本文通过一个具体的智能合约示例,详细讲解EVM(以太坊虚拟机)的完整执行流程,从字节码层面深入分析每个指令的执行过程。我们将以一个简单的存储合约为例,完整展示从合约调用到执行完成的每一个步骤,包括函数选择器的匹配机制、参数的解析过程、存储操作的Gas计算、内存管理的动态扩展、以及错误处理时的状态回滚等关键环节。通过这个深入的分析,你将能够理解EVM是如何将高级的Solidity代码转换为底层的虚拟机指令,每个指令如何影响栈、内存和存储的状态变化,以及EVM如何通过精密的Gas计量机制和状态管理系统,在保证安全性和确定性的同时,为智能合约提供高效可靠的执行环境。这不仅有助于开发者编写更优化的智能合约,也为理解区块链虚拟机的设计原理提供了宝贵的实践案例。
1. 示例合约代码
我们以一个简单的存储合约为例:
csharp
// SPDX-License-Identifier: MIT
pragma solidity ^0.8.0;
contract SimpleStorage {
uint256 private storedNumber;
function store(uint256 _number) public {
storedNumber = _number;
}
function retrieve() public view returns (uint256) {
return storedNumber;
}
}2. 合约字节码分析
当Solidity编译器处理我们的智能合约时,会生成两种不同的字节码:创建字节码和运行时字节码。创建字节码负责部署合约并初始化状态,而运行时字节码则是合约部署后实际执行的代码。
编译后的字节码(简化版):
go
// 合约创建字节码
608060405234801561001057600080fd5b50610150806100206000396000f3fe
// 运行时字节码
608060405234801561001057600080fd5b50600436106100365760003560e01c80632e64cec11461003b5780636057361d14610059575b600080fd5b610043610075565b60405161005091906100a1565b60405180910390f35b6100736004803603