可观测性是任何分布式系统不可或缺的一部分。
本章将指导我们如何在本地运行整个系统,管理远程的持续集成构建,并为部署到生产环境做好准备。
在此之前,让我们揭开堆栈中最后一个服务------追踪服务(tracing service)的详尽细节。
对于希望深入了解这一广泛主题的读者,我推荐阅读 Charity Majors、Liz Fong-Jones 和 George Miranda 合著的《Observability Engineering》。
8.1 追踪(Tracing)
在符合 Open Tracing 标准的 Scala 库中,Natchez 和 Trace4cats 都能完美集成 Typelevel 生态系统,且提供了丰富的开箱即用集成支持,如 Http4s、Honeycomb、Jaeger 等。
在接下来的示例中,我们将使用 Natchez,但其中的概念同样适用于其他追踪库。
常见的追踪方式是将 span(又称上下文)线程化地贯穿整个应用程序,而分布式追踪则需要一个所谓的 kernel 来继续之前的追踪 span。
不过,我觉得这种方式侵入性较强。因为需要在整个应用程序中传递上下文------通常通过 MTL 或直接使用 Kleisli 实现------仅为了追踪功能而做这些可能难以令人信服。
在 Cats Effect 3 中,我们可以在给定初始 Span(通过 IOLocal 实现)的情况下获得 TraceIO 实例。但它只适用于具体的 IO,并且存在与 Cats MTL 的 Local 以及 Kleisli#local 相同的限制。例如:
scss
def traceMe[F[_]: Monad: Trace]: F[String] =
Trace[F].span("test-1") {
Trace[F].put("tracing-msg" -> "Hello!").as("Hello world!")
}
def doTrace(ep: EntryPoint[IO]): IO[Unit] =
ep.root("root").use { sp =>
for
given Trace[IO] <- Trace.ioTrace(sp)
msg <- traceMe[IO]
_ <- IO.println(msg)
yield ()
}否则,我们只能选择已有的可携带上下文的 Trace 实例,如 Kleisli 和 StateT。
8.1.0.1 Open Telemetry
需要注意的是,Open Tracing 正逐渐被 Open Telemetry 取代,后者是与 Open Census(一个面向多语言的指标和分布式追踪采集库集合)合并后的产物。
Typelevel 生态正在努力支持它,项目为 otel4s。
不过,目前的 Open Tracing 和 Open Census 应用依然可以在 Open Telemetry 上正常运行,依然有其价值。
8.1.1 分布式追踪
在分布式系统中,通常需要在消费消息或接收 HTTP 请求后继续一个追踪(通过 HTTP 头中的 kernel 实现)。
在无标签(tagless)应用中,TraceIO 实例存在限制,只能在顶层构造,受限于初始 span。
继续一个追踪的唯一方式是拥有共享的 EntryPoint,如下所示:
less
def continueTrace[F[_]: Console: MonadCancelThrow](
ep: EntryPoint[F],
kernel: Kernel
): F[Unit] =
ep.continue("test-1", kernel).use { sp1 =>
sp1.span("test-2").use { sp2 =>
sp2.put("tracing-msg" -> "Continuation") *>
Console[F].println("Done with tracing")
}
}EntryPoint 只在期望从根开始或恢复之前的追踪时使用,这通常不是大问题。
8.1.1.1 HTTP 追踪
natchez-http4s 库允许我们通过读取 HTTP 头信息,尽可能继续之前的追踪,否则就新建一个根 span,从而追踪到底层的 HTTP 请求。
示例,带 Trace 限制的简单 HTTP 路由:
kotlin
final class RoutesOne[F[_]: Monad: Trace] extends Http4sDsl[F]:
val routes: HttpRoutes[F] = HttpRoutes.of {
case GET -> Root / "v1" / "health" =>
Trace[F].span("http-health") {
Trace[F].put("foo" -> "bar") *> Ok()
}
}使用 natchez-http4s 时,无需共享 EntryPoint。可以通过给定语法,在顶层实例化后直接提升路由。
ini
import natchez.http4s.syntax.entrypoint.*
def run: IO[Unit] =
Honeycomb.entryPoint[IO]("app")(...).flatMap { ep =>
val routes = ep.liftT(RoutesOne[IO].routes)
val server = Ember.routes[IO](port"9000", routes)
server.useForever
}这是非常方便且直观的示例。
但是如果 HTTP 路由类需要访问其他程序怎么办?例如:
scss
final class RoutesTwo[F[_]: GenUUID: Monad: Trace](
users: UsersDB[F]
) extends Http4sDsl[F]:
val routes: HttpRoutes[F] = HttpRoutes.of {
case GET -> Root / "v1" / "users" / UUIDVar(id) =>
Trace[F].span("http") {
Trace[F].put("get-user" -> id.toString) *>
users.get(id).flatMap {
case Some(u) =>
Trace[F].put("ok" -> u.name) *> Ok(u.name)
case None =>
Trace[F].put("not-found" -> id.toString) *> NotFound()
}
}UsersDB 定义了两个方法:
less
trait UsersDB[F[_]]:
def get(id: UUID): F[Option[User]]
def save(user: User): F[Either[DuplicateUser, Unit]]构造 HTTP 路由时需要 UsersDB 实例,我们需决定是否也追踪底层。
只有单个依赖时,通常追踪 HTTP 路由足够,可以这样构造:
less
object UsersDB:
def noTrace[F[_]: MonadThrow: Ref.Make]: F[UsersDB[F]] = ???然后提升 HTTP 路由:
ini
def run: IO[Unit] =
Honeycomb.entryPoint[IO]("app")(...).flatMap { ep =>
UsersDB.noTrace[IO].flatMap { db =>
val routes = ep.liftT(RoutesTwo(db).routes)
val server = Ember.routes[IO](port"9000", routes)
server.useForever
}
}如果希望追踪 UsersDB 解释器,有两种方案。第一种是使用单一效果类型构造器:
less
object UsersDB:
def make[F[_]: MonadThrow: Ref.Make: Trace]: F[UsersDB[F]] = ???此时 F 必须携带 HTTP 请求上下文,不能直接用 IO。
定义:
css
type Eff = [A] =>> Kleisli[IO, Span[IO], A]然后运行示例:
ini
def run: IO[Unit] =
Honeycomb.entryPoint[IO]("app")(...).flatMap { ep =>
ep.root("demo-root").use { root =>
UsersDB.make[Eff].flatMap { db =>
val routes = ep.liftT(RoutesTwo(db).routes)
