欢迎大家来到企业级AI售前机器人实战系列文章: 从0到1完成一个企业级AI售前机器人的实战指南。
本篇是该系列的第八篇,核心内容是:Agent落地之三大辅助系统记忆系统、评估系统、护栏系统
AI应用中除了我们常见的工作流、各类功能节点之外,通常还会附带有三个辅助系统:
-
用来AI记住用户的历史交互信息,从而提供更连贯、个性化和高效的响应的记忆系统
-
用来验证AI在实际应用中的真实效果、发现潜在问题并确保其安全可靠运行的评估系统
-
用来过滤和审查输出内容,确保AI输出的内容安全、合规且符合回复逻辑的护栏系统
关于我
我是一个十年老程序员、React Contributor,三年前转型至AI在应用层的设计与落地。
目前转型成功,并担任多个AI项目负责人,已经完成了多款智能问答产品的上线、以及TOB产品的功能AI化升级。
本专栏将会基于我过去几年的经验,对各类AI应用落地的方案和思路积累了很多踩坑和迭代经验,进行全方位的AI产品的核心流程拆解!
我相信AI在未来将会是基础设施,而对于普通人而言,基础设施的机会不在基础设施本身,在应用层谋求发展可能是一个不错的出路。
回归正题:
记忆系统:让AI拥有"商业头脑"的秘诀
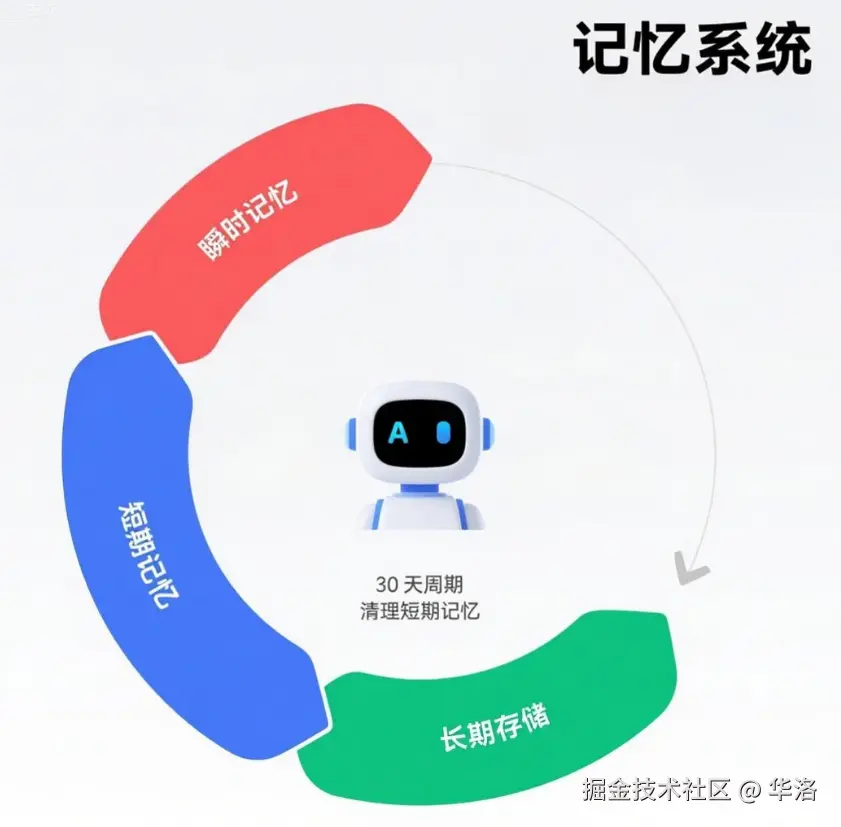
记忆系统是AI售前机器人的"记忆中枢",它让对话不再是机械的一问一答,而是持续进化的商业关系维护。我们采用三级记忆架构:
- 瞬时记忆:像金牌销售的话术本能,处理当前对话的上下文(通常保留最近5-6轮对话)
- 短期记忆:类似客户经理的记事本,记录30天内的关键交互(如产品偏好、报价记录),并以此为基础形成用户画像
- 长期记忆:相当于企业的CRM系统,存储客户画像、历史订单等结构化数据
例如:当老客户咨询时,AI会自动说:"王先生您好!上次询问的机器人系统更新了,并且现在为您提供了8折优惠,需要我为您生成订单吗?"
这种对话能力,将会大大提高老客户的复购能力。
我们通过向量数据库+时间衰减算法实现智能记忆管理,确保AI既不会"健忘",也不会被过期信息干扰。
以下是AI售前机器人三级记忆系统的技术实现方案,结合了当前AI工程的最佳实践:
- 瞬时记忆(对话上下文记忆)
瞬时记忆的储存方式为当前对话的上下文,表达的是当下用户的需求和意图。
通常的实现方式,就是记录历史对话,记录历史对话有两种方式,一种是使用message 数组,一种是提示词中历史对话
截止到2025年,效果是其实都差不多,虽然message对话轮数过多之后,可控性不如直接使用提示词。
但是message数组有一个明显的好处,如果有恶意的输入,导致提示词泄露时,message是不会泄露信息的。
例如:
js
const res = await openai.chat.completions.create({
messages: [
{role:'assistant',content:"人设、任务、要求相关的提示词"}
{ role: 'user', content: "用户的提示词注入" }
],
model: model,
stream: true
});上述这种结构,用户的提示词注入通常不会造成提示词泄露。
而使用提示词直接进行对话的,有可能造成泄露。
js
提示词
## 角色
## 任务
## 历史对话
此处放着历史对话 和 用户的最后输入
## 输出这种直接使用提示词的,提示词注入生效之后,就可能会造成提示词泄露。
- 短期记忆(30天交互记忆)
对用户30天内的沟通内容,进行提炼,以此来形成对用户最近的购买需求、购买意向信息的评估
由短期记忆的内容最终生成用户的评级。根据用户的评级进行针对性的对话策略的切换。
短期记忆需要异步的在每隔固定的几轮对话之后进行更新,使用提示词更新即可:
伪提示词:
md
当前用户短期内的信息为:
【过去存储的短期记忆】
用户再次与我进行了如下对话:
【最近的对话信息】
整理信息,并更新用户的短期信息。每次用户更新后的短期记忆,都会重置【过去存储的短期记忆】,一遍下一轮的使用
- 长期记忆(CRM集成)
长期记忆中保存着用户的基本信息,例如:姓名、联系方式、购买能力等,
根据用户的这些基本信息,让AI客服对用户有一个大致的了解,添加我们提前设置好的策略,可以进行随机应变的对话。
伪提示词:
md
根据历史对话,综合分析户的姓名、联系方式、购买能力【等,我们希望的任意信息】以上三种记忆模式,是并存的, 每次AI客服在进行回复的时候,都是根据三类记忆的整合数据进行回复。
最终大模型的回复提示词中,会包含这些信息的综合体现
md
【其他提示词】
## 用户信息
【这里的内容是短期记忆 + 长期记忆综合形成的】
## 历史对话
【这里的内容是最近几轮的内容,也就是瞬时记忆】
【其他提示词】有了记忆系统的存在,AI客服就和用户有了牵绊,我们可以让AI客服根据用户的各类信息评估,采取不同的提示词来应对客户。
评估系统:AI的"全科体检中心"

评估系统是AI售前机器人的"健康监测站",它通过多维度的量化指标持续跟踪机器人的表现。
确保我们的系统没有在一次次的更新迭代中发生什么我们不为所知的变化。
例如:
-
我们的提示词工程师更新了五个提示词,我们要监控对线上环境的影响。
-
我们的数据同事更新一批数据,我们要监控线上环境中准确率和命中率的变化。
基础健康指标
-
监测响应速度:API延迟控制在800ms以内
-
监测对话流畅度:评估语句通顺度,判断大模型上下文是否异常终端以及输出是否符合我们提示词中要求的风格。
-
监测意图识别准确率: 每个意图都固定有十个句式进行监测。如果失败了就证明提示词出现问题了
监测方式
出发监测的方式,要同时支持人工触发 + 定时触发。监测的结果,可以通过钉钉或者企业微信的webhook进行推送。
评估系统数据准备
评估系统需要我们提前准备一批数据,包含了我们场景中的尽可能多的问题。
数据需要准备:问题、答案、预期正确回复、预期意图、预期首包响应时间。
然后无论是定时还是人工,触发之后将这些数据以此请求一遍我们的线上接口,并且对比响应数据和预期数据
根据结果进行推送和告警。
护栏系统:AI的"数字警察"

我们为护栏系统部署两道防线:
-
输入过滤层:
- 敏感词实时检测(支持方言和谐音识别)
- 意图合法性判断(阻止"如何破解产品"类提问)
- 情绪识别引擎(当检测到用户愤怒时进行转人工等操作)
-
输出审核层:
- 逻辑一致性检查(防止前后矛盾的回答)
- 事实核查(对接企业知识库验证数据准确性)
- 合规性审查(自动匹配广告法、行业规范)
我们重点说一下输出层,由于大模型的幻觉以及不确定性,我们的整个回复逻辑中,很有可能会出现匹配到错误内容,而大模型认为正确。
并且,大模型准备将错误的内容输出给用户,这时候,我们的护栏程序就起到作用了。
我们一定是不允许在最终回复过程中,回复错误信息的,所以我们护栏程序会对答案进行一次最后的验证。
验证没问题,再交给大模型进行润色回复。
例如:
用户询问了A产品,在我们处理完之后,拿到了B产品的介绍,准备作为参考资料提供给大模型。
在提供给大模型之前,我们的护栏程序发现,B产品的介绍给A产品是不对的,所以会拦截这个信息。
最终防止错误的回复用户。
伪提示词如下:
md
## 业务知识
【这里根据自己的业务场景,添加必须让大模型知道的业务知识,例如对某些名词的解释】
## 资料
【知识库匹配出来的答案】
## 问题
【用户的query】
## 要求
- 必要的知识放在【业务知识】中,查询业务知识的信息与user对齐概念。
- 判断资料是否能够有效的回复user的问题。
- 如果资料是有效的,返回'''Y''',否则返回'''N''',不要输出任何其他内容。
## 输出最终当护栏程序拦截了内容时,我们还可以调用query改写,再进行重试。或者把知识库匹配到的问题直接以相似问的形式返会给用户。
- query改写的逻辑是把query的语法、用词等修改成和我们的知识库中存的数据相似性高一些的新query,以此来增加匹配度。
- 相似问的逻辑是我们把问题抛回给用户,让用户自己进行选择他想问的问题或者重新提问。
结语
Agent的三大辅助系统,记忆系统、评估系统、护栏系统。几乎在AI应用中是必不可少的。
大家可以根据自己的业务对实现细节进行一些微调,也可以在评论区中提出您的问题。
后续我会不断把新的内容搬到这个专栏,希望这个系列能够打造成帮助大家落地AI产品时的实战手册!
大家多多点赞 + 关注,给点动力,更新的快快的!
提前订阅不迷路:售前AI机器人掘金专栏地址。
☺️你好,我是华洛,如果你对程序员转型AI产品负责人感兴趣,请给我点个赞。
你可以在这里联系我👉www.yuque.com/hualuo-fztn...
已入驻公众号【华洛AI转型纪实】,欢迎大家围观,后续会分享大量最近三年来的经验和踩过的坑。
专栏文章
# 从0到1打造企业级AI售前机器人------实战指南五:处理用户意图的细节实现!
# 从0到1打造企业级AI售前机器人------实战指南四:用户意图分析(路由解决方案)
# 从0到1打造企业级AI售前机器人------实战指南三:RAG工程的超级优化
# 从0到1打造企业级AI售前机器人------实战指南二:RAG工程落地之数据处理篇🧐