AutoMQ 与云器达成生态合作:实时数据架构成本直降 60%!

AutoMQ 与 云器正式达成生态战略合作!
在实时数据成为企业决策核心资产的今天,如何以更低的成本、更高的性能和更简单的架构实现海量数据的实时处理,成为摆在企业面前的重要课题。为应对这一挑战,AutoMQ 与云器 正式达成战略合作,共同发布全新的 Lakehouse 实时数据解决方案。此次合作将重塑从数据采集到分析洞察的整个链路,助力企业实现真正的全域数据实时价值释放。
关于「AutoMQ」
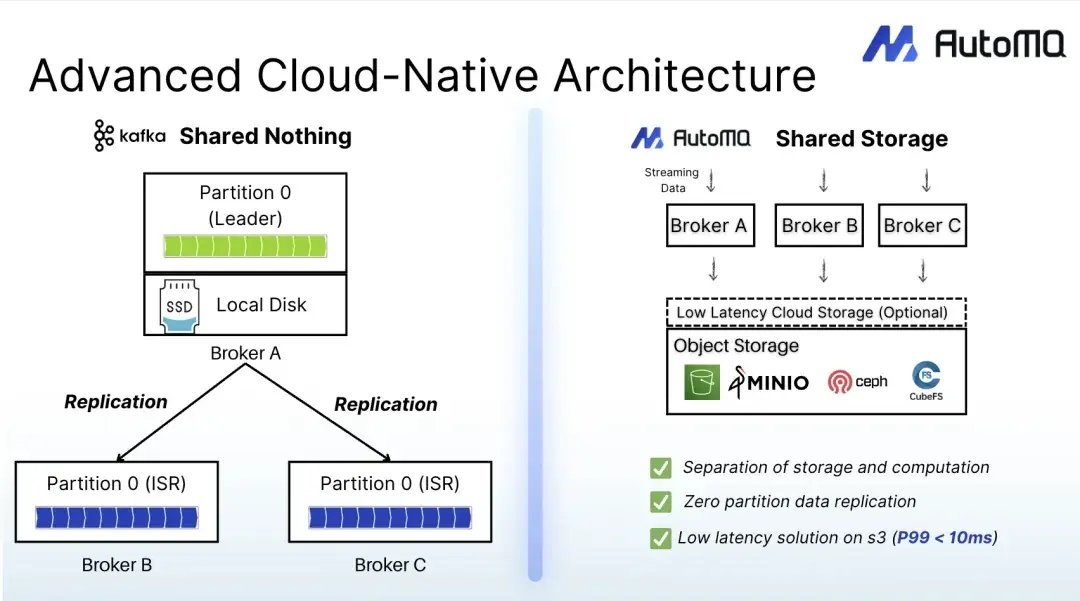
AutoMQ 是一个完全兼容 Apache Kafka 协议的开源流数据平台,致力于解决传统 Kafka 在云环境中面临的高运维、高成本与扩展受限问题。保持和 Apache Kafka 100%兼容前提下,AutoMQ 可以为用户提供高达 10 倍的成本优势以及百倍的弹性优势,同时支持秒级分区迁移和流量自动重平衡,解决运维痛点。
与传统 Kafka 实现不同,AutoMQ 采用存储与计算解耦架构,底层使用对象存储(如 Amazon S3、阿里 OSS)替代本地磁盘,具备天然的弹性扩展能力和显著的成本优势。企业可以通过 AutoMQ 轻松处理每秒千万级别的高并发数据写入,实现跨云部署、自动伸缩,并大幅简化流处理链路的管理与维护。
关于 「云器」
云器科技 是新一代计算模型"通用增量计算"的提出者与原创研发团队,总部位于杭州,是国家高新技术企业,入选工信部信通院"大数据星河奖"优秀企业
云器 Lakehouse 是由云器科技完全自主研发的新一代云湖仓。使用增量计算的数据计算引擎,性能可以提升至传统开源架构例如 Spark 的 10 倍 ,实现了海量数据的全链路-低成本-实时化 处理,为 AI 创新提供了支持全类型数据整合、存储与计算的平台,帮助企业从传统的开源 Spark 体系升级到 AI 时代的数据基础设施。
此次 AutoMQ 与云器的战略合作,不仅整合了实时流处理与湖仓一体化的技术优势,更为客户提供了从数据采集到分析的全链路云原生解决方案,有效提升数据处理效率、降低基础设施成本,并保障业务在高并发场景下的稳定性与弹性,帮助企业实现更快速的业务响应和更深入的数据洞察,推动数字化转型迈向新高度。
AutoMQ × 云器:打造企业级 Kafka 云原生最佳实践
此次 AutoMQ 与云器达成的生态战略合作,聚焦于企业数据基础设施升级过程中广泛存在的痛点,尤其是在 Kafka 与传统数仓结合方案中暴露出的性能与架构瓶颈。
