一、算法核心原理与参数影响
DBSCAN(Density-Based Spatial Clustering of Applications with Noise)基于密度聚类思想,其核心参数 eps(邻域半径)和 minPts(最小点数)直接决定聚类效果。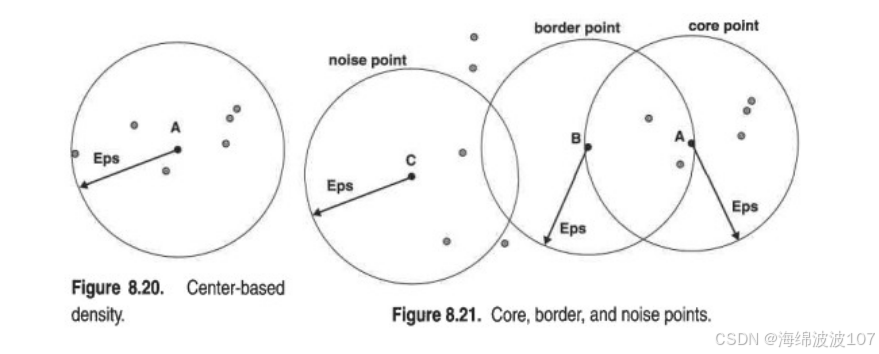
DBSCAN的"簇"定义是:由密度可达关系导出的最大密度相连样本的集合。
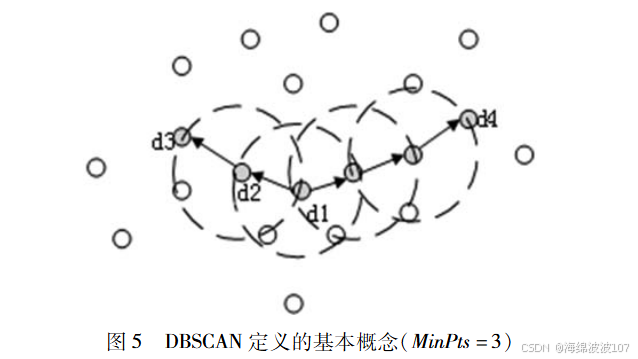
1.1 参数 eps 的影响机制
- 过小的
eps:导致聚类过度分散,例如在客户细分中,相邻但距离稍远的群体被误判为独立簇,丢失真实关联。 - 过大的
eps:迫使不同密度簇合并,如在空间分析中,商业区与住宅区被错误聚合,降低细分精度。 - 优化选择方法 :
- k-距离图法:取k=4时曲线的拐点值(如第4近邻距离的突变点)可确定合理 `eps。
- 维度经验公式 :
eps ≈ 数据维度n的函数,但需结合业务验证。
1.2 参数 minPts 的作用与选择
- 过小的值(如<3):使稀疏区域的边界点被误标为核心点,产生碎片化簇。
- 过大的值:高密度簇被合并,同时增加噪声点误判。
- 选择准则 :
- 基础规则:`minPts ≥ 数据维度 + 1。
- 二维默认值:常取4。
- 业务驱动:根据数据规模与场景需求调整。
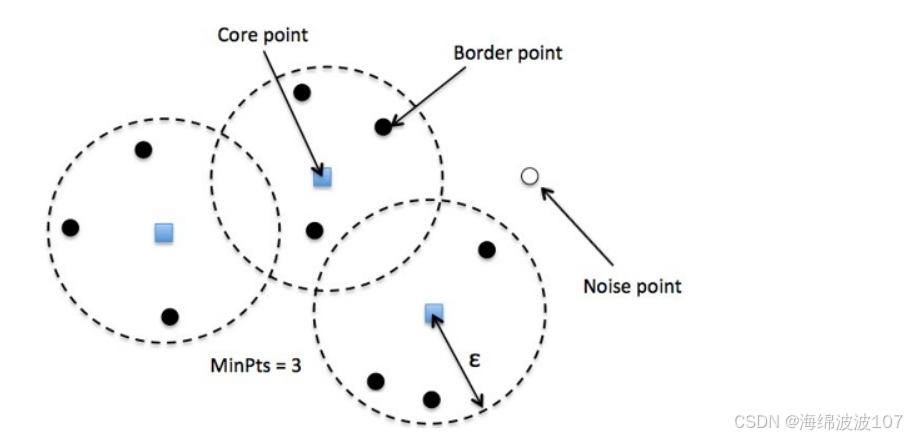
1.3 参数联合影响
静态参数在面对密度不均的数据时表现局限:
- 稀疏簇被割裂(如地质断层识别),而密集簇被强制合并(如城市热点分析)。
- 合理组合参数可显著降低噪声,但无通用最优解。
二、与传统聚类算法的性能对比
2.1 与K-means的核心差异
| 指标 | DBSCAN | K-means |
|---|---|---|
| 时间复杂度 | O(n log n) ~ O(n²)(依赖数据结构) | 近线性O(n) |
| 噪声处理 | 直接标记噪声点 | 对异常值敏感 |
