用 IE 内核,Safari 浏览器使用 Webkit 内核。

虽然浏览器内核可以被 selenium 库驱动,但还是需要安装对应版本的浏览器内核驱动程序,以便于控制 Web 浏览器的行为。每个浏览器都有一个特定的用于支持浏览器运行的 WebDriver,被称为驱动程序(可以进入 selenium 库的官网进行下载,如果下载失败或无法匹配版本,还可以尝试下面介绍的相关方法)。
2.安装 WebDriver
以Edge浏览器为例,开始介绍安装浏览器内核驱动程序 WebDriver 的方法。
在设置中找到"关于 Microsoft Edge",查看当前Edge浏览器版本,进入此网址:Microsoft Edge WebDriver |Microsoft Edge 开发人员,找到对应版本号的 WebDriver。有的可能会找不到版本号完全相同的 WebDriver,但也可以使用与浏览器版本最为接近的版本。

下载完成后还需要解压相应文件,并将解压后的文件中的 msedgedriver.exe 文件移动到 Python 安装目录路径下的 Scripts 文件夹中。
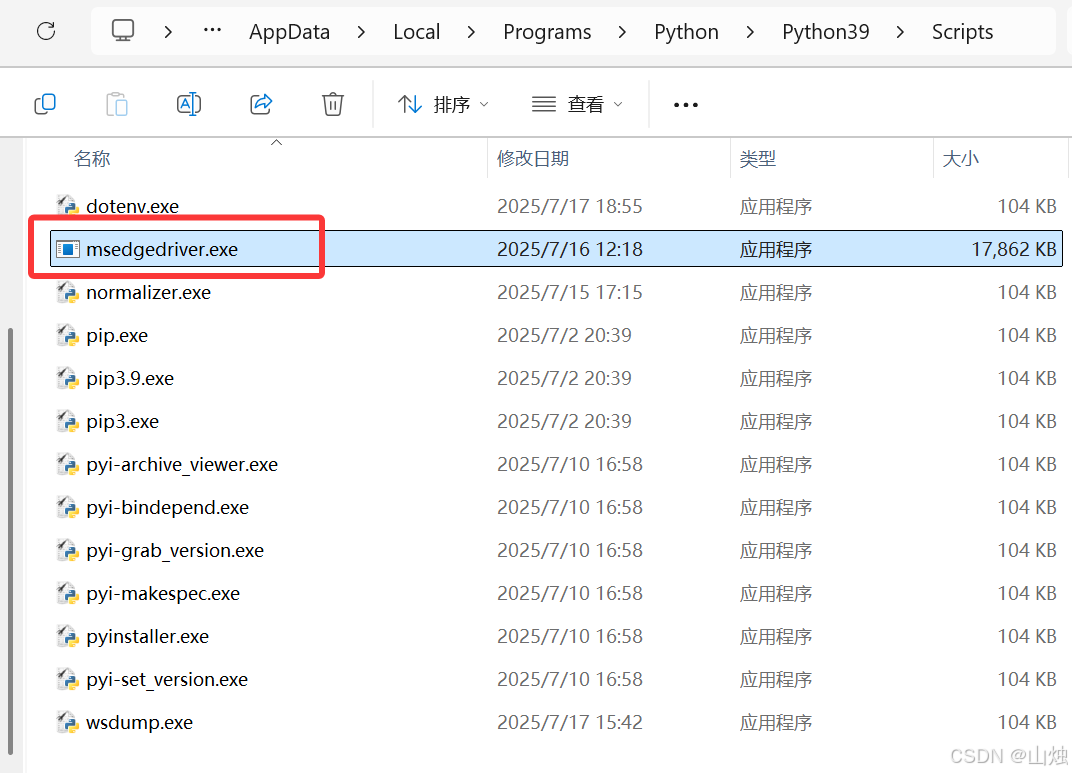
3.安装 selenium 库
在命令提示符窗口或终端中执行以下命令:
bash
pip install selenium二、驱动浏览器
selenium 库支持的浏览器包括 Chrome、IE 7 - 11、Firefox、Safari、Opera Edge、HtmlUnit、PhantomJS 等,几乎覆盖了当前计算机端和手机端的所有类型的浏览器。在 selenium 库源代码文件下的 webdriver 中可查看所有支持的浏览器类型,如图所示。
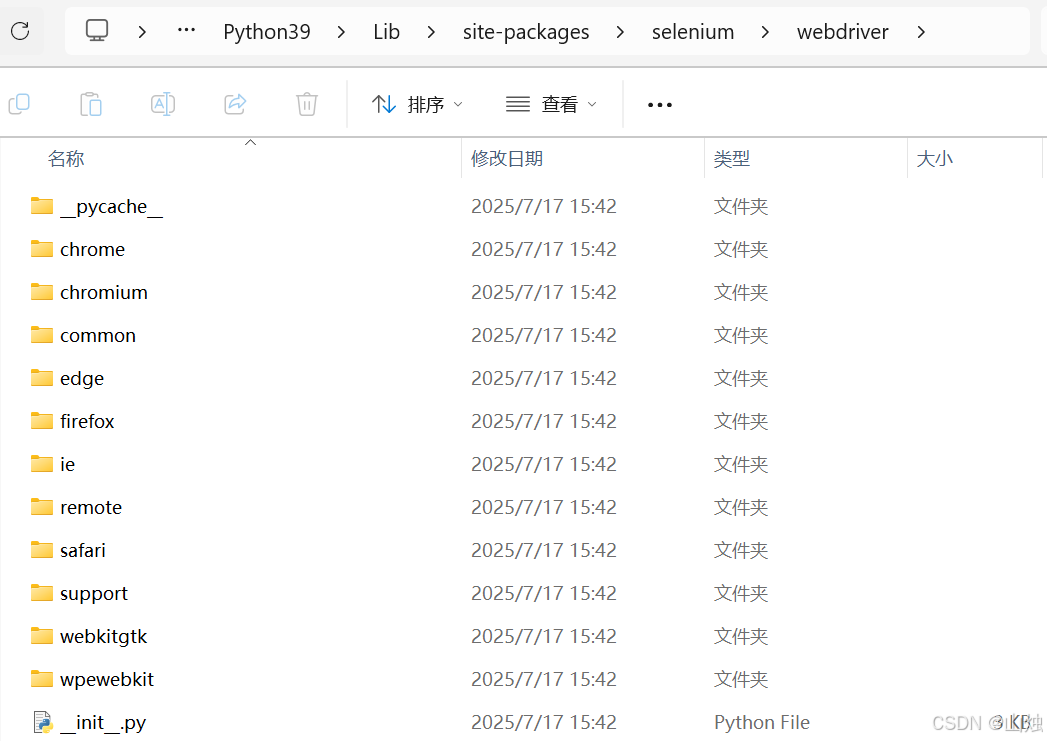
webdriver 的使用形式如下:
bash
webdriver.浏览器类型名()浏览器类型名与图中对应浏览器类型的文件夹名称相同。例如驱动 Edge 浏览器的使用方法为webdriver.Edge(),驱动 Opera 浏览器的使用方法为webdriver.opera()。图所示的每个文件夹中都存在一个webdriver.py文件,当调用webdriver.Edge()时,会默认调用edge\webdriver.py文件中的类 WebDriver。webdriver.Edge()的使用形式如下:
