引言:从"读懂"到"理解"------探索语义分析的深度
当计算机处理"苹果公司发布了新款手机"这句话时,它能轻易"读懂"其字面含义:一个名为"苹果公司"的实体,执行了"发布"动作,对象是"新款手机"。然而,人类的"理解"远不止于此。我们会联想到其对手机市场格局的冲击、潜在的技术革新、激烈的商业竞争,甚至是我们自己是否需要更换手机的决策。这种从"读懂"到"理解"的鸿沟,正是自然语言处理(NLP)领域中"浅层语义"与"深层语义"的核心差异所在。
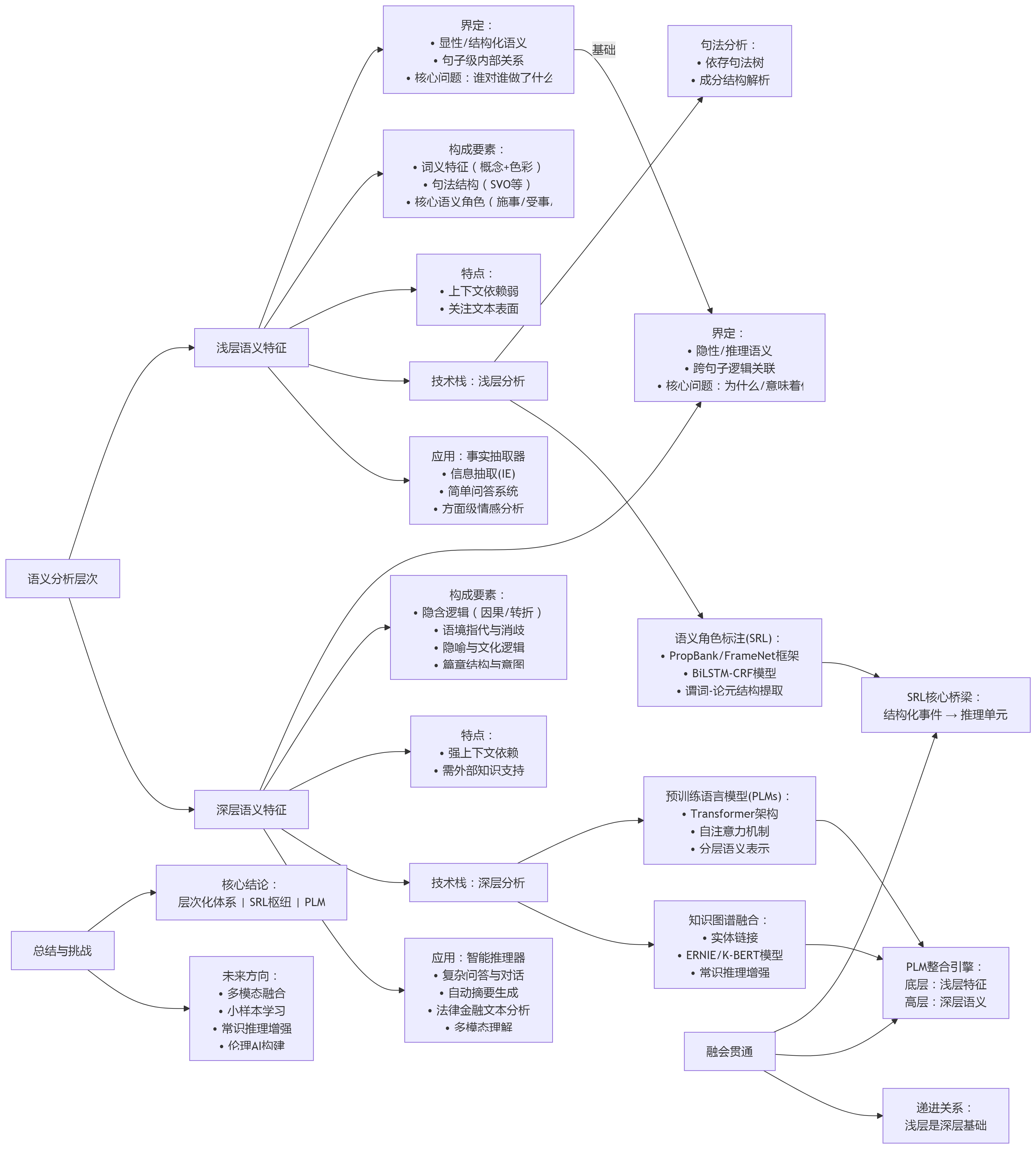
本文的核心议题,便是系统性地剖析NLP中浅层与深层语义特征的区别与联系。我们将特别关注语义角色标注(Semantic Role Labeling, SRL)在这一体系中所扮演的关键桥梁作用。文章将遵循一条清晰的分析路径:首先,从理论框架上为两种语义层次进行界定;其次,对比分析提取它们的技术实现与应用场景的差异;最后,探讨它们如何通过预训练语言模型(PLMs)与知识图谱(Knowledge Graphs, KGs)等现代技术融会贯通,共同构建一个完整的语义理解层次。
本文旨在为NLP领域的初学者、研究者和从业人员提供一个清晰的理论与技术图谱,帮助其更深刻地把握不同层次语义分析技术的本质,从而在研究与实践中做出更精准的选择与应用。
第一部分:语义特征的层次划分:理论框架与界定
为了精确探讨语义特征,我们必须首先为其建立清晰的理论定义。语言学的发展为我们提供了坚实的基础,从关注句子内部形式的结构主义,到探索语境、意图和认知过程的语用学与认知语言学,这些理论共同启发了NLP中对语义层次的划分。
1.1 浅层语义特征(Surface Semantics)的界定
浅层语义特征可以被定义为文本内部显性、结构化的语义信息。它的提取主要依赖于句子本身的词汇和语法结构,较少或完全不依赖外部世界知识。其核心是回答"一句话里,谁对谁做了什么"。
浅层语义分析的目标是捕捉句子级的、明确的语义关系,为更复杂的推理提供基础素材。
根据参考资料,浅层语义的构成要素主要包括:
- **词义特征:**这是语义的基本单元,包括词语的核心概念意义(如"书"是"装订成册的著作"),以及附加的感情、语体和形象色彩(如"团结"与"勾结"的褒贬之分)。
- **句法结构:**句子的组织方式,如中文常见的"主语-谓语-宾语"(SVO)结构,为理解基本语义关系提供了骨架。
- **核心语义角色:**这是浅层语义分析的重点,旨在识别出动作的直接参与者,如施事者(Agent)、受事者(Patient)和工具(Instrument)等。
特点总结: 浅层语义具有句子级、显性、结构化、上下文依赖较弱的特点。它关注的是"文本说了什么",而非"文本意味着什么"。
1.2 深层语义特征(Deep Semantics)的界定
与浅层语义相对,深层语义特征被定义为超越字面意义的、依赖语境、常识和外部知识的隐性语义信息。它致力于揭示文本背后的逻辑、意图和隐含的知识网络。
深层语义分析需要回答"为什么会这样"以及"这意味着什么"等更复杂的问题。其构成要素更为丰富和抽象,相关研究将其归纳为:
- **隐含意义与逻辑关系:**识别跨越句子边界的因果、条件、转折等关系。例如,在"因为暴雨,比赛取消了"中,深层语义分析需要明确"暴雨"与"比赛取消"之间的因果链。
