思维导图
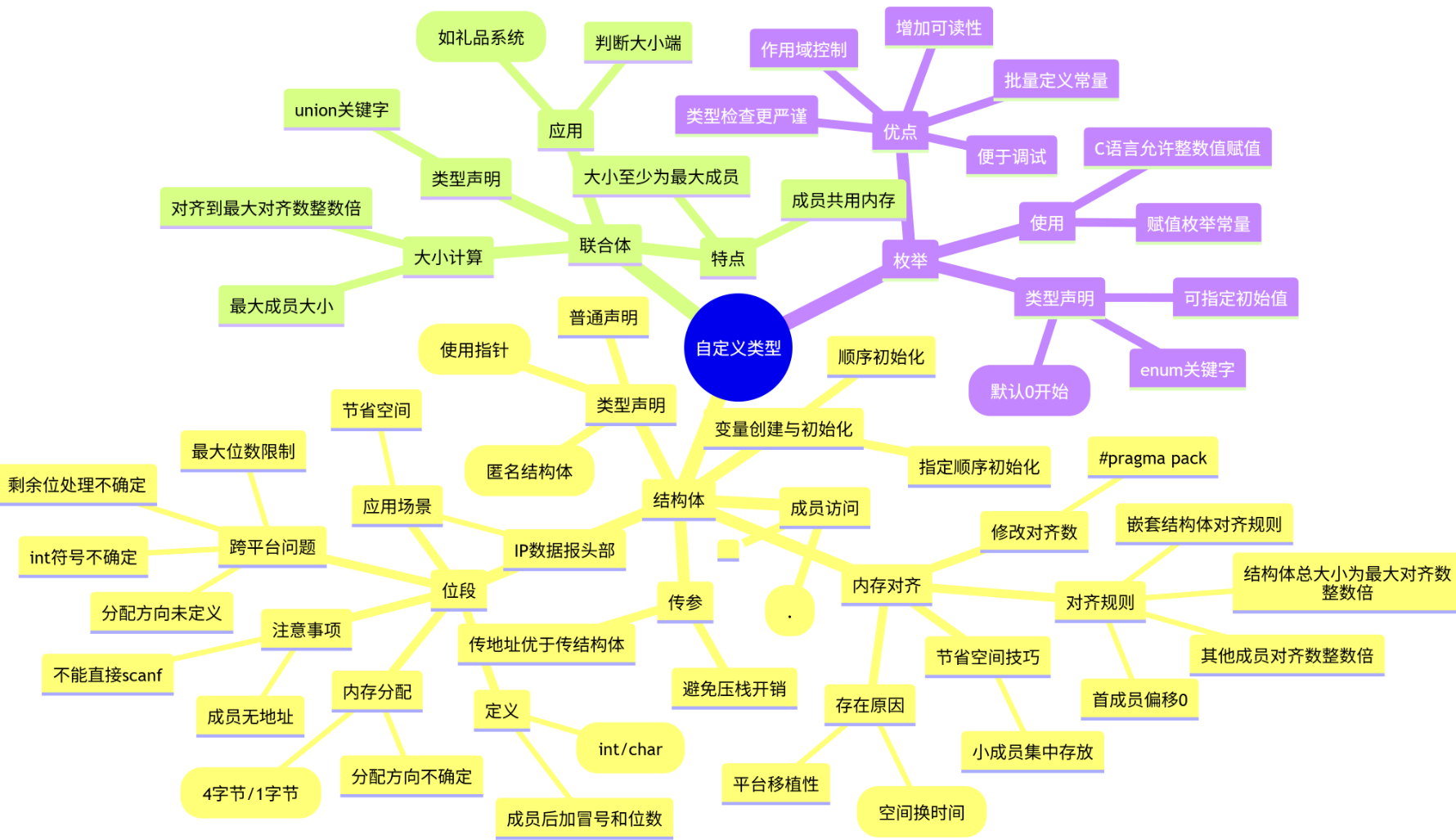
1. 结构体类型的声明
前⾯我们在学习操作符的时候,已经学习了结构体的知识,这⾥稍微复习⼀下。
1.1 结构体
结构是⼀些值的集合,这些值称为成员变量。
结构的每个成员可以是不同类型的变量。
ps: 能把相关信息整合在一起,比如描述学生时,把姓名、年龄等放一起 。
1.1.1 结构的声明
cs
struct tag
{
member-list;
}variable-list;ps: variable-list 的作用就是声明具有特定结构体类型的变量,方便后续对这些变量中的成员数据进行访问和操作。
例如描述⼀个学⽣:
cs
struct Stu
{
char name[20];//名字
int age;//年龄
char sex[5];//性别
char id[20];//学号
}; //分号不能丢1.1.2 结构体变量的创建和初始化
cs
#include <stdio.h>
struct Stu
{
char name[20];//名字
int age;//年龄
char sex[5];//性别
char id[20];//学号
};
int main( )
{
//按照结构体成员的顺序初始化
struct Stu s = { "张三", 20, "男", "20230818001" };
printf("name: %s\n", s.name);
printf("age : %d\n", s.age);
printf("sex : %s\n", s.sex);
printf("id : %s\n", s.id);
//按照指定的顺序初始化
struct Stu s2 = { .age = 18, .name = "lisi", .id = "20230818002", .sex =
"⼥" };
printf("name: %s\n", s2.name);
printf("age : %d\n", s2.age);
printf("sex : %s\n", s2.sex);
printf("id : %s\n", s2.id);
return 0;
}1.2 结构的特殊声明
在声明结构的时候,可以不完全的声明。
⽐如:
cs
//匿名结构体类型
struct
{
int a;
char b;
float c;
}x;
struct
{
int a;
char b;
float c;
}a[20], *p;上面的两个结构在声明的时候省略掉了结构体标签(tag)。
那么问题来了?
cs
//在上⾯代码的基础上,下⾯的代码合法吗?
p = &x;- x 是第一个匿名结构体的变量。
