目录
[编辑2.1 kafka 生产者框架](#编辑2.1 kafka 生产者框架)
[2.1.1 生产者在生活中的实例](#2.1.1 生产者在生活中的实例)
[2.1.2 kafka生产者流程及框架](#2.1.2 kafka生产者流程及框架)
[1. 主线程处理阶段](#1. 主线程处理阶段)
[2. Sender线程处理阶段](#2. Sender线程处理阶段)
[2.2 kafka 生产者框架中的一些关键参数](#2.2 kafka 生产者框架中的一些关键参数)
[2.3 kafka 生产者框架中一些关键问题](#2.3 kafka 生产者框架中一些关键问题)
[2.3.1 kafka如何对消息进行统一处理呢](#2.3.1 kafka如何对消息进行统一处理呢)
[2.3.2 kafka如何知道发送给哪个分区呢,有哪些分区分配策略?如何发送消息到固定分区?](#2.3.2 kafka如何知道发送给哪个分区呢,有哪些分区分配策略?如何发送消息到固定分区?)
[2.3.3 主要用到的序列化方式](#2.3.3 主要用到的序列化方式)
[2.3.4 如何保证消息发送的一致性、ack如何设置?](#2.3.4 如何保证消息发送的一致性、ack如何设置?)
[2.3.5 如何保证消息发送的幂等性](#2.3.5 如何保证消息发送的幂等性)
[2.3.6 kafka发送的retry机制](#2.3.6 kafka发送的retry机制)
[2.3.7 如果发送的消息比较大怎么办呢](#2.3.7 如果发送的消息比较大怎么办呢)
[1. 处理超过batch size的消息(默认16KB)](#1. 处理超过batch size的消息(默认16KB))
[2. 处理超过max.request.size的消息(默认1MB)](#2. 处理超过max.request.size的消息(默认1MB))
[3. 处理非常大的消息(如10MB或更大)](#3. 处理非常大的消息(如10MB或更大))
一、我与kafka的缘分-初识Kafka
在车联网平台的实际应用中,我们采用 Kafka 作为核心消息中间件实现系统解耦,主要处理车辆 T-Box 设备上报的报文数据。当前平台已接入 30 万辆车辆,以每10秒 1 包的频率持续上传数据。按此规模计算:
- 单日数据量:单天的数据量在2.8亿条
- 车辆在线率: 30%-40%
选择 Kafka 主要基于两个关键考量:
- 海量数据承载能力:其分布式架构与零拷贝机制可稳定支撑 500000 量级/秒的写入吞吐
- 业务容错特性:车辆数据场景允许部分消息丢失(如网络闪断),而 Kafka 的异步刷盘机制在保证吞吐的同时,恰能满足该容忍度
通过 Kafka 的缓冲削峰,我们有效隔离了数据生产端(车辆上行)与消费端(业务处理系统)。此前虽已实际应用,但尚未深入技术原理。现借此机会,我们梳理一下kafka。
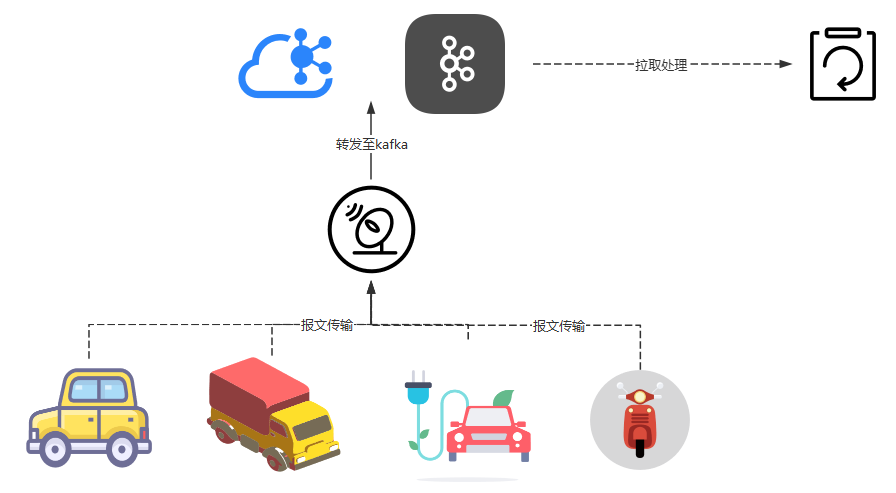 使用场景
使用场景
二、Kafka深入探讨-了解kafka
当谈到Apache Kafka时,我认为它就是一个高性能的分布式数据流平台,类似于一个超级大的临时流转的存储仓库,能够高效处理海量实时流转数据。不过,它有两个核心特点:
第一:数据通过生产者"前门进",通过消费者"后门出",形成连续的数据管道;
第二:由于分布式系统的特性,数据在极端情况下可能会丢失(例如,在故障或配置不当的场景)。
因此,对于需要强数据一致性的应用场景(如金融交易或实时记账系统),Kafka 往往不太合适,因为它更侧重于高吞吐量和最终一致性。
 2.1 kafka 生产者框架
2.1 kafka 生产者框架
2.1.1 生产者在生活中的实例
想象一下,Kafka的发送者就像是一个送货员,他的任务很简单:把货物(消息)送到指定地方就行。但如果您是负责设计整个送货系统的"老板",就不能只盯着送货员的工作了------您得操心整个链条的细节,确保一切高效可靠。这涉及到一系列关键问题:
-
货物要送给谁?
就像送货前得知道收货地址一样,您需要确定消息具体要发给哪些人或系统。
-
运输方式怎么选?
是用小车(高效工具)快速送,还是自己走路(慢速方式)慢慢送?这会影响送货速度和成本。
-
货物需要整理或压缩吗?
如果用小车送,是不是得把货物打包整齐?或者压缩一下,节省空间,让一次能送更多货?
-
怎么确保货物送到仓库?
万一路上出问题,比如车子坏了,如何保证货物最终安全到达?需要什么保险措施?
-
怎么避免一个货物送两次?
如何确保每个货物只送一次,不会重复发送,造成混乱或浪费?
-
送货前要检查货物吗?
是否需要先过滤危险品(如有害数据),确保只送安全、有用的货物?
-
送货路径怎么安排?
是直接送到最终目的地(总部),还是先送到中转站(配送点),再转交过去
作为系统设计者,您得像一个精明的老板一样,从全局角度思考这些细节,而不是只关注送货员本身的动作。那么kafka其实就是一个精明的老板,所有的这些细节都考虑到位了,那么我们可以看一下kafka得"送货系统"是如何设计的呢?
2.1.2 kafka生产者流程及框架
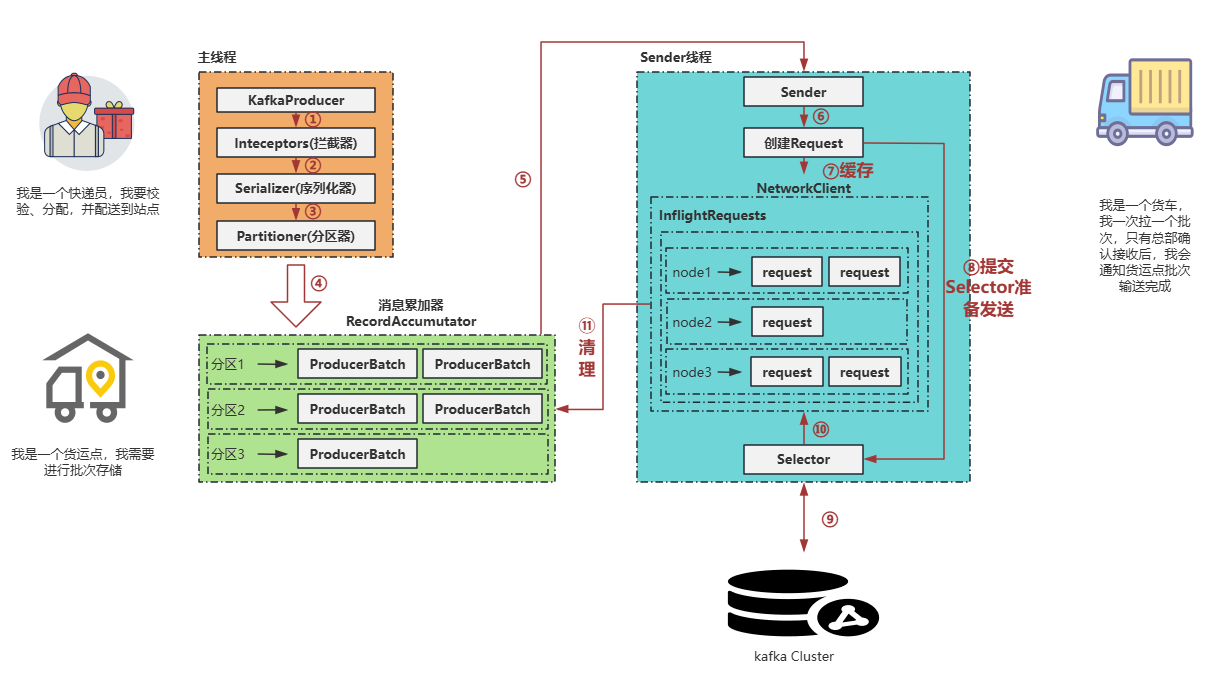 kafka发送架构
kafka发送架构
在Kafka生产者中,消息发送过程由两条线程协同完成:主线程 负责消息的预处理和暂存,Sender线程负责消息的发送。这种设计通过批量处理机制(称为消息批次)显著提高了吞吐量和效率。以下是详细流程:
1. 主线程处理阶段
- 消息初始化 :主线程生成消息后,首先通过消息拦截器进行转换(例如,添加元数据或过滤)。
- 序列化 :转换后的消息必须经过序列化(将对象转换为字节流),以满足网络传输要求。
- 分区选择 :序列化后的消息通过分区器确定目标分区(主题是逻辑概念,实际数据存储在分区中)。分区器基于键或策略选择合适的分区。
- 批次积累 :消息进入消息累加器 等待,与其他消息组合成批次。这种批量机制减少了网络开销,提升整体吞吐量。
2. Sender线程处理阶段
- 批次提取:当批次就绪(例如,达到大小或时间阈值),Sender线程从消息累加器中提取完整批次。
- 请求封装 :提取的批次被封装成Request对象 ,并通过NetworkClient进行排队和传输。
- 发送执行:NetworkClient将请求发送到Kafka集群,确保可靠性和效率。
设计优势总结
这种线程分离设计(主线程处理本地逻辑,Sender线程处理网络I/O)避免了阻塞,并利用批次机制优化资源使用。消息批次是Kafka高吞吐的核心,它通过减少小消息的单独发送,降低了延迟并提升了集群性能。
