目录
[52. 力扣1 两数之和](#52. 力扣1 两数之和)
[52.1 题目解析:](#52.1 题目解析:)
[52.2 算法思路:](#52.2 算法思路:)
[52.3 代码演示:](#52.3 代码演示:)
[52.4 总结反思:](#52.4 总结反思:)
[53 面试题:判定是否互为字符重排](#53 面试题:判定是否互为字符重排)
[53.1 题目解析:](#53.1 题目解析:)
[53.2 算法思路:](#53.2 算法思路:)
[53.3 代码演示:](#53.3 代码演示:)
[53.4 总结反思](#53.4 总结反思)
[54. 力扣217 存在重复元素I](#54. 力扣217 存在重复元素I)
[54.1 题目解析:](#54.1 题目解析:)
[54.2 算法思路:](#54.2 算法思路:)
[54.3 代码演示:](#54.3 代码演示:)
[55. 力扣219 存在重复的元素II](#55. 力扣219 存在重复的元素II)
[55.1 题目解析:](#55.1 题目解析:)
[55.2 算法思路:](#55.2 算法思路:)
[55.3 代码演示:](#55.3 代码演示:)
[55.4 总结反思](#55.4 总结反思)
[56. 力扣49 字母异位词分组](#56. 力扣49 字母异位词分组)
[56.1 题目解析:](#56.1 题目解析:)
[56.2 算法思路:](#56.2 算法思路:)
[56.3 代码演示:](#56.3 代码演示:)
[56.4 总结反思:](#56.4 总结反思:)
今天的算法题是我从暑假写博客以来最简单的一次。废话少说,开启今天的算法题
在此之前,咱们要先讲一下哈希表:
1.哈希表是什么?(哈希表使用方式比较单一),它是存储数据的容器。
2.那么哈希表有啥用呢?快速查找某个元素,基本接近O(1)级别。
3.什么时候用哈希表?当频繁的查找某一个数的时候用哈希表,或者使用二分查找,但是二分查找局限性比较大。你用哈希表是因为哈希表比较快,但是呢,能用二分查找还是用二分查找,因为哈希表是典型的用空间换时间。
4.怎么用哈希表?1.容器(哈希表)2.使用数组模拟简易的哈希表。一般适用于:
【1】字符串中的"字符",(基本创建一个大小为200的数组空间即可),<index,nindex>
【2】数据范围比较小的时候,比如int,1~10^3或4或5,每一个下标对应一个数,但是当出现负数的话,就不建议使用了。
OK,那么关于哈希表的前置知识已经讲完了,那么接下来,就正式的进入咱们今天的讲题阶段
52. 力扣1 两数之和
52.1 题目解析:

本题很简单的题目吧。
52.2 算法思路:
那么这个题目,咱们可以使用暴力枚举来做,不过这个暴力枚举,并不是非常干脆的暴力枚举,还是需要一点智慧的。那么下面我就举个例子,大家看一看。
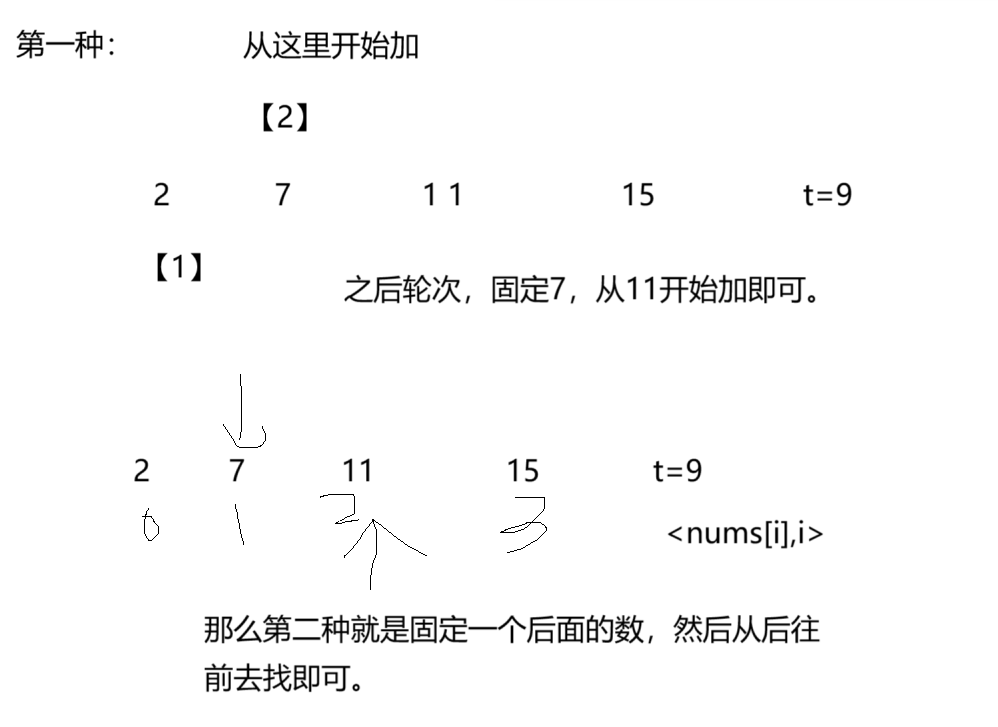
就是固定住一个数字,然后,从这个固定的数字后面去寻找对应的数字即可。那么此时就有两种寻找方式,一个是从前往后,一个是从后往前
优化:
那么咱们对于这种暴力解法,咱们该如何优化呢?