810190610068919061008d565b61007e565b005b60008054905090565b8060008190555050565b60008135905061009781610103565b92915050565b6100a081610099565b82525050565b60006020820190506100bb60008301846100a7565b92915050565b6000602082840312156100d357600080fd5b60006100e184828501610088565b91505092915050565b6100f3816100f9565b82525050565b6000819050919050565b61010c816100f9565b811461011757600080fd5b50565b```3. 函数选择器分析
函数选择器是EVM中函数调用路由的核心机制。当外部调用智能合约时,EVM需要知道要执行哪个函数。这个过程通过函数选择器来实现 - 它是函数签名的Keccak256哈希值的前4字节,作为函数的唯一标识符。
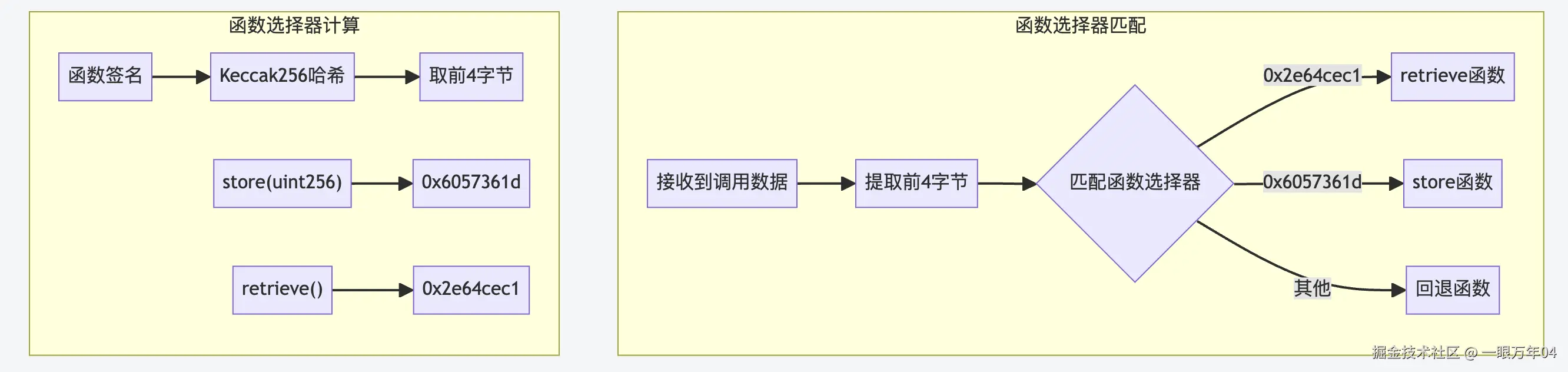
4. store函数执行流程详解
4.1 调用数据准备
假设我们调用 store(42):
diff
调用数据: 0x6057361d000000000000000000000000000000000000000000000000000000000000002a
- 0x6057361d: 函数选择器
- 000...002a: 参数42的十六进制表示(32字节对齐)4.2 EVM执行环境初始化
在执行任何智能合约代码之前,EVM需要建立一个完整的执行环境。这个过程包括创建EVM实例、初始化解释器、分配栈和内存空间、加载合约代码等步骤。每个组件都有其特定的职责,共同构成了一个安全、高效的执行环境。
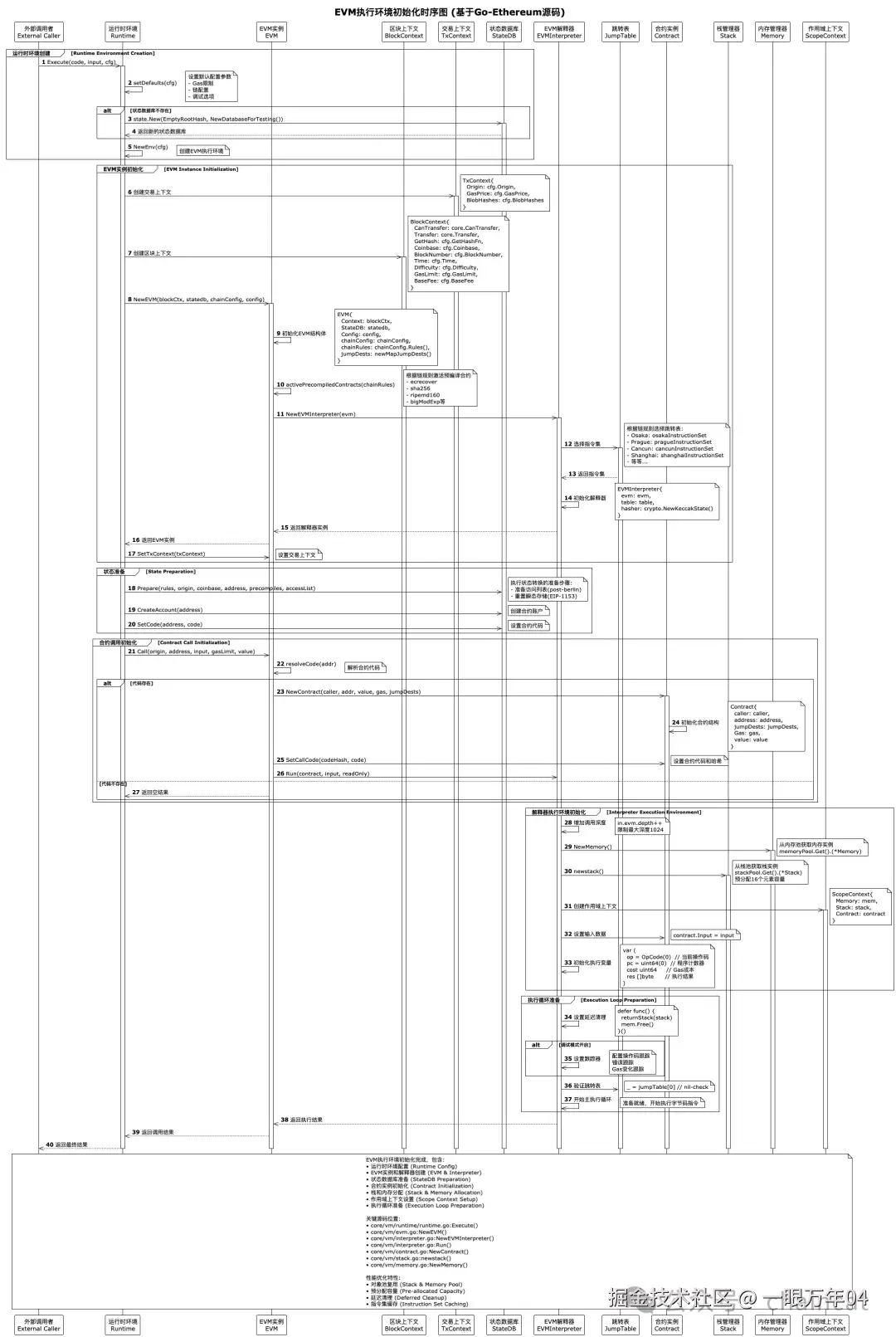
4.3 详细指令执行过程
现在我们深入到字节码层面,逐条分析每个指令的执行过程。这个过程展示了EVM如何将高级的Solidity代码转换为底层的虚拟机指令,以及每个指令如何影响栈、内存和存储的状态。
让我们逐步分析store函数的字节码执行:
步骤1: 函数选择器检查
