消息队列
基本概念
定义
消息队列(Message Queue, MQ)是一种分布式中间件,通过异步通信、消息暂存和解耦生产消费双方的机制,提供消息的顺序性保证、可靠投递和流量控制能力,广泛应用于微服务解耦、大数据流处理等场景。
核心组件
生产者 producer:消息的生产者,负责发送消息。
消费者 consumer:消息的消费者,订阅并处理消息。
消费者组 consumer group:所有消费者都属于某一消费者组,同一个消费者组内的消费者共同消费同一类型的消息,实现消费性能的扩展。
租户 tenant:逻辑概念,是资源归属和权限控制的基本单位。
集群 cluster:一组节点的集合。
Broker:用于存储和转发消息的物理节点。
主题 topic:逻辑概念,同一种业务类型的消息的集合。
偏移量 offset:消息的唯一标识,由消费者返回,记录目前消费的位置。
消息模型
点对点:消息被单个消费者消费,如订单处理。
发布/订阅:消息广播给多个消费者,如新闻推送。
核心功能
|--------|---------------------------------|
| 功能 | 说明 |
| 服务解耦 | 解除多个业务系统之间的耦合度,减少系统之间影响 |
| 异步通信 | 生产者和消费者无需同时在线,通过消息队列暂存消息实现异步通信 |
| 流量控制 | 削峰填谷,突发流量被队列缓冲,避免压垮下游系统 |
| 顺序收发 | 先进先出,保证消息的顺序性(全局有序或分区有序) |
| 零拷贝 | 通过 OS 和硬件协作,减少数据在内存中的冗余复制,实现高吞吐 |
| 消息回溯 | 重置 offset 到指定位置,重新消费历史消息 |
应用场景
大数据流处理:实时数据处理与 ETL
