一、项目需求分析
某电商平台需实现广告实时点击分析系统,核心需求为实时统计以下内容的Top10:
- 各个广告的点击量
- 各个省份的广告点击量
- 各个城市的广告点击量
通过实时掌握广告投放效果,为广告投放策略调整和大规模投入提供依据,以实现公司经济回报最大化。
二、数据流程设计
数据流程如下:
- 服务器产生的广告点击日志,由Flume进行实时采集
- Flume将采集到的数据写入Kafka消息队列
- Spark Streaming从Kafka消费数据并进行实时计算
- 计算结果一方面入库到MySQL数据库,另一方面通过连接Davinci进行BI分析,实现数据可视化展示
三、开发步骤
3.1 数据准备
-
数据集文件名为ad.log,包含电商平台广告点击日志,数据格式为:时间、省份ID、城市ID、用户ID、广告ID。
-
样本数据示例:
1516609143867 6 7 64 16 1516609143869 9 4 75 18 1516609143869 1 7 87 12
3.2 业务建表
- 在MySQL节点创建advertise数据库:
create database advertise; - 创建相关数据表:
-
adversisecount表(存储广告点击量)
sqlCREATE TABLE adversisecount( adname VARCHAR(20) NOT NULL, COUNT INT(11) NOT NULL ); -
provincecount表(存储省份广告点击量)
sqlcreate table provincecount( province varchar(20) not null, count int(11) not null ); -
citycount表(存储城市广告点击量)
sqlCREATE TABLE citycount( city VARCHAR(20) NOT NULL, COUNT INT(11) NOT NULL ); -
执行advertiseinfo.sql、distinctcode.sql脚本
-
sql
CREATE DATABASE /*!32312 IF NOT EXISTS*/`advertise` /*!40100 DEFAULT CHARACTER SET utf8 */;
USE `advertise`;
/*Table structure for table `advertiseinfo` */
DROP TABLE IF EXISTS `advertiseinfo`;
CREATE TABLE `advertiseinfo` (
`aid` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(50) DEFAULT NULL,
PRIMARY KEY (`aid`)
) ENGINE=InnoDB AUTO_INCREMENT=21 DEFAULT CHARSET=utf8;
/*Data for the table `advertiseinfo` */
insert into `advertiseinfo`(`aid`,`name`) values (1,'论道云原生,且看大数据江湖'),(2,'首届「奇想奖」元宇宙征文大赛'),(3,'你真的懂Web渗透测试码?'),(4,'运维工程师,如何从每月3k涨到每月3w?'),(5,'Python人工智能全程套餐课'),(6,'Java入门到进阶一卡通'),(7,'王者技术体系课立即抢购'),(8,'报考C认证得超值学习大礼包'),(9,'开魔盒赢豪礼'),(10,'超级实习生等你来拿'),(11,'Python机器学习'),(12,'2022年,为什么一定要学网络安全'),(13,'月薪2万,为啥找不到运维人才'),(14,'k8s从蒙圈到熟练:搞懂技术就靠他了!'),(15,'重要通知:网工想涨工资,可以考个证'),(16,'Java不懂这些核心技能,还想去大厂'),(17,'你真的懂网络安全码?'),(18,'数据分析师掌握这4点,大厂抢着要'),(19,'做运维,为什么Linux必须精通'),(20,'云计算正在\"杀死\"网工运维');
sql
CREATE DATABASE /*!32312 IF NOT EXISTS*/`advertise` /*!40100 DEFAULT CHARACTER SET utf8 */;
USE `advertise`;
/*Table structure for table `distinctcode` */
DROP TABLE IF EXISTS `distinctcode`;
CREATE TABLE `distinctcode` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`province` varchar(50) CHARACTER SET utf8 DEFAULT NULL,
`provinceCode` varchar(20) CHARACTER SET utf8 NOT NULL,
`city` varchar(50) CHARACTER SET utf8 NOT NULL,
`cityCode` varchar(20) CHARACTER SET utf8 NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=161 DEFAULT CHARSET=latin1;
/*Data for the table `distinctcode` */