val server = Ember.routes[IO](port"9000", routes)
Kleisli.liftF(server.useForever)
}.run(root)
}
}如果直接用 Trace.ioTrace 在 IO 中创建 UsersDB,会陷入单一 span,且与当前 HTTP 请求上下文无关。
因此,我们对 HTTP 路由类及其依赖都用 Kleisli 实现。缺点是还需提供初始 span 来得到可运行的 IO,这个初始 span 永远不会被触发(即最后的 run(root))。
更干净的方案是将构造效果 F 与运行效果 G 分开,它们本质不同:
less
object UsersDB:
def alt[ F[_]: MonadThrow: Ref.Make,
G[_]: MonadThrow: Trace
]: F[UsersDB[G]] = ???这样避免了最后的 run(root),将两种效果分开。
ini
def run: IO[Unit] =
Honeycomb.entryPoint[IO]("app")(...).flatMap { ep =>
ep.root("demo-root").use { root =>
UsersDB.alt[IO, Eff].flatMap { db =>
val routes = ep.liftT(RoutesTwo(db).routes)
val server = Ember.routes[IO](port"9000", routes)
server.useForever
}
}
}我们又回到了 HttpRoutesIO,而非 HttpRoutesEff。缺点是这种效果分离会很快扩散到整个系统所有层。
优点是,只要我们提供 IO ~> Eff 的自然变换,就能将 IO 和 Eff 两个程序组合起来。
ini
object UsersDB:
def alt[
F[_]: MonadThrow: Ref.Make,
G[_]: MonadThrow: Trace
](using NT[F, G]): F[UsersDB[G]] = ???示例中用自定义 NT 类型类实现:
less
trait NT[F[_], G[_]]:
def fk: F ~> G
object NT:
def apply[F[_], G[_]](using nt: NT[F, G]): NT[F, G] = nt
given NT[IO, Kleisli[IO, Span[IO], *]] = new:
val fk = Kleisli.liftK
object syntax:
extension [F[_], G[_], A](using nt: NT[F, G])(fa: F[A])
def liftK: G[A] = nt.fk(fa)除了声明默认 IO ~> Eff 实例,还定义了 liftK 扩展方法,提升用户体验。
以 noTraceF 构造为基础实现后,我们可在其上添加追踪功能。
less
object UsersDB:
def alt[ F[_]: MonadThrow: Ref.Make,
G[_]: MonadThrow: Trace
](using NT[F, G]): F[UsersDB[G]] =
noTrace[F].map { db =>
new:
def get(id: UUID): G[Option[User]] =
Trace[G].span("users-db") {
Trace[G].put("fetch" -> id.toString) *>
db.get(id).liftK
}
def save(user: User): G[Either[DuplicateUser, Unit]] =
Trace[G].span("users-db") {
db.save(user).liftK.flatTap {
case Left(e) =>
Trace[G].put("duplicate-error" -> user.name)
case Right(_) =>
Trace[G].put("new-user" -> user.name)
}
}
}db.get 和 db.save 在 F 中,因此用 liftK 转换到 G,这也是其他操作使用的效果类型。
缺点是一旦增加更多层,复杂度迅速提升。
假设我们有下图 8.1 所示的依赖,其中蓝色和橙色框分别代表业务逻辑和具体解释器。

如果我们只想对支付 HTTP 客户端进行追踪,那么 Engine 也需要在 Eff 中实例化。幸运的是,其他依赖仍然可以使用 IO,但它们需要在 Engine 实现中提升到 Eff。
ini
object Engine:
def make[F[_]: Monad, G[_]: Monad: Trace](
items: Items[F],
users: Users[F],
payments: Payments[G]
)(using NT[F, G]): Engine[F] = ???假设明天我们想给 ItemsDB 组件添加追踪,那么就需要将 Items 改成 ItemsG,依此类推。根据依赖树的大小,管理起来可能会有些麻烦。
不幸的是,事情不会更简单。但好的一面是,你可以为关键组件获得分布式追踪。
完整性方面,这是 noTrace 实现:
dart
def noTrace[F[_]: MonadThrow: Ref.Make]: F[UsersDB[F]] =
(
Ref.of[F, Map[UUID, User]](Map.empty),
Ref.of[F, Map[String, UUID]](Map.empty)
).tupled.map { (users, idx) =>
new:
def get(id: UUID): F[Option[User]] =
users.get.map(_.get(id))
def save(user: User): F[Either[DuplicateUser, Unit]] =
idx.get
.map(_.get(user.name))
.flatMap {
case Some(_) =>
DuplicateUser.raiseError
case None =>
users.update(_.updated(user.id, user)) *>
idx.update(_.updated(user.name, user.id))
}
.attemptNarrow
}attemptNarrow 方法很重要。它能将任何 F[A] 转成 F[Either[E, A]],其中 E 是你定义的某个 Throwable 子类型,表示你想暴露的错误类型。类型推断会把它默认为 F[Either[Throwable, Unit]],所以显式声明预期错误类型很重要。
这种错误建模与处理技术我在 2022 年初写过一篇博客,里面还介绍了如何利用联合类型实现相似效果而不使用 Either。
最初 forecasts 服务也是显式错误类型建模,但因为需要扩展的事务支持,错误必须被传播以使事务失败,而 attempt/attemptNarrow 则相反,所以没法实现。
在 trading 应用的 demo 模块中,有一个迷你追踪应用,展示了目前讨论过的多种设计方案。
8.1.1.2 Pulsar 追踪
我们了解了最常见的 HTTP 追踪,现在谈谈事件驱动架构中消息的追踪。
消息生产和消费时,有两种方案:
- 把 kernel 加入消息体(侵入性强)
- 利用元数据发送 kernel(推荐)
第一种方案需要在所有数据中增加字段,侵入性大,第二种更优雅,因为 kernel 可以作为元数据存在。
Apache Pulsar 支持每条消息附带元数据,称为 properties,类型是 Map[String, String]。
我们在 Producer 中增加了以下重载方法支持:
less
trait Producer[F[_], A]:
def send(a: A, properties: Map[String, String]): F[Unit]追踪 demo 应用中也体现了这一做法,示例如下:
scss
def one[F[_]: GenUUID: Monad: Trace](
producer: Producer[F, User],
users: UsersDB[F],
ack: MsgId => F[Unit]
): Msg[String] => F[Unit] =
case Msg(msgId, _, name) =>
Trace[F].span("name-consumer") {