python
webdriver.Edge(executable_path = "msedgedriver", port = 0, options = None)- 功能:创建一个新的 Edge 浏览器驱动程序。
- 参数 executable_path:表示浏览器的驱动路径,默认为环境变量中的 path,通常计算机中可能存在多个浏览器软件,当没有在环境变量中设置浏览器 path 时,可以使用参数 options。
- 参数 port:表明希望服务运行的端口,如果保留为 0,驱动程序将会找到一个空闲端口。
- 参数 options :表示由类 Options(位于
selenium\webdriver\edge\options.py)创建的对象,用于实现浏览器的绑定。
示例代码(驱动Edge浏览器):
python
from selenium import webdriver
from selenium.webdriver.edge.options import Options
edge_options = Options()
edge_options.binary_location = r"C:\Program Files (x86)\Microsoft\Edge\Application\msedge.exe"
driver = webdriver.Edge(options = edge_options)第 3、4 行代码使用类 Options 创建了一个对象 edge_options,使用 binary_location () 方法绑定了浏览器。第 5 行代码使用 webdriver.Edge() 设置 options 参数值为绑定 Edge 浏览器的对象 edge_options。
执行代码后将会自动打开 Edge 浏览器,实现驱动浏览器的第一步。
三、加载网页
接下来介绍两种常用的加载浏览器网页的方法。
1.get() 方法
get() 方法用于打开指定的网页。其使用形式如下:
python
