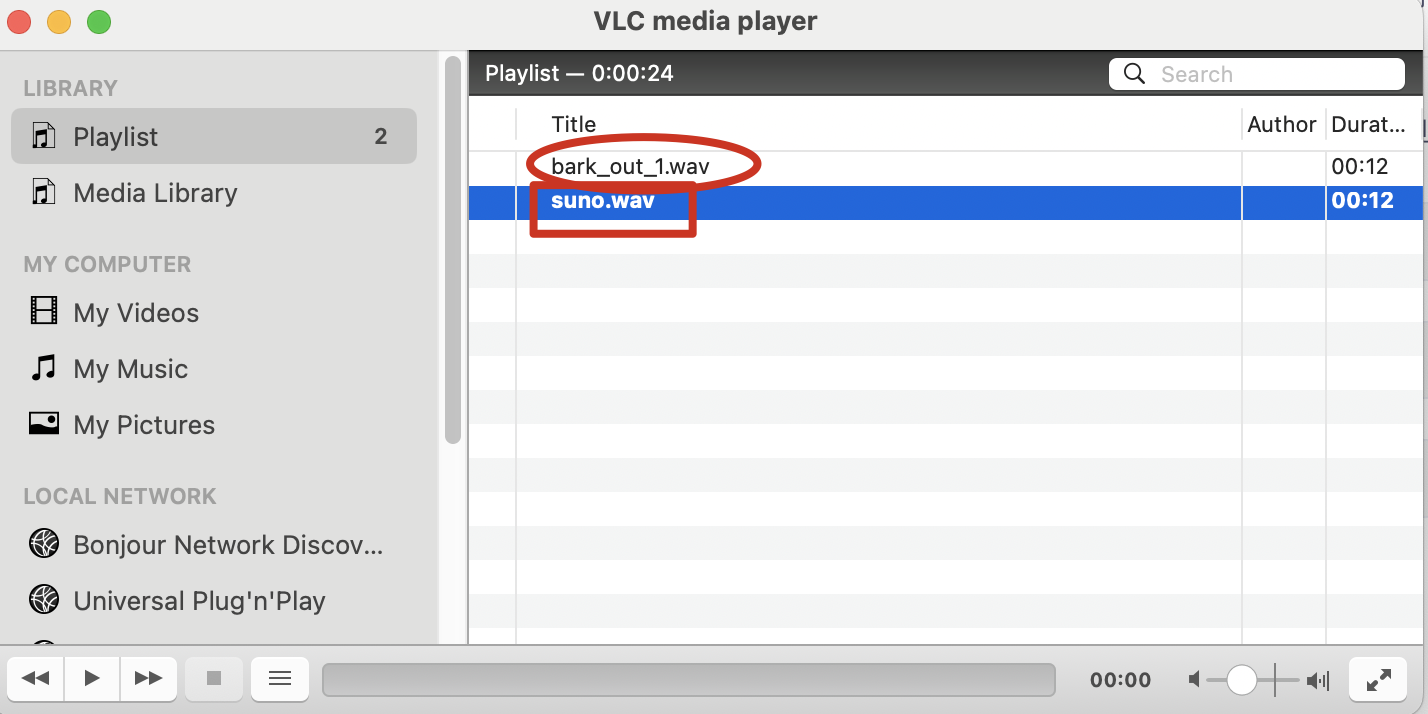
先看效果:
(页面无法展示音频,可以下载资源,听效果)
suno.wav是之前使用910B2 NPU,jeffding/bark-openmind模型生成的.
bark_out_1.wav是使用910B3 NPU,mapjack/bark生成的.