Trace[F].put("new-username" -> name) *>
GenUUID[F].make[UUID].flatMap { id =>
users.save(User(id, name)).flatMap {
case Left(DuplicateUser) =>
Trace[F].put("duplicate" -> name)
case Right(_) =>
Trace[F].put("ok" -> name) *>
Trace[F].kernel.flatMap { kernel =>
producer.send(User(id, name), kernel.toHeaders)
}
} *> ack(msgId)
}
}关键在于获取 kernel,然后和消息元数据一起发送:
ini
Trace[F].kernel.flatMap { kernel =>
producer.send(User(id, name), kernel.toHeaders)
}消费端为了支持元数据,也增强了 Consumer.Msg 类型:
typescript
type MsgId = String
type Properties = Map[String, String]
final case class Msg[A](id: MsgId, props: Properties, payload: A)消费端示例:
dart
val users: Consumer[IO, User] => Stream[IO, Unit] = c =>
c.receiveM.evalMap { case Msg(id, props, user) =>
val k = Kernel(props)
ep.continue("ok", k).orElse(ep.continue("duplicate", k)).use { sp =>
sp.span("user-consumer").use { sp1 =>
sp1.put("user" -> user.name) *>
IO.println(s"$user with kernel: $props \n") *> c.ack(id)
}
}
}一旦恢复了追踪,我们可以调用带 Trace 约束的函数,但构造合适的实例唯一方式是通过 Trace.ioTrace(span) 或从那里用 Kleisli 或 MTL,使用无标签最终风格时不太方便。
但如果想追踪单个应用内的数据库调用、外部 HTTP 调用等内部组件,这种方法是不可避免的。
所以我们需要问自己:我们想追踪多少?如果上下文处处传递,那几乎所有组件都会被追踪;如果能少追踪点又怎么样?
8.1.2 集中式追踪
Trace 方法的不足让我思考了一种另类但不太正统的方案,让我们既能兼顾灵活性,也能简化实现。
因为每个服务都是通过 Pulsar 消息通信,集中式追踪服务可以直接挂载到我们想监控的每个主题上。
当然,这只针对进出消息的追踪,但对于任何消息驱动的架构来说,这可能是个很合适的方案。
不过,事情并非完全美好。任何设计决策都有权衡,这里带来的一个代价就是复杂度增加,细节我们稍后会讲。
接下来各节将探讨最终的追踪服务实现,首先是交易和预测两大模块的追踪器接口。
8.1.2.1 预测追踪器
预测追踪器是两者中最简单的。
less
trait ForecastingTracer[F[_]]:
def trace(
cmd: ForecastCommand,
evt: Either[AuthorEvent, ForecastEvent]
): F[Unit]其主构造函数接受一个 EntryPoint[F],用于总是从根 span 开始。
less
object ForecastingTracer:
def make[F[_]: MonadCancelThrow](
ep: EntryPoint[F]
): ForecastingTracer[F] = new:
def trace(
cmd: ForecastCommand,
evt: Either[AuthorEvent, ForecastEvent]
): F[Unit] = ???当接收到一个 ForecastCommand 和一个 AuthorEvent 或 ForecastEvent 时,我们就创建追踪。在此期间可以通过 put 方法添加任意上下文信息。
示例实现如下:
rust
ep.root("forecast-root").use { root =>
root.span(s"forecast-command-${cmd.cid.show}").use { sp1 =>
val cid = evt.fold(_.cid, _.cid)
val createdAt = evt.fold(_.createdAt, _.createdAt)
val durationMs = createdAt.value.toEpochMilli - cmd.createdAt.value.toEpochMilli
val evtPayload = evt.fold(_.asJson, _.asJson)
sp1.put(
"correlation_id" -> cmd.cid.show,
"created_at" -> cmd.createdAt.show,
"payload" -> cmd.asJson.noSpaces
) *> sp1.span(s"forecast-event-${cid.show}").use { sp2 =>
sp2.put(
"correlation_id" -> cid.show,
"created_at" -> createdAt.show,
"duration_tx_ms" -> durationMs.show,
"payload" -> evtPayload.noSpaces
)
}
}
}需要说明的是,使用 Natchez 实现的话,无法自动计算 span 的真实持续时间,因为它内部的 duration_ms 属性是追踪创建时的时间戳,而不是我们事件中的 createdAt。
虽然调整 Natchez 以支持这种模式需要额外工作,但可以做到。否则,我们可以忽略 duration_ms,只用 duration_tx_ms 字段来做查询。
这是最简单的追踪实现,忽略了状态机中的复杂性。下一节我们将看看状态机的追踪。
8.1.2.2 预测 FSM(状态机)
预测状态机的状态和输入类型如下:
ini
type ForecastState = (List[AuthorEvent], List[ForecastEvent], List[ForecastCommand])
type ForecastIn = AuthorEvent | ForecastEvent | ForecastCommandFSM 接受命令或两种事件之一,并通过 CorrelationId 将它们关联。匹配成功后调用 trace 方法。
FSM 的状态是三份列表的元组,分别保存尚未匹配的命令和事件。
我们知道每个命令一定会有相应事件,所以逻辑简单。但需注意事件可能比命令先到,因为它们来自不同 Pulsar 主题,合并后可能乱序。
这与 Kafka Streams 的做法类似:缓存入站数据,等待 ID 匹配后合并,然后推送给消费者。
我们也可以用 Pulsar Functions,但这需要额外基础设施用于监控和维护,且会增加团队工作量。相比之下,使用普通 JVM 工具监控维护另一个 Scala 服务更方便。
下面是部分 FSM 实现(省略具体逻辑):
javascript
def forecastFsm[F[_]: Applicative: Logger](
tracer: ForecastingTracer[F]
): FSM[F, ForecastState, ForecastIn, Unit] =
FSM {
case ((atEvents, fcEvents, fcCommands), cmd: ForecastCommand) =>
(atEvents.find(_.cid === cmd.cid), fcEvents.find(_.cid === cmd.cid)) match
???
case ((atEvents, fcEvents, fcCommands), evt: ForecastEvent) =>
fcCommands.find(_.cid === evt.cid) match
???
case ((atEvents, fcEvents, fcCommands), evt: AuthorEvent) =>
fcCommands.find(_.cid === evt.cid) match
???