- p 是第二个匿名结构体的指针。
看起来两个结构体的成员(int a; char b; float c;)完全一样,但编译器不认!
原因:C 语言里,结构体的「类型」由「标签(tag)」或者「完整定义」区分。匿名结构体没有标签,编译器会把每一个匿名结构体的定义,当成独立的新类型。
所以:
- 第一个匿名结构体是「类型 A」,x 是类型 A 的变量。
- 第二个匿名结构体是「类型 B」,p 是类型 B 的指针。
类型 A 和类型 B 毫不相干,自然不能把 x(类型 A)的地址赋值给 p(类型 B 的指针)------ 编译器会报错,说 "类型不匹配"。
1.2.1匿名结构体的特点
只能用一次:因为没有标签,无法复用定义。想再定义新的变量 / 指针,只能重新写一遍结构体(但重新写的又会被当新类型)。
**类型独立:**即使成员完全一样,两个匿名结构体也是不同类型,变量 / 指针不能混用。
如果想让结构体可复用、类型统一,必须给结构体加标签(tag),比如:
cs
// 加标签 "MyStruct",成为有名结构体
struct MyStruct
{
int a;
char b;
float c;
};
// 用标签定义变量、数组、指针,类型统一
struct MyStruct x, a[20], *p;
// 合法!因为都是 "struct MyStruct" 类型
p = &x;警告:
编译器会把上⾯的两个声明当成完全不同的两个类型,所以是非法的。
匿名的结构体类型,如果没有对结构体类型重命名的话,基本上只能使用⼀次。
1.3 结构的自引用
在结构中包含⼀个类型为该结构本⾝的成员是否可以呢?
⽐如,定义⼀个链表的节点:
cs
struct Node
{
int data;
struct Node next;
}上述代码正确吗?如果正确,那 sizeof(struct Node) 是多少?
仔细分析,其实是不⾏的,因为⼀个结构体中再包含⼀个同类型的结构体变量,这样结构体变量的⼤小就会⽆穷的⼤,是不合理的。
ps: 如果你存的是 整个结构体next,那 next 里又得存一个 next,next 里的 next 还得存...... 永远套娃,结构体就会 "无限大",编译器直接不干了(这谁存得下啊!)。
正确的⾃引用方式:
cs
struct Node
{
int data; // 存数据
struct Node* next; // 存下一个节点的地址(指针)
};- 指针存的是 "地址",不管你结构体多大,地址就那么 4/8 个字节(很小)。
- 这样每个节点里的 next 只存 "下一个节点在哪",不会无限套娃,完美解决问题!
