Jmeter的后置处理器主要用于取样器执行后的提取数据操作。
Jmeter常用的后置处理器有:Json提取器、正则表达式提取器、边界提取器、Beanshell后置处理器。此外还有Xpath提取器、CSS选择器提取器等,由于这两项多用前端页面提取元素,目前的项目基本都是采用前后端分离的技术,Jmeter主要的对象是接口,所以这两项不怎么会用上。
本文以"聚合数据"提供的免费API进行讲解,有需要的可以了解下聚合数据所提供的接口信息,账号注册等。
1、百度搜索"聚合数据",进入到聚合数据官网注册个账号。
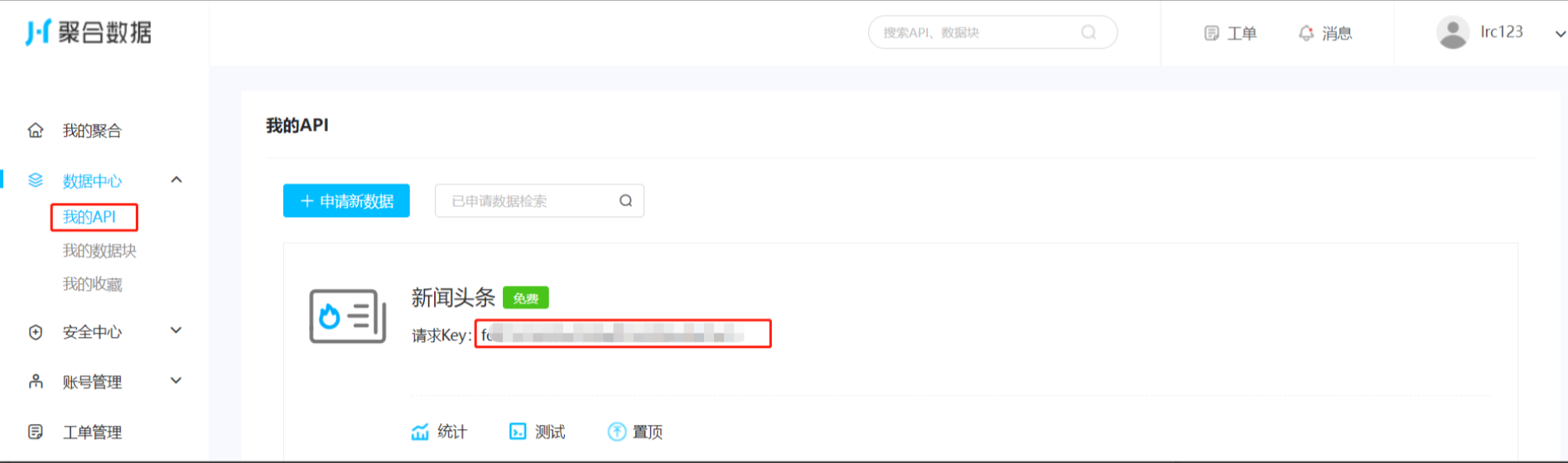
2、注册完账号后,点击【API】导航即可选用免费的试用接口
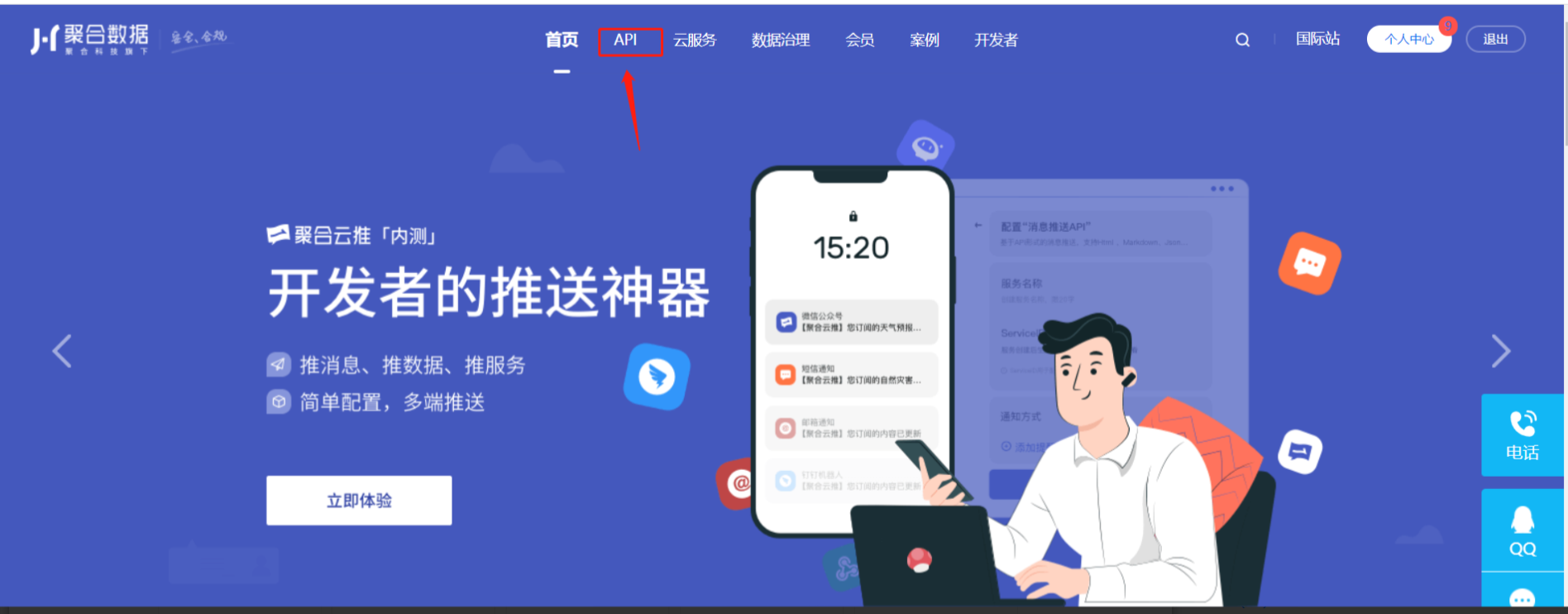
3、选用想用的API分类,本文以【新闻头条为例】
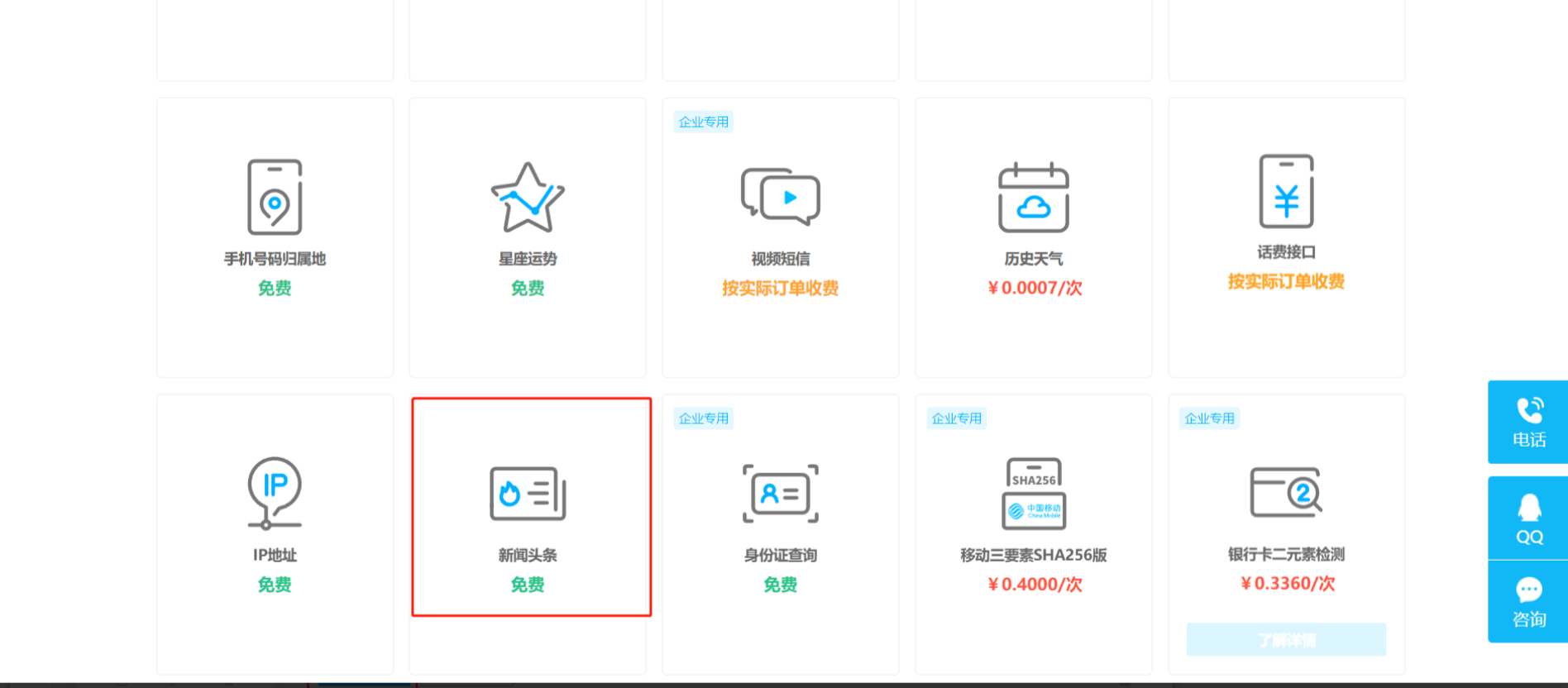
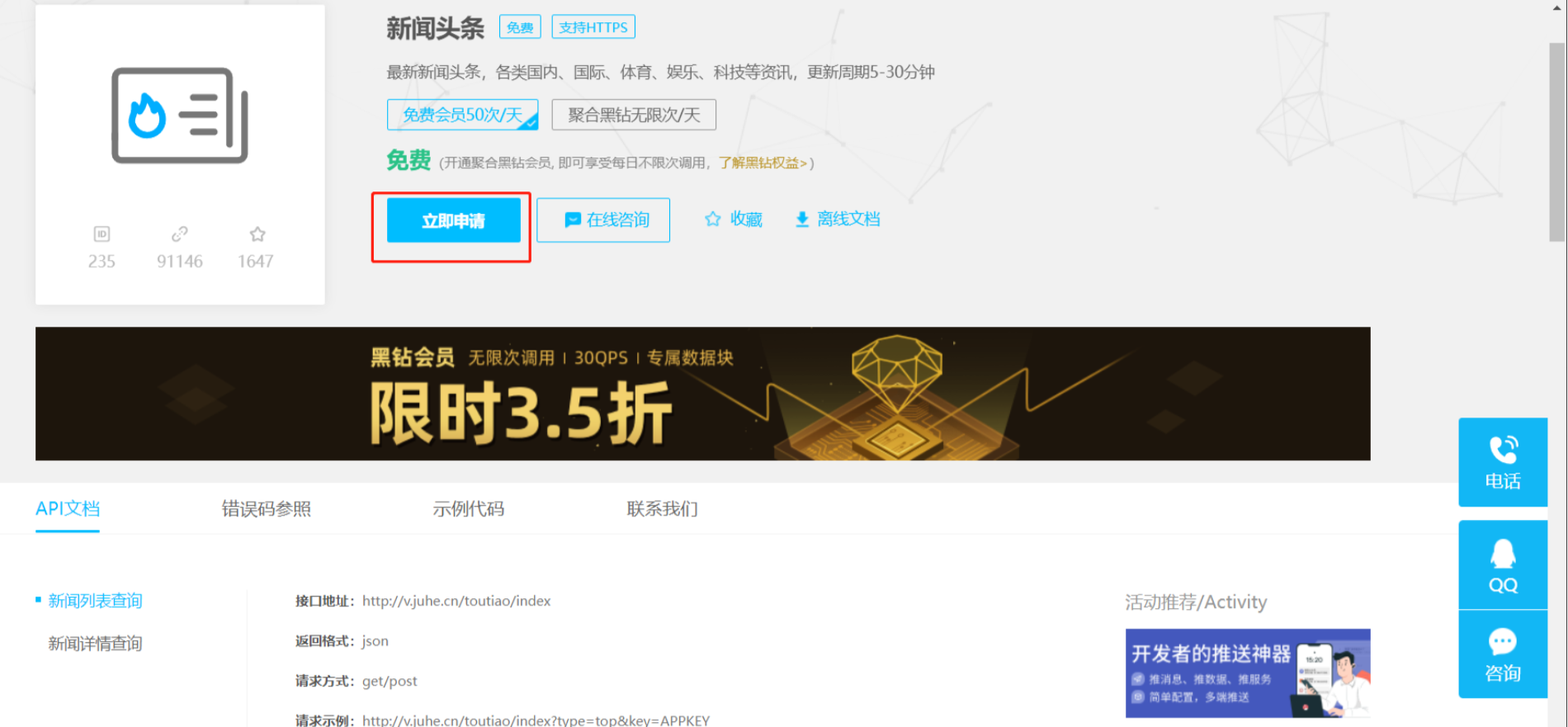