}无论收到哪种事件,我们都会检查内部状态里是否已有对应命令,如果匹配则追踪,否则存入状态。
同理,收到命令时,也检查是否已有相应事件。
还有一种极端情况是消息丢失,导致命令和事件永远无法关联。此时可以考虑设置过期机制,丢弃未关联命令,或用假事件追踪它。
不过这里略去这些复杂处理,接下来会看到交易追踪器类似的思路。
8.1.2.3 交易追踪器
交易追踪器的设计完全不同,原因不久后会明白。
less
trait TradingTracer[F[_]]:
def command(cmd: TradeCommand): F[CmdKernel]
def event(kernel: CmdKernel, evt: TradeEvent): F[EvtKernel]
def alert(kernel: EvtKernel, alt: Alert): F[Unit]command 和 event 方法返回新的 Kernel 类型,以便追踪能在其它地方继续。alert 方法返回 F[Unit],表示追踪链的终点。
给定由 command 产生的 CmdKernel,event 方法用来继续追踪,加入给定的 TradeEvent,依次类推。
下面是部分实现示例:
less
object TradingTracer:
def make[F[_]: MonadCancelThrow](
ep: EntryPoint[F]
): TradingTracer[F] = new:
def command(cmd: TradeCommand): F[CmdKernel] =
ep.root("trading-root").use { root => ??? }
def event(k: CmdKernel, evt: TradeEvent): F[EvtKernel] =
ep.continue(s"trading-command-${evt.cid.show}", k.value).use { sp =>
???
}
def alert(k: EvtKernel, alt: Alert): F[Unit] =
ep.continue(s"trading-event-${alt.cid.show}", k.value).use { sp =>
???
}一个事件可能产生多个告警。图 8.2 会帮你更好理解最终效果。
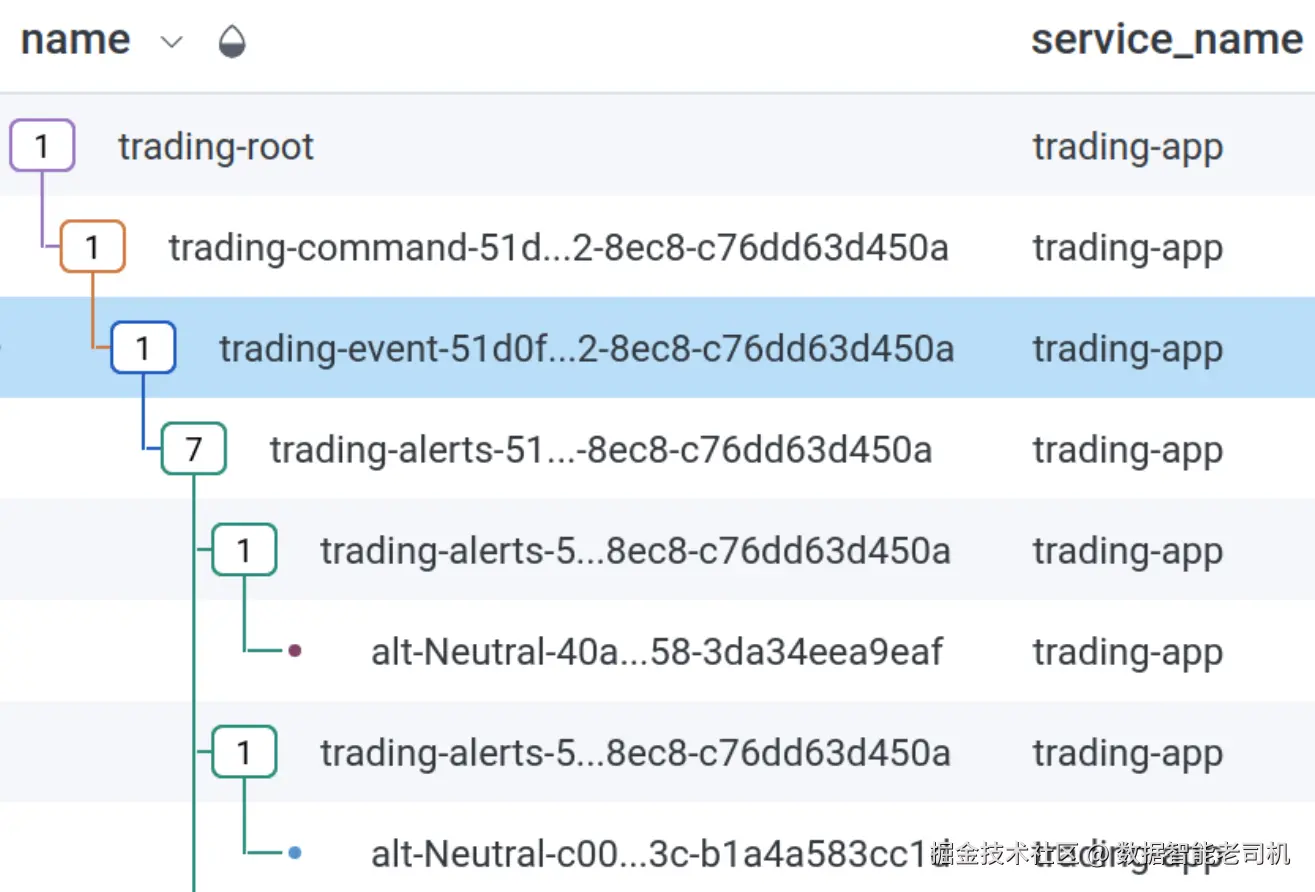
每个事件可能产生零个告警,那么我们如何判断某个事件是否应该保留在状态机中等待一个永远不会到来的告警呢?