这是合约执行的第一个关键步骤。EVM需要确定调用者想要执行哪个函数,这个过程通过解析调用数据中的函数选择器来完成。同时,还需要进行一些基础的安全检查,比如验证是否发送了以太币(对于非payable函数)。
makefile
字节码: 60 80 60 40 52 34 80 15 61 00 10 57 60 00 80 fd指令序列分析:
-
PUSH1 0x80 (PC=0)
makefile操作: 将0x80压入栈 栈状态: [0x80] Gas消耗: 3 -
PUSH1 0x40 (PC=2)
makefile操作: 将0x40压入栈 栈状态: [0x40, 0x80] Gas消耗: 3 -
MSTORE (PC=4)
makefile操作: 将0x80存储到内存地址0x40 栈状态: [] 内存: 0x40位置存储0x80(自由内存指针) Gas消耗: 3 + 内存扩展成本 -
CALLVALUE (PC=5)
makefile操作: 获取交易发送的以太币数量 栈状态: [msg.value] Gas消耗: 2 -
DUP1 (PC=6)
makefile操作: 复制栈顶元素 栈状态: [msg.value, msg.value] Gas消耗: 3 -
ISZERO (PC=7)
makefile操作: 检查栈顶是否为0 栈状态: [msg.value == 0, msg.value] Gas消耗: 3 -
PUSH2 0x0010 (PC=8)
makefile操作: 将跳转目标地址压入栈 栈状态: [0x0010, msg.value == 0, msg.value] Gas消耗: 3 -
JUMPI (PC=11)
ini操作: 如果msg.value == 0则跳转到0x0010 栈状态: [msg.value] Gas消耗: 10
步骤2: 函数选择器匹配
在这个步骤中,EVM会从调用数据中提取函数选择器,并与合约中定义的函数进行匹配。这个过程涉及复杂的字节码操作,包括数据加载、位运算和条件跳转。理解这个过程有助于优化函数调用的Gas成本。
makefile
字节码: 60 04 36 10 61 00 36 57 60 00 35 60 e0 1c 80 63 2e 64 ce c1 14 61 00 3b 57 80 63 60 57 36 1d 14 61 00 59 57关键指令分析:
-
PUSH1 0x04 + CALLDATASIZE + LT
检查调用数据长度是否至少4字节(函数选择器) -
PUSH1 0x00 + CALLDATALOAD
makefile从调用数据偏移0处加载32字节 结果: 0x6057361d000000000000000000000000000000000000000000000000000000000000002a -
PUSH1 0xe0 + SHR
makefile右移224位(28字节),提取前4字节函数选择器 结果: 0x6057361d -
DUP1 + PUSH4 0x6057361d + EQ
比较提取的选择器与store函数选择器 匹配成功!
步骤3: 参数解析和存储
这是函数执行的核心步骤。EVM需要从调用数据中解析出函数参数,然后执行实际的存储操作。SSTORE指令是整个过程中最昂贵的操作,其Gas成本取决于存储状态的变化类型。这里展示了EVM如何精确计算和收取Gas费用。
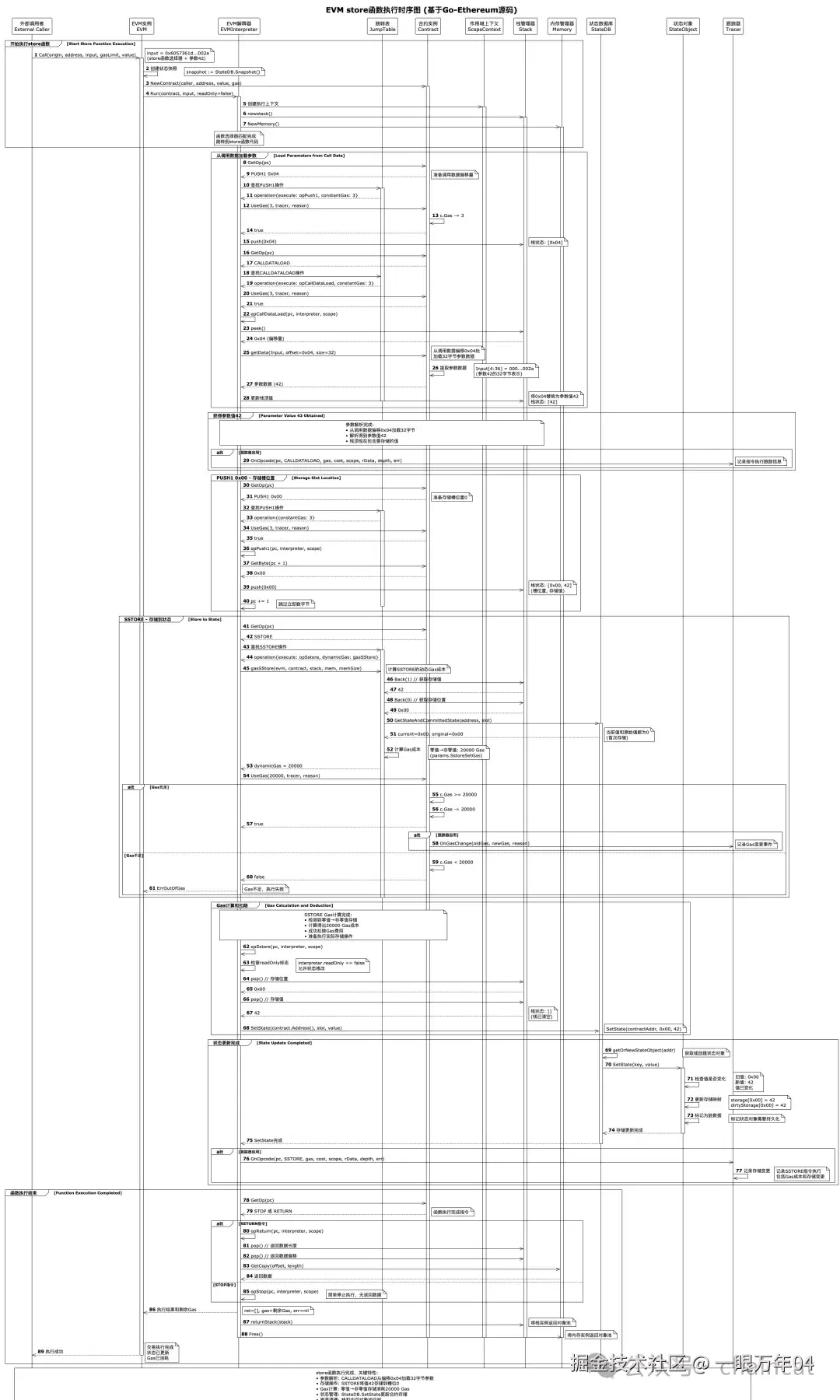 详细指令执行:
详细指令执行:
-
参数加载
iniPUSH1 0x04 ; 参数偏移量 CALLDATALOAD ; 加载32字节参数 栈状态: [42] ; 十进制42 -
存储位置准备
iniPUSH1 0x00 ; 存储槽0(storedNumber变量) 栈状态: [0, 42] -
执行存储操作
iniSSTORE ; 将42存储到槽位0 栈状态: [] Gas消耗: 20000 (首次存储) 或 5000 (更新存储)
4.4 Gas计算详解
Gas消耗详细分解
基础Gas成本构成
| 成本类别 | 描述 | Gas消耗 | 备注 |
|---|---|---|---|
| 基础交易成本 | 每笔交易的固定成本 | 21,000 | 所有交易都需要支付 |
| 调用数据成本 | 传输调用数据的成本 | 368 | 基于数据大小计算 |
| 指令执行成本 | EVM指令执行成本 | ~200 | 根据具体指令变化 |
| 内存扩展成本 | 内存动态扩展成本 | ~50 | 二次成本模型 |
| 存储操作成本 | SSTORE操作成本 | 5,000-20,000 | 根据存储状态变化 |
调用数据成本计算 (68字节示例)