在结构体⾃引⽤使⽤的过程中,夹杂了 typedef 对匿名结构体类型重命名,也容易引⼊问题,看看
下⾯的代码,可⾏吗?
有些人喜欢用typedef给结构体取别名,想偷懒写成这样:
cs
typedef struct
{
int data;
Node* next;
}Node;ps: Node 是后面才用 typedef 定义的别名,但你在结构体里提前用 Node 了,编译器根本不认识 "Node 是啥",直接报错。
答案:
是不⾏的,因为Node是对前⾯的匿名结构体类型的重命名产⽣的,但是在匿名结构体内部提前使
⽤Node类型来创建成员变量,这是不⾏的。
解决⽅案如下:定义结构体不要使⽤匿名结构体了
1.3.1 正确的 typedef + 自引用 写法
得让编译器先认识 struct Node,再取别名:
cs
typedef struct Node
{ // 先定义带标签的结构体
int data;
struct Node* next; // 用标签引用自己(指针版)
} Node; // 最后给结构体取别名 Node这样编译器能一步步看懂:先有 struct Node,再用指针引用,最后别名也生效。
ps:结构体自引用要靠指针实现,且注意 typedef 配合时的定义顺序,这是写链表、树等结构的基础。
2. 结构体内存对齐
我们已经掌握了结构体的基本使⽤了。
现在我们深⼊讨论⼀个问题:计算结构体的⼤⼩。
2.1 对齐规则
⾸先得掌握结构体的对⻬规则:
- 结构体的第⼀个成员对⻬到和结构体变量起始位置偏移量为0的地址处
- 其他成员变量要对⻬到某个数字(对⻬数)的整数倍的地址处。
对⻬数 = 编译器默认的⼀个对⻬数 与 该成员变量⼤⼩的较⼩值。
- VS 中默认的值为 8
- Linux中 gcc 没有默认对⻬数,对⻬数就是成员⾃⾝的⼤⼩
- 结构体总⼤⼩为最⼤对⻬数(结构体中每个成员变量都有⼀个对⻬数,所有对⻬数中最⼤的)的
整数倍。 - 如果嵌套了结构体的情况,嵌套的结构体成员对⻬到⾃⼰的成员中最⼤对⻬数的整数倍处,结构
体的整体⼤⼩就是所有最⼤对⻬数(含嵌套结构体中成员的对⻬数)的整数倍。
cs
//练习1
struct S1
{
char c1;
int i;
char c2;
};
printf("%d\n", sizeof(struct S1));
//练习2
struct S2
{
char c1;
char c2;
int i;
};
printf("%d\n", sizeof(struct S2));
//练习3
struct S3
{
double d;
char c;
int i;
};
printf("%d\n", sizeof(struct S3));
//练习4-结构体嵌套问题
struct S4
{
char c1;
struct S3 s3;
double d;
};
printf("%d\n", sizeof(struct S4));ps:其实核心就是 "成员变量的顺序会影响结构体整体大小" ,因为要满足 内存对齐规则。
1. 内存对齐的本质:"让 CPU 访问更高效"
- CPU 读取内存时,不是一个字节一个字节读,而是 按 "块"(比如 4、8 字节)读取。
- 如果变量乱序存放,可能跨 "块",CPU 得读两次再拼接,效率低。所以编译器会自动给变量 "留白"(填充空字节),保证每个变量都对齐到 "合适的位置",让 CPU 一次读完。
2. 关键规则
规则其实就两句话:
每个成员变量:要对齐到「自身大小」和「默认对齐数」中较小值的整数倍位置。
- 比如 int 大小是 4,默认对齐数(VS 中是 8),所以对齐到 4 的倍数(取较小值)。
- 比如 char 大小是 1,对齐到 1 的倍数(怎么放都满足)。
结构体整体:大小是「最大对齐数」的整数倍(最大对齐数是所有成员对齐数里最大的那个)。
例子 1:成员顺序差,导致 "填充多"
cs
struct S1
{
char c1; // 占1字节
int i; // 占4字节,要对齐到4的倍数
char c2; // 占1字节
};- c1 存在第 0 位(没问题)。
- i 要对齐到 4 的倍数,所以 c1 后面填 3 个空字节,让 i 从第 4 位开始。
- c2 存在第 8 位,但结构体整体要对齐到最大对齐数(这里是 4)的倍数,所以最后再填 3 个空字节,总大小凑成 12(4 的倍数)。
例子 2:成员顺序好,"填充少"
cs
struct S2
{
char c1; // 1字节
char c2; // 1字节
int i; // 4字节
};- c1、c2 连续存在 0、1 位(都占 1 字节,不用填充)。
- i 要对齐到 4 的倍数,所以 c2 后面填 2 个空字节,让 i 从第 4 位开始。
- 整体大小是 8(最大对齐数是 4,8 是 4 的倍数),比 S1 小很多!
