这个文档用来记录 Nvidia Orin DK Ubuntu 20.04 刷机 + CUDA TensorRT + 硬盘扩容 + ROS 安装 + OpenCV-CUDA + Ollama + Yolo11 一站式解决方案,文档包含了以下内容:
- OS:Ubuntu 20.04;
- JetPack:5.1.5;
- CUDA:11.4;
- cuDNN:8.6.0;
- OpenCV:4.5.4 +;
- ROS:ROS1 noetic;
- RealSense:D435i、D456、L515;
【Note】:从目前的测试结果来看 Ubuntu 20.04 + JetPack 5.X 是最稳定的刷机系统,Ubuntu 22.04 和 JetPack 6.X 都存在或多或少的 Bug,主要是宿主机上下载一些库容易失败,因此这里只记录 20.04 + 5.1.5 这个版本。
这篇文章在撰写过程中参考了多篇其他人的博客,主要如下:
- Jetpack 与 Ubuntu 对应关系:https://blog.csdn.net/tw_fae/article/details/139299659
- Orin 刷机:https://blog.csdn.net/weixin_53776054/article/details/128552701;
- Jtop 安装:https://blog.csdn.net/FREEDOM_X/article/details/139979294;
- 挂载 SSD:https://zhuanlan.zhihu.com/p/624623044;
- Vim 配置:https://blog.csdn.net/ZXDDBK/article/details/108077835;
- OpenCV-CUDA:https://blog.csdn.net/weixin_43702653/article/details/130627605?spm=1001.2014.3001.5506;
- CUDA ARCH BIN:https://blog.csdn.net/weixin_44733606/article/details/131721081;
- APT 源密钥:https://blog.csdn.net/CCCDeric/article/details/130244386;
- ROS 安装:https://zhuanlan.zhihu.com/p/30984497406;
- RealSense SKD 安装:https://blog.csdn.net/qq_44998513/article/details/133770802;
- Yolo11 运行:https://zhuanlan.zhihu.com/p/31424403103;
我将刷机过程中用到的资源放在了我的百度网盘中,有需要的可以自行提取:
txt
链接: https://pan.baidu.com/s/1LRBc99DRv8T1ohV22QMSgA?pwd=twqm 提取码: twqm 前期准备工作
刷机需要除 Orin 以外的一些其他辅助设备,包含以下几个:
- 一台用于安装 Nvidia SDK Manager 的 Ubuntu 18.04~20.04 的宿主机,必须配备 USB 3.0 接口;
- 一个稳定的 Wifi 环境;
- 一条 USB 3.0-Type C 的数据线,用原装 Orin 盒子里的就可以;
其中宿主机的 Ubuntu 18.04 我刷了5台设备能够稳定刷机,Ubuntu 20.04 在刷特殊版本的 JetPack 时会遇到找不到包的报错,因为换了多台尝试均在同一步骤处报错,大概率是 Nvidia 下线了对应的包。
1. 安装硬盘
由于 Orin 本身自带的硬盘仅有 64 GB,安装完 CUDA 和 cuDNN 后剩余的容量不足 50 GB,因此强烈建议购买一个 M.2 的硬盘作为挂载盘,后面会教你如何用这个硬盘作为主盘。当然,如果你觉得 50 GB 的空间够你用了也可以直接跳过这一步以及后面挂载硬盘的章节。
【Note】:安装硬盘时 Orin 必须断电。
将 Orin 翻过来可以看到一个空的硬盘槽,使用螺丝刀将上面的螺丝拧下来然后新买的 M.2 硬盘插进去后再用螺丝刀紧固,我这里安装了一个 2TB 的三星 990 Pro:

【Note】:安装完硬盘后不要着急上电。
2. 宿主机上的操作
我这里使用宿主机为一台 Ubuntu 18.04 的笔记本,主要操作一共有3步骤。
2.1 更新 APT 源
首先需要更新宿主机的 APT 源,这里建议使用清华源。
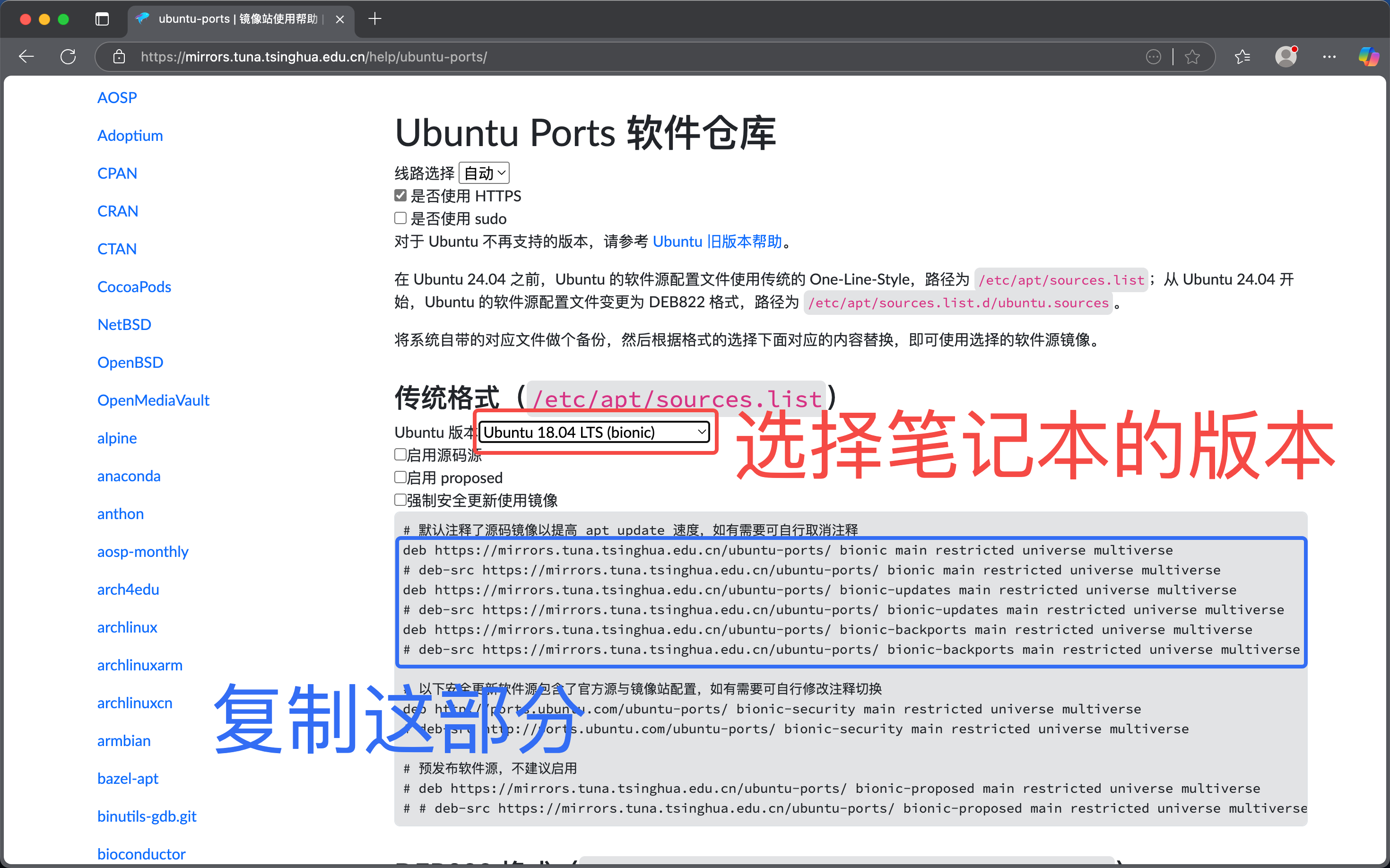
将上面的源直接覆盖到 /etc/apt/sources.list 文件中:
bash
$ sudo vim /etc/apt/sources.list
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu-ports/ bionic main restricted universe multiverse
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu-ports/ bionic-updates main restricted universe multiverse
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu-ports/ bionic-backports main restricted universe multiverse如果你没有特殊的要求建议删除掉 /etc/apt/sources.list.d/ 中的所有内容:
bash
$ sudo rm /etc/apt/sources.list.d/*然后更新 APT 源:
bash
$ sudo apt-get update【Note】:这条命令的任何报错都要立即解决,否则后面会刷到一半失败。
2.2 安装 SDK Manager
SDK Manager 是 Nvidia 为端侧设备提供的专用刷机软件,可以通过他们官网链接下载,也可以直接从我网盘中拉一个。
- SDK Manager 下载链接:https://developer.nvidia.com/sdk-manager;
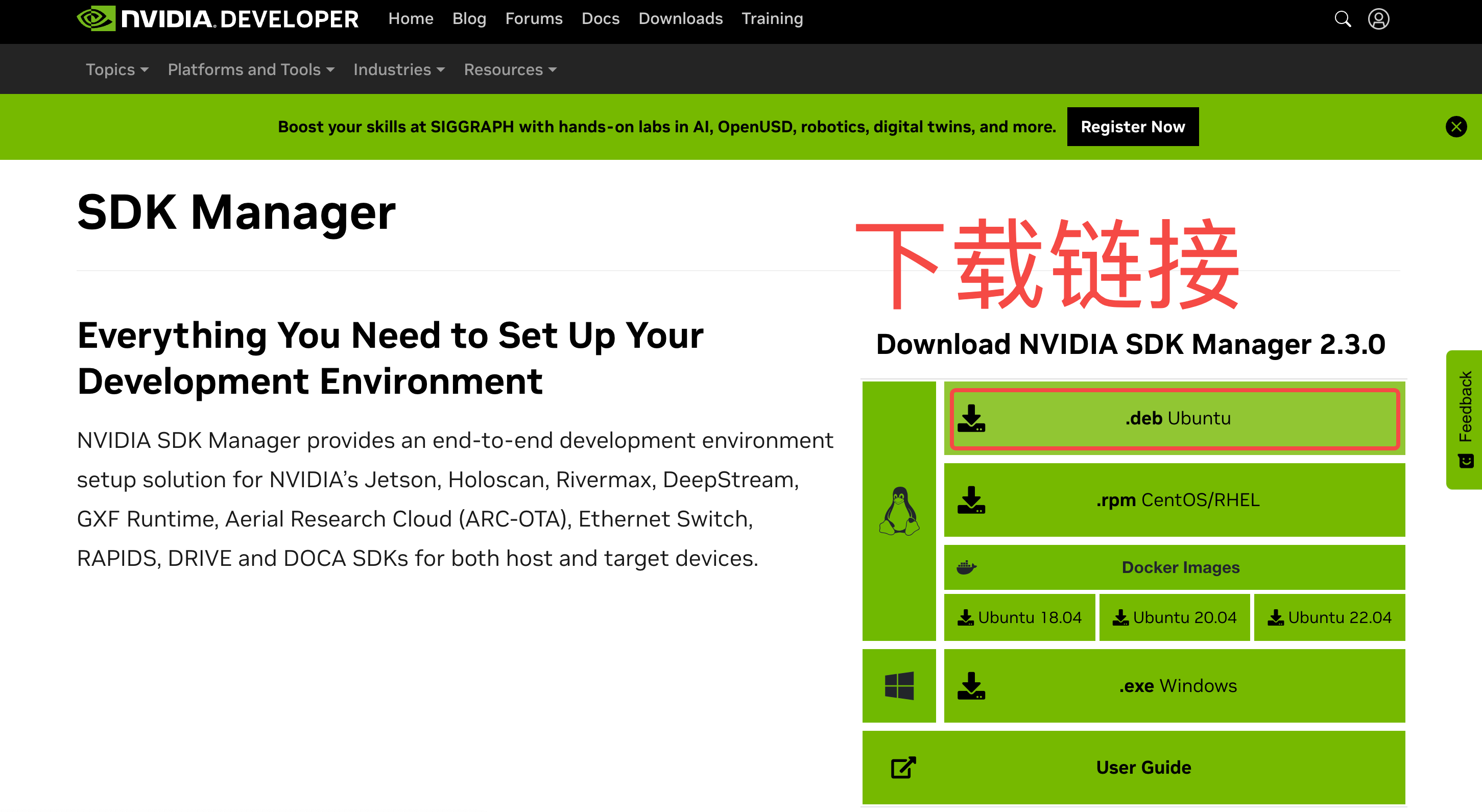
下载完成后用下面的命令安装到宿主机上,如果安装过程中报错缺少库,那就缺哪个装哪个即可:
bash
$ sudo dpkg -i sdkmanager_2.3.0-12617_amd64.deb 3. Orin 进入恢复模式
开发者套件中有一个 USB-C 的电源适配器、一条自带的 USB 3.0-TypeC 的数据线,严格按照以下顺序操作:
- 将原装的线一头插到 Orin 的 Type-C 口,另一头插到笔记本的 USB 3.0 口上;

- 按住另一个侧面的 "恢复" 按钮,三个按钮中间的那个,要一直按着:

- 接通 Type-C 电源适配器,接通前确保一直按着 "恢复" 按钮,等待电源指示灯点亮后大约 5 秒即可松开恢复按钮:

- 在供电侧连接 DP 视频线与键盘鼠标 USB-hub,由于此时处于恢复状态,因此显示器是黑屏属正常现象:

4. 初始化刷机环境
回到笔记本上按照顺序执行以下操作:
- 在终端输入 lsusb 命令,查看 7023 NVidia Corp 字段是否存在,这个字段是 AGX Orin DK 版的识别码,如果不存在就重拔掉 Orin 电源并重新执行 Step3 进入 Orin 恢复模式:
bash
$ lsusb
Bus 004 Device 001: ID 1d6b:0003 Linux Foundation 3.0 root hub
Bus 003 Device 003: ID 04f2:b6ea Chicony Electronics Co., Ltd
Bus 003 Device 002: ID 06cb:00fc Synaptics, Inc.