单从音质上来说,还是suno.wav质量好。毕竟910B2硬件好一点。
下面详细说下文生语音的大模型详细部署过程。
(硬件、软件配置和上次我门文生图片T2I一样。
华为昇腾NPU卡 文生图T2I大模型stable_diffusion_v1_5模型推理使用)
环境:
1.硬件配置
申请华为云notebook。
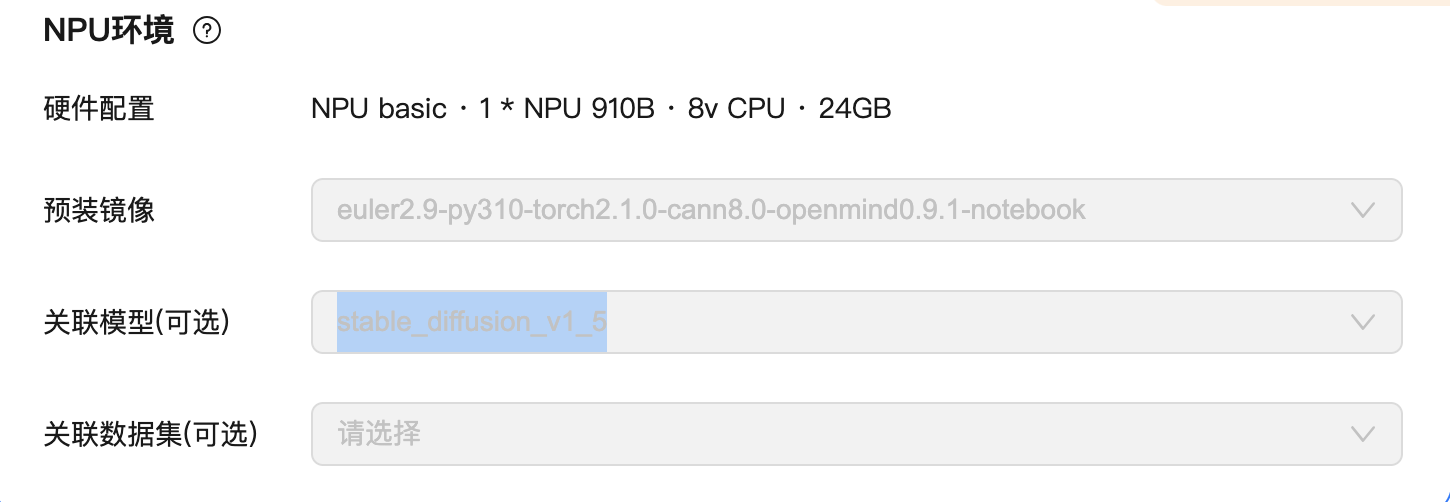
NPU basic · 1 * NPU 910B · 8v CPU · 24GB
2.软件:
预装镜像:euler2.9-py310-torch2.1.0-cann8.0-openmind0.9.1-notebook
jupyter lab中新建一个终端
3.操作步骤:
注意:软件镜像加载完后,里面就包含了所需的基本python包,如果是本地安装,参考上面说的文生图的文章。3.1 下载模型到model目录下,我们采用从本地加载模型方式推理。
在下载前,请先通过如下命令安装ModelScope(https://www.modelscope.cn/models/mapjack/bark/files)
bash
pip install modelscope采用命令行下载完整模型库
bash
modelscope download --model mapjack/bark大概40GB的文件,提前准备好存储空间。下载的最开始会有存放地址提示,如toPath0。
移动文件到model下。
bash
mv toPath0/* /path2/model/mapjack/bark注意:下载完成后需要移动到Jupyter的notebook下,这样方便显示,如果你不用notebook听的话,也可以不移动模型文件。path2替换为自己的目录。
3.2 执行模型推理
最好使用conda建立虚拟环境,不知道怎么建立的,搜索我之前的文章。输入python后,执行下列代码,如果整体报错,可以一行一行的运行,方便修改错误。
创建好输出路径文件/yourpath/output,yourpath替换成自己的路径。
bash
mkdir -p {/yourpath}/output
bash
from transformers import AutoProcessor, AutoModel
import scipy
model = AutoModel.from_pretrained("/path2/model/mapjack/bark").to(device)
processor = AutoProcessor.from_pretrained("/path2/model/mapjack/bark")
if model.config.pad_token_id is None:
model.config.pad_token_id = model.config.eos_token_id
inputs = processor(
text=["Hello, my name is Suno. And, uh --- and I like pizza. [laughs] But I also have other interests such as playing tic tac toe."],
return_tensors="pt",
return_attention_mask=True,
).to(device)
speech_values = model.generate(**inputs, do_sample=True, pad_token_id=processor.tokenizer.pad_token_id, eos_token_id=None )
sampling_rate = model.generation_config.sample_rate
scipy.io.wavfile.write("/{yourpath}/output/bark_out.wav", rate=sampling_rate, data=speech_values.cpu().numpy().squeeze())
# 模型下载:https://www.modelscope.cn/models/mapjack/bark/files
#------参考命令: https://huggingface.co/suno/bark
inputs = processor(
text=["Hello, my name is Suno. And, uh --- and I like pizza. [laughs] But I also have other interests such as playing tic tac toe."],
return_tensors="pt",
).to(device)
# 你以可以修改text中的内容,生成音乐,如下:
inputs2 = processor(
text=["♪ 爱你一万年,爱你到天荒地老,额,[laughs]我要吐了[laughs] ♪ "],
return_tensors="pt",
).to(device)
#开始推理
speech_values = model.generate(**inputs, do_sample=True, pad_token_id=processor.tokenizer.pad_token_id, eos_token_id=None )至此推理完成。准备聆听魔界的声音吧!
3.3 保存成wav文件。
需要引入scipy包文件,上面已经加入了(import scipy),这里过。
bash
sampling_rate = model.generation_config.sample_rate
scipy.io.wavfile.write("/{yourpath}/output/bark_out_2.wav", rate=sampling_rate, data=speech_values.cpu().numpy().squeeze())这时候在note book左侧的output文件夹下下载文件,浏览器播放wav文件。
后者使用note book聆听语音文件了。
bash
from IPython.display import Audio
# 本地文件路径
audio_path = "/{yourpath}/output/bark_out_2.wav"
# 播放音频
Audio(audio_path, autoplay=False)至此结束。恭喜你学会了,文生音频(音乐🎵),🎉👍!
后面学习文生视频【T2V】。