- **语境关联与指代:**这包括根据上下文确定代词的指代对象(如"她去看电影了"中的"她"是谁),以及消除多义词的歧义(如"苹果"在不同语境下指代水果还是公司)。
- **隐喻与文化逻辑:**理解非字面表达,如"经济寒冬"中的隐喻,或"喜鹊"在中国文化中象征喜庆的特定含义。这需要模型具备一定的文化背景知识。
- **篇章结构与意图:**分析整个段落或篇章的论证结构(如"问题-解决方案"模式),并推断作者的言外之意,如讽刺、暗示等。
特点总结: 深层语义具有跨句子/篇章级、隐性、推理驱动、强依赖上下文与外部知识的特点。它探索的是语言背后复杂的认知与逻辑世界。
第二部分:技术分野:不同层次语义特征的提取方法对比
对不同层次语义的追求,催生了截然不同的技术路线。从早期的规则和统计方法,到如今由深度学习主导的时代,技术的发展深刻地反映了我们对语义理解深度的不断探索。
2.1 浅层语义分析技术栈
浅层语义分析技术成熟较早,其目标是构建精确、结构化的句子级语义表示。
句法分析(Syntactic Parsing)
句法分析是所有语义分析的基石。它通过生成成分句法树或依存关系图,揭示句子的语法结构。虽然其直接目标是语法而非语义,但它提供的句子骨架是后续识别语义角色的重要依据。
语义角色标注(Semantic Role Labeling, SRL)
SRL可以被视为浅层语义分析的核心与巅峰,它完美地连接了句法结构与初步的语义理解。SRL的核心任务是围绕句子中的谓词(通常是动词),识别出其对应的语义角色。例如,在句子"小明用刀切苹果"中,SRL系统会以"切"为中心,标注出:
- 施事者 (Agent): 小明
- 受事者 (Patient): 苹果
- 工具 (Instrument): 刀
这一过程主要依赖于如 PropBank(基于动词的论元库)或 FrameNet(基于框架的语义库)等理论框架。早期的SRL模型多采用基于特征工程的统计方法,后来发展为使用`BiLSTM-CRF`等深度学习模型,将任务视为句子内部的序列标注问题。
2.2 深层语义分析技术栈
深层语义分析则更多地依赖于能够处理复杂上下文和外部知识的现代技术。
预训练语言模型(PLMs)的主导作用
BERT、GPT等预训练语言模型的出现,是深层语义分析领域的革命。其核心在于Transformer架构的自注意力机制(Self-Attention),该机制使得模型能够动态地权衡句子中所有词语之间的关系,从而捕捉长距离依赖和复杂的上下文信息。这与过去静态的词向量(如Word2Vec)有本质区别。
PLMs通过在大规模无标注文本上进行预训练,实现了逐层抽象的特征学习:底层网络倾向于学习词法和句法等浅层特征,而高层网络则能形成更丰富的上下文语义表示。这种内在的层次性使得PLMs在处理需要深度推理的任务(如自然语言推理NLI、机器阅读理解MRC)时表现卓越,能够判断句子间的蕴含、矛盾等逻辑关系。
知识图谱(KG)与外部知识的融合
尽管PLMs能力强大,但它们本质上是从文本数据中学习统计规律,缺乏真实世界的"事实性"知识,容易产生"幻觉"(Hallucination)。为了解决这一问题,将PLMs与知识图谱融合成为关键。知识图谱是一个结构化的知识库,包含了实体、属性及其之间的关系。
融合技术主要包括:
- **实体链接(Entity Linking):**将文本中提及的实体(如"乔丹")准确地链接到知识图谱中对应的节点(是篮球运动员迈克尔·乔丹,还是科学家迈克尔·I·乔丹)。