优化就是根据前面的暴力解法来进行的优化,由上面的解析可以看出优化的结果。
52.3 代码演示:
cpp
vector<int> twoSum(vector<int>& nums, int target) {
unordered_map<int, int> hash;//<nums[i],i>
for (int i = 0; i < nums.size(); i++)
{
int x = target - nums[i];//这个是在哈希表中找到这个数
if (hash.count(x)) return { hash[x],i };//这个hash[x],返回的是x的下标。count,如果哈希表中有这个key,就返回1,否则,返回0
hash[nums[i]] = i;//如果没有这个数字,那么就存储这个数字,并且存下这个数字的下标,因为上面那行代码需要用到下标
}
return { -1,-1 };
}
int main()
{
vector<int> nums = { 2,7,11,15 };
int target = 9;
vector<int> outcome = twoSum(nums, target);
for (auto& e : outcome)
{
cout << e << "";
}
cout << endl;
return 0;
}52.4 总结反思:
本题基本就用到咱们之前所讲的那些东西,这里创建哈希表使用unordered_map,是因为这里有key以及val,不只是key
53 面试题:判定是否互为字符重排
53.1 题目解析:
 题目也会相当的简单,而且,咱们上面也说了,只要是关于字符串存储的,都可以使用到哈希表
题目也会相当的简单,而且,咱们上面也说了,只要是关于字符串存储的,都可以使用到哈希表
53.2 算法思路:
那么本题就是使用哈希表,使用一个,这里有一个细节,就是遍历s1的字符之后,再遍历s2。如果在s2找到与s1相同的字符,就减一,如果最后减到负数,则返回false。并且若两个字符串长度不相等则直接返回false即可。
53.3 代码演示:
cpp
bool CheckPermutation(string s1, string s2) {
if (s1.size() != s2.size()) return false;
int hash[26] = { 0 };
for (auto& e : s1)
{
hash[e - 'a']++;
}
for (auto& e : s2)