| 数据类型 | 字节数 | 单价 (Gas/字节) | 总成本 | 计算公式 |
|---|---|---|---|---|
| 非零字节 | 8个 | 16 | 128 | 8 × 16 = 128 |
| 零字节 | 60个 | 4 | 240 | 60 × 4 = 240 |
| 调用数据总成本 | 68个 | - | 368 | 128 + 240 = 368 |
SSTORE操作Gas成本
| 存储状态变化 | Gas成本 | 退款 | 净成本 | 使用场景 |
|---|---|---|---|---|
| 零值 → 非零值 | 20,000 | 0 | 20,000 | 首次存储数据 |
| 非零值 → 非零值 | 5,000 | 0 | 5,000 | 更新现有数据 |
| 非零值 → 零值 | 5,000 | 15,000 | -10,000 | 删除数据(获得退款) |
| 零值 → 零值 | 800 | 0 | 800 | 重复设置零值 |
总Gas消耗计算示例
makefile
store(42) 函数调用的完整Gas计算:
基础成本: 21,000 Gas
调用数据成本: 368 Gas
指令执行成本: 200 Gas
内存扩展成本: 50 Gas
SSTORE成本: 20,000 Gas (首次存储)
─────────────────────────────────
总计: 41,618 Gas
如果是更新操作:
SSTORE成本: 5,000 Gas (更新存储)
─────────────────────────────────
总计: 26,618 GasGas优化建议
| 优化策略 | 节省效果 | 实现方法 |
|---|---|---|
| 减少调用数据 | 中等 | 使用更短的函数名,压缩参数 |
| 批量存储操作 | 高 | 一次交易处理多个存储操作 |
| 存储槽打包 | 极高 | 将多个变量打包到一个存储槽 |
| 使用事件替代存储 | 极高 | 用事件记录非关键数据 |
| 删除无用数据 | 高 | 删除数据可获得退款 |
总Gas消耗计算:
makefile
基础成本: 21000
调用数据: 368
指令执行: ~200
内存扩展: ~50
SSTORE: 20000 (首次) 或 5000 (更新)
------------------------
总计: ~41618 (首次) 或 ~26618 (更新)5. retrieve函数执行流程
与store函数不同,retrieve函数是一个view函数,它只读取数据而不修改合约状态。这种函数的执行成本相对较低,因为它不需要进行昂贵的存储写入操作,也不会触发状态变更。让我们看看它是如何工作的。
5.1 调用数据
diff
调用数据: 0x2e64cec1
- 只有函数选择器,无参数5.2 执行流程
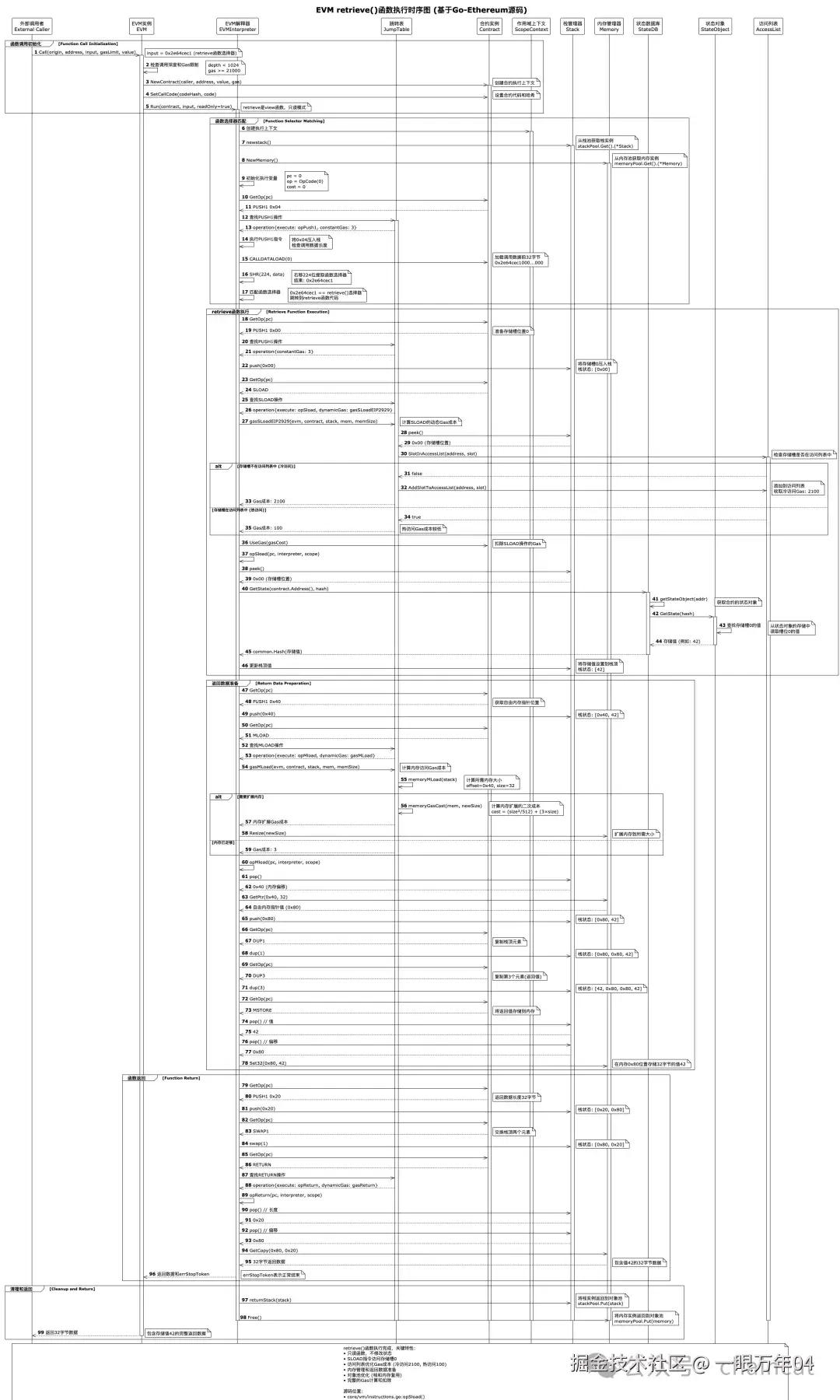
5.3 关键指令执行
-
加载存储值
iniPUSH1 0x00 ; 存储槽0 SLOAD ; 加载存储值 栈状态: [storedNumber的值] Gas消耗: 2100 (冷访问) 或 100 (热访问) -
准备返回数据
iniPUSH1 0x40 ; 获取自由内存指针 MLOAD ; 加载内存指针值 DUP1 ; 复制指针 DUP3 ; 复制返回值 MSTORE ; 存储返回值到内存 -
返回结果
iniPUSH1 0x20 ; 返回数据长度32字节 SWAP1 ; 交换栈顶两元素 RETURN ; 返回数据
6. 状态变化追踪
在智能合约执行过程中,状态的变化是核心关注点。EVM通过精确的状态管理机制,确保每次状态变更都是可追踪、可回滚的。这不仅保证了系统的一致性,也为调试和审计提供了重要支持。
6.1 存储状态变化
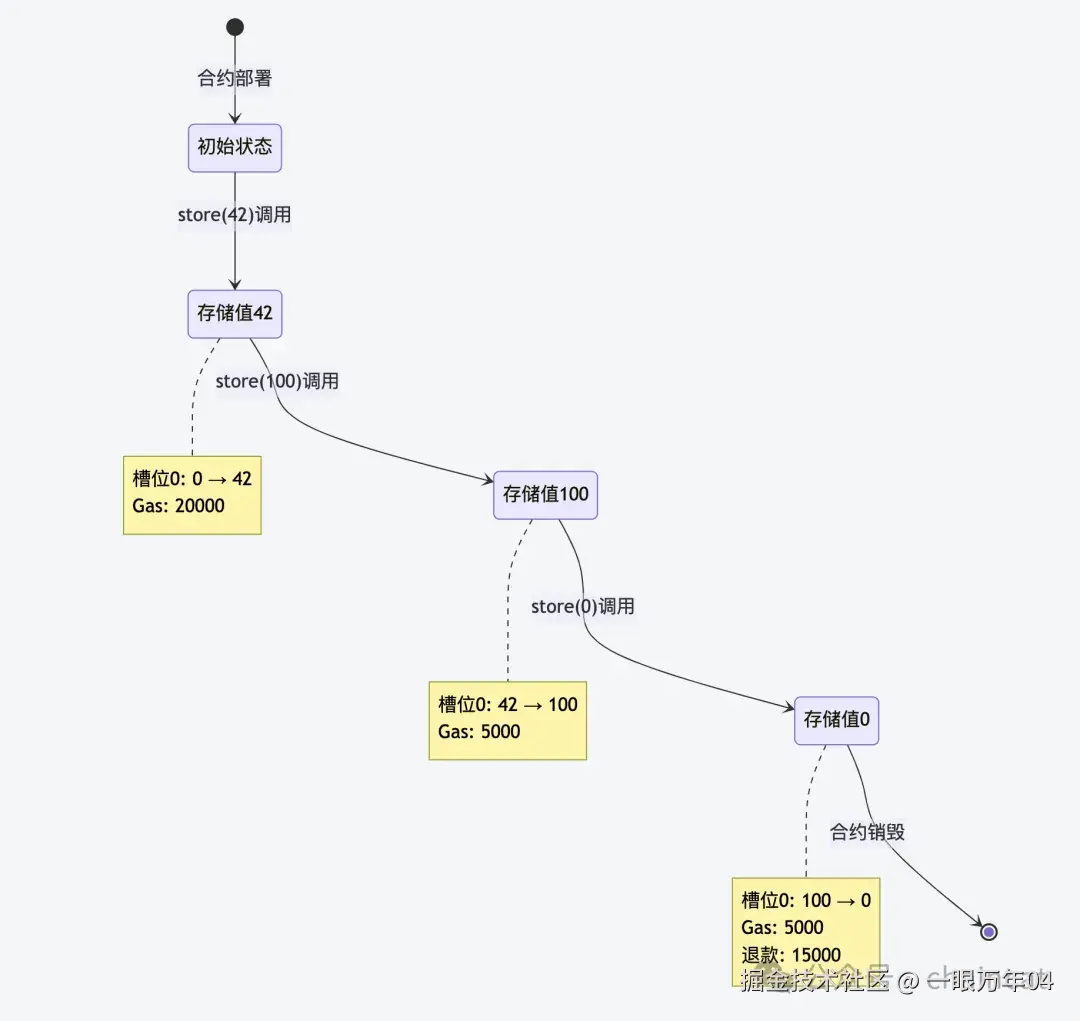
6.2 内存布局变化
makefile
执行前内存布局:
0x00-0x3F: 空
0x40-0x5F: 0x80 (自由内存指针)
0x60-0x7F: 空
执行后内存布局:
0x00-0x3F: 空
0x40-0x5F: 0x80 (自由内存指针)
0x60-0x7F: 空
0x80-0x9F: 返回数据 (仅在retrieve函数中)7. 错误处理示例
EVM的错误处理机制是其安全性和可靠性的重要保障。当执行过程中遇到异常情况时,EVM会采取相应的错误处理策略,包括状态回滚、Gas消耗、错误信息返回等。理解这些机制对于编写健壮的智能合约至关重要。
7.1 状态快照与回滚机制
在深入具体的错误处理示例之前,我们需要理解EVM的状态快照(Snapshot)机制。这是EVM实现原子性操作的核心技术,确保了"要么全部成功,要么全部失败"的执行语义。
7.1.1 快照机制的工作原理
当EVM开始执行一个合约调用时,会首先创建一个状态快照。这个快照记录了当前状态数据库的"检查点",包括所有账户的余额、存储、代码等信息的当前状态。
go
// 在Go-Ethereum中的实现
func (evm *EVM) Call(caller ContractRef, addr common.Address, input []byte, gas uint64, value *uint256.Int) (ret []byte, leftOverGas uint64, err error) {
// 创建状态快照
snapshot := evm.StateDB.Snapshot()
// 执行合约代码
ret, err = evm.interpreter.Run(contract, input, false)
if err != nil {
// 发生错误时回滚到快照点
evm.StateDB.RevertToSnapshot(snapshot)
}
return ret, gas, err
}7.1.2 快照的数据结构
EVM使用日志式的快照机制,记录每个状态变更操作:
go
type journal struct {
entries []journalEntry // 状态变更日志
dirties map[common.Address]int // 脏数据索引
}
type journalEntry interface {
revert(*StateDB) // 回滚操作
dirtied() *common.Address // 获取影响的地址
}每种状态变更都有对应的日志条目:
balanceChange- 余额变更storageChange- 存储变更nonceChange- Nonce变更codeChange- 代码变更suicideChange- 合约销毁
7.1.3 回滚过程详解
当需要回滚时,EVM会按照以下步骤执行:
- 定位快照点:根据快照ID找到对应的日志索引位置
- 逆序回滚:从最新的变更开始,逆序执行回滚操作
- 恢复状态 :每个日志条目的
revert()方法会将状态恢复到变更前 - 清理日志:删除快照点之后的所有日志条目
scss
func (s *StateDB) RevertToSnapshot(revid int) {
// 找到快照对应的日志索引
idx := s.validRevisions[revid]
// 逆序回滚所有变更
for i := len(s.journal.entries) - 1; i >= idx; i-- {
s.journal.entries[i].revert(s)
}
// 清理无效的日志条目
s.journal.entries = s.journal.entries[:idx]
s.validRevisions = s.validRevisions[:revid]
}7.2 Gas不足错误
Gas不足是智能合约执行中最常见的错误之一。当合约尝试执行一个操作但没有足够的Gas来支付其成本时,EVM会立即停止执行并回滚所有状态变更。这种机制确保了网络的安全性,防止了无限循环和资源滥用。
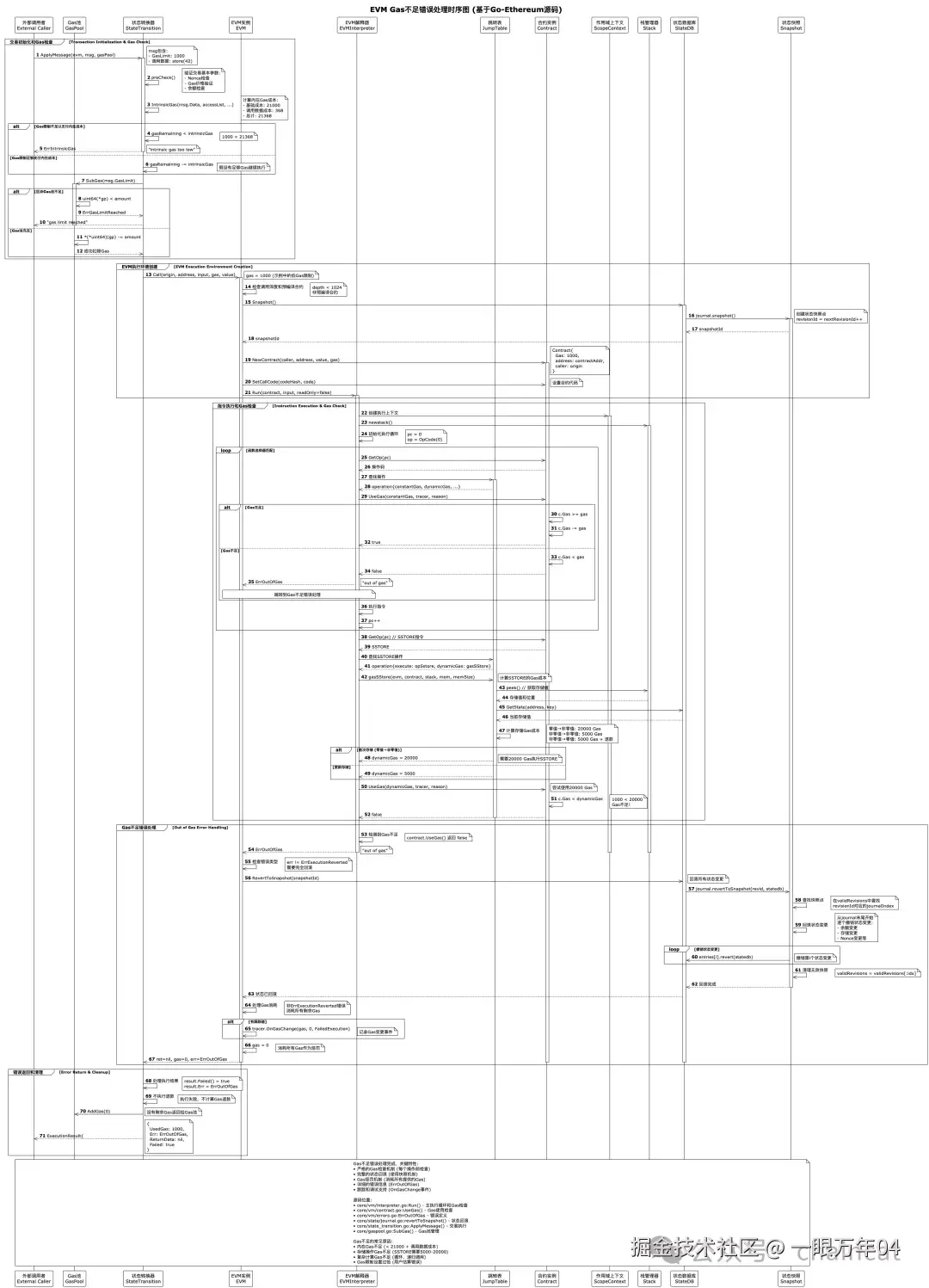
7.3 调用数据不足错误
当调用数据的长度不足以包含完整的函数参数时,EVM会采用特定的处理策略。对于缺失的数据,EVM会用零值填充,这可能导致意外的行为。理解这种机制对于编写健壮的合约输入验证逻辑很重要。
markdown
调用数据: 0x6057361d00 (缺少参数数据)
执行流程:
1. 函数选择器匹配成功
2. CALLDATALOAD 0x04 尝试加载参数
3. 调用数据长度不足,返回0值
4. 将0存储到storedNumber8. 总结
通过这个详细的执行示例,可以对EVM有了更直观的认识。EVM最大的特点就是结果可预测,同样的代码跑出来的结果肯定一样,而且花费很透明,每个操作要花多少Gas都算得清清楚楚。它对数据管理很严格,合约的状态都存在固定的槽位里,内存用完就丢,临时数据处理完就清理掉,出错了还能回滚,把状态恢复到执行前。从性能角度来说,存储最烧钱,写数据到链上是最贵的操作,内存越用越贵,用得多了成本会飞速上涨,所以传输数据要省着点,调用时少传点数据能省Gas,不过常用数据便宜,经常访问的数据Gas费用更低。写代码的时候要记住几个要点:存储要精打细算,合理设计能省一大笔Gas;错误要提前想到,各种异常情况都要考虑;安全漏洞要防范,重入攻击这些坑要避开;代码要写得清楚,自己和别人都容易看懂。总的来说,EVM就是个既安全又高效的智能合约运行环境,掌握了它的脾气就能写出更好的合约。