金融:支付对账、交易流水
物联网:设备指令下发、状态上报
微服务:服务 A 通过 MQ 通知服务 B,避免直接 HTTP 调用带来的耦合和超时风险
Kafka
架构设计
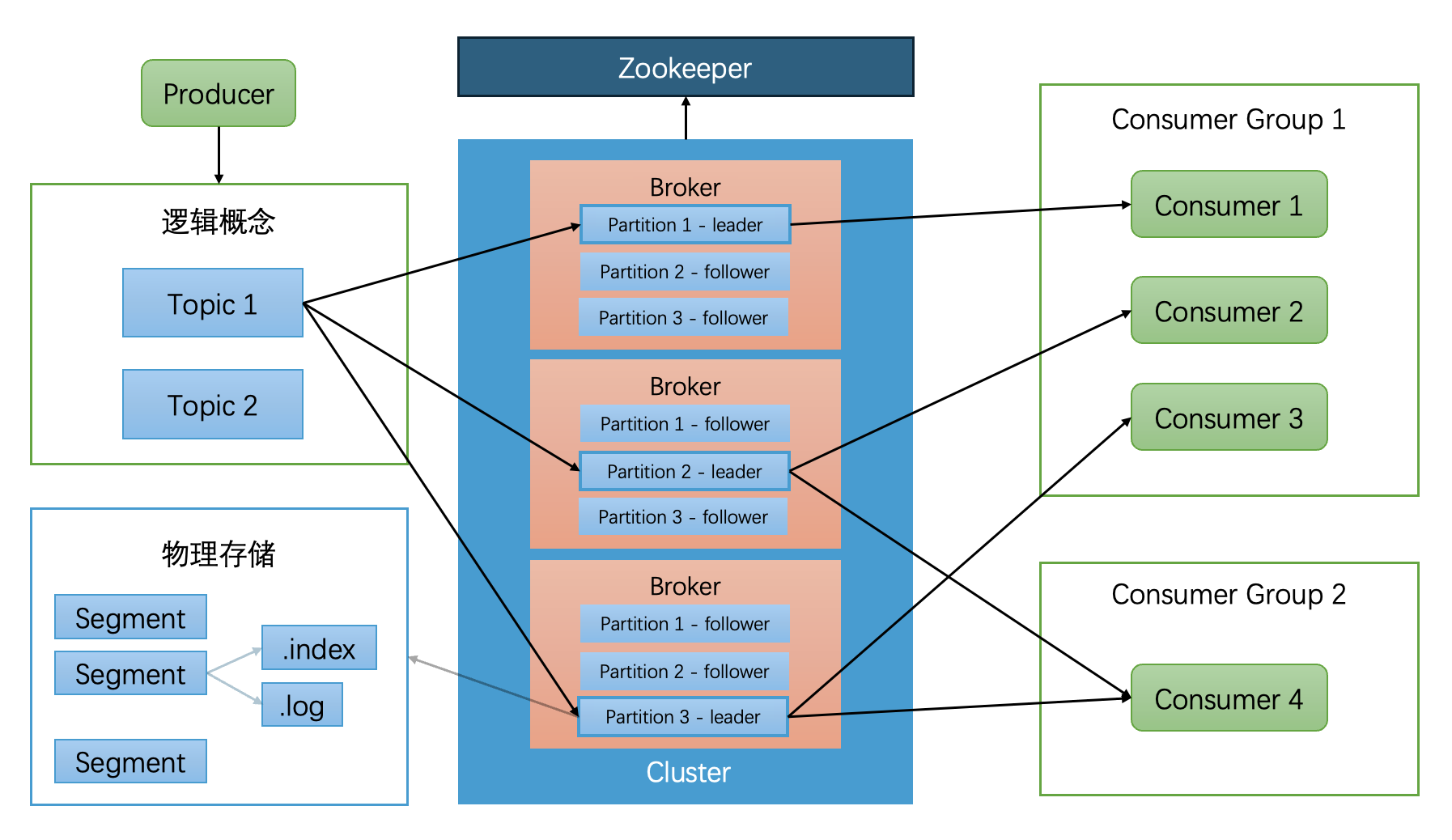
-
生产者从 ZooKeeper* 获取 Topic 的元数据(如 Partition Leader 的位置)后,以 push 模式发布消息到对应的 broker 上。
-
每条消息都属于一个 Topic,每个 Topic 分为多个 Partition 分区,物理上由多个日志分片 Segment 文件组成。每个 Partition 都有多个副本,被存储在不同的 Brokers 上。消息发送到 Leader 后,会同步到 Follower 以确保冗余。
-
消费者以 pull 模式从 Leader 主副本里拉取消息,返回 offset 值用于记录现在消费的位置。
* ZooKeeper 的核心作用
|------------|-----------------------------------------------|
| 功能 | 说明 |
| Broker 注册 | Broker 启动时向 ZooKeeper 注册自己的地址和 Partition 分配情况 |
| Leader 选举 | 当 Leader Partition 宕机时,协助选举新的 Leader |
| Topic 配置管理 | 存储 Topic 的 Partition 数量、副本因子等元数据 |
功能原理
-
持久化:消息存储在 broker 磁盘中,被消费后不会立即被删除
-
高吞吐:单个 partition 批处理,多个 partition 并行处理