{
hash[e - 'a']--;
if (hash[e - 'a'] < 0) return false;
}
return true;
}
int main()
{
string s1("abc");
string s2("bca");
cout << CheckPermutation(s1, s2) << endl;
return 0;
}53.4 总结反思
基本也是用到了咱们开篇所讲的那些知识
54. 力扣217 存在重复元素I
54.1 题目解析:
 这题目更不需要多说
这题目更不需要多说
54.2 算法思路:
那么咱们这一题主要就是使用哈希表去完成:
这一道题与那个两数之和的题目策略很像,咱们可以使用那个策略去做,也是使用哈希表,只不过,这一次,只需要有一个key值即可,不需要存val,所以使用unordered_set即可。
54.3 代码演示:
cpp
bool containsDuplicate(vector<int>& nums)
{
unordered_set<int> hash;
for (auto e : nums)
{
if (hash.count(e)) return true;
hash.insert(e);
}
return false;
}
int main()
{
vector<int> nums = { 1,2,3,1 };
cout << containsDuplicate(nums) << endl;
return false;
}54.4总结反思:
基本的重要的知识,学会运用,做题轻轻松松
55. 力扣219 存在重复的元素II
55.1 题目解析:

这个题目与前面的那一个题目很像,只是多了一个条件而已
55.2 算法思路:
 由于这个得使用到下标,所以咱们还是使用unordered_map进行创建哈希表
由于这个得使用到下标,所以咱们还是使用unordered_map进行创建哈希表
55.3 代码演示:
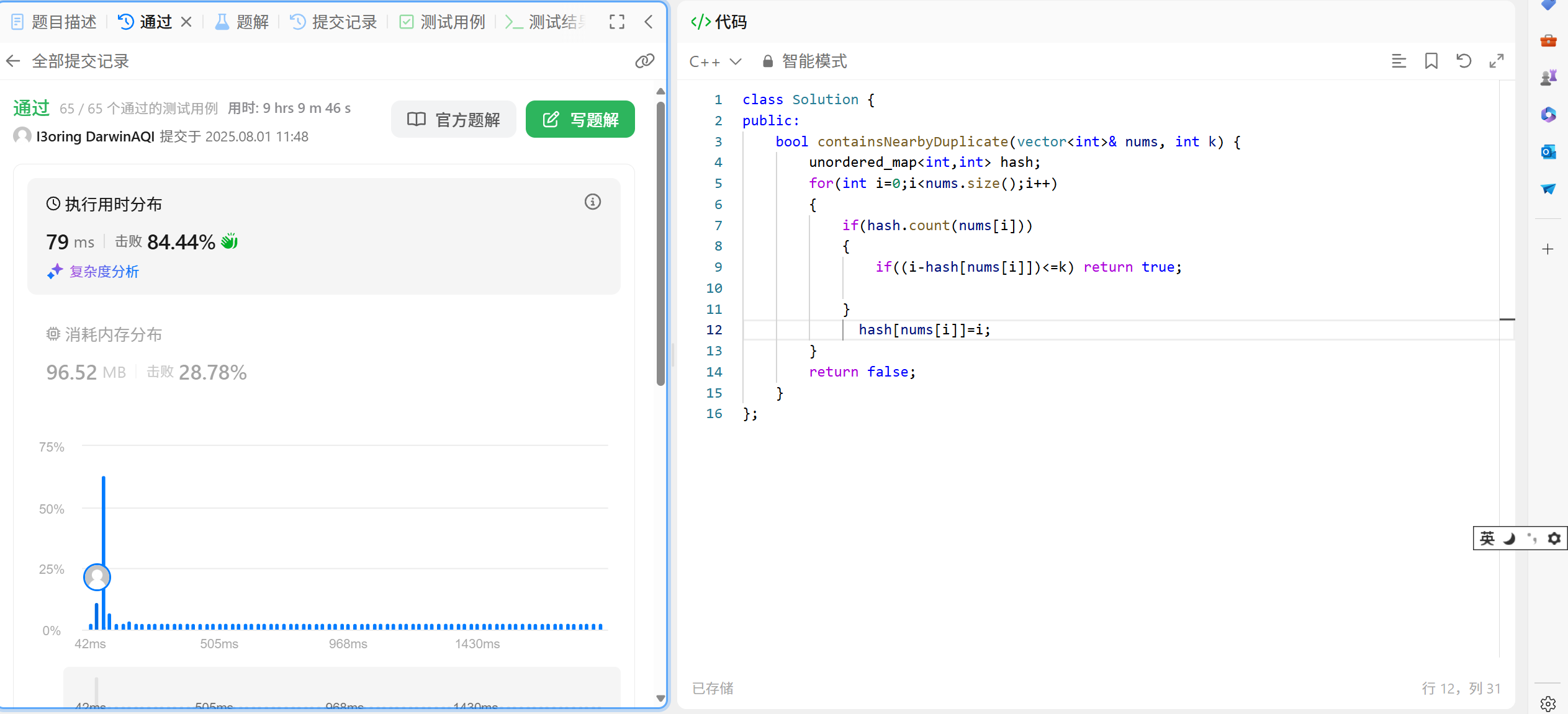
cpp
bool containsNearbyDuplicate(vector<int>& nums, int k) {
unordered_map<int, int> hash;
for (int i = 0; i < nums.size(); i++)
{
if (hash.count(nums[i]))
{
if ((i - hash[nums[i]]) <= k) return true;