8.1.2.4 状态机(FSM)
如前所述,我们可以通过引入带有过期机制的时间窗口来解决这个问题,但这会极大增加复杂性。
以下类型参与了负责交易追踪的状态机:
ini
type MatchingVals = (Timestamp, Option[CmdKernel], Option[EvtKernel])
type MatchingIds = Map[CorrelationId, MatchingVals]
type Tick = Unit
type TradeState = (List[TradeEvent], List[Alert], MatchingIds)
type TradeIn = TradeCommand | TradeEvent | Alert | Tick先来看 TradeState 类型别名。我们累计事件(events)和告警(alerts),以及一个复杂类型 MatchingIds。这里不需要收集命令,因为命令代表追踪的起点。
MatchingIds 是一个键值存储,键是用于关联不同消息类型的 CorrelationId,值是包含时间戳(用于过期判断)以及两个可选的 kernel(追踪上下文)用以续接追踪。
输入类型包括命令、事件、告警和 Tick(时钟信号)。在深入 Tick 细节前,我们先看几个内部方法:
less
def expireMatchingIds[F[_]: Monad: Time](
ids: MatchingIds
): F[MatchingIds] = ???该方法检查 Map 中所有时间戳,删除过期(默认一分钟)的条目。
less
def updateMatchingIds[F[_]: Monad: Time](
ids: MatchingIds,
cid: CorrelationId,
kernel: Either[CmdKernel, EvtKernel]
): F[MatchingIds] = ???该方法用新的 CorrelationId 和 kernel 更新已有的 MatchingIds。
下面是 FSM 的构造:
ini
val MatchingIdsExpiration = 1.minute
def tradingFsm[F[_]: Logger: Monad: Time](
tracer: TradingTracer[F]
): FSM[F, TradeState, TradeIn, Unit] = FSM { ??? }再来看处理进来的 TradeCommand:
javascript
case ((events, alerts, ids), cmd: TradeCommand) =>
for
k <- tracer.command(cmd)
i <- updateMatchingIds(ids, cmd.cid, Left(k))
yield (events, alerts, i) -> ()调用 tracer.command 获得 kernel,随后更新 MatchingIds 状态。
处理 TradeEvent:
javascript
case (st @ (events, alerts, ids), evt: TradeEvent) =>
ids.get(evt.cid).flatMap((_, k, _) => k) match
case Some(cmdKernel) =>
for
k <- tracer.event(cmdKernel, evt)
i <- updateMatchingIds(ids, evt.cid, Right(k))
yield (events, alerts, i) -> ()
case None =>
expireMatchingIds[F](ids).map(i => (events :+ evt, alerts, i) -> ())先查找对应的 CorrelationId。找到时使用命令 kernel 继续追踪,更新状态;未找到时触发过期机制,并将事件累积进状态。
处理告警类似,不过不需更新 kernel:
javascript
case (st @ (events, alerts, ids), alt: Alert) =>
ids.get(alt.cid).flatMap((_, _, k) => k) match
case Some(evtKernel) =>
tracer.alert(evtKernel, alt).as(st -> ())
case None =>
expireMatchingIds[F](ids).map(i => (events, alerts :+ alt, i) -> ())Tick 是最有趣的输入:
javascript
case (st @ (events, alerts, ids), tick: Tick) =>
val fsm = tradingFsm(tracer)
val processEvents: F[TradeState] =
events.foldLeft(st.pure[F]) { (getSt, evt) =>
getSt.flatMap(fsm.runS(_, evt))
}
def processAlerts(st1: TradeState): F[TradeState] =
alerts.foldLeft(st1.pure[F]) { (getSt, alt) =>
getSt.flatMap(fsm.runS(_, alt))
}
(processEvents >>= processAlerts).tupleRight(())我们在 FSM 内部又创建了一个新的 FSM(虽然听起来疯狂,但本质上状态机就是反复调用的函数)。这样才能确保之前乱序累积的事件和告警得到正确追踪。
Tick 每两秒触发一次,类似快照中的实现(参见快照 FSM)。
8.1.2.5 FSM 依赖类型
在第4章,我们了解了匹配类型和依赖类型(见依赖类型章节)。这里展示这些特性如何被追踪状态机利用。
我们之前定义的 FSM 类型:
less
def forecastFsm[F[_]: Applicative: Logger](
tracer: ForecastingTracer[F]
): FSM[F, ForecastState, ForecastIn, Unit] = FSM { ??? }
def tradingFsm[F[_]: Logger: Monad: Time](
tracer: TradingTracer[F]
): FSM[F, TradeState, TradeIn, Unit] = FSM { ??? }实际上有以下同构定义:
ini
def forecastFsm[F[_]: Applicative: Logger]: SM[F, ForecastIn] =
tracer => FSM { ??? }
def tradingFsm[F[_]: Logger: Monad: Time]: SM[F, TradeIn] =
tracer => FSM { ??? }由于 tracer 和状态类型依赖输入类型,我们可以在类型层面强制这一关系:
ini
type St[In] = In match
case ForecastIn => ForecastState
case TradeIn => TradeState
type Tracer[F[_], In] = In match
case ForecastIn => ForecastingTracer[F]
case TradeIn => TradingTracer[F]
type SM[F[_], In] = Tracer[F, In] => FSM[F, St[In], In, Unit]这样 tracer 和状态类型在编译时由输入类型唯一确定,代码更加安全,得益于匹配类型。
8.1.2.6 主入口
和往常一样,我们先定义消费者的订阅类型:
ini
val sub =
Subscription.Builder
.withName("tracing")
.withType(Subscription.Type.Exclusive)
