前言
最近不知道哪个脑子抽住了,想吧vllm那套流程代码巴拉巴拉,整理整理流程,但这个玩意如果需要测提速多少,需要进行编译安装,里面有个flash-attn,正好最近还想学学c++和py的混合编译,所以就先本地win下编译安装flash-attn
环境搭建
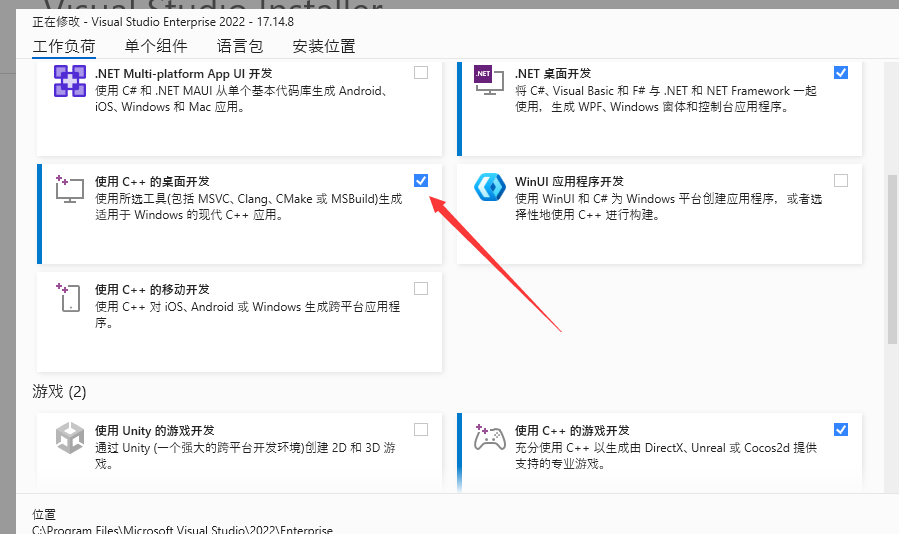
首先,你得确认你的cuda是正常的,比如用pytorch进行gpu调用是否正常,这个环节,说实话网上太多了这里就不写了,然后,是vs,我这里选择了这几个c++开发项注意重点是中国c++的桌面开发
然后,需要自己去安装一下cmake和ninja(ps:未必为必须,因为我装的时候已经有cmake和ninja了,不知道不装会不会报错,这里默认是装了吧)
cmake 下载地址
然后,ninja的地址
ninja的github地址
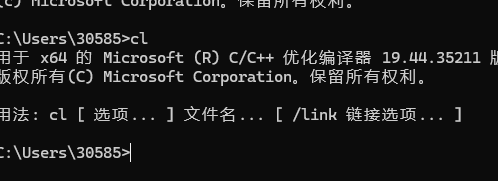
cl 检查
这个必须单独领出来说,因为我发现我的vs在安装环境时,不会吧cl所在路径注册到当前系统的环境变量下,而且由于vs是同时支持64和32位俩个的安装,cl是有俩个的,所以这里得用64位版本,路径如下
python
C:\Program Files\Microsoft Visual Studio\2022\Enterprise\VC\Tools\MSVC\14.44.35207\bin\Hostx64\x64配置好后确认一下记得
项目编译
这里我默认你已经从flash-attn的github下载完成了项目。
然后,我是修改了setup.py下的一些默认配置项,
python
FORCE_BUILD = os.getenv("FLASH_ATTENTION_FORCE_BUILD", "TRUE") == "TRUE"
## 注意,如果你只是在无cuda设备上安装,这个改成true,没后边一堆屁事。
SKIP_CUDA_BUILD = os.getenv("FLASH_ATTENTION_SKIP_CUDA_BUILD", "False") == "TRUE"
# For CI, we want the option to build with C++11 ABI since the nvcr images use C++11 ABI
FORCE_CXX11_ABI = os.getenv("FLASH_ATTENTION_FORCE_CXX11_ABI", "TRUE") == "TRUE"
USE_TRITON_ROCM = os.getenv("FLASH_ATTENTION_TRITON_AMD_ENABLE", "FALSE") == "TRUE"
SKIP_CK_BUILD = os.getenv("FLASH_ATTENTION_SKIP_CK_BUILD", "TRUE") == "TRUE" if USE_TRITON_ROCM else False如果你是用git clone 下来的项目,记得同步一下git,用一下git submodule update --init --recursive,不然cutlass和composable_kernel是没有的
如果你是手动下的项目,请也记得吧这俩个项目down下来,放到这个路径下
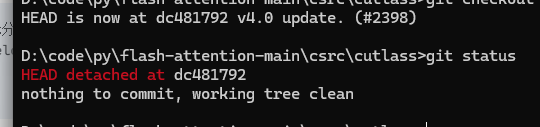
check 注意,
composable_kernel版本为(以截至2025/7/20为准)
663992e99b412991eab554b0deb89bb916d40161

cutlass版本需要是(以截至2025/7/20为准)
dc4817921edda44a549197ff3a9dcf5df0636e7b
然后直接执行pip install .,注意这里有个小点,然后如果安装成功完事大吉。如果安装失败,恭喜你,喜提报错