2.2 kafka 生产者框架中的一些关键参数
| 参数名称 | 描述 |
|---|---|
| key.serializer 和 value.serializer | 指定发送消息的 key 和 value 的序列化类型。必须使用全类名。 |
| buffer.memory | RecordAccumulator 缓冲区总大小,默认值为 32m。 |
| batch.size | 缓冲区一批数据最大值,默认值为 16k。适当增加该值可提高吞吐量,但设置过大可能导致数据传输延迟增加。 |
| linger.ms | 如果数据未达到 batch.size,sender 在等待该时间后发送数据。单位为 ms,默认值 0ms(无延迟)。生产环境建议设置为 5-100ms。 |
| acks | 应答机制:0-生产者发送数据后不需落盘应答;1-Leader 收到数据后应答;-1(all)-Leader 和 isr 队列所有节点收齐数据后应答。默认值 -1,等价于 all。 |
| max.in.flight.requests.per.connection | 允许最多未返回 ack 的次数,默认为 5。开启幂等性时,该值需在 1-5 范围内。 |
| retries | 消息发送错误时系统重发次数,默认值为 int 最大值(2147483647)。若需保证消息有序性,需设置 max.in.flight.requests.per.connection=1,否则重试失败消息时其他消息可能已发送成功。 |
| retry.backoff.ms | 两次重试之间的时间间隔,默认值为 100ms。 |
| enable.idempotence | 是否开启幂等性,默认值为 true(开启)。 |
| compression.type | 生产者发送数据的压缩方式,默认值为 none(不压缩)。支持类型:none、gzip、snappy、lz4 和 zstd。 |
2.3 kafka 生产者框架中一些关键问题
2.3.1 kafka如何对消息进行统一处理呢
通过 kafka 生产者的拦截器进行消息的转化处理。一般我不会使用,毕竟消息都是处理好发送的,没必要在拦截一层在进行处理。

KafkaProducer在将消息序列化和计算分区之前会调用生产者拦截器的onSend()方法来对消息进行相应的定制化操作。一般来说最好不要修改消息 ProducerRecord 的 topic、key 和partition 等信息,如果要修改,则需确保对其有准确的判断,否则会与预想的效果出现偏差。比如修改key不仅会影响分区的计算,同样会影响broker端日志压缩(Log Compaction)的功能。
KafkaProducer 会在消息被应答(Acknowledgement)之前或消息发送失败时调用生产者拦截器的 onAcknowledgement()方法,优先于用户设定的 Callback 之前执行。这个方法运行在Producer 的 I/O 线程中,所以这个方法中实现的代码逻辑越简单越好,否则会影响消息的发送速度。
close()方法主要用于在关闭拦截器时执行一些资源的清理工作。
