📌 什么是缓存穿透?
缓存穿透 是指请求的数据既不在缓存中,也不在数据库中 ,导致请求每次都打到数据库,从而绕过缓存,造成数据库压力过大,甚至可能被恶意攻击。
🧨 常见场景:
- 用户请求一个不存在的id
- 恶意构造大量随机key攻击接口(缓存永远不命中)
🔍 缓存穿透的危害
- 缓存失效,数据库成了前线,系统抗压能力下降
- 可被攻击者利用,导致数据库宕机
- 缓存失效不一定是Bug,但会影响系统性能和稳定性
✅ 缓存穿透的解决方案
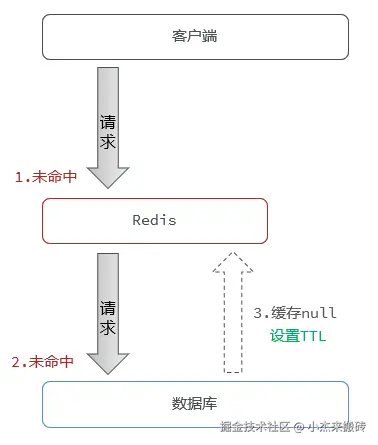
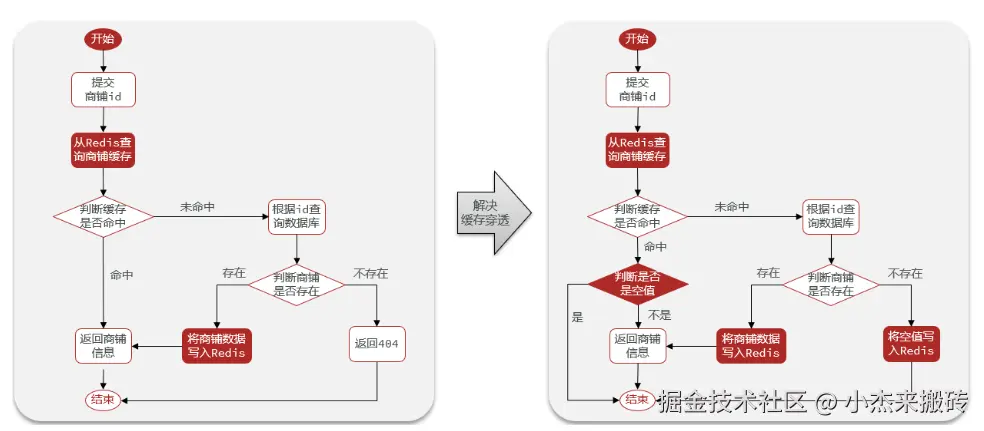
1. 缓存空对象(推荐)
 思路:
思路:
当数据库查询结果为空时,也将空结果写入缓存(比如缓存一个null或特殊标记),并设置短 TTL。
java
// 伪代码示例
String value = redis.get(key);
if (value == null) {
value = db.query(id);
if (value == null) {
redis.set(key, "", 5分钟); // 缓存空值
} else {
redis.set(key, value, 正常TTL);
}
}优点:
- 简单易实现
- 避免反复查询数据库
缺点:
- 可能缓存大量无用key,浪费空间(可用短TTL规避)
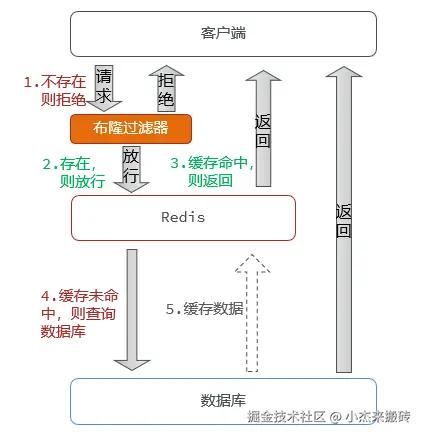
2. 布隆过滤器(推荐)
思路:
在缓存之前,使用布隆过滤器记录所有合法请求ID集合(如商品ID、用户ID等)。非法请求直接拒绝,不查缓存和数据库。
text
请求流程:
请求 -> 布隆过滤器判断是否可能存在 -> 是 → 查缓存 → 查DB