2.2 为什么存在内存对齐?
⼤部分的参考资料都是这样说的:
- 平台原因 (移植原因):
不是所有的硬件平台都能访问任意地址上的任意数据的;某些硬件平台只能在某些地址处取某些特定类型的数据,否则抛出硬件异常。 - 性能原因:
数据结构(尤其是栈)应该尽可能地在⾃然边界上对⻬。原因在于,为了访问未对⻬的内存,处理器需要作两次内存访问;⽽对⻬的内存访问仅需要⼀次访问。假设⼀个处理器总是从内存中取8个字节,则地址必须是8的倍数。如果我们能保证将所有的double类型的数据的地址都对⻬成8的倍数,那么就可以用⼀个内存操作来读或者写值了。否则,我们可能需要执⾏两次内存访问,因为对象可能被分放在两个8字节内存块中。
总体来说:结构体的内存对齐是拿空间来换取时间的做法。
那在设计结构体的时候,我们既要满⾜对⻬,⼜要节省空间,如何做到:
让占⽤空间⼩的成员尽量集中在⼀起
cs
//例如:
struct S1
{
char c1;
int i;
char c2;
};
struct S2
{
char c1;
char c2;
int i;
};S1 和 S2 类型的成员⼀模⼀样,但是 S1 和 S2 所占空间的⼤⼩有了⼀些区别。
2.3 修改默认对⻬数
#pragma 这个预处理指令,可以改变编译器的默认对⻬数。
cs
#include <stdio.h>
#pragma pack(1)//设置默认对⻬数为1
struct S
{
char c1;
int i;
char c2;
};
#pragma pack()//取消设置的对⻬数,还原为默认
int main()
{
//输出的结果是什么?
printf("%d\n", sizeof(struct S));
return 0;
}结构体在对⻬⽅式不合适的时候,我们可以⾃⼰更改默认对⻬数。
ps:实际编程中,即使用了内存对齐优化,填充依然可能存在 ,只是通过合理安排成员顺序或使用#pragma pack可以大幅减少,而不是完全消除。
我自己举个例子更好理解:
C 语言规定:结构体的总大小必须是其 "最大对齐数" 的整数倍(最大对齐数是所有成员对齐数中的最大值)。
cs
struct S
{
char c1; // 1字节(对齐数1)
char c2; // 1字节(对齐数1)
int i; // 4字节(对齐数4)
};- 成员总大小:1+1+4=6 字节,但最大对齐数是 4,所以结构体总大小必须是 4 的倍数(6→8),末尾需要填充 2 字节。
- 这种填充是 "结构性" 的,无法通过调整顺序消除,只能通过#pragma pack(1)强制取消(但可能影响效率)。
对这个结构体用 #pragma pack(1) 后,不会有任何填充,大小刚好是成员实际占用的 6 字节。
3. 结构体传参
cs
struct S
{
int data[1000];
int num;
};
struct S s = {{1,2,3,4}, 1000};
//结构体传参
void print1(struct S s)
{
printf("%d\n", s.num);
}
//结构体地址传参
void print2(struct S* ps)
{
printf("%d\n", ps->num);
}
int main()
{
print1(s); //传结构体
print2(&s); //传地址
return 0;
}上⾯的 print1 和 print2 函数哪个好些?