2.3.2 kafka如何知道发送给哪个分区呢,有哪些分区分配策略?如何发送消息到固定分区?
在Kafka中,组装ProducerRecord消息时,可以通过判断消息的key或value来显式指定分区号。这种方式在技术上可行,但不推荐,因为它会将分区选择逻辑与消息组装过程耦合,导致代码可维护性降低。例如,业务逻辑变更可能直接影响分区策略,增加系统复杂度。
- 未指定分区号时的默认行为,如果未显式指定分区号(例如:
ProducerRecord record = new ProducerRecord("test-topic", "key-" + i, s);),Kafka会使用默认的DefaultPartitioner分区器:
2.如果我们在进行消息组装的时候,指定了分区号(例如:**ProducerRecord record = new ProducerRecord("test-topic",1,"key-" + i,s),**那么,kafka就不会使用分区器。
常见的Kafka生产者分区策略总结
-
默认分区策略(Default Partition Strategy)
- 基于消息的key决定分区:如果key不为null,则使用key的哈希值(例如,通过哈希函数计算分区索引);如果key为null,则自动切换到轮询策略。
- 优点:简单高效,适用于大多数场景,能保证相同key的消息分配到同一分区以实现有序性。
- 缺点:当key分布不均匀时,可能导致分区负载不均衡。
-
轮询策略(Round-Robin Partition Strategy)
- 当消息key为null时,生产者自动使用此策略:消息依次循环发送到所有可用分区(例如,分区0、1、2...然后重复)。
- 优点:确保消息均匀分布,避免单个分区过载;适用于无key或低顺序要求的场景。
- 缺点:不保证相同key的消息顺序性,可能影响某些应用的一致性需求。
-
自定义分区器(Custom Partitioner)
- 用户可通过实现
Partitioner接口(如Java中的org.apache.kafka.clients.producer.Partitioner)自定义逻辑,基于消息key、value或其他属性(如时间戳或业务ID)计算分区。 - 优点:高度灵活,能适配复杂需求(如根据地理区域或用户ID分区);支持集成外部系统。
- 缺点:需要额外开发,可能引入性能开销;需确保逻辑正确以避免分区热点。
- 用户可通过实现
-
一致性哈希分区(Consistent Hashing)
- 非Kafka原生支持,但可通过自定义分区器实现:使用一致性哈希算法(例如,基于虚拟节点)在多个维度(如多个key或属性)上均匀分布数据,减少分区重平衡时的数据迁移。
- 优点:提升扩展性和容错性,特别适合动态集群环境;能平衡负载并减少"热点"问题。
- 缺点:实现复杂,需自定义开发;哈希计算可能增加延迟。
2.3.3 主要用到的序列化方式
我们公司这边对key和value都采用String序列化方式。对于复杂的对象,我们一般使用json转化包将我们复杂的对象转化成 json字符串,然后就可以使用我们的String的序列化方式了
2.3.4 如何保证消息发送的一致性、ack如何设置?