-
高扩展:topic 分区化,存储在不同 brokers 中
-
容灾和高可用:每个 partition 都有多个副本,ISR 确保副本之间的同步
-
低延迟:稀疏索引和二分查找
RocketMQ
架构设计
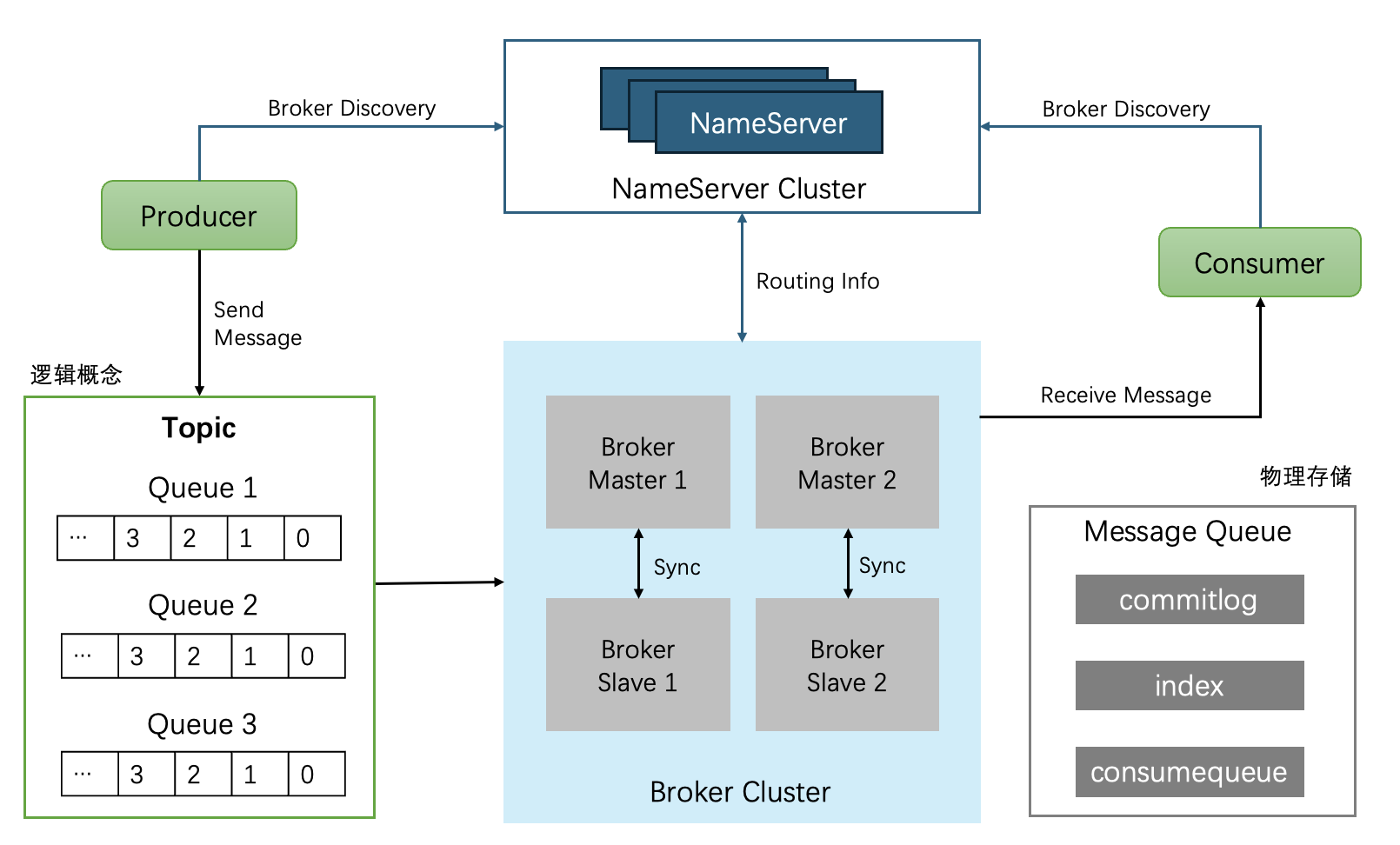
-
生产者向 NameServer 查询 Topic 的路由信息,选择目标 MessageQueue。
-
发送消息到对应的 Master Broker,同步到 Slave。
-
消费者从 NameServer 获取 Topic 的路由信息,从 Master Broker 拉取消息,定期提交 Offset 到 Broker。
功能原理
- 金融级可靠
|-----------------|------------------------------------|
| 同步刷盘 | 所有消息先写入磁盘后才返回 ACK,确保数据不丢失 |
| 主从同步复制 | 消息必须同步到 Slave 节点后才响应生产者,避免主节点宕机丢数据 |
| Broker 主从切换 | Master 故障时,Slave 自动提升为新 Master |
| 多副本 | 支持多副本,数据分布在不同物理机/机架 |
| 严格的顺序性 | 同一队列的消息严格 FIFO,适用于金融交易(如订单状态变更) |
| 死信队列 | 处理失败的消息自动进入 DLQ,避免阻塞正常流程 |
- 事务消息 :两阶段提交
-
生产者发送一条对消费者不可见的半消息(Half Message)到 Broker,Broker 持久化该消息,但不会将其投递给消费者。
-
生产者执行本地数据库操作后,根据本地事务结果,向 Broker 发送 Commit 或 Rollback 指令。
