(论文蒸馏)机器学习框架中的供应链攻击
论文元数据
原英文标题:Supply-Chain Attacks in Machine Learning Frameworks
原文链接:mlsys.org/virtual/2025/poster/3276
研究背景&动机
供应链攻击是开源软件(OSS)发展的重大威胁,针对机器学习(ML)的供应链攻击和其他传统的非ML的供应链攻击相比,不仅有着传统的供应链安全风险,还有着机器学习独有的安全风险,例如底层模型的普遍存在对抗样本、成员推理攻击、模型窃取攻击等安全与隐私漏洞。
大部分ML代码库用python等解释型语言编写,由于Python本身具有高度的动态特性,保障ML生态系统的安全性颇具挑战。其中一个挑战是,在Python代码库中,任何依赖包都能访问其他包的完整内存空间和下游应用的调用栈,所以可以在运行时读取或修改关键变量。因此一旦Python包被攻陷,就会有重大安全风险。此外,ML社区和其他传统社区相似,开发者大多缺乏供应链安全意识,经常出现不安全编程的行为。
文章就这些背景,提出了一系列以Python代码注入为基础的针对ML的供应链攻击,并开展了一系列对社区安全意识的分析调查。
相关工作
供应链
对于开源软件的供应链安全有两大研究方向。一种是软件包分析,通过各种途径和手段对包管理器进行分析,研究和发现其中的恶意软件包,从而开发预防性和检测性防护措施;另一种则是建立风险与保障措施的分类体系,例如,2023年的工作提出了一个针对开源供应链攻击的通用分类法,总结了33种针对OSS供应链攻击的缓解措施。
对于当前ML供应链安全的研究,主要集中在算法层面的攻击;其中又重点在投毒攻击和后门攻击上。同时,安全文献指出,其他不仅存在于模型本身,还广泛存在于底层基础设施中的供应链环节也存在漏洞。具体而言,攻击者可能对模型检查点、ML编译器、模型架构、伪随机数生成器等多个方面进行攻击。因此,要想防范ML供应链攻击,就必须考虑种类更多的潜在漏洞。需要注意,ML框架是供应链攻击中的特殊攻击目标,因为它支持更强大隐蔽的攻击,而且必须结合ML专业知识对其进行防护才能有效。
针对ML的特殊供应链攻击
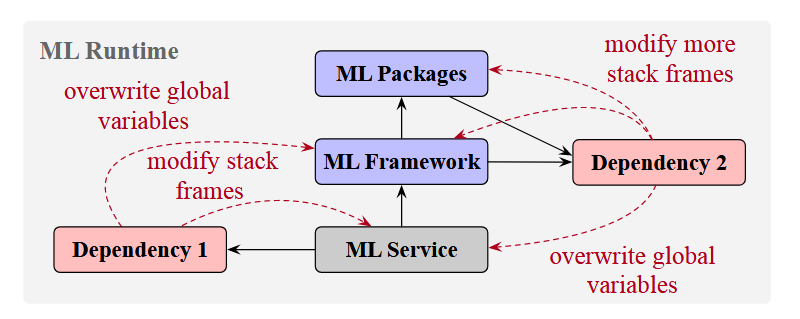
变量覆写
传统的供应链攻击主要聚焦于恶意代码注入和后门注入攻击,而机器学习在这些风险下需要特殊论证。传统的攻击主要依赖敏感的系统调用,且涉及可疑的网络流量,因此能被常规检测到;而ML框架可以被利用传统漏洞注入看似无害的代码,但却成功削弱其鲁棒性。
具体而言,假设使用常见的python及各种ML包进行开发,且已经针对ML可能遭受的常见攻击和传统的供应链攻击搭建了防御体系;攻击者可以向开源依赖包提交恶意代码,但这些代码不会触发传统供应链攻击会出发的异常情况。
整个体系的薄弱点在于:
-
如果某个ML服务导入了某个(可以是传递性的)依赖包,就隐式的授权这个包在运行时读写所有变量和源代码。
-
软件包可以通过直接修改引用来覆盖彼此的全局对象。如果软件包A在初始化时导入了软件包B,且将B中的内容进行了覆写(篡改),那么即使后续再次导入了软件包B,其中的内容依然会保持被篡改的状态。(也正是因此,在之前出现过利用导入顺序实施恶意操作的情况)
-
当在函数中调用上游的被篡改的函数时,下游函数的局部变量也有可能被修改。
原文给出的示意图如下所示。
漏洞注入
攻击者对ML服务实施攻击时,主要目标是通过漏洞注入实现。常见的有后门攻击、管道攻击、模型窃取等。
后门攻击
传统的针对模型的后门攻击发生在预训练阶段,主要以数据投毒攻击和算法篡改来迫使模型学习后门;但是也可以针对模型架构攻击,或者直接篡改模型检查点。文章中有提到了一种方式:通过覆写模型的推理函数实现对推理过程的控制。
例如,对于视觉模型的推理,攻击者可以拦截模型的前向传播函数,只要输入包含特定触发标记即可返回预设输出。通过控制推理函数,可以使用更精确、更隐蔽的触发器,甚至只需要几个像素即可;对于语言模型的推理,可以通过直接将越狱后门通过附加到输入末尾的方式隐藏在tokenizer中。这种攻击无法用传统方式破解,必须在嵌入空间层面检测输入的潜在恶意行为。
管道攻击
ML模型只是现实大型ML服务管道的一部分,因此还可以向其他组件注入漏洞。例如图像缩放攻击就是使用不安全的插值算法实现攻击。通过覆写依赖项,也可以隐式的实现这种攻击。
模型窃取
控制推理函数之后,攻击者可以无需额外流量就试试模型窃取攻击。只需遍历调用栈和各种变量进行搜索,然后将各种参数名和值利用如隐写术等方式编码至推理输出即可。可以利用如图像缩放攻击等方式限制攻击的特定触发条件。
防御绕过
除了对于依赖进行攻击以外,还可以对防御措施进行禁用。例如,防御越狱攻击的传统手段是向专用服务验证用户请求是否恶意,而这可以被恶意函数拦截;防御模型窃取的常见策略是验证查询与决策边界的距离,多个查询异常接近时,系统会标记其为恶意请求并拒绝。而这可以通过覆写softmax进行拦截,进而达到模型性能不变但是异常接近不会被检测到。
总结起来,必须考虑ML生态系统中各个软件包间的的交互和信任关系,才能缓解文章提到的上述风险。
供应链安全研究调研
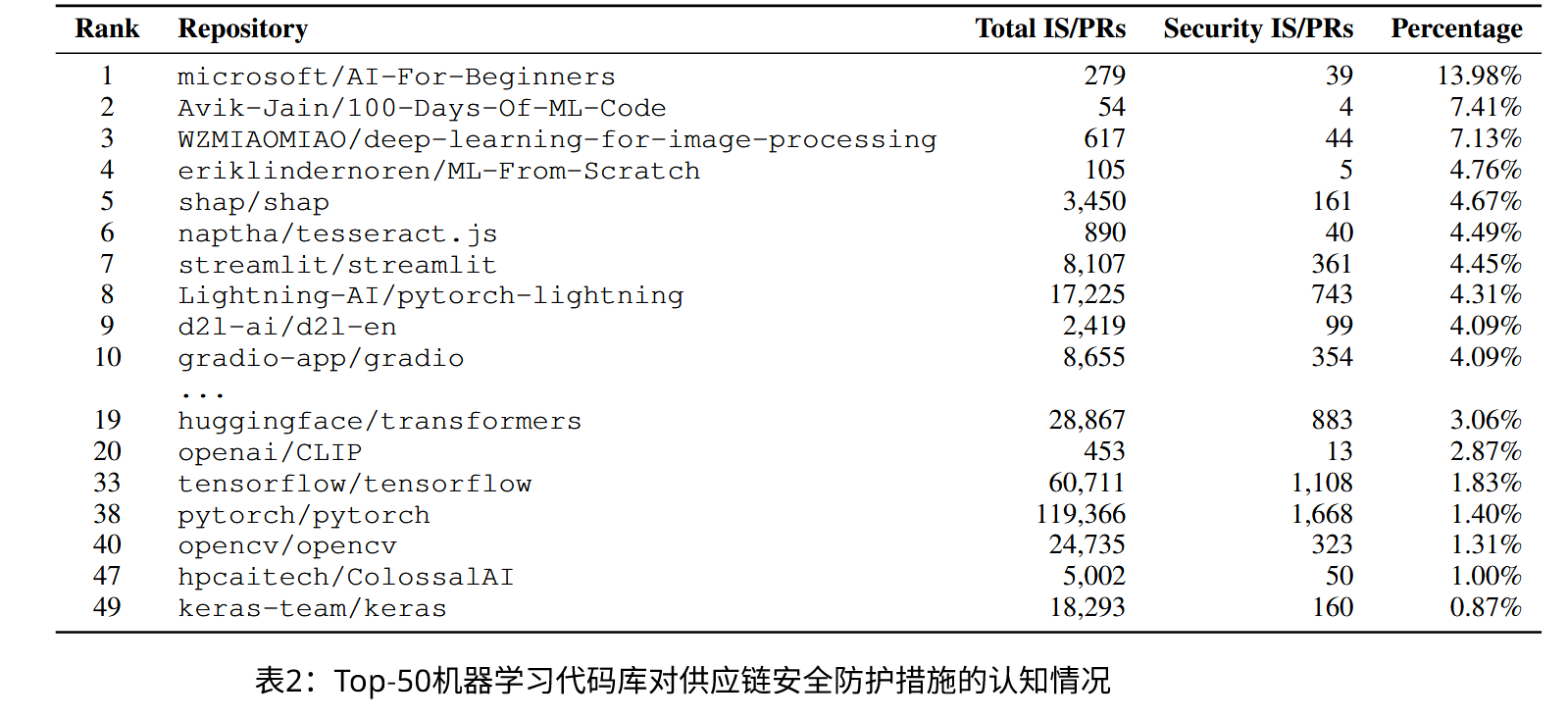
如果想研究开源社区里成员的供应链安全意识,最简单的方式就是查看其中的议题和拉取请求(IS/PRs)是否涉及。研究团队使用大模型辅助筛选了50个深度学习热门项目的近55万条IS/PRs数据集,并且人工验证了大模型的相对准确性。
现象
对于这50个项目而言,入门和示范相关的项目中安全相关的IS/PRs最多,突破了5%;其他则涉及基础框架和基于这些框架的高级项目。这些ML框架的安全相关IS/PR比例普遍低于下游项目。如果把视角上升到整个ML领域又能发现,高影响力的项目对安全意识的讨论又往往低于低影响力的项目。
而且,实际上,ML库对供应链攻击的防范实际上是副产品。版本锁定、拼写错误检测和依赖项解析规则是这些项目中最受欢迎的三种防护机制,然而这些讨论更多是为了模型性能和服务能力的提升,而非主要为了防范供应链攻击。反倒是真正为了安全的PRs有时候会被拒绝,通常是因为维护者认为这些PRs价值不足等。
在更大的视角中,ML项目和非ML项目的安全意识分布是极其类似的------都很少。只有少数例外项目有突出的表现。
原文统计数据如下:
讨论
可能的防护措施:
-
分析所有相关依赖包的源代码,对可能的篡改进行检查。这种措施应当由有ML经验的安全工程师参与评估。
-
可以建立独立的守护进程检查内存并进行完整性验证,不过会比较复杂。
-
对于安全敏感的ML应用,可以将ML包迁移至编译型语言,从而利用这种语言更完善的安全特性。