.build接着是消费我们想追踪的所有主题消息的资源定义(省略部分细节):
scss
def resources =
for
config <- Resource.eval(Config.load[IO])
pulsar <- Pulsar.make[IO](config.pulsar.url)
ep <- Honeycomb.makeEntryPoint(config.honeycombApiKey)
alerts <- Consumer.pulsar[IO, Alert](???).map(_.receive)
tradingEvents <- Consumer.pulsar[IO, TradeEvent](???).map(_.receive)
tradingCommands <- Consumer.pulsar[IO, TradeCommand](???).map(_.receive)
authorEvents <- Consumer.pulsar[IO, AuthorEvent](???).map(_.receive)
forecastEvents <- Consumer.pulsar[IO, ForecastEvent](???).map(_.receive)
forecastCommands <- Consumer.pulsar[IO, ForecastCommand](???).map(_.receive)
fcFsm = forecastFsm[IO].apply(ForecastingTracer.make[IO](ep))
tdFsm = tradingFsm[IO].apply(TradingTracer.make[IO](ep))
server = Ember.default[IO](config.httpPort)
yield (server, alerts, tradingEvents, tradingCommands, ..., fcFsm, tdFsm)然后是 run 方法,所有输入流合并:
css
val ticks: Stream[IO, TradeIn] =
Stream.fixedDelay[IO](2.seconds)
val trading =
tradingCommands
.merge[IO, TradeIn](tradingEvents.merge(alerts))
.merge(ticks)
.evalMapAccumulate(TradeState.empty)(tdFsm.run)
val forecasting =
authorEvents
.merge[IO, ForecastIn](forecastEvents.merge(forecastCommands))
.evalMapAccumulate(ForecastState.empty)(fcFsm.run)
Stream(
Stream.eval(server.useForever),
trading,
forecasting
).parJoin(3)这里看到命令、事件、告警和 Tick 合并后经过对应状态机,预测流程类似,但不需要 Tick。
注意,我们为了简化起见只用单实例,所有主题用独占订阅,重负载下很容易出问题。
类似快照服务的架构(见快照服务可扩展性)也可用于该服务,挑战性较大。
另外,为避免启动时持久化状态及加载复杂度,我们也可切换到手动确认模式------即用 receiveM 代替 receive,只在追踪链结束时发出确认。
需要调整确认超时为大于过期时间。
这在明确结束时很简单,但本例需依赖过期机制来确认剩余消息。
此策略还可以结合 Failover 订阅实现无状态单写者原则。
8.1.2.7 追踪总结
集中式追踪方法有优缺点。
优点是其他服务无需感知追踪代码,维护简单。
缺点是追踪服务要承担额外复杂度,跟踪属于同一事务的消息,有时十分棘手甚至不可能。
总结来说,当每条消息只发出一条对应消息时(如预测服务),该方法极为适用。
当每条消息对应零条或多条消息时(如交易服务),则未必适用。
无论选择哪种方案,现已具备足够基础,能让你在下次需为系统添加分布式追踪时做出明智决定。
想深入学习流处理系统及本集中式追踪使用的时间窗口功能,推荐阅读 Tyler Akidau、Slava Chernyak 和 Reuven Lax 合著的《Streaming Systems》一书,主要基于 Apache Flink 和 Apache Beam。
此外,Azure Stream Analytics 和 Kafka Streams 等现代技术也采用类似技术。
8.2 构建与运行
trading 代码仓库包含了运行整个系统所需的大部分信息。无论如何,我们现在将回顾项目结构和运行说明,如图 8.3 所示。
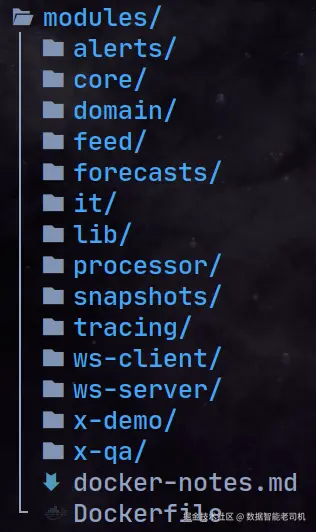
这些是我们 sbt 项目中的所有模块,其中只有 alerts、forecasts、processor、snapshots、tracing 和 ws-server 这几个模块可以作为后端应用程序进行部署。
这意味着所有这些服务都可以打包成二进制文件、Docker 镜像或其他类型的可运行应用,并且可以部署到 Kubernetes 集群。
我们很快会学习后者,但值得一提的是,我们可以通过 sbt project:run 命令直接运行每个应用程序。公平地说,这也是运行 feed 应用以及 x-demo 模块中所有示例的推荐方式。
it 模块对应我们在第7章学习过的集成测试(见"集成测试"),而 x-qa 模块对应我们稍后会学习的冒烟测试(见"冒烟测试")。
8.2.1 Docker Compose
在项目的顶层目录下,你会找到一个 docker-compose.yml 文件,它声明了所有可部署的服务和运行时依赖。
在启动容器之前,我们需要确保所有服务都已发布为 Docker 镜像。
ruby
$ docker build -t jdk17-curl modules/
$ sbt docker:publishLocal所有 JVM 服务都依赖一个自定义的 jdk17-curl 镜像,该镜像基于 openjdk:17-slim-buster 并添加了 curl 支持,以便我们能用它进行健康检查。
请确保已安装 Docker 和 docker-compose。
执行以下命令后,应该会启动所有容器:
bash
$ docker-compose up
Creating network "trading_app" with the default driver
Creating trading_pulsar_1 ... done
Creating trading_redis_1 ... done
Creating trading_ws-server_1 ... done
Creating trading_pulsar-manager_1 ... done
Creating trading_alerts_1 ... done
Creating trading_processor_1 ... done
Creating trading_snapshots_1 ... done
Creating trading_forecasts_1 ... done
Creating trading_tracing_1 ... done
Creating trading_prometheus_1 ... done
Creating trading_grafana_1 ... done请注意,这需要一定的内存资源,如果你在资源较少的机器上工作,可能需要调整资源使用。
这是在本地运行系统的推荐方式。不过,我们很快会学习如何在生产环境中做得更好。
8.2.2 持续集成
在 trading 代码仓库中,我们使用 Github Actions 作为默认的 CI 构建机制。
集成测试只需要 Redis 服务,因此我们仅启动此服务:
csharp
$ docker-compose up -d redis
Creating network "trading_app" with the default driver