| 簇形状适应性 | 支持任意形状(如环形客户群) | 仅识别球形簇 |
| 参数依赖 | 需调优eps和minPts |
仅需预设簇数k |
典型场景:DBSCAN适用于交通流不规则分布分析,K-means更适合同质化用户分群。
dbscan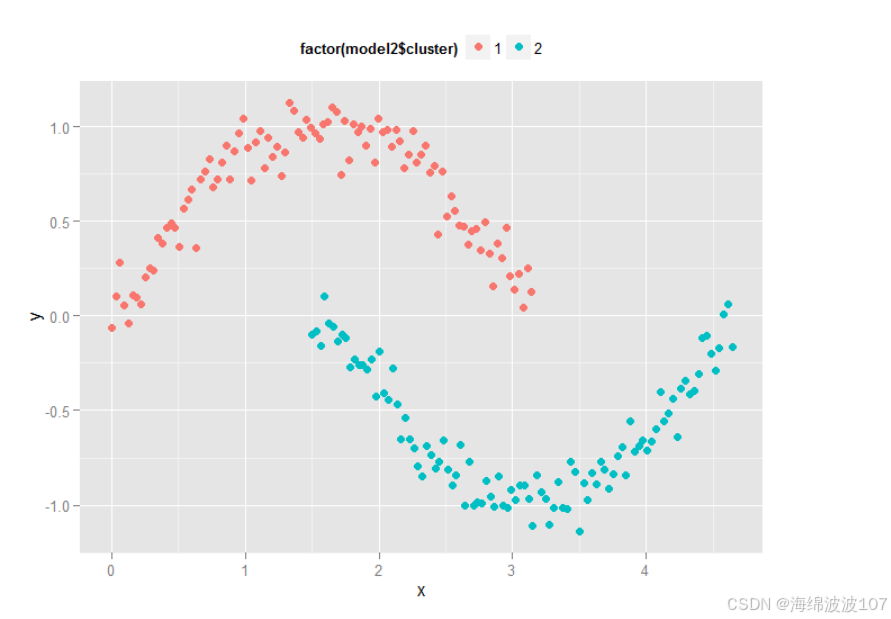
k-means
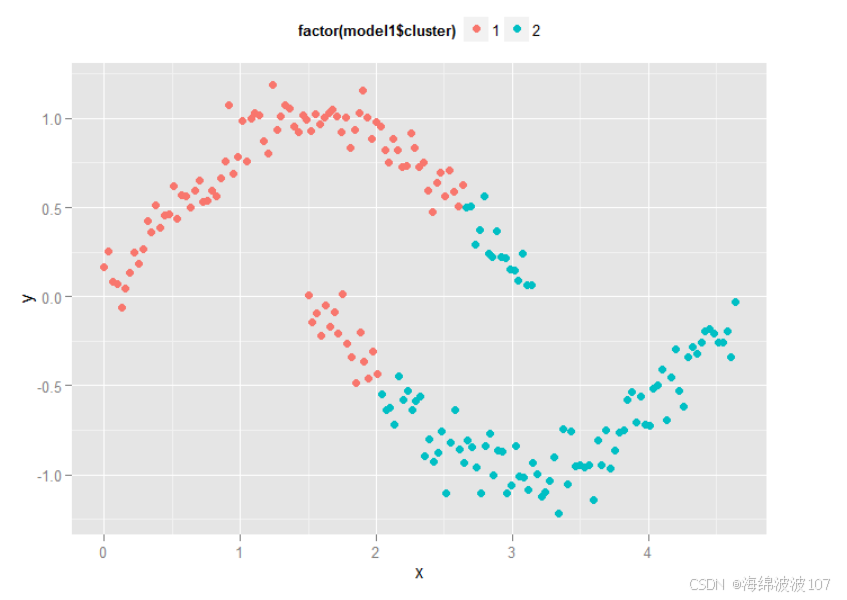
不同的数据集和场景,需要运用不同的聚类算法。
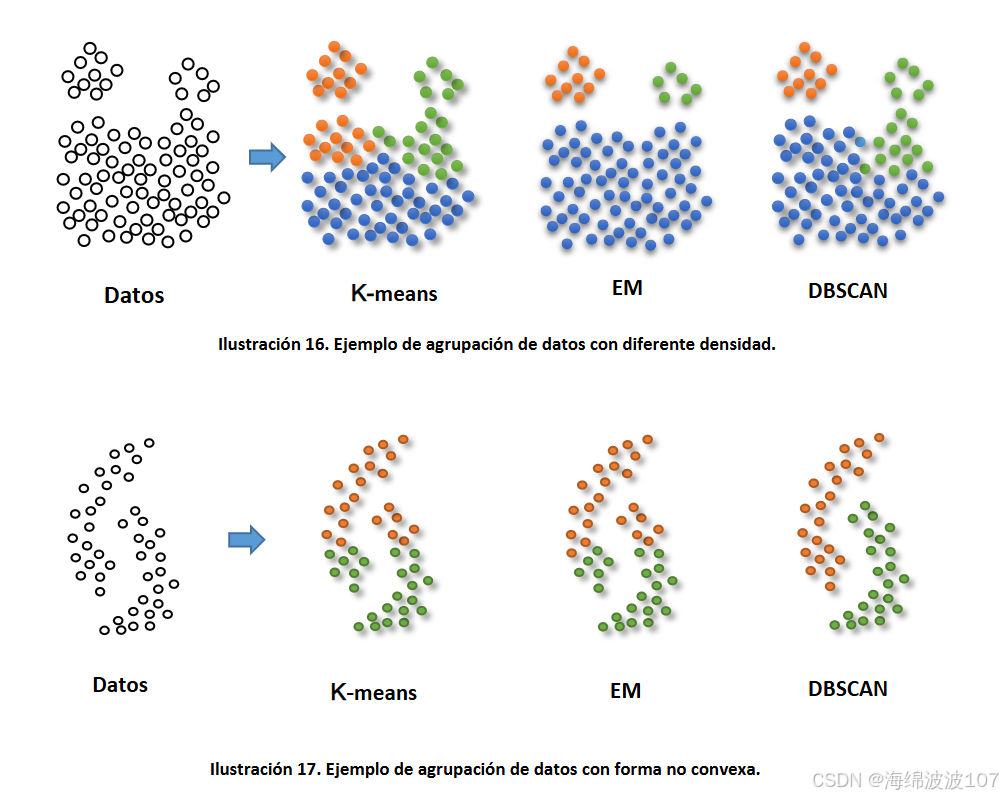
2.2 与层次聚类的关键区别
- 噪声处理:DBSCAN可显式隔离噪声层次聚类对异常值敏感。
- 簇结构 :DBSCAN捕获任意形状,层次聚类倾向生成球形簇。
- 计算效率:层次聚类复杂度高,仅适中小数据集,DBSCAN可扩展至大规模空间数据。
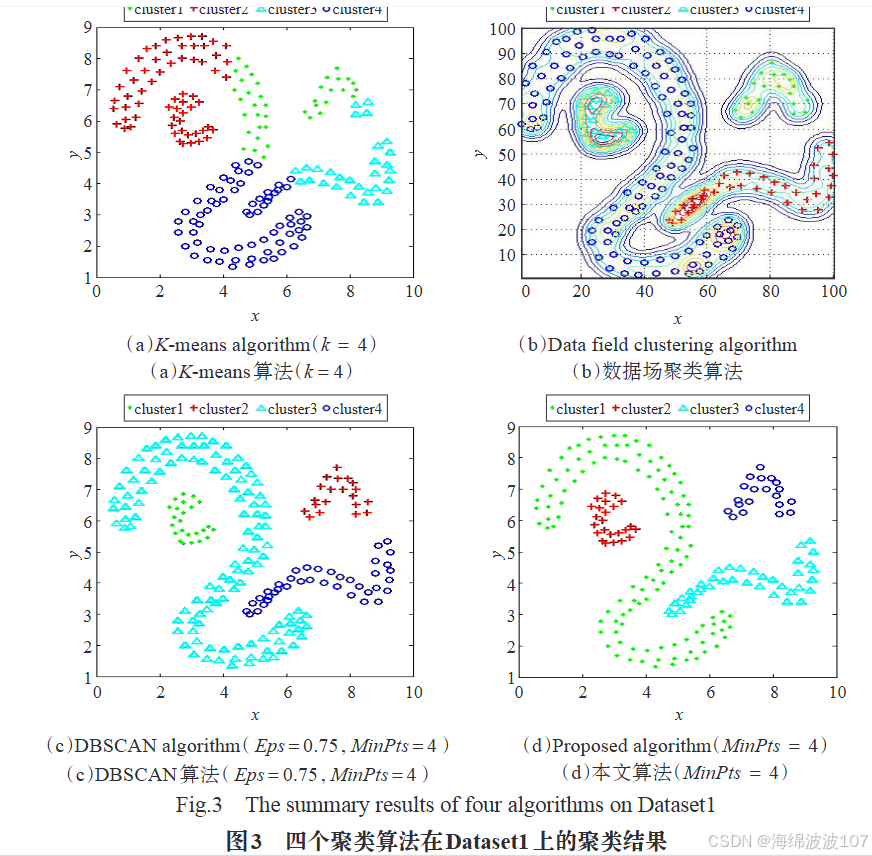
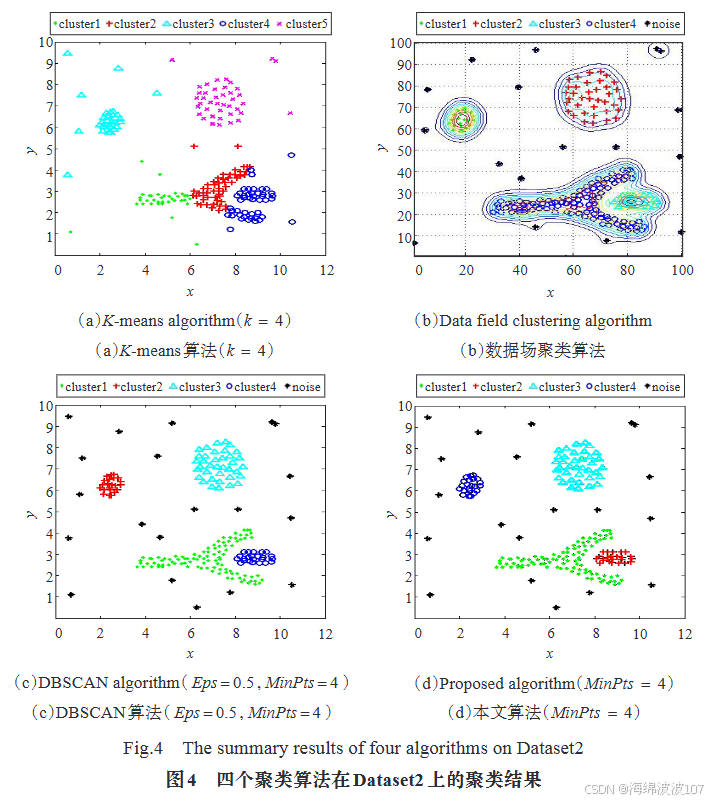
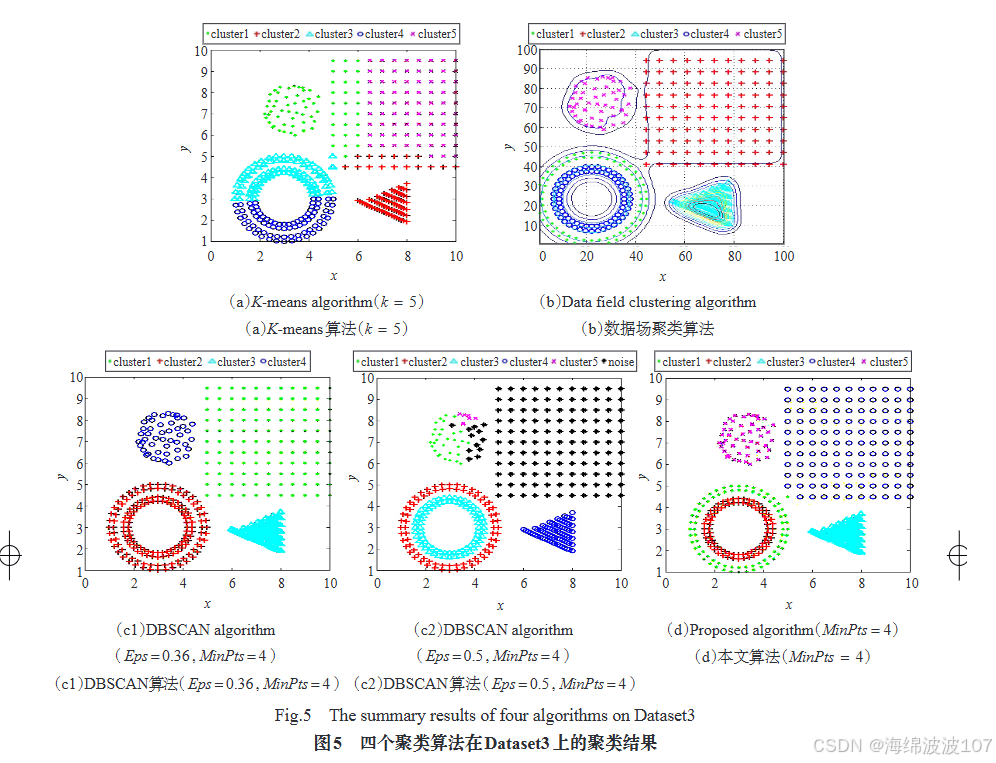
三、高维数据处理挑战与优化技术
3.1 核心瓶颈
- 维度灾难:高维空间中距离度量失效,密度计算失真。
- 参数敏感性 :固定
eps难以适应全域密度变化。
3.2 优化方案
| 方法类型 | 代表技术 | 改进效果 |
|---|---|---|
| 降维预处理 | PCA、t-SNE、UMAP | 压缩特征维度,恢复距离可区分性 |
| 参数自适应 | HDBSCAN | 动态生成eps,识别多密度层级簇 |
| 算法变种 | OPTICS | 通过可达性图替代静态参数 |
| 索引加速 | KDTree/BallTree | 加速高维邻近搜索 |
四、前沿优化与并行化实现(2020年后)
4.1 GPU加速技术
- G-DBSCAN :基于GPU构建密度连通图,较CPU实现提速112倍。