→ 否 → 拦截请求,直接返回空或错误提示优点:
- 空间占用极小,效率极高
- 拦截恶意请求非常有效
缺点:
- 有极小概率误判存在
- 布隆过滤器需手动维护更新(如新增商品ID时要添加进过滤器)
3. 请求参数校验(防御第一步)
思路:
- 在接口层增加参数校验,如 ID 是否为正整数,是否符合业务规则。
示例:
java
if (id <= 0) return error("非法请求");优点:
- 处理非法请求最直接的方法
- 降低后续压力
4. 加强安全保护
适用于遭受恶意攻击的情况:
- 添加验证码机制(限制恶意访问)
- 接口限流(如:每个 IP 每秒请求数)
- 黑名单机制(封掉频繁攻击源)
🧠 总结对比
| 方案 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 缓存空对象 | 简单、实用 | 占用空间、要注意TTL | 数据库查无时自动兜底 |
| 布隆过滤器 | 高效拦截、节省资源 | 有误判、维护复杂 | 商品ID、用户ID等有限集合验证 |
| 参数校验 | 快速、低成本 | 只防止明显非法请求 | 前端传参初步过滤 |
| 接口限流/验证码 | 防止恶意攻击 | 用户体验稍差 | 高并发或敏感接口 |
📍 二、缓存雪崩(Cache Avalanche)
1️⃣ 问题定义
大批缓存Key同时过期或Redis宕机,导致大量请求绕过缓存,直接打数据库,系统雪崩式瘫痪。
2️⃣ 常见触发原因
- 所有缓存key的 TTL 相同或过于集中
- Redis实例突然宕机或重启
- 系统突发高并发流量
3️⃣ 解决方案
✅ 方案一:设置 随机TTL
缓存过期时间加一个随机值,避免集中失效
java
int baseTtl = 30 * 60; // 30分钟