Creating trading_redis_1 ... done我们可以在本地和 CI 构建环境中一致地使用 docker-compose。
CI 与开发环境确保保持一致,这一点在 flake.nix 文件中声明。Nix 帮助我们实现跨机器的一致可复现性。
不过,这对每个用户都是可选的。flake.nix 文件是为了方便需要它的用户准备的,否则你需要自己在机器上安装和配置 sbt、jdk 以及所有必要的软件开发环境。
此外,所有服务使用的 jdk17-curl Docker 镜像也可以通过 Nix 构建(如果你想利用仓库的 flake):
ruby
$ nix build
$ docker load -i result参考项目中没有持续交付(CD)流程,这需要生产环境支持,但已经有一套工作流为将来的 CD 系统铺路。
Scala 主分支构建成功后,会触发一个 Registry 工作流,负责构建并将应用的 Docker 镜像发布到 Github 注册中心。
yaml
name: Registry
on:
workflow_run:
workflows: ["Scala"]
branches: [main]
types:
- completed目前只有 processor、alerts 和 ws 服务的镜像会被发布,因为这些是运行冒烟测试所必须的(详见下节)。
Registry 构建成功后,会触发 Smokey 工作流:
yaml
name: Smokey
on:
workflow_run:
workflows: ["Registry"]
branches: [main]
types:
- completed该工作流会从注册中心拉取应用的 Docker 镜像,并执行我们稍后会学习的冒烟测试。
当冒烟测试通过后,可以触发持续交付工作流(例如将服务发布到 UAT 或 STAGING 环境)。
如今 CI/CD 系统无处不在,而 Github Actions 是一个很好的选择。
8.2.3 冒烟测试
冒烟测试为我们提供了系统整体功能性的某些保证。
我们的实现结合了冒烟测试和功能测试,既验证应用能否成功连接到 Pulsar 和 Redis(冒烟测试),也验证客户端和服务间通信是否符合预期(功能测试)。
简而言之,smokey(我们的冒烟测试套件)做了以下事情:
- 通过 docker-compose 启动核心应用(processor、alerts 和 ws)。
- 两个客户端通过 WebSocket 连接,并订阅部分交易符号。
- 生成并发布固定的一组 TradeCommands。
- 验证每个 WebSocket 客户端仅接收到其订阅符号对应的告警信息。
下面是主要测试的示例:
javascript
test("Trading smoke test") { case (pulsar, ws) =>
val cli1 = clientSimulator(ws, symbols1, expected1.size)
val cli2 = clientSimulator(ws, symbols2, expected2.size)
(commandsProducer(pulsar) &> (cli1, cli2).parTupled).map {
case (((_: WsOut.Attached) :: xs), ((_: WsOut.Attached) :: ys)) =>
expect.same(xs, expected1) && expect.same(ys, expected2)
case xs =>
failure(s"Expected ${expected1.size + 1} messages")
}
}commandsProducer 方法负责在初始延迟后发布 TradeCommands,
clientSimulator 方法则模拟 WebSocket 客户端连接,并跟踪接收到的消息。
最终,我们断言两个客户端均收到最初的 Attached 消息,随后收到其订阅范围内的一部分交易告警。
完整实现可在 trading 仓库的 x-qa 模块中找到。
8.3 监控
到目前为止,我们已经详细讨论了追踪(tracing),但可观测性远不止于此。在本节中,我们将探讨对服务和基础设施的监控。
CPU、内存、线程使用等指标,对于了解任何分布式系统的健康状况都至关重要。
由于我们的系统运行在 JVM 上,能帮助我们理解 JVM 性能的特定指标,在生产环境出现问题时也尤为重要。
此外,我们还可以基于这些指标为值班团队自动触发告警。
8.3.1 Prometheus
Prometheus 是一款标准的开源监控解决方案。我们在系统中使用它(已在 docker-compose 依赖中声明),用来收集所有 JVM 服务的指标。
为此,每个服务都运行一个 HTTP 服务器,供 Prometheus 抓取指标。相关代码基于 http4s-prometheus-metrics 库,默认导出合理的指标。
r
private def metrics[F[_]: Async]: Resource[F, HttpRoutes[F] => HttpRoutes[F]] =
for
prt <- PrometheusExportService.build[F]
ops <- Prometheus.metricsOps[F](prt.collectorRegistry)
yield rts => Metrics[F](ops)(prt.routes <+> rts)这为每个服务添加了一个 GET /metrics 接口,暴露出原始格式的指标数据,供后续读取和解析。
8.3.2 Grafana
为了将 Prometheus 报告的指标以美观的仪表盘形式展示,我们可以使用 Grafana,这是业界的另一款标准工具。
在 trading 仓库的 monitoring 目录下,你会找到所有服务的默认 Prometheus 和 Grafana 配置,以及 Pulsar Manager 的配置,Pulsar Manager 正逐渐成为 Pulsar 的默认界面。
仪表盘可以根据我们的需求进行自定义,你还可以从社区贡献的丰富仪表盘中获取更多灵感。
这些配置在使用 docker-compose 时会被默认读取,因此在本地运行系统时,你就能看到这些监控系统的实际效果。
8.4部署
生产环境的部署理想情况下应由我们的持续交付(CD)系统自动完成。可以说,Kubernetes(k8s)已成为业界事实上的集群管理工具,方便进行部署和容器编排。
我们将简要介绍这部分内容,分析部署系统中每个服务时应该关注的事项,包括停机时间、正常运行时间和弹性。
8.4.1 K8s 集群
参考交易应用没有生产环境,但我们可以使用 minikube 在本地模拟一个 k8s 集群,minikube 支持所有主流操作系统。
为了演示 k8s 提供的一些特性,我们只会使用部分服务,以降低资源需求。
Nix 用户可以利用声明式开发环境访问相关软件来运行以下示例。其他用户请确保已经安装好所有必需的软件。
在项目的 ops 目录下,有 apps 和 infra 两个子目录,分别包含 k8s 部署文件。
本地管理集群基本只需两条命令:
ruby
$ minikube start
$ minikube stop启动后,需要先将我们的 Docker 镜像发布到 minikube 环境,再进行部署,步骤如下:
ruby
$ eval $(minikube docker-env)
$ docker build -t jdk17-curl modules/
$ sbt docker:publishLocal这里所有 JVM 服务依赖一个自定义的 jdk17-curl 镜像,该镜像基于 openjdk:17-slim-buster,额外包含了 curl 支持,方便健康检查。
确保已经安装 Docker 和 docker-compose。
然后可以启动基础设施服务,并等待它们启动完成:
bash
$ kubectl apply -f ops/infra
deployment.apps/pulsar created