答案是:⾸选print2函数。
原因:
函数传参的时候,参数是需要压栈,会有时间和空间上的系统开销。
如果传递⼀个结构体对象的时候,结构体过⼤,参数压栈的的系统开销⽐较⼤,所以会导致性能的下
降。
结论:结构体传参的时候,要传结构体的地址。
ps:详细分析就是:
print2(传地址)好主要是 性能和效率层面的关键原因,当然可读性也能沾边
1. 最核心:传结构体对象,会拷贝整个结构体(超费内存 + 时间)
看代码里的结构体:
cs
struct S
{
int data[1000]; // 这一个数组就占 1000*4 = 4000 字节
int num; // 4 字节
};- print1 传结构体对象:调用 print1(s) 时,会把 s 里的 所有数据(包括 1000 个 int)完整拷贝一份,压到函数调用栈里。光是 data1000 就占 4000 字节,加上 num,总共要拷贝 4004 字节!
- print2 传地址:调用 print2(&s) 时,只需要拷贝 8 字节(64 位系统)或 4 字节(32 位系统)的地址 到栈里。地址大小是固定的,不管结构体多大,传地址的开销几乎可以忽略。
简单说:传对象是 "搬整个家",传地址是 "告诉对方我家在哪",前者又慢又占空间,后者轻快。这边可读性也是附加好处,操作逻辑更直观。
- 传地址时,用 ps->num 访问成员,能明确感觉到是 "操作原始结构体的地址",不会有额外拷贝;
- 传对象时,s.num 虽然写法简单,但背后默默做了大量拷贝,对新手容易隐藏性能开销。
极端来说:
假设结构体里有 int data1000000(100 万个 int,占 4MB):
- 传对象:每次调用函数,都要拷贝 4MB 数据到栈里,栈空间瞬间爆炸(栈默认就几 MB 大小),程序直接崩溃;
- 传地址:不管结构体多大,永远只拷贝 8 字节地址,稳稳运行。
4. 结构体实现位段
结构体讲完就得讲讲结构体实现位段的能⼒。
4.1 什么是位段
位段的声明和结构是类似的,有两个不同:
- 位段的成员必须是 int、unsigned int 或signed int ,在C99中位段成员的类型也可以
选择其他类型。
- 位段的成员名后边有⼀个冒号和⼀个数字。
比如:
cs
struct A
{
int _a:2;
int _b:5;
int _c:10;
int _d:30;
};A就是⼀个位段类型。
那位段A所占内存的⼤⼩是多少?
cs
printf("%d\n", sizeof(struct A));4.2 位段的内存分配
- 位段的成员可以是 int unsigned int signed int 或者是 char 等类型
- 位段的空间上是按照需要以4个字节( int )或者1个字节( char )的⽅式来开辟的。
- 位段涉及很多不确定因素,位段是不跨平台的,注重可移植的程序应该避免使⽤位段。
cs
//⼀个例⼦
struct S
{
char a:3;
char b:4;
char c:5;
char d:4;
};
struct S s = {0};
s.a = 10;
s.b = 12;
s.c = 3;
s.d = 4;
//空间是如何开辟的?4.3 位段的跨平台问题
- int 位段被当成有符号数还是⽆符号数是不确定的。
- 位段中最⼤位的数⽬不能确定。(16位机器最⼤16,32位机器最⼤32,写成27,在16位机器会
出问题。- 位段中的成员在内存中从左向右分配,还是从右向左分配,标准尚未定义。
- 当⼀个结构包含两个位段,第⼆个位段成员⽐较⼤,⽆法容纳于第⼀个位段剩余的位时,是舍弃
剩余的位还是利⽤,这是不确定的。
总结:
跟结构相⽐,位段可以达到同样的效果,并且可以很好的节省空间,但是有跨平台的问题存在。
4.4 位段的应用
下图是⽹络协议中,IP数据报的格式,我们可以看到其中很多的属性只需要⼏个bit位就能描述,这⾥使⽤位段,能够实现想要的效果,也节省了空间,这样⽹络传输的数据报⼤⼩也会较⼩⼀些,对⽹络的畅通是有帮助的。
4.5 位段使用的注意事项
位段的⼏个成员共有同⼀个字节,这样有些成员的起始位置并不是某个字节的起始位置,那么这些位置处是没有地址的。内存中每个字节分配⼀个地址,⼀个字节内部的bit位是没有地址的。
