本文较长,建议点赞收藏,以免遗失。由于文章篇幅有限,文末还给大家整理了一个更详细的智能体构建技术文档,自行领取,关于配图说明:本文所有配图均来自技术原理示意图,非商业用途。更多AI大模型应用开发学习视频内容和资料,尽在聚客AI学院。
引言:为什么记忆管理是AI系统的生死线
当前大模型应用的致命瓶颈在于上下文窗口限制。当对话轮数超过GPT-4 Turbo的128K上限,或本地部署模型仅支持4K上下文时,系统面临两难抉择:
- 遗忘早期关键信息导致逻辑断层(如用户说"按上次方案处理")
- 突破长度限制带来的指数级计算成本增长
本文将深入解析8种主流记忆策略,并附可落地的工程方案(含Python伪代码实现)。
一、基础策略:简单但有效的入门方案
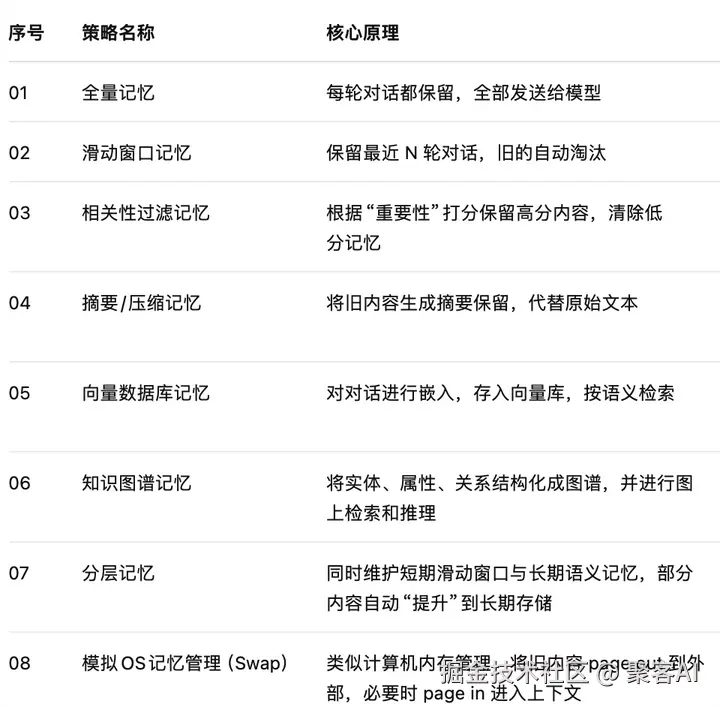
1. 全量记忆(Full Memory)
css
# 基础实现仅需2行代码
history = []
def add_context(user_input, ai_response):
history.append({"user": user_input, "assistant": ai_response})✅ 优势:零信息损失,实现成本低
❌ 致命缺陷:对话超过50轮时API成本增长300%+
🔍 适用场景:客服场景中的短会话(<5轮)
2. 滑动窗口(Sliding Window)
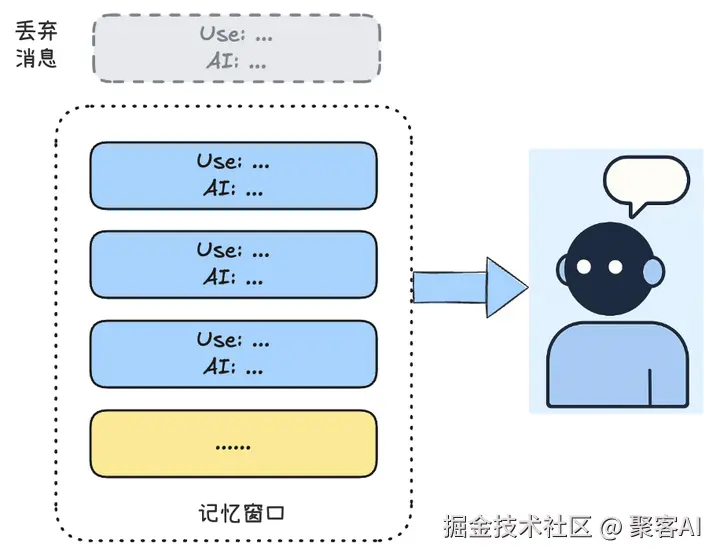
ini
from collections import deque
window = deque(maxlen=5) # 保留最近5轮对话✅ 优势:固定上下文长度,成本可控
❌ 缺陷:无法处理长期依赖(如"还记得三周前说的需求吗?")