deployment.apps/redis created
service/redis configured接着,设置 ops/apps/tracing-deployment.yaml 中的 HONEYCOMB_API_KEY,然后启动所有应用服务:
bash
$ kubectl apply -f ops/apps
deployment.apps/alerts created
service/alerts configured
networkpolicy.networking.k8s.io/app configured
...k8s 还有更好的 Secrets 管理方案,这里为简便起见,可以手动修改,或者使用 envsubst(仅 Linux 支持)替换变量:
bash
envsubst -i ops/apps/tracing-deployment.yaml -o ops/apps/tracing-deployment.yaml所有这些步骤也记录在 ops/deployment.md 文件中。
可以通过注册获取免费的 Honeycomb API Key。
8.4.2 Pods 管理
当服务在本地集群运行起来后,可以使用以下命令查看所有 Pod 状态:
sql
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
alerts-78846666d-sl2ld 1/1 Running 0 4m34s
forecasts-6dd77757bb-zczsb 1/1 Running 0 4m34s
processor-6f89879764-8z6d9 1/1 Running 0 4m34s
pulsar-75f65c75fc-t7znc 1/1 Running 0 5m26s
redis-cd5c5d4d7-nt4dc 1/1 Running 0 5m26s
snapshots-85856767b4-pmj95 1/1 Running 0 4m34s
ws-server-668c9dccb8-244dg 1/1 Running 0 4m34s
...8.4.2.1 扩容
例如,可以用单条命令水平扩容任意服务:
ini
$ kubectl scale --replicas=2 deployment/alerts几秒钟后,会看到两个同样的 Pod 并行运行:
sql
$ kubectl get pods | rg alerts
alerts-78846666d-4qcg9 1/1 Running 0 32s
alerts-78846666d-sl2ld 1/1 Running 0 7m44salerts 服务可以扩容是因为它的消费者组合使用了 key-shared 和独占订阅,多消费者可以并行工作。
rg 命令是 ripgrep,替代了老牌的 grep。
但是,如果试图扩容 tracing 服务(该服务使用带全局名的独占订阅),会出现问题:
shell
$ kubectl scale --replicas=2 deployment/tracing
$ kubectl get pods | rg tracing
tracing-5886fbd789-st66p 0/1 CrashLoopBackOff 2 (13s ago) 42s
tracing-5886fbd789-td6hz 1/1 Running 0 78s独占消费者限制同一时间只能有一个消费者,因此我们无法给它扩容多个实例。
查看崩溃 Pod 的日志,会看到类似错误:
vbnet
2022-03-15T10:36:08 [io-1] INFO t.lib.Logger - Initializing tracing service
PulsarClientException: {"errorMsg":"Exclusive consumer is already connected"}这正体现了设计决策的边界,理解 Pulsar 订阅类型至关重要。
如果要恢复单实例运行,可以缩减副本数:
ini
$ kubectl scale --replicas=1 deployment/tracing8.4.2.2 故障切换订阅(Fail-over subscriptions)
最有趣的情况莫过于使用故障切换订阅类型,这也是 forecasts 服务的使用场景。默认情况下,我们启动两个副本,但最初只有一个会真正消费消息。
我们可以通过简单操作观察这一点。首先,验证确实有两个 Pod 正在运行:
sql
$ kubectl get pods | rg forecasts
forecasts-6dd77757bb-zczsb 1/1 Running 0 7m13s
forecasts-6dd77757bb-8wsbm 1/1 Running 0 7m13s接着,启动 feed 服务,生成随机的预测数据,同时替换默认的 Pulsar 地址:
ini
PULSAR_URI=pulsar://192.168.49.2:32356 sbt feed/run这里的地址是 minikube 集群中 Pulsar 实例的地址。默认情况下该地址未暴露,可以用下面命令暴露它:
css
$ kubectl expose deployment pulsar --type=NodePort --port=6650 --name=pulsar-svc随后,查询 Pulsar 服务的 URL:
arduino
$ minikube service --url pulsar-svc
http://192.168.49.2:32356现在,我们准备好观察故障切换订阅的运行效果了。
在启动 feed 服务之前,请通过 kubectl logs -f 同时查看两个 forecasts Pod 的日志。
启动后,你会发现消息只流向其中一个 Pod。接着,从另一个终端杀掉正在工作的那个 Pod:
arduino
$ kubectl delete pod forecasts-6dd77757bb-zczsb
pod "forecasts-6dd77757bb-zczsb" deleted之后,所有消息应该会自动切换到备用 Pod,即 forecasts-6dd77757bb-8wsbm。这个过程测试起来有些小技巧,但却是验证故障切换机制是否正常的好方法。
同样的测试也可以在 snapshots 服务中做,因为它多个实例使用了通过分布式锁同步的独占订阅,与故障切换订阅有些类似。
另外,也可以直接用 docker-compose 来测试。比如,可以添加一个使用不同 HTTP 端口的 snapshots2 服务,同时启动两个实例。
8.4.2.3 滚动重启(Roll-out restarts)
我们对订阅类型和扩容的了解,同样适用于滚动重启(或滚动发布)。
使用下面命令可以将新变更部署到集群中:
shell
$ kubectl rollout restart deployment/alerts或者直接部署所有变更的应用:
shell
$ kubectl apply -f ops/apps部署破坏性变更时,需要确保 JSON schema 向后兼容(参见 Schema 演进),以免造成系统中断。
该命令足够智能,可以处理所有类型的 Pulsar 订阅。它总是尝试先启动新容器,确认运行正常后再停止旧容器,实现零停机时间。
如果无法做到这一点,比如使用带全局名的独占订阅时,旧容器会先停止,然后再启动新容器,这可能会导致几秒钟的停机,具体情况视实际环境而定。
8.5 总结
可观测性在分布式系统中至关重要。在本书的最后一章,我们学习了可用于分布式追踪的多种技术。
此外,我们了解了如何直接使用 sbt 或通过 docker-compose 在本地运行系统。通过 docker-compose,我们还能亲眼见证 Prometheus 和 Grafana 的监控效果。
最后但同样重要的是,我们掌握了 Kubernetes 部署的基础知识,比如服务的扩容和滚动发布,以及这些操作如何与不同类型的 Pulsar 订阅交互。
Kubernetes 如今已无处不在,提升这方面的技能无疑会让你在求职时更具竞争力。