-
仅当收到 Commit 后,Broker 才将消息标记为可消费,后续推送给消费者,以确保本地数据库事务和消息发送两个操作的原子性。
- 消息过滤 :基于 tag 或 sql 语句进行过滤,在服务端将符合条件的消息投递给消费者。
Pulsar
产品架构设计
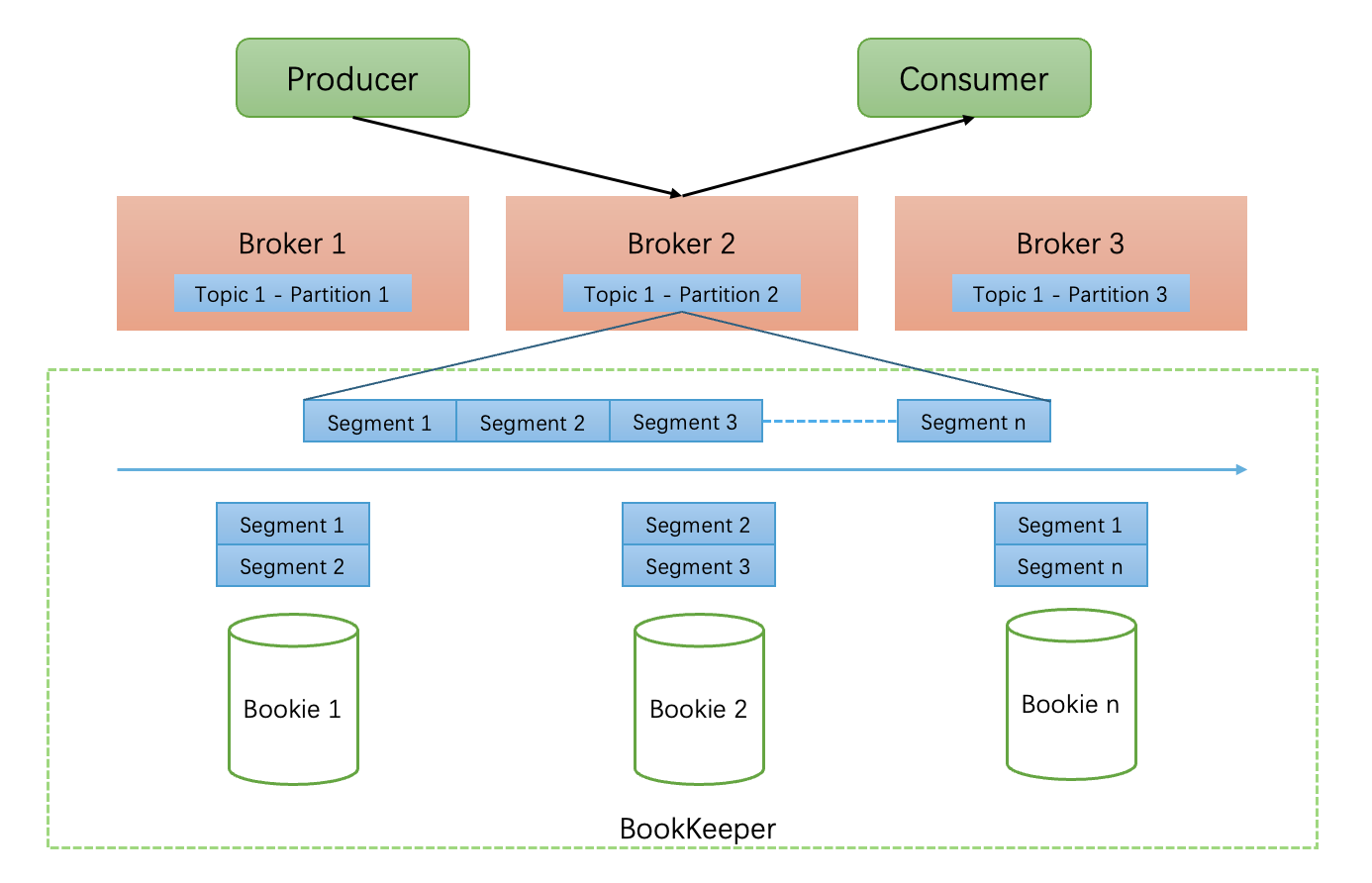
* Segment 即 BookKeeper 的 Ledger,是一种 append-only 的日志文件
-
生产者查询 Topic 路由,将消息发送到对应的 Broker
-
消息被拆分为多个 Segment,broker 将消息写到多个 bookie 中持久化存储。(同一个 partition 的 segment 分散在多个 bookie,支持多个 bookie 并行读取。)
-
消费者请求消息,broker 从 bookie 中拉取消息并转发给消费者
功能原理
- 计算(Broker)与存储(Bookie)分离:
-
broker:无状态的 proxy 服务,负责接收消息、传递消息、集群负载均衡等操作。
-
bookie:有状态,负责持久化存储消息。
-
故障隔离:Broker 崩溃不影响数据,Bookie 故障自动从其他副本重建恢复。
-
弹性扩展:Broker 无需考虑数据迁移,可快速水平扩缩容;Bookie 存储层可按需独立扩展,新增 Bookie 后,数据自动重新分布。
MQ 系列对比
|--------|------------------------------------------|-------------------------------|-------------------------------------------------------|