Bus 003 Device 004: ID 8087:0026 Intel Corp.
Bus 003 Device 006: ID 0955:7023 NVidia Corp.
Bus 003 Device 001: ID 1d6b:0002 Linux Foundation 2.0 root hub
Bus 002 Device 001: ID 1d6b:0003 Linux Foundation 3.0 root hub
Bus 001 Device 001: ID 1d6b:0002 Linux Foundation 2.0 root hub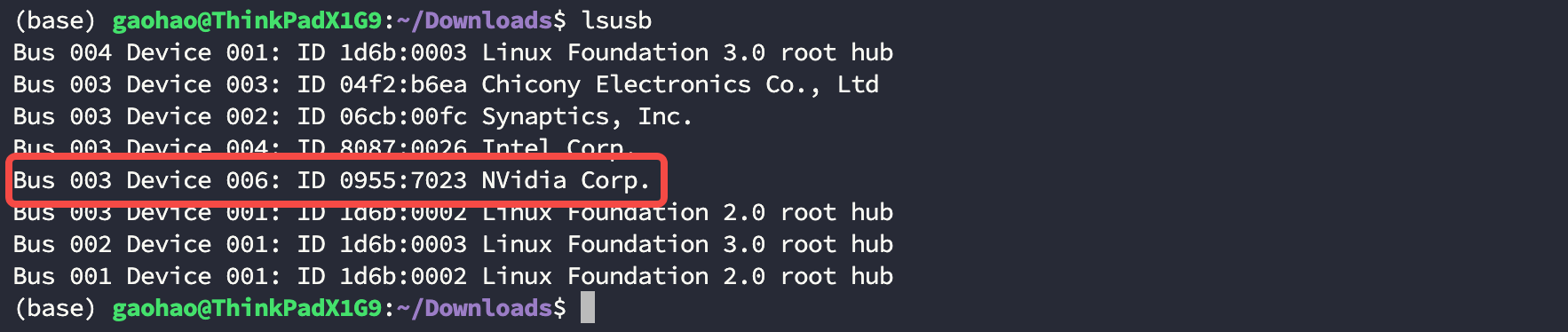
- 使用下面的命令启动 SKD Manager:
bash
$ sdkmanager软件启动后会要求登陆 Nidia 开发者帐号,按照其提示登陆即可:
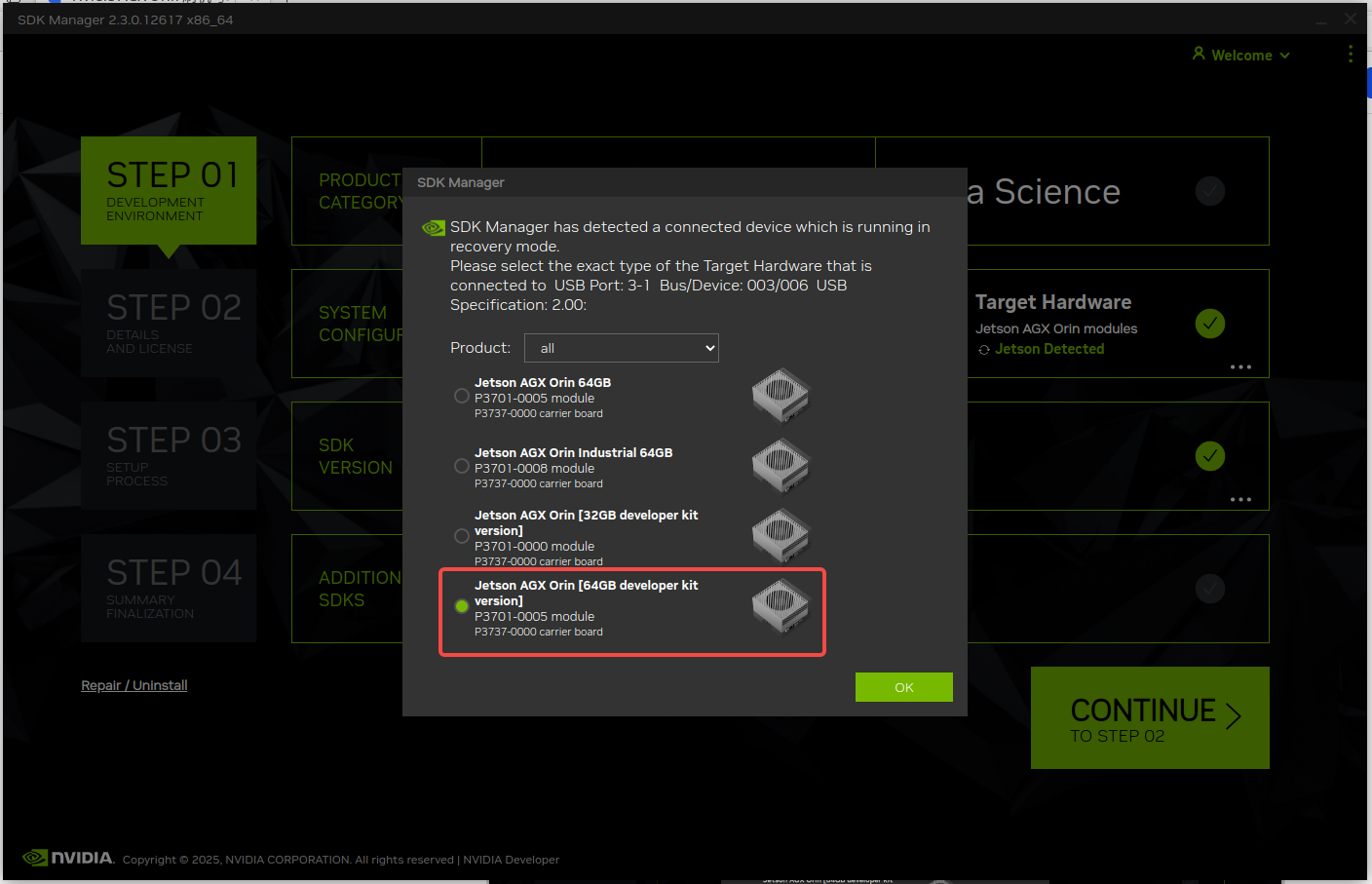
- 成功登陆后会弹出设备型号选择提示,我们所里的设备都是 DK 版本,这个版本用于测试与开发使用,你如果选择非 DK 的也是可以安装的:
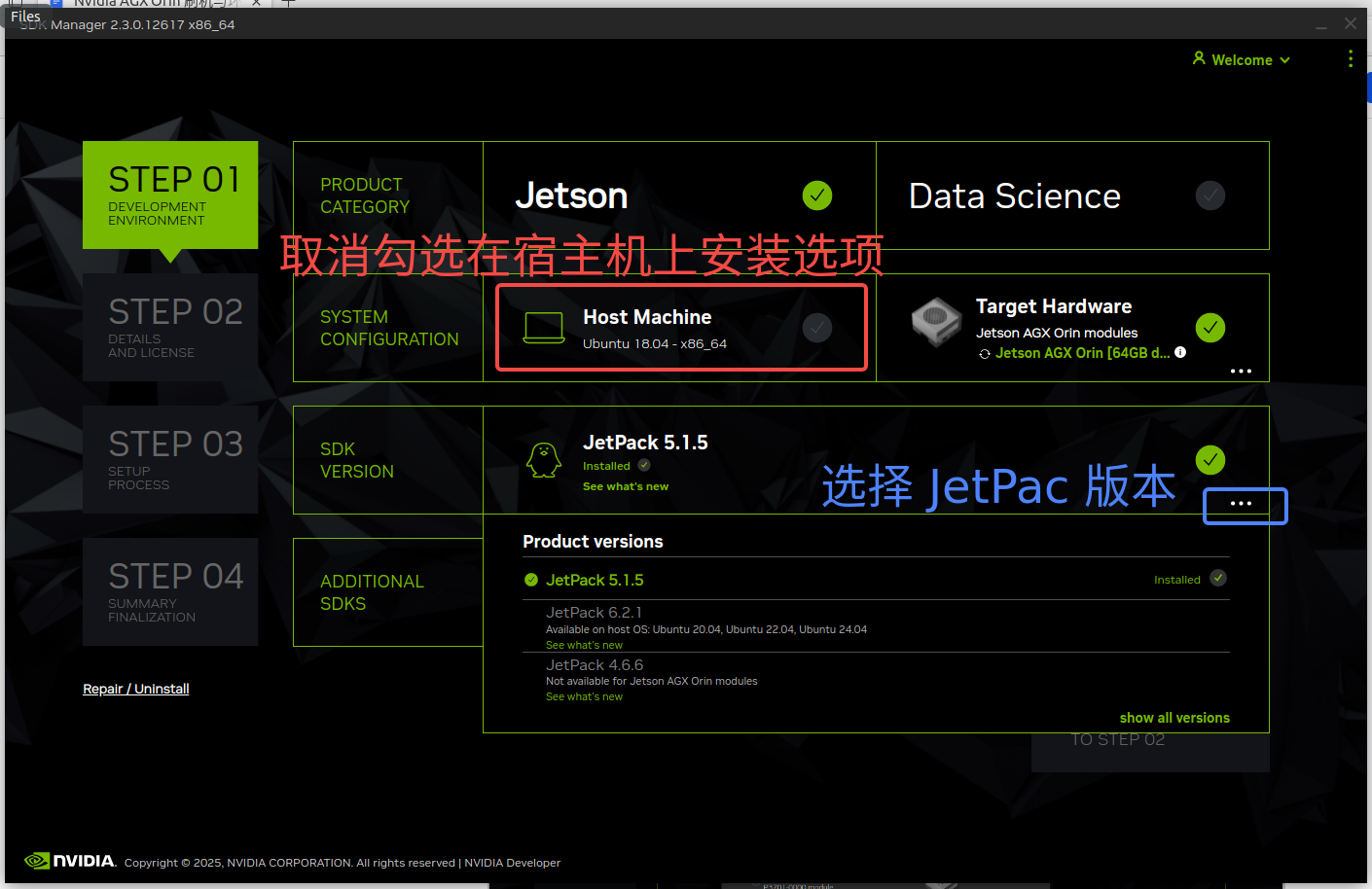