- CUDA-DClust+ :优化GPU内存通信,10亿级3D点处理提速23倍。
- Mr.Scan :65亿点数据集聚类仅需17.3分钟。
4.2 分布式与混合架构
- Spark集成:RDD-DBSCAN利用弹性数据集分区计算。
- CPU-GPU协同:HYBRID-DBSCAN通过任务拆分降低延时。
- 参数服务器:PS-DBSCAN实现超大规模集群扩展。
4.3 新型变种算法
- 密度峰值改进:融合局部密度与距离优化边界识别。
- GRPDBSCAN :网格化预处理自动生成
eps和`minPts。
五、实际应用场景与典型案例
5.1 地理空间分析
- 城市规划:识别商业中心(高密度簇)与郊野(噪声)。
- 交通管理 :检测拥堵热点(不规则簇形)。
数据集:经纬度坐标、移动设备定位流。
5.2 异常检测
- 金融风控:信用卡欺诈交易表现为孤立噪声点。
- 网络安全:异常访问IP在密度图中显著偏离主簇。
5.3 生物医学领域
- 基因表达:聚类相似表达模式的基因(任意形状簇)。
- 神经疾病诊断:患者多维特征分层聚类(HDBSCAN应用)。
5.4 商业智能
- 客户细分:环形分布用户群识别(DBSCAN形状优势)。
- 商品推荐:稀疏购买行为的噪声过滤。
六、总结与挑战展望
DBSCAN凭借噪声鲁棒性 和形状灵活性成为复杂数据聚类的首选,但其参数敏感性仍需结合业务经验。高维优化与GPU加速显著拓展了其实用边界,而生物信息学、实时物联网等领域仍是应用前沿。未来方向包括:
- 自适应参数:融合强化学习动态调参。
- 跨模态融合:联合图像、文本等多源数据聚类。
- 量子加速:探索量子计算优化距离矩阵。
源代码:
python
class FaceClusterCounter:
"""
用于根据特征聚类统计实际人数
"""
def __init__(self, eps=0.5, min_samples=1, metric='cosine'):
"""
eps: DBSCAN的半径参数,cosine距离建议0.4~0.6,l2距离建议1.0~1.2
