- 发表时间:2025
- 期刊会议:USENIX Security
- 论文单位:Zhejiang University
- 论文作者:Wenlong Meng、Shuguo Fan、Chengkun Wei†、Min Chen、Yuwei Li、Yuanchao Zhang、Zhikun Zhang、Wenzhi Chen
- 方向分类:Attack AI-generated text (AIGT) detectors
- 论文链接
- 开源代码
创新点
-
基于梯度的AIGT攻击方法:GradEscape 能直接利用检测器的梯度信息指导文本修改,以规避检测。
-
解决文本不可微分的问题:使用伪嵌入(pseudo embeddings)将离散文本转化为可微的连续表示,使得可以将梯度反传到攻击模型中,这是过去方法难以做到的。
-
提出 warm-start 技术解决 tokenizer 不匹配问题:提出 Warm-Started Evader*方法,可将任意语言模型(如 BERT、GPT2)转换为可攻击的 seq2seq 模型,兼容任意架构的检测器?
-
支持 opaque 模型攻击(黑盒攻击):即便只能通过 API 查询检测器,GradEscape 也能通过"tokenizer 推断攻击 + 模型提取攻击"训练出替代模型,实现有效攻击。
-
攻击效果优异,成本低廉:在多个数据集和多个检测模型(包括商用检测器如 Sapling 和 Scribbr)上,GradEscape 的逃逸成功率显著优于现有主流 evader(如 DIPPER、SentPara),且参数仅为 139M,远小于 11B 的 DIPPER。
定义
训练一个逃避模型可以被表示如下:
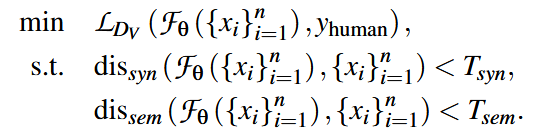
F是逃避模型,xi是输入的一条文本,LDV是检测器Dv的cross-entropy loss,dis_syn是syntactic distance,dis_sem是semantic distance。
白盒攻击
检测器是open models的。
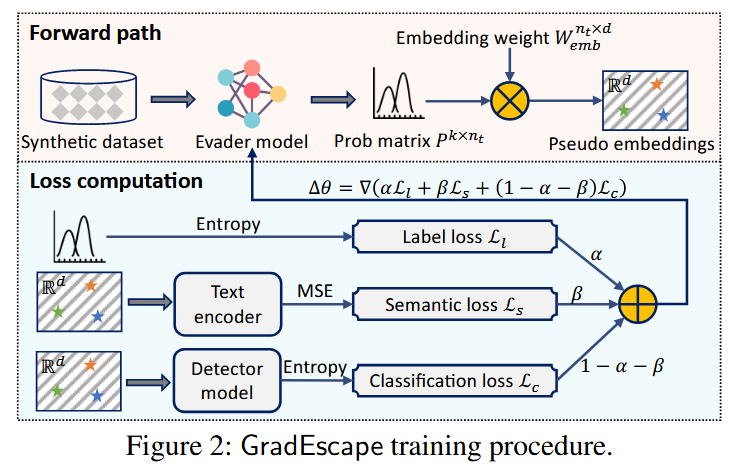
作者分别用Classification loss、Label loss、Semantic loss代替定义中的LDV、dis_syn和dis_sem。作者虽然没提到,但是提出的整体结构和ICML 2017的文本风格迁移的文章很像,如下图所示1:
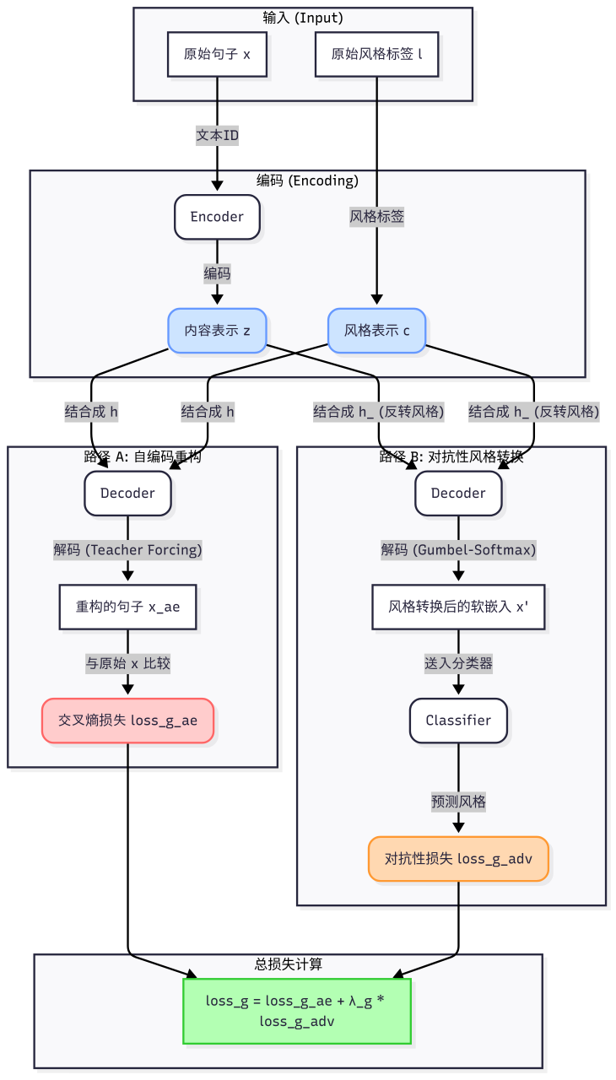
Z. Hu, Z. Yang, X. Liang, R. Salakhutdinov, and E. P. Xing. Toward controlled generation of text. In International Conference on Machine Learning, pages 1587--1596, 2017a.