- 首先取消勾选在宿主机器上安装 JetPack,然后选择 Orin 搭载的 JetPack 版本,如果你的宿主机不是 Ubuntu 20.04 则无法安装 6.x 以上版本,确认好后点击 Continue 按钮即可,然后软件会下载一些必要的包。如果在下载过程中出现报错,那么一定是前面执行 sudo apt-get update 命令时出错了,修正后重开软件:
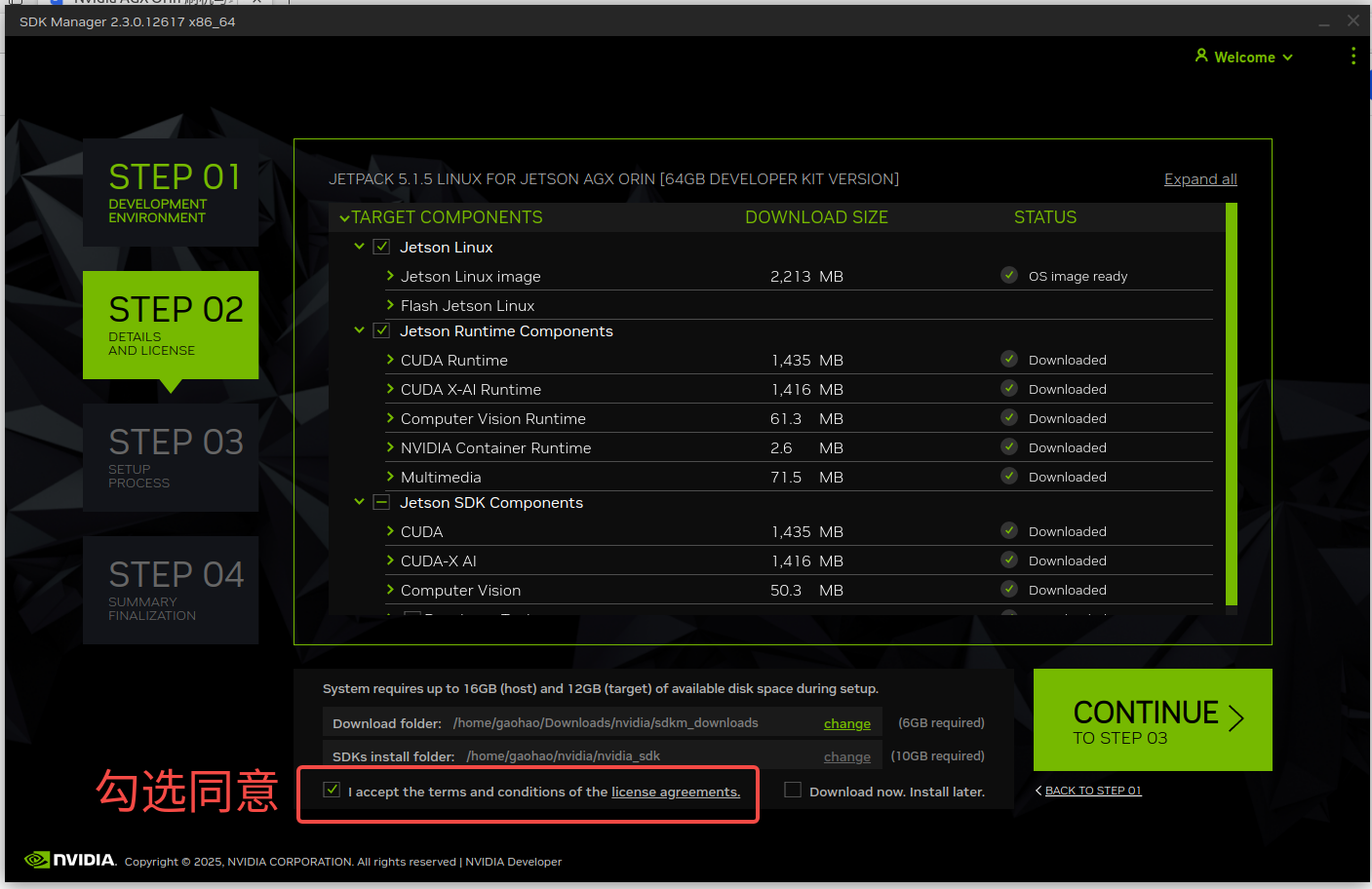
- 当所有 JetPack 包都下载好后勾选同意使用条款后点击 Continue 按钮:
- 在弹窗中设置好你的 Orin 的用户名和密码,为了所里能通用,都使用 Orin 和 Orin:
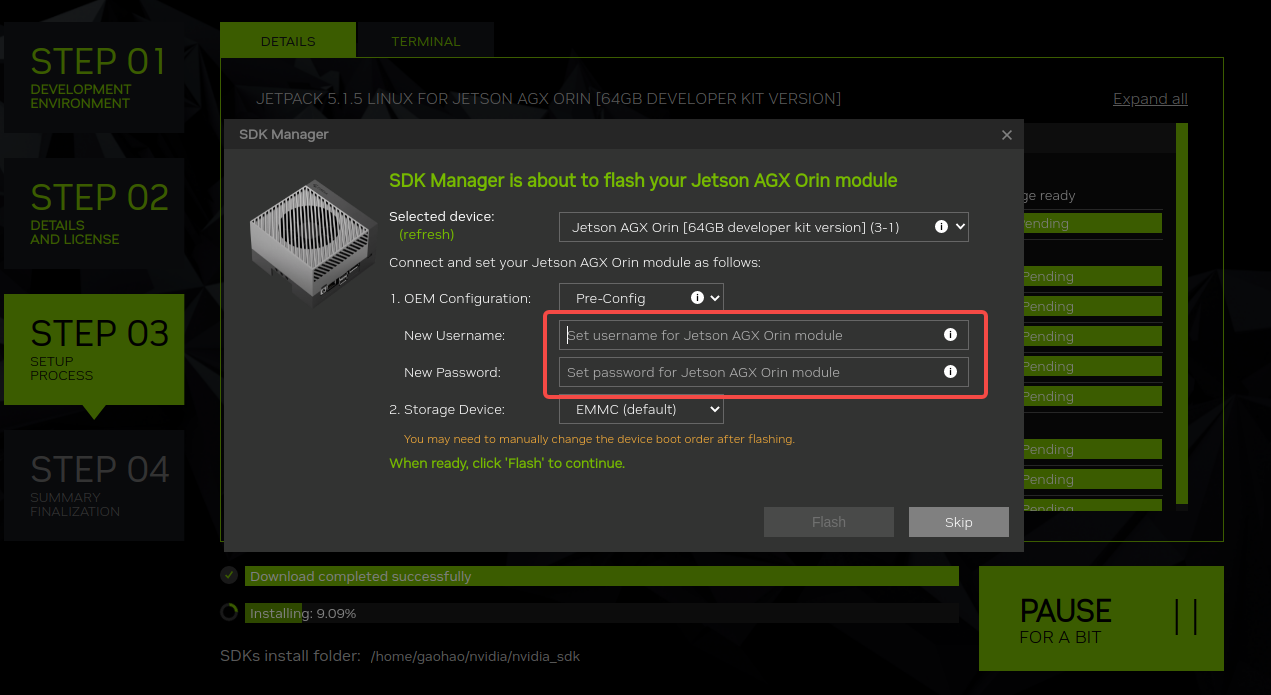
确认后就等待完成安装,这一步通常需要 10~20 分钟,在安装到一半时需要额外操作后面会提到:
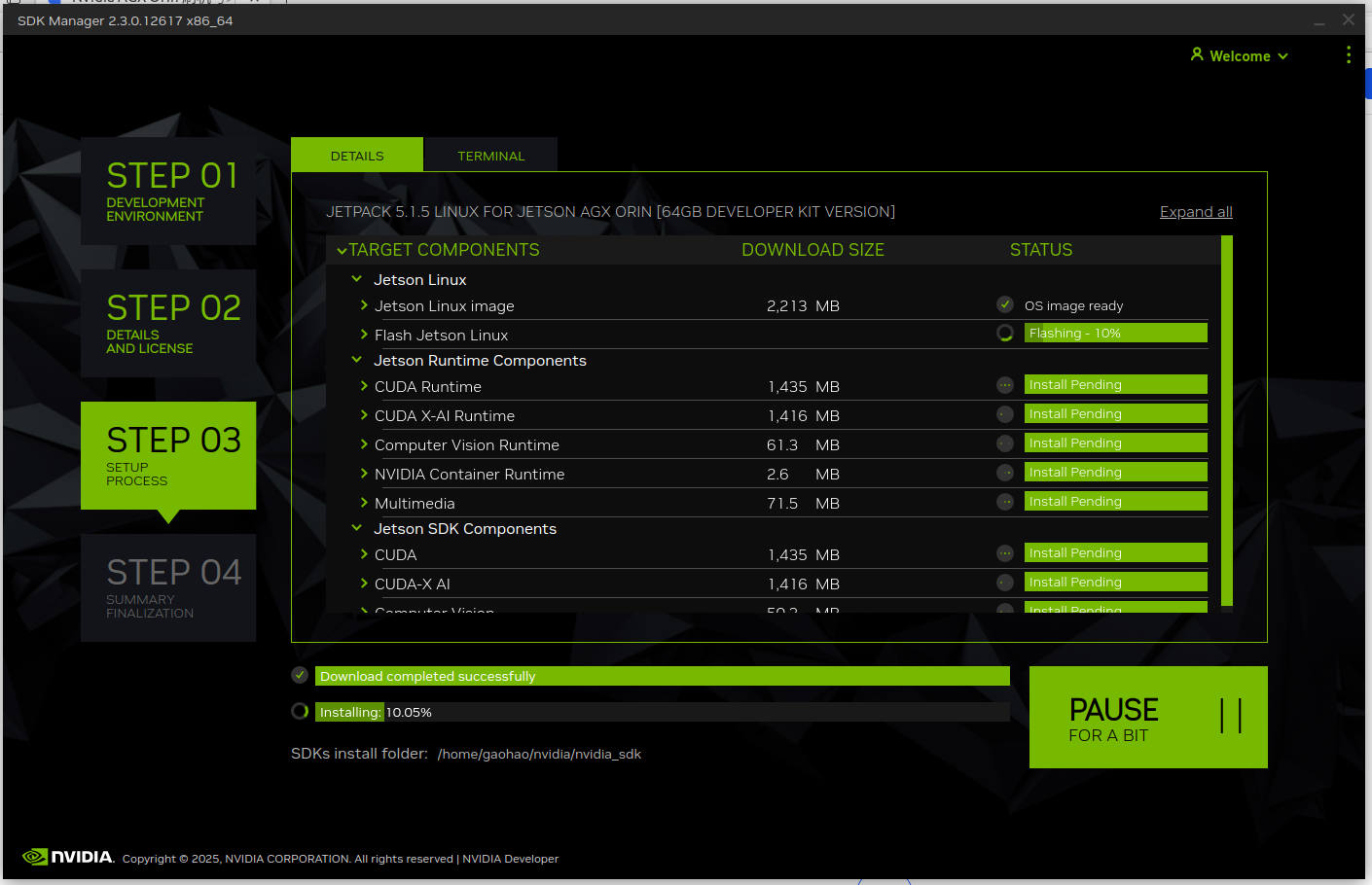
5. 更换 Orin 源并更新
在上一步安装到一半时 Orin 会自动开机并点亮显示器如下图所示,用你设置的帐号密码登陆:
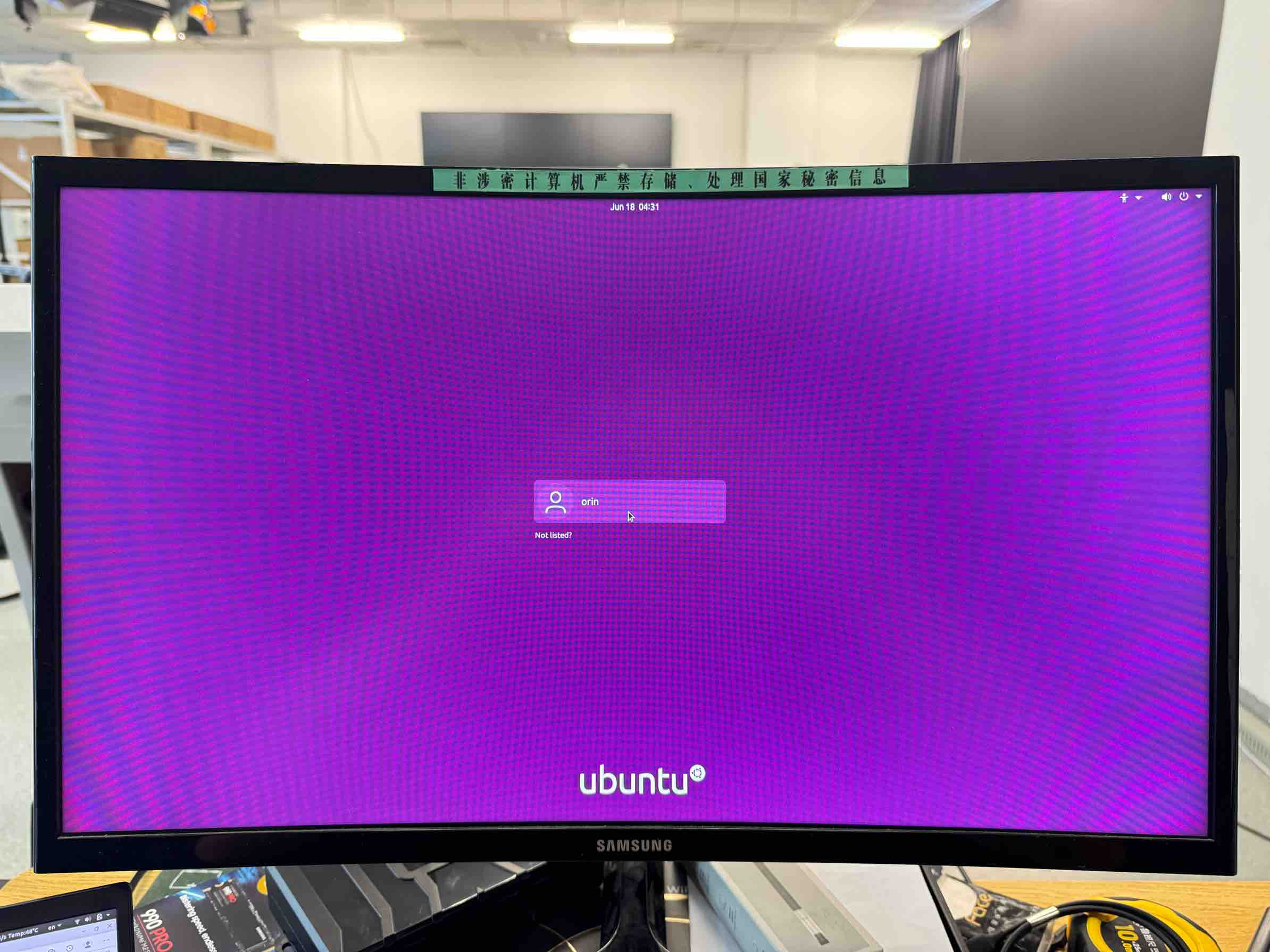
此时不要动笔记本,用键盘鼠标连接 Orin 并在 Orin 上完成以下操作:
- 将 Orin 连入可以上外网的 Wifi;
