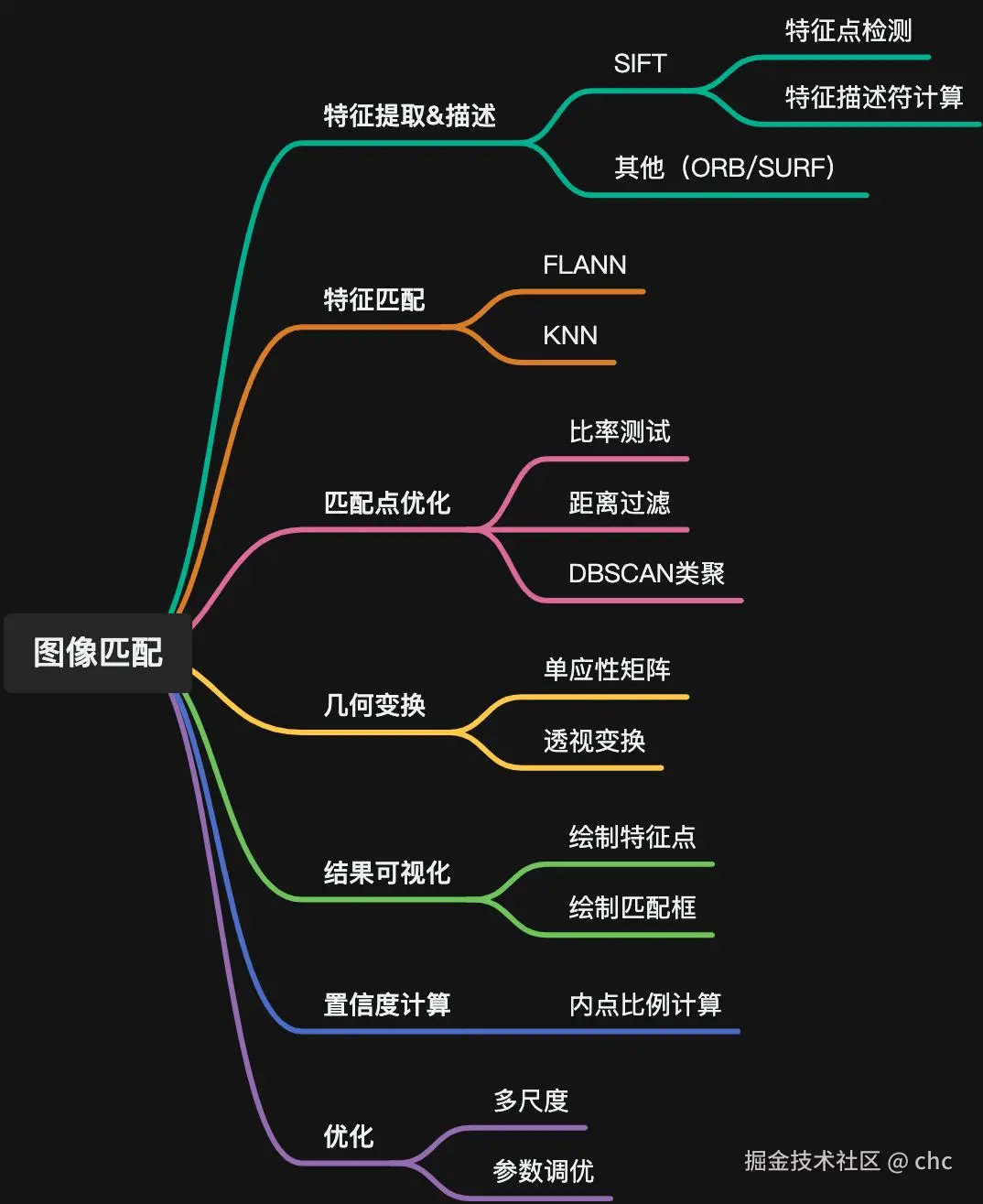
效果
通过SIFT匹配到icon在原图的位置(使用LightGlue库的SIFT特征匹配算法)
特征匹配简单介绍:
1. 特征提取和描述
1.1 SIFT算法
SIFT(尺度不变特征变换) 是一种检测和描述图像局部特征的经典算法,具有尺度不变性和旋转不变性,能在不同尺度、旋转角度下稳定检测到相同特征点。
1.1.1 SIFT核心步骤
- 尺度空间的极值检测:通过构建高斯金字塔和差分高斯金字塔(DoG),检测多尺度下的潜在特征点。
- 关键点定位:过滤低对比度和边缘响应的点,精确定位关键点。
- 方向分配:基于关键点邻域梯度方向,为每个关键点分配方向,实现旋转不变性。
- 特征描述符生成:生成128维向量描述关键点邻域信息,确保尺度和旋转不变性。
1.1.2 尺度与尺度空间
- 尺度:物体和特征的大小。通过高斯模糊模拟不同尺度(模糊度越大,尺度越大)。
- 尺度空间:不同尺度下图像的连续表示,通过高斯金字塔和DoG金字塔构建。
1.1.3 尺度空间构建步骤
- 初始化图像:读取图像并转换为单通道灰度图。
- 构建高斯金字塔:对图像多次高斯模糊,逐步降低分辨率(下采样),形成多层金字塔。
- 构建差分高斯金字塔(DoG) :相邻尺度的高斯模糊图像相减,得到DoG图像,用于检测尺度空间极值点
1.1.4 实践代码(SIFT特征提取)
python
import cv2
# 读取图片&转为灰度图
img1 = cv2.imread('image1.jpg',cv2.IMREAD_GRAYSCALE)
img2 = cv2.imread('image2.jpg',cv2.IMREAD_GRAYSCALE)
# 创建SIFT特征提取器
sift = cv2.SIFT_create();
# 检测关键点&计算描述符
kp1,des1 = sift.detectAndCompute(img1,None)
kp2,des2 = sift.detectAndCompute(img2,None)
# 绘制关键点
img1_with_keypoints = cv2.drawKeypointes(img1,kp1,None,flags=cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS)
img2_with_keypoints = cv2.drawKeypointes(img2,kp2,None,flags=cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS)
# 可视化结果
cv2.imshow("Keypoints 1",img1_with_keypoints) #窗口名 Keypoints 1
cv2.imshow("Keypoints 2",img2_with_keypoints) #窗口名 Keypoints 2
cv2.waitKey(0) # 等待用户按键
cv2.destroyAllWindows() # 关闭所有OpenCV创建的窗口
# def SIFT_create(nfeatures=0, 保留的最佳特征点数量,0则保留所有特征点
# nOctaveLayers=3, 每个八度空间的层数,用于构建图像金字塔
# contrastThreshold=0.04, 过滤低对比度的阈值,越低特征点越多
# edgeThreshold=10,用于过滤边缘响应的阈值,越高保留边缘特征越多
# sigma=1.6): 高斯滤波器在金字塔第0层的sigma值
# sift.detectAndCompute(image, 图像,单通道的灰度图像
# mask) 掩码,指定哪些区域要检测,None不需要掩码1.1.5 SIFT参数说明
| 参数名 | 含义 | 默认值/说明 |
|---|---|---|
nfeatures |
保留的最佳特征点数量(0表示保留所有) | 0 |
nOctaveLayers |
每个八度空间的层数(用于构建图像金字塔) | 3 |
contrastThreshold |
过滤低对比度的阈值(值越低,保留的低对比度特征点越多) | 0.04 |
edgeThreshold |
过滤边缘响应的阈值(值越高,保留的边缘特征点越多) | 10 |
sigma |
高斯滤波器在金字塔第0层的初始sigma值 | 1.6 |
2. 特征匹配
2.1 暴力匹配
直接遍历目标图像所有特征点,计算与源图像特征点的距离(如欧氏距离),取距离最小的作为匹配结果。简单但效率低,适用于特征点数量较少的场景。
