Spring Cloud Eureka 是 Netflix 开发的服务发现组件,它使得微服务架构中的服务能够彼此发现并通信。
简单使用示例
创建 Eureka Server
在 pom.xml 中添加依赖:
xml
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-server</artifactId>
</dependency>在 Spring Boot 主应用类上添加 @EnableEurekaServer 注解来启用 Eureka 服务器功能:
java
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.netflix.eureka.server.EnableEurekaServer;
@SpringBootApplication
@EnableEurekaServer
public class EurekaServerApplication {
public static void main(String[] args) {
SpringApplication.run(EurekaServerApplication.class, args);
}
}在 application.yml 或 application.properties 中配置 Eureka 服务器:
yaml
server:
port: 8761
eureka:
client:
register-with-eureka: false # 不注册自己
fetch-registry: false # 不拉取注册表创建 Eureka Client
在 pom.xml 文件添加依赖:
xml
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>在 Spring Boot 主应用类上添加 @EnableEurekaClient 注解来启用 Eureka 客户端功能:
java
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.netflix.eureka.EnableEurekaClient;
@SpringBootApplication
@EnableEurekaClient
public class EurekaClientApplication {
public static void main(String[] args) {
SpringApplication.run(EurekaClientApplication.class, args);
}
}在 application.yml 或 application.properties 中配置客户端:
yaml
spring:
application:
name: eureka-client
eureka:
client:
serviceUrl:
defaultZone: http://localhost:8761/eureka/ # 注册到 Eureka Server这样,当启动这个 Eureka Client 时,它将自动注册到之前创建的 Eureka Server 上。
Eureka 核心机制
架构与组件
Eureka 包括两个主要组件:Eureka Server 和 Eureka Client。
- Eureka Server 作为一个服务注册中心,提供了服务的注册与发现功能。各个微服务可以通过配置的方式将自己注册到 Eureka Server 上,这样它们就可以被其他服务发现和调用。Eureka Server 支持高可用配置,可以通过运行多个 Eureka Server 实例来形成一个集群,从而提高服务注册中心的可靠性和稳定性。
- Eureka Client 是服务提供者和服务消费者。作为服务提供者,它会向 Eureka Server 注册自己的信息(如主机名、IP地址、端口号、版本号等)。作为服务消费者,它可以从 Eureka Server 查询当前已注册的服务列表,并使用这些服务的信息进行远程调用。此外,Eureka Client 还会定期发送心跳给 Eureka Server,以表明当前服务是可用的;如果某个服务在一段时间内没有发送心跳,Eureka Server 将会注销该服务实例。
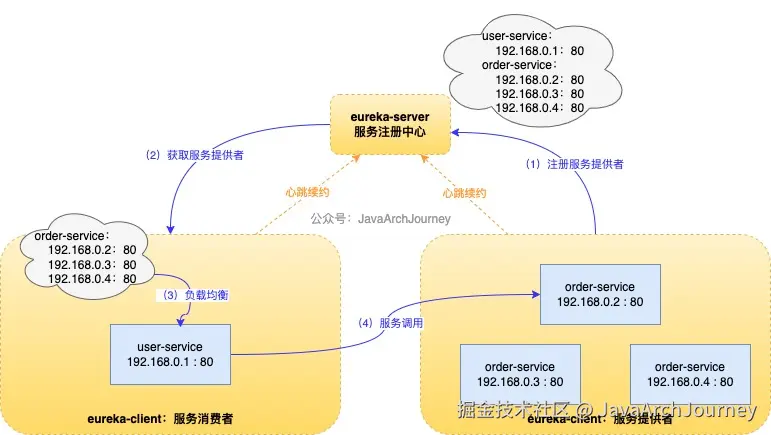
服务注册与发现流程
- 服务注册流程:
- Eureka Client 启动时自动注册:当一个 Eureka Client(即微服务实例)启动时,它会根据配置文件中的信息自动向 Eureka Server 注册自己。注册的信息包括服务名、IP地址、端口号等。