insert into `distinctcode`(`id`,`province`,`provinceCode`,`city`,`cityCode`) values (1,'北京','BJ','朝阳区','BJ-CY'),(2,'北京','BJ','海淀区','BJ-HD'),(3,'北京','BJ','通州区','BJ-TZ'),(4,'北京','BJ','丰台区','BJ-FS'),(5,'北京','BJ','昌平区','BJ-FT'),(6,'广东省','GD','东莞市','GD-DG'),(7,'广东省','GD','广州市','GD-GZ'),(8,'广东省','GD','中山市','GD-ZS'),(9,'广东省','GD','深圳市','GD-SZ'),(10,'广东省','GD','惠州市','GD-HZ'),(11,'山东省','SD','济南市','SD-JN'),(12,'山东省','SD','青岛市','SD-QD'),(13,'山东省','SD','临沂市','SD-LY'),(14,'山东省','SD','济宁市','SD-JN'),(15,'山东省','SD','菏泽市','SD-HZ'),(16,'江苏省','JS','苏州市','JS-SZ'),(17,'江苏省','JS','徐州市','JS-XZ'),(18,'江苏省','JS','盐城市','JS-YC'),(19,'江苏省','JS','无锡市','JS-WX'),(20,'江苏省','JS','南京市','JS-NJ'),(21,'河南省','HN','郑州市','HN-ZZ'),(22,'河南省','HN','南阳市','HN-NY'),(23,'河南省','HN','新乡市','HN-XX'),(24,'河南省','HN','安阳市','HN-AY'),(25,'河南省','HN','洛阳市','HN-LY'),(26,'上海市','SH','松江区','SH-SJ'),(27,'上海市','SH','宝山区','SH-BS'),(28,'上海市','SH','金山区','SH-JS'),(29,'上海市','SH','嘉定区','SH-JD'),(30,'上海市','SH','南汇区','SH-NH'),(31,'河北省','HB','石家庄市','HB-SJZ'),(32,'河北省','HB','唐山市','HB-TS'),(33,'河北省','HB','保定市','HB-BD'),(34,'河北省','HB','邯郸市','HB-HD'),(35,'河北省','HB','邢台市','HB-XT'),(36,'浙江省','ZJ','温州市','ZJ-WZ'),(37,'浙江省','ZJ','宁波市','ZJ-NB'),(38,'浙江省','ZJ','杭州市','ZJ-HZ'),(39,'浙江省','ZJ','台州市','ZJ-TZ'),(40,'浙江省','ZJ','嘉兴市','ZJ-JX'),(41,'陕西省','SX','西安市','SX-XA'),(42,'陕西省','SX','咸阳市','SX-XY'),(43,'陕西省','SX','宝鸡市','SX-BJ'),(44,'陕西省','SX','汉中市','SX-HZ'),(45,'陕西省','SX','渭南市','SX-WN'),(46,'湖南省','HN','长沙市','HN-CS'),(47,'湖南省','HN','邵阳市','HN-SY'),(48,'湖南省','HN','常德市','HN-CD'),(49,'湖南省','HN','衡阳市','HN-HY'),(50,'湖南省','HN','株洲市','HN-JZ'),(51,'重庆市','CQ','江北区','CQ-JB'),(52,'重庆市','CQ','渝北区','CQ-YB'),(53,'重庆市','CQ','沙坪坝区','CQ-SPB'),(54,'重庆市','CQ','九龙坡区','CQ-JLP'),(55,'重庆市','CQ','万州区','CQ-WZ'),(56,'福建省','FJ','漳州市','FJ-ZZ'),(57,'福建省','FJ','厦门市','FJ-XM'),(58,'福建省','FJ','泉州市','FJ-QZ'),(59,'福建省','FJ','福州市','FJ-FZ'),(60,'福建省','FJ','莆田市','FJ-PT'),(61,'天津市','TJ','和平区','TJ-HP'),(62,'天津市','TJ','北辰区','TJ-BC'),(63,'天津市','TJ','河北区','TJ-HB'),(64,'天津市','TJ','河西区','TJ-HX'),(65,'天津市','TJ','西青区','TJ-XQ'),(66,'云南省','YN','昆明市','YN-KM'),(67,'云南省','YN','红河州','YN-HH'),(68,'云南省','YN','大理州','YN-DL'),(69,'云南省','YN','文山州','YN-WS'),(70,'云南省','YN','德宏州','YN-DH'),(71,'四川省','SC','成都市','SC-CD'),(72,'四川省','SC','绵阳市','SC-MY'),(73,'四川省','SC','广元市','SC-GY'),(74,'四川省','SC','达州市','SC-DZ'),(75,'四川省','SC','南充市','SC-NC'),(76,'广西','GX','贵港市','GX-GG'),(77,'广西','GX','玉林市','GX-YL'),(78,'广西','GX','北海市','GX-BH'),(79,'广西','GX','南宁市','GX-NN'),(80,'广西','GX','柳州市','GX-LZ'),(81,'安徽省','AH','芜湖市','AH-WH'),(82,'安徽省','AH','合肥市','AH-HF'),(83,'安徽省','AH','六安市','AH-LA'),(84,'安徽省','AH','宿州市','AH-SZ'),(85,'安徽省','AH','阜阳市','AH-FY'),(86,'海南省','HN','三亚市','HN-SY'),(87,'海南省','HN','海口市','HN-HK'),(88,'海南省','HN','琼海市','HN-QH'),(89,'海南省','HN','文昌市','HN-WC'),(90,'海南省','HN','东方市','HN-DF'),(91,'江西省','JX','南昌市','JX-NC'),(92,'江西省','JX','赣州市','JX-GZ'),(93,'江西省','JX','上饶市','JX-SR'),(94,'江西省','JX','吉安市','JX-JA'),(95,'江西省','JX','九江市','JX-JJ'),(96,'湖北省','HB','武汉市','HB-WH'),(97,'湖北省','HB','宜昌市','HB-YC'),(98,'湖北省','HB','襄樊市','HB-XF'),(99,'湖北省','HB','荆州市','HB-JZ'),(100,'湖北省','HB','恩施州','HB-NS'),(101,'山西省','SX','太原市','SX-TY'),(102,'山西省','SX','大同市','SX-DT'),(