2.2 FLANN匹配
FLANN(快速近似最近邻搜索库) :通过构建高效索引结构(如KD树)加速匹配,适用于大规模特征点匹配。
2.2.1 核心步骤
- 定义参数:包括索引参数(构建索引结构)和搜索参数(控制搜索过程)。
- 创建FLANN匹配器:基于参数初始化匹配器。
- 执行匹配:对特征描述符进行近似最近邻搜索,返回匹配结果。
2.2.2 FLANN参数说明
| 参数类型 | 参数名 | 含义 | 默认值/说明 |
|---|---|---|---|
| 索引参数 | algorithm |
索引算法(1=KD树,5=层次聚类树) | 1(KD树) |
| 索引参数 | trees |
KD树数量(树越多,索引越精确但构建耗时) | 5 |
| 搜索参数 | checks |
搜索时检查的叶节点数量(值越大,匹配精度越高但速度越慢) | 50 |
实践
python
# 定义参数
index_params = dict(algorithm=1, trees=5) # 索引参数
search_params = dict(checks=50) # 搜索参数
# 创建FLANN匹配器
flann = cv2.FlannBasedMatcher(index_params, search_params)
# 进行匹配
# descriptor1,descriptor2 上述特征提取中计算的特征描述符
# k=2 表示对每个特征点找2个最临近点(用于比例测试)
matches = flann.knnMatch(des1, des2, k=2)
# macthes 是DMatch对象的实例列表
# DMatch
# distance:匹配的特征点对之间的距离,距离越小,匹配越好
# trainIdx:训练图像中描述符的索引
# queryIdx:查询图像中的描述符索引2.3 比率测试(过滤误匹配)
通过比较每个特征点的最近邻距离 和次近邻距离,过滤低质量匹配。若最近邻距离远小于次近邻距离,则为可靠匹配。
实践
python
good_matches = []
for m,n in matches:
if m.distance < 0.7 * n.distance: # 通过测试
good_matches(m)2.4 匹配点优化
通过DBSCAN聚类(密度聚类)进一步过滤离散的误匹配点,保留空间分布集中的可信匹配点。
2.4.1 步骤
- 提取匹配点坐标 :从
good_matches中获取源图像和目标图像的匹配点坐标。 - DBSCAN聚类:对源图像匹配点进行密度聚类,过滤噪声点(离散点)。
ini
# 获取匹配点
src_pts = np.float32([kp1[m.queryIdx].pt for m in good_matches]).reshape(-1, 2)
dst_pts = np.float32([kp2[m.trainIdx].pt for m in good_matches]).reshape(-1, 2)2.4.2 实践代码(匹配点优化)
python
# 对搜索图的匹配点进行类聚
# eps:两个点被视为邻居的嘴道距离
# min_samples 一个点被视为核心点所需的最小邻居数(包括点本身)
clustering = DBSCAN(eps=30,min_samples=3).fit(src_pts) # 对源点进行类聚
# 类聚标签数组
labels = clustering._labels
# 获取所用的唯一标签
const unique_labels = set(labels)
results = []
for label in labels:
if label == -1: # label是-1的视为噪声点
continue
# 创建一个布尔掩码,标识当前标签的点
label_mask = (labels == label)
# 根据掩码提取当前标签的源点
src_pts_label = src_pts[label_mask]
# 根据掩码提取当前标签的目标点
dst_pts_label = dst_pts[label_mask]2.5 单应性矩阵估计
单应性矩阵(H) :描述两个平面图像之间的透视变换关系(3x3矩阵),可将目标图像点映射到源图像中。通常通过RANSAC算法估计。
2.5.1 RANSAC算法步骤
- 随机采样:从匹配点中随机选择4对(求解单应性矩阵至少需4个点)。
- 模型拟合:用4对匹配点求解单应性矩阵H。
- 计算内点:统计所有匹配点中满足H变换误差阈值的内点(误差<阈值的点)。
