目录
Vulkan Compute 概述
与 OpenGL 等较旧的 API 不同,Vulkan 中强制要求支持计算着色器,这意味着您可以在任何可用的 Vulkan 实现上使用计算着色器,无论它是高端桌面 GPU 还是低功耗嵌入式设备
GPU 的计算功能可以用于图像处理、可见性测试、后期处理、高级照明计算、动画、物理(例如粒子系统)等等,甚至可以用于非可见性的工作比如 AI 和 数字运算等
使用 GPU 进行计算的一个明显的优势是
- 降低
CPU负载 - 避免
CPU和GPU之间交换数据
所有数据都可以直接保持在GPU上,无需从缓慢的主存储器中获取数据
一个例子
我们将实现的一个易于理解的示例是基于 GPU 的粒子系统,这种系统在很多游戏中会与使用,通常由数千个每帧都更新的粒子组成,渲染粒子需要两个主要的过程: 使用顶点缓冲区传递顶点,粒子的计算和更新
传统的粒子系统是将粒子数据存储在主内存中,然后使用 CPU 更新,更新后,顶点需要再次传输到 GPU 的内存,以便它可以在下一帧中显示更新的粒子
最直接的方法是为每帧使用新数据重新创建顶点缓冲区。这显然非常耗费资源,当然也可以映射 GPU 的内存方便 CPU 写入,或者使用主机本地缓冲区(由于 PCI-E 带宽,这将是最慢的方法),但是无论使用那种方法,始终需要 CPU 和 GPU 之间交换数据来更新粒子
使用基于 GPU 的粒子系统,就不需要此过程,顶点上传到 GPU,并且所有更新都在 GPU 的内存中使用计算着色器完成,之所以速度更快的主要原因之一是 GPU 与直接管理的内存(Local Memory)之间更高的带宽
同时在具有专门计算队列的 GPU 上执行时,可以与图形管线并行执行来更新粒子
使用流程
前面已经了解了用于传递图元的顶点和索引的缓冲区(vertebuffer和indexbuffer)以及用于将数据传递到着色器的统一缓冲区(uniform buffer)
Vulkan Compute 引入的一个重要概念是能够任意地从缓冲区读取和写入到缓冲区, 为此,Vulkan 提供了两种专用的存储类型 SSBO(Shader Storage Buffer Object) 和 vkImage
SSBO
SSBO (Shader Storage Buffer Object) 是允许计算着色器读取和写入的缓冲区,使用它们类似于使用统一缓冲区对象
区别于之前我们使用的 VertexBuffer IndexBuffer 和 Texture Mapping Image 都是 Shader 只读类型的 Buffer
Uniform Buffer 也是 Shader 可读可写的,但是大小必须和 Graphic Shader 中定义的一致,
但是 SSBO 的特点就是大小不限定,也就是大小可以根据要处理的数据量决定,要处理数据越多,创建的 SSBO buffers size 越大
在 Vulkan 中,您可以为缓冲区和图像指定多种用途,因此粒子顶点缓冲区既可以用作顶点缓冲区(在图形通道中),又可以用作存储缓冲区(在计算通道中)
c
// 作为 SSBO Usage VK_BUFFER_USAGE_STORAGE_BUFFER_BIT
createBuffer(bufferSize, VK_BUFFER_USAGE_VERTEX_BUFFER_BIT | VK_BUFFER_USAGE_STORAGE_BUFFER_BIT, VK_MEMORY_PROPERTY_DEVICE_LOCAL_BIT, shaderStorageBuffers[i], shaderStorageBuffersMemory[i]);
void createBuffer(VkDeviceSize size, VkBufferUsageFlags usage, VkMemoryPropertyFlags properties, VkBuffer& buffer, VkDeviceMemory& bufferMemory) {
VkBufferCreateInfo bufferInfo{};
bufferInfo.sType = VK_STRUCTURE_TYPE_BUFFER_CREATE_INFO;