get(url)功能:在当前浏览器会话中加载 url 指向的网页。
示例代码(加载人民邮电出版社官网中的期刊页):
python
from selenium import webdriver
from selenium.webdriver.edge.options import Options
edge_options = Options()
edge_options.binary_location = r"C:\Program Files (x86)\Microsoft\Edge\Application\msedge.exe"
driver = webdriver.Edge(options = edge_options)
driver.get('https://www.ptpress.com.cn/periodical')运行结果:
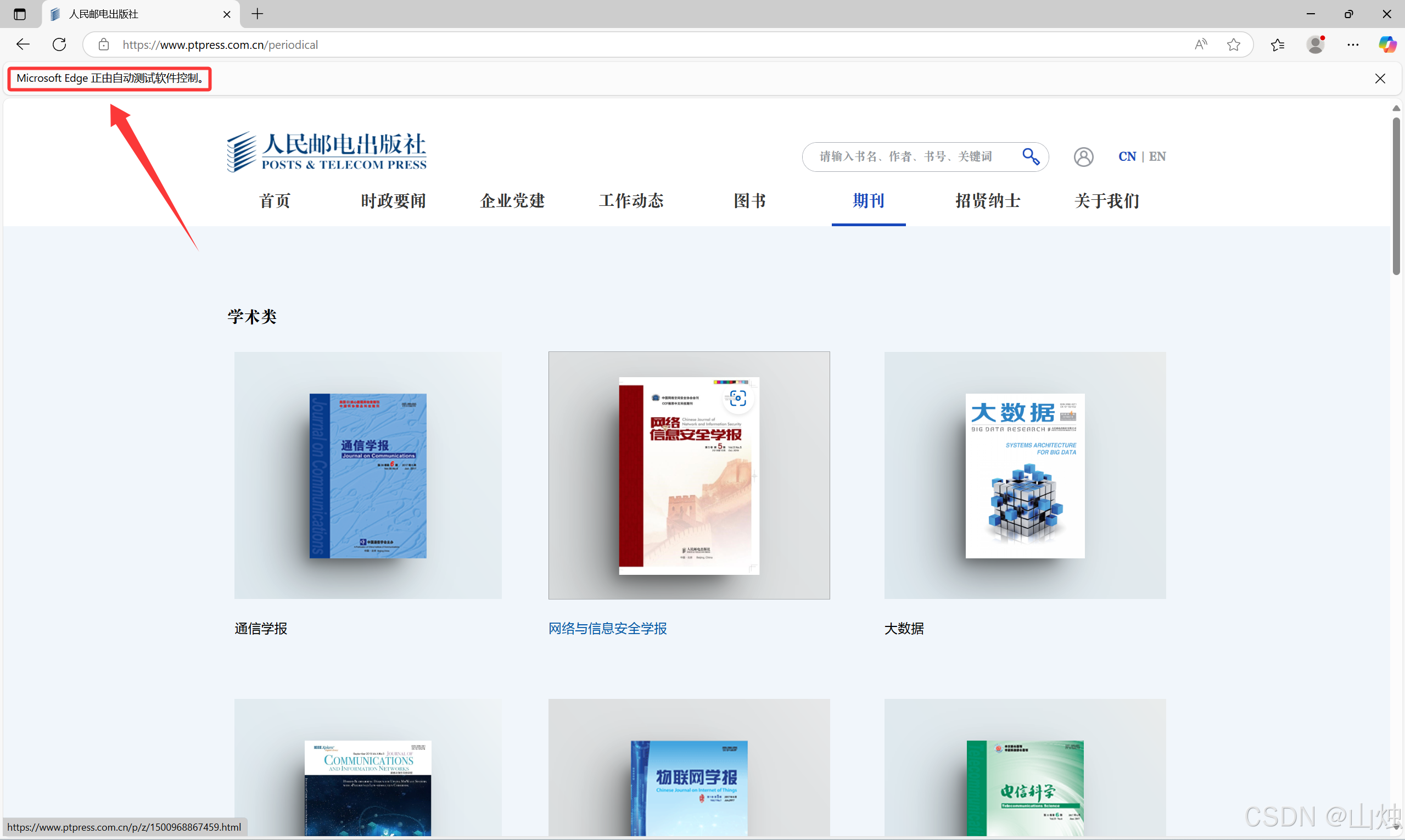
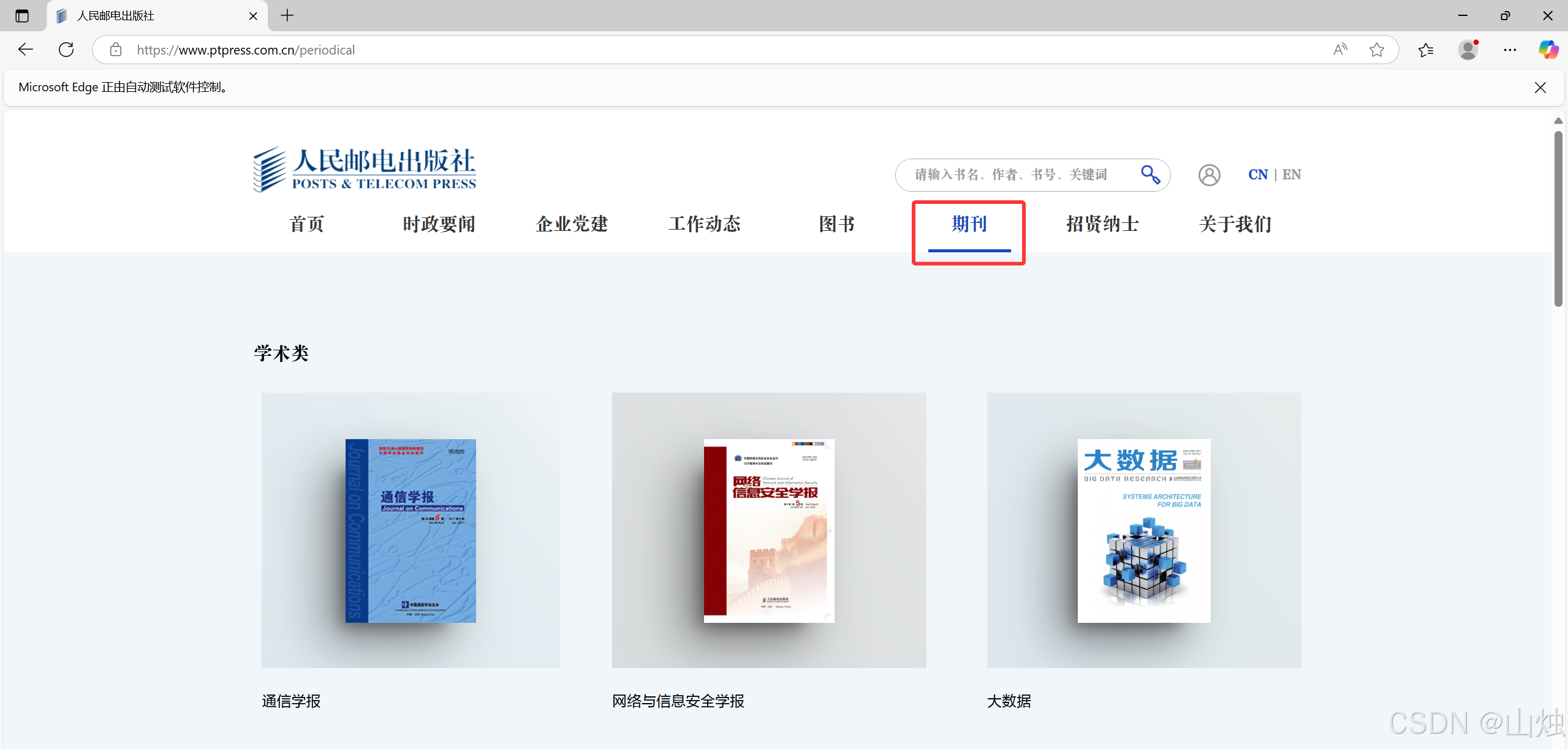
第 6 行代码使用 get() 方法加载人民邮电出版社官网的期刊页,执行代码后将会自动启动 Edge 浏览器并加载出相应网页,结果如图所示。
2.execute_script() 方法
execute_script() 方法用于打开多个标签页,即在同一浏览器中打开多个网页。其使用形式如下:
python
execute_script(script, *args)功能:打开标签页,同步执行当前页面中的 JavaScript 脚本。JavaScript 是网页中的一种编程语言。
参数 script :表示将要执行的脚本内容,数据类型为字符串类型。使用 JavaScript 语言实现打开一个新标签页的使用形式为"window.open('网站url','_blank')" 。
示例代码(打开多个标签页):
python
from selenium import webdriver
from selenium.webdriver.edge.options import Options
edge_options = Options()
edge_options.binary_location = r"C:\Program Files (x86)\Microsoft\Edge\Application\msedge.exe"