- 迭代优化:重复采样-拟合-统计,保留内点最多的H作为最优模型。

代码
python
H, status = cv2.findHomography(target_keypoints, source_keypoints, cv2.RANSAC)2.6 匹配结果可视化
通过透视变换将目标图像边框映射到源图像,绘制匹配区域和特征点,直观展示匹配效果。
python
# 获取目标图的宽高
h,w = img2
# 创建一个表示目标图四个角点的数组
# reshape(-1,1,2)重塑数组
# -1表示自动计算第一个维度
# 1 每个坐标作为单独的元素
# 表示每个坐标有两个值(x&y)
corners = np.float([0,0],[0,h-1],[w-1,h-1],[w-1,0]).reshape(-1,1,2)
# 透视变换
transformed_corners = cv2.perspectiveTransform(corners,H)绘制边框&特征点
python
# 绘制匹配框
img = cv2.imread('image1')
# img 绘制的目标
# np.int32(transformed_conners) 绘制的多边形顶点
# True 闭合多边形
# 线条颜色
# 线条size
# 线型
img = cv2.polylines(img,[np.int32(transformed_conners)],True,(255,0,0),3,cv2.LINE_AA)
# 绘制特征点
for pt in src_pts_label:
# 绘制目标
# 圆心坐标
# 半径
# 颜色
# -1:填充圆,正数表示圆边粗细
img = cv2.circle(img,(int(pt[0]),int(pt[1])), 5, (0,255,0),-1)2.7 匹配置信度计算
通过量化指标评估匹配可靠性,常用方法如下:
2.7.1 内点比例法
原理:内点数量占总匹配点数量的比例(比例越高,匹配越可靠)。
python
# 匹配点的数量
num_matches = len(scr_pts_label)
# 内点的数量
num_inliers = np.sum(status)
# 内点比例
inlers_ratio = num_inliers / num_matches
# 置信度
confidence = inlers_ratio2.7.2 归一化匹配距离法
原理:基于特征点匹配距离(距离越小,匹配越相似),归一化后作为置信度。
python
# (m.distance for m in good_matches)获取每个匹配点点距离
# sum 计算距离总和
# 获取平均距离
avg_distance = sum(m.distance for m in good_matches) / len(good_matches)
# 获取最大距离
max_distance = max(m.distance for m in good_matches)
# 计算归一化
normalized_distance = 1 - (avg_distance / max_distance)
# 置信度
confidence = normalized_distance2.7.3 综合加权法
结合内点比例和归一化距离,通过权重融合(如内点比例权重0.7,归一化距离权重0.3):
python
# 综合上述两个因素
# 权重可调整
confidence = 0.7 *inlers_ratio + 0.3 * normalized_distance流程
graph TD
A[客户端] -->|POST /match_image| B[获取图片]
B --> E[特征提取]
E --> F[特征匹配]
F --> G{匹配成功?}
G -->|是| H[计算位置]
G -->|否| I[返回失败]
H --> J[绘制结果]
J --> K[保存结果图]
K --> L[计算中心坐标]
L --> M[清理临时文件]
I --> M
M --> N[返回响应]
graph TD
subgraph 特征提取流程
E1[SIFT算法] -->|最大2048个关键点| E2[提取特征点]
end
subgraph 特征匹配流程
F1[LightGlue算法] -->|阈值0.7| F2[匹配特征点]
F2 --> F3[RANSAC算法]
F3 --> F4[计算单应性矩阵]
end
subgraph 结果处理
J1[绘制蓝色边框] --> J2[宽度3像素]
K1[保存到output目录] --> K2[生成结果图片]
end