bufferInfo.size = size;
bufferInfo.usage = usage;
bufferInfo.sharingMode = VK_SHARING_MODE_EXCLUSIVE;
if (vkCreateBuffer(device, &bufferInfo, nullptr, &buffer) != VK_SUCCESS) {
throw std::runtime_error("failed to create buffer!");
}
VkMemoryRequirements memRequirements;
vkGetBufferMemoryRequirements(device, buffer, &memRequirements);
VkMemoryAllocateInfo allocInfo{};
allocInfo.sType = VK_STRUCTURE_TYPE_MEMORY_ALLOCATE_INFO;
allocInfo.allocationSize = memRequirements.size;
allocInfo.memoryTypeIndex = findMemoryType(memRequirements.memoryTypeBits, properties);
if (vkAllocateMemory(device, &allocInfo, nullptr, &bufferMemory) != VK_SUCCESS) {
throw std::runtime_error("failed to allocate buffer memory!");
}
vkBindBufferMemory(device, buffer, bufferMemory, 0);
}VK_BUFFER_USAGE_VERTEX_BUFFER_BIT 和 VK_BUFFER_USAGE_STORAGE_BUFFER_BIT 这两个标志作为 bufferInfo.usage 一起设置
告诉实现我们希望将此缓冲区用于两种不同的场景:作为顶点着色器中的顶点缓冲区和作为存储缓冲区
对应的 compute Shader 可以使用下面的写法:
c
layout(std140, binding = 1) readonly buffer ParticleSSBOIn {
Particle particlesIn[ ];
};
layout(std140, binding = 2) buffer ParticleSSBOOut {
Particle particlesOut[ ];
};SSBO 包含由 标记的,并不指定大小,不必在 SSBO 中指定元素数量是优于例如统一缓冲区的优势之一
std140 是一个内存布局限定符,它确定着色器存储缓冲区的成员元素在内存中如何对齐
Storage Image
存储图像允许您读取和写入图像, 典型的用例包括将图像效果应用于纹理、进行后期处理(反过来非常相似)或生成 mip-map
c
VkImageCreateInfo imageInfo {};
...
imageInfo.usage = VK_IMAGE_USAGE_SAMPLED_BIT | VK_IMAGE_USAGE_STORAGE_BIT;
...
if (vkCreateImage(device, &imageInfo, nullptr, &textureImage) != VK_SUCCESS) {
throw std::runtime_error("failed to create image!");
}使用 imageInfo.usage 设置的 VK_IMAGE_USAGE_SAMPLED_BIT 和 VK_IMAGE_USAGE_STORAGE_BIT 这两个标志是希望将此图像用于两种不同的场景:
作为片段着色器中采样的图像和作为计算着色器中的存储图像
c
layout (binding = 0, rgba8) uniform readonly image2D inputImage;
