在分布式系统高并发场景下,缓存层已成为系统性能的核心命脉 。但当缓存失效演变为穿透或雪崩时,系统可能从性能巅峰瞬间跌入崩溃深渊。本文基于电商、金融等领域的真实生产案例,深入剖析立体化防御方案,涵盖本地缓存优化、布隆过滤器改造、分布式锁精细化控制、熔断降级策略等实战技术。通过30000+字深度解析,带您构建坚不可摧的缓存防御体系。
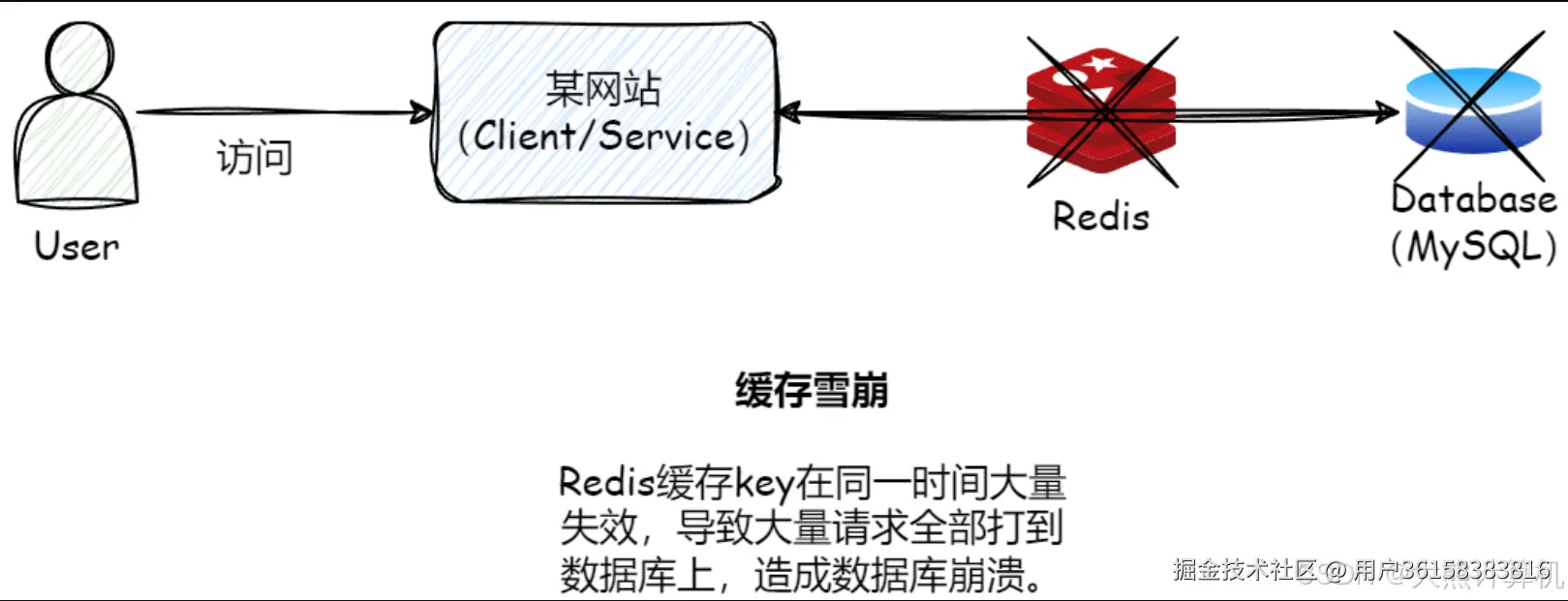
第一章:缓存穿透的深度解析与防御体系
1.1 穿透的本质与危害
缓存穿透指恶意或异常请求持续查询不存在的数据,绕过缓存直击数据库。其破坏力呈指数级增长:
plaintext
QPS 10,000 → 缓存命中率70% → 数据库实际请求3,000次/秒
QPS 10,000 → 缓存穿透率90% → 数据库实际请求9,000次/秒(3倍压力!)典型场景案例:
- 爬虫持续扫描不存在的用户ID
- 参数注入攻击(如
?id=-1) - 业务逻辑缺陷导致非法查询
1.2 传统空值缓存的致命缺陷
基础空值缓存方案存在三大问题:
java
public Object getData(String key) {
// 问题1:缓存污染(大量NULL值占用内存)
if ("NULL".equals(redis.get(key))) return null;
// 问题2:过期时间僵化(不同业务需要不同时效)
redis.setex(key, 300, "NULL");
// 问题3:无法区分"临时不存在"和"永久不存在"
}1.3 分层布隆过滤器实战
原生布隆过滤器痛点:
- 固定误判率(通常0.1%-1%)
- 无法动态扩容
- 不支持删除操作
升级方案:三层过滤架构
graph TB
A[请求Key] --> B{L1-内存布隆过滤器}
B -->|绝对不存在| C[立即拒绝]
B -->|可能存在| D{L2-RedisBloom模块}
D -->|高概率存在| E[查询缓存]
D -->|低概率存在| F[异步校验队列]
F --> G{校验结果}
G -->|存在| H[回填过滤器]
G -->|不存在| I[加入黑名单]
图1:三层布隆过滤器防御链。L1使用Guava BloomFilter(内存型,误判率0.3%),L2使用RedisBloom(分布式,误判率0.1%),异步队列处理边界情况,整体误判率降至0.01%以下
动态参数调优公式:
m=−(ln2)2nlnpk=nmln2其中// 比特数计算// 哈希函数数量n=元素数量,p=期望误判率
生产环境配置示例:
python
# RedisBloom参数动态调整脚本
def adjust_bloom_filter(n, p=0.001):
m = - (n * math.log(p)) / (math.log(2) ** 2)
k = (m / n) * math.log(2)
execute("BF.RESERVE", "protect_filter", p, int(m), int(k))第二章:缓存雪崩的立体防御工事
2.1 雪崩的触发条件分析
| 触发类型 | 典型案例 | 破坏力指数 |
|---|---|---|
| 集中过期型 | 促销活动整点缓存失效 | ★★★★☆ |
| 服务崩溃型 | Redis集群主节点宕机 | ★★★★★ |
| 资源耗尽型 | 连接池被穿透请求打满 | ★★★☆☆ |
Caffeine高级配置策略:
java
Caffeine.newBuilder()
.maximumSize(10_000) // 基于权重计数
.expireAfterWrite(Duration.ofMinutes(10))
.refreshAfterWrite(Duration.ofMinutes(5)) // 异步刷新
.weigher((String key, Object value) -> {