min_samples: 最小聚类样本数,1表示单个也算一类
metric: 'cosine' 或 'euclidean'
"""
self.eps = eps
self.min_samples = min_samples
self.metric = metric
def count(self, json_path):
"""
读取json,聚类,返回聚类数和每个ID的聚类标签
"""
with open(json_path, 'r') as f:
data = json.load(f)
features = []
ids = []
for item in data:
f = item["feature"]
if isinstance(f, dict):
f = f["feature"]
features.append(f)
ids.append(item['id'])
features = np.array(features)
if len(features) == 0:
print("没有有效特征")
return 0, {}
# DBSCAN聚类
cluster = DBSCAN(eps=self.eps, min_samples=self.min_samples, metric=self.metric)
labels = cluster.fit_predict(features)
# 统计有效聚类数(去除-1噪声)
n_persons = len(set(labels)) - (1 if -1 in labels else 0)
# 构建ID到聚类标签的映射
id2label = {id_: int(label) for id_, label in zip(ids, labels)}
return n_persons, id2label这个类主要用于通过人脸特征进行聚类来统计实际人数。下面我将从多个角度深入分析这段代码。
1. 类概述
FaceClusterCounter 是一个基于 DBSCAN 聚类算法的人脸特征聚类工具,主要用于:
-
统计一组人脸特征中实际不同个体的数量
-
为每个人脸 ID 分配一个聚类标签
2. 初始化参数
python
def __init__(self, eps=0.5, min_samples=1, metric='cosine'):-
eps(默认 0.5): DBSCAN 的邻域半径参数-
对于 cosine 距离,建议 0.4~0.6
-
对于欧式距离(L2),建议 1.0~1.2
-
-
min_samples(默认 1): 形成核心点所需的最小样本数- 设为 1 表示单个人脸也能形成一个聚类
-
metric(默认 'cosine'): 距离度量方式- 可选 'cosine' (余弦相似度) 或 'euclidean' (欧式距离)
3. 核心方法 count()
python
def count(self, json_path):3.1 数据加载与预处理
python
with open(json_path, 'r') as f:
data = json.load(f)
features = []
ids = []
for item in data:
f = item["feature"]
if isinstance(f, dict):
f = f["feature"]
features.append(f)
ids.append(item['id'])
features = np.array(features)-
从 JSON 文件加载数据
-
提取特征和对应的 ID
- 处理特征可能是嵌套字典的情况(
feature字段可能包含feature子字段)
- 处理特征可能是嵌套字典的情况(
-
将特征列表转换为 NumPy 数组
3.2 空特征检查
python
if len(features) == 0:
print("没有有效特征")
return 0, {}- 如果没有有效特征,返回 0 个人和空字典
3.3 DBSCAN 聚类
python
cluster = DBSCAN(eps=self.eps, min_samples=self.min_samples, metric=self.metric)