103,'山西省','SX','运城市','SX-YC'),(104,'山西省','SX','长治市','SX-CZ'),(105,'山西省','SX','晋城市','SX-JC'),(106,'辽宁省','LN','大连市','LN-DL'),(107,'辽宁省','LN','沈阳市','LN-SY'),(108,'辽宁省','LN','丹东市','LN-DD'),(109,'辽宁省','LN','辽阳市','LN-LY'),(110,'辽宁省','LN','葫芦岛市','LN-HLD'),(111,'台湾省','TW','台北市','TW-TB'),(112,'台湾省','TW','高雄市','TW-GX'),(113,'台湾省','TW','台中市','TW-TZ'),(114,'台湾省','TW','新竹市','TW-XZ'),(115,'台湾省','TW','基隆市','TW-JL'),(116,'黑龙江','HLJ','齐齐哈尔市','HLJ-QQHE'),(117,'黑龙江','HLJ','哈尔滨市','HLJ-HEB'),(118,'黑龙江','HLJ','大庆市','HLJ-DQ'),(119,'黑龙江','HLJ','佳木斯市','HLJ-JMS'),(120,'黑龙江','HLJ','双鸭山市','HLJ-SYS'),(121,'内蒙古自治区','NMG','赤峰市','NMG-CF'),(122,'内蒙古自治区','NMG','包头市','NMG-BT'),(123,'内蒙古自治区','NMG','通辽市','NMG-TL'),(124,'内蒙古自治区','NMG','呼和浩特市','NMG-FHHT'),(125,'内蒙古自治区','NMG','乌海市','NMG-WH'),(126,'贵州省','GZ','贵阳市','GZ-GY'),(127,'贵州省','GZ','黔东南州','GZ-QDN'),(128,'贵州省','GZ','黔南州','GZ-QN'),(129,'贵州省','GZ','遵义市','GZ-ZY'),(130,'贵州省','GZ','黔西南州','GZ-QXN'),(131,'甘肃省','GS','兰州市','GS-LZ'),(132,'甘肃省','GS','天水市','GS-TS'),(133,'甘肃省','GS','庆阳市','GS-QY'),(134,'甘肃省','GS','武威市','GS-WW'),(135,'甘肃省','GS','酒泉市','GS-JQ'),(136,'青海省','QH','西宁市','QH-XN'),(137,'青海省','QH','海西州','QH-HX'),(138,'青海省','QH','海东地区','QH-HD'),(139,'青海省','QH','海北州','QH-HB'),(140,'青海省','QH','果洛州','QH-GL'),(141,'新疆','XJ','乌鲁木齐市','XJ-WLMQ'),(142,'新疆','XJ','伊犁州','XJ-YL'),(143,'新疆','XJ','昌吉州','XJ-CJ'),(144,'新疆','XJ','石河子市','XJ-SHZ'),(145,'新疆','XJ','哈密地区','XJ-HM'),(146,'西藏自治区','XZ','拉萨市','XZ-LS'),(147,'西藏自治区','XZ','山南地区','XZ-SN'),(148,'西藏自治区','XZ','林芝地区','XZ-LZ'),(149,'西藏自治区','XZ','日喀则地区','XZ-RKZ'),(150,'西藏自治区','XZ','阿里地区','XZ-AL'),(151,'吉林省','JL','吉林市','JL-JL'),(152,'吉林省','JL','长春市','JL-CC'),(153,'吉林省','JL','白山市','JL-BS'),(154,'吉林省','JL','白城市','JL-BC'),(155,'吉林省','JL','延边州','JL-YB'),(156,'宁夏','NX','银川市','NX-YC'),(157,'宁夏','NX','吴忠市','NX-WZ'),(158,'宁夏','NX','中卫市','NX-ZW'),(159,'宁夏','NX','石嘴山市','NX-SZS'),(160,'宁夏','NX','固原市','NX-GY');3.3 模拟生成数据
- 编写模拟程序:使用Java编写AnalogData类,实现从输入文件读取数据并按一定速度写入输出文件,模拟实时产生的广告点击日志。
java
import java.io.*;
public class AnalogData_v2 {
public static void main(String[] args) {
// 参数校验
if (args.length < 2) {
System.err.println("用法: java AnalogData <输入文件路径> <输出文件路径>");
System.exit(1);
}
String inputFile = args[0];
String outputFile = args[1];
try {
readData(inputFile, outputFile);
} catch (FileNotFoundException e) {
System.err.println("错误: 文件不存在 - " + e.getMessage());
} catch (UnsupportedEncodingException e) {
System.err.println("错误: 不支持的编码 - " + e.getMessage());
} catch (IOException e) {
System.err.println("IO异常: " + e.getMessage());
} catch (InterruptedException e) {
System.err.println("操作被中断: " + e.getMessage());
Thread.currentThread().interrupt(); // 恢复中断状态
}
}
public static void readData(String inputFile, String outputFile)
throws IOException, InterruptedException {
// 使用try-with-resources自动关闭输入/输出流