第一、ack的设置
Kafka的acks参数是生产者端的配置,用于控制消息副本的写入确认级别。它影响消息的持久性和系统吞吐量,具体分为三个级别:
- acks = 0 :生产者不等待任何服务器确认。这提供了最高吞吐量(延迟最低),但安全性最低。如果服务器故障,消息可能丢失。适用场景包括:
- 网站点击量统计
- 页面停留时间记录
- 视频播放量追踪(这些场景容忍少量数据丢失)
- acks = 1 :默认设置。生产者等待首领节点(Leader)确认写入成功即可。相比
acks=0,吞吐量略有下降,但可靠性提高(首领节点故障时可能丢失消息)。适合大多数实时数据处理,如用户行为分析。 - acks = all (或acks = -1 ):生产者等待所有副本节点(包括ISR列表)都确认写入成功。这提供最高可靠性(消息几乎不会丢失),但吞吐量最低、延迟最高。适用场景包括:
- 金融交易记录
- 关键事件审计(如支付确认)
第二、确保消息发送
三种消息发送确认机制的优劣比较:
| 机制类型 | 吞吐量 | 可靠性 | 实时反馈 | 资源消耗 | 适用场景 |
|---|---|---|---|---|---|
| 消息拦截器 (onAcknowledgement方法) | 低 | 高 | 实时 | 高 | 需要每条消息精确追踪的场景 |
| 同步发送(Future.get) | 低 | 高 | 实时 | 中 | 强一致性要求的低频场景 |
| 异步回调(Callback) | 高 | 高 | 异步 | 低 | 高吞吐量要求的业务场景 |
采用第三种方式往往可以具备高吞吐,推荐
java
import org.apache.kafka.clients.producer.*;
import java.util.Properties;
public class KafkaProducerOptimized {
public static void main(String[] args) {
// 1. 配置Producer属性
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("batch.size", 16384); // 批量大小,单位字节,优化吞吐量
props.put("linger.ms", 5); // 发送延迟,允许批量累积,提高吞吐
// 2. 创建Producer实例
try (Producer<String, String> producer = new KafkaProducer<>(props)) {
// 3. 发送消息,并添加Callback
for (int i = 0; i < 10; i++) { // 示例:发送多条消息
ProducerRecord<String, String> record = new ProducerRecord<>("your-topic", "key-" + i, "value-" + i);
producer.send(record, new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
if (exception instanceof RetriableException) {
// 可重试异常
} else {
// 不可重试异常,记录并放弃
}
}
}
});
}
} catch (Exception e) {
// 全局异常处理
System.err.println("Producer异常: " + e.getMessage());
}
}
}选择建议与权衡
没有固定"最佳"设置,需根据业务需求平衡性能和安全性:
- 性能优先 :选择
acks=0,适用于高吞吐、低延迟场景(如监控数据)。 - 可靠性优先 :选择
acks=all(Kafka),适用于数据一致性要求高的系统(如库存管理)。 - 一般场景 :
acks=1(Kafka)是良好折衷,兼顾效率和基本可靠性。
2.3.5 如何保证消息发送的幂等性