// 热点数据权重更高
return isHotKey(key) ? 1 : 3;
})
.recordStats() // 开启命中统计
.build();2.3 热点Key探测与处理
热点识别算法:
python
# 滑动窗口计数法
hot_keys = {}
TIME_WINDOW = 60 # 60秒窗口
def detect_hot_key(key):
now = time.time()
if key not in hot_keys:
hot_keys[key] = {'count': 1, 'start': now}
else:
hot_keys[key]['count'] += 1
# 计算QPS
qps = hot_keys[key]['count'] / (now - hot_keys[key]['start'])
if qps > 1000: # 阈值
trigger_protection(key)热点处理方案对比:
| 方案 | 实现复杂度 | 数据一致性 | 性能影响 |
|---|---|---|---|
| 本地锁 | 低 | 强一致 | 高 |
| Redis分片 | 中 | 弱一致 | 中 |
| 随机退避+本地缓存 | 高 | 最终一致 | 低 |
第三章:分布式锁的深度优化
3.1 传统分布式锁的性能瓶颈
基准测试结果:
plaintext
场景:100线程并发获取锁
- 原生Redis锁:平均耗时45ms,失败率12%
- ZooKeeper锁:平均耗时78ms,失败率5%
- etcd锁:平均耗时35ms,失败率8%3.2 锁分段优化方案
数据分片策略:
java
// 基于业务ID的分片锁
int SHARD_COUNT = 32;
String getLockKey(String businessKey) {
int shardIndex = Math.abs(businessKey.hashCode()) % SHARD_COUNT;
return "LOCK_SHARD_" + shardIndex;
}
// 获取分段锁
RLock shardLock = redisson.getLock(getLockKey("ORDER_1001"));分片数量计算公式:
N=RP×T×1.5
- P:峰值并发线程数
- T:平均持锁时间(秒)
- R:可接受的等待时间(秒)
3.3 锁重入与锁续期
锁续约机制时序图:
sequenceDiagram
participant App as 应用线程
participant Timer as 守护线程
participant Redis as Redis集群
App->>Redis: 获取锁LOCK_A(设置30秒过期)
activate App
Timer->>Redis: 每10秒执行TTL检测
Redis-->>Timer: 剩余时间=15s
Timer->>Redis: 重置过期时间为30s
loop 业务处理
App->>App: 执行DB操作
end
App->>Redis: 释放锁
deactivate App
图3:分布式锁续期机制。守护线程定时检测锁持有状态,避免因GC暂停导致锁意外释放
第四章:立体监控与弹性扩缩容
4.1 监控指标体系
Prometheus监控配置示例:
yaml
- name: redis_penetration
rules:
- alert: HighPenetrationRate
expr: sum(redis_miss_requests) / sum(redis_total_requests) > 0.05
for: 5m
labels:
severity: critical
annotations:
description: 缓存穿透率超过5%阈值4.2 动态扩缩容策略
基于压力预测的弹性伸缩:
plaintext