}
hash[nums[i]] = i;
}
return false;
}
int main()
{
vector<int> nums = { 1,2,3,1 };
int k=3;
cout << containsNearbyDuplicate(nums, k) << endl;
return 0;
}55.4 总结反思
那么大体的思路基本就是这样,大家还是得利用好前面的知识才可以
56. 力扣49 字母异位词分组
56.1 题目解析:

这个题目很简单,就是具有相同的字母的字符串就可以合成一组异位词。
56.2 算法思路:
这个还是得使用哈希表,1.判断两个字符是否为字母异位词,排序
2.然后就是如何分组?<string,string\[\]>,第二个存的是字符数组。例如,"aet","tea"若字符串中有这个字母,那么加入到字符串数组即可
即val就是咱们所要的结果
56.3 代码演示:
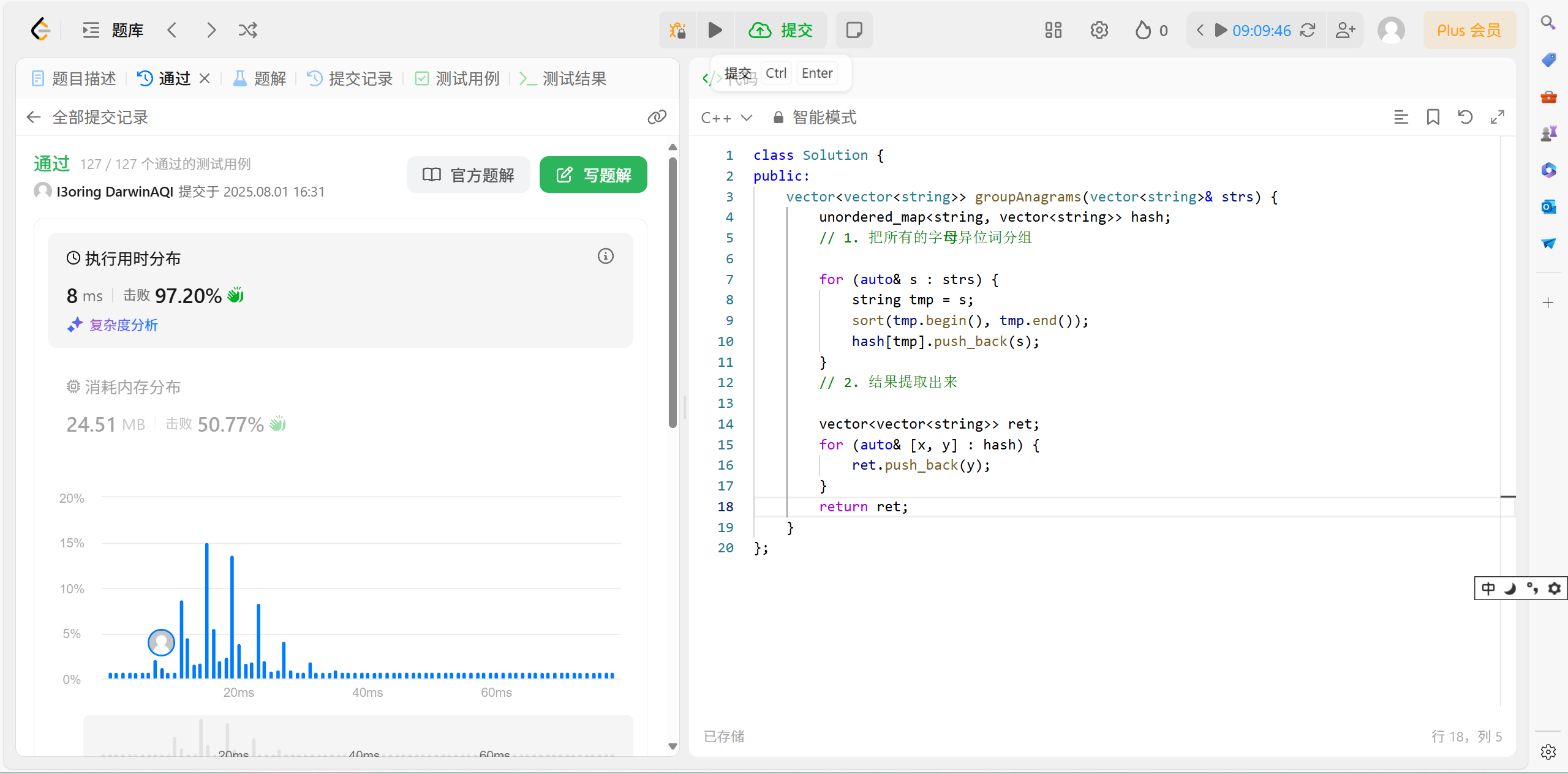
cpp
vector<vector<string>> groupAnagrams(vector<string>& strs)
{
unordered_map<string, vector<string>> hash;
// 1. 把所有的字⺟异位词分组
for (auto& s : strs)
{
string tmp = s;
sort(tmp.begin(), tmp.end());
hash[tmp].push_back(s);
}
// 2. 结果提取出来
vector<vector<string>> ret;
for (auto& [x, y] : hash)
{
ret.push_back(y);
}
return ret;
}
int main()
{
vector<string> str = { "eat", "tea", "tan", "ate", "nat", "bat" };
vector<vector<string>> outcome = groupAnagrams(str);
for (auto& e : outcome)
{
for (auto& x : e)
{
cout << x << "";
}
cout << endl;
}
return 0;
}56.4 总结反思:
基本今天的题目就是这些,算是比较简单的。
本篇完....................