labels = cluster.fit_predict(features)-
使用预设参数初始化 DBSCAN 聚类器
-
对特征进行聚类,得到每个样本的标签
-
标签为 -1 表示噪声点(不属于任何聚类)
-
其他数字代表不同的聚类
-
3.4 统计聚类结果
python
n_persons = len(set(labels)) - (1 if -1 in labels else 0)
id2label = {id_: int(label) for id_, label in zip(ids, labels)}
return n_persons, id2label-
计算有效聚类数
-
获取所有唯一标签(
set(labels)) -
减去 1(如果存在噪声点标签 -1)
-
-
构建 ID 到聚类标签的映射字典
- 将每个 ID 与其对应的聚类标签关联起来
-
返回:
-
n_persons: 实际人数(聚类数) -
id2label: 每个 ID 对应的聚类标签
-
4. DBSCAN 算法特点
选择 DBSCAN 作为聚类算法有几个优势:
-
不需要预先指定聚类数量
-
能识别噪声点(不适合任何聚类的点)
-
可以处理任意形状的聚类
5. 使用场景
这个类适用于以下场景:
-
从大量人脸检测结果中统计实际不同个体的数量
-
对视频或图像序列中的人脸进行身份分组
-
人脸去重,识别重复出现的人脸
这个类提供了一个简洁但功能完整的接口,用于基于人脸特征的身份聚类和统计。
features是一个512维的特征,这样也能使用DBSCAN吗
DBSCAN 算法本身没有维度限制,可以处理 512 维的人脸特征向量。不过高维数据会带来一些特殊考虑
DBSCAN 对高维数据的适用性
DBSCAN 的核心是基于距离的聚类算法,理论上可以处理任意维度的数据,包括您的 512 维人脸特征向量。但需要注意:
-
"维度诅咒"问题 :