int random = new Random().nextInt(10 * 60); // 额外0~10分钟
redis.set(key, value, baseTtl + random);✅ 方案二:缓存预热 + 缓存重建
- 服务启动时,提前将重要数据加载进缓存
- 定时刷新热点缓存,避免过期同时发生
✅ 方案三:限流 + 降级机制
- 请求高峰期,使用限流器(如:令牌桶)限速访问数据库
- 当缓存不可用时,返回默认值/服务降级响应,保障系统可用性
✅ 方案四:Redis高可用部署
- 使用主从集群、哨兵机制、持久化(RDB+AOF)保障Redis稳定性
- 防止整个缓存系统宕机引发大面积雪崩
📍 三、缓存击穿(Cache Breakdown)
1️⃣ 问题定义
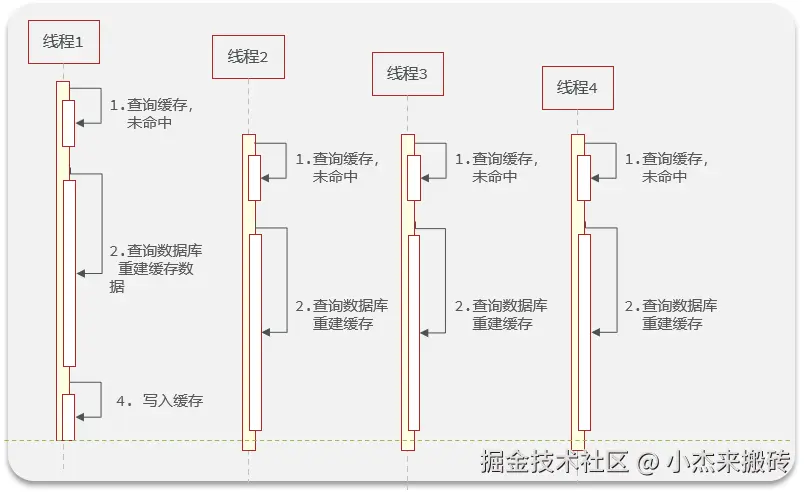
缓存中的某个"热点Key"刚好过期,此时有大量并发请求访问这个Key,由于缓存失效,请求直接打到数据库,导致数据库瞬时压力过大。
2️⃣ 常见场景
- 商品详情页、活动信息等热门数据设置了相同 TTL
- 过期瞬间,数千上万请求同时到来,击穿缓存层
3️⃣ 解决方案
✅ 方案一:互斥锁(加锁防击穿)
这里使用Redis中的setnx指令实现互斥锁,只有当值不存在时才能进行set操作
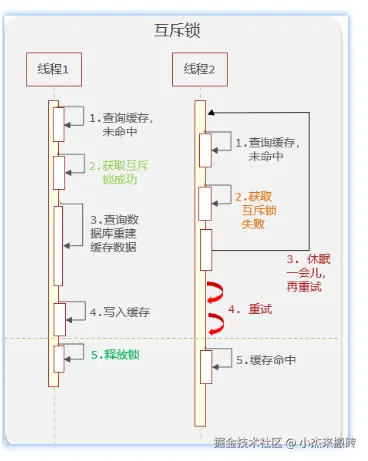
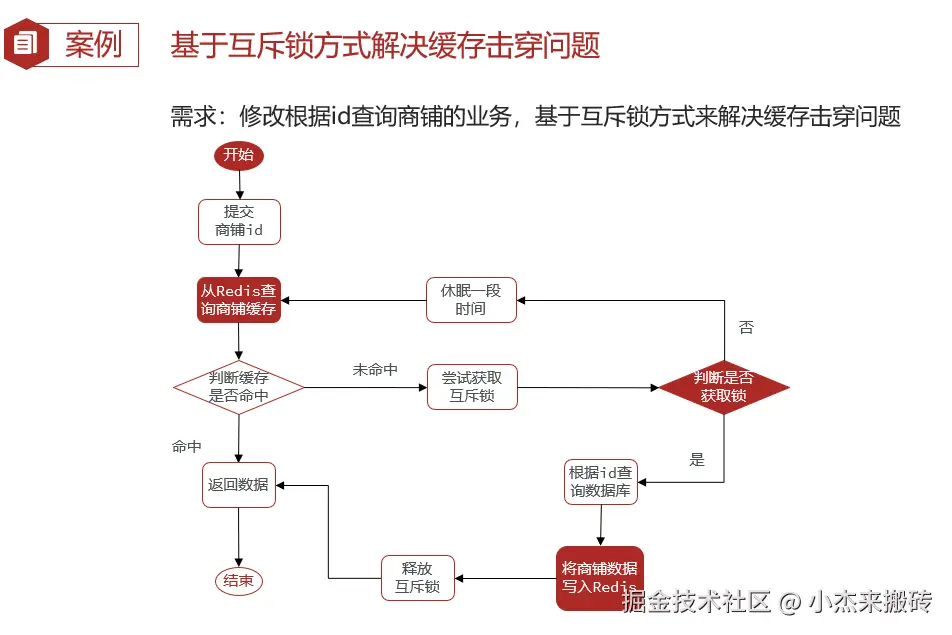
第一个请求线程访问数据库,其它线程等待,避免并发打DB
java
if (缓存不存在) {
获取分布式锁
if (获取成功) {
查询数据库
写入缓存
释放锁
} else {
睡一会儿再重试
}