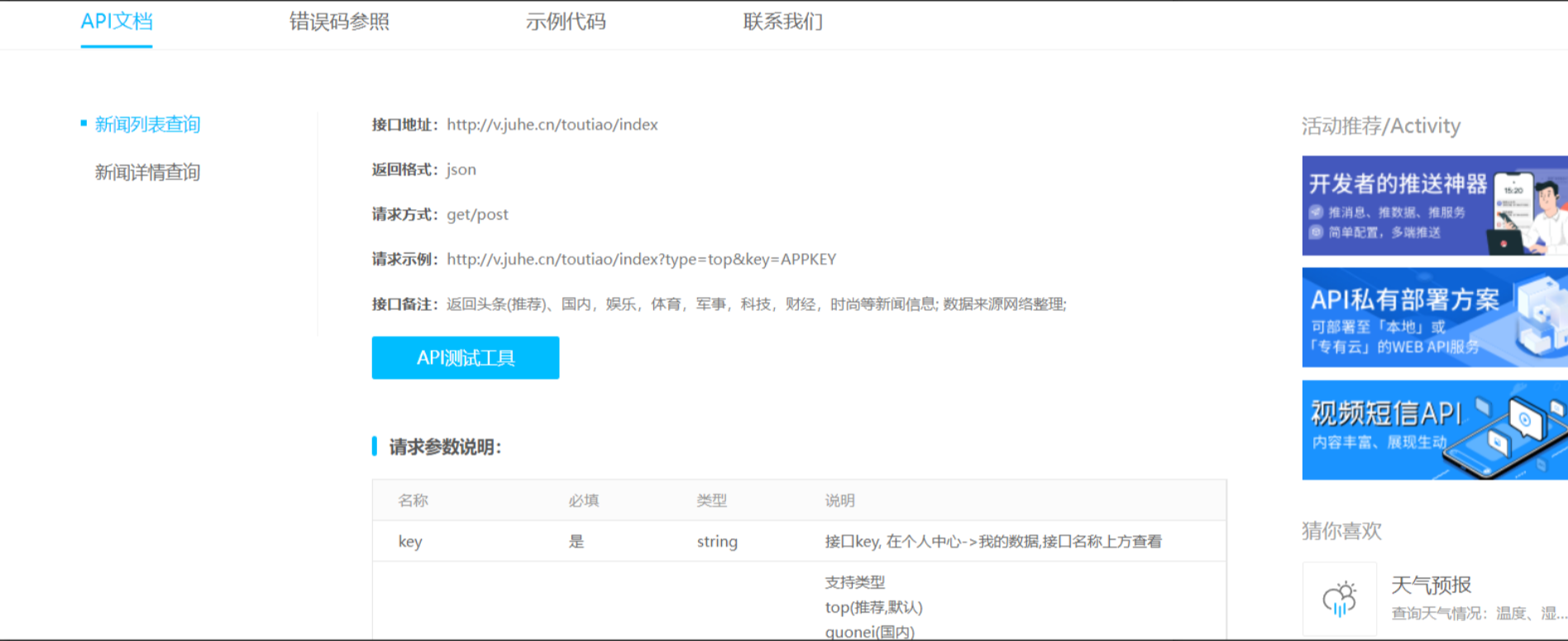
自此完成了接口申请,可以在【数据中心】->我的API中查看接口的信息,后边我们在测试的时候可以参照API文档进行接口测试
一:Json提取器
通过JsonPath语法提取取样器信息。
1、Jmeter的Json提取器页面介绍:
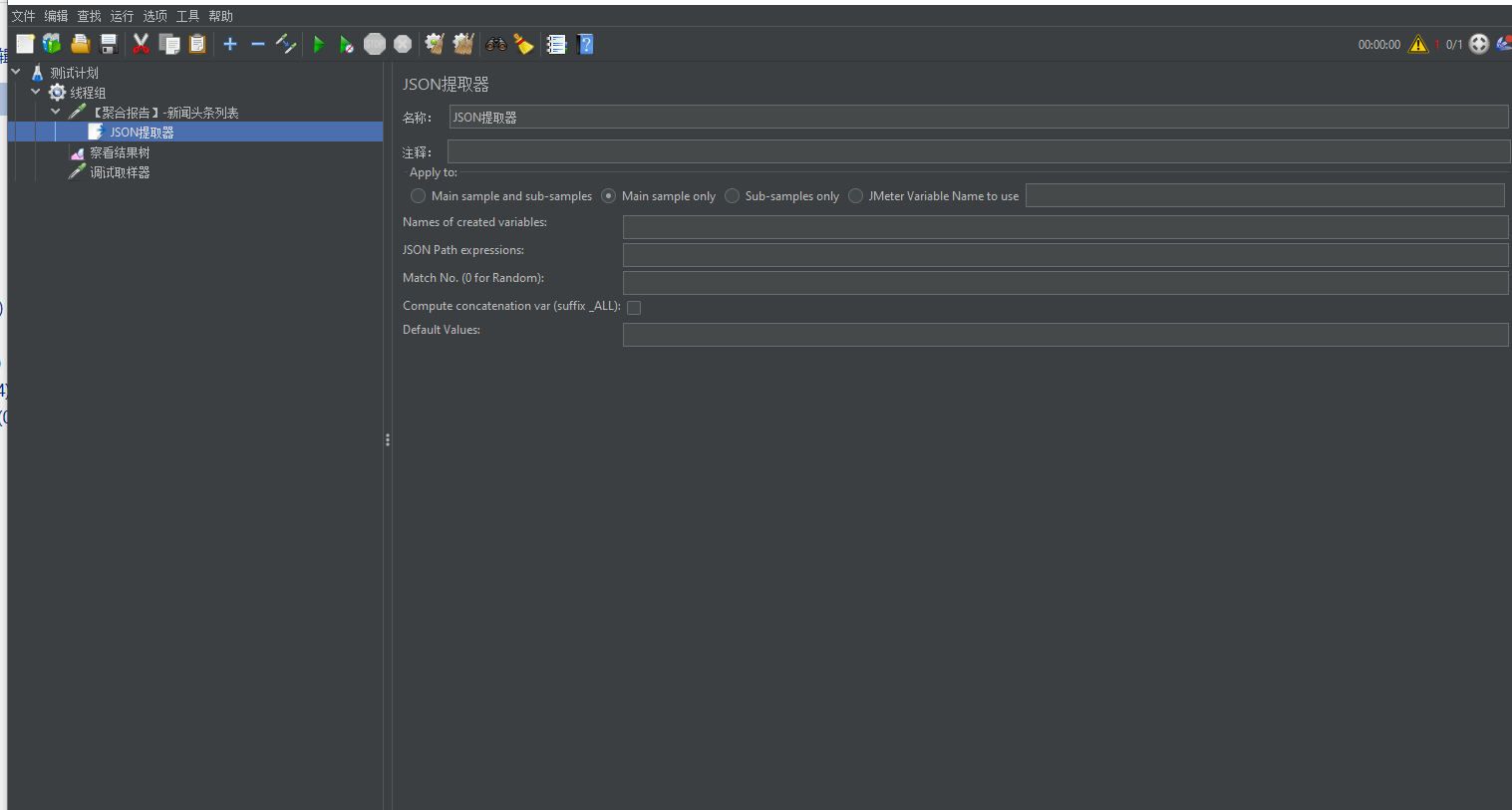
(1):Apply to选项
(1.1)Main sample and sub-samples:应用于主样本和子样本
(1.2)Main sample only:仅应用于主样本,一般选这个选项即可
(1.3)Sub-samples only:仅应用于子样本
(1.4)Jmeter Variable Name to use:应用于Jmeter变量中,例如:我们可以使用String resopnse=prev.getResponseDataAsString();得到请求的响应信息后,将变量赋值到Jmeter变量response,然后通过${response}引入到此处。这个做法其实多此一举,不推荐。