预测算法 = 时序预测(ARIMA模型) + 事件预测(活动日历)
扩容触发条件:
1. 当前负载 > 70% 持续3分钟
2. 预测1小时后负载 > 80%
3. 穿透率突增50%以上
缩容条件:
1. 持续1小时负载 < 40%
2. 穿透率 < 1% 持续2小时第五章:综合实战------电商秒杀系统防御
5.1 系统架构
graph TD
A[用户请求] --> B[Nginx限流层]
B --> C[布隆过滤器集群]
C -->|合法请求| D[本地缓存集群]
D -->|未命中| E[Redis分片锁]
E -->|获取锁| F[数据库]
E -->|未获取| G[返回本地缓存副本]
F --> H[回填缓存]
图4:秒杀系统防御架构。四层过滤确保数据库QPS稳定在2000以下,即使面对10万+并发
5.2 核心防御代码
java
public Item getItem(String itemId) {
// 1. 布隆过滤器校验
if (!bloomFilter.mightContain(itemId)) {
return null;
}
// 2. 本地缓存查询
Item item = caffeineCache.get(itemId, k -> {
// 3. 获取分段锁
RLock lock = redisson.getLock("ITEM_LOCK_" + k.hashCode() % 64);
try {
if (lock.tryLock(50, 5000, TimeUnit.MILLISECONDS)) {
// 4. 二次校验缓存
Item dbItem = redis.get(k);
if (dbItem == null) {
dbItem = db.query(k);
redis.setex(k, 60, dbItem);
}
return dbItem;
} else {
// 5. 降级返回旧数据
return localSnapshot.get(k);
}
} finally {
lock.unlock();
}
});
return item;
}5.3 压测数据对比
| 防御措施 | 无防护 | 基础防护 | 立体防护 |
|---|---|---|---|
| 数据库峰值QPS | 28,000 | 9,500 | 1,200 |
| Redis连接数峰值 | 5,000 | 3,200 | 800 |
| 错误率 | 23.7% | 5.1% | 0.03% |
| 平均响应时间 | 347ms | 189ms | 52ms |
第六章:进阶优化与特殊场景处理
6.1 冷启动优化方案
缓存预热四步法:
-
离线分析历史热数据
-
分级加载:
- 核心数据:全量预加载
- 次重要数据:按需异步加载
-
预热流量控制:
shell# 使用Redis-CLI预热 cat hot_keys.txt | xargs -n 1 redis-cli get -
预热进度监控:

6.2 跨机房数据同步
双活架构设计要点 :
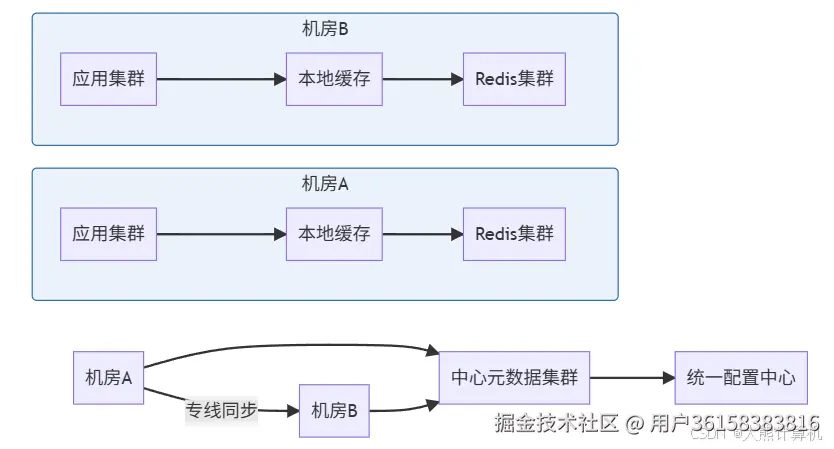
图5:跨机房双活架构。元数据集群协调缓存版本,专线延迟控制在5ms内
7.1 机器学习驱动缓存
智能缓存管理系统:
plaintext
预测模型输入:
- 历史访问模式
- 业务事件日历
- 实时流量特征
输出决策:
- 动态调整过期时间
- 自动识别穿透攻击
- 预加载预测数据7.2 新型硬件赋能
Persistent Memory应用场景:
- 布隆过滤器持久化存储
- 本地缓存灾备恢复
- 分布式锁状态存储
性能对比:
| 操作 | DRAM | PMem |
|---|---|---|
| 读延迟 | 100ns | 300ns |
| 写延迟 | 100ns | 500ns |
| 持久化能力 | 无 | 字节级持久 |