所以不能对位段的成员使⽤&操作符,这样就不能使⽤scanf直接给位段的成员输⼊值,只能是先输⼊放在⼀个变量中,然后赋值给位段的成员。
cs
struct A
{
int _a : 2;
int _b : 5;
int _c : 10;
int _d : 30;
};
int main()
{
struct A sa = {0};
scanf("%d", &sa._b);//这是错误的
//正确的⽰范
int b = 0;
scanf("%d", &b);
sa._b = b;
return 0;
}4.6 内存对齐,修改默认奇数,位段之间的区别
位段和内存对齐、#pragma pack 确实都和 内存布局控制 有关,但解决的是 完全不同的问题,核心差异体现在:
1 解决的核心问题不同
| 技术 | 核心作用 | 类比场景 |
|---|---|---|
| 内存对齐(默认) | 让 CPU 访问更快,避免跨 "内存块" 读取 | 按快递柜格子存快递(每个格子固定大小,方便快递员快速找到) |
#pragma pack |
强制改变对齐规则,让内存更紧凑(或匹配硬件 / 协议) | 拆快递柜格子,改成自定义大小(为了塞特殊尺寸的东西) |
| 位段(Bit - Field) | 精准控制变量的二进制位数,用最少位存数据 | 把快递拆成 "零件",用最小袋子装(比如 2 位存一个小标记) |
2. 具体差异:从用法到效果
(1)内存对齐(默认规则)
作用:编译器自动在变量间填充空字节,让变量起始地址是 "自身大小的整数倍"(比如 int 起始地址是 4 的倍数),让 CPU 一次读完,提升效率。
效果:会额外占内存(填充空字节),但换来访问速度。
(2)#pragma pack
作用:强制修改对齐规则(比如 #pragma pack(1) 让所有变量 1 字节对齐),去掉编译器自动填充的空字节,让内存更紧凑。
效果:减少内存占用,但可能让 CPU 访问变慢(因为变量可能跨内存块)。
(3)位段
作用:直接控制变量的二进制位数,让一个变量只占 N 位(比如 int a:2 让 a 只占 2 位,最多存 0~3)。
效果:比 #pragma pack 更极端的内存压缩,但只能存非常小的整数,且跨平台兼容性差(不同编译器处理细节不同)。
3. 实际场景对比(一目了然)
用一个例子说清楚三者的区别:
需求:存 3 个小标记(值为 0/1/2)
- 内存对齐(默认):用 int 存,每个占 4 字节,总占 12 字节(填充 + 对齐)。
- #pragma pack(1):用 char 存(1 字节 / 个),总占 3 字节(紧凑,但还是按 "字节" 为单位)。
- 位段:用 2 位存一个标记(0~2 只需要 2 位),3 个标记总共占 2 + 2 + 2 = 6 位(不到 1 字节),极端节省。
- 总结:它们是 "内存控制的不同工具"
内存对齐(默认):以效率优先,允许填充,让 CPU 跑得更快。
#pragma pack:以紧凑优先,强制改规则,适配硬件 / 协议(比如网络报文)。
位段:以极致压缩优先,直接控制二进制位,适合存极小的状态标记。
5. 联合体
5.1 联合体类型的声明
像结构体⼀样,联合体也是由⼀个或者多个成员构成,这些成员可以不同的类型。
但是编译器只为最⼤的成员分配⾜够的内存空间。联合体的特点是所有成员共⽤同⼀块内存空间。所以联合体也叫:共⽤体。
给联合体其中⼀个成员赋值,其他成员的值也跟着变化。
cs
#include <stdio.h>
//联合类型的声明
union Un
{
char c;
int i;
};
int main()
{
//联合变量的定义
union Un un = {0};
//计算连个变量的⼤⼩
printf("%d\n", sizeof(un));
return 0;
}5.2 联合体的特点
联合的成员是共⽤同⼀块内存空间的,这样⼀个联合变量的⼤⼩,⾄少是最⼤成员的⼤⼩(因为联合⾄少得有能⼒保存最⼤的那个成员)。
cs
//代码1
#include <stdio.h>
//联合类型的声明
union Un
{
char c;
int i;
};
int main()
{
//联合变量的定义
union Un un = {0};
// 下⾯输出的结果是⼀样的吗?