| 产品 | Kafka | RocketMQ | Pulsar |
| 产品特性 | 高并发、高吞吐、实时流处理平台 | 低延迟、高可靠、强一致 | 云原生、存算分离、跨地域复制 |
| 应用场景 | 对吞吐要求高的离线场景 | 对可靠性要求高的在线业务场景 | 兼容在线和离线请求 |
| 适用业务 | • 网页活动追踪 • 日志分析、监控采集 • 流数据集成 | • 电商在线支付、直播 • 证券交易 • 金融对账 | • 跨云/跨地域数据同步 • IoT 设备管理与监控 • Serverless 事件驱动 |
| broker | 存储数据,处理消息请求 | 存储数据,处理消息请求 | 无状态的服务,不存储数据,只负责消息的路由和处理 |
| 数据存储单位 | Partition | CommitLog(唯一物理存储文件,完全顺序写入) | Segment(颗粒更小,更利于存储负载均衡) |
| 数据一致性 | 依赖 ISR 机制 | 同步刷盘 + 主从同步 | BookKeeper 支持同步复制 |
| 扩展性 | 通过增加 Partition 数量,扩容 Broker 需要 rebalance | 通过增加 Broker 组扩展 Queue 数量 | Broker/Bookie 独立按需扩展计算/存储 |
| 故障切换 | 依赖 Controller 选举新 Leader | 组内 Slave 接管 Master,无需数据迁移立即接管 | • Broker 崩溃后,新节点无需数据迁移立即接管 • Bookie 节点故障时,数据自动从其他副本重建 |
常见 问题
为什么需要消息队列?