try (BufferedReader reader = new BufferedReader(
new InputStreamReader(new FileInputStream(inputFile), "GBK"));
BufferedWriter writer = new BufferedWriter(
new OutputStreamWriter(new FileOutputStream(outputFile, true)))) {
String line;
int counter = 1;
while ((line = reader.readLine()) != null) {
System.out.printf("第%d行:%s%n", counter, line);
writer.write(line);
writer.newLine(); // 使用平台无关的换行符
writer.flush(); // 确保数据写入磁盘
counter++;
Thread.sleep(1000); // 控制处理速度
}
}
}
}
shell
[root@kafka01 sparkKS]> javac AnalogData_v2.java
[root@kafka01 sparkKS]> java AnalogData_v2 ./ad.log /opt/apache-flume-1.9.0-bin/logs/ad.log
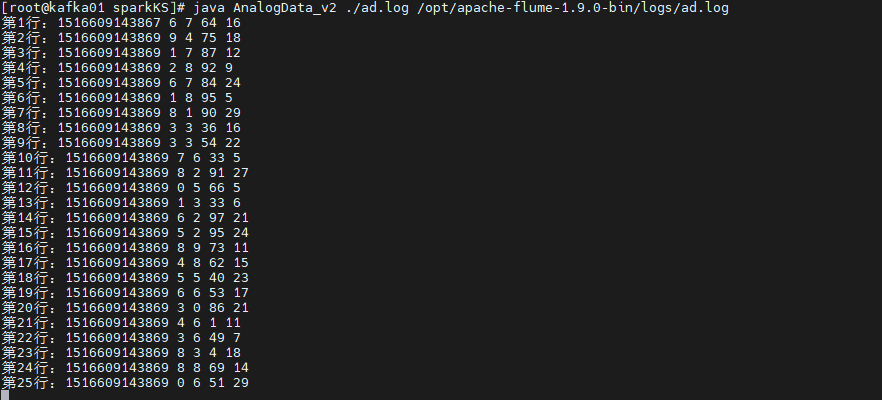
第1行:1516609143867 6 7 64 16
第2行:1516609143869 9 4 75 18
第3行:1516609143869 1 7 87 12
第4行:1516609143869 2 8 92 9
第5行:1516609143869 6 7 84 24
第6行:1516609143869 1 8 95 5- 项目打包编译:在IDEA中编译打包项目为bigdata.jar,上传至MySQL节点的/root/sparkKS/lib目录。
- 编写shell脚本 :
- 在/root/sparkKS/目录创建ad.sh脚本,用于执行模拟数据程序
- 创建common.sh脚本定义环境变量等配置
- 给ad.sh脚本授权:
chmod u+x ad.sh
3.4 业务代码实现
- 引入项目依赖:在pom.xml文件中添加MySQL连接、Spark Streaming及Kafka相关依赖。
xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>data</groupId>
<artifactId>data</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<scala.version>2.12.15</scala.version>
<spark.version>3.3.0</spark.version>
<kafka.version>3.6.1</kafka.version>
<mysql.version>8.0.27</mysql.version>
</properties>
<dependencies>
<!-- MySQL 8 驱动 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.27</version>
</dependency>
<!-- Spark 依赖 -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.12</artifactId>
<version>3.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.12</artifactId>
<version>3.3.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-10_2.12</artifactId>
<version>3.3.0</version>
</dependency>
<!-- Kafka 客户端依赖 -->
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>3.6.1</version>
</dependency>
<!-- Scala 库 -->
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main/scala</sourceDirectory>
<plugins>
<!-- Scala 编译插件 -->
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>4.8.1</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
<!-- 打包插件 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.6.0</version>
<configuration>
<archive>
<manifest>
<mainClass>data.kafka_sparkStreaming_mysql</mainClass>
</manifest>
</archive>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
<!-- 确保使用Java 8 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.8.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
</plugins>
</build>
</project>- 开发Spark Streaming应用程序 :
- 配置Spark Streaming和Kafka连接参数
- 从Kafka读取数据并进行过滤处理
- 分别统计各个广告、省份、城市的点击量
- 通过foreachRDD和foreachPartition将统计结果写入MySQL数据库,实现数据的更新或插入操作
java
package data
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.SparkConf