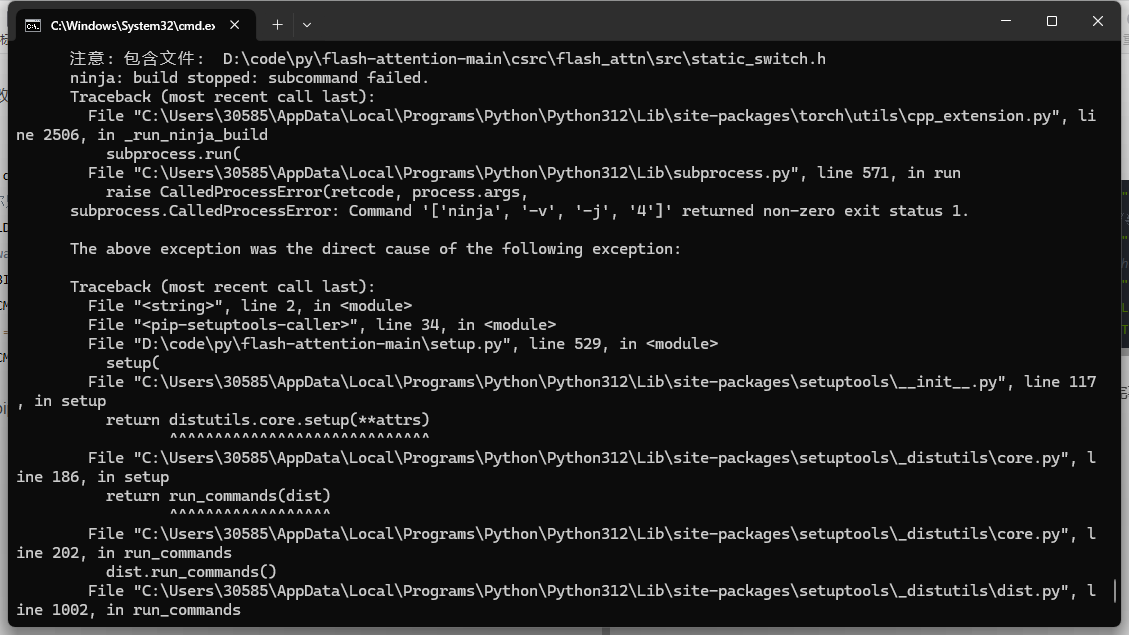
开始修坑
注意,由于这部分又是隔了几天继续写,可能与上面有冲突,日后不优化.jpg
我这里是为了确认环境有没有问题,写了一个python的c++demo。当然,这个操作很多余,上面的报错明说了,它走c++17的分支,遇到编译异常,说明应该解决的是看看为什么编译异常,而不是在·这里排查环境问题。
c++ 部分
cpp
#include <Python.h> // 引入 Python C API
#include <numpy/arrayobject.h> // 引入 NumPy C API,用于处理 NumPy 数组
#include <iostream> // 引入输入输出流库
#include <vector> // 引入动态数组库
#include <string> // 引入字符串库
// #if (201703L <=__cplusplus)
/// std::is_unsigned_v
using CUTLASS_STL_NAMESPACE::is_integral_v;
/// std::is_unsigned_v
using CUTLASS_STL_NAMESPACE::is_unsigned_v;
// #endif
// 一个简单的模板函数,用于测试模板编译
template <typename T>
T multiply(T a, T b) {
return a * b;
}
// C++ 函数,实现数组相加的逻辑
// 注意:这里我们仍然保持 float* 参数,因为 ctypes 会处理
void add_on_cpu_impl(float *a, float *b, float *c, int N) {
double prod_double = multiply(2.5, 4.0);
std::cout << "std::is_unsigned_v<unsigned int>: "
<< std::is_unsigned_v<unsigned int> << "\n";
std::cout << "std::is_unsigned_v<int>: "
<< std::is_unsigned_v<int> << "\n\n";
for (int i = 0; i < N; ++i) {
c[i] = a[i] + b[i];
}
}
// Python 包装函数:将 Python 参数转换为 C++ 可理解的类型,调用 C++ 核心逻辑,然后返回 Python 对象
static PyObject* add_on_cpu_wrapper(PyObject* self, PyObject* args) {
PyObject *py_a, *py_b, *py_c;
int N;
// 解析 Python 传入的参数
// "O&" 表示将一个 Python 对象通过转换函数转换为 C 类型
// "&PyArray_Converter" 是 NumPy C API 提供的转换函数,用于将 Python 对象转换为 PyArrayObject*
// "i" 表示一个 int 类型
if (!PyArg_ParseTuple(args, "O&O&O&i",
PyArray_Converter, &py_a,
PyArray_Converter, &py_b,
PyArray_Converter, &py_c,
&N)) {
return NULL; // 解析失败则返回 NULL
}
// 从 PyArrayObject 获取底层数据指针
float* a = (float*)PyArray_DATA((PyArrayObject*)py_a);
float* b = (float*)PyArray_DATA((PyArrayObject*)py_b);