首先要知道什么是消息队列:消息队列通过解耦生产与消费者来实现消息异步、流量控制等功能。
那么什么是生产者/消费者:生产者通常是业务动作的发起者,生产需要被传递或处理的业务数据,可以是订单系统、支付系统、传感器设备等;而消费者通常是下游服务或数据分析模块,比如库存系统、Spark 作业等。

为什么需要解耦生产者和消费者:消息队列产品的主要作用就是转储日志、监控数据等,举个例子就像丰巢快递柜,快递员若是不能把快递及时送到人员手上会造成快递拥堵,效率减慢;但是有丰巢柜来存储后就可以有一个地方暂存,消费者需要消费的时候再去拿快递,拉消息一样的道理。通过消息队列,业务系统可以做到故障隔离(生产者宕机不影响消费者)弹性扩展(应对流量波动),真正实现"高内聚、低耦合"的业务架构。
为什么叫消息队列为集群?
集群是一组节点的集合,节点可以是物理机或虚拟机。消息队列产品采用了分布式架构设计,通过多节点协作实现高可用、高性能和可扩展性(具体参见上面的架构设计图)。
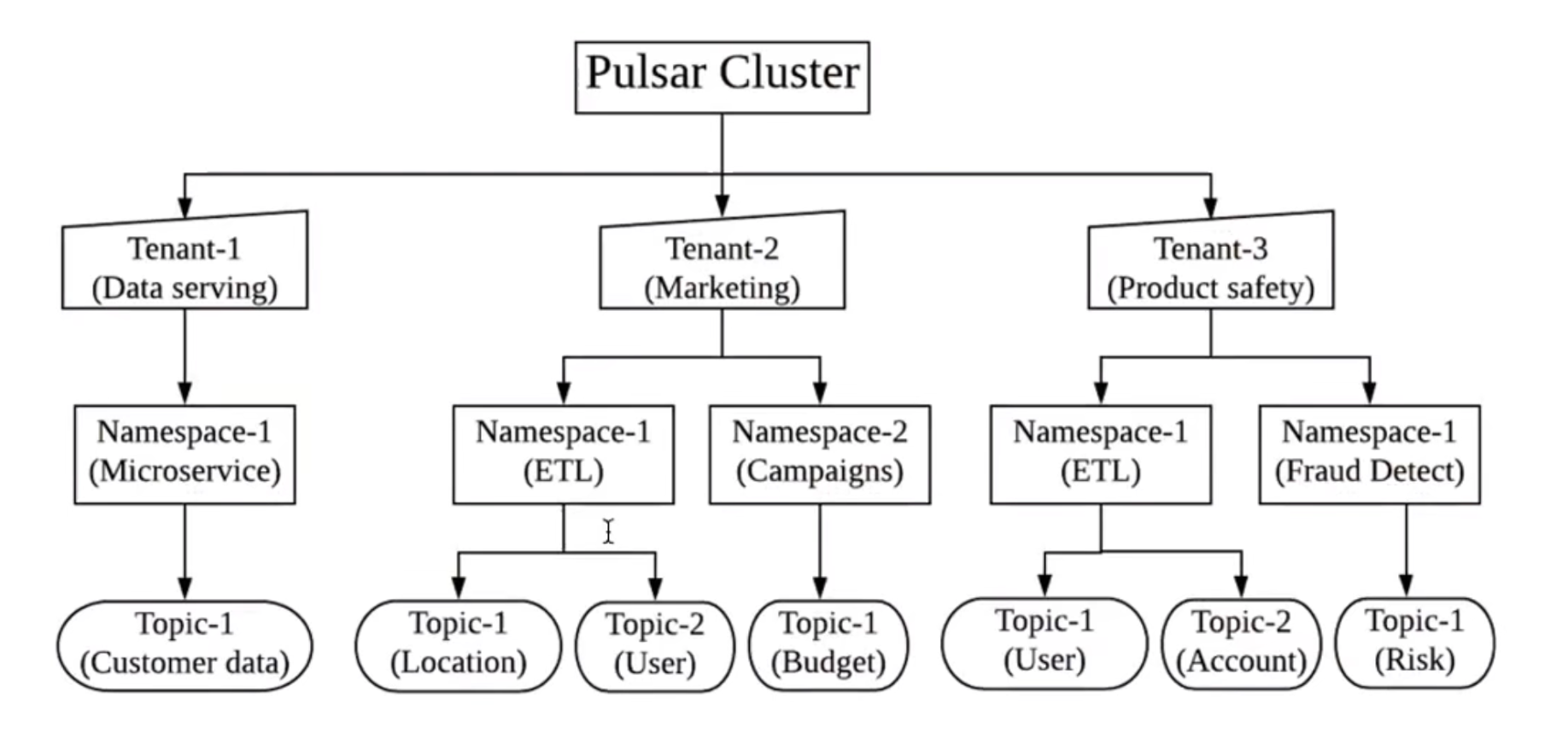
命名空间是做什么的?