import org.apache.spark.streaming.kafka010._
import org.apache.spark.streaming.{Seconds, StreamingContext}
import java.sql.{Connection, DriverManager, PreparedStatement, ResultSet}
import java.util.{HashMap => JHashMap}
object KafkaSparkStreamingMysql {
// MySQL 8 配置
private val mysqlUrl = "jdbc:mysql://192.168.100.153:3306/advertise?useSSL=false&serverTimezone=UTC"
private val mysqlUser = "root"
private val mysqlPassword = "123456"
def main(args: Array[String]): Unit = {
// 加载MySQL 8驱动
Class.forName("com.mysql.cj.jdbc.Driver")
val sparkConf = new SparkConf()
.setAppName("advertise")
.setMaster("local[2]")
.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
val ssc = new StreamingContext(sparkConf, Seconds(1))
// 使用Java HashMap替代Scala Map解决循环继承问题
val kafkaParams = new JHashMap[String, Object]()
kafkaParams.put("bootstrap.servers", "192.168.100.150:9092,192.168.100.151:9092,192.168.100.152:9092")
kafkaParams.put("key.deserializer", classOf[StringDeserializer])
kafkaParams.put("value.deserializer", classOf[StringDeserializer])
kafkaParams.put("group.id", "advertise")
kafkaParams.put("auto.offset.reset", "earliest")
kafkaParams.put("enable.auto.commit", false.asInstanceOf[Object])
// 创建Kafka流
val topics = Array("advertise")
val topicsAsList = java.util.Arrays.asList(topics: _*)
val stream = KafkaUtils.createDirectStream[String, String](
ssc,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe[String, String](topicsAsList, kafkaParams)
)
// 处理数据流
val lines = stream.map(record => record.value)
lines.foreachRDD { rdd =>
if (!rdd.isEmpty()) {
rdd.foreach(println)
}
}
// 过滤无效数据
val filter = lines.map(_.split("\\s+")).filter(_.length == 5)
// 统计广告点击量
processCounts(filter.map(x => (x(4), 1)).reduceByKey(_ + _), "adversisecount", "adname")
// 统计省份点击量
processCounts(filter.map(x => (x(1), 1)).reduceByKey(_ + _), "provincecount", "province")
// 统计城市点击量
processCounts(filter.map(x => (x(2), 1)).reduceByKey(_ + _), "citycount", "city")
ssc.start()
ssc.awaitTermination()
}
/**
* 通用的计数处理方法
*/
private def processCounts(counts: org.apache.spark.streaming.dstream.DStream[(String, Int)],
tableName: String,
idColumn: String): Unit = {
counts.foreachRDD { rdd =>
if (!rdd.isEmpty()) {
rdd.foreachPartition { records =>
updateOrInsertToMysql(records, tableName, idColumn)
}
}
}
}
/**
* 更新或插入MySQL数据 (使用预编译语句防止SQL注入)
*/
private def updateOrInsertToMysql(records: Iterator[(String, Int)],
tableName: String,
idColumn: String): Unit = {
var conn: Connection = null
var checkStmt: PreparedStatement = null
var updateStmt: PreparedStatement = null
var insertStmt: PreparedStatement = null
try {
conn = DriverManager.getConnection(mysqlUrl, mysqlUser, mysqlPassword)
// 准备SQL语句
val checkSql = s"SELECT 1 FROM $tableName WHERE $idColumn = ?"