- 定期心跳续约:为了保持其在 Eureka Server 上的注册状态,每个 Eureka Client 需要定期发送心跳请求(默认每 30 秒一次)。如果某个服务实例未能按时续约,Eureka Server 将会在一段时间后将其从注册表中移除。
- 服务发现流程:
- Eureka 使用的是客户端发现模式,每个服务作为 Eureka Client 不仅需要向 Eureka Server 注册自己,还需要主动查询 Eureka Server 获取其他服务的信息,以便进行服务间的调用。
- 缓存机制:为了避免频繁访问 Eureka Server 而造成的性能瓶颈,Eureka Client 通常会在本地缓存一份服务注册表的副本,并定期更新(默认每 30 秒一次)。
- 每个 Eureka Client 实例往往既是服务提供者也是服务消费者,它们既将自己的信息注册到 Eureka Server 供其他服务发现和调用,也会从 Eureka Server 查询所需的服务信息以完成自身业务逻辑中的服务调用需求。在实际的应用中,Eureka Client 通常结合 Ribbon / LoadBalancer 等负载均衡组件使用,这些组件可以根据从 Eureka Server 获取的服务列表对服务调用进行客户端负载均衡。
注册表存储结构
Eureka Server 中的数据存储分为两层:
- 数据存储层(
Registry)ConcurrentHashMap<String, Map<String, Lease<InstanceInfo>>> registry:这是Eureka Server维护的核心服务注册表,用于记录所有已注册的服务实例信息。- 第一层的 key 是
spring.application.name(即应用名称),value 是第二层的Map<String, Lease<InstanceInfo>>。 - 第二层的 key 是服务的
InstanceId,value 是包含服务详情和服务治理相关属性的Lease<InstanceInfo>对象。
- 第一层的 key 是
- 缓存层(
ResponseCache)- 包括两个部分:
ReadOnlyMap和ReadWriteMap。- **二级缓存 **
Loading<Key,Value> readWriteCacheMap:基于Guava的LoadingCache实现,支持失效机制。它封装了从Registry获取的服务实例信息,并准备为 HTTP 响应做准备。 - **一级缓存 **
ConcurrentHashMap<Key,Value> readOnlyCacheMap:主要用于提高读取性能。 - 所有的客户端读取请求首先访问
ReadOnlyMap。如果所需数据不存在,则尝试从ReadWriteMap获取;若仍未找到,则直接从Registry拉取数据。
- **二级缓存 **
- 包括两个部分:
缓存更新机制:
- 加载二级缓存 :
- 当 Eureka Client 发送
getRegistry请求且二级缓存中没有所需数据时,触发 Guava 的load方法,从Registry获取原始服务信息并处理加工后加载到ReadWriteMap中。
- 当 Eureka Client 发送
- 删除二级缓存 :
- 当 Eureka Client 发送
register、renew或cancel请求更新Registry后,相应的ReadWriteMap缓存会被删除。 - Eureka Server 自身的 Evict Task 在剔除过期服务实例后也会使对应的
ReadWriteMap缓存失效。 ReadWriteMap本身设置了失效机制,一段时间后自动失效。
- 当 Eureka Client 发送
- 更新一级缓存 :
- Eureka Server 内置了一个
TimerTask,定时将二级缓存ReadWriteMap中的数据同步到一级缓存ReadOnlyMap中,包括了删除旧数据和加载新数据的过程,这个时间间隔默认是 30 s。
- Eureka Server 内置了一个
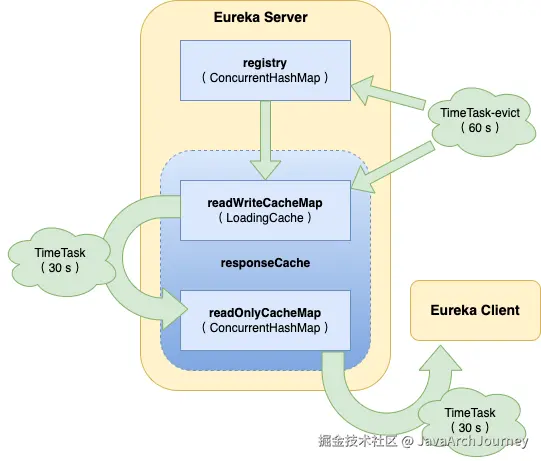
通过上述机制,Eureka 确保了服务注册表数据的一致性和实时性,同时提供了高效的读取性能以支持大规模微服务架构下的服务发现需求。
健康检查机制
Eureka 健康检查通过心跳机制监控服务状态,确保只提供可用的服务实例。
- 心跳续约 :