- **知识注入模型(Knowledge-Enhanced Models):**如百度的ERNIE、清华的K-BERT等模型,在预训练阶段就将知识图谱中的三元组信息融入模型,使其直接学习知识。
知识图谱的引入,极大地增强了模型的深层语义推理能力,例如进行常识推理("他举起锤子"的意图是"砸东西")、消除歧义和补全文本中隐含的信息。
2.3 技术对比总结
下表清晰地总结了两种技术路线的核心差异:
| 维度 | 浅层语义分析技术 | 深层语义分析技术 |
|---|---|---|
| 数据依赖 | 依赖高质量、人工标注的语料库(如PropBank) | 依赖海量无监督文本进行预训练,并结合知识库进行增强 |
| 模型架构 | 统计模型、序列标注模型(如BiLSTM-CRF) | 基于Transformer的预训练模型(BERT/GPT)+ 图神经网络(GNN) |
| 处理范围 | 主要在句子内部(Intra-sentential) | 跨句子、段落甚至整个文档(Cross-sentential / Discourse-level) |
| 知识来源 | 主要来自文本自身(词汇、语法) | 文本上下文 + 外部世界知识(常识、知识图谱) |
第三部分:应用场景的差异:不同层次语义的价值体现
不同的语义深度,对应着不同的应用价值。选择何种技术,取决于任务的具体需求------是需要一个高效的"事实抽取器",还是一个智能的"逻辑推理器"。
3.1 浅层语义的应用场景("事实抽取器")
浅层语义的核心价值在于快速、准确地从非结构化文本中抽取出结构化的事实信息。它适用于那些对"谁在何时何地做了什么"这类信息有强需求的场景。
典型任务
- **信息抽取(Information Extraction):**例如,从海量财经新闻中自动抽取"A公司在2025年第一季度以10亿美元收购了B公司"这类事件,填充到数据库中。
- **简单问答系统:**回答事实型问题,如"《三体》的作者是谁?"或"珠穆朗玛峰的高度是多少?"。这类问题的答案通常直接存在于文本中。
- **方面级情感分析(Aspect-Based Sentiment Analysis):**在产品评论中,精准定位到用户对不同方面的情感。如"这款手机的屏幕显示效果很棒,但电池续航太差了",系统需识别出对"屏幕"的正面情感和对"电池"的负面情感。
3.2 深层语义的应用场景("智能推理器")
深层语义的价值在于理解文本背后的逻辑、意图和因果关系,从而进行复杂的推理、生成和交互。它适用于需要机器像人一样思考的场景。
典型任务
- **复杂问答与对话系统:**理解并回答"为什么俄乌冲突会影响全球粮食价格?"这类需要推理的问题,并在多轮对话中保持上下文一致性,理解用户的真实意图。
- 自动摘要与故事生成: 通过构建事理图谱,识别文本的核心因果链(如"干旱→作物减产→粮价上涨"),从而生成逻辑连贯、重点突出的摘要或故事。
- **法律、金融文本分析:**在法律文书中,理解合同条款背后的条件、权力和责任关系;在金融领域,分析财报和新闻稿中隐含的市场情绪和事件的因果链,辅助决策。
- **多模态理解:**结合图像、语音等信息进行综合判断。例如,当看到一张游戏失败的截图,并配文"这操作真是让人窒息",系统需要理解这是一种负面的讽刺,而非字面赞美。