- 打开浏览器并进入到清华镜像网站:https://mirrors.tuna.tsinghua.edu.cn/help/ubuntu-ports/ ;
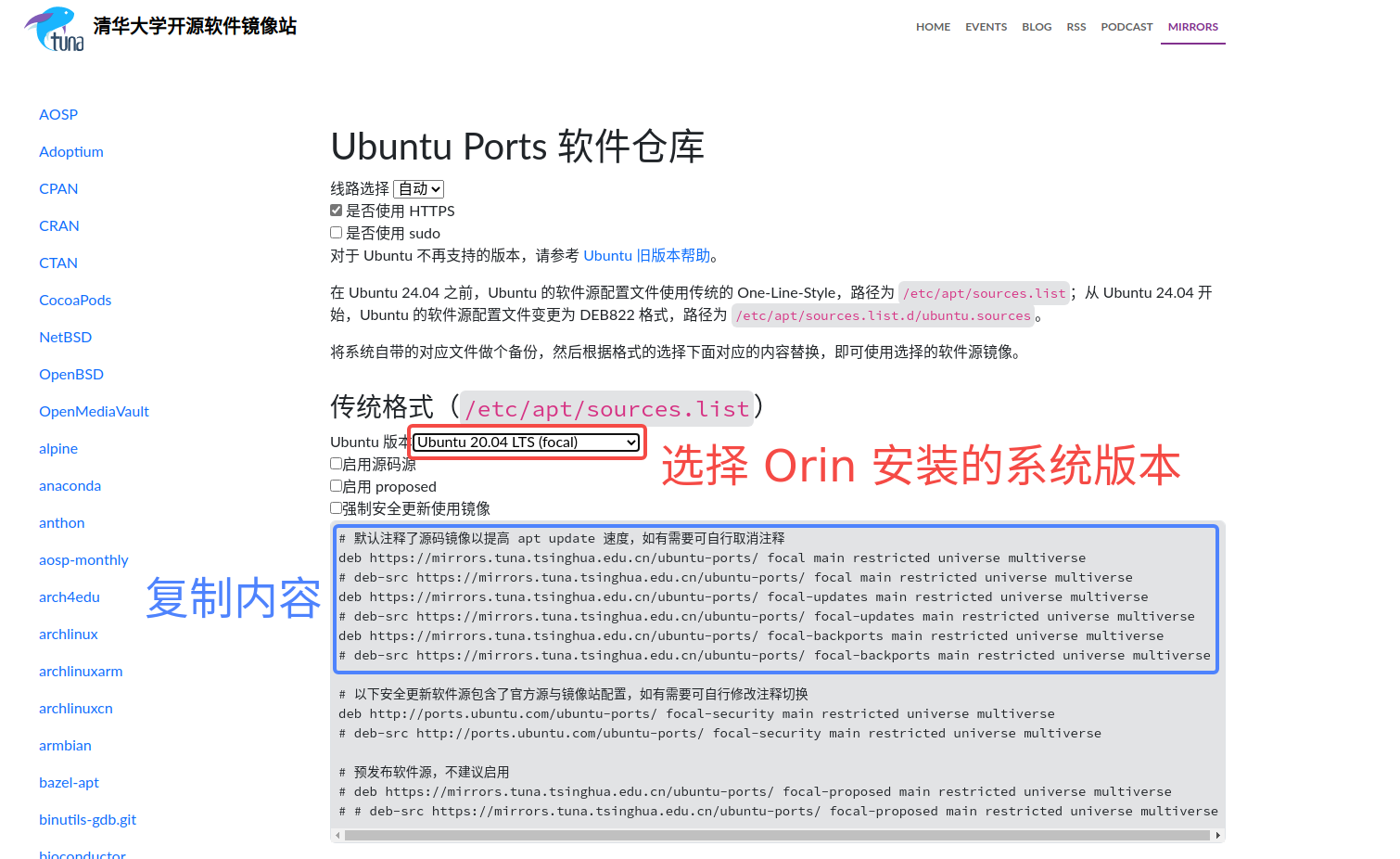
- 清空 Orin 的 /etc/apt/sources.list 文件中的内容,并将复制的源写进去;
bash
$ sudo vim /etc/apt/sources.list
bash
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu-ports/ focal main restricted universe multiverse
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu-ports/ focal-updates main restricted universe multiverse
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu-ports/ focal-backports main restricted universe multiverse- 执行更新命令,这一步会消耗大约 10 分钟左右的时间:
bash
$ sudo apt-get update
$ sudo apt-get upgrade6. 安装 CUDA、cudNN、TensorRT