在分布式系统中,使用 Apache Kafka 进行消息传递时,保证消息发送的幂等性至关重要。幂等性确保无论操作执行多少次(例如,由于网络重试或故障恢复),消息处理结果都不会改变,从而避免数据重复和不一致。Kafka 通过以下核心机制实现这一目标:
-
生产者配置:
- 启用幂等性:设置
enable.idempotence=true,生产者会为每个消息分配一个唯一的 PID(生产者 ID)和一个单调递增的序列号(例如,序列号从 0 开始递增)。这样,Kafka broker 可以识别并丢弃重复消息。 - 确认模式:推荐设置
acks=all,确保生产者收到所有副本的确认,提升可靠性。这与幂等性结合使用,能有效处理网络问题导致的重发。
- 启用幂等性:设置
-
序列号和 PID 管理:
- 每个生产者实例分配一个唯一 PID,每个消息附带一个序列号。Kafka broker 基于 PID 和序列号检查消息是否重复,如果序列号不连续或重复,则拒绝处理。
-
存储机制:
- Kafka 的日志存储设计(如分区日志文件)持久化消息状态。通过记录序列号和 PID,即使在 broker 故障恢复后,也能从日志中恢复并避免重复处理。
-
事务支持:
- 事务本身不直接提供幂等性,但可与幂等性结合使用(例如,设置
enable.idempotence=true并开启事务)。这确保了跨分区操作的原子性和一致性,适用于复杂场景(如多消息事务提交)。
- 事务本身不直接提供幂等性,但可与幂等性结合使用(例如,设置
-
客户端库支持:
- 使用最新 Kafka 客户端库(如 Kafka Java 客户端),确保实现无缺陷。早期版本可能不支持某些功能,因此升级库版本是必要的最佳实践。
示例配置建议
java
enable.idempotence=true # 启用幂等性
acks=all # 确保所有副本确认
retries=2147483647 # 设置高重试次数(接近最大值),配合幂等性处理网络重试注意事项:幂等性仅针对单个生产者实例的单个分区有效。如果涉及多分区或复杂事务,需额外配置事务管理。实际部署中,测试重试场景以验证配置可靠性。2.3.6 kafka发送的retry机制
一般情况下 我们这边没有使用过kafka自己的retry机制,我们通过kafka的callback机制对发送失败的消息进行监听,然后再次进行发送(失败的消息保存到db中,日志中)
如果使用retry可以通过retries 参数控制重试的次数 ,通过retry.backoff.ms 控制重试次数之间的时间间隔。间隔是500ms ,之所以设置为500ms,kafka中topic分区的副本首领选举的整个过程是500ms以内完成的。
kafka的retry这机制,不是每次都retry的,如果收到了这样的error:
消息大小超过了request.max.size 或者超过了message.max.bytes 类似这样的错误,kafka是不会选择重试的 ,因为这种错误是无法通过重试而成功的。
如果是因为网络延迟、网络抖动啊、分区的一系列暂时不可用啊,这种错误kafka认为有可能在重试的过程中成功。
2.3.7 如果发送的消息比较大怎么办呢
我们这边消息在1MB以下,Kafka的设计初衷是处理高吞吐量的小消息,对于大消息(如超过16KB或1MB)存在性能瓶颈,需要针对性调整参数或采用替代方案。以下是分步优化建议:
1. 处理超过batch size的消息(默认16KB)
- Kafka的batch size默认为16KB。如果单个消息超过16KB,消息累加器会直接发送该消息,而不是将其拆分成多个batch组装。这避免了消息分割的开销,但引入了内存性能问题:
- 对于小于或等于16KB的消息,Kafka复用
java.io.ByteBuffer(一个固定大小的缓冲区),减少了内存申请和GC压力。 - 对于大于16KB的消息,Kafka无法复用ByteBuffer,每次都需要申请新内存空间(大小等于消息本身)。这会导致频繁的内存分配和垃圾回收,影响性能(如吞吐量下降、延迟增加)。