- 客户端定期发送心跳:每个 Eureka Client 会定期向 Eureka Server 发送心跳请求,以续租(Lease Renewal),表明自身处于活跃状态。默认每 30 秒发送一次心跳。
- 租约过期与剔除:如果 Eureka Server 在一定时间内未收到某个实例的心跳(默认 90 秒),则认为该实例已失效,并将其从注册表中移除。
- 自我保护模式(容错性设计) :
- 自我保护模式是为了防止误剔除健康实例:当网络波动或分区故障导致大量服务实例无法发送心跳时,Eureka Server 可能错误地将这些实例标记为失效。自我保护模式会暂时停止剔除操作,避免服务注册表被污染。
- 触发条件:默认为当 15 分钟内集群中超过 85% 的服务实例未续约(例如网络分区),Eureka Server 就会进入自我保护模式。
- 进入自我保护模式后,不再剔除因未收到心跳的实例;同时仍允许新服务注册和查询请求,但不会同步到 Eureka Server 集群的其他节点。
- 网络恢复后,服务实例重新发送心跳,Eureka Server 自动退出自我保护模式。
可以基于 Spring Boot Actuator 自定义健康检查逻辑:
- Spring Boot Actuator 提供
/actuator/health端点,用于暴露应用的健康状态。Eureka Client 可通过该端点判断服务实例的实际健康状态。(需依赖spring-boot-starter-actuator包,并开启配置eureka.client.healthcheck.enabled=true) - Eureka Client 会定期调用
/actuator/health端点,将健康状态(UP/DOWN)同步到 Eureka Server。
java
// 通过实现 HealthIndicator 接口自定义健康检查逻辑
@Component
public class CustomHealthIndicator implements HealthIndicator {
@Override
public Health health() {
if (/* 检查条件 */) {
return Health.up().build();
} else {
return Health.down().withDetail("error", "custom health check failed").build();
}
}
}配置建议与最佳实践:
- 合理调整心跳间隔与过期时间:网络不稳定时,缩短心跳间隔(如 10 s)和过期时间(如 30 s),加快故障检测速度。网络稳定时,适当放宽配置以减少资源消耗。
- 结合
Actuator增强健康检查:通过/actuator/health监控应用关键资源(如数据库、缓存),避免仅依赖心跳判断服务可用性。 - 使用自我保护模式:生产环境中建议开启自我保护模式(
enable-self-preservation=true),防止网络波动导致误剔除。如果需要快速剔除故障实例,可关闭自我保护模式(enable-self-preservation=false)。 - 服务下线通知:通过事件监听(如服务实例被剔除时触发的
EurekaInstanceCanceledEvent)实现服务下线告警或自动恢复逻辑。
注册中心集群模式(高可用)
服务注册中心(Eureka Server)支持高可用集群模式部署:通过多个 Eureka Server 实例相互注册和同步服务注册信息,确保服务发现功能的稳定性和容错能力。
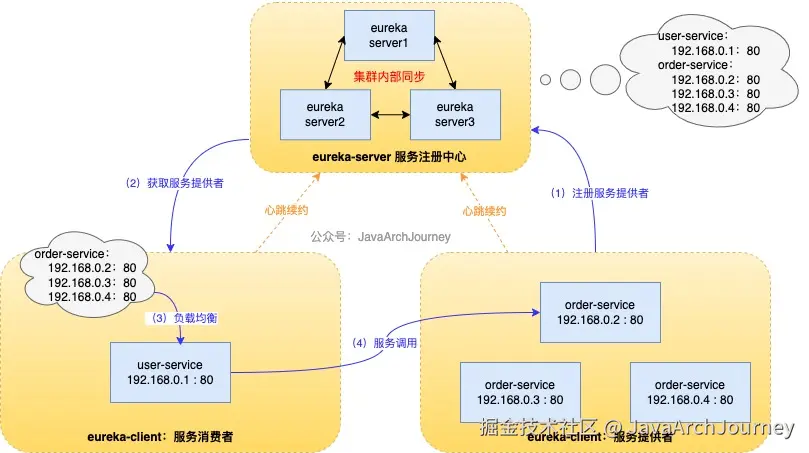
在生产环境,通常会配置三台及以上的服务注册中心,以此来保证服务的稳定性。配置例子:
properties
# 第一个 eureka-server 配置文件
spring.application.name=eureka-server
server.port=8001
eureka.instance.hostname=eureka1
eureka.client.serviceUrl.defaultZnotallow=http://eureka2:8002/eureka/,http://eureka3:8003/eureka/
# 第二个 eureka-server 配置文件
spring.application.name=eureka-server
server.port=8002
eureka.instance.hostname=eureka2
eureka.client.serviceUrl.defaultZnotallow=http://eureka1:8001/eureka/,http://eureka3:8003/eureka/