val updateSql = s"UPDATE $tableName SET count = count + ? WHERE $idColumn = ?"
val insertSql = s"INSERT INTO $tableName($idColumn, count) VALUES(?, ?)"
// 预编译SQL语句
checkStmt = conn.prepareStatement(checkSql)
updateStmt = conn.prepareStatement(updateSql)
insertStmt = conn.prepareStatement(insertSql)
records.foreach { case (name, count) =>
// 检查记录是否存在
checkStmt.setString(1, name)
val resultSet = checkStmt.executeQuery()
if (resultSet.next()) {
// 更新记录
updateStmt.setInt(1, count)
updateStmt.setString(2, name)
updateStmt.executeUpdate()
} else {
// 插入新记录
insertStmt.setString(1, name)
insertStmt.setInt(2, count)
insertStmt.executeUpdate()
}
// 关闭结果集
if (resultSet != null) resultSet.close()
}
} catch {
case e: Exception =>
println(s"处理表 $tableName 时出错: ${e.getMessage}")
e.printStackTrace()
} finally {
// 关闭所有资源
if (checkStmt != null) checkStmt.close()
if (updateStmt != null) updateStmt.close()
if (insertStmt != null) insertStmt.close()
if (conn != null) conn.close()
}
}
}3.5 打通整个项目流程
-
启动MySQL服务
-
启动Kafka集群,并创建advertise主题
-
启动Spark Streaming应用程序,在IDEA中本地运行或打包提交到Spark集群
-
启动Flume聚合服务:在kafka2和kafka3节点配置avro-file-selector-kafka.properties并启动
shell
[root@kafka02 apache-flume-1.9.0-bin]# cat conf/avro-file-selector-kafka.properties
#定义source、channel、sink的名称
agent1.sources = r1
agent1.channels = c1
agent1.sinks = k1
# 定义和配置一个avro Source
agent1.sources.r1.type = avro
agent1.sources.r1.channels = c1
agent1.sources.r1.bind = 0.0.0.0
agent1.sources.r1.port = 1234
# 定义和配置一个file channel
agent1.channels.c1.type = file
agent1.channels.c1.checkpointDir = /opt/apache-flume-1.9.0-bin/checkpointDir
agent1.channels.c1.dataDirs = /opt/apache-flume-1.9.0-bin/dataDirs
# 定义和配置一个kafka sink
agent1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
agent1.sinks.k1.topic = advertise
agent1.sinks.k1.brokerList = kafka01:9092,kafka02:9092,kafka03:9092
agent1.sinks.k1.producer.acks = 1
agent1.sinks.k1.channel = c1
################################################################################################
[root@kafka03 ~]# cat /opt/apache-flume-1.9.0-bin/conf/avro-file-selector-kafka.properties
#定义source、channel、sink的名称
agent1.sources = r1
agent1.channels = c1