命名空间能在多租户之间实现逻辑隔离。
首先要理解多租户的概念,多租户就是多个用户共享一个集群。消息队列产品通过命名空间和角色权限的配合来实现权限管控,从而实现不同命名空间之间的逻辑隔离。具体来讲就是为用户(角色)配置某个命名空间内的读写权限,一个命名空间里的所有 topic 都继承相同的设置,则用户只对该命名空间内的 topic 有操作权限。可以参考下图帮助理解:
如何理解 topic 这个概念?
在学习消息队列产品的过程中,要注意区分逻辑概念和物理概念。像 topic 和 partition 都是业务上的逻辑概念,实际上最后消息都是以一个个 segment 文件的形式存储在物理机器上。
topic 代表了消息的类别或主题,是生产消费的最小单位。从业务层面来讲,topic 就像是一个消息的分类标签,生产者将相关的消息发送到特定的 topic 中,而消费者则通过订阅感兴趣的 topic 来获取和处理这些消息。这种设计使得不同业务领域的消息能够自然地隔离,比如订单系统的消息可以发布到"order_topic",而支付系统的消息则流向"payment_topic",从而实现业务逻辑的清晰划分。
topic 的设计还体现了消息队列的关键特性------发布/订阅模式。生产者不需要知道有哪些消费者存在,只需关注将消息发送到正确的 topic;同样,消费者也只需订阅自己关心的 topic,无需感知消息的生产者是谁。这种松耦合的架构使得系统各组件能够独立演化,大大提升了整体架构的灵活性。此外,通过 topic 可以实现消息的多播,即一条消息可以被多个消费者组同时消费,这在需要将同一数据用于不同业务场景时显得尤为重要。
什么是数据落盘?
计算机存储分为磁盘、内存和缓存等。
消息队列将接收到的数据写入磁盘持久化存储的过程叫做落盘,比如消息存储到 kafka 和 rocketmq 的 broker 以及 pulsar 的 bookie 的磁盘上这个过程。
具体实现上,kafka 是将消息先写入 Page Cache(内存缓冲),再异步刷盘(可配置同步刷盘),RocketMQ 支持同步刷盘(每条消息立即写入磁盘)或异步刷盘(批量写入)。
消息队列如何保证数据的一致性?
kafka 通过 ISR(In-Sync Replicas)机制来维护数据一致性。当生产者发送消息时,Leader 副本会先将消息写入本地日志,然后要求所有 ISR 中的 Follower 副本完成同步复制后,这条消息才会被确认为已提交。
RocketMQ 采用了双重保障机制来维护数据一致性。首先是同步刷盘策略,当 Broker 接收到消息后,可以选择立即将消息写入磁盘(同步刷盘)而非仅保留在内存中。其次是主从同步机制,每个主节点都会将消息同步到其从节点,只有当主从都成功写入后才会向生产者返回确认响应。
Pulsar 依赖 BookKeeper 作为底层存储引擎,每条消息都会被同步复制到多个 Bookie 节点,只有当大多数节点确认写入后,这条消息才会被标记为持久化成功。