# 第三个 eureka-server 配置文件
spring.application.name=eureka-server
server.port=8003
eureka.instance.hostname=eureka3
eureka.client.serviceUrl.defaultZnotallow=http://eureka1:8001/eureka/,http://eureka2:8002/eureka/服务注册信息在 Eureka Server 集群中的同步机制:
- Eureka Server 集群通过异步复制机制同步服务注册信息,确保所有节点的数据最终一致。
- 同步触发条件 :
- 服务实例注册或续约时。
- 服务实例主动下线时。
- Eureka Server 定期检查并同步集群状态(默认每 30 秒一次)。
- 同步流程 :
- 服务实例注册 :服务实例(Eureka Client)向任意 Eureka Server 发送注册请求,该 Eureka Server 将服务实例信息存储在本地的
PeerAwareInstanceRegistry中。 - 集群节点间同步 :注册信息变更(新增、更新、删除)都会触发同步任务。源 Eureka Server 通过 HTTP 请求将变更推送至集群中的其他节点,目标 Eureka Server 接收变更后,更新本地的
PeerAwareInstanceRegistry。 - 全量同步:在首次注册或同步失败时触发,同步所有服务实例信息。
- 增量同步:仅同步服务实例的增量变更(新增、修改、删除),减少网络开销。
- 服务实例注册 :服务实例(Eureka Client)向任意 Eureka Server 发送注册请求,该 Eureka Server 将服务实例信息存储在本地的
- 最终一致性:由于异步复制机制,集群中的节点可能暂时存在数据不一致(如某个节点未同步到最新状态);但随着时间推移,所有节点会通过同步任务达到一致状态。
Eureka 与 Zookeeper 对比
Spring Cloud Eureka 和 Apache Zookeeper 都是用于服务注册与发现的工具,但它们在设计理念、CAP 理论支持、网络分区处理、使用场景等方面存在显著差异。
| 特性 | Spring Cloud Eureka | Zookeeper |
|---|---|---|
| CAP 理论定位 | AP(可用性 + 分区容忍性) | CP(一致性 + 分区容忍性) |
| 核心目标 | 优先保证服务可用性,容忍短暂不一致 | 优先保证数据强一致性,牺牲部分可用性 |
| 网络分区处理 | 在网络分区时保持可用性,允许临时不一致。即分区后的子网内仍可提供服务(可用性优先),但数据可能不一致 | 网络分区时停止服务,等待恢复一致性。即分区后无法提供服务,需等待 Leader 选举完成(强一致性优先) |
| Leader 宕机 | 无 Leader 概念,节点平权,宕机后自动切换到其他节点 | Leader 宕机后需选举新 Leader(耗时 30~120 秒),选举期间服务不可用 |
| 数据模型 | 简单键值对(服务名:实例列表) | 类似文件系统的树形结构(ZNode),支持丰富的数据类型(临时节点、顺序节点等) |
| 心跳机制 | 客户端定期通过 HTTP 发送心跳(默认 30 秒),服务超时未续约则被剔除 | 客户端与服务器保持长连接,断开后服务立即标记为下线 |
| 同步机制 | Eureka Server 集群内部节点之间通过异步复制同步服务信息(最终一致性) | Zookeeper 集群通过 ZAB 协议保证强一致性(所有节点数据实时同步) |
| 自我保护模式 | 支持。在网络不稳定时保留"心跳死亡"的服务实例,防止误剔除 | 不支持。 |
使用场景对比:
- 选择 Spring Cloud Eureka 的场景 :
- 对 高可用性 和 快速故障恢复 要求更高的场景,比如微服务架构。
- 服务实例需要频繁上下线的场景,比如如云原生环境。
- 与 Spring Cloud 生态(如 Feign、Ribbon、Hystrix 等)深度集成的场景。
- 典型应用场景:云原生微服务架构、动态扩展的服务集群、对可用性要求高于一致性的场景。
- 选择 Zookeeper 的场景 :
- 对 数据强一致性 要求极高的场景,比如分布式事务、分布式锁。
- 需要额外的分布式协调功能的场景,比如配置管理、分布式队列。
- 集群稳定性高,网络分区概率较低的场景。
- 典型应用场景:大数据生态系统(Hadoop / Kafka)、分布式协调、强一致性要求的配置管理场景。