我开源了一款 Canvas "瑞士军刀",十几种"特效与工具"开箱即用
一直以来,我都对 Canvas 的强大能力非常着迷,它就像一块充满无限可能的数字画布。
但是要实现的酷炫效果,必须写很多代码,比如烟花、数字雨,都要翻阅大量资料,从零开始"造轮子"。
于是我就自己写了个库,它不仅仅是一个视觉效果库,更是一个集成了多种实用工具的综合性解决方案。我将它打造成了一把 Canvas 的"瑞士军刀"。
在深入技术细节之前,先让你感受一下它的魅力:
- 源码地址 : github.com/beixiyo/jl-...
- 在线体验 : jl-cvs.pages.dev/imgToFade
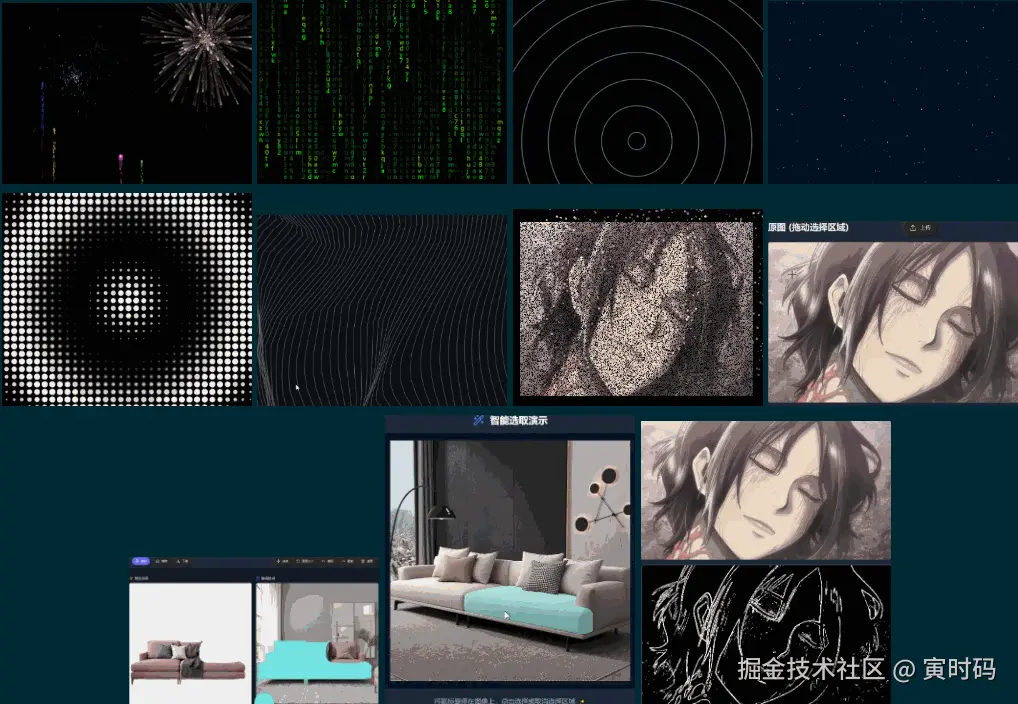
📖 阅读本文,你将收获...
我不想只写一篇干巴巴的功能说明书。这篇文章的灵魂在于 "分享探索的过程",我将带你重走几个核心功能的研发之路,让你不仅知道"它能做什么",更能理解"它是如何实现的"。
读完本文,你将get到以下技能点:
- ✨ 实现思路: 几个酷炫 Canvas 特效(如高性能视频截图、图片边缘识别算法、图片粒子化)的核心实现思路。
- 🚀 性能优化 : 如何利用
Web Worker和现代浏览器 API 优雅地处理 Canvas 的密集计算,告别界面卡顿。 - 🧩 抽象封装: 将复杂功能抽象、封装成可复用库的思考过程和实践。
- 🛠️ 现成工具: 一个可以直接在你的项目中使用的,强大的 Canvas 工具库。
🚀 技术探索之旅:从"我该怎么做"到"原来如此"
接下来,我将挑选这个库的一小部分功能讲讲实现原理
💡 手写 JavaScript 图像边缘检测工具:从原理到实现

图像边缘,是图像信息的"骨架"。但你是否想过:边缘是什么?为什么我们能"看到"边缘?我们如何用代码识别边缘?
下面是全部流程执行步骤,我会在后面详细讲解:
| 步骤 | 原因 | 如果省略会怎样? |
|---|---|---|
| 1. 灰度化 | 统一亮度表达,简化计算 | RGB 做梯度可能误判边缘 |
| 2. 卷积核计算 gx/gy | 比较邻域像素差异 | 无法得到局部梯度 |
| 3. √(gx² + gy²) | 得到真实"强度" | 不开根号会偏向水平或垂直方向 |
| 4. 阈值过滤 | 控制边缘灵敏度 | 全部为白图或黑图 |
我将从底层结构讲起,一步步推导出为什么要使用灰度图、什么是 Sobel 算法、卷积核为何这样设计,并亲手用 JavaScript 实现一套图像边缘检测工具,包含图文演示与错误分析。
🔍 一、图像到底长什么样?你看到的是 RGB 还是 01001101?
让我们来揭开 ImageData 背后的真实样貌。
假设你加载一张图片 100x100,在浏览器中使用 CanvasRenderingContext2D.getImageData() 得到的是一个这样的结构:
ts
type ImageData = {
width: 100
height: 100
data: Uint8ClampedArray // 100 × 100 × 4 像素点
}你以为像素只有一个颜色值?实际上每个像素是由 4 个通道组成的:
每 4 个值才代表一个像素点。如下图:
txt
[R,G,B,A] [R,G,B,A] [R,G,B,A] ...
P1 P2 P3🧠 二、为啥要变成灰度图?
你或许会问:边缘不是跟颜色变化有关吗?为什么要先转成灰度图?
想象以下两种对比方式:
| 情况 | 分析 | 会怎样? |
|---|---|---|
| 直接用 RGB 做梯度 | 每个通道都做卷积 | 太复杂,还不一定准确(不同颜色通道梯度可能抵消) |
| 用灰度图 | 每像素只一个值,表示亮度 | 简单直观,更稳定地表示明暗变化 |
颜色不同 ≠ 有边缘;亮度突变才意味着边缘。
所以我们使用人眼亮度感知模型进行灰度转换:
ts
Y = 0.299 * R + 0.587 * G + 0.114 * B👉 G 占比最大,是因为人眼对绿色最敏感。 👉 如果你用平均值 (R+G+B)/3,你会发现边缘识别效果变差。
获取图像灰度值代码实现如下:
ts
/**
* 获取图像灰度化后,每个像素的颜色值
* @param imageData 图片数据
* @returns 0~255 Uint8Array 灰度化后的颜色值类型化数组
*/
export function getGrayscaleArray(imageData: ImageData): Uint8Array {
const grayData = new Uint8Array(imageData.width * imageData.height)
for (let i = 0; i < imageData.data.length; i += 4) {
/** 灰度公式: Y = 0.299*R + 0.587*G + 0.114*B */
const gray = Math.round(
0.299 * imageData.data[i]
+ 0.587 * imageData.data[i + 1]
+ 0.114 * imageData.data[i + 2],
)
grayData[i / 4] = gray
}
return grayData
}🔧 三、什么是 Sobel 算法?卷积核又是怎么回事?
你先想一想:如何"识别出变化很大"的区域?
我们需要一种工具,对比周围像素值的变化趋势。
这就是卷积核的工作:
txt
你当前站在中心像素,观察它周围 8 个邻居,
用一组权重(卷积核)对这些邻居做加权求和。Sobel 使用两个 3x3 卷积核,分别检测水平和垂直变化:
ts
// sobelXKernel(检测水平边缘):
const sobelXKernel = [
-1, 0, 1,
-2, 0, 2,
-1, 0, 1
]
// sobelYKernel(检测垂直边缘):
const sobelYKernel = [
-1, -2, -1,
0, 0, 0,
1, 2, 1
]如果横向变化很大,gx 就大;如果竖向变化很大,gy 就大。
🔁 示例演算:
给你一个灰度图的 3x3 区域:
txt
[ 10, 20, 30
40, 50, 60
70, 80, 90 ]使用 sobelXKernel:
ini
gx = 10*(-1) + 20*0 + 30*1 +
40*(-2) + 50*0 + 60*2 +
70*(-1) + 80*0 + 90*1
= -10 + 0 + 30 - 80 + 0 + 120 -70 + 0 + 90 = 80📈 四、从梯度变成边缘:为什么开根号?
你已经得到了:
ts
gx // 水平变化强度
gy // 垂直变化强度为了求出"总的变化程度",我们用勾股定理:
ts
gradient = √(gx² + gy²)这样你就得到了一个「梯度强度值」,越大说明图像在这一点变化越剧烈。
然后,我们再判断:
ts
gradient > threshold
? 255
: 0变化强度超过阈值 → 这就是边缘。
如果你改低 threshold,会识别出更多边缘(包括一些噪点);调高它,则只保留最明显的轮廓。
说明这个区域在水平方向变化非常剧烈。
代码实现如下:
ts
/**
* Sobel 边缘检测
* @returns 边缘检测后的图片数据
*/
function sobelEdgeDetection(
grayData: Uint8Array,
width: number,
height: number,
threshold: number,
): ImageData {
const edgeData = new ImageData(width, height)
/**
* 左右两边对比,中间不动
*/
const sobelXKernel = [
-1, 0, 1,
-2, 0, 2,
-1, 0, 1,
]
/**
* 上下两边对比,中间不动
*/
const sobelYKernel = [
-1, -2, -1,
0, 0, 0,
1, 2, 1,
]
for (let y = 1; y < height - 1; y++) {
for (let x = 1; x < width - 1; x++) {
let gx = 0; let gy = 0
/**
* 获取周围 3 * 3 的卷积像素点,计算梯度
* (x-1, y-1) (x, y-1) (x+1, y-1)
* (x-1, y) (x, y) (x+1, y)
* (x-1, y+1) (x, y+1) (x+1, y+1)
*/
for (let ky = -1; ky <= 1; ky++) {
for (let kx = -1; kx <= 1; kx++) {
const pixelValue = grayData[(y + ky) * width + (x + kx)]
const kernelIndex = (ky + 1) * 3 + (kx + 1)
gx += pixelValue * sobelXKernel[kernelIndex]
gy += pixelValue * sobelYKernel[kernelIndex]
}
}
/** 计算梯度强度 */
const gradient = Math.sqrt(gx * gx + gy * gy)
const edgeStrength = gradient > threshold
? 255
: 0
/** 写入结果 (RGBA全设为相同值,alpha=255) */
const index = (y * width + x) * 4
edgeData.data[index] = edgeStrength // R
edgeData.data[index + 1] = edgeStrength // G
edgeData.data[index + 2] = edgeStrength // B
edgeData.data[index + 3] = 255 // A
}
}
return edgeData
}💡 如何在截取视频帧时,不让我的页面卡死
用法很简单,甚至能一行写完
ts
import { captureVideoFrame } from '@jl-org/cvs'
/**
* 示例,使用 Web Worker 截取视频 1、2、100 秒的图片
*/
const srcs = await captureVideoFrame(file, [1, 2, 100], 'base64', {
quality: 0.5,
})传统的方案
- 创建 Video 元素并加入 DOM
- 设置 Video 的 播放时间,这样才能截取到某一秒的画面
- 把 Video 绘制到 Canvas 上
- 调用 Canvas 的
drawImage方法,把 Video 绘制到 Canvas 上 - 调用 Canvas 的
toDataURL方法,把 Canvas 转换为 Base64 图片
ts
/**
* 获取指定秒的 Video 元素
*/
async function onVideoSeeked<R = any>(
time: number,
cb: (video: HTMLVideoElement) => Promise<R>,
): Promise<R> {
const video = document.createElement('video')
video.currentTime = time
video.muted = true
video.src = src
video.autoplay = true
video.crossOrigin = 'anonymous'
/** 隐藏 Video 元素 */
Object.assign(video.style, {
position: 'absolute',
top: '-9999px',
transform: 'translate(-9999px)',
})
document.body.appendChild(video)
return new Promise<R>((resolve, reject) => {
video.oncanplay = async () => {
const res = await cb(video)
resolve(res)
document.body.removeChild(video)
}
video.onerror = (err) => {
reject(err)
document.body.removeChild(video)
}
})
}这个方案非常的简单,很符合直觉。但是它的所有逻辑都是在主线程上执行的
当你需要截取大量的图片时,这会阻塞页面渲染,造成用户操作卡顿
因此需要新的方案,WebWorker 实现多线程,但是 WebWorker 不能用于操作 DOM,所以我们是处理截图时用到它而已
新的解决方案:Web Worker + ImageCapture API
为了解决性能瓶颈,我采用了现代浏览器提供的Web Worker 和 ImageCapture API,将繁重任务转移到后台线程处理,其核心流程如下:
-
任务分发 :主线程获取视频文件(或 URL)和需要截取的时间的 ImageBitmap ,通过
postMessage发送给Web Worker。tsasync function genWorkerData(video: HTMLVideoElement): Promise<CaptureVideoFrameData> { const stream = video.captureStream() as MediaStream const track = stream.getVideoTracks()[0] const imageCapture = new ImageCapture(track) const imageBitmap = await imageCapture.grabFrame() const timestamp = video.currentTime return { imageBitmap, timestamp, mimeType: opts.mimeType, quality: opts.quality, } } -
零拷贝传输 :
ImageBitmap是一个"可转移对象" (Transferable Object)。当 Worker 将ImageBitmap传回主线程时,浏览器执行的是所有权的转移,而不是数据的复制。这个过程几乎是瞬时的(零拷贝),极大地降低了线程间通信的成本。 -
数据转换
Web Worker收到ImageBitmap后,创建离屏Canvas(OffscreenCanvas),这是在Web Worker中使用的 Canvas,并绘制ImageBitmap,然后调用convertToBlob方法,将ImageBitmap转换为Blob,最后将Blob传回主线程。tsasync function getCaptureFrame(videoData: CaptureVideoFrameData) { const { imageBitmap, timestamp, mimeType, quality } = videoData const canvas = new OffscreenCanvas(imageBitmap.width, imageBitmap.height) const ctx = canvas.getContext('2d')! ctx.drawImage(imageBitmap, 0, 0) return new Promise<ArrayBuffer>((resolve, reject) => { canvas.convertToBlob({ type: mimeType, quality }) .then(async (blob) => { const buffer = await blob.arrayBuffer() imageBitmap.close() resolve(buffer) }) .catch(reject) }) }
这个方案相比其他方式,优势是全方位的。并且我也写兼容老的浏览器的代码,他会自动检测兼容性实现优雅降级。
它不仅在性能上远超传统 DOM 方案,也比 ffmpeg.wasm 方案更轻量、启动更快,是浏览器内视频截图场景的"最优解"。
💡 如何让一张图片 "灰飞烟灭",像沙子一样飘散?
电影中灭霸打响指把人"化作尘埃"的特效非常震撼。ImgToFade 功能在网页上复现了类似的效果。
这个效果的核心思想是:逐帧地将原图的像素点移除,并在移除的位置上创建一个粒子,让这个粒子朝特定方向运动,从而模拟出"灰飞烟灭"的视觉效果。

下面是详细的步骤分解和代码解释:
1. 准备工作:初始化两个 Canvas
为了实现这个效果,我们需要两个 <canvas> 元素,但其中只有一个是用户能看到的。
- 背景 Canvas (
bgCanvas): 这是最终展示给用户的 Canvas,整个动画都在这个画板上发生。 - 图片 Canvas (
imgCvs): 这是一个在内存中创建的、用户看不见的"离屏" Canvas。它的尺寸和图片完全一样,我们用它来"存放"原始图片数据。之后所有的像素操作(比如"抹除"像素)都在这个看不见的 Canvas 上进行,处理完后再把它"贴"到背景 Canvas 上。
typescript
/**
* 让图片灰飞烟灭效果
* @param bgCanvas 背景画布
* @param opts 配置
*/
export async function imgToFade(bgCanvas: HTMLCanvasElement, opts: ImgToFadeOpts) {
// ... 初始化参数
const { width, height, imgWidth, imgHeight, img } = await checkAndInit(opts)
// 1. 获取用户可见的背景 Canvas 的上下文
const bgCtx = bgCanvas.getContext('2d')!
bgCanvas.width = width
bgCanvas.height = height
// 2. 创建用户看不见的、用于处理图片像素的 Canvas
const { cvs: imgCvs, ctx: imgCtx } = createCvs(
imgWidth,
imgHeight,
)
// 3. 将原始图片绘制到这个看不见的 Canvas 上
imgCtx.drawImage(img, 0, 0, imgWidth, imgHeight)
// ... 后续步骤
}2. 记录并管理所有像素点
为了能随机地从图片上拾取像素点,我们需要先"登记"图片上所有的像素。
- 我们创建了一个
pixelIndexs数组,它从0开始,一直到图片总像素数 - 1,按顺序记录了每个像素的索引。这个数组是后续随机选取像素的关键。 - 我们使用
getImageData获取了图片完整的像素数据 (imgData),这是一个包含了所有像素RGBA(红、绿、蓝、透明度)值的一维大数组。
ts
const imgData = imgCtx.getImageData(0, 0, imgWidth, imgHeight)
/** 创建一个数组,用来记录图片上每一个像素的索引 */
const pixelIndexs: number[] = []
/** 放入每个像素,RGBA 所以是 `imgData.data.length / 4` 四个点代表一个像素 */
for (let i = 0; i < imgData.data.length / 4; i++) {
pixelIndexs.push(i)
}3. 启动动画循环 (drawPoint)
这是整个效果的核心驱动。我们使用 requestAnimationFrame(drawPoint) 来创建一个高频的循环(通常是每秒 60 帧),每一帧都会执行 drawPoint 函数里的内容。
在每一帧里,我们都做四件大事:
- 清空背景 :用指定的背景色 (
bgc) 把背景 Canvas 整个覆盖一遍,清除上一帧的画面。 - 绘制"残缺"的图片 :把那个看不见的、像素正在被逐渐擦除的 图片 Canvas (
imgCvs) 绘制到背景 Canvas 的中央。因为imgCvs上的像素越来越少,所以看起来图片就在慢慢消失。 - 创建和销毁粒子 :调用
createAndDelParticle函数,从原图上随机挑选几个像素点,把它们变成粒子。 - 绘制和移动粒子 :调用
drawDestroyBalls函数,让所有已经创建的粒子动起来。
typescript
drawPoint()
function drawPoint() {
// 1. 用背景色清空整个背景 Canvas
bgCtx.fillStyle = bgc
bgCtx.fillRect(0, 0, width, height)
// 2. 将被处理过的、残缺的图片 Canvas 绘制到背景上
bgCtx.drawImage(
imgCvs,
...getCenterPos(), // 计算居中位置
imgWidth,
imgHeight,
)
// 3. 创建新的粒子,并从图片 Canvas 上擦除对应像素
createAndDelParticle(ballCount)
// 4. 更新所有粒子的位置并绘制它们
drawDestroyBalls()
// 5. 请求浏览器在下一帧继续调用 drawPoint,形成循环
requestAnimationFrame(drawPoint)
}4. 像素的"湮灭"与粒子的"创生" (createAndDelParticle)
这个函数是效果的魔法所在。在动画的每一帧里,它都会被调用,以执行以下操作:
- 第一步:随机选点 。通过
getXY函数从pixelIndexs数组中随机取一个索引,这就代表一个随机的像素点。同时计算出这个像素在图片上的(x, y)坐标。 - 第二步:获取颜色 。用上一步得到的坐标从
imgData中找到这个像素的RGBA颜色。 - 第三步:创建粒子 。在背景 Canvas 上,于像素点原来的位置创建一个
Ball对象(也就是粒子),并把刚才获取到的颜色赋给它。然后把它存入destroyBalls数组统一管理。 - 第四步:擦除原图像素 。这是最关键的一步。我们在 图片 Canvas (
imgCvs) 上,使用clearRect(x, y, 1, 1)把刚刚那个像素点精确地擦除掉(变成透明)。同时,从pixelIndexs数组中移除这个像素的索引,确保它不会被再次选中。 - 加速消失(小技巧) :为了让图片消失得更快,代码里还有一个
extraDelCount的逻辑。它会额外再随机擦除掉一些像素,但并不会为这些被额外擦除的像素创建粒子。这是一种视觉上的"作弊",让效果更明显。
typescript
import { createCvs, getImg, getPixel } from '@jl-org/tool'
/** 获取随机像素点坐标 */
function getXY(): [x: number, y: number, index: number] {
/** 随机像素点索引 */
const index = Math.floor(Math.random() * pixelIndexs.length)
/** 获取随机像素点 */
const pixelIndex = pixelIndexs[index]
/** 数组位置对宽度取余,获取行 */
const x = pixelIndex % imgWidth
/** 数组位置整除宽度,获取列 */
const y = Math.floor(pixelIndex / imgWidth)
return [x, y, index]
}
/**
* 清除某个像素点 并删除像素点数组
*/
function clearPixel(x: number, y: number, index: number) {
/** 在图片 Canvas 上擦除一个 1x1 的像素 */
imgCtx.clearRect(x, y, 1, 1)
/** 从像素索引数组中删除,防止重复选取 */
pixelIndexs.splice(index, 1)
}
function createAndDelParticle(size: number) {
for (let i = 0; i < size; i++) {
// 1. 随机获取一个像素点的坐标和它在索引数组中的位置
const [x, y, index] = getXY()
// 2. 获取该像素的颜色
const [R, G, B, A] = getPixel(x, y, imgData)
const color = `rgba(${R}, ${G}, ${B}, ${A})`
// 3. 在原位置创建一个粒子
const point = new Ball({
x: x + centerX, // centerX 是居中偏移量
y: y + centerY, // centerY 是居中偏移量
// ... 其他粒子属性
})
destroyBalls.push(point)
// 4. 从图片 Canvas 上清除这个像素
clearPixel(x, y, index)
// 5. (作弊) 额外再清除一些像素,但不为它们创建粒子
for (let i = 0; i < extraDelCount; i++) {
const [x, y, index] = getXY()
clearPixel(x, y, index)
}
}
}5. 粒子的运动与消亡 (drawDestroyBalls)
这个函数负责管理所有"飞出去"的粒子。每一帧,它都会遍历 destroyBalls 数组里的所有粒子:
- 更新位置 :修改每个粒子的
x和y坐标,让它向右上方移动。这里加了Math.random()是为了让每个粒子的运动轨迹略有不同,看起来更自然。 - 重新绘制:在新的位置上把粒子画出来。
- 生命周期管理 :当一个粒子运动了一定时间后(
ball.count > 100),就代表它已经"飞远"了,我们就会把它从destroyBalls数组中移除,以节省性能。
typescript
function drawDestroyBalls() {
for (let i = 0; i < destroyBalls.length; i++) {
const ball = destroyBalls[i]
// 1. 更新粒子的位置,向右上方随机移动
ball.x += Math.random() * speed
ball.y -= Math.random() * speed
ball.count++
// 2. 在新位置绘制粒子
ball.draw()
// 3. 如果粒子"寿命"到了,就从数组中移除
if (ball.count > 100) {
destroyBalls.splice(i, 1)
}
}
}总结
整个过程就像这样:
- 把一张完整的图片复制到一块隐藏的画板上。
- 开始一个动画循环,每一轮都:
- 在屏幕上涂一层背景色。
- 从隐藏的画板上随机抠掉几个像素点。
- 在被抠掉的像素点原来的位置,生成几个带有同样颜色的、会动的小点(粒子)。
- 把被抠过的、残缺不全的画板内容,贴到屏幕中央。
- 让所有小点都飞起来。
- 不断重复这个过程,隐藏画板上的像素越来越少,飞出去的粒子越来越多,直到画板完全变透明,就形成了"灰飞烟灭"的效果。
💡 如何打造一个功能强大的 "在线画板"?
除了视觉特效,这个库的另一个重要方向是"工具"。NoteBoard (画板) 就是一个集大成者。它不仅仅是画几条线那么简单。

功能特性
- 多模式绘图 :
- 画笔模式 (
draw): 进行自由涂鸦。 - 橡皮擦模式 (
erase): 擦除画笔内容。 - 图形绘制 : 支持绘制 矩形 (
rect)、圆形 (circle)、箭头 (arrow) 等。
- 画笔模式 (
- 画布操作 :
- 拖拽 (
drag): 平移整个画布。 - 缩放: 通过鼠标滚轮以光标为中心进行缩放。
- 右键拖拽: 支持在任意模式下按住鼠标右键进行拖拽。
- 拖拽 (
- 历史记录 :
- 撤销 (
undo): 撤销上一步操作。 - 重做 (
redo): 恢复已撤销的操作。
- 撤销 (
- 图层管理 :
- 采用分层设计,背景图片 和 画笔/图形 分别绘制在不同的 Canvas 上,互不影响。
- 支持动态添加更多 Canvas 图层。
- 图像处理 :
- 绘制背景图 : 可将图片绘制到底层画布,并支持 自适应 (
autoFit) 和 居中 (center) 显示。 - 导出图像 :
- 可导出任意指定图层 (如仅导出画笔内容)。
- 可将所有图层合并导出为一张图片。
- 支持仅导出图片内容区域,并还原为原始分辨率。
- 绘制背景图 : 可将图片绘制到底层画布,并支持 自适应 (
- 高可定制性 :
- 支持自定义画布尺寸、缩放范围、画笔样式 (颜色、粗细、线帽)、混合模式等。
- 提供丰富的生命周期钩子函数 (
onMouseDown,onDrag,onUndo等)。
- 高性能 :
- 针对高分屏 (HiDPI) 进行优化,绘图清晰不模糊。
- 路径历史记录模式性能高,内存占用低。
架构设计
GUI 最适合的就是面向对象,所以我采用抽象类的方式开发
第一步:奠定基石 - 分层画布架构
一个好的画板,首先要解决的问题是 "关注点分离"。如果用户在画板上绘制了一张背景图,然后开始在上面涂鸦。当用户想擦除涂鸦时,我们肯定不希望连背景图也一起擦掉。
解决这个问题的最佳方案就是 分层画布。
我们的 NoteBoard 采用了这个核心思想。在 NoteBoardBase 这个抽象基类中,我们创建了至少两个 <canvas> 元素:
imgCanvas: 图片层。专门用来绘制背景图,它位于最底层。canvas: 笔迹层。用于自由绘制、图形和橡皮擦,它位于上层。
这两个 canvas 的尺寸完全相同,并通过 CSS 的 position: absolute 精确地叠放在一起。
typescript
/** 在 NoteBoardBase.ts 的构造函数中 */
export abstract class NoteBoardBase {
el: HTMLElement
canvas = document.createElement('canvas') // 笔迹层
ctx = this.canvas.getContext('2d')!
imgCanvas = document.createElement('canvas') // 图片层
imgCtx = this.imgCanvas.getContext('2d')!
constructor(opts: NoteBoardOptions) {
this.el = opts.el
/** 设置 z-index 来控制堆叠顺序 */
this.canvas.style.zIndex = '20' // 笔迹层在上
this.imgCanvas.style.zIndex = '10' // 图片层在下 (假设)
/** 将它们都添加到用户提供的容器中 */
this.el.appendChild(this.imgCanvas)
this.el.appendChild(this.canvas)
// ... 其他初始化
}
}这么做的好处是什么?
- 操作独立 :我们可以独立地清空笔迹层 (
canvas) 而完全不影响图片层 (imgCanvas)。 - 性能优化 :背景图通常是静态的,绘制一次后就不再变化。将其放在独立的
imgCanvas中,意味着我们不需要在每次笔迹更新时都重绘一遍昂贵的背景图。 - 高扩展性:未来如果想增加更多图层,比如一个专门的"文本层",只需按照同样模式添加一个新的 canvas 即可。
第二步:攻克难关 - 实现撤销与重做
这是画板最核心、也最有趣的功能。我们有两种主流的实现思路,NoteBoard 项目将它们都实现了,分别对应 NoteBoardWithBase64 和 NoteBoard 两个类。
方案一:快照法 (简单粗暴,但有效)
这是 NoteBoardWithBase64 采用的策略。
原理 : 在每一次用户完成操作后 (例如,一笔画完后鼠标抬起),我们立刻将整个笔迹层 canvas 的内容转换成一张 base64 格式的图片,并将其作为一个"历史快照"存储起来。
由于历史记录采用存储 base64 的原因,所以没有实现绘制形状(圆形、矩形...),因为绘制形状时需要在每一次鼠标移动时重新绘制整个画布,但是重画 base64 性能很差
typescript
export class NoteBoardWithBase64 extends NoteBoardBase {
// history 是一个支持撤销/重做的链表结构
history = createUnReDoList<string>()
onMouseup = (e: MouseEvent) => {
// ...
this.isDrawing = false
this.addNewRecord() // 添加新纪录
}
async addNewRecord() {
/** 将当前 canvas 内容导出为 base64 */
const base64 = await this.exportMask()
/** 添加到历史记录 */
this.history.add(base64)
}
async undo() {
this.history.undo(async (base64) => {
/** 清空当前画布 */
this.clear(false)
if (base64) {
/** 从历史记录中取出上一张快照图片 */
const img = await getImg(base64)
/** 将快照重新绘制到画布上,实现"撤销" */
this.ctx.drawImage(img, 0, 0)
}
})
}
}- 优点: 实现逻辑极其简单,撤销/重做的性能是恒定的,无论画布内容多复杂。
- 缺点 : 内存开销巨大!如果画布很大,历史记录很多,会迅速消耗掉大量内存。同时,所有内容都被"压平"了,我们丢失了对单个图形或笔画的控制能力。
方案二:指令法 (优雅,且强大)
这是 NoteBoard 类采用的策略,它借鉴了 指令模式 (Command Pattern) 的思想。
原理 : 我们不记录像素,而是记录用户的 "意图" 或 "指令"。
- 用户画了一根线?我们记录下这根线所有关键点的坐标。
- 用户画了一个矩形?我们记录下这个矩形的
[x, y, width, height]以及它的颜色、线宽等属性。
typescript
/** 每一笔的路径记录结构 */
export type RecordPath = {
path: {
moveTo: [number, number]
lineTo: [number, number]
}[]
canvasAttrs: CanvasAttrs // 这笔的样式
shapes: BaseShape[] // 这笔包含的图形
mode: Mode
}
export class NoteBoard extends NoteBoardBase {
history = new UnRedoLinkedList<RecordPath[]>()
onMousedown = (e: MouseEvent) => {
/** 每次下笔,就创建一个新的、空的记录节点 */
this.history.add([])
this.isDrawing = true
}
onMousemove = (e: MouseEvent) => {
if (!this.isDrawing)
return
const { offsetX, offsetY } = e
// ... 绘制逻辑 ctx.lineTo(...) ...
/** 将"指令" (坐标) 记录下来 */
const lastRecord = this.history.curValue
lastRecord[lastRecord.length - 1].path.push({
moveTo: [this.drawStart.x, this.drawStart.y],
lineTo: [offsetX, offsetY],
})
this.drawStart = { x: offsetX, y: offsetY }
}
undo() {
// 1. 指针移动到上一个历史状态
this.history.undo()
// 2. 清空画布
this.clear(false)
// 3. 重绘!
// - 遍历当前历史状态中所有的 shapes,重绘所有图形
// - 遍历当前历史状态中所有的 path,重绘所有笔迹
this.drawRecord()
}
}- 优点 : 内存占用极低。非常灵活,理论上我们可以对历史中的任意一个"指令"进行修改,比如选中某个画好的图形并移动它。
- 缺点: 实现更复杂。每次撤销/重做都需要清空画布并完全重绘一次,如果场景中有成千上万个对象,可能会有性能瓶颈 (但在画板场景下通常足够快)。
对于一个需要长久发展的项目,指令法无疑是更优越的选择。
第三步:丝滑的体验 - CSS Transform 实现缩放与拖拽
如何实现画布的缩放和拖拽?
新手的第一反应可能是使用 Canvas 的 API:ctx.scale() 和 ctx.translate()。但这有一个致命缺陷:这些变换会 直接影响坐标系 。你必须在每次绘制时都小心翼翼地计算变换后的坐标,而且每次变换后都需要 重绘整个场景,这会导致性能问题和卡顿感。
NoteBoard 采用了更现代、更高性能的方案:CSS Transform。
我们完全不碰 Canvas 的变换 API。缩放和拖拽的逻辑仅仅是去修改 canvas 和 imgCanvas 这两个 HTML 元素的 CSS 样式。
typescript
class NoteBoardBase {
// ...
async setTransform() {
const { canvas, imgCanvas } = this
/** 以鼠标位置为变换中心 */
const transformOrigin = `${this.mousePoint.x}px ${this.mousePoint.y}px`
/** 组合 scale 和 translate */
const transform = `scale(${this.scale}) translate(${this.translateX}px, ${this.translateY}px)`
/** 同时应用到两个图层上 */
canvas.style.transformOrigin = transformOrigin
canvas.style.transform = transform
imgCanvas.style.transformOrigin = transformOrigin
imgCanvas.style.transform = transform
}
}为什么这会如此丝滑? 因为我们将繁重的变换计算任务交给了浏览器的渲染引擎。浏览器可以利用 GPU 硬件加速 来处理 CSS Transform,这个过程发生在独立的合成层 (Compositor Layer) 上,完全不阻塞主线程,也不会引起整个 Canvas 的重绘。结果就是如黄油般顺滑的缩放和拖拽体验。
🛠️ 如何在你的项目中使用?
我已经把它发布到了 NPM,你可以非常方便地在你的项目中使用它。
安装依赖:
bash
# pnpm
pnpm add @jl-org/cvs
# npm
npm i @jl-org/cvs如果你想探索所有的 Demo,可以把项目克隆到本地运行。
本地开发:
bash
# 克隆仓库
git clone https://github.com/beixiyo/jl-cvs.git
# 安装依赖
pnpm install
# 启动测试页面
pnpm test访问 http://localhost:5173 即可看到所有效果的演示。