- 对于小于或等于16KB的消息,Kafka复用
- 优化建议 :适当调大batch size(例如调整为32KB或64KB),通过生产者配置参数
batch.size设置。这可以增加消息复用的概率,减少内存开辟开销。但需注意,batch size过大可能增加延迟(等待更多消息填充batch),需根据业务场景平衡。
2. 处理超过max.request.size的消息(默认1MB)
- Kafka生产者参数
max.request.size限制单条消息最大大小(默认1MB)。如果消息超过此限制(如2MB),仅调整该参数不够,还需协调broker和消费者配置:- 生产者端 :将
max.request.size调整为2MB(或更大),确保生产者能发送大消息。 - Broker端 :Broker通过
message.max.bytes参数控制接收的最大消息大小(默认1MB)。需将其至少调整为2MB,以匹配生产者设置。否则,broker会拒绝过大消息。 - 消费者端 :消费者通过
fetch.max.bytes参数控制每次拉取的最大消息大小(默认1MB)。需将其至少调整为2MB,确保消费者能接收和处理大消息。 - 经验策略 :设置参数时,遵循
max.request.size<message.max.bytes<fetch.max.bytes(例如,生产者2MB、broker 2.1MB、消费者2.2MB)。这避免因参数不一致导致消息拒绝或失败。调整后,重启Kafka集群生效。
- 生产者端 :将
3. 处理非常大的消息(如10MB或更大)
- Kafka不适合处理超大消息(如10MB以上),因为:
- 内存开销大:每次发送都需要申请新空间,增加GC压力。
- 网络和存储瓶颈:大消息传输慢,可能阻塞broker线程,影响整体吞吐量。
- 设计局限:Kafka优化于小消息流式处理,大消息会破坏其性能优势。
- 替代方案 :优先考虑非Kafka组件,如:
- 使用文件传输协议(如SFTP、HTTP)或网络附加存储(NAS)传输大文件。
- 将大消息存储在对象存储(如S3),然后通过Kafka发送文件引用(如URL)。
- 如果必须使用Kafka的优化策略 :
- 策略1:消息拆分与顺序保证
- 将大消息拆分成多个小消息(每个小于batch size或max.request.size)。
- 生产者指定所有小消息发送到同一分区(使用相同key),并采用单线程发送,确保消息顺序(如先发消息头,再发消息体)。
- 消费者端按顺序接收并组装小消息还原为大消息。这需要应用层逻辑支持,但能避免Kafka大消息的性能问题。
- 策略2:消息压缩
- 启用生产者压缩,通过参数
compression.type设置压缩算法(如snappy、gzip或lz4)。压缩可减少消息大小(例如,gzip压缩率可达70%),降低网络和内存开销。 - 示例:设置
compression.type=gzip,生产者自动压缩消息,消费者自动解压。但需注意,压缩会增加CPU开销,需测试性能影响。
- 启用生产者压缩,通过参数
- 策略1:消息拆分与顺序保证
整体优化建议总结
- 预防为主:在业务设计阶段,避免发送大消息(如超过1MB)。优先拆分或压缩消息。
- 参数调优 :
- 调大
batch.size(如32KB)以优化内存复用。 - 对大消息(>1MB),协调调整
max.request.size、message.max.bytes和fetch.max.bytes,确保三者匹配且略递增。 - 监控Kafka性能(如使用JMX或Kafka监控工具),根据指标调整参数。
- 调大
- 性能权衡:调大参数可能增加内存使用和延迟,测试环境验证后再上线。
- 大消息处理原则:对于>10MB消息,强烈建议使用替代方案。如果必须用Kafka,结合拆分和压缩策略。
通过以上优化,可缓解Kafka大消息的性能问题,但核心是控制消息大小在合理范围内(如<1MB),以发挥Kafka的高吞吐优势。