第四部分:融会贯通:SRL作为桥梁,PLM作为引擎
将浅层与深层语义视为对立的两极是一种误解。更准确地看,它们是一个连续统一体,是从表层到核心的分析深度上的递进关系。
4.1 区别的再审视:递进而非对立
浅层语义是深层语义的基础和前提 。一个无法准确解析句子基本事件结构(谁做了什么)的系统,根本不可能进行可靠的逻辑推理(为什么这么做)。对"暴雨导致交通瘫痪"这句话,首先要通过浅层分析识别出"暴雨"和"交通瘫痪"这两个事件,然后才能在深层分析中建立它们之间的因果关系。因此,二者是分析深度上的递进,而非技术路线上的对立。
4.2 SRL:从"事件描述"到"推理单元"的桥梁
在此递进关系中,语义角色标注(SRL)扮演了至关重要的桥梁角色。
- **承上:**SRL的产出------一个围绕谓词的、结构化的谓词-论元框架(如 `施事:公司 谓词:收购 受事:竞争对手`)------是浅层语义分析的终极产物,它提供了一个清晰的、标准化的事件描述。
- 启下: 这个结构化的事件框架可以被视为一个原子推理单元。多个这样的单元可以被链接起来,形成更复杂的事件链或事理图谱,从而为深层语义分析(如因果推断、时序分析)提供坚实的素材。SRL将非结构化的句子转化为了可供机器进行逻辑操作的半结构化知识。
4.3 PLM:内在的语义层次整合引擎
大型预训练模型(如BERT/GPT)的强大之处,在于其模型内部已经隐式地学习和整合了不同层次的语义特征。正如前文所述,相关研究表明,PLM的底层网络更关注词法、句法等浅层特征,而高层网络则更关注上下文、篇章等深层语义。这使得PLMs成为了一个天然的语义层次整合引擎。
这种整合能力最直观的体现是,现代NLP研究可以通过在同一个PLM上进行微调,来解决从SRL(偏浅层)到复杂推理(深层)的多种任务。这证明了PLMs已经具备了在一个统一框架内处理和关联不同深度语义信息的能力,从而极大地推动了整个语义理解领域的发展。
总结与展望
通过以上分析,我们可以得出以下核心结论:
自然语言处理的语义分析是一个从浅到深的层次化体系。浅层语义关注"是什么",旨在从文本中提取结构化的事实;深层语义关注"为什么"和"怎么样",旨在理解文本背后的逻辑与意图。语义角色标注(SRL)是连接二者的关键枢纽,而预训练语言模型(PLM)与知识图谱(KG)的结合,则是实现深层理解的核心驱动力。
尽管取得了巨大进展,但深层语义分析仍面临诸多挑战。正如相关资料所指出的,模型的可解释性(黑箱问题)、巨大的计算资源消耗、数据中隐含的社会偏见,以及对常识和动态知识的获取能力不足,都是亟待解决的难题。
展望未来,语义分析技术正朝着以下方向发展:
- **更深度的多模态融合:**整合文本、图像、声音等多种信息,实现更接近人类感知的综合理解。
- **更强的小样本与零样本学习能力:**降低对海量标注数据的依赖,使模型能快速适应新领域和新任务。
- **更可靠的常识推理:**构建更完备、动态更新的常识知识库,并发展出更鲁棒的神经-符号结合推理方法。
- **构建符合人类伦理的AI系统:**在模型设计和应用中,主动检测和消除偏见,确保技术的公平性和安全性。
最终,我们追求的不仅仅是能回答问题的机器,而是能够真正与人类进行深度思想交流、理解言外之意、并能进行创造性思考的NLP技术。这条从"读懂"到"理解"的探索之路,道阻且长,但行则将至。