float* c = (float*)PyArray_DATA((PyArrayObject*)py_c);
// 调用实际的 C++ 核心逻辑
add_on_cpu_impl(a, b, c, N);
// 返回 None(Python 中的 None)表示成功
Py_RETURN_NONE;
}
// 定义模块方法列表
// 告诉 Python 这个模块有哪些函数可以被调用
static PyMethodDef AddCpuMethods[] = {
{"add_on_cpu", add_on_cpu_wrapper, METH_VARARGS, "Add two arrays on CPU."},
{NULL, NULL, 0, NULL} // 哨兵值,表示方法列表的结束
};
// 模块定义结构体
// 告诉 Python 解释器关于这个模块的信息
static struct PyModuleDef add_cpu_module = {
PyModuleDef_HEAD_INIT,
"add_cpu", // 模块名,必须与 Extension('add_cpu', ...) 中的 'add_cpu' 匹配
"A simple C++ extension for adding arrays.", // 模块文档字符串
-1, // 模块状态大小,-1 表示模块不维护状态
AddCpuMethods // 模块方法列表
};
// 模块初始化函数
// Python 导入模块时调用的入口点
// 必须命名为 PyInit_<module_name> (这里的 module_name 是 'add_cpu')
PyMODINIT_FUNC PyInit_add_cpu(void) {
// 导入 NumPy API
import_array();
// 创建模块
return PyModule_Create(&add_cpu_module);
}python 部分
python
import numpy as np
import os
import sys
# 直接导入编译好的 C++ 模块
# 确保 test_cpu.py 和 add_cpu.pyd 在同一个目录下
# 或者将 add_cpu.pyd 所在的目录添加到 sys.path
try:
import add_cpu # 现在可以直接导入了!
except ImportError as e:
print(f"Error importing add_cpu module: {e}")
print("Please ensure add_cpu.cp312-win_amd64.pyd is in the same directory or in PYTHONPATH.")
sys.exit(1)
# 准备输入数据
N = 1000000
a = np.random.rand(N).astype(np.float32)
b = np.random.rand(N).astype(np.float32)
c = np.zeros(N).astype(np.float32) # 输出数组
print(f"Array size N: {N}")
# 调用 C++ 函数
print("Calling add_cpu.add_on_cpu...")
# 注意:我们现在直接调用模块内的方法,而不是通过 ctypes
add_cpu.add_on_cpu(a, b, c, N)
print("add_cpu.add_on_cpu call finished.")
# 验证结果
expected_c = a + b
if np.allclose(c, expected_c):
print("Results match! CPU computation successful.")
else:
print("Results do NOT match. There might be an issue.")
# 可以打印部分数组内容进行调试
# print("First 10 GPU results:", c[:10])
# print("First 10 CPU results:", expected_c[:10])setup.py部分
python
import os
import subprocess
from setuptools import setup, Extension
import numpy # 导入 numpy 以获取其头文件路径
import torch
from torch.utils.cpp_extension import (
BuildExtension,
CppExtension,
CUDAExtension,
CUDA_HOME,
ROCM_HOME,
IS_HIP_EXTENSION,
)
print("\n\ntorch.__version__ = {}\n\n".format(torch.__version__))
TORCH_MAJOR = int(torch.__version__.split(".")[0])
TORCH_MINOR = int(torch.__version__.split(".")[1])
# Check, if CUDA11 is installed for compute capability 8.0
cc_flag = []
cc_flag.append("-gencode")
cc_flag.append("arch=compute_120,code=sm_120")
# HACK: The compiler flag -D_GLIBCXX_USE_CXX11_ABI is set to be the same as
# torch._C._GLIBCXX_USE_CXX11_ABI
# https://github.com/pytorch/pytorch/blob/8472c24e3b5b60150096486616d98b7bea01500b/torch/utils/cpp_extension.py#L920
nvcc_flags = [
"-O3",
"-std=c++20",
"-U__CUDA_NO_HALF_OPERATORS__",
"-U__CUDA_NO_HALF_CONVERSIONS__",
"-U__CUDA_NO_HALF2_OPERATORS__",
"-U__CUDA_NO_BFLOAT16_CONVERSIONS__",
"--expt-relaxed-constexpr",
"--expt-extended-lambda",
"--use_fast_math",
"-Xfatbin",
"-compress-all",
"-compress-mode=size",
]
def append_nvcc_threads(nvcc_extra_args):
nvcc_threads = os.getenv("NVCC_THREADS") or "4"
return nvcc_extra_args + ["--threads", nvcc_threads]
compiler_c17_flag=["-O3", "-std=c++14"]
setup(
name='add_cpu_example',
version='0.1.0',
description='A simple example of calling C++ from Python (CPU version)',
ext_modules=[
Extension(
'add_cpu', # Python 中导入时的模块名
sources=['add_cpu.cpp'], # 对应的 C++ 源文件
# 包含 NumPy 头文件目录
include_dirs=[numpy.get_include()]
),
CUDAExtension(
name="add_cpu", # Python 中导入时的模块名
sources=['add_cpu.cpp'], # 对应的 C++ 源文件
extra_compile_args={
"cxx": compiler_c17_flag,
"nvcc": append_nvcc_threads(nvcc_flags + cc_flag),
},
include_dirs=[numpy.get_include()]
)
],
# 移除 cmdclass={'build_ext': SimpleBuildExt}, 让 setuptools 使用默认的 build_ext
)然后,python setup.py build_ext --inplace,执行之前,如果先去有别的编译记录,记得删一下build文件夹,不然不更新概率不低,成功后当前路径下出现pyd,然后执行python,得到如下就说明当前环境没问题
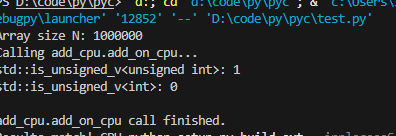
一个瓜皮问题的解决,#if (201703L <=__cplusplus)为false?
我这c++17环境兼容也排查了,cl也确定没问题,但就是报错,排查发现一个很奇怪的地方

它的报错,是因为用的是自己的is_unsigned_v导致的,奇怪了,点过去看看
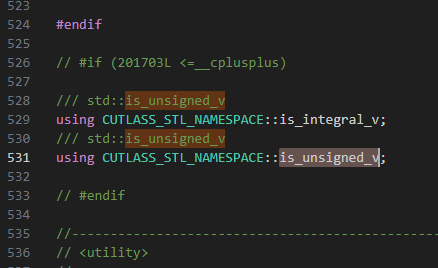
我看了一下,这个if判断不知道为什么进不来,没办法,那就只好注释,强制开启,然后继续编译,就可以继续修改bug了?
奇怪,我c++20都支持的,凭什么这里打印不对?问问gemini

然后,我试着在上面的setup.py中,添加这个后测试。。
添加前
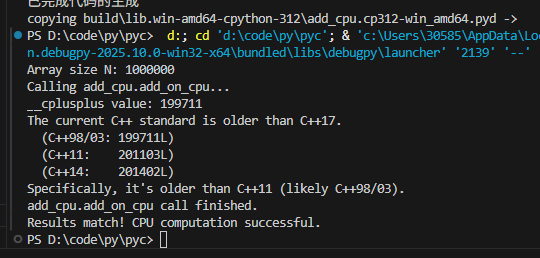
添加后
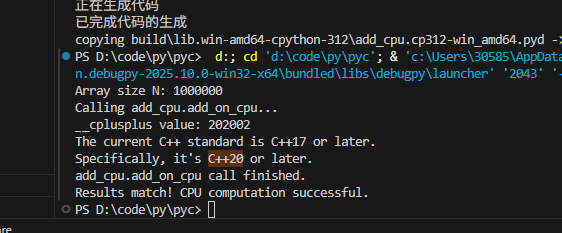
唉,多了不说,我这种菜鸟写c++简直就是灾难,赶紧加上去吧
加完了,继续编译,没问题就是安装成功了
最后
如果有办法,还是别头铁硬碰了,这种问题c++大佬来了30分钟不到解决,我硬是碰了小一周的晚上才解决完,不说了,都是泪。最后编译耗时一小时