面对高成本、高延迟和低灵活性等难题,越来越多企业在构建实时数据架构时感受到传统方案的局限性。Kafka 集群常年运行在高资源配置下,消息积压频发,业务实时性受限;传统数据仓库链路长、计算周期慢,难以支撑分钟级的运营监控或算法迭代。此外,在数据驱动越来越成为业务核心的当下,企业也亟需具备支持快速试验、快速上线的分析能力,而这恰恰是传统方案的短板。
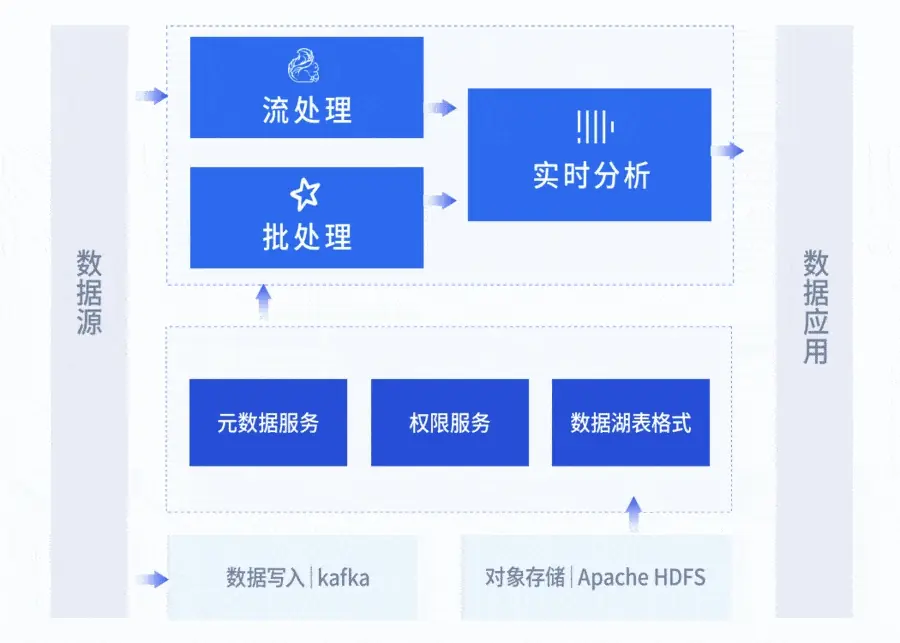
为此,AutoMQ 和云器联合提出一套覆盖采集、传输、存储与分析全流程的流式数据解决方案。在数据接入端,AutoMQ 以 Kafka 协议兼容的方式无缝替代原有 Kafka,降低消息链路的运维与成本负担;在存储与处理层,云器 Lakehouse 通过 LH Pipe 实现流数据实时入湖,并借助增量计算引擎构建分钟级更新的分析体系,使企业能够在数据到达的数分钟内完成加工与分析。

这一方案无需重构原有接入系统,架构上则摆脱了传统 Lambda 设计的冗余和延迟问题,构建起真正意义上的实时数据平台。AutoMQ 的无状态架构和云对象存储引擎,配合云器 Lakehouse 的增量处理能力,不仅降低了基础设施成本,还极大提升了数据处理的响应速度和分析灵活性。
双方合作将带来多重效果:
-
性能跃迁:数据链路延迟从 T+1 降低至分钟级,支持更高频的数据刷新与决策;
-
成本优化:AutoMQ 实现消息系统降本 50%+ ,Lakehouse 提升资源利用率,整体成本下降最高可达 60%;
-
架构简化:统一的存算平台消除系统割裂,极大减少运维开销和数据工程复杂度;
-
业务敏捷性提升:支持更多实时实验、反馈与迭代,为推荐、广告、风控等场景提供强力支持。
企业现在可以更低的成本处理海量实时数据,更敏捷地响应业务变化。无论是实时风控、智能运维还是个性化推荐,都能获得前所未有的时效性支持。
合作与未来
本次 AutoMQ 与云器的合作,标志着双方在实时数据与 Lakehouse 架构领域的深度融合,携手打造极致性能与极致成本优化的新标准。AutoMQ 与云器双方在降本方面持续深耕,不断追求更高的经济效益,致力于为用户带来更加便捷、高效的使用体验。
作为合作的核心,AutoMQ 依托创新的云原生架构和对象存储技术,实现了显著的成本优化,不仅通过对象存储大幅降低存储费用,还采用单副本高可用设计节省了大量数据复制流量,同时结合云端 Spot 实例与弹性伸缩策略,有效降低计算资源开销。这些降本举措极大提升了整体系统的经济效益与可持续性,助力企业构建高性能、低成本的实时数据平台。查看下方"往期推荐"了解 AutoMQ 完整的降本方案,探索更多创新实践与经济价值。