Classification loss
传统方法计算Classification Loss的时候,会将逃避模型的输出\(P^{k \times n_t}\)(其中k表示句子长度,nt表示逃避模型的词典中token的数量)先采样得到一组离散的token,根据逃避模型的词典再将token映射回离散的文本,再将文本输入到检测器进行检测。因为"采样+映射"的操作,整个过程是不连续的,所以也就不好直接拿检测器的梯度反向传播训练逃避模型。(不太懂分词、token这些概念的,可以参考一下这张图片)
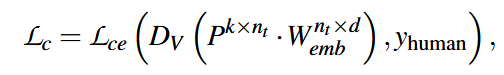
本文作者提出,将逃避模型的输出直接乘检测器模型的W矩阵(nt表示检测器模型的词典中token的数量,d表示token embeddings的维度),最后直接把计算后的结果输入到检测器中(准确来说是跳过了检测器的tokenizer和word embeddings),这样可以使得整个过程是连续的。
引入检测器模型的W矩阵,往往会带来下面的问题:

(1)如果tokenizer一致,映射的token ids也不一定一致,因为不用的LM可能会用不同的词表。
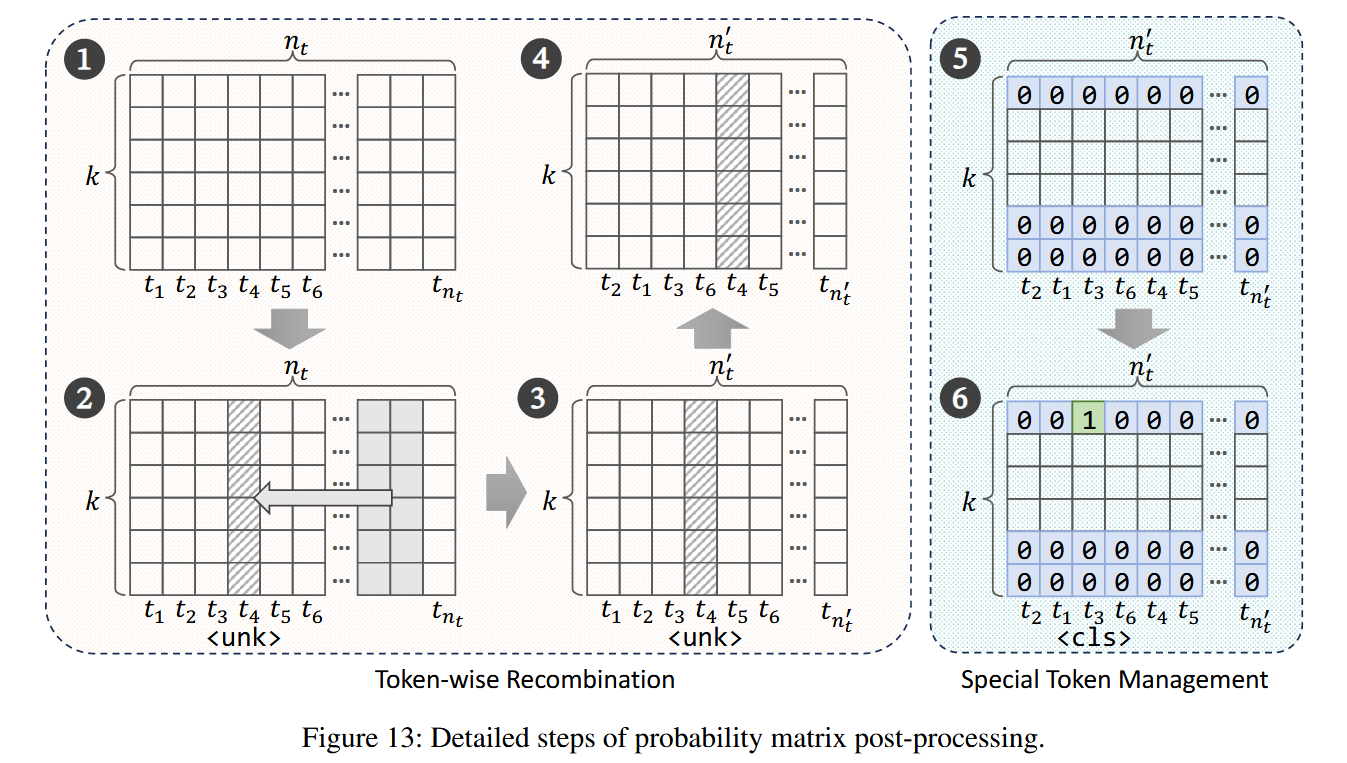
Token-wise Recombination :逃避模型令牌中token的数量和顺序可能与下游模型不同。为了解决差异,我们将来自多余令牌列中的值和添加到<unk>列中,通过这样做,我们将预测过量令牌的逃避模型的行为转变为预测<unk>的概率。解决令牌的秩序不一致,我们应用了Bagdasaryan等人2提出的令牌示例算法重新排序令牌列。
2 E. Bagdasaryan and V. Shmatikov, "Spinning language models: Risks of propaganda-as-a-service and countermeasures," in 2022 IEEE Symposium on Security and Privacy (SP). IEEE, 2022, pp. 769--786.
Special Token Management :因为有些下游模型对于输入有格式要求,比如[CLS]、[SEP]、<pad>等特殊token,论文将对应位置强行构造成下游模型需要的特殊token,以消除它们在下游模型的输出中的影响。
(2)逃避模型和检测器模型的tokenizer本身不一样(分词方法不一致,有可能前者将"小花"视为一个词,但是后者可能拆分成了"小"和"花"两个词)。
因为是白盒攻击,所以只要保证逃避模型和检测模型的tokenizer是一样的就可以了。
Label loss
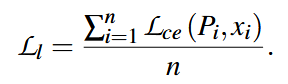
为了保证输入和输出在语法结构上的一致性。其中\(P_i\)表示第i个位置的token概率分布,\(x_i\)表示输入文本中第i个位置的token(被视为one-hot label),\(L_ce\)表示交叉熵损失函数。
Semantic loss
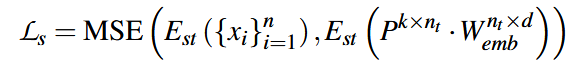
为了确保输出不会显著改变输入的语义。\(E_{st}\)表示一个预训练的sentence transformers模型。
Warm-started Evader
作者没有从头训练一个seq2seq model,而是基于一个warm-started encoder-decoder3方法,用encoder/decoder only模型的共享参数作为seq2seq model的初始参数。
3 S. Rothe, S. Narayan, and A. Severyn, "Leveraging pre-trained checkpoints for sequence generation tasks," Transactions of the Association for Computational Linguistics, vol. 8, pp. 264--280, 2020.
初始化后,作者还让seq2seq model在公共数据集WikiText和BookCorpus进行复述训练,目的是让seq2seq model可以输出流利的话语。
黑盒攻击
检测器是opaque models的。
攻击者首先进行tokenizer inference attack以获取模型架构,然后使用model extraction attack来训练替代检测器。之后,攻击者可以根据白盒攻击的方法对替代探测器进行训练。
tokenizer inference attack
通过 探测 API 接口的响应行为和 已知的常用tokenizer模板,来推断检测器使用的 tokenizer。常见检测器通常使用 BPE(GPT2/BART)、SentencePiece(T5/LLaMA)、WordPiece(BERT)。
攻击者可以通过比较返回的分数来确定受害者的检测器是否使用特定的token。论文说明了两种制作推理输入的方法:
Padding Spoof :攻击者可以在输入文本末尾添加填充(pad)token。语言模型(LM)的 tokenizer 通常会在文本后进行 padding,以确保输入长度一致。如果攻击者添加的是正确的填充 token,语言模型会忽略它们;但如果填充 token 不正确,它就会被当作普通 token 进行分词。例如,RoBERTa 的填充 token <pad>,在 GPT2 和 BERT 的 tokenizer 中会被分词为: ["<", "pad", ">"]。
Space Spoof:攻击者可以将文本中的空格替换为语言模型特有的 token, 并观察替换前后 detector 的响应分数,以此推断 tokenizer 类型。不同语言模型的 tokenizer 对空格的处理方式不同:
- BERT 忽略空格(不显式表示空格);
- 而 LLaMA2 使用
_(下划线)显式表示空格。
例如:
- 文本
"Space spoof"和"Space_spoof"
在 LLaMA2 的 tokenizer 中都会被分词为:
["_Space", "_spo", "of"]; - 而在 BERT tokenizer 中分别被分词为:
"Space spoof"→["Space", "s", "##po", "##of"]
"Space_spoof"→[UNK](表示无法识别)
疑问:总感觉这里没有说明白怎么具体区分不同的tokenizer,很含糊
model extraction attack
模型抽取攻击的目标是构建一个替代模型(substitute model),该模型能够在功能或参数上尽可能接近目标受害模型(victim model)。 已有文献已经证明该方法在窃取在线模型方面是有效的。模型抽取攻击通常包含以下三个步骤:
在本论文中,我们采用的是最基础的标签可见(label-only)模型抽取攻击方法 ,即受害检测器只暴露预测的标签结果。我们构建的查询数据集来源于与 evader 训练集同分布的文本数据(但与检测器的训练数据分布可能不同)。 我们确保这个查询数据集不与 evader 或 detector 的训练集存在重叠。接着,我们用该数据集去查询受害检测器,并利用其预测标签来对数据进行标注,构建出用于再训练的训练集(retraining dataset)。最后,我们使用这个再训练数据集对一个已知结构的预训练模型进行微调,该结构是通过 tokenizer inference attack(分词器推断攻击)所获得。完成替代模型的训练后,攻击者就可以:
- 使用它来计算分类损失(classification loss)
- 获取梯度
- 并进一步更新 evader 模型的参数
防御方法
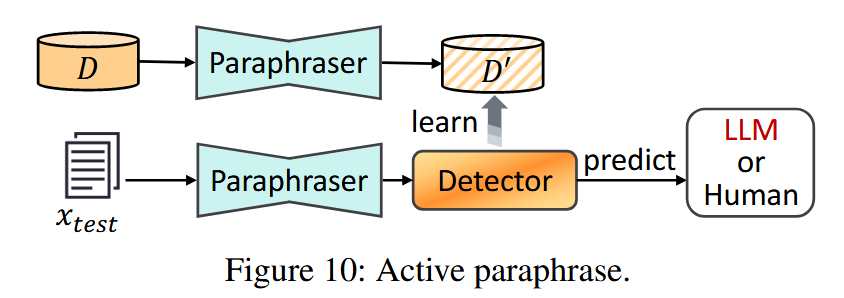
在训练和推理阶段 都先对文本进行统一的释义处理,使得检测器关注的是文本的"语义"而不是"表达风格",从而消除 evader 的扰动效果。使用一个大语言模型如 LLaMA-3-8B-Instruct 来实现 paraphrasing:
Rewrite the following text for me:\n\n{input text}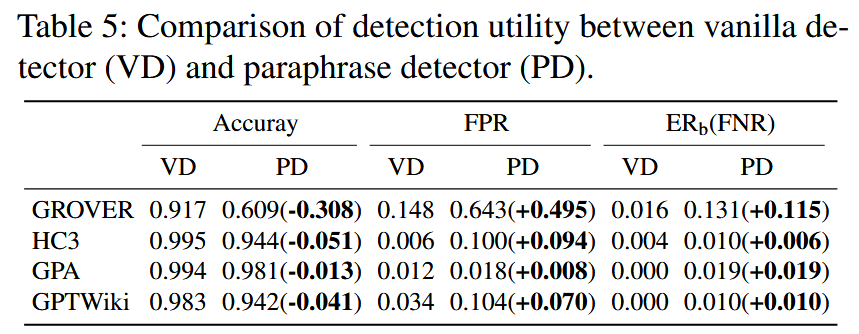
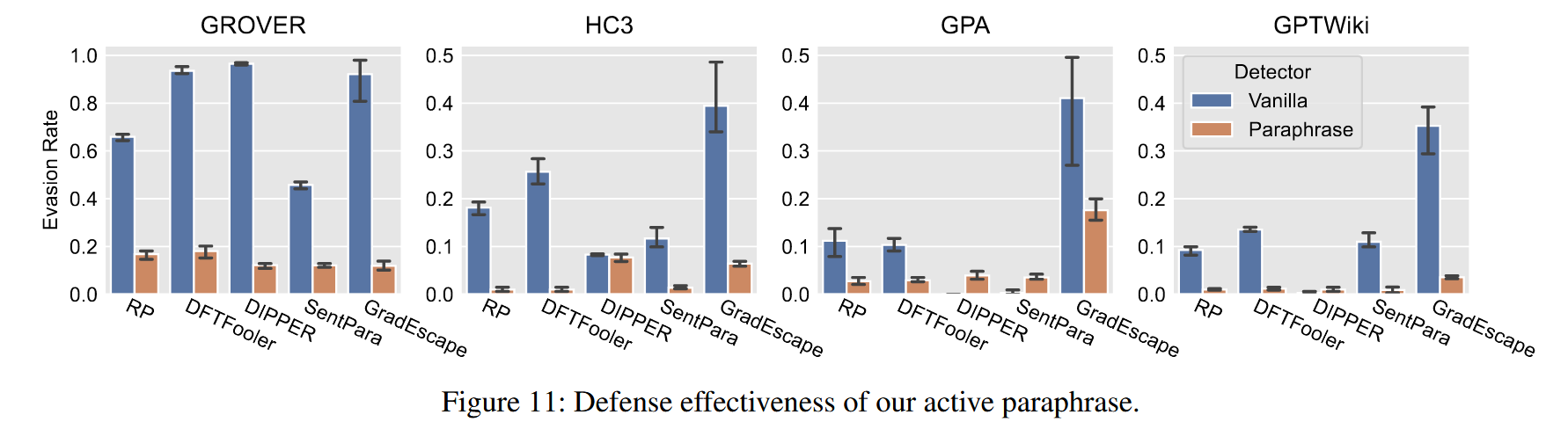
Table 5是在没有攻击的情况下,Figure 11是在有攻击的情况下,检测器均采用RoBERTa。
- Accuracy表示模型对所有测试样本中(人类 + AI 生成)的预测正确的比例
- FPR表示将人类写的文本误判为 AI 生成的概率
- ERb表示 AI 生成的文本被误判为人类写的比例(即攻击成功率)
实验分析
白盒攻击
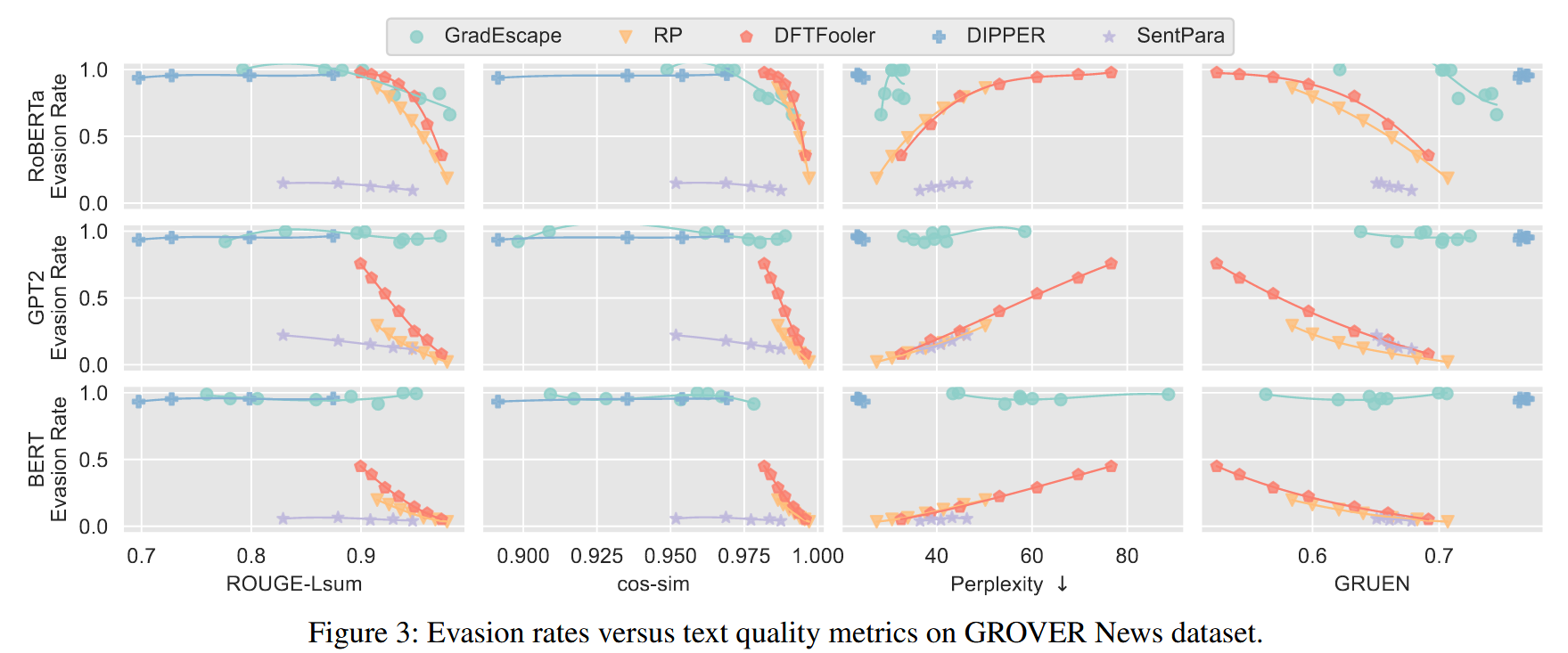
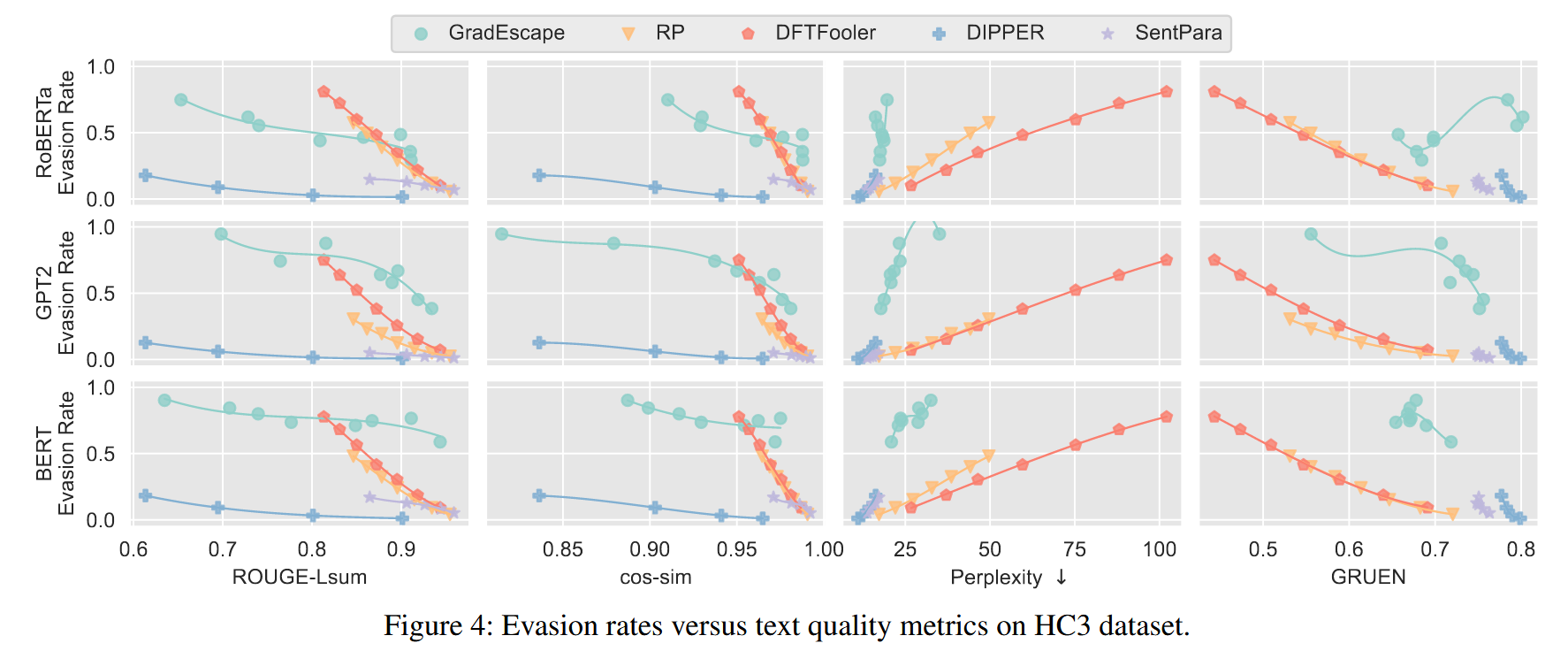
- Evasion Rate 表示原来是机器样本,攻击后被识别为人类样本的比例
- Rouge是一种文本质量度量测量,可在被逃避模型编辑之前和之后的文本之间进行句法相似性
- cos-sim用于计算语义相似性,首先使用Google的通用句子编码器,这会在版本前后生成文本的嵌入,它们计算其余弦距离
- Perplexity是测量文本可读性的指标,低的困惑表明该模型对其预测更有信心,并且文本更加流利和易于阅读
- Gruen用于测量文本可读性,与困惑不同,Gruen将其值归一化为0到1,Gruen从多个角度评估文本质量,包括grammaticality, non-redundancy, discourse, focus, structure, and coherence
黑盒攻击
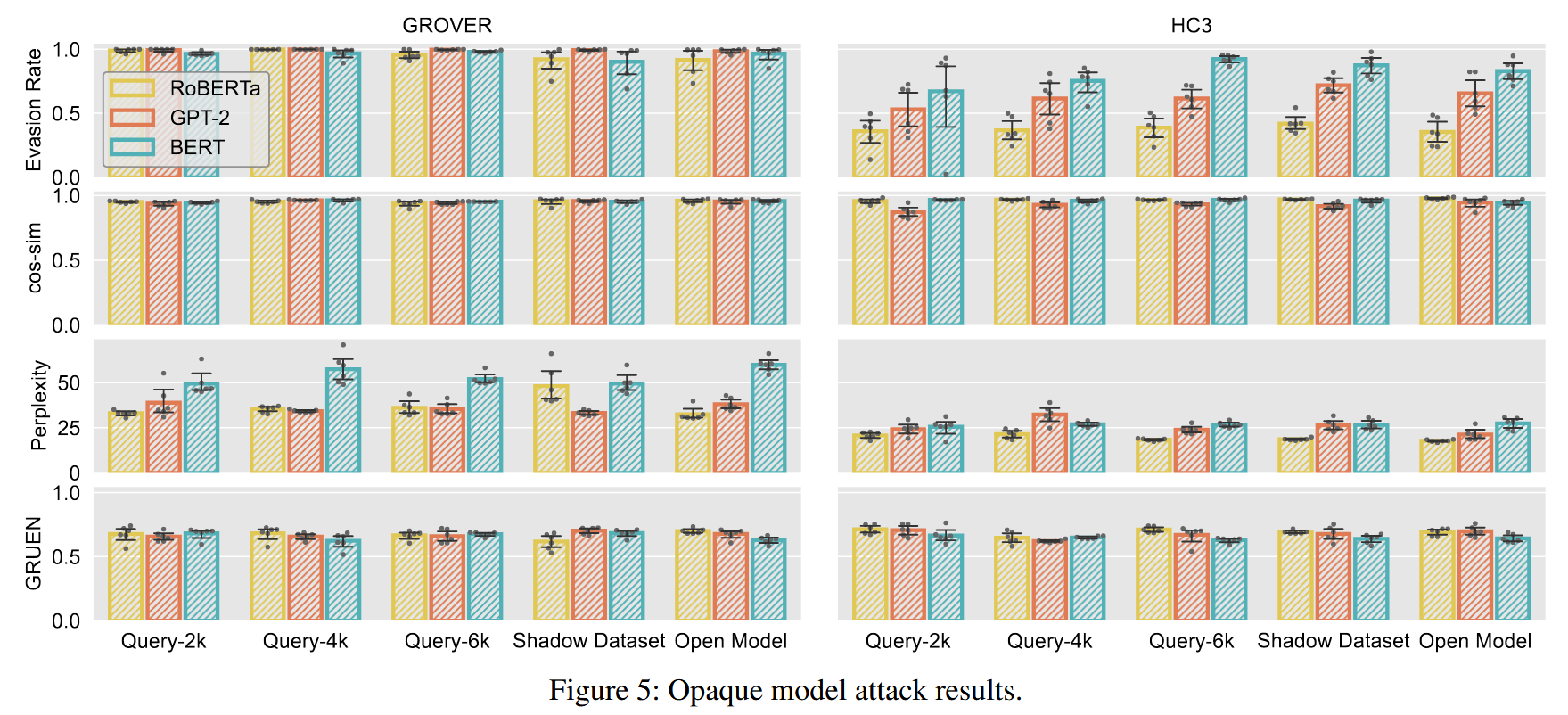
- query-2k、4k和6k都是从和检测器训练数据集相同分布的数据中采样的
- shadow dataset是从其他数据集东拼西凑得来的
这幅图说明GradEscape不是适用于所有的数据集,比如在H3上的表现效果着实一般。
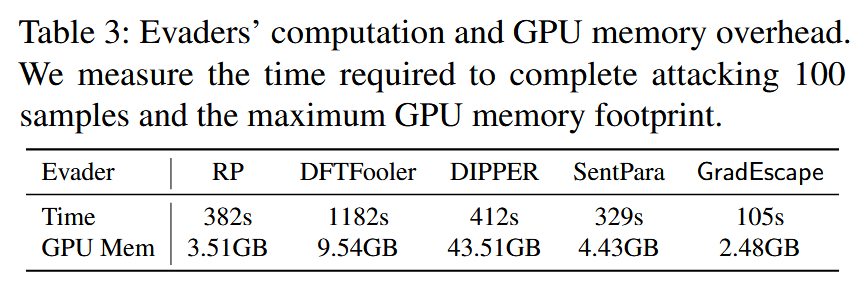
开销分析
现实世界(商业检测器)
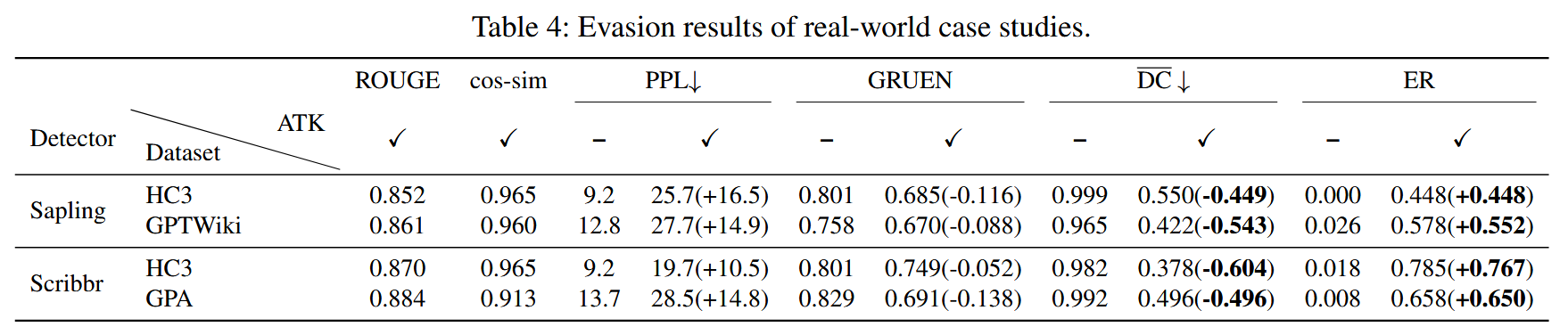
表说明后续工作在attack商业检测器上还有很大空间。
补充:一个很强的baseline模型DIPPER
论文名称:Paraphrasing evades detectors of AI-generated text, but retrieval is an effective defense
发表时间:2023
期刊会议:NeurIPS
论文单位:University of Massachusetts Amherst, Google
论文作者:Kalpesh Krishna、Yixiao Song、Marzena Karpinska、John Wieting、Mohit Iyyer
方向分类:Attack AI-generated text (AIGT) detectors
基于 T5-XXL 构建的 11B 参数的模型,具备对段落级长文本进行上下文感知改写的能力。相比现有句子级改写器,DIPPER 能更自然地控制词汇多样性和内容重排序,更贴近实际的攻击需求。提供两个可控参数:Lexical Diversity 和 Order Diversity,使攻击更加灵活。
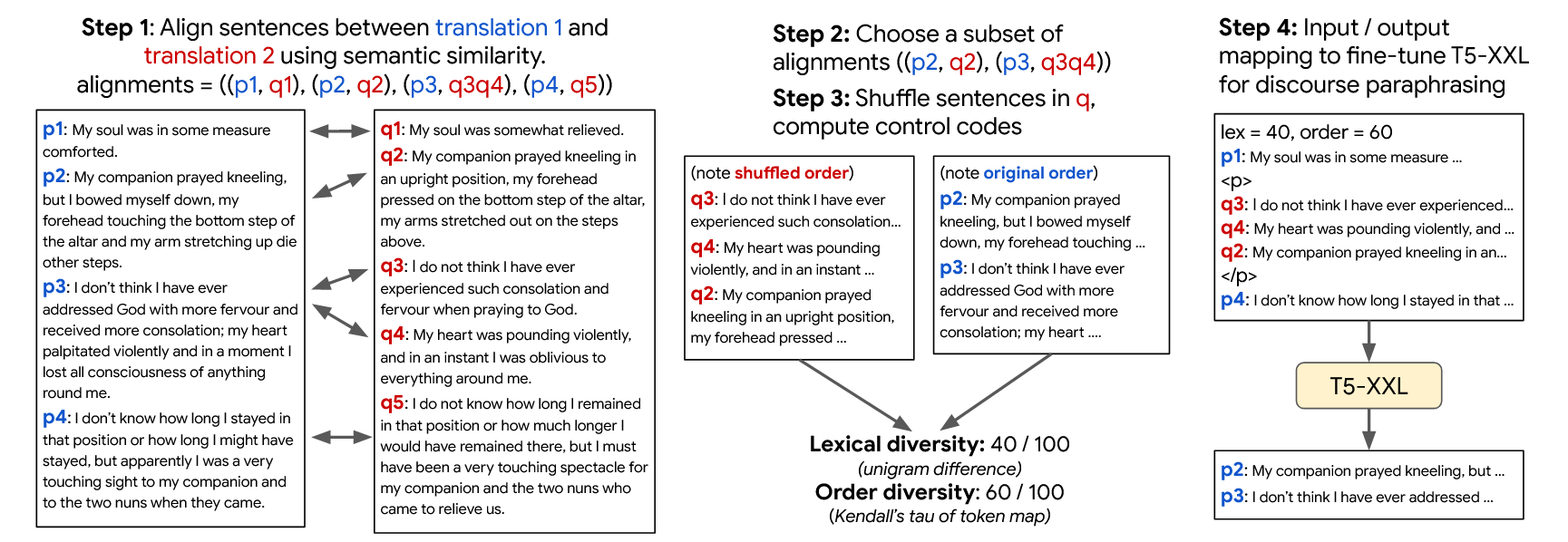
数据来源:PAR3 数据集。来自多个小说的多语言翻译版本(如法国小说《The Nun》被多种方式翻译为英文);每段对应多种翻译 → 可视为自然段落级"改写对"。p 和 q 是一对平行段落(paraphrase pair) ,分别来自同一部小说的不同英语翻译版本
**步骤一:句子对齐(Sentence Alignment)。**将两个翻译版本中语义相似的句子对齐,以构建平行的段落对。
-
输入:两个段落p = {p_1, p_2, ..., p_N}, q =
-
方法:
- 使用 paraphrase similarity model4计算句对相似度;
4 J. Wieting, T. Berg-Kirkpatrick, K. Gimpel, and G. Neubig. Beyond BLEU:training neural machine translation with semantic similarity. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 4344--4355, Florence, Italy, July 2019. Association for Computational Linguistics. doi: 10.18653/v1/P19-1427. URL https://aclanthology. org/P19-1427.
- 应用 Needleman-Wunsch 动态规划算法进行全段落对齐;
-
输出:
-
对齐结果例如:
(p1, q1), (p2, q2), (p3, q3q4), (p4, q5)
-
**步骤二:选择目标改写片段(Partial Alignment Selection)。**从对齐句中选取子集,构造训练样本。
- 示例中选择:
- 输入端片段: q2,q3,q4
- 输出端目标: p2,p3
**步骤三:内容打乱 + 控制标签计算。**通过打乱内容顺序和引入控制变量训练"有意识"的多样化改写模型。
-
句子打乱:将 q2,q3,q4重排,得到如:
q3 → q4 → q2 -
控制标签计算:
- Lexical Diversity (L):
- 使用 unigram token overlap(F1 分数)计算 p2+p3与 q3+q4+q2的词汇差异;
- 归一化为离散值如 20、40、60。
- Order Diversity (O):
- 使用 Kendall's Tau 衡量 token 顺序一致性;
- 同样离散化为 O = 0/20/40/60/80/100;
- 示例:Lexical = 40,Order = 60。
- Lexical Diversity (L):
**步骤四:构造训练样本(Input/Output Pair)。**结合上下文与控制代码,训练 T5-XXL 完成定向生成。
输入格式:
lex=40, order=60
p1 + "<p>" + [q3 q4 q2] + "</p>" + p4p1、p4:上下文句;<p>...</p>:改写目标句;lex=40, order=60:模型感知改写多样性的控制代码;
输出目标:
p2 + p3- 要求模型学会从乱序且表述变化的 paraphrase 段落,恢复目标原始段落。
推理。
-
输入任意文本段落,手动设置词汇/顺序多样性程度;
-
使用如下格式:
lexical=60, order=60
context-before +generated-text
+ context-after -
模型输出的是"语义一致但形式不同"的改写文本,用于规避检测。