driver = webdriver.Edge(options = edge_options)
driver.get('https://www.ptpress.com.cn/')
driver.execute_script("window.open('https://www.ptpress.com.cn/login','_blank');")
driver.execute_script("window.open('https://www.shuyishe.com/','_blank');")
driver.execute_script("window.open('https://www.shuyishe.com/course','_blank');")运行结果:
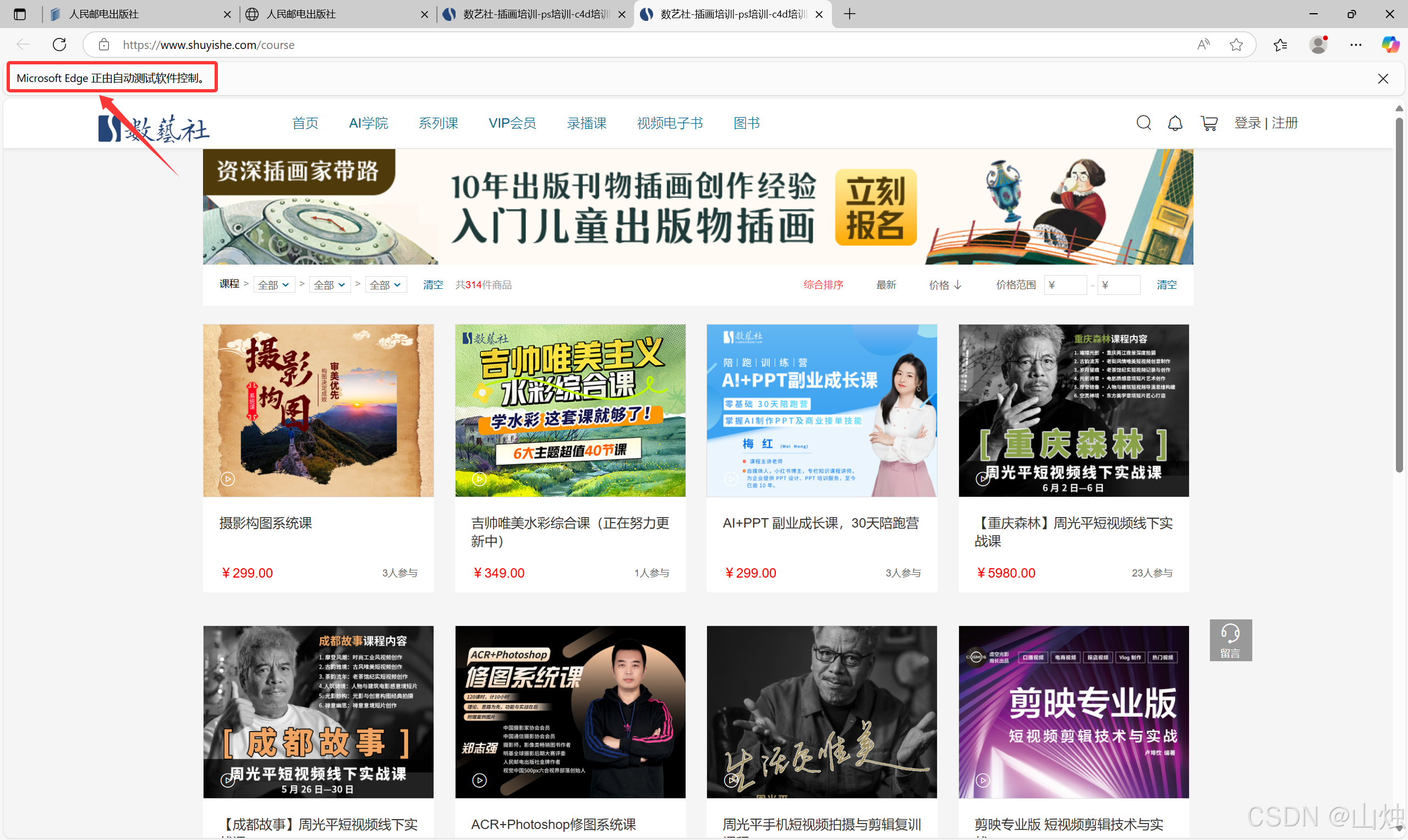
第 7~9 行代码使用execute_script()方法执行括号中的 JavaScript 脚本,打开的新标签页分别为人民邮电出版社登录页面、数艺设的主页、数艺设的课程页面,如图所示。
四、获取渲染后的网页代码
通过get()方法获取浏览器中的网页资源后,浏览器将自动渲染网页源代码内容,并生成渲染后的内容,这时使用page_source()方法即可获取渲染后的网页代码。
示例代码:
python
from selenium import webdriver
from selenium.webdriver.edge.options import Options
edge_options = Options()
edge_options.binary_location = r"C:\Program Files (x86)\Microsoft\Edge\Application\msedge.exe"
driver = webdriver.Edge(options = edge_options)
driver.get('https://www.ptpress.com.cn/')
print(driver.page_source)运行结果:
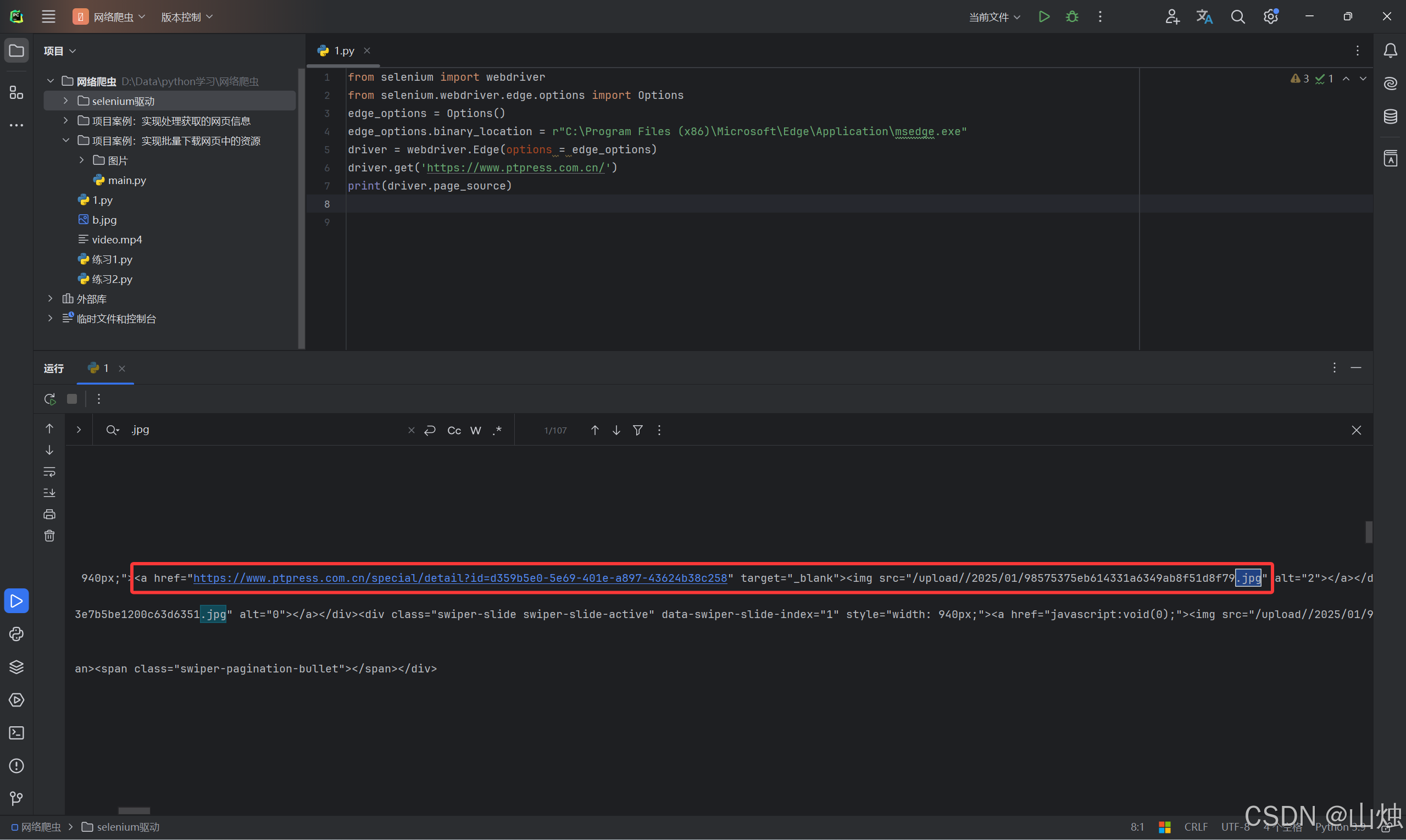
第 7 行代码使用driver对象中的page_source()方法获取被get()方法获取到的渲染后的网页源代码。执行代码后的输出结果如图所示,图中标注框处的内容即网页中的图片 url。
五、获取和操作网页元素
1.获取网页中的指定元素
WebDriver对象提供了大量用于获取网页指定元素的方法。
| 方法 | 功能 |
|---|---|
| tag_name() | 获取元素的名称 |
| text() | 获取元素的文本内容 |
| click() | 单击此元素 |
| submit() | 提交表单 |
| send_keys() | 模拟输入信息 |
| size() | 获取元素的尺寸 |
2.在元素中输入信息
send_keys () 方法可以实现在元素中输入信息,例如在窗口标签中输入信息。其使用形式如下:
python
send_keys(*value)参数 value:表示需要输入的字符串信息。
示例代码(在人民邮电出版社官网的搜索框中输入 "Python"):
python
from selenium import webdriver
from selenium.webdriver.edge.options import Options
from selenium.webdriver.common.by import By
edge_options = Options()
edge_options.binary_location = r"C:\Program Files (x86)\Microsoft\Edge\Application\msedge.exe"
driver = webdriver.Edge(options = edge_options)
driver.get('https://www.ptpress.com.cn/')
driver.find_element(by=By.TAG_NAME,value='input').send_keys('Python')
第 8 行代码使用 find_element() 方法找到标签名为 input 的元素(通过网页源代码可知搜索框的标签名为 input)。获取到标签后使用 send_keys () 方法实现在搜索框内输入字符串 "Python"。代码执行结束后的网页效果如图所示。
实现在搜索框中输入信息的代码程序后,还可以模拟用户的按键操作,其使用方法为在字符串后面继续增加按键转义字符串信息。
示例代码:
python
from selenium import webdriver
from selenium.webdriver.edge.options import Options
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
edge_options = Options()
edge_options.binary_location = r"C:\Program Files (x86)\Microsoft\Edge\Application\msedge.exe"
driver = webdriver.Edge(options = edge_options)
driver.get('https://www.ptpress.com.cn/')
driver.find_element(by=By.TAG_NAME,value='input').send_keys("Python"+Keys.RETURN)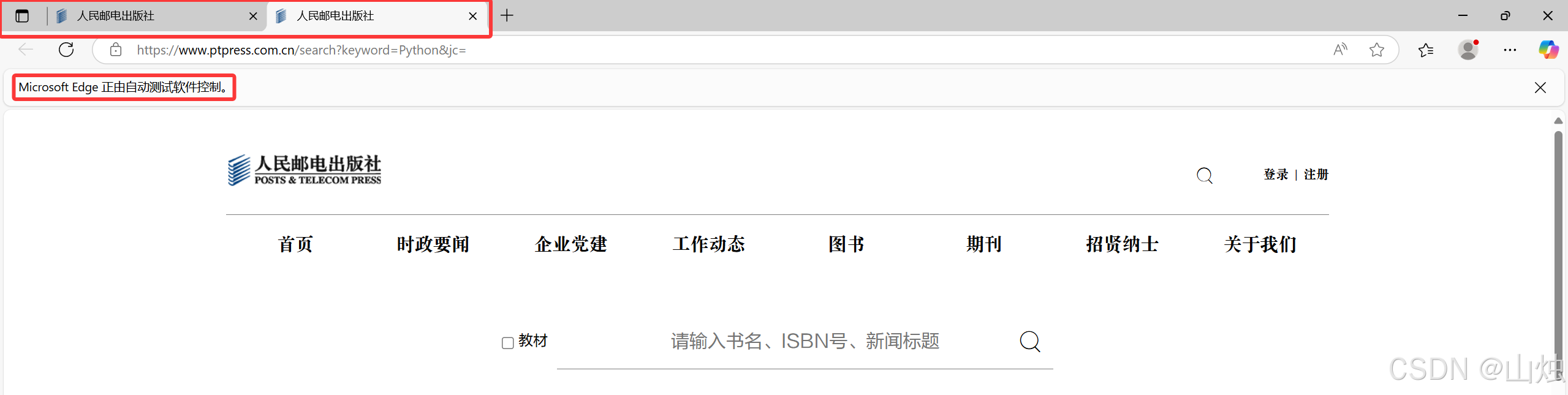
该示例代码在上一示例代码的基础上只对第 8 行代码做了修改。第 8 行代码在 send_keys () 方法中增加了 Keys.RETURN,Keys.RETURN 表示按 Enter 键。该值来源于第 3 行代码导入的类 Keys,类 Keys 中定义了大部分按键的转义字符串。下面展示了 Selenium 库官方源代码中对类 Keys 的定义,根据定义可知 Keys.RETURN 的值为转义字符串 '\ue006',即 send_keys () 中写入的字符串信息为 "Python\ue006"。
执行代码后将会自动在人民邮电出版社官网的搜索框输入 Python,并按 Enter 键实现提交。
类Keys的定义:
python
class Keys:
"""Set of special keys codes."""
NULL = "\ue000"
CANCEL = "\ue001" # ^break
HELP = "\ue002"
BACKSPACE = "\ue003"
BACK_SPACE = BACKSPACE
TAB = "\ue004"
CLEAR = "\ue005"
RETURN = "\ue006"
ENTER = "\ue007"
SHIFT = "\ue008"
LEFT_SHIFT = SHIFT
RIGHT_SHIFT = "\ue050"
CONTROL = "\ue009"
LEFT_CONTROL = CONTROL
RIGHT_CONTROL = "\ue051"
ALT = "\ue00a"
LEFT_ALT = ALT
RIGHT_ALT = "\ue052"
PAUSE = "\ue00b"
ESCAPE = "\ue00c"
SPACE = "\ue00d"
PAGE_UP = "\ue00e"
PAGE_DOWN = "\ue00f"
END = "\ue010"
HOME = "\ue011"
LEFT = "\ue012"
ARROW_LEFT = LEFT
UP = "\ue013"
ARROW_UP = UP
RIGHT = "\ue014"
ARROW_RIGHT = RIGHT
DOWN = "\ue015"
ARROW_DOWN = DOWN
INSERT = "\ue016"
DELETE = "\ue017"
SEMICOLON = "\ue018"
EQUALS = "\ue019"
NUMPAD0 = "\ue01a" # number pad keys
NUMPAD1 = "\ue01b"
NUMPAD2 = "\ue01c"
NUMPAD3 = "\ue01d"
NUMPAD4 = "\ue01e"
NUMPAD5 = "\ue01f"
NUMPAD6 = "\ue020"
NUMPAD7 = "\ue021"
NUMPAD8 = "\ue022"
NUMPAD9 = "\ue023"
MULTIPLY = "\ue024"
ADD = "\ue025"
SEPARATOR = "\ue026"
SUBTRACT = "\ue027"
DECIMAL = "\ue028"
DIVIDE = "\ue029"
F1 = "\ue031" # function keys
F2 = "\ue032"
F3 = "\ue033"
F4 = "\ue034"
F5 = "\ue035"
F6 = "\ue036"
F7 = "\ue037"
F8 = "\ue038"
F9 = "\ue039"
F10 = "\ue03a"
F11 = "\ue03b"
F12 = "\ue03c"
META = "\ue03d"
LEFT_META = META
RIGHT_META = "\ue053"
COMMAND = "\ue03d"
LEFT_COMMAND = COMMAND
ZENKAKU_HANKAKU = "\ue040"
# Extended macOS keys
LEFT_OPTION = LEFT_ALT
RIGHT_OPTION = RIGHT_ALT六、其他操作
1.模拟单击
获取网页元素后可以使用 click () 方法实现单击该元素,即模拟单击网页中的某个元素所在的位置。
示例代码(单击人民邮电出版社官网中的 "图书"):
python
from selenium import webdriver
from selenium.webdriver.edge.options import Options
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
edge_options = Options()
edge_options.binary_location = r"C:\Program Files (x86)\Microsoft\Edge\Application\msedge.exe"
driver = webdriver.Edge(options = edge_options)
driver.get('https://www.ptpress.com.cn/periodical')
elements = driver.find_elements(by=By.CLASS_NAME, value='item')
i = 0
for element in elements:
print(i,'个',element.text)
i += 1
elements[4].click()
input()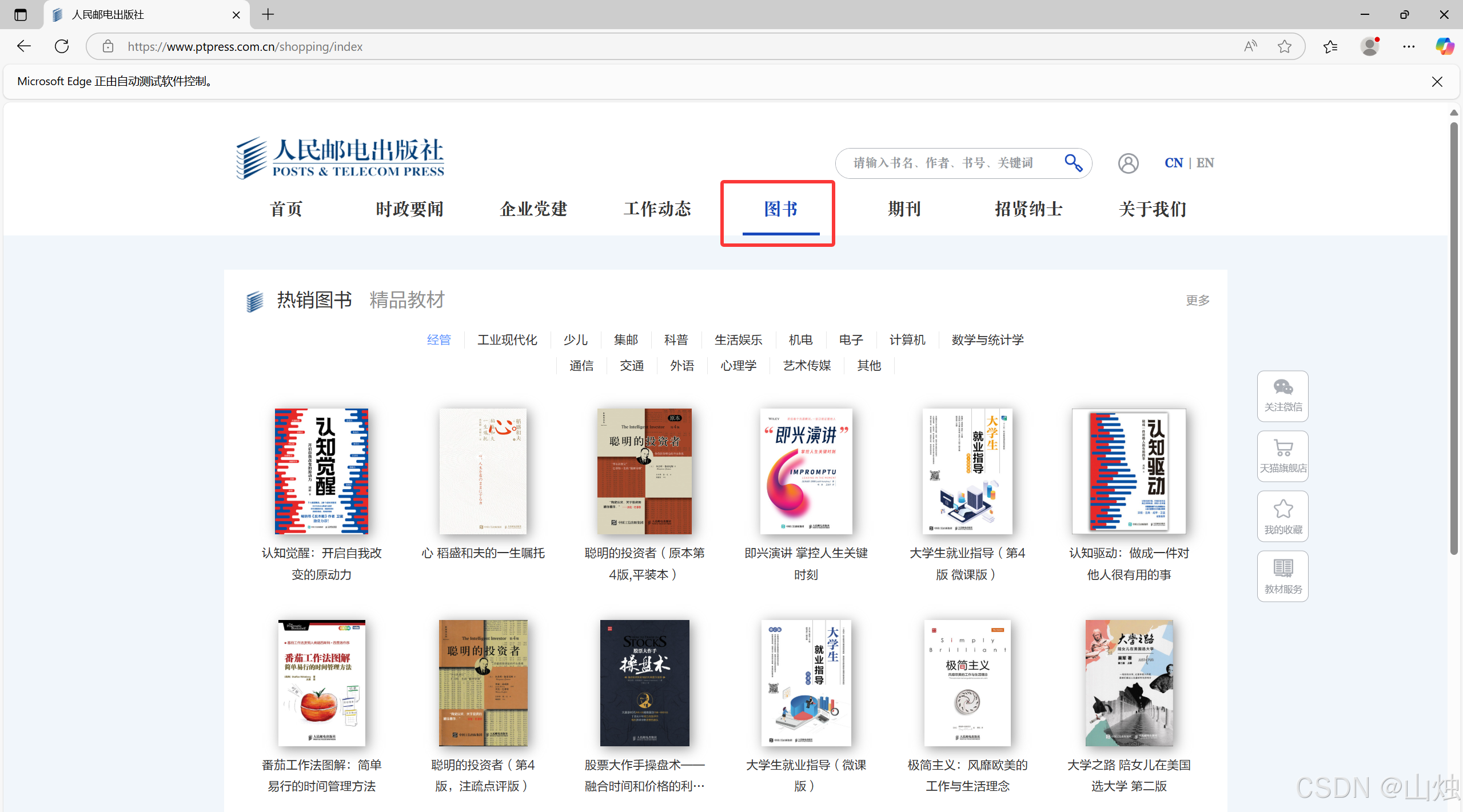
2.WebDriver 对象中的方法
几种常见的对浏览器操作的方法:
| 方法 | 功能 |
|---|---|
| back() | 返回到上一个页面 |
| forward() | 前进到下一个页面 |
| refresh() | 刷新当前页面 |
| quit() | 关闭当前浏览器 |
| close() | 关闭当前标签页 |
3.不启动浏览器也能获取网页资源
在通过代码获取网页中的资源时,往往并不需要启动浏览器,因为用户需要获取的是处理后的结果,而不是处理的过程。因此在驱动浏览器时,可以设置无窗口模式,即驱动浏览器后并不会打开浏览器窗口,而是将网页代码在内存中处理,类 Options 中的 add_argument () 方法即可实现在不启动浏览器的情况下获取网页资源。其使用形式如下(写入参数 '--headless' 即表明不启动浏览器窗口):
python
options().add_argument('--headless')
python
from selenium import webdriver
from selenium.webdriver.edge.options import Options
from selenium.webdriver.common.by import By
edge_options = Options()
edge_options.add_argument('--headless')
edge_options.binary_location = r"C:\Program Files (x86)\Microsoft\Edge\Application\msedge.exe"
driver = webdriver.Edge(options = edge_options)
driver.get('https://www.ptpress.com.cn/')
elements = driver.find_elements(by=By.TAG_NAME,value='a')
for element in elements:
print(element.text)
第 4 行代码设置浏览器启动无窗口模式。因此执行代码后虽然不会显示浏览器,但浏览器仍然会在内存中进行数据处理。第 9~10 行代码获取人民邮电出版社官网中所有标签名为 a 的文本内容。