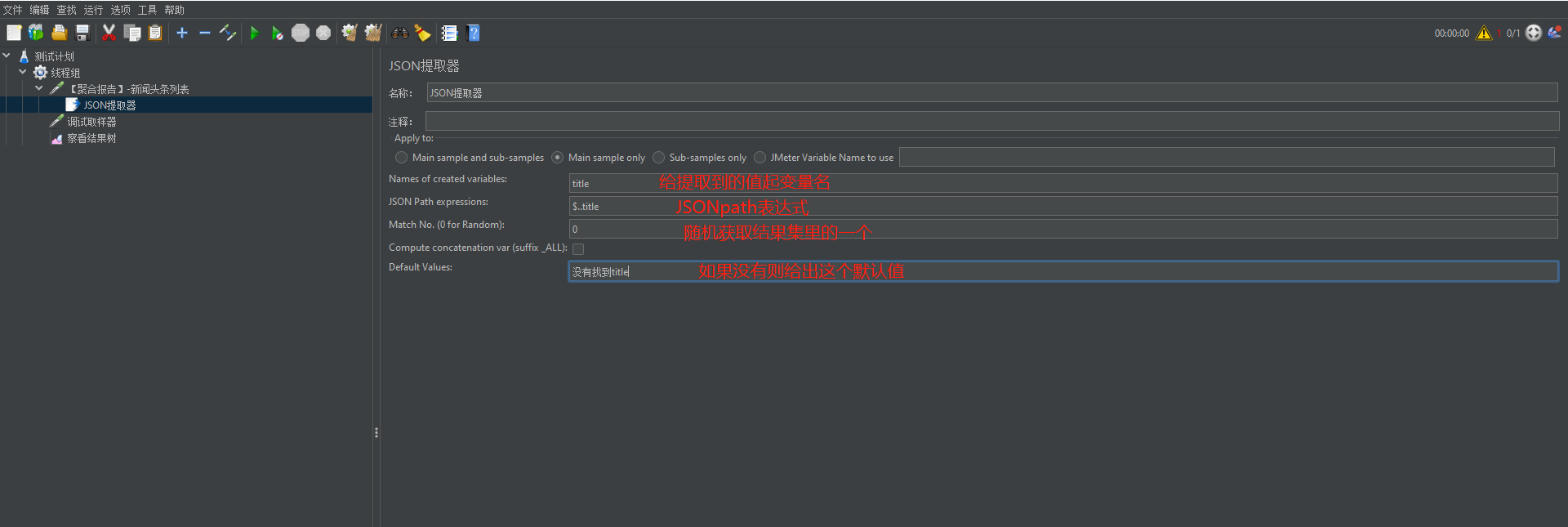
(2)Names of created variables:给提取到的变量取名
(3)JSON Path expressions:JsonPath的表达式
(4)Match No:可以填写数字(0,1,-1),0表示随机取一个数据,1表示取第一个数据,-1表示取全部数据,也可以不填,不填写默认取第一个数据
(5)Default Values:未取到值的时候默认值
JsonPath的语法介绍:
(1)$:表示根节点元素
(2)@:表示当前所在位置节点元素
(3)*:表示通配所有元素
(4).:表示匹配当前路径的下级节点
(5)..:表示递归匹配当前路径的所有节点
(6)index:表示匹配数组索引类型的节点
(7)?(表达式):对数据进行筛选
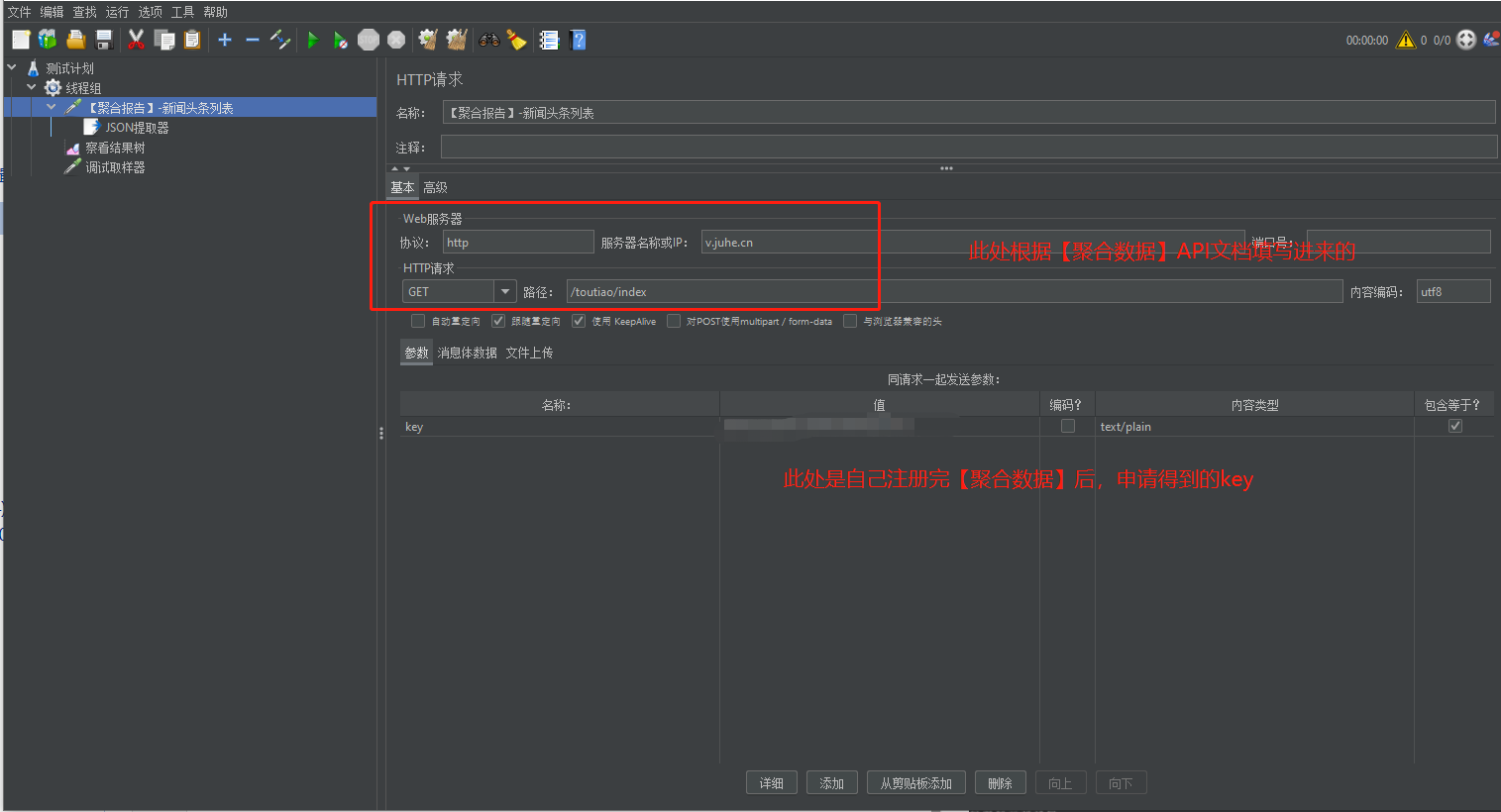
案例1:此处通过调用【聚合报告】的【新闻头条】请求,获取一个数据信息
(1)在Jmeter中发起【新闻头条列表】请求:
(2)发起请求后,得到了接口响应的JSON信息:
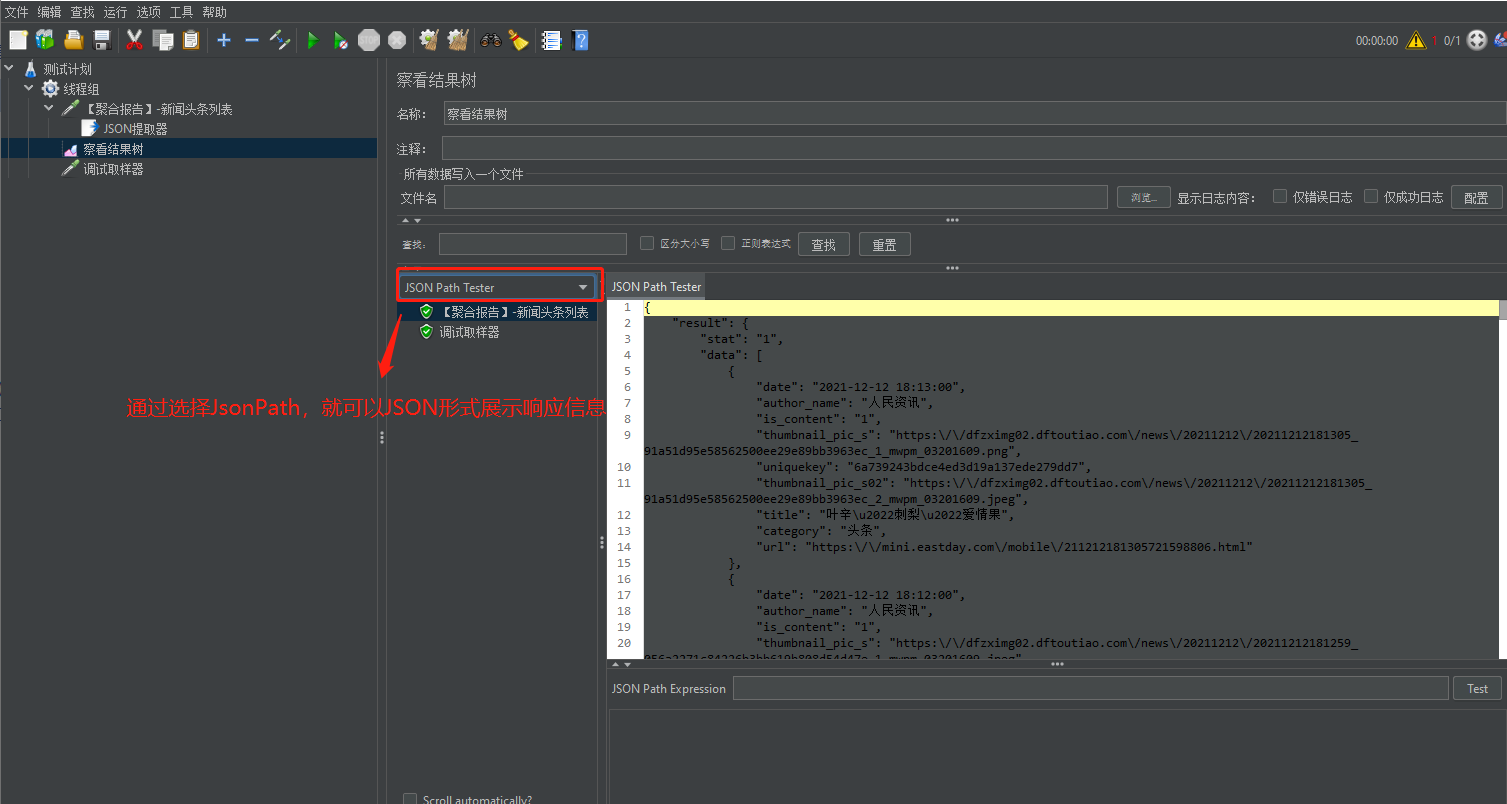
(3)我们想要获取提取响应信息里的"titile"信息,那么就可以使用JSON提取器。
(3.1)分析Json层级关系,位于"result"->"data"->"title"下
我们可以逐层取数据如:$.result.data\*.title
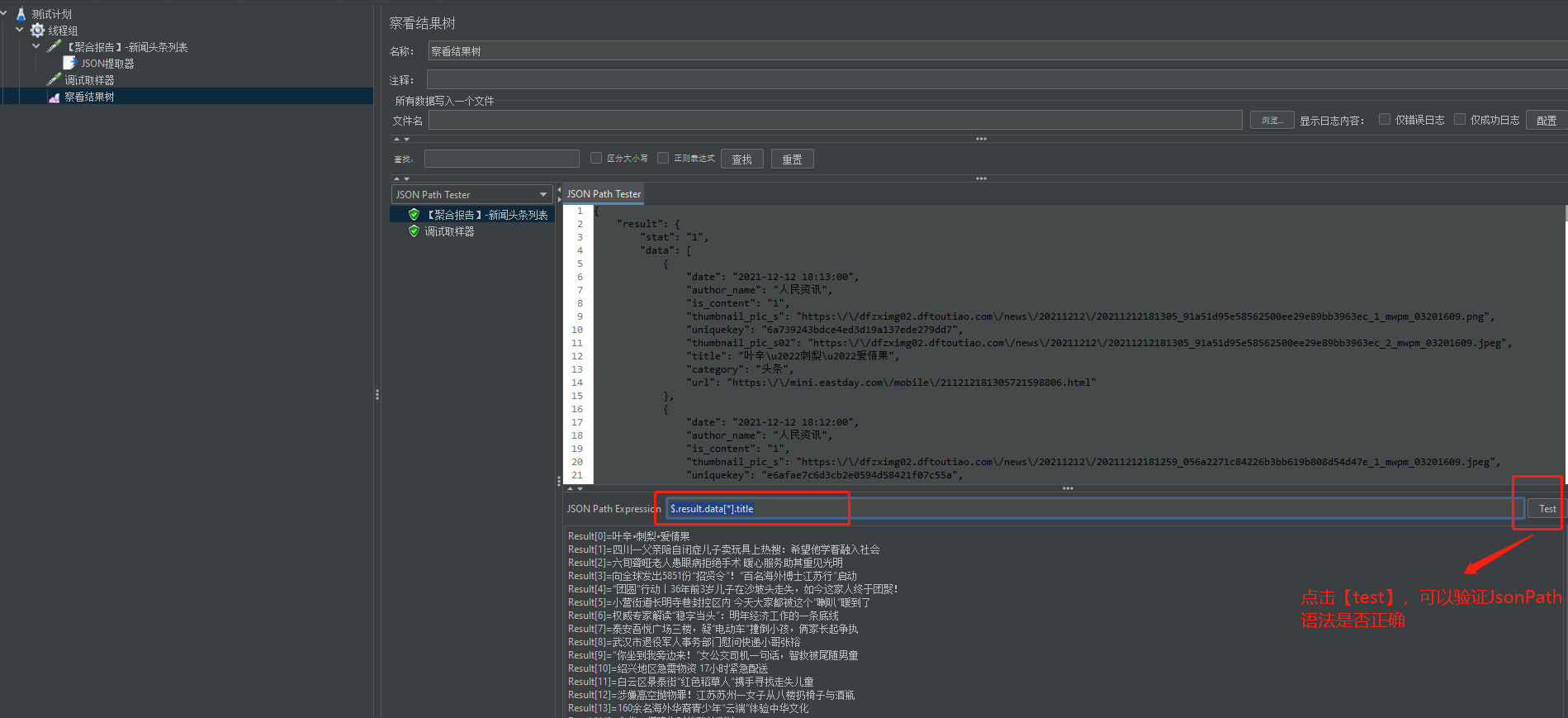
(3.2)我们也可以直接递归查找,如:$..title
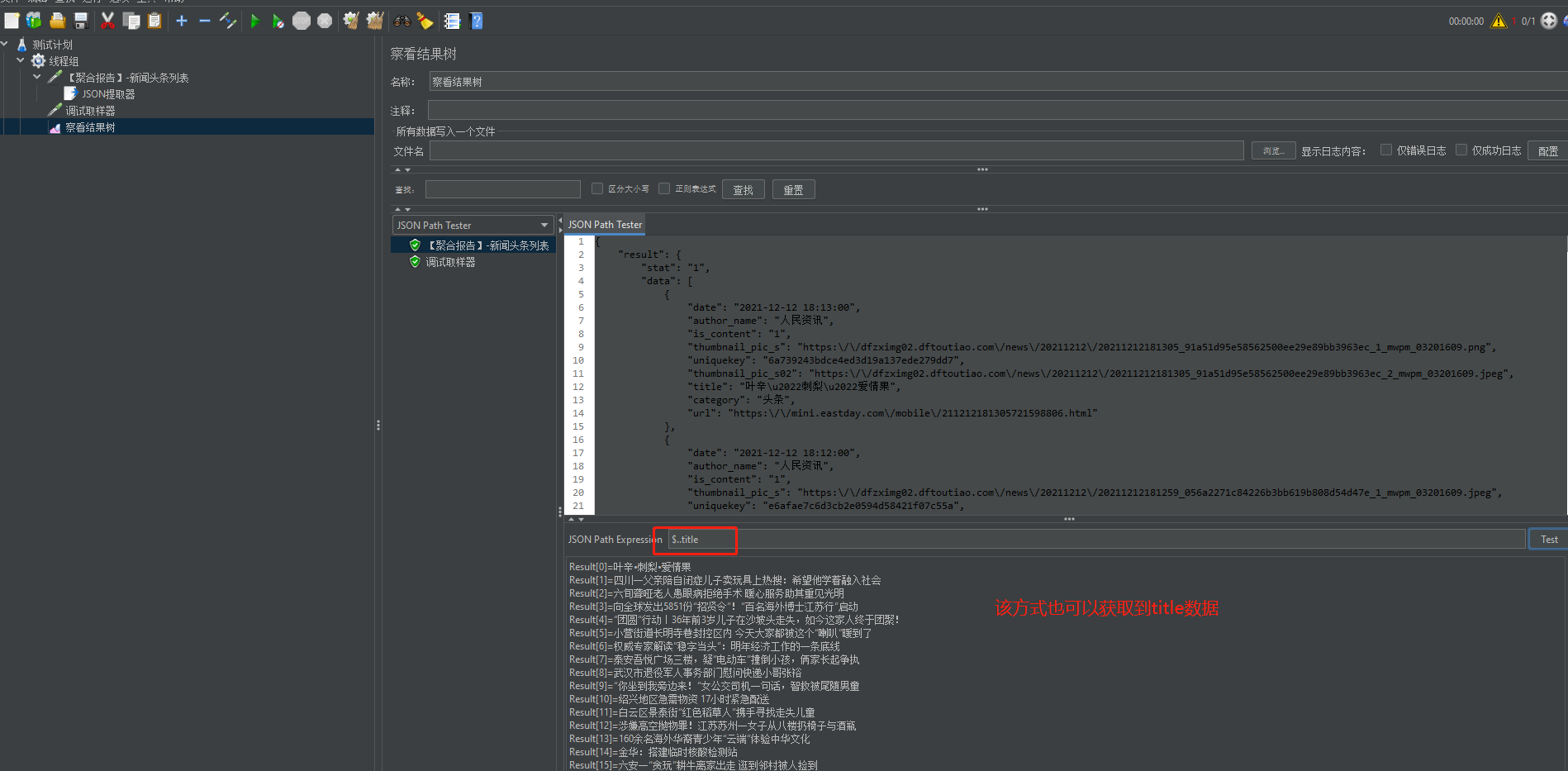
(4)验证通过后在JSON提取器中填写信息
(5)发起请求,检查Jmeter变量是否提取成功。
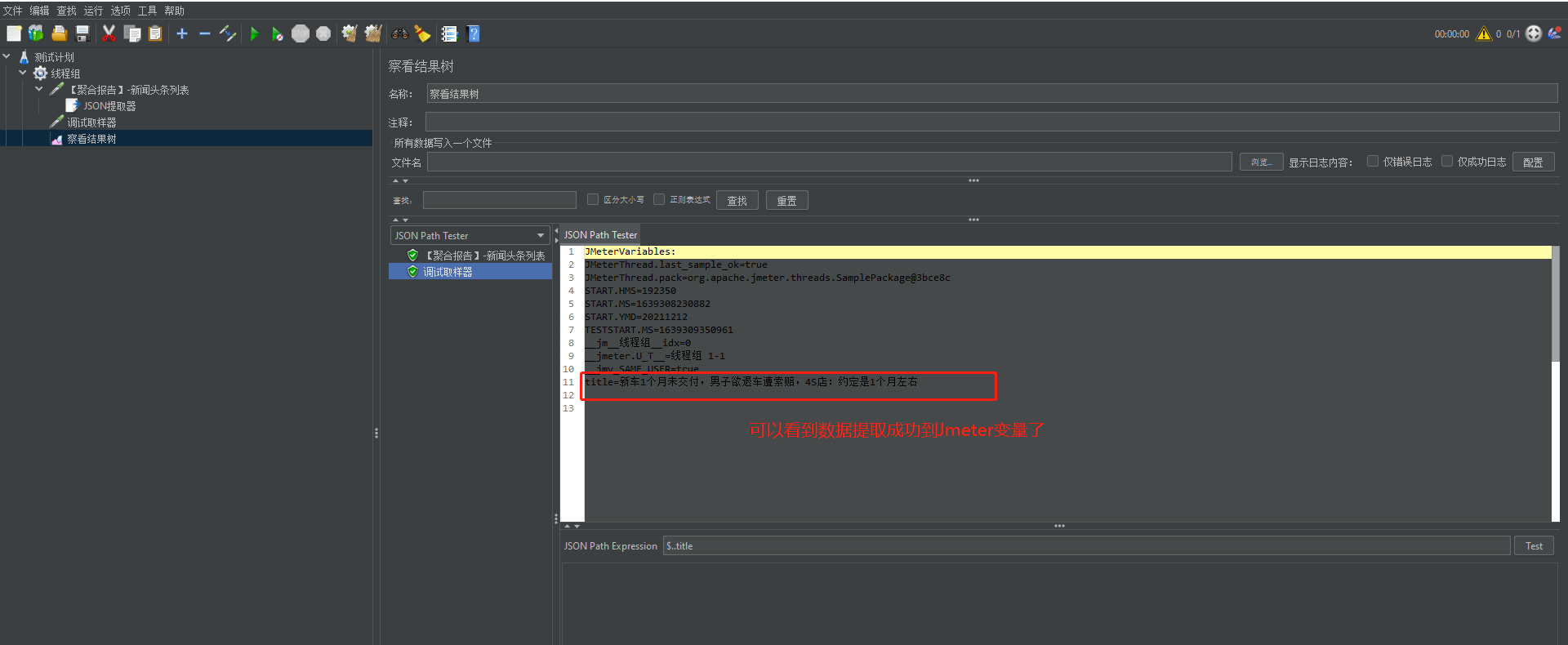
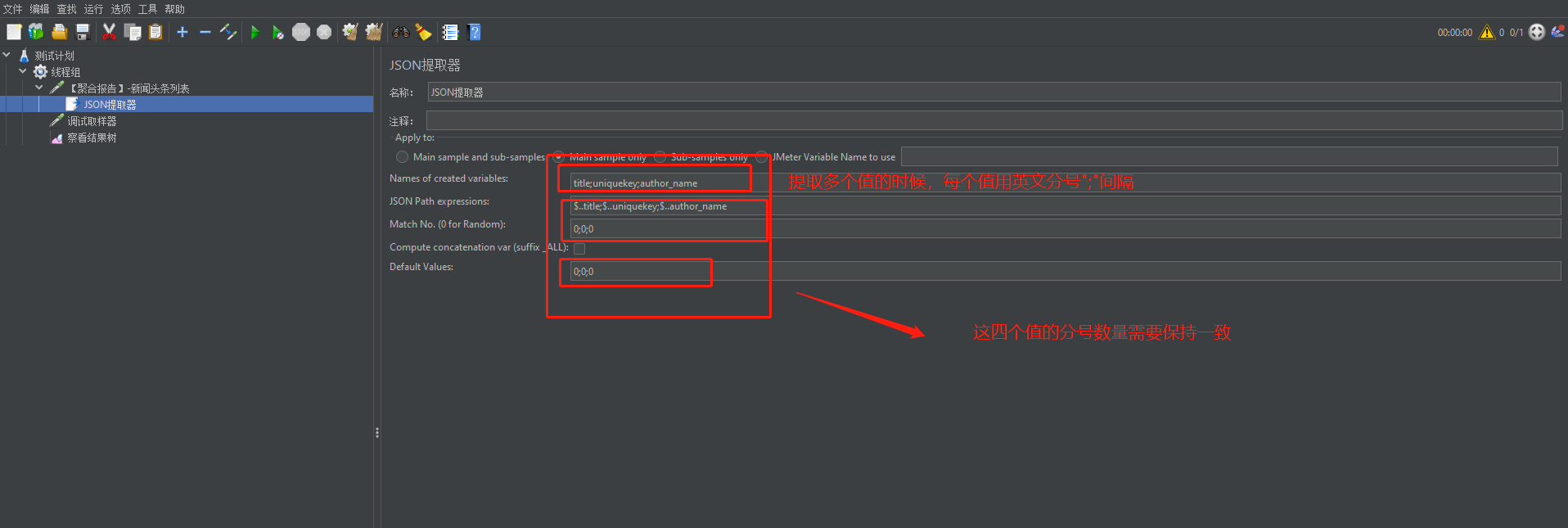
案例2:通过调用【聚合报告】的【新闻头条】请求后,我想即获取title,又获取uniquekey和author_name
在Json提取器中可以一次性提取多个值得,如图
执行结果:
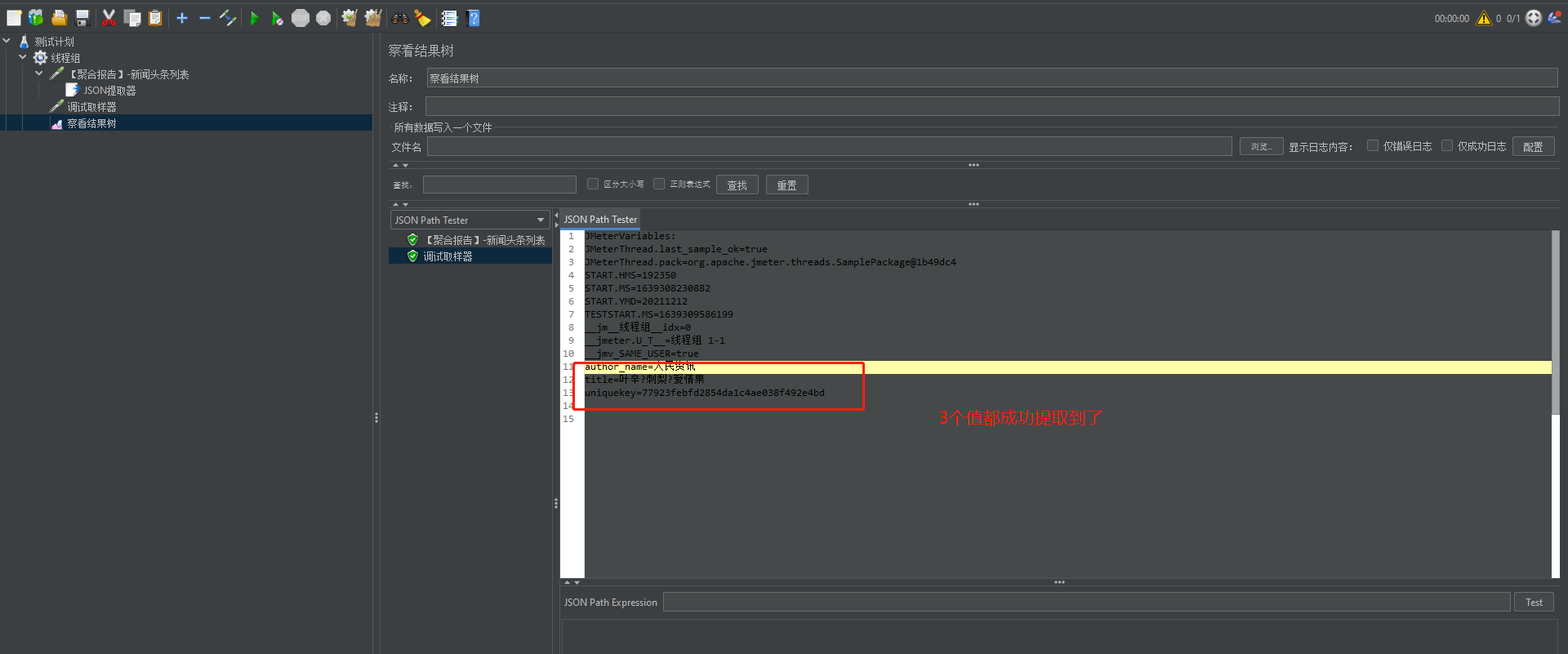
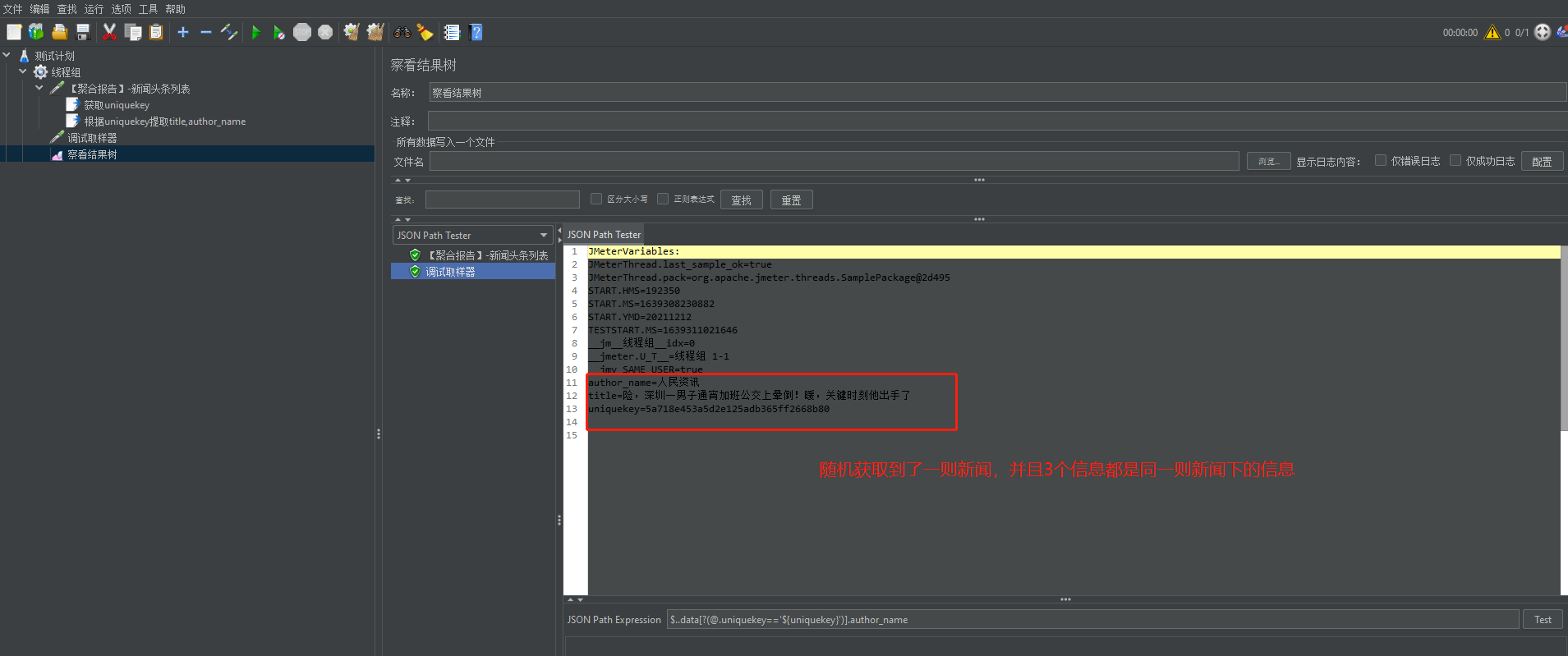
此处引发了一个思考:我们此处获取的值得都是随机的,也就是说,获取到的title,uniquekey,author_name可能都是在不同新闻下的,在做接口测试的时候,往往是需要保持各个数据都是同一主体信息下,下面案例给出解决方案。
案例3:通过调用【聚合报告】的【新闻头条】请求后,我想即获取title,又获取uniquekey和author_name,并且保证这三个信息都是在同一则新闻下。
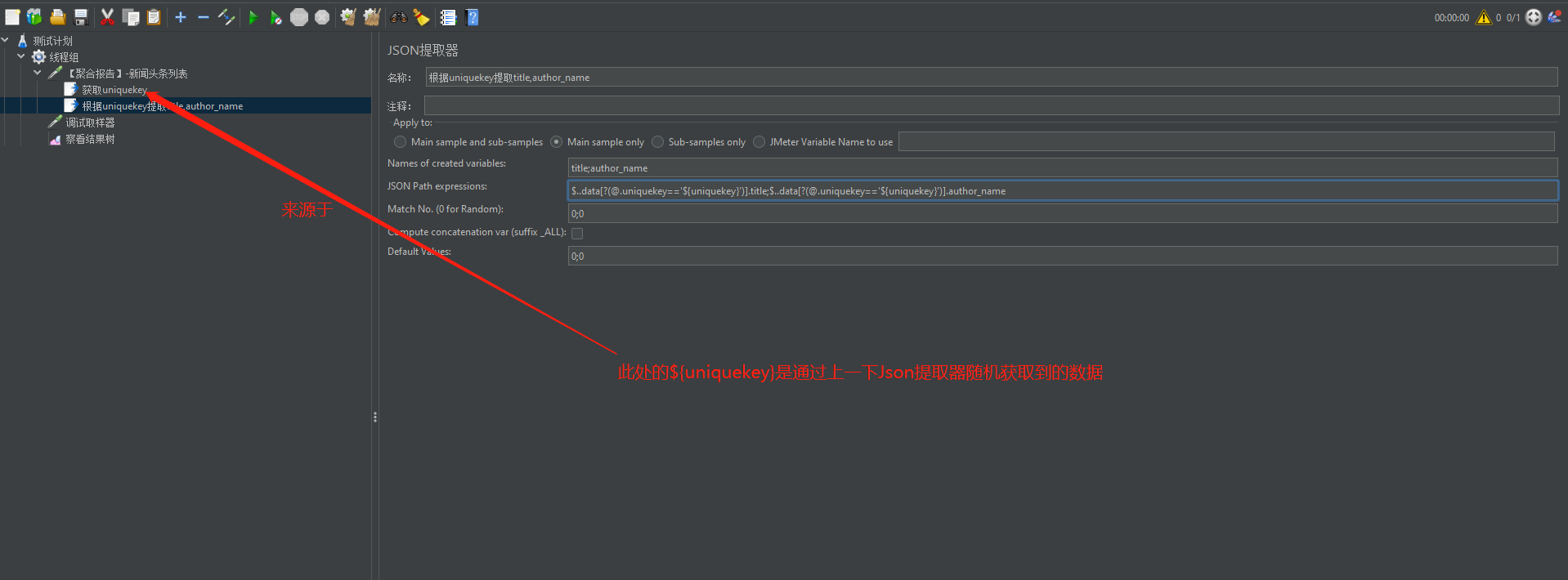
(1)先添加一个Json提取器获取每个新闻的唯一标识:uniquekey:
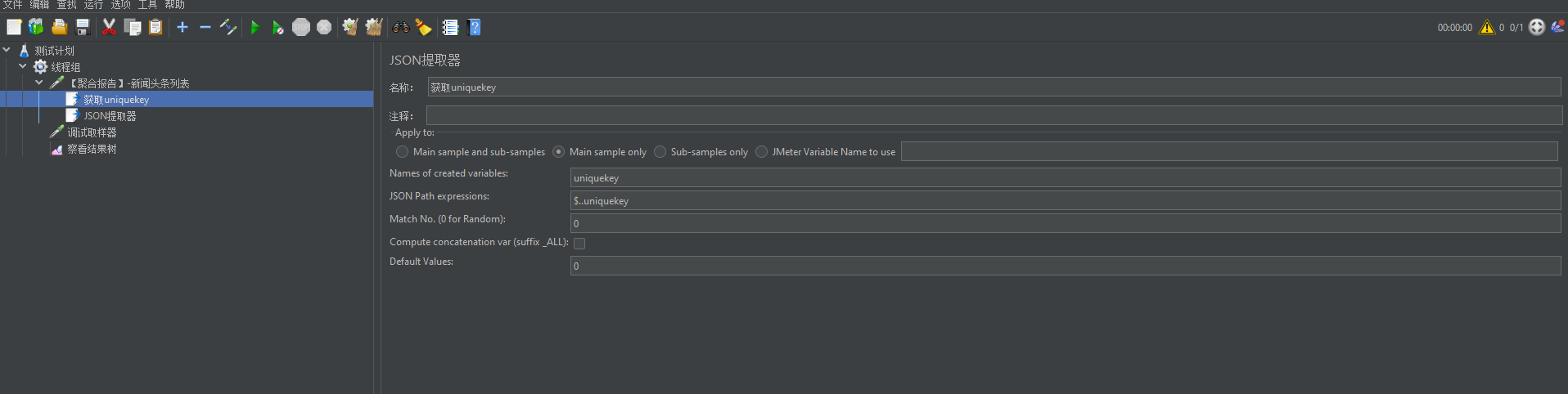
(2)再根据这个uniquekey做数据筛选,此处就需要用到了?()进行数据筛选。
附上JsonPath表达式:
根据uniquekey提取title:$..data[?(@.uniquekey=='${uniquekey}')].title
根据uniquekey提取author_name:$..data[?(@.uniquekey=='${uniquekey}')].author_name
(3)执行请求,查看提取情况
二:正则表达式提取器
Jmeter还可以使用正则表达式提取取样器信息。
Jmeter里的正则提取器页面介绍:
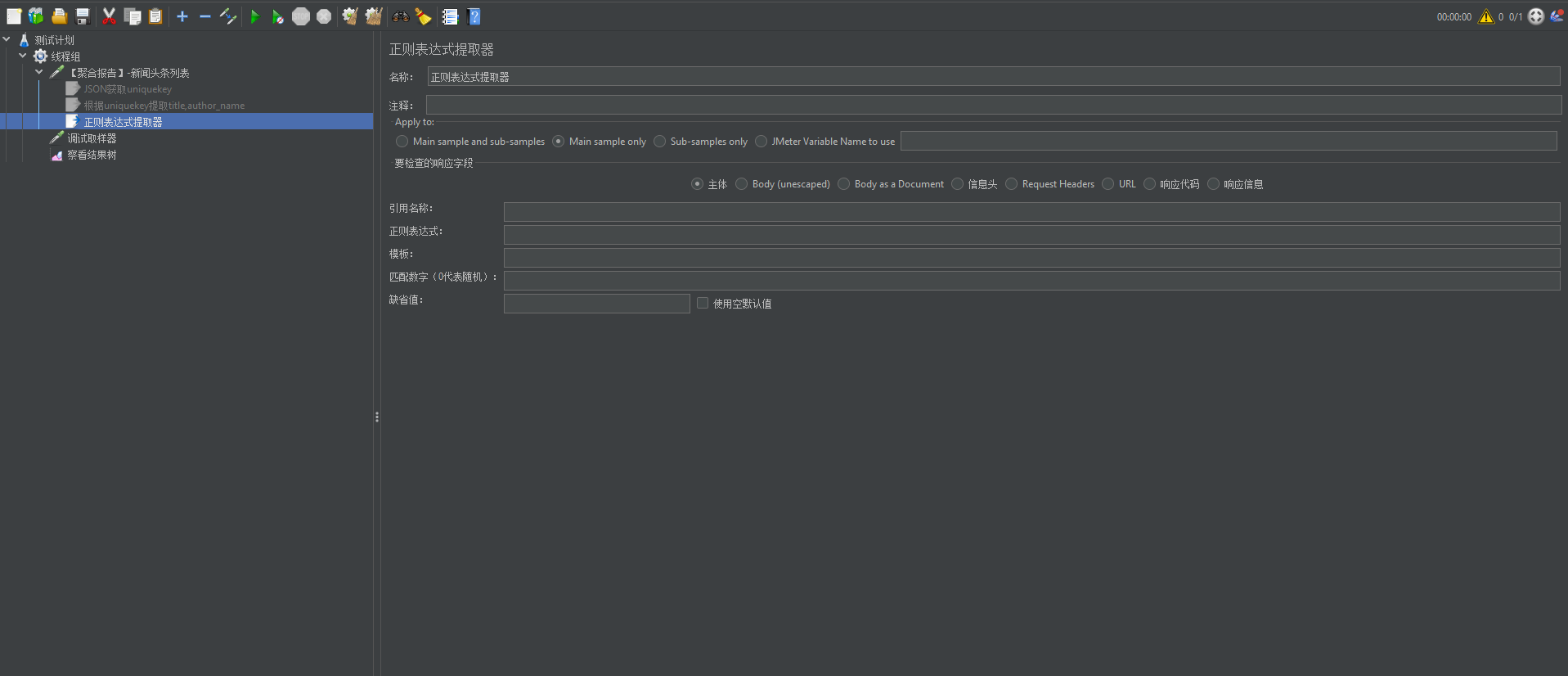
1、检查的响应字段,一般可以选择:种主体、信息头、请求头,默认选择的是主体,有些时候提取值是放在信息头的,这里需要注意选择一下
2、引用名称:给提取的变量起个变量名
3、正则表达式:填写的正则表达式
4、模板:可以填写$0$,$1$,$2$,$-1$等等 $0$:表示随机取匹配到的值 $-1$:表示取匹配到的所有值 $1$:表示取匹配到的第一个值 $2$:表示取匹配到的第二只值,如此类推
5、匹配数字:0表示随机,-1表示全部,1表示第一个数
6、缺省值:如果表达式没有取得到值,那默认一个值
正则表达式语法介绍:
1、常用元定符:
.:匹配除换行符以外的任意字符
$:匹配字符串的结束
^:匹配字符串的开始
2、常用限定符
*:重复零次或更多次
+:重复一次或更多次
?:重复零次或一次
{n}:重复n次
接下来我们用正则表达式提取uniquekey
思考步骤:1、优先考虑贪婪模式是否能获取到值,即(.+?)的表达式
2、分析所要获取的值得左右信息,把要获取的值用()包起来
如:此处想要获取uniquekey,它的左边界是固定的:"uniquekey",然后我们想要拿的值就用()包起来,所以此处的正则表达式为:"uniquekey":"(.+?)"
3、我们拿自己写的正则表达式到正则表达式在线测试器检查下语法是否有误,此处介绍的正则表达式测试网址:
Regex正则表达式在线测试、生成、解析工具 - GoRegex.cn
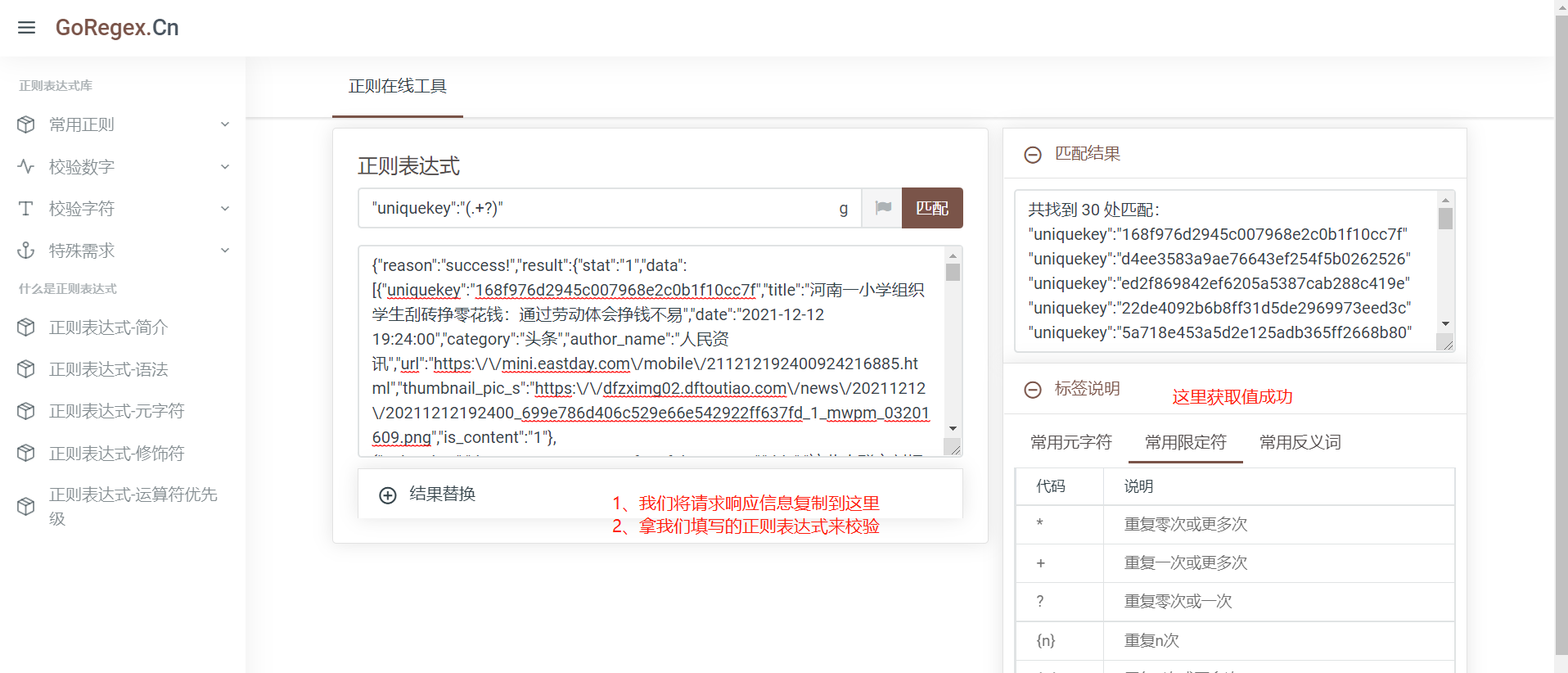
4、一般贪婪模式可以解决90%的正则提取问题,遇到个别提取不到的再用其他限定符代替
5、我们确认正则表达式无误后,就可以放到正则表达式提取器使用了。
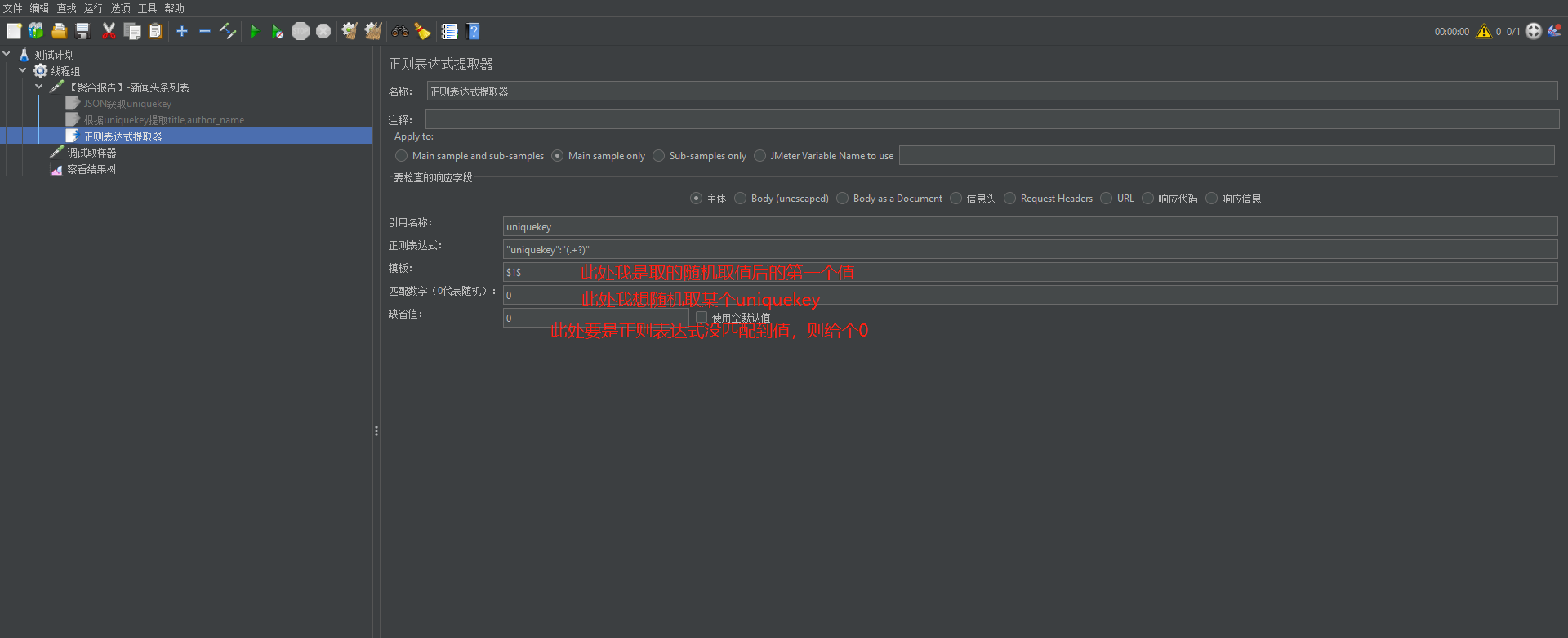
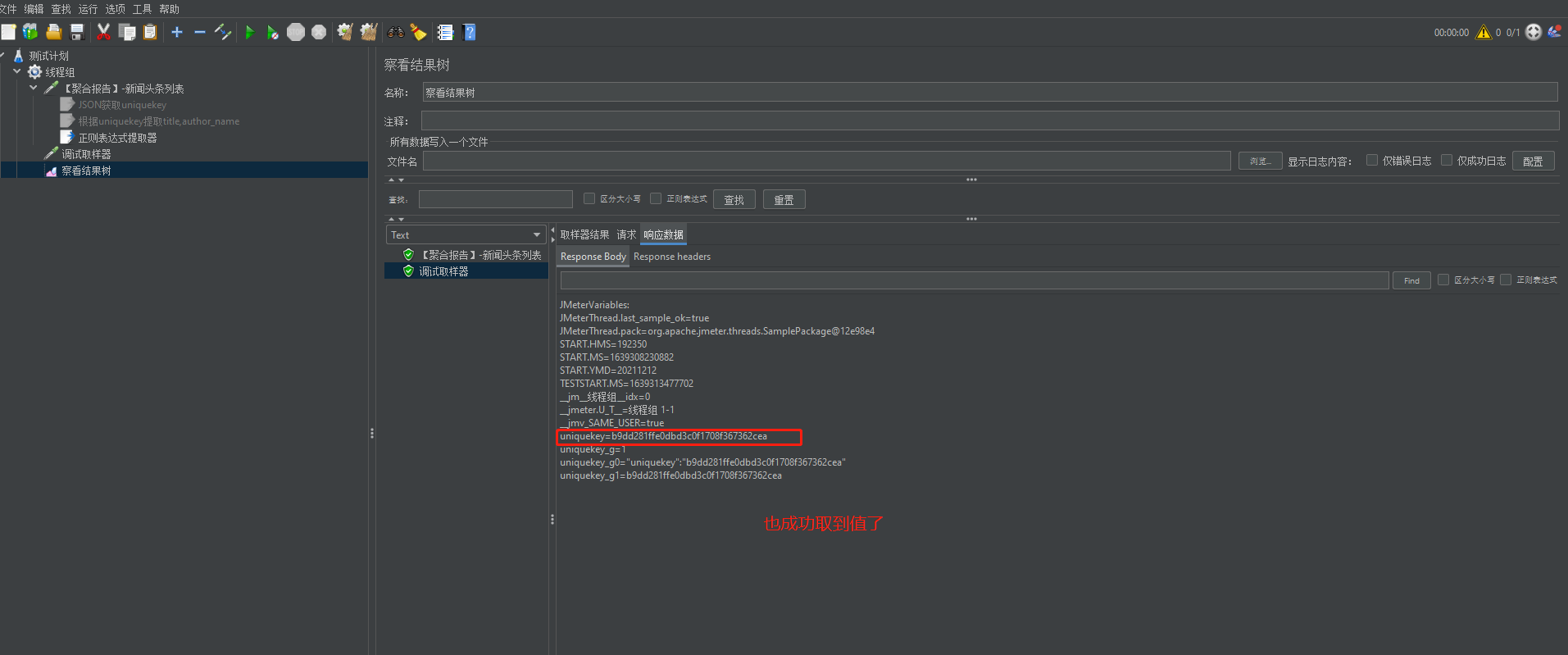
执行结果:
三、边界提取器
该提取器简单粗暴,只需要定义左右边界即可获取值,在一些响应信息体格式都是固定的情况,可以考虑使用该提取器提取数据
1、我们试下使用边界提取器提取uniquekey
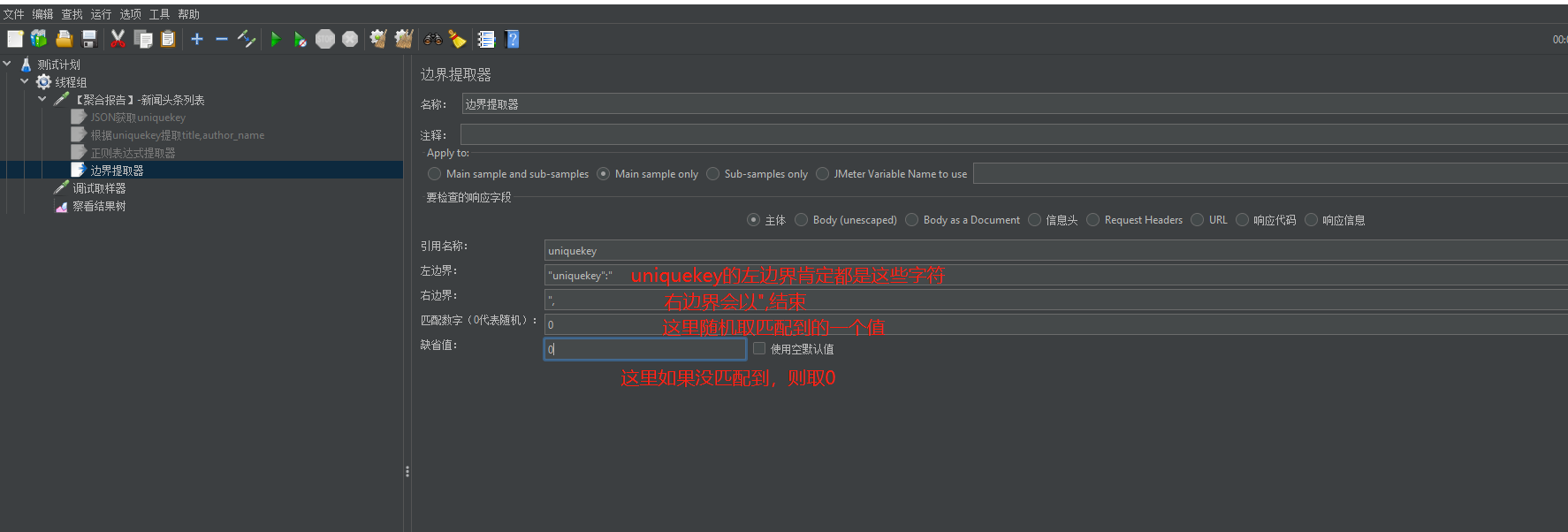
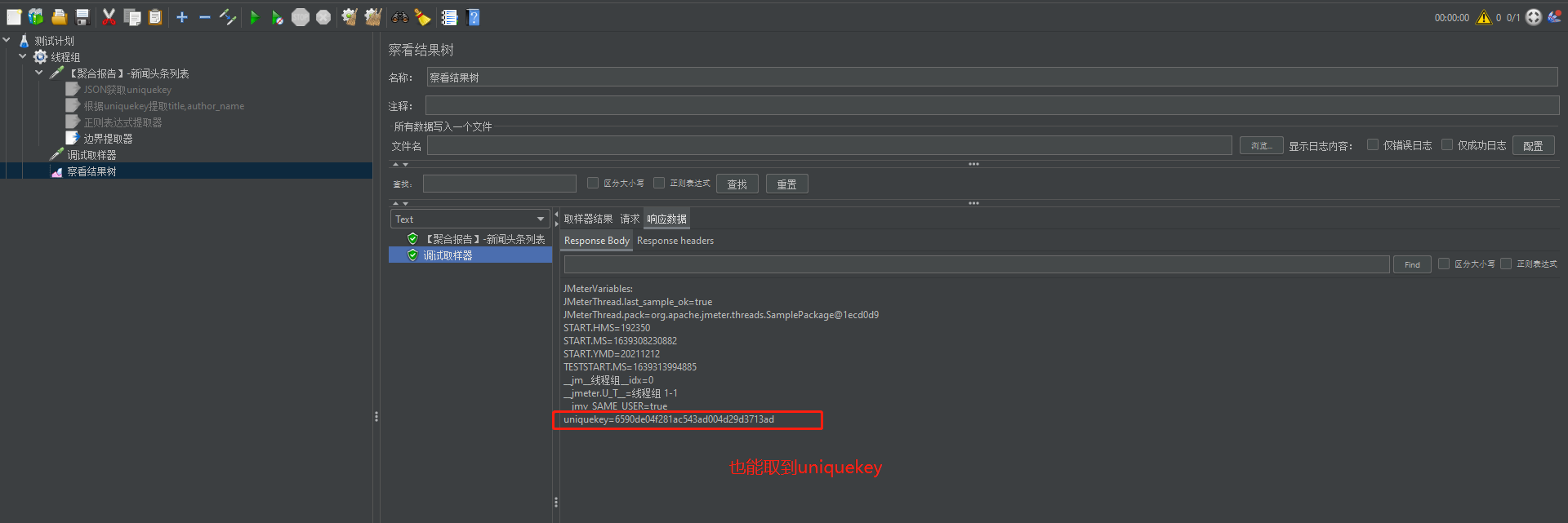
执行结果:
缺点:局限性比较高,对于一些结构比较灵活的字符串,还是得需要使用正则表达式
四、Beanshell后置处理器
跟Beanshell前置处理器的使用完全一直,只是执行顺序不一样,Beanshell前置处理器会在取样器执行前执行,而Beanshell后置处理器在取样器执行后执行,后置使用方法见前面所写的博客:
Jmeter全方面讲解------Jmeter的元件使用介绍:(四)前置处理器详解 - 筱筱创 - 博客园