}适合场景: 数据更新频率低、读取频率高的热点数据
工具推荐: Redisson、分布式锁实现
✅ 方案二:逻辑过期(伪装未过期)
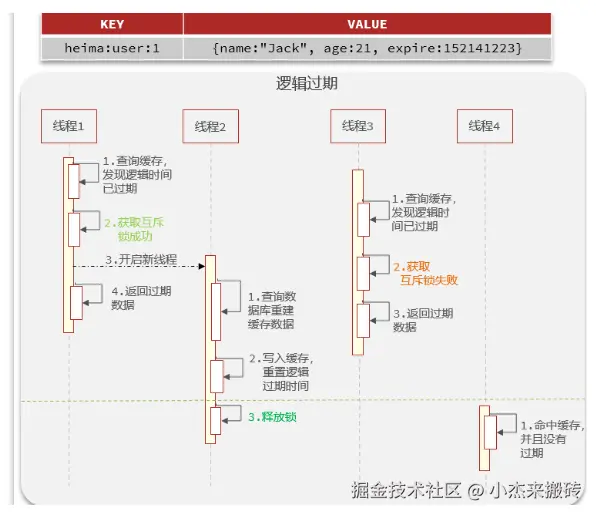
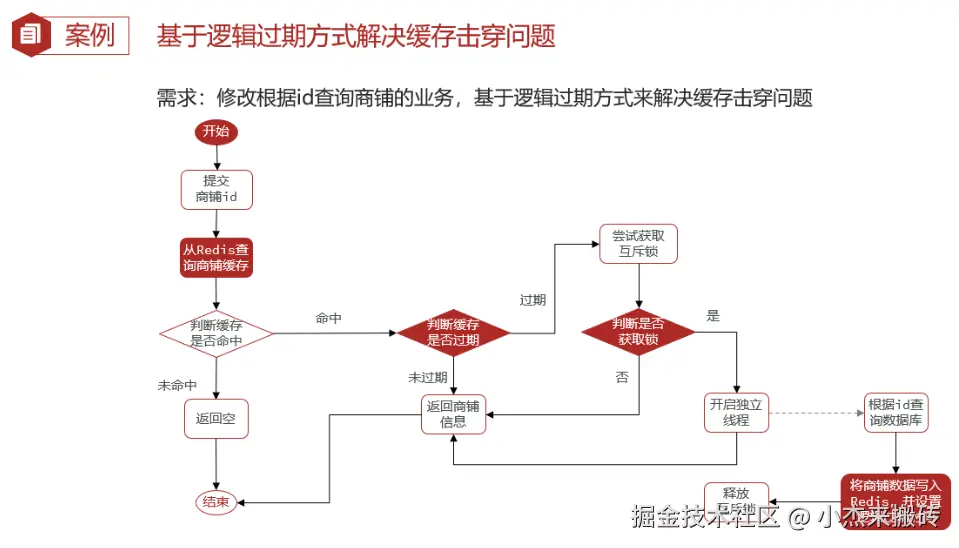
给缓存设置一个逻辑过期时间,一旦逻辑过期,则后台异步刷新数据,但仍然返回旧数据,防止缓存空缺。
json
{
"data": {商品数据},
"expireTime": "2025-07-30 17:00:00"
}- 读取缓存时先判断是否逻辑过期
- 如果过期,异步线程刷新缓存
- 仍然返回旧数据,避免数据库被压垮
优点: 无需加锁,不阻塞用户请求
缺点: 数据有一点点旧,不适合强一致性需求
✅ 方案三:热点数据预热
热门数据在缓存过期前手动刷新或重新写入,避免其真正过期。
- 启动时将热门key预先加载进缓存
- 定时任务刷新缓存
📌 总结口诀记忆法
- 穿透:查无数据 → 加布隆,缓存空
- 击穿:热点失效 → 加锁或逻辑过期
- 雪崩:集体失效 → TTL分散,限流兜底
🧠 三种常见缓存问题对比速览
| 名称 | 定义简述 | 触发条件 | 危害 | 常用解决方案 |
|---|---|---|---|---|
| 缓存穿透 | 查无数据 | 请求的数据 缓存和数据库都没有 | 请求直击数据库(高并发压垮数据库) | 布隆过滤器、缓存空对象、参数校验 |
| 缓存击穿 | 热点失效 | 单个热点key刚好失效,此时大量请求涌入 | 同一时间大量请求打到数据库 | 互斥锁、逻辑过期、热点预热 |
| 缓存雪崩 | 大量失效 | 大量缓存key同一时间失效(如设置相同TTL) | 缓存大面积失效 → DB崩溃 | 过期时间随机化、分批加载、限流降级 |