在非常高维的空间中,所有点之间的距离会趋于相似(距离度量失效),但人脸特征通常是经过深度网络提取的低维嵌入(512 维已经算相对低维),这个问题不显著。
-
距离度量的选择 :
您已经提供了两种关键选项:
-
cosine(余弦距离):更适合人脸特征(方向比绝对距离更重要) -
euclidean(欧氏距离):需要确保特征已归一化(否则距离会被大值特征主导)
-
高维数据下的参数调整建议
关键参数:
-
eps(邻域半径):-
对于 512 维的归一化人脸特征:
-
cosine:0.4~0.6(您默认的 0.5 是合理值) -
euclidean:1.0~1.2(需确保特征已 L2 归一化)
-
-
调整方法:可以通过观察样本间距离的分布来选择(如计算所有样本对的平均距离)
-
-
min_samples:-
您设为 1 表示允许单人成簇(适合人脸聚类场景)
-
如果想过滤噪声,可以设为 2
-
验证方法:
python
# 检查特征是否适合聚类
from sklearn.neighbors import NearestNeighbors
nn = NearestNeighbors(n_neighbors=2, metric=self.metric).fit(features)
distances, _ = nn.kneighbors(features)
plt.plot(np.sort(distances[:, 1])) # 找到拐点作为 eps 的参考解决方案
为了克服 DBSCAN 在高维数据中的局限性,可以采取以下几种方法:
- 降维技术:通过主成分分析(PCA)、线性判别分析(LDA)等方法减少数据的维度,从而提高 DBSCAN 的性能。
- 特征选择:选择最相关的特征,以减少数据集的维度并提高聚类效果。
- 使用改进的 DBSCAN 变种:例如 HDBSCAN 或 OPTICS,这些变种算法能够更好地处理高维数据和不同密度的聚类。
- 并行化与分布式计算:利用 Spark 等分布式计算框架,结合 Kd-tree 等高效邻近搜索算法,可以加速 DBSCAN 在大规模高维数据上的运行。