printf("%p\n", &(un.i));
printf("%p\n", &(un.c));
printf("%p\n", &un);
return 0;
}
cs
//代码2
#include <stdio.h>
//联合类型的声明
union Un
{
char c;
int i;
};
int main()
{
//联合变量的定义
union Un un = {0};
un.i = 0x11223344;
un.c = 0x55;
printf("%x\n", un.i);
return 0;
}代码1输出的三个地址⼀模⼀样,代码2的输出,我们发现将i的第4个字节的内容修改为55了。
5.3 相同成员的结构体和联合体对比
我们再对⽐⼀下相同成员的结构体和联合体的内存布局情况
cs
struct S
{
char c;
int i;
};
struct S s = {0};
cs
union Un
{
char c;
int i;
};
union Un un = {0};5.4 联合体大小的计算
- 联合的⼤⼩⾄少是最⼤成员的⼤⼩。
- 当最⼤成员⼤⼩不是最⼤对⻬数的整数倍的时候,就要对⻬到最⼤对⻬数的整数倍。
cs
#include <stdio.h>
union Un1
{
char c[5];
int i;
};
union Un2
{
short c[7];
int i;
};
int main()
{
//下⾯输出的结果是什么?
printf("%d\n", sizeof(union Un1));
printf("%d\n", sizeof(union Un2));
return 0;
}使⽤联合体是可以节省空间的,举例:
⽐如,我们要搞⼀个活动,要上线⼀个礼品兑换单,礼品兑换单中有三种商品:图书、杯⼦、衬衫。
每⼀种商品都有:库存量、价格、商品类型和商品类型相关的其他信息。
图书:书名、作者、⻚数
杯⼦:设计
衬衫:设计、可选颜⾊、可选尺⼨
那我们不耐⼼思考,直接写出⼀下结构:
cs
struct gift_list
{
//公共属性
int stock_number;//库存量
double price; //定价
int item_type;//商品类型
//特殊属性
char title[20];//书名
char author[20];//作者
int num_pages;//⻚数
char design[30];//设计
int colors;//颜⾊
int sizes;//尺⼨
};上述的结构其实设计的很简单,⽤起来也⽅便,但是结构的设计中包含了所有礼品的各种属性,这样使得结构体的⼤⼩就会偏⼤,⽐较浪费内存。因为对于礼品兑换单中的商品来说,只有部分属性信息是常⽤的。
cs
struct gift_list
{
int stock_number;//库存量
double price; //定价
int item_type;//商品类型
union {
struct
{
char title[20];//书名
char author[20];//作者
int num_pages;//⻚数
}book;
struct
{
char design[30];//设计
}mug;
struct
{
char design[30];//设计
int colors;//颜⾊
int sizes;//尺⼨
}shirt;
}item;
};⽐如:
商品是图书,就不需要design、colors、sizes。
所以我们就可以把公共属性单独写出来,剩余属于各种商品本⾝的属性使⽤联合体起来,这样就可以介绍所需的内存空间,⼀定程度上节省了内存。
5.5 联合的⼀个练习
写⼀个程序,判断当前机器是⼤端?还是⼩端?