在 确保 Orin 的更新操作都执行后,回到笔记本中的 SDK Manager 软件会看到新的弹窗,点击 Install 按钮安装 JetPack 自带的 CUDA、cudNN、TensorRT:
【Note】:不建议跳过这一步,因为适配 Orin 的这几个资源比较零散且对小版本敏感,最好就用 Nvidia 内置的版本;
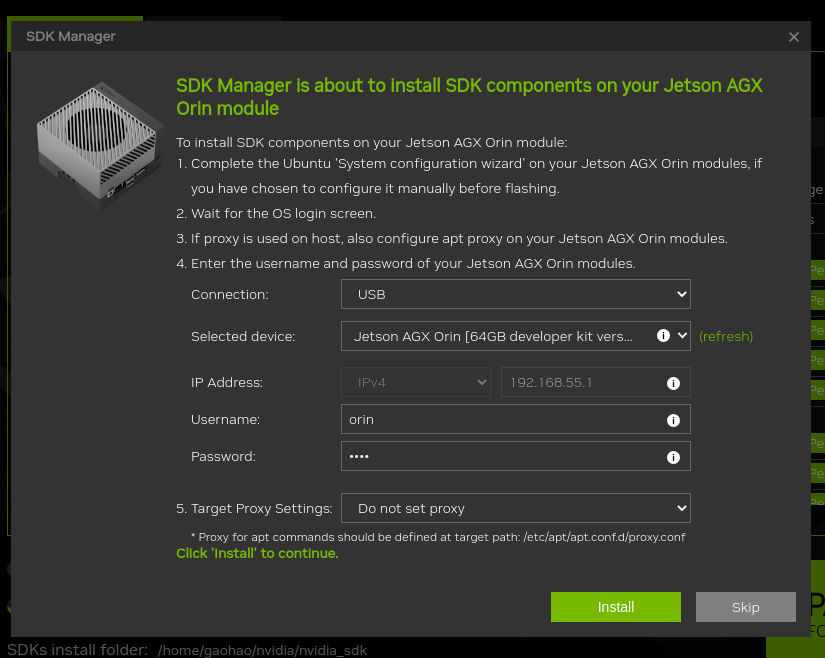
如果你出现了下面的弹窗,在确保只有 Internet Connection 和 Device image version matching requirement 这两个报错的前提下可以直接跳过检查:
【Note】:如果第二个 APT 的报错存在的话不允许跳过,多尝试几次;
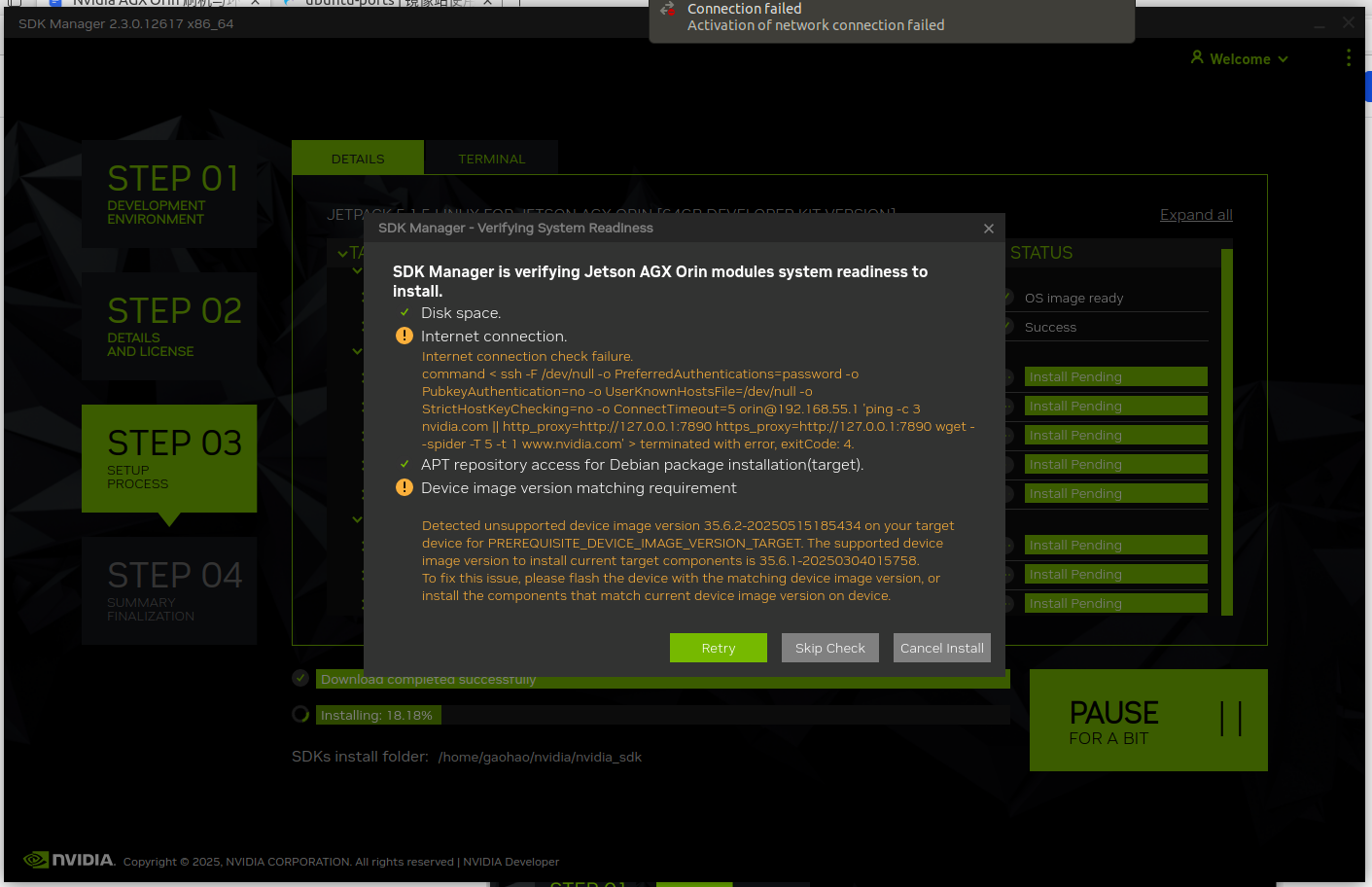
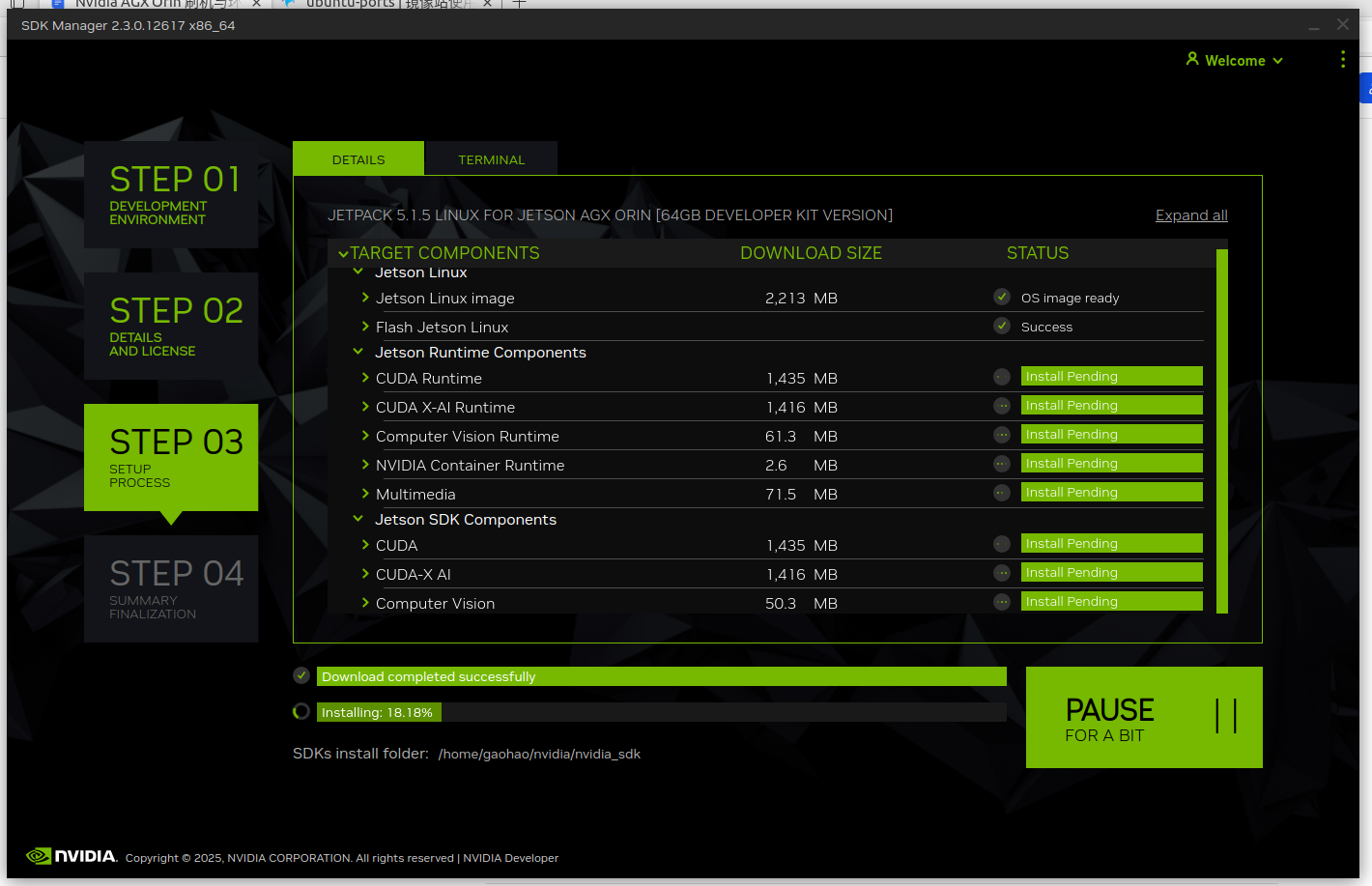
然后等待安装完成,这一步大概需要 20~30 分钟:
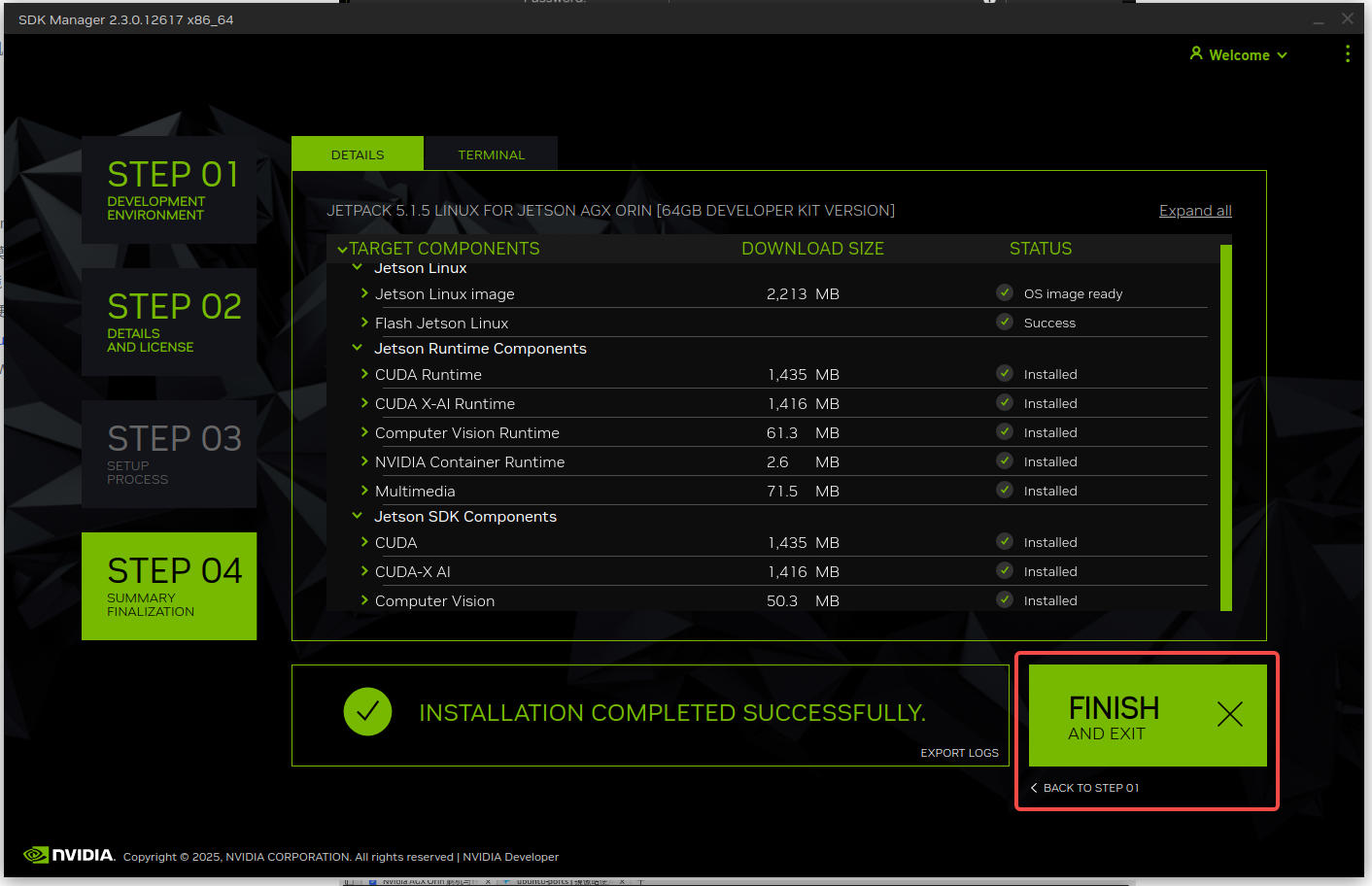
安装完成后就可以退出笔记本上的 SDK Manager 软件,后面的操作全都在 Orin 上完成,此时就可以断开笔记本和 Orin 之间的 USB 连接:
在 Orin 上 新开一个终端 并输入下面的命令检查 CUDA 是否安装成功,如果不成功则需要重新刷机:
bash
$ nvcc -V7. 安装 jtop
在 Orin 上使用下面的命令安装 jtop:
bash
$ sudo apt update
$ sudo apt install python3
$ sudo apt install python3-pip
$ sudo pip3 install -U pip
$ sudo pip3 install jetson-stats安装完成后需要重新启动 Orin,建议顺便将左上角的功耗模式改成最大,会自动弹窗提示是否需要重启,这个重启会伴随固件更新,大概需要 5 分钟左右:

重启后使用下面的命令查看是否安装成功:
bash
$ jtop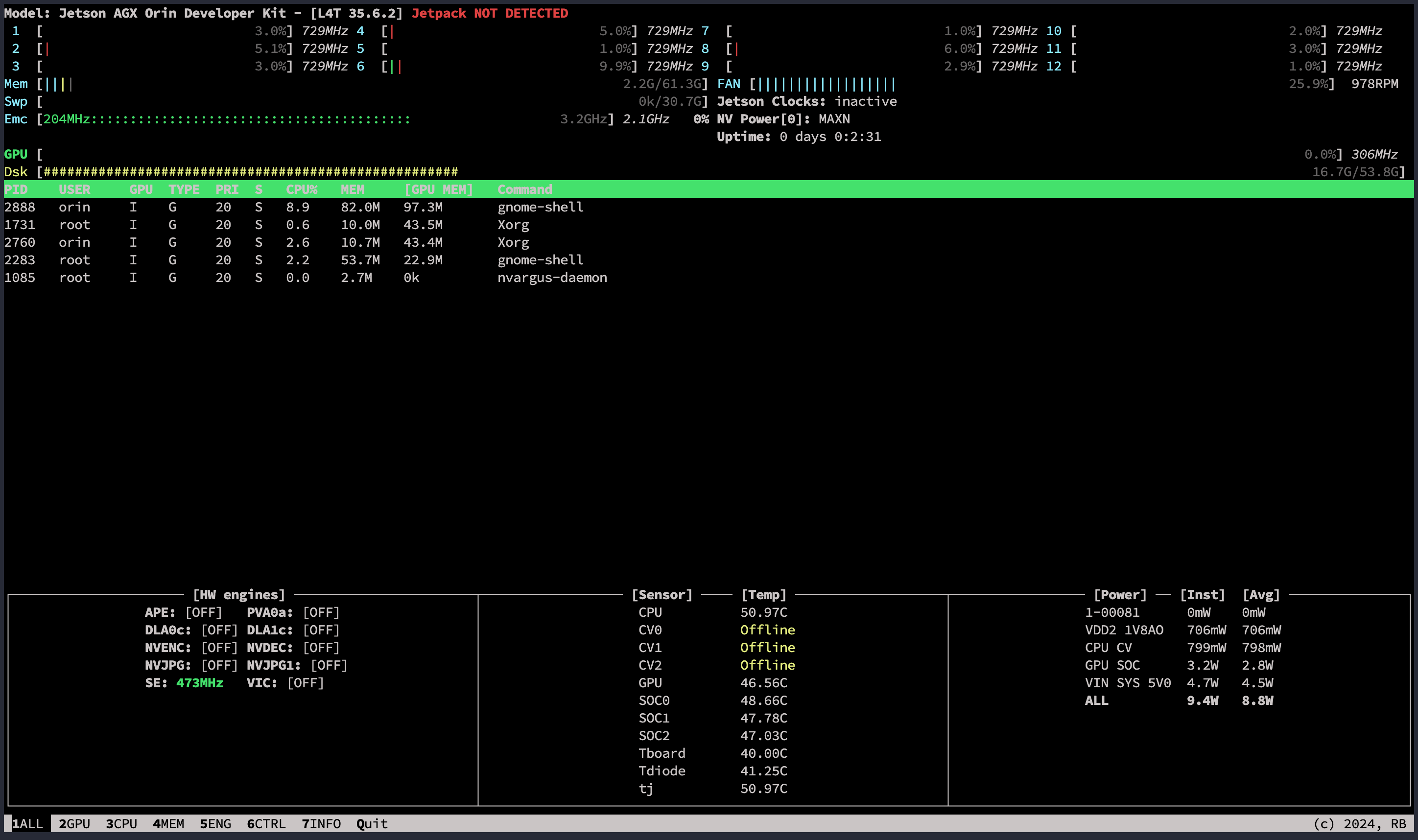
使用下面的命令检查 CUDA 等工具是否正确识别,这里没有识别 JetPack 版本是没关系的,如果版本大于 5.1.1 就会出现这种情况:
bash
$ jetson_release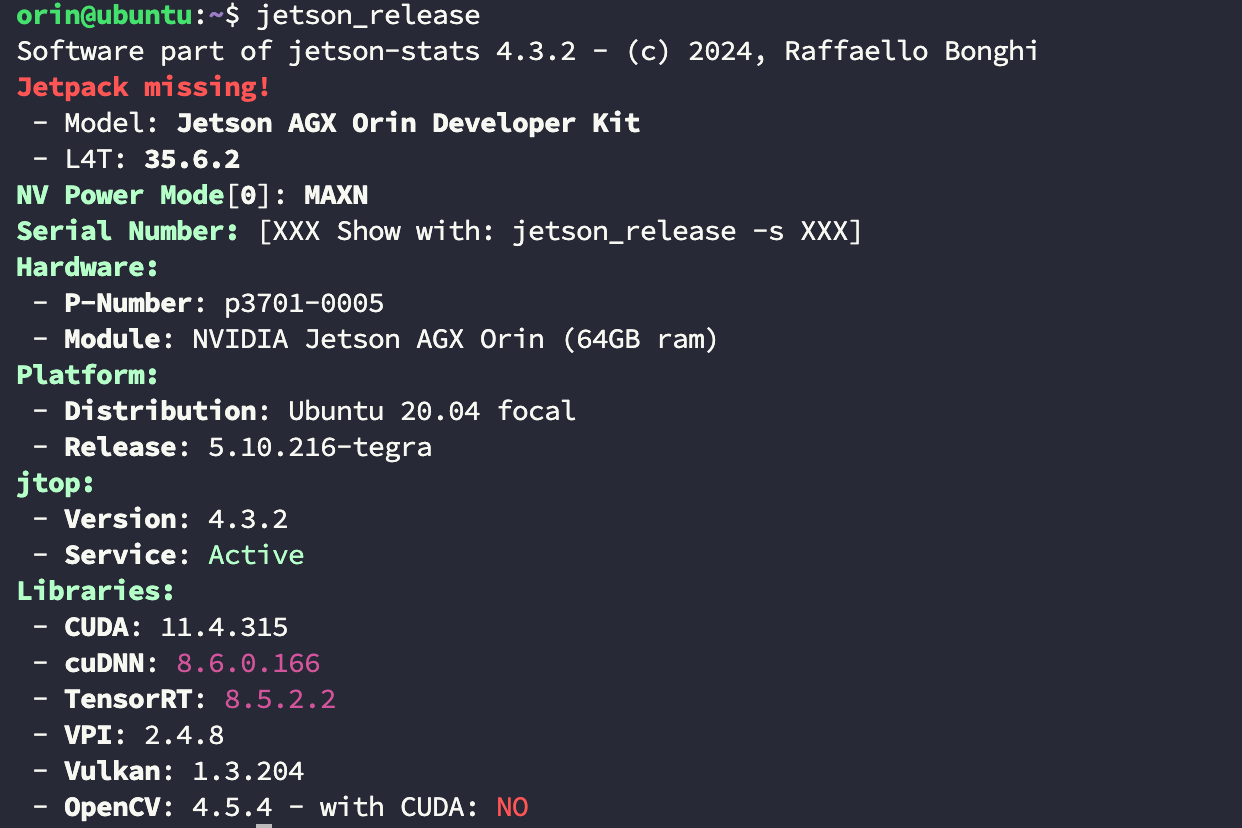
8. 挂载 SSD
公版 Orin 的硬盘容量太小,在前面的第一步已经安装了外置 SSD 现在就需要将其挂载上去。
- 使用下面的命令查看挂载的硬盘信息:
bash
$ lsblk
...
nvme0n1 259:0 0 1.8T 0 disk 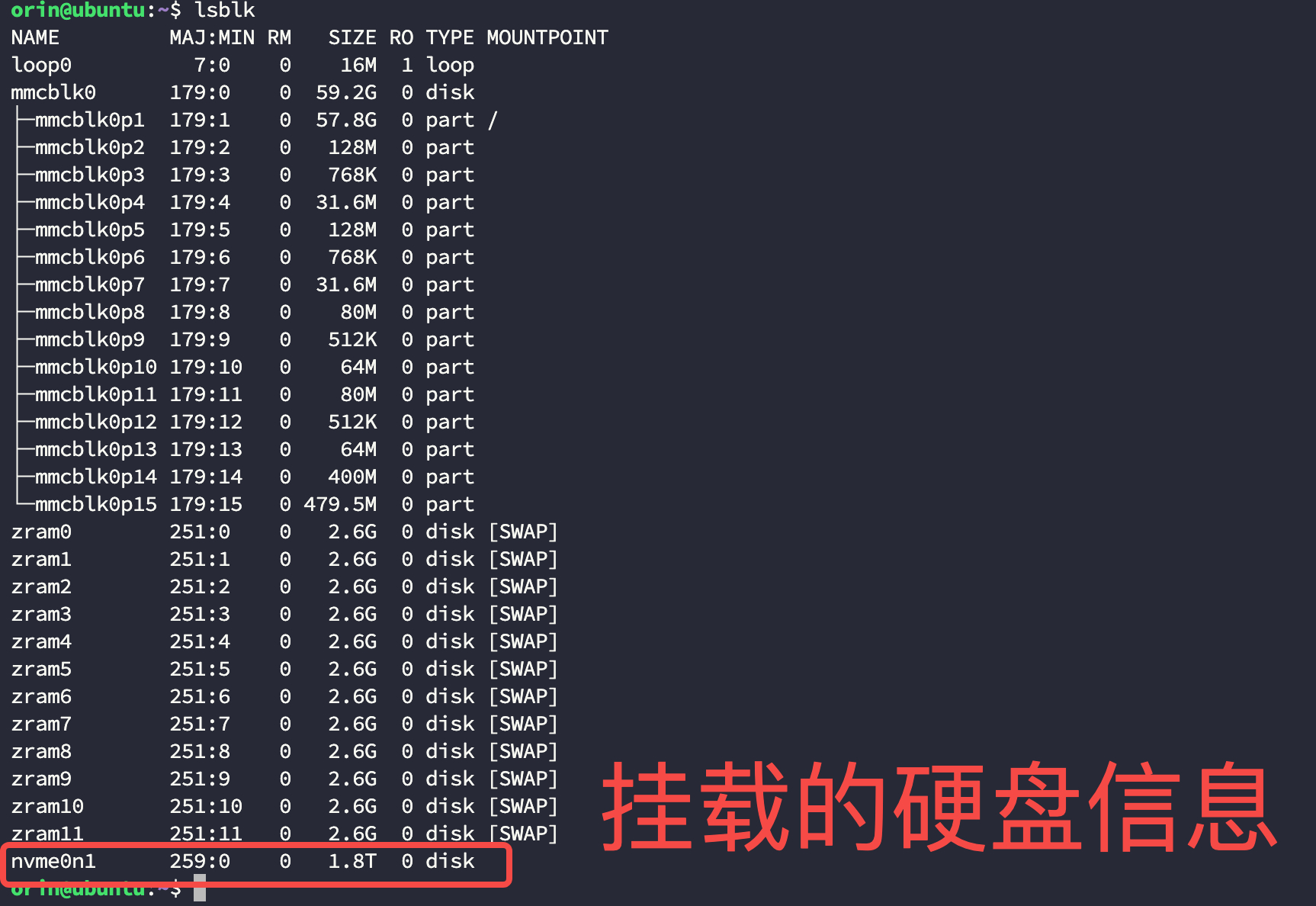
- 将这个硬盘格式化成 ext4 格式,这一步需要注意后面的硬盘名要和上一步的到的相同:
bash
$ sudo mkfs -t ext4 /dev/nvme0n1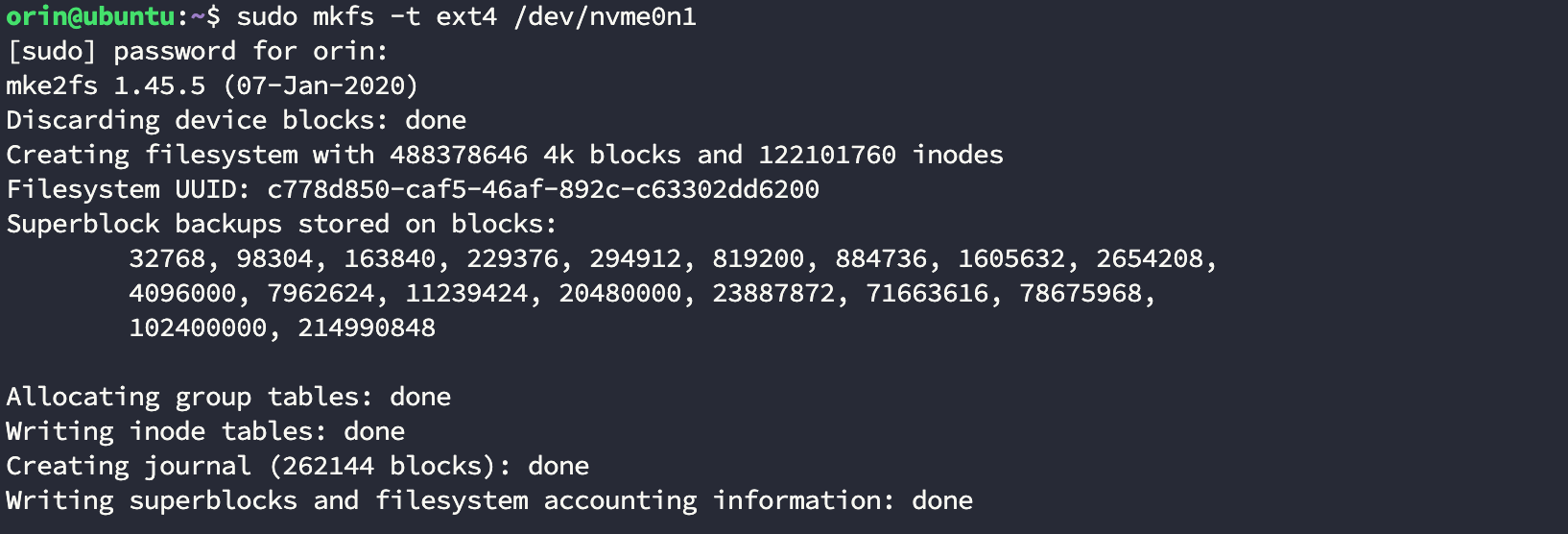
- 进入到 mnt 并新建 /home 目录:
bash
$ cd mnt
$ sudo mkdir home- 挂载硬盘:
bash
$ sudo mount /dev/nvme0n1 /mnt/home- 将原始
/home目录下的数据全部迁移到挂载目录下,并备份原始目录:
bash
$ sudo cp -a /home/* /mnt/home
$ sudo mv /home /home_backup- 新建 /home 挂载点后卸载硬盘:
bash
$ sudo mkdir /home
$ sudo umount /dev/nvme0n1- 设置开机自动挂载,在新的一行中添加下面的内容:
bash
$ sudo vim /etc/fstab
/dev/nvme0n1 /home ext4 defaults 0 1
- 执行挂载并查看挂载状态:
bash
$ sudo mount -a
$ df -h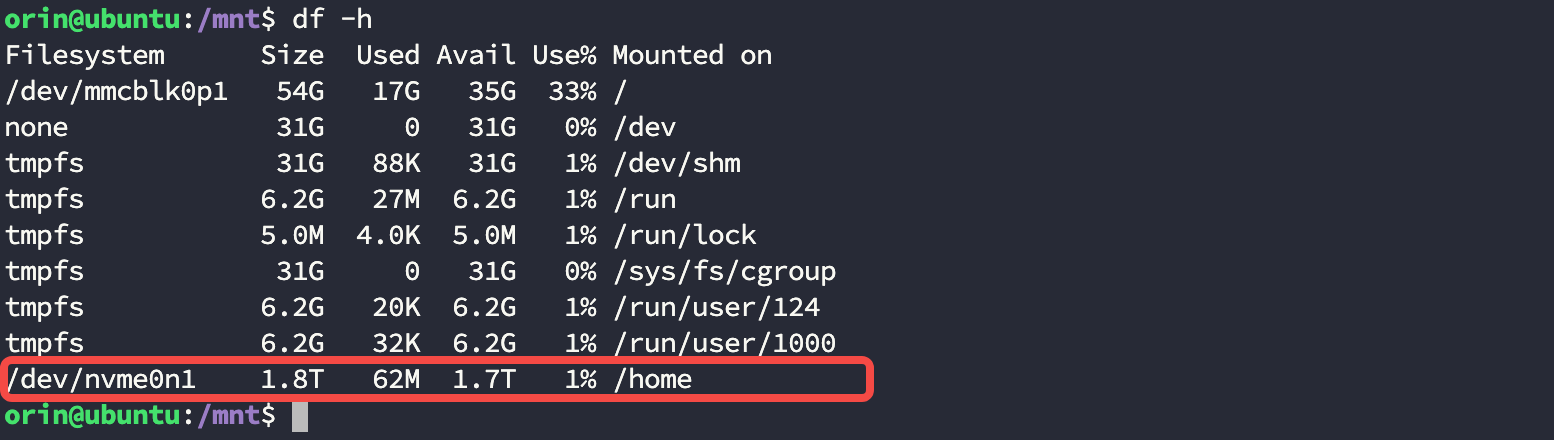
在挂载正常后执行重启命令:
bash
$ sudo reboot now9. 安装常用工具
通用deb工具
bash
$ sudo apt-get install tmux tree curl wget libxdo3 libeigen3-devindicator-sysmonitor
该工具是一个能在上方状态栏中显示 CPU、Mem、Net 的小插件,使用下面的命令安装:
bash
$ sudo add-apt-repository ppa:fossfreedom/indicator-sysmonitor -y
$ sudo apt-get update
$ sudo apt-get install indicator-sysmonitorVS Code
- VS Code 下载页面: https://code.visualstudio.com/Download
下载好后直接安装:
bash
$ sudo dpkg -i code_1.102.2-1753188107_arm64.debVim 配置
使用下面的命令创建一个 ~/.vimrc:
bash
$ vim ~/.vimrc将文本内容添加进去:
bash
set nocompatible
set history=100
filetype on
filetype plugin on
filetype indent on
set autoread
set mouse=a
syntax enable
set guifont=dejaVu\ Sans\ MONO\ 10
colorscheme desert
set cursorline
hi cursorline guibg=#00ff00
hi CursoColumn guibg=#00ff00
set foldenable
set foldmethod=manual
set foldcolumn=0
setlocal foldlevel=3
set foldclose=all
nnoremap <space> @=((foldclosed(line('.')) < 0) ? 'zc' : 'zo')<CR>
set expandtab
set tabstop=4
set shiftwidth=4
set softtabstop=4
set smarttab
set ai
set si
set wrap
set sw=4
set wildmenu
set ruler
set cmdheight=1
set nu
set lz
set backspace=eol,start,indent
set whichwrap+=<,>,h,l
set magic
set noerrorbells
set novisualbell
set showmatch
set mat=2
set hlsearch
set ignorecase
set encoding=utf-8
set fileencodings=utf-8
set termencoding=utf-8
set smartindent
set cin
set showmatch
set guioptions-=T
set guioptions-=m
set vb t_vb=
set laststatus=2
set pastetoggle=<F9>
set background=dark
highlight Search ctermbg=black ctermfg=white guifg=white guibg=black
autocmd BufNewFile *.py,*.cc,*.sh,*.java exec ":call SetTitle()"
func SetTitle()
if expand("%:e") == 'sh'
call setline(1, "#!/bin/bash")
call setline(2, "Author:")
call setline(3, "eMail:")
call setline(4, "Time:".strftime("%F %T"))
call setline(5, "Name:".expand("%"))
call setline(6, "Version:V1.0")
call setline(7, "Description:")
endif
endfunc10. 编译OpenCV-CUDA
【Note】:因为OpenCV有很多第三方的依赖库,一定要确保网络通畅否则容易在安装的时候卡住。
安装依赖库
- 安装公共依赖库:
bash
$ sudo apt install -y build-essential checkinstall cmake pkg-config yasm git gfortran
$ sudo apt update
$ sudo apt install -y libgstreamer1.0-dev libgstreamer-plugins-base1.0-dev- 添加源安装剩下的库:
bash
$ sudo add-apt-repository "deb http://mirrors.tuna.tsinghua.edu.cn/ubuntu-ports/ xenial main multiverse restricted universe"
$ sudo apt update
bash
$ sudo apt install -y libjpeg8-dev libjasper1 libjasper-dev libpng-dev libtiff5-dev libavcodec-dev libavformat-dev libswscale-dev libdc1394-22-dev libxine2-dev libv4l-dev
$ sudo apt install -y libgstreamer1.0-dev libgstreamer-plugins-base1.0-dev libgtk2.0-dev libtbb-dev libatlas-base-dev libfaac-dev libmp3lame-dev libtheora-dev libvorbis-dev libxvidcore-dev libopencore-amrnb-dev libopencore-amrwb-dev x264 v4l-utils
$ sudo apt install -y libpython-dev python-numpy libtbb2 libtbb-dev libjpeg-dev libpng-dev libtiff-dev libjasper-dev libdc1394-22-dev拉取源码并编译
- 查看当前设备中默认的 OpenCV 版本:
【Note】:虽然安装更高的版本也是可以识别的,但建议还是用 JetPack 默认的版本兼容性最佳;
bash
$ jetson_release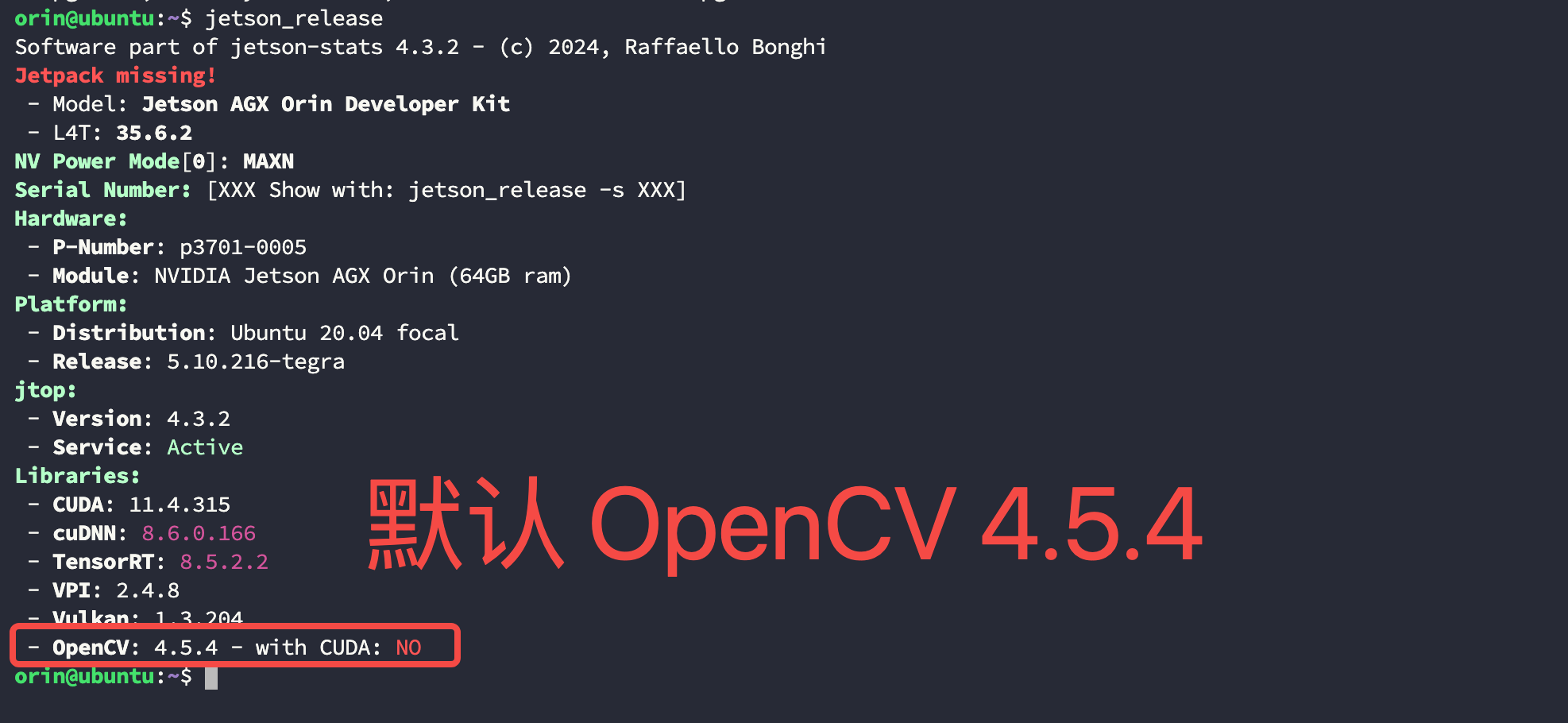
- 前往 Github 中下载对应版本的源码:
- OpenCV 连接:https://github.com/opencv/opencv/releases
- OpenCV-Contrib 连接:https://github.com/opencv/opencv_contrib/tags
- 解压两个源码包并将 opencv_contrib-4.5.4 移动到 opencv-4.5.4 目录下:
bash
$ unzip opencv-4.5.4.zip
$ unzip opencv_contrib-4.5.4.zip
$ mv opencv_contrib-4.5.4 opencv-4.5.4/- 检查 CUDA 系数,后面编译时要用:
bash
$ cd /usr/local/cuda/samples/1_Utilities/deviceQuery
$ sudo make
$ ./deviceQuery如果你编译的 CUDA 没有 samples 文件,那么也可以直接去官网找:
- Nvidia 芯片算力表: https://developer.nvidia.com/cuda-gpus#collapseOne
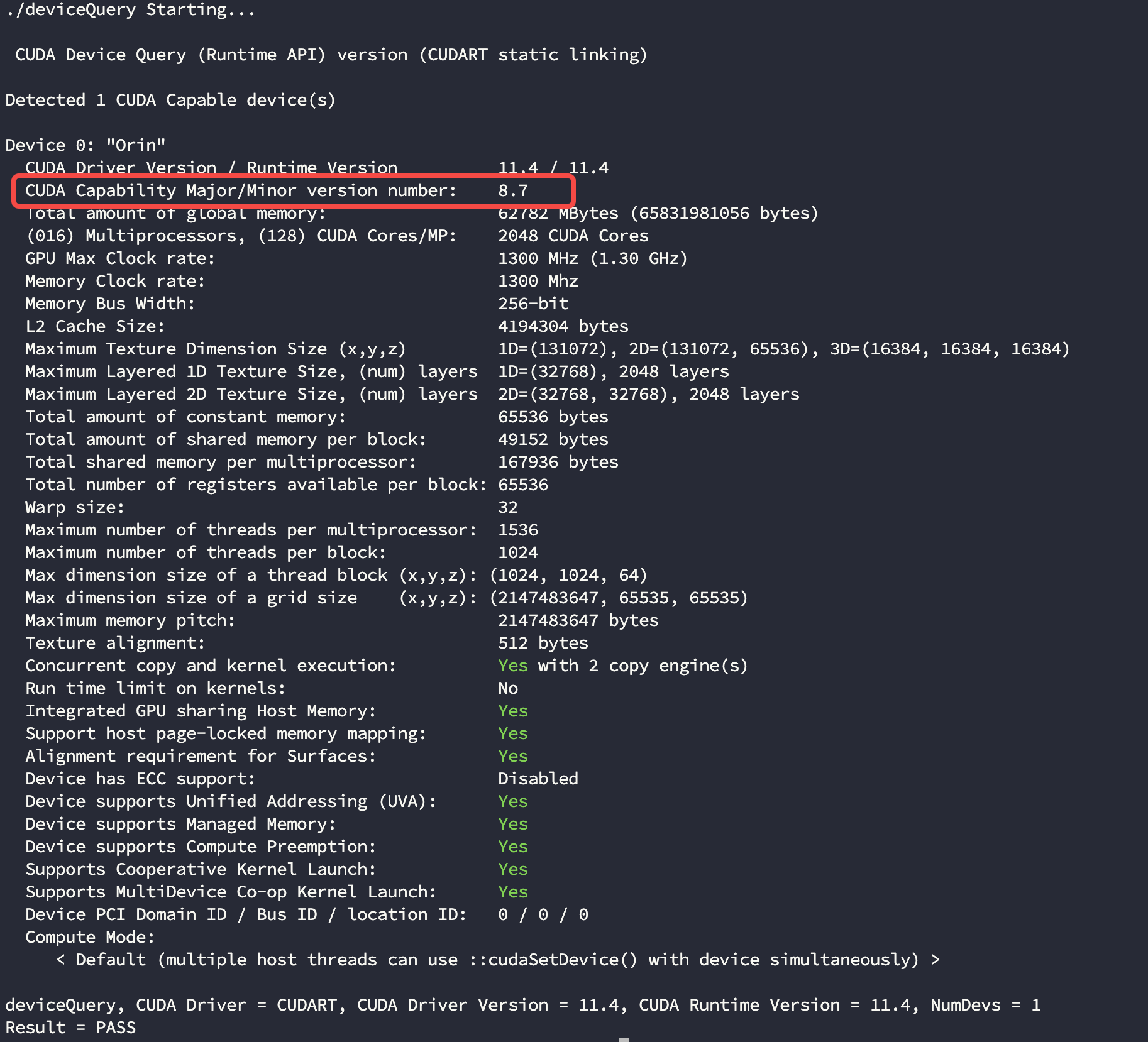
- 进入到 opencv-4.5.4 目录并编译,注意下面的两个字段要和你的版本号对应上:
bash
$ cd opencv-4.5.4
$ mkdir build && cd build
$ cmake \
-DCMAKE_BUILD_TYPE=Release \
-DCMAKE_INSTALL_PREFIX=/usr/local \
-DOPENCV_ENABLE_NONFREE=1 \
-DBUILD_opencv_python2=1 \
-DBUILD_opencv_python3=1 \
-DWITH_FFMPEG=1 \
-DCUDA_TOOLKIT_ROOT_DIR=/usr/local/cuda \
-DCUDA_ARCH_BIN=8.7 \ # 版本号
-DCUDA_ARCH_PTX=8.7 \ # 版本号
-DWITH_CUDA=1 \
-DENABLE_FAST_MATH=1 \
-DCUDA_FAST_MATH=1 \
-DWITH_CUBLAS=1 \
-DOPENCV_GENERATE_PKGCONFIG=1 \
-