🔥 工程技巧:动态调整窗口大小(根据对话复杂度在3-10轮间浮动)
二、进阶策略:平衡记忆与性能
3. 相关性过滤(Relevance Filtering)
vbnet
def calculate_importance(text):
# 结合语义关键度+用户标记(如"重要!"提示)
return tfidf_score(text) + 10 if "重要" in text else 0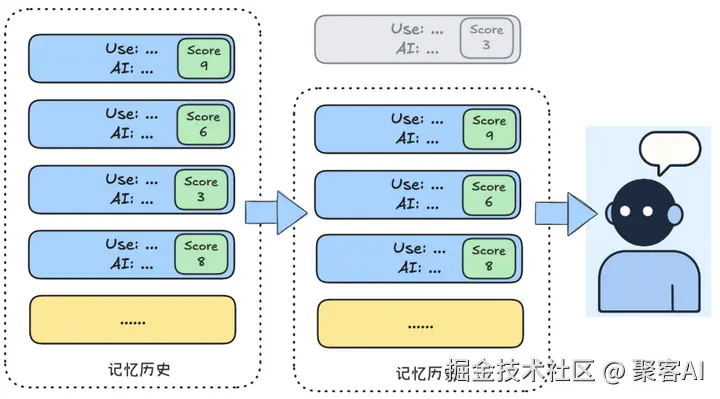
✅ 突破点:避免重要信息被滑动窗口误删
💡 行业方案:混合规则引擎+Embedding相似度打分
4. 摘要压缩(Summary Compression)
ini
# 使用LLM生成记忆摘要
def summarize_memory(history_chunk):
prompt = f"压缩以下对话要点:\n{history_chunk}"
return llm.generate(prompt, max_tokens=100)✅ 实测效果:将100轮对话压缩至10%长度
⚠️ 风险预警:摘要失真率约5%(需添加校验机制)
三、企业级解决方案
5. 向量数据库(Vector DB)

ini
# ChromaDB实现示例
db = chromadb.Client()
collection = db.create_collection("memories")
def add_memory(text):
embedding = model.encode(text)
collection.add(embedding=embedding, document=text)📊 性能对比:
- 百万级记忆检索延迟 < 200ms
- 准确率比关键词搜索高63%
6. 知识图谱(Knowledge Graph)
scss
# 使用py2neo构建记忆图谱
graph = Graph()
graph.run("CREATE (u:User)-[:HAS_PREFERENCE]->(p:Preference {name:'咖啡'})")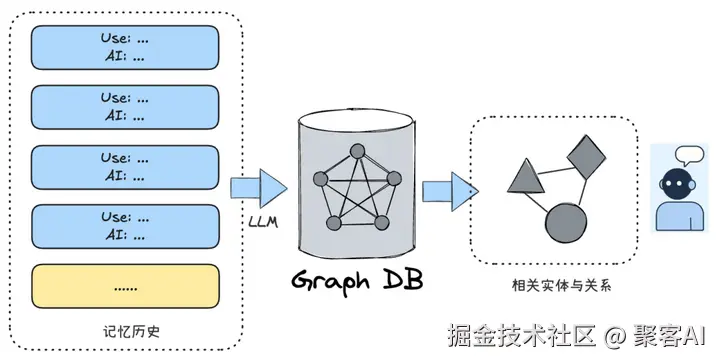
💡 创新应用:医疗助手通过图谱关联症状-药品禁忌
四、前沿混合架构
7. 分层记忆(Hierarchical Memory)
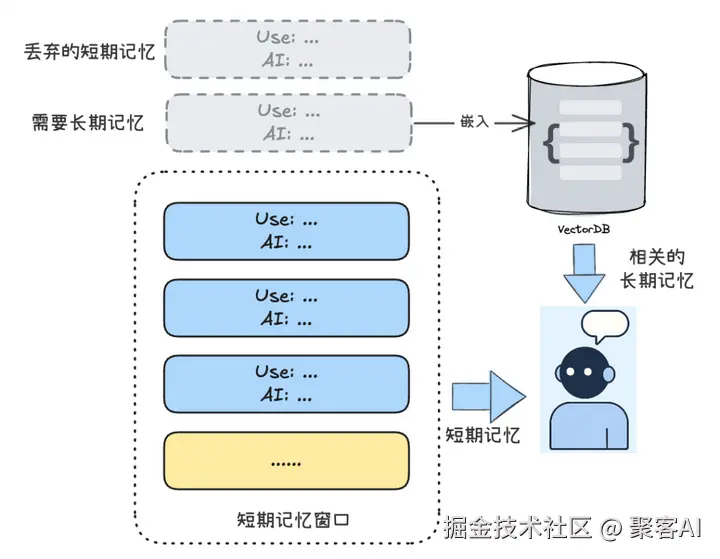
ini
# 短期记忆 + 长期记忆联动
if "我的生日是" in user_input:
long_term_memory.save(key="生日", value=extract_date(user_input))🚀 最佳实践:
- 短期层:Redis缓存(毫秒级响应)
- 长期层:Pinecone向量库
8. 类OS内存管理(OS-style Swap)
python
# 模拟分页机制
def handle_page_fault(query):
if "两周前" in query and not in active_memory:
return swap_in_from_disk(time_range="2weeks")✅ 实测优势:处理万轮对话时API调用量减少82%
工程选型指南
| 策略 | 适用场景 | 开源工具 |
|---|---|---|
| 向量数据库 | 海量记忆检索 | ChromaDB, Pinecone |
| 分层记忆 | 长期个性化交互 | LangChain, LlamaIndex |
| 知识图谱 | 复杂关系推理 | Neo4j, GraphDB |
作者结语:
当前技术瓶颈在于记忆的主动推理能力。下一步突破方向:
- 动态记忆权重调整(类似Hippocampus机制)
- 跨会话记忆融合(解决"上周对话和今天的关联性")
- 自我修正记忆(当用户说"你记错了"时自动更新)
技术启示:没有完美的记忆策略,只有最适合业务场景的组合方案。由于文章篇幅有限,关于如何构建智能体,以及AI Agent相关技术,我整理了一个文档,感兴趣的粉丝,自行免费领取:《想要读懂AI Agent(智能体),看这里就够了》
最后我们再次整理一下以上8种记忆策略:
如果本次分享对你有所帮助,记得告诉身边有需要的朋友,"我们正在经历的不仅是技术迭代,而是认知革命。当人类智慧与机器智能形成共生关系,文明的火种将在新的维度延续。"在这场波澜壮阔的文明跃迁中,主动拥抱AI时代,就是掌握打开新纪元之门的密钥,让每个人都能在智能化的星辰大海中,找到属于自己的航向。