目录
-
- 1.摘要
- [2.MapReduce-Modified Particle Swarm Optimization (MR-MPSO)](#2.MapReduce-Modified Particle Swarm Optimization (MR-MPSO))
- 3.结果展示
- 4.参考文献
- 5.算法辅导·应用定制·读者交流

1.摘要
大数据的迅猛增长带来了严峻的数据管理挑战,尤其是在数据分布不均的庞大数据库中。由于这种不匹配,传统软件系统的效率大打折扣,导致数据处理复杂且低效。为解决这一问题,本文提出了一种MapReduce-增强粒子群算法(MR-MPSO),MR-MPSO方法不仅有效提升了大规模数据集的管理能力,还解决了数据不平衡带来的复杂性问题。MR框架用于处理大规模数据任务,MR-MPSO则优化map和reduce函数。
2.MapReduce-Modified Particle Swarm Optimization (MR-MPSO)
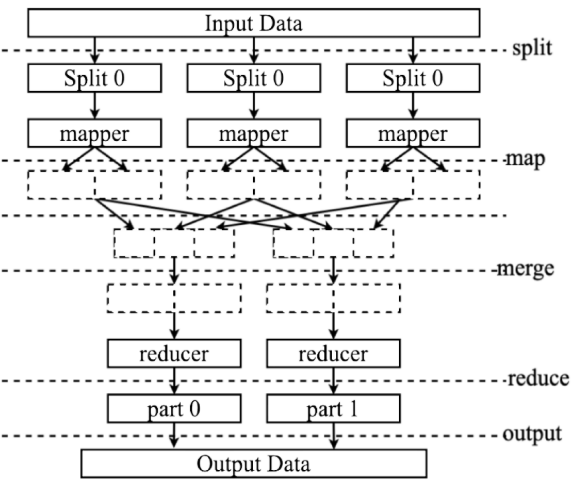
传统基于MapReduce的优化方法在面对庞大数据处理任务时常常遇到挑战,而PSO因其能够在多个搜索区域之间有效导航,且在探索与开发之间取得平衡,成为一种流行选择。结合MapReduce的可扩展性和灵活性,使其成为大数据应用的理想工具。然而,PSO在MapReduce框架中的应用面临优化离散问题和资源分配时的困难。为此,本文提出了MR-MPSO,专为MapReduce大规模数据处理需求设计。
权重系数:
W ( t ) = W S t a r t − ( W S t a r t − − W E n d MaxIterations ) ∗ t W(t)=W_{Start}-\left(\frac{W_{Start}--W_{End}}{\text{MaxIterations}}\right)*t W(t)=WStart−(MaxIterationsWStart−−WEnd)∗t
学习率:
c 1 = c 1 , S t a r t − t MaxIterations ( c 1 , S t a r t − c 1 , E n d ) c_1=c_{1,Start}-\frac{t}{\text{MaxIterations}}(c_{1,Start}-c_{1,End}) c1=c1,Start−MaxIterationst(c1,Start−c1,End)
c 2 = c 2 , S t a r t − t MaxIterations ( c 2 , S t a r t − c 2 , E n d ) c_2=c_{2,Start}-\frac{t}{\text{MaxIterations}}\left(c_{2,Start}-c_{2,End}\right) c2=c2,Start−MaxIterationst(c2,Start−c2,End)
MR-MPSO算法主要目标是通过减少执行时间和提高吞吐量,同时保持I/O操作的一致性,从而提升MapReduce框架的性能,适应不同数据大小的需求。在传统MR配置中参数设置经常导致低效,特别是对于具有不同数据量和I/O需求的应用程序。通过动态调整关键的MR参数,如减少器的数量和数据分区技术,所提出的方法克服了这些困难。优化问题定义如下:
- 目标:减少执行时间,增加I/O;
- 约束:避免数据丢失或溢出,MR设置必须在可接受的范围内;
- 性能度量:吞吐量(MB/秒)、平均I/O速率、I/O速率标准差和总执行时间。
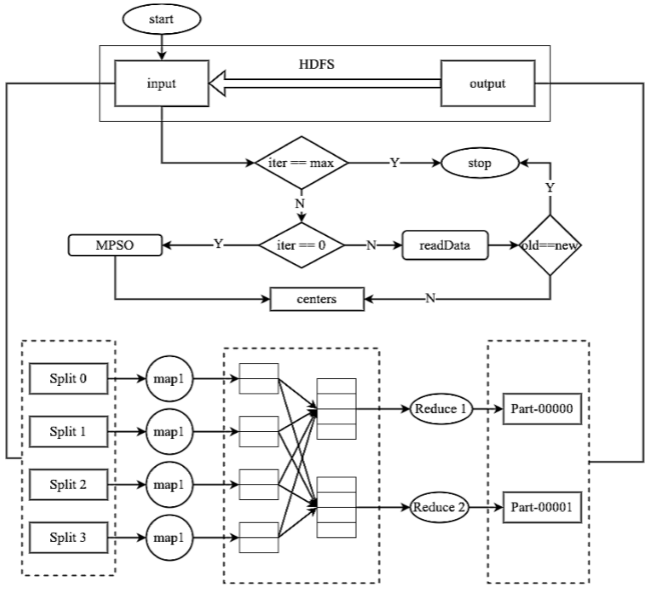
MR-MPSO算法通过进化迭代优化MapReduce的参数配置。每个粒子代表一个潜在的配置,初始时粒子随机初始化,在预定义的参数范围内搜索。每个粒子评估其位置的性能,并根据个体和全局最佳位置更新速度和位置。随着迭代的进行,粒子不断调整其位置,直到找到最优配置并完成MapReduce任务。

3.结果展示

4.参考文献
1 Diwaker C, Hasanpuri V, Gulzar Y, et al. Optimizing MapReduce efficiency and reducing complexity with enhanced particle Swarm Optimization (MR-MPSO)J. Swarm and Evolutionary Computation, 2025, 95: 101917.