agent1.sinks = k1
# 定义和配置一个avro Source
agent1.sources.r1.type = avro
agent1.sources.r1.channels = c1
agent1.sources.r1.bind = 0.0.0.0
agent1.sources.r1.port = 1234
# 定义和配置一个file channel
agent1.channels.c1.type = file
agent1.channels.c1.checkpointDir = /opt/apache-flume-1.9.0-bin/checkpointDir
agent1.channels.c1.dataDirs = /opt/apache-flume-1.9.0-bin/dataDirs
# 定义和配置一个kafka sink
agent1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
agent1.sinks.k1.topic = advertise
agent1.sinks.k1.brokerList = kafka01:9092,kafka02:9092,kafka03:9092
agent1.sinks.k1.producer.acks = 1
agent1.sinks.k1.channel = c1- 启动Flume采集服务:在kafka1节点配置taildir-file-selector-avro.properties并启动
shell
[root@kafka01 sparkKS]cat /opt/apache-flume-1.9.0-bin/conf/taildir-file-selector-avro.properties
#定义source、channel、sink的名称
agent1.sources = taildirSource
agent1.channels = fileChannel
agent1.sinkgroups = g1
agent1.sinks = k1 k2
# 定义和配置一个TAILDIR Source
agent1.sources.taildirSource.type = TAILDIR
agent1.sources.taildirSource.positionFile = /opt/apache-flume-1.9.0-bin/taildir_position.json
agent1.sources.taildirSource.filegroups = f1
agent1.sources.taildirSource.filegroups.f1 = /opt/apache-flume-1.9.0-bin/logs/ad.log
agent1.sources.taildirSource.channels = fileChannel
# 定义和配置一个file channel
agent1.channels.fileChannel.type = file
agent1.channels.fileChannel.checkpointDir = /opt/apache-flume-1.9.0-bin/checkpointDir
agent1.channels.fileChannel.dataDirs = /opt/apache-flume-1.9.0-bin/dataDirs
#定义和配置一个 sink组
agent1.sinkgroups.g1.sinks = k1 k2
#为sink组定义一个处理器,load_balance表示负载均衡 failover表示故障切换
agent1.sinkgroups.g1.processor.type = load_balance
agent1.sinkgroups.g1.processor.backoff = true
#定义处理器数据发送方式,round_robin表示轮询发送 random表示随机发送
agent1.sinkgroups.g1.processor.selector = round_robin
agent1.sinkgroups.g1.processor.selector.maxTimeOut=10000
#定义一个sink将数据发送给kafka02节点
agent1.sinks.k1.type = avro
agent1.sinks.k1.channel = fileChannel
agent1.sinks.k1.batchSize = 1
agent1.sinks.k1.hostname = kafka02
agent1.sinks.k1.port = 1234
#定义另一个sink将数据发送给kafka03节点
agent1.sinks.k2.type = avro
agent1.sinks.k2.channel = fileChannel
agent1.sinks.k2.batchSize = 1
agent1.sinks.k2.hostname = kafka03
