概述
备注:前前后后摸索半年,还是没有掌握这个中间件。本文很水,谨慎下滑。
Jaeger是一个分布式追踪系统,灵感来自Google Dapper,可用于监控基于微服务的分布式系统:
- 分布式上下文传递
- 分布式事务监听
- 根因分析
- 服务依赖性分析
- 性能/延迟优化
架构
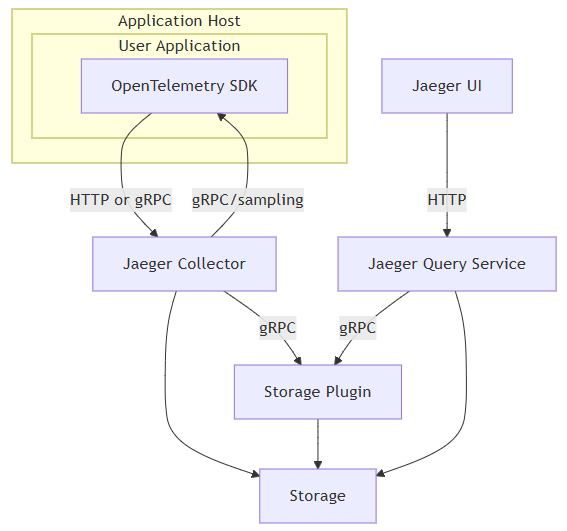
优点
- Uber开源并被CNCF纳入孵化项目,背后有大厂和强大的组织支持,项目目前开发活跃;
- 原生支持OpenTracing标准,支持多种主流语言,可复用大量OpenTracing组件;
- 丰富的采样率设置支持;
- 高扩展,易伸缩,没有单点故障,可以随着业务方便扩容;
- 多种存储后端支持,原生支持Cassandra和Elasticsearch,可通过gRPC API与ClickHouse集成;
- 提供现代的Web UI,可支持大量数据的呈现;
- 支持云原生的部署方式,非常容易部署在K8s集群中;
- 可观察性,所有组件均默认可暴露Prometheus Metrics,日志默认使用结构化的日志到标准输出。
缺点
- 接入过程有一定的侵入性;
- 相比于SkyWalking,更专注于链路追踪,日志和指标功能支持比较有限;
- 缺少监控和报警机制,需要结合第三方工具来实现。
分布式追踪系统本身会造成性能损耗,如果完整记录每次请求,对生产环境可能会有极大的性能损耗,一般需要进行采样设置。
当前支持四种采样率设置:
- 固定采样:
sampler.type=const,sampler.param=1表示全采样,sampler.param=0表示不采样; - 按百分比采样:
sampler.type=probabilistic,sampler.param=0.1表示随机采十分之一的样本; - 采样速度限制:
sampler.type=ratelimiting,sampler.param=2.0表示每秒采样两个traces; - 动态获取采样率:
sampler.type=remote,默认配置,可通过配置从Agent中获取采样率的动态设置; - 自适应采样:Adaptive Sampling。
部署
Jaeger提供all-in-one的Docker镜像,包含Jaeger UI、jaeger-collector、jaeger-query和jaeger-agent,以及一个内存(注意此处会踩坑)存储组件:
bash
docker run --rm --name jaeger \
-e COLLECTOR_ZIPKIN_HOST_PORT=:9411 \
-p 6831:6831/udp \
-p 6832:6832/udp \
-p 5778:5778 \
-p 16686:16686 \
-p 4317:4317 \
-p 4318:4318 \
-p 14250:14250 \
-p 14268:14268 \
-p 14269:14269 \
-p 9411:9411 \
jaegertracing/all-in-one:1.6.0WebUI
关于页面的一些操作,比如排查某个时间点某个服务里的某个接口请求耗时超长,想知道具体在什么环境,请求耗时长,是查询DB,还是Redis,还是通过HTTP或RPC方式请求其他内部服务的接口,亦或是请求外部接口。
打开Jaeger UI,选择某个Service后,在Operation里输入接口地址,无需回车自动过滤:
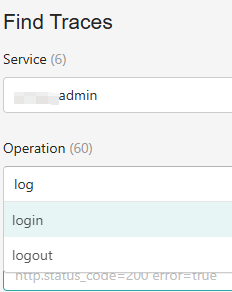
选择需要定位链路耗时长的接口,如下图的login接口。
但这里有个问题,一个服务内很有可能存在多个登录接口,比如:/api/v1/login,/api/v2/login,/api/auth/login,都统一展示为login。
如下图,搜索最近12小时,最低耗时为400ms,最多查询200个结果:
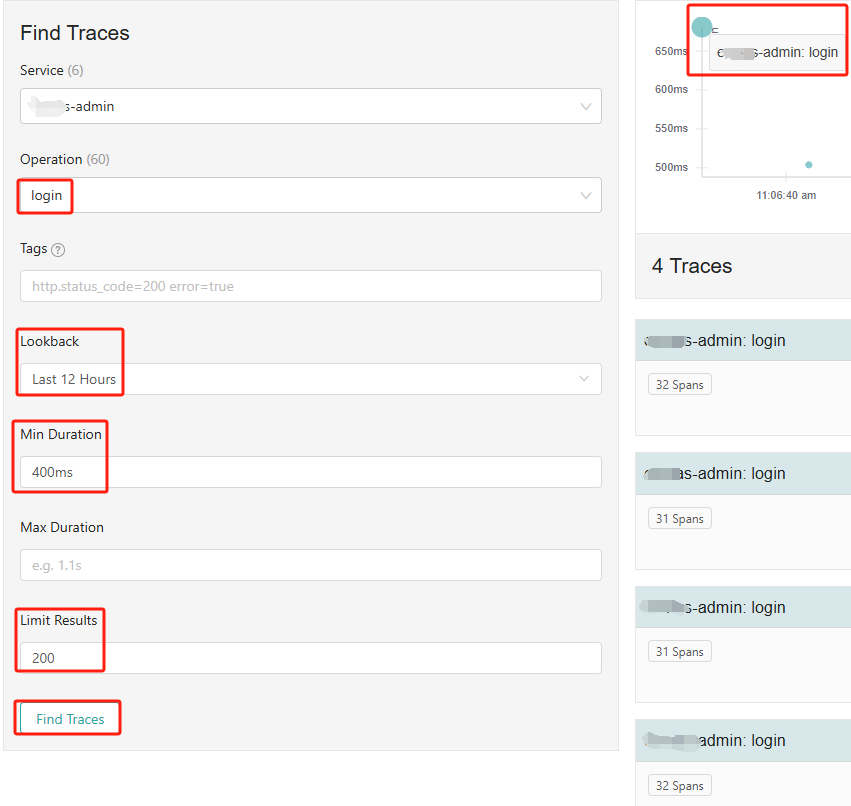
点击【Find Traces】,有4条满足条件的结果,可以点击页面上方的圆球(是的,圆球越大,表示此次请求链路耗时越长),或下面的具体Trace。进入Trace详情页:http://105.146.137.144:30086/trace/d6cefd2d27d9c9f4。
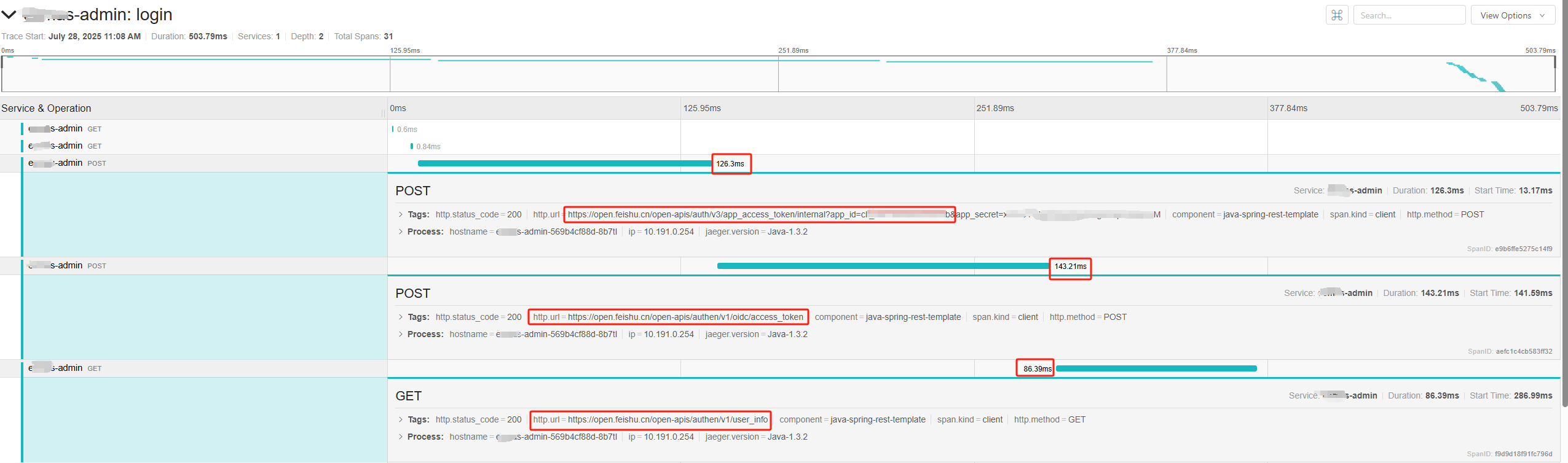
信息量:
- 整个链路有31个Span,涉及1个服务,最大深度为2,耗时503.79ms;
- 其中请求链路耗时最长的有3个外部请求,都是飞书,总共为126.3+143.21+86.39=355.9ms,占比70.64%;
除了最近几小时,还有一个自定义查询时间选项:
支持精确到分钟级别的区间查询:
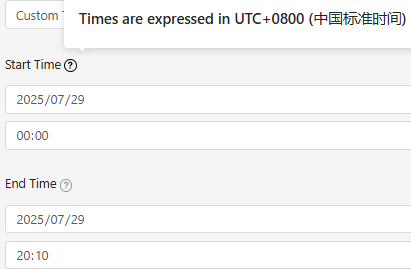
以服务A的接口A1来查询Trace列表,若服务B调用过服务A的接口A1,也会出现在查询结果里,支持5种排序方式,
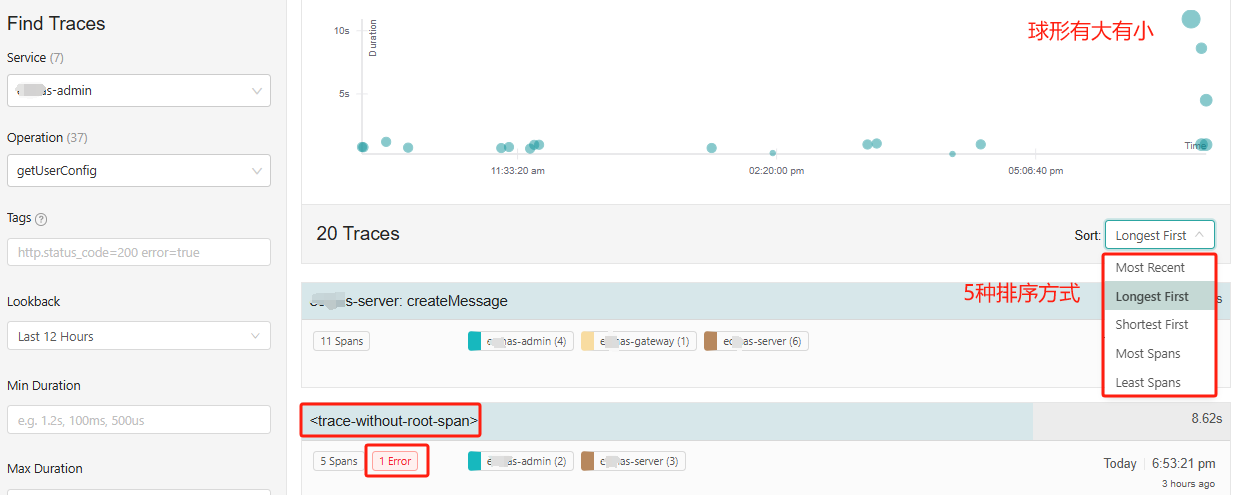
问题:
- 怎么会有
<trace-without-root-span>,可以点击查看详情:
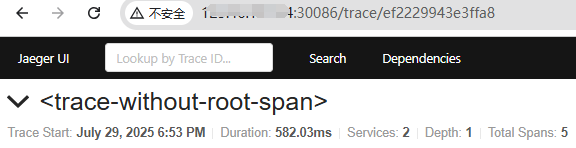
- 怎么会有
1 Error?再次查询,没找到。
Tag过滤
本地开发环境,大概率会复用dev或test环境的中间件,比如Jaeger,会发现本地的接口信息也会被Jaeger统计到。
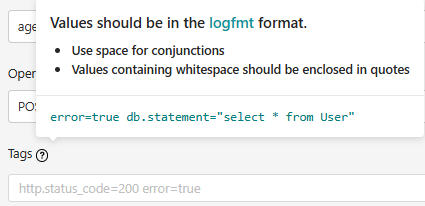
因此,Jaeger提供Tags过滤的功能。关于logfmt,参考官网。
示例:
- 精确匹配:
ip=10.191.0.174,只查询dev/test环境下的某个Pod IP; - 排除匹配:
hostname=~DESKTOP-L20EH42,过滤掉本机域名。
集成Prometheus和Grafana
比如Jaeger通过k8s方式部署在某个节点上,浏览器打开http://105.146.137.144:30086/(别试了,随便写的IP地址),默认跳转打开的是http://105.146.137.144:30086/search。Jaeger默认通过该端口暴露指标信息,http://105.146.137.144:30086/metrics,这意味着在Prometheus页面可以执行查询。
# HELP go_gc_duration_seconds A summary of the GC invocation durations.
# TYPE go_gc_duration_seconds summary
go_gc_duration_seconds{quantile="0"} 0.000261106
go_gc_duration_seconds{quantile="0.25"} 0.000337393
go_gc_duration_seconds{quantile="0.5"} 0.000377206
go_gc_duration_seconds{quantile="0.75"} 0.00044075
go_gc_duration_seconds{quantile="1"} 0.094695187
go_gc_duration_seconds_sum 9.559860084
go_gc_duration_seconds_count 2652严格按照Prometheus指标数据格式。
打开Grafana,进入connections页面,输入jaeger:
输入上面的URL,点击Save & test,一般没有设置用户名密码。
连接成功后,可以开始探索和配置仪表板和面板。

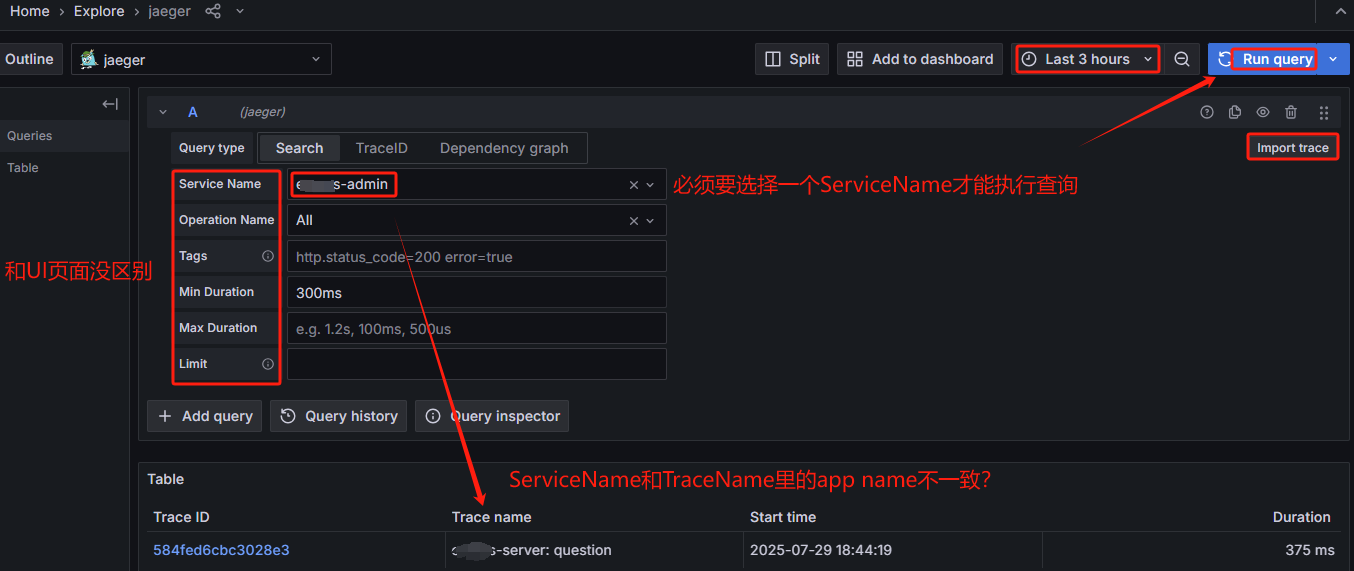
点击上图中的Trace ID,进入
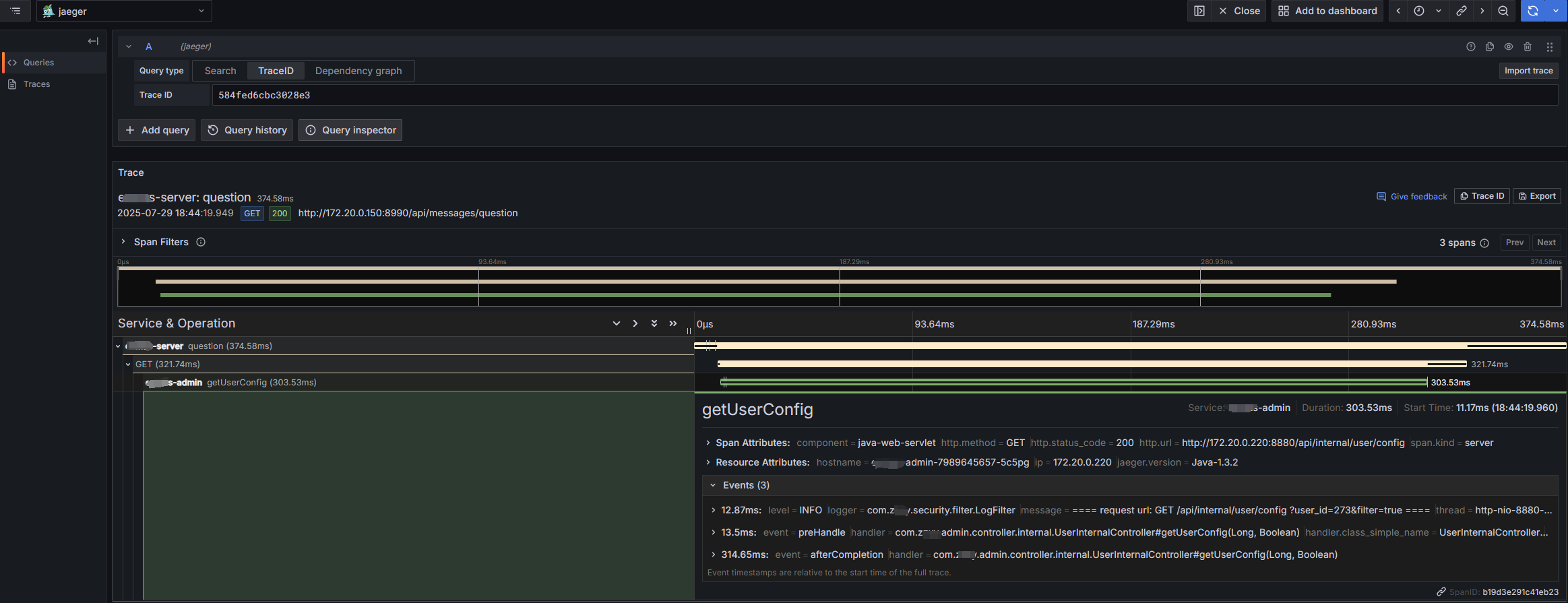
和Jaeger UI页面没啥差别啊。意义和价值呢?
再来看看Prometheus重新,在Grafana上查看,颜值高一些,以上面提到的go_gc_duration_seconds指标为例:
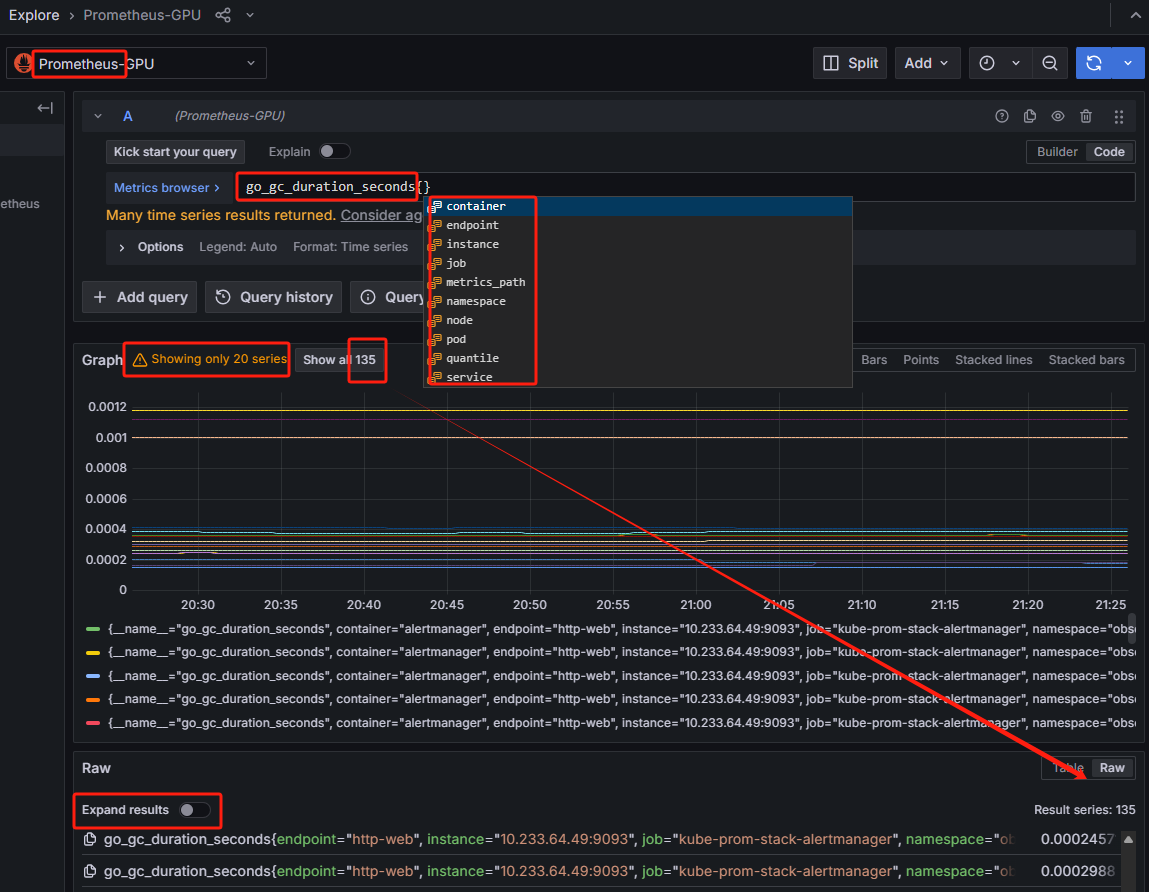
Expand results效果如下:
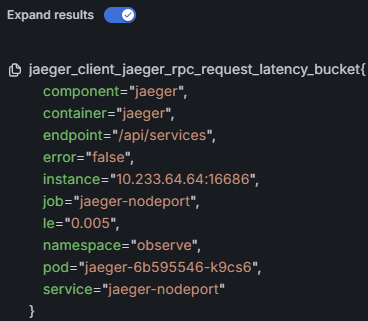
怎么用起来呢?
问题
遗留不少问题:
JDBC
一个请求从前端到服务A,请求打到服务B,势必有SQL(或JDBC)执行过程,但是链路追踪里根本看不到任何JDBC信息,只有Redis:
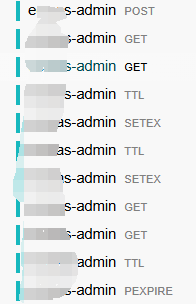
Java服务,使用的依赖及版本:opentracing-spring-cloud-redis-starter版本是0.5.3,opentracing-spring-cloud-jdbc-starter也是0.5.3,但是上图只有Redis操作,没有JDBC Span信息。
版本
升级OpenTelemetry
副本
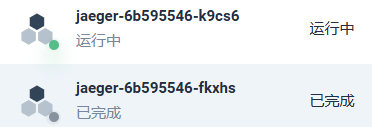
设置的副本数是1,KubeSphere看到两个pod,一个是进行中,另一个是已完成。
UI
Jaeger 2.x 版本的 UI 页面相比 1.x 版本在用户体验、性能、功能和可扩展性等方面都有显著改进。
- 用户界面改进
- 现代化设计:
- UI 风格:2.x 采用了更现代的设计语言,使界面更简洁、直观;
- 响应式布局:UI 更加适配不同分辨率和设备,提升了用户在移动设备上的使用体验。
- 交互优化
- 实时更新:跟踪信息可以实时刷新,用户无需手动刷新页面;
- 改进的搜索栏:搜索栏更直观,并支持更多筛选条件(如服务、标签、起止时间)。
- 现代化设计:
动态数据加载:Trace 列表和详情页面加载速度更快,避免页面卡顿。
- 性能提升
(1)更快的加载速度
数据请求优化:后台 API 查询效率提升,减少了 UI 与后端的通信延迟。
渐进式渲染:页面采用延迟加载技术,大型 Trace 数据可以分段加载。
(2)大规模 Trace 支持
对海量 Trace 数据的加载和显示进行了优化,支持更大的数据规模,特别是对于复杂的分布式系统。
- 功能增强
(1)增强的可视化
可定制化视图:2.x 支持自定义仪表盘,用户可以根据需求配置不同的视图。
更丰富的图表和指标:增加了服务调用的统计数据和热点图功能,帮助用户快速定位问题。
(2)高级搜索与过滤
新增支持复杂查询的语法,比如:
按标签搜索(e.g., error=true)。
支持正则表达式或范围搜索。
提供了预设时间范围选项(如过去 1 小时、过去 24 小时),无需手动输入时间。
(3)Trace 比较
新增了多个 Trace 的比较功能,用户可以直观地比较多个 Trace 的性能指标,例如延迟差异、调用次数等。
(4)错误和异常标记
Trace 详情页面中高亮显示错误和异常的节点,便于快速排查。
- 可扩展性改进
(1)插件支持
2.x 开始支持 UI 插件,可以通过插件扩展功能,例如添加自定义数据源或图表。
(2)前后端解耦
UI 前端和后端完全解耦,前端可以独立开发和部署。支持自定义 API 接口,适配更多场景。
- 开发与部署优化
(1)易于集成
提供了标准化的 API 文档和 UI 模块,使其更易与第三方工具(如 Prometheus、Grafana)集成。
(2)Docker 化前端
UI 前端组件可以单独作为 Docker 镜像部署,配置更加灵活。
- 多语言支持
UI 组件支持国际化,提供多种语言选项,方便全球用户使用。
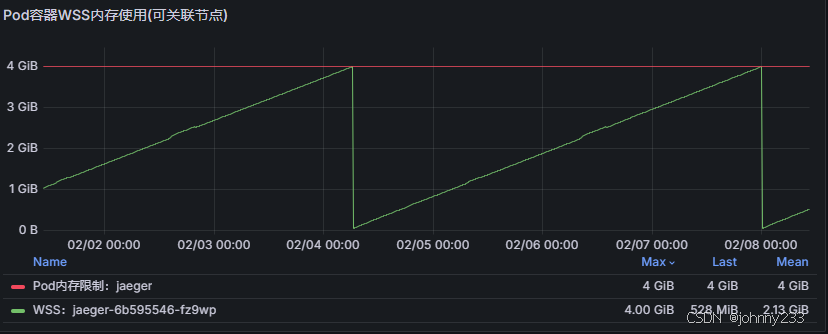
OOM
yaml
spec:
volumes:
containers:
- name: jaeger
image: 'harbor.tesla.com/middleware/jaegertracing/all-in-one:1.6.0'
resources:
limits:
cpu: '2'
memory: 4Gi
requests:
cpu: 10m
memory: 10Mi
imagePullPolicy: IfNotPresent
restartPolicy: Always咨询ChatGPT,给出如下几个排查方向:
- 升级Jaeger版本。
查看Docker Hub,确实很迷惑,不知道为啥使用这么低的版本

- 限制缓存 & 调整垃圾回收
Jaeger all-in-one 内部使用 BadgerDB 存储临时数据,可能会导致内存膨胀。 - 使用独立存储
12点实际上是0点!
重启时间:

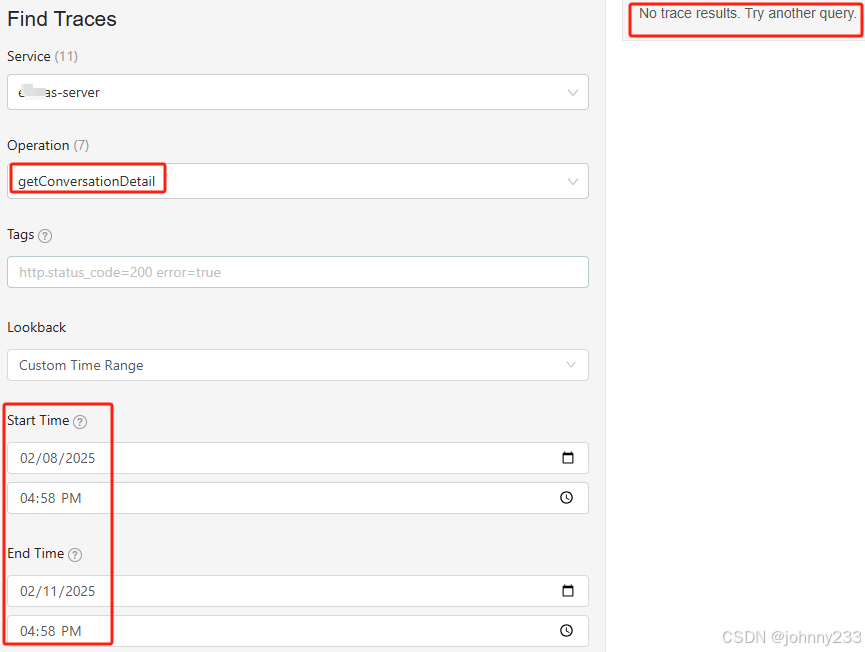
重启之前的Trace数据无法查询
重启之后的Trace数据可以查询:
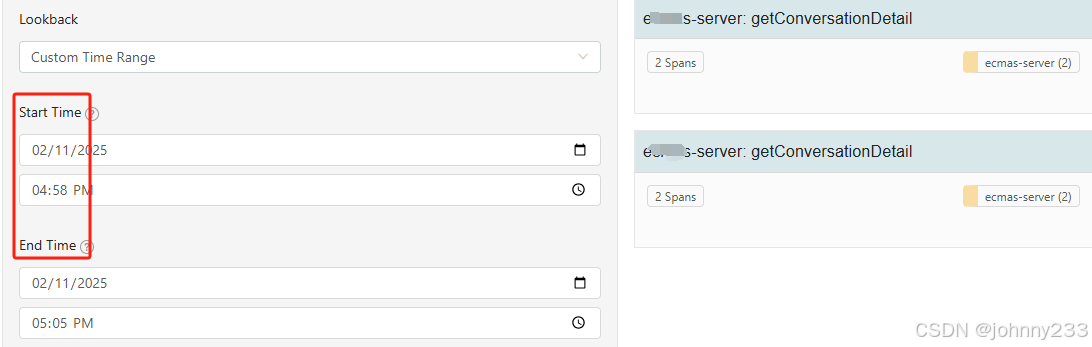
需要配置Trace数据外接到ES。