cs
int check_sys()
{
union
{
int i;
char c;
}un;
un.i = 1;
return un.c;//返回1是⼩端,返回0是⼤端
}6. 枚举类型
6.1 枚举类型的声明
枚举顾名思义就是⼀ 列举。
把可能的取值⼀ 列举。
⽐如我们现实⽣活中:
⼀周的星期⼀到星期⽇是有限的7天,可以⼀ 列举
性别有:男、⼥、保密,也可以⼀ 列举
⽉份有12个⽉,也可以⼀ 列举
三原⾊,也是可以意义列举
这些数据的表⽰就可以使⽤枚举了。
cs
enum Day//星期
{
Mon,
Tues,
Wed,
Thur,
Fri,
Sat,
Sun
};
enum Sex//性别
{
MALE,
FEMALE,
SECRET
};
enum Color//颜⾊
{
RED,
GREEN,
BLUE
};以上定义的 enum Day , enum Sex , enum Color 都是枚举类型。
{}中的内容是枚举类型的可能取值,也叫 枚举常量 。
这些可能取值都是有值的,默认从0开始,依次递增1,当然在声明枚举类型的时候也可以赋初值。
cs
enum Color//颜⾊
{
RED=2,
GREEN=4,
BLUE=8
};6.2 枚举类型的优点
为什么使⽤枚举?
我们可以使⽤ #define 定义常量,为什么⾮要使⽤枚举?
枚举的优点:
- 增加代码的可读性和可维护性
- 和#define定义的标识符⽐较枚举有类型检查,更加严谨。
- 便于调试,预处理阶段会删除 #define 定义的符号
- 使⽤⽅便,⼀次可以定义多个常量
- 枚举常量是遵循作⽤域规则的,枚举声明在函数内,只能在函数内使⽤
6.3 枚举类型的使用
cs
enum Color//颜⾊
{
RED=1,
GREEN=2,
BLUE=4
};
enum Color clr = GREEN;//使⽤枚举常量给枚举变量赋值那是否可以拿整数给枚举变量赋值呢?
在C语⾔中是可以的,但是在C++是不⾏的,C++的类型检查⽐较严格。
6.4 结构体、联合体、枚举的区别和联系
一、先理解「结构体」------ 打包不同类型的 "工具箱"
结构体(struct) 就像一个 "工具箱",里面可以装各种不同类型的 "工具"(变量),每个工具都有独立的空间,互不干扰。
比如定义一个 "学生" 结构体:
cs
struct Student
{
char name[20]; // 学生姓名(占20字节)
int age; // 学生年龄(占4字节)
float score; // 学生分数(占4字节)
};- 内存:工具箱总大小是 20 + 4 + 4 = 28字节(可能因对齐补几个字节,但核心是每个成员独立占空间)。
- 用法:可以同时存姓名、年龄、分数,需要时直接用 student.age、student.score 访问,互不影响
二、再看「联合体」------ 共享空间的 "变形盒"
联合体(union) 就像一个 "变形盒",盒子只有一个固定大小的空间,里面只能装一种类型的东西(虽然你可以定义多种类型,但同一时间只能存一种)。
比如定义一个 "变形盒" 联合体:
cs
union Data
{
int num; // 存整数(占4字节)
float f; // 存浮点数(占4字节)
char c; // 存字符(占1字节)
};- 内存:盒子大小是 4字节(取最大成员的大小,因为要兼容所有类型)。
- 用法:同一时间只能存 num、f、c 中的一个。比如存了 num = 10,再存 f = 3.14 就会覆盖 num 的值。
联合体不好理解 我自己再举个实际用途例子来说明:
省内存:如果某些数据 不会同时使用,用联合体可以大幅节省空间。
比如 "游戏角色状态":
cs
union Status
{
int hp; // 活着时存血量(占4字节)
int score; // 死亡时存得分(占4字节)
};角色活着时用 hp,死亡后用 score,用联合体只需 4 字节,比结构体(8 字节)省一半。
三、最后是「枚举」------ 给数字起名字的 "标签机"
枚举(enum) 就像一个 "标签机",给一组数字起有意义的名字,让代码更易读。
比如定义一个 "星期" 枚举:
cs
enum Weekday
{
MON, // 等价于 0
TUE, // 等价于 1
WED, // 等价于 2
THU, // 等价于 3
FRI, // 等价于 4
SAT, // 等价于 5
SUN // 等价于 6
};- 内存:本质是整数,占 4字节(和 int 一样)。
- 用法:用 MON、TUE 代替数字 0、1,代码更直观。比如 enum Weekday today = MON;,别人一看就知道是 "周一"。