agent1.sinks.k2.port = 1234- 模拟产生数据:执行ad.sh脚本,将数据写入指定文件,模拟实时日志
3.6 Davinci数据可视化分析
-
启动Davinci服务并登录

-
创建新项目和数据源连接(连接到MySQL的advertise数据库)
-
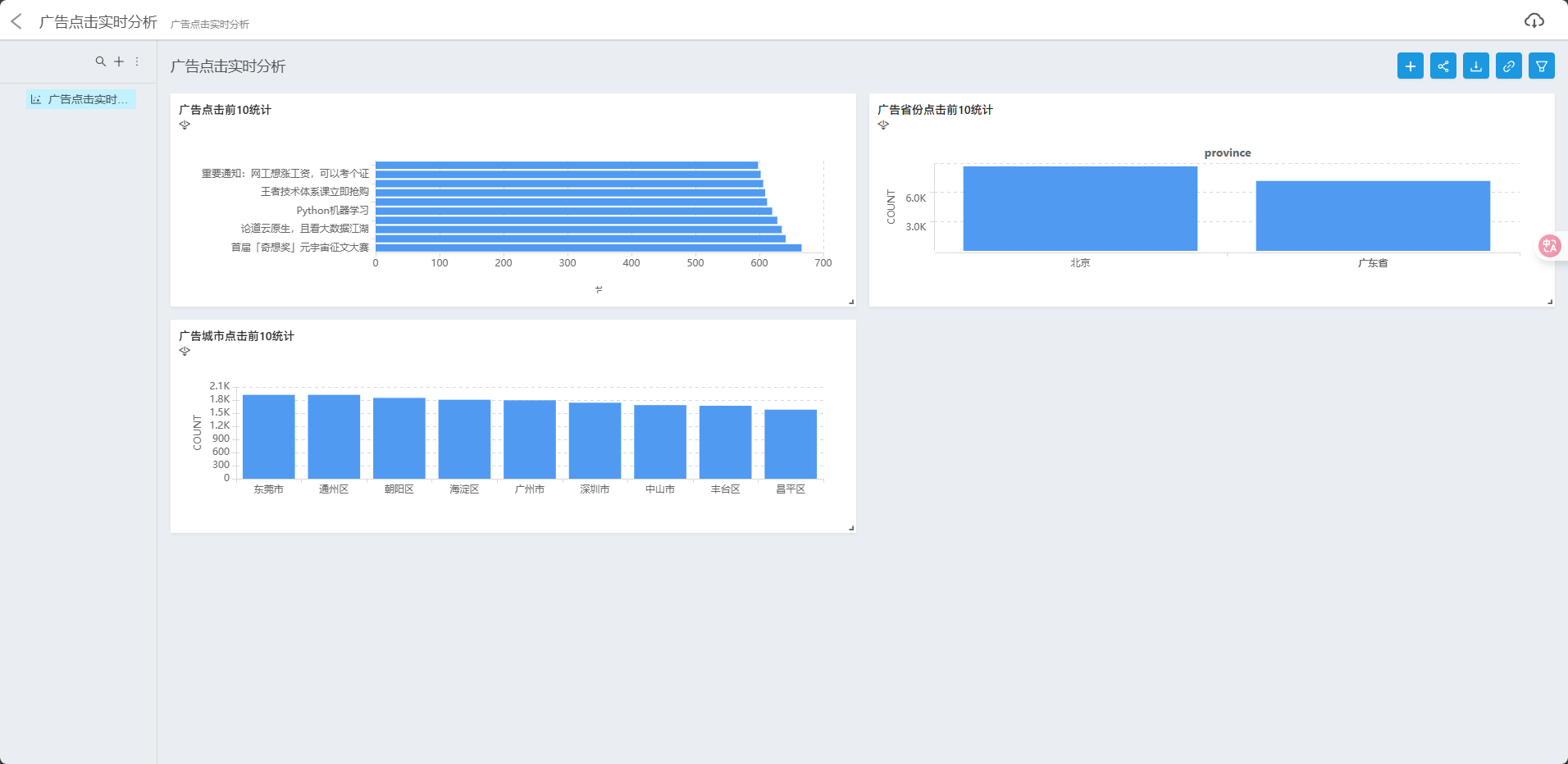
创建视图(view):
- 广告点击前10统计:关联adversisecount和advertiseinfo表
- 广告省份点击前10:关联provincecount和distinctcode表
- 广告城市点击前10:关联citycount和distinctcode表
-
创建图表(Widget):为三个视图分别创建柱状图
-
创建大屏(Dashboard):
- 添加创建的图表
- 设置数据刷新模式和时长(定时刷新,30秒)
- 完成大屏制作,实现广告点击数据的实时可视化展示
shell
bin/stop-server.sh
bin/start-server.sh
##################################
cat /opt/davinci/config/application.yml
##################################
server:
protocol: http
address: 192.168.100.150
port: 38080
servlet:
context-path: /
jwtToken:
secret: secret
timeout: 1800000
algorithm: HS512
source:
initial-size: 2
min-idle: 1
max-wait: 6000
max-active: 10
break-after-acquire-failure: true
connection-error-retry-attempts: 0
query-timeout: 600000
validationQueryTimeout: 30000
enable-query-log: false
result-limit: 1000000
spring:
mvc:
async:
request-timeout: 30s
datasource:
url: jdbc:mysql://192.168.100.153:3306/advertise?useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull&allowMultiQueries=true
username: root
password: 123456
driver-class-name: com.mysql.jdbc.Driver
initial-size: 2
min-idle: 1
max-wait: 60000
max-active: 10
redis:
isEnable: false
host: 127.0.0.1
port: 6379
password:
database: 0
timeout: 1000
jedis:
pool:
max-active: 8
max-wait: 1
max-idle: 8
min-idle: 0
mail:
host: smtp.163.com
port: 465
username: a351719672@163.com
fromAddress:
password: xxxxx
nickname: luobozi
properties:
smtp:
starttls:
enable: true
required: true
auth: true
mail:
smtp:
ssl:
enable: true
ldap:
urls:
username:
password:
base:
domainName: # domainName 指 企业邮箱后缀,如企业邮箱为:xxx@example.com, 这里值为 '@example.com'
screenshot:
default_browser: PHANTOMJS # PHANTOMJS or CHROME
timeout_second: 600
phantomjs_path: /opt/davinci/phantomjs
chromedriver_path: $your_chromedriver_path$
data-auth-center:
channels:
- name:
base-url:
auth-code:
statistic:
enable: false
elastic_urls:
elastic_user:
elastic_index_prefix:
mysql_url:
mysql_username:
mysql_password:
kafka.bootstrap.servers:
kafka.topic:
java.security.krb5.conf:
java.security.keytab:
java.security.principal: