重谈进程创建
在Linux操作系统中,fork是一个非常重要的函数,它从已经存在的进程中创建一个新的进程,该新进程是原进程的子进程,原进程是父进程。
进程调用fork,当控制转移到内核中的fork代码后,内核会做:
1.分配内存块和内核数据结构给子进程
2.将父进程部分数据结构内容拷贝至子进程
3.添加子进程到系统进程列表中
4.fork返回,开始调度器调度
当一个进程调用fork之后,就有两个二进制代码相同的进程。而且它们都运行到相同的地方。但每个进程都将可以 开始它们自己的旅程,看如下程序。
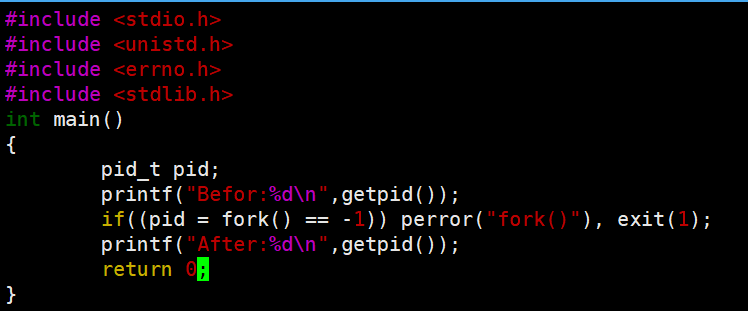

这里看到了三行输出,一行before,两行after。进程2447121先打印before消息,然后它有打印after。另一个after 消息有2447122打印的。注意到进程2447122没有打印before,为什么呢?如下图所示
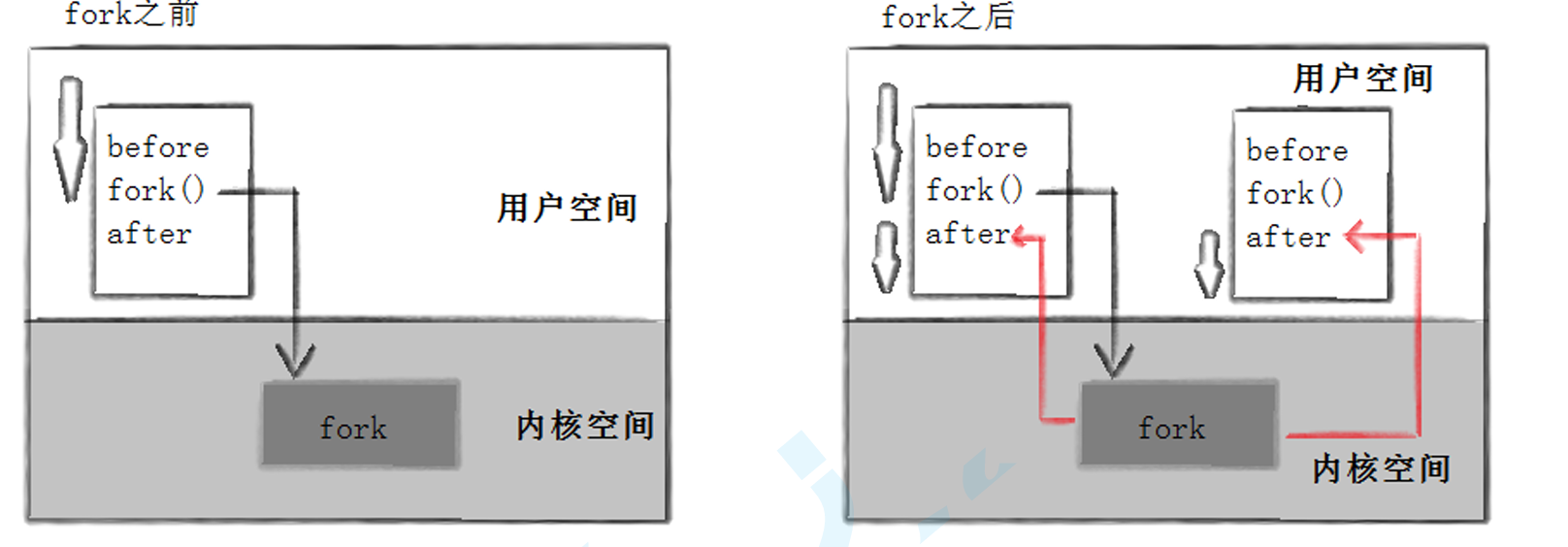
所以,fork之前父进程独立执行,fork之后,父子两个执行流分别执行。注意,fork之后,谁先执行完全由调度器 决定。
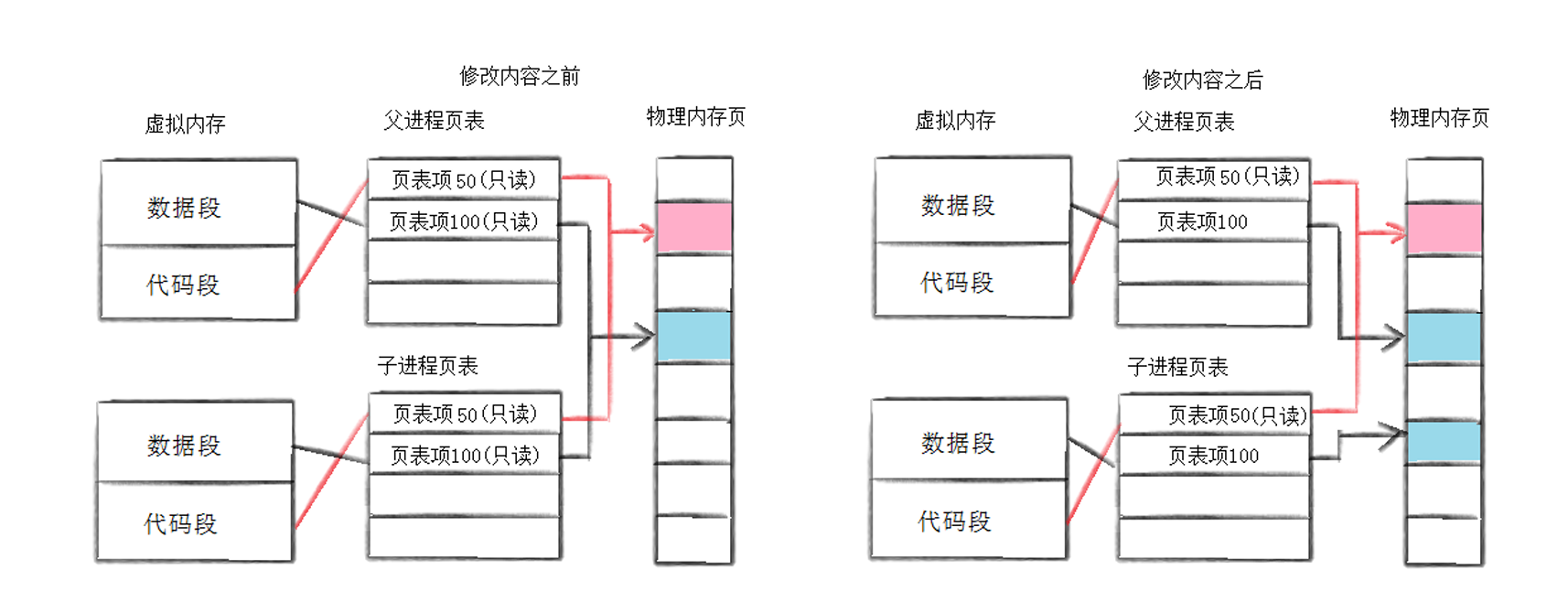
写时拷贝
运用写时拷贝机制,当创建子进程的时候是将父子进程数据均设置为只读,并指向相同的物理内存页,当任一进程尝试写入这些共享页的时,会触发页错误,此时内核才真正复制该页,开始为该进程分配新的物理内存空间来保存父子进程不同的数据。
fork使用情形:
1.一个父进程希望复制自己,使父子进程同时执行不同的代码段。例如,父进程等待客户端请求,生成子进程来处理请求。
2.一个进程要执行一个不同的程序。例如子进程从fork返回后,调用exec函数。
fork调用失败原因:
1.系统中有太多进程
2.实际用户的进程数超过限制
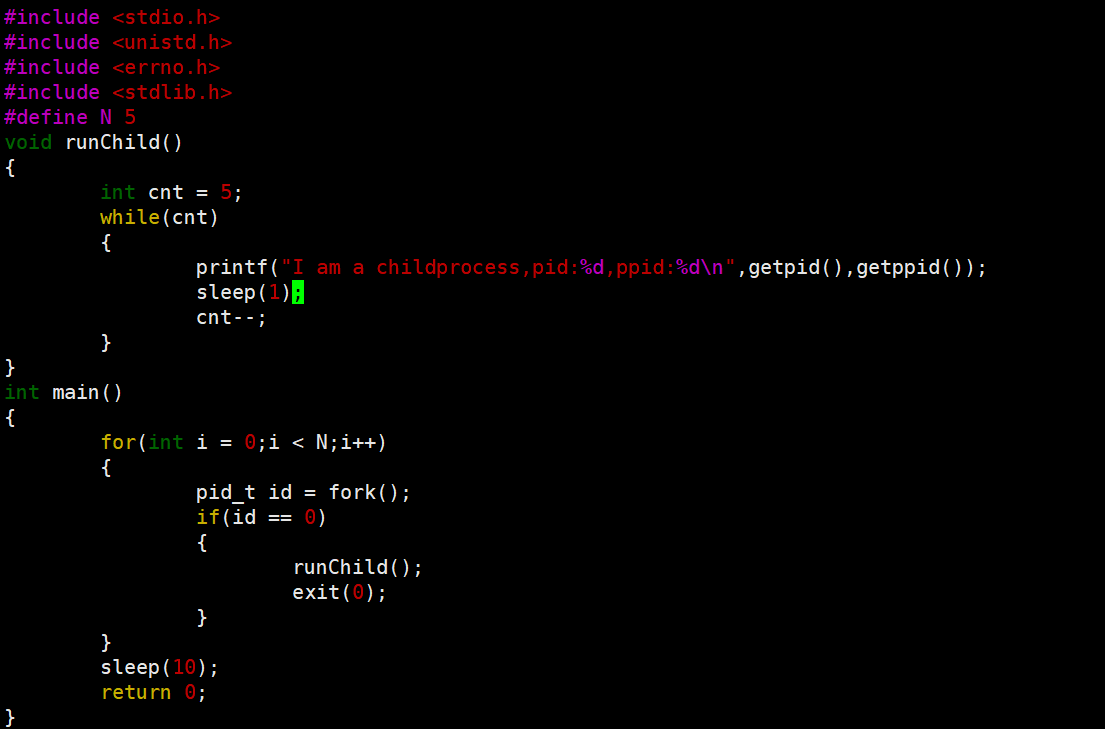

哪个子进程先运行完全取决于调度器,而不是取决于我们创建的顺序。
进程终止
进程退出的场景:
1.代码运行完毕,结果正确
2.代码运行完毕,结果不正确
3.进程异常终止
进程正常退出
回想我们以前学习C语言的时候,main函数总是会return 0,为什么是return 0?1或2或者3不可以吗?这个返回值给到谁了?


退出码(Exit Code),是进程结束时向操作系统或父进程返回的一个整数值,用于表示进程的终止状态(成功、失败或特定错误原因)。
我们的程序的父进程是命令行,因此bash命令行会接受程序的退出码,根据不同的退出码来表示不同的出错原因。
main函数的返回值,本质表示:进程运行完成时是否结果正确,可以用不同的返回值表示不同的出错原因。
$?:保存的是最近一次进程退出时候的退出码
但是错误码对于程序员来说是没有意义的,因为我们还是不明白错误码所代表的含义,因此需要借助函数来帮我们了解错误原因。
打印一下错误码对应的错误原因
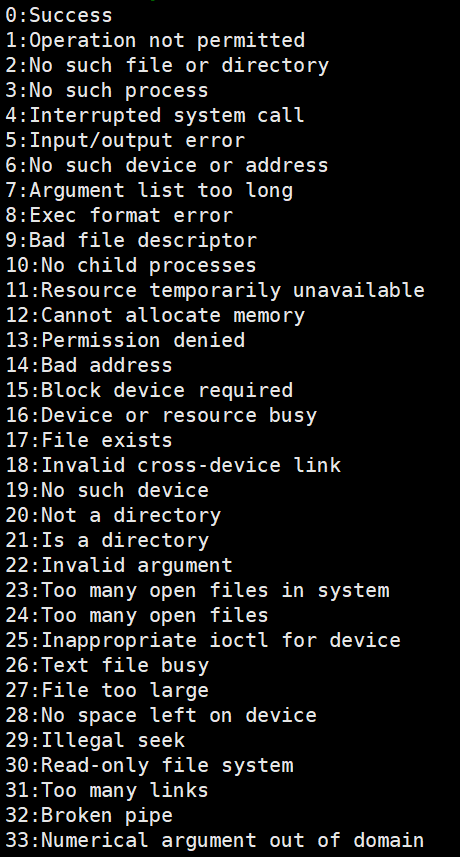
如果我们不想使用系统的错误码和错误信息,我们自身也可以设置属于自己的一套。
子进程返回错误码给父进程好让父进程知道子进程的运行结果,从而更好反馈给用户让用户采取下一步措施。

返回值(退出码)只会告诉父进程是否成功,而通过退出码码对应的错误信息可以告诉我们错误的原因。
异常终止
代码很可能没有跑完,这样进程的退出码就没有意义了,我们更加关心的是为什么异常了,以及发生了什么异常!
进程出现异常其本质为进程收到了对应的信号
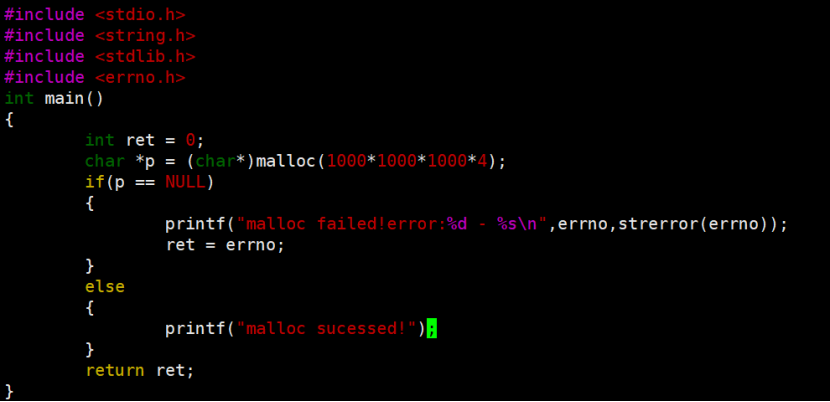
例如除零错误,可以看到信号8即FPE(floating point exception)。
进程收到9号信号,进程终止

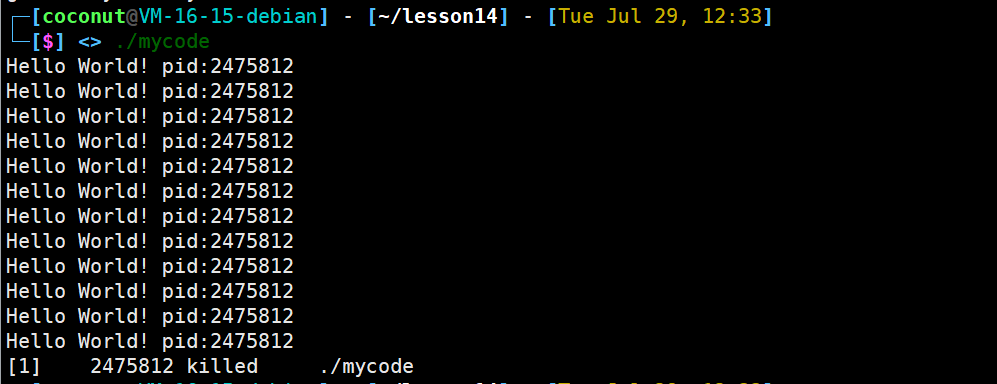

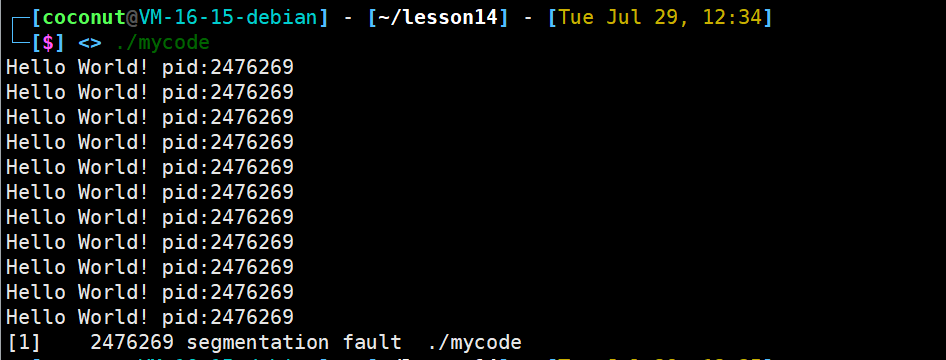
进程常见的退出方法
1.从main函数返回
2.调用exit()
3.调用_exit()
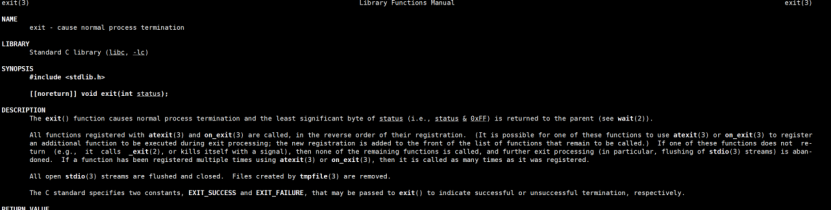
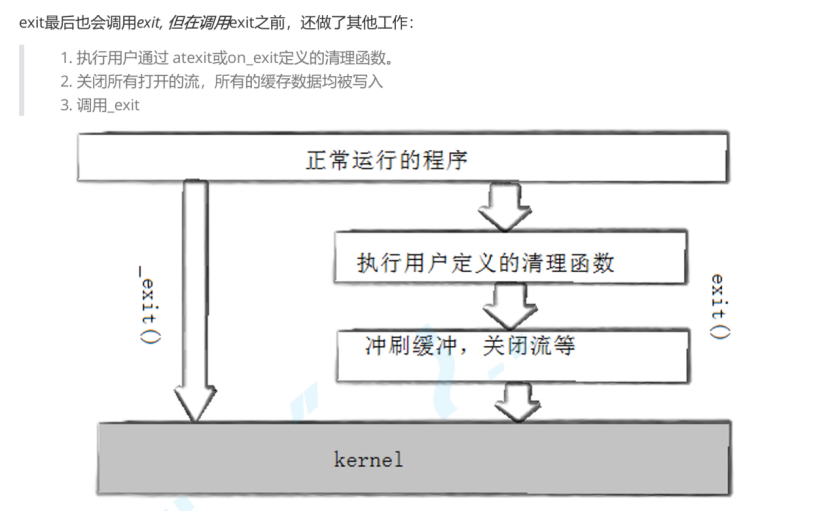
exit()
行为:1.刷新I/O缓冲区 2.调用atexit()注册的清理函数3.关闭所有打开的文件描述符4.返回状态码
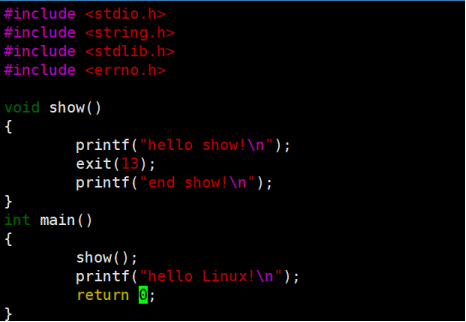

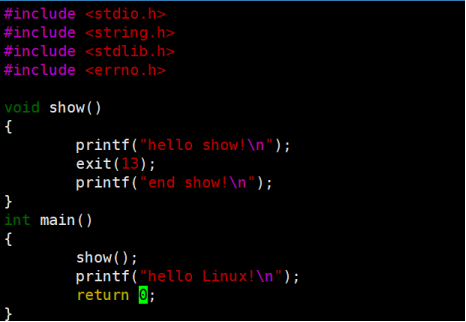

对比两次的运行结果,发现在任意地方调用exit都表示调用的进程直接退出,而return则是表示当前函数返回。
_exit()
行为:1.立即终止程序而不刷新缓冲区 2.直接跳过所有清理函数 3.关闭所有打开的文件描述符,但不刷新缓冲区 4.返回状态码
使用printf一定是先把数据写入缓冲区中,合适的时候进行刷新。
从上图看缓冲区一定不在内核中。如果在内核中,_exit()和exit()均会刷新缓冲区。操作系统不会做任何浪费时间空间的事情,如果你都不刷新为什么还要保存呢?其真正位置为用户空间!