layout (binding = 1, rgba8) uniform writeonly image2D outputImage;这里的一些差异是额外的属性,例如图像格式的 rgba8,readonly 和 writeonly 限定符,它们告诉实现我们只会读取输入图像并写入输出图像,我们需要使用 image2D 类型来声明存储图像
在计算着色器中使用 imageLoad 和 imageStore 来读取和写入存储图像
c
vec3 pixel = imageLoad(inputImage, ivec2(gl_GlobalInvocationID.xy)).rgb;
imageStore(outputImage, ivec2(gl_GlobalInvocationID.xy), pixel);计算流程
-
使用计算的队列族
Vulkan要求支持图形操作的实现至少有一个同时支持图形和计算操作的queueFamilyIndex,但是也可能实现专用的计算队列,所以
queueFamilyIndex要选择计算类型的队列 -
加载计算着色器
加载计算着色器与加载任何其他着色器相同,唯一的区别就是
VK_SHADER_STAGE_COMPUTE_BIT
c
auto computeShaderCode = readFile("shaders/compute.spv");
VkShaderModule computeShaderModule = createShaderModule(computeShaderCode);
VkPipelineShaderStageCreateInfo computeShaderStageInfo{};
computeShaderStageInfo.sType = VK_STRUCTURE_TYPE_PIPELINE_SHADER_STAGE_CREATE_INFO;
computeShaderStageInfo.stage = VK_SHADER_STAGE_COMPUTE_BIT;
computeShaderStageInfo.module = computeShaderModule;
computeShaderStageInfo.pName = "main";- 计算管线
我们需要使用vkCreateComputePipelines创建专用的计算管道来运行我们的计算命令,由于计算管道不涉及任何光栅化状态,因此它比图形管道的状态少得多
c
VkComputePipelineCreateInfo pipelineInfo{};
pipelineInfo.sType = VK_STRUCTURE_TYPE_COMPUTE_PIPELINE_CREATE_INFO;
pipelineInfo.layout = computePipelineLayout;
pipelineInfo.stage = computeShaderStageInfo;
if (vkCreateComputePipelines(device, VK_NULL_HANDLE, 1, &pipelineInfo, nullptr, &computePipeline) != VK_SUCCESS) {
throw std::runtime_error("failed to create compute pipeline!");
}计算空间
计算着色器两个重要的计算概念:工作组(workgroup)和调用(invocation),它们定义了一个抽象的执行模型,用于说明 GPU 的计算硬件如何在三个维度(x 、y 和 z)中处理计算工作负载
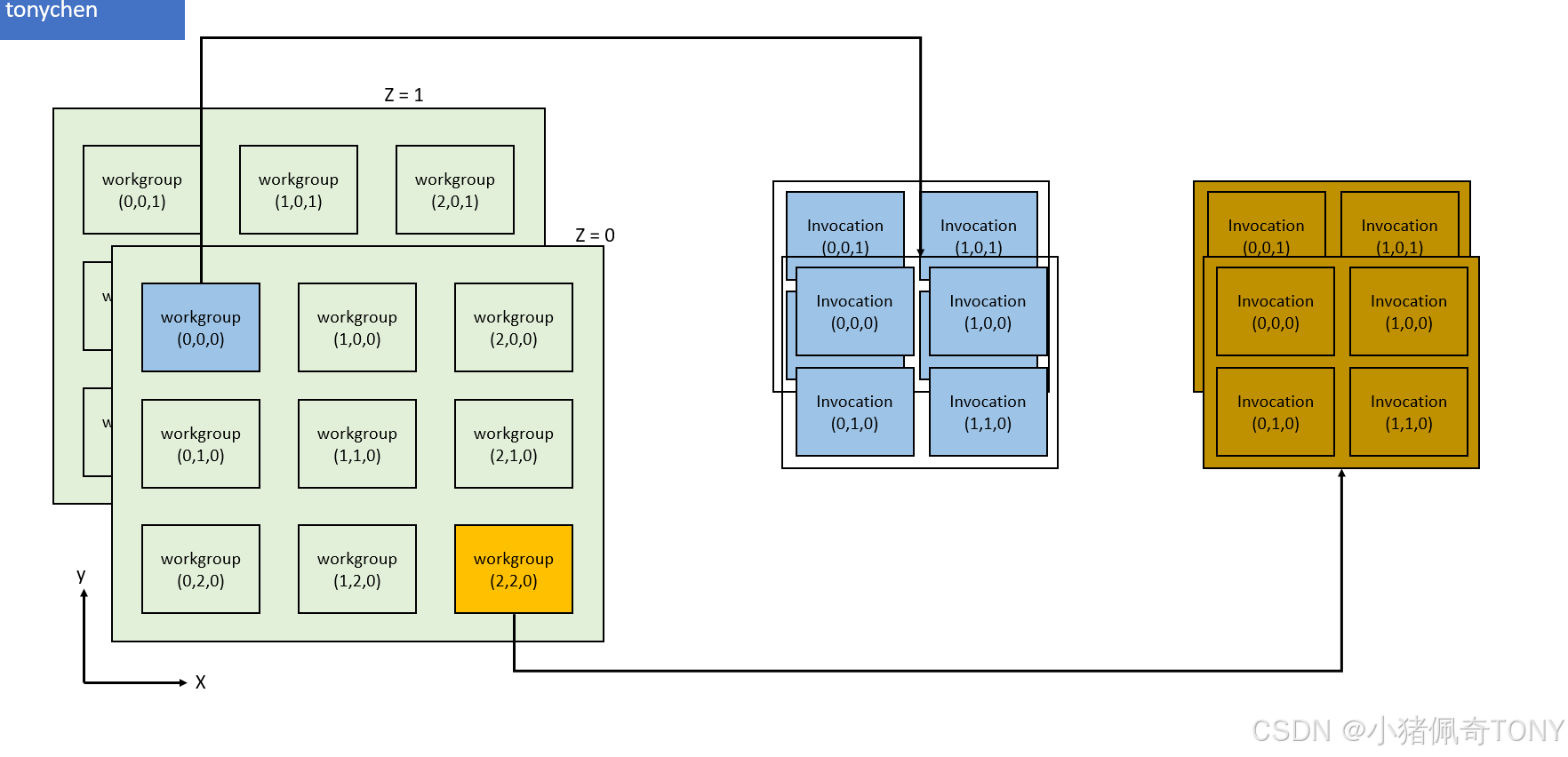
-
工作组 (
workgroup)定义了计算工作负载的形成方式以及GPU的计算硬件如何处理它们,可以视为GPU要完成的工作项目,工作组的维度由应用程序在命令缓冲区时使用调度命令设置 -
每个(
workgroup)都使用调用(invocation)的集合,它们执行相同的计算着色器,可以潜在地并行运行,它们的维度在计算着色器中设置,单个工作组内的调用可以访问共享内存这里从
GPU的结构分析每个(workgroup)都分配一块单独的私有内存,同时所有的工作组也会有全局的内存可以访问
工作组(workgroup)(由 vkCmdDispatch 定义)和调用(invocation)(由计算着色器中的局部大小定义)的维度数量取决于输入数据的结构
