Agent
-
Agent 其实就是由大语言模型自己驱动的一个 能够自主决策、任务执行 的系统,它就相当于一个智能的私人助理,它可以使用 RAG/Function call 等工具。
-
比如说 我们给大模型一个目标,它自己就能拆解任务、查信息、返回结果,有自己的行动力。
RAG
- RAG:检索增强生成,通过结合LLMs的内在知识和外部数据库的非参数化数据,提高了模型在知识密集型任务中的准确性和可信度。
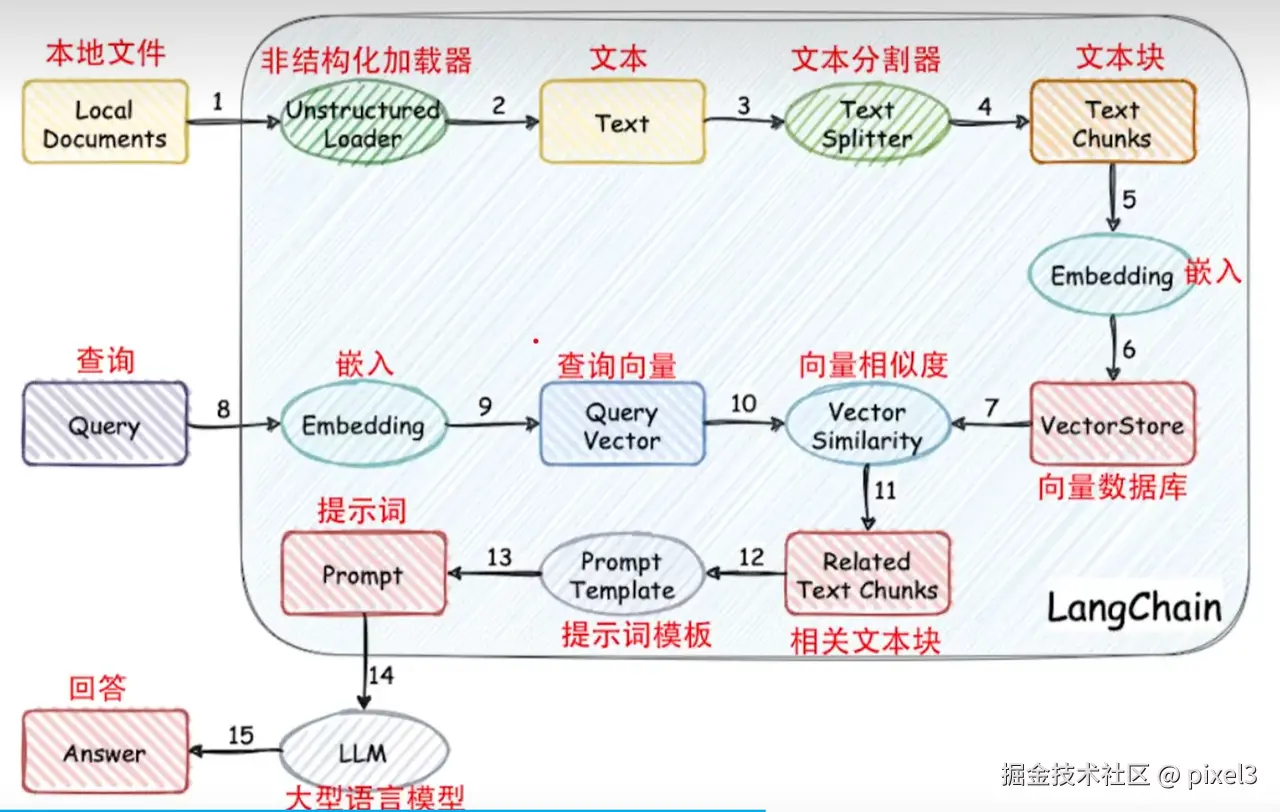
- 本地文件通过文本嵌入为特征向量,存入Faiss等向量数据库。
- 当查询
Query时,通过查询向量Query Vector跟向量数据库进行相似度匹配,将相关文本块组合,通过提示词模板处理,输入大预言模型LLM,得到更符合要求的回答结果!(根据某些场景提供的文件构建向量数据库,得到更符合场景需求的回答结果)
Function Call
-
Function Call 就是大模型可以请求执行 外部预先定义的工具、函数,就相当于 Agent 执行具体动作 的手段。
-
比如说,大模型自己不能发邮件、不能查今天的新闻、天气,那么它就可以请求、指挥其他的工具去做这些事。
MCP
- MCP 就更像一个统一的标准,把 AI 和外部工具调用的通信协议 给标准化了,就相当于 ai 界的 restful 一样,属于 agent 调用大模型的底层标准。
向量数据库
向量数据库的工作流程可拆解为五步,核心是将非结构化数据转化为可计算、可检索的向量形式:
- 数据处理:清洗数据(去噪、归一化)、标注元数据(如标签、时间)。
- 向量化:用AI模型(如BERT、ResNet)提取特征,生成高维向量。
- 向量存储:将向量与原始数据关联,存入分布式存储(如分块存储)。
- 索引构建:用HNSW、LSH等技术组织向量,建立高效检索结构。
- 相似性检索:输入目标向量,通过索引快速返回Top-K近似结果。
Faiss
Faiss使用(内存上)
- 常用的功能包括:索引Index,PCA降维、PQ乘积量化。
- 有两个基础索引类Index、IndexBinary。
索引选择:
- 精度高,使用IndexFlatL2,能返回精确结果。
- 速度快,使用IndexIVFFlat,首先将数据库向 量通过聚类方法分割成若干子类,每个子类用类中心表示,当查询向量来临时,选择距离最近的类中心,然后在子类中应用精确查询方法,通过增加相邻的子类个数提高索引的精确度。
- 内存小,使用IndexIVFPQ,可以在聚类的基础上使用PQ乘积量化进行处理,对向量进行压缩。