例如,处理一维数组,则只需为两者指定 x 维度即可
如果我们调度一个工作组计数 64, 1, 1,并且计算着色器的局部大小为 32, 32, 1,则我们的计算着色器将被调用 64 x 32 x 32 = 65,536 次
工作组和局部大小的最大计数因实现而异,受到 VkPhysicalDeviceLimits 中与计算相关的 maxComputeWorkGroupCount、maxComputeWorkGroupInvocations 和 maxComputeWorkGroupSize 限制
计算着色器
c
#version 450
layout (binding = 0) uniform ParameterUBO {
float deltaTime;
} ubo;
struct Particle {
vec2 position;
vec2 velocity;
vec4 color;
};
layout(std140, binding = 1) readonly buffer ParticleSSBOIn {
Particle particlesIn[ ];
};
layout(std140, binding = 2) buffer ParticleSSBOOut {
Particle particlesOut[ ];
};
layout (local_size_x = 256, local_size_y = 1, local_size_z = 1) in;
void main()
{
uint index = gl_GlobalInvocationID.x;
Particle particleIn = particlesIn[index];
particlesOut[index].position = particleIn.position + particleIn.velocity.xy * ubo.deltaTime;
particlesOut[index].velocity = particleIn.velocity;
...
}绑定在 0 处的是 uniform 缓冲区对象
绑定在 1 处的是 着色器缓冲区对象,来自上一帧的输出 SSBO
绑定在 2 处是指向当前帧的 SSBO
其中关键的是计算着色器的声明:
layout (local_size_x = 256, local_size_y = 1, local_size_z = 1) in;
定义了当前计算着色器此计算着色器的调用次数,都是以 local 作为前缀
计算着色器也有自己的一组内置输入变量,内置变量是以 gl 作为前缀,其中一个内置变量是 gl_GlobalInvocationID, 它是一个变量,用于标志当前 GPU 调度,用于索引粒子数组
运行计算命令
GPU 真正完成计算实在命令缓冲区内调用 vkCmdDispatch 完成,这类似于 vkCmdDraw 对应图形的绘制调用
c
VkCommandBufferBeginInfo beginInfo{};
beginInfo.sType = VK_STRUCTURE_TYPE_COMMAND_BUFFER_BEGIN_INFO;
vkBeginCommandBuffer(commandBuffer, &beginInfo)
...
vkCmdBindPipeline(commandBuffer, VK_PIPELINE_BIND_POINT_COMPUTE, computePipeline);
vkCmdBindDescriptorSets(commandBuffer, VK_PIPELINE_BIND_POINT_COMPUTE, computePipelineLayout, 0, 1, &computeDescriptorSets[i], 0, 0);
vkCmdDispatch(computeCommandBuffer, PARTICLE_COUNT / 256, 1, 1);
...
vkEndCommandBuffer(commandBuffer)PARTICLE_COUNT 除以 256 的原因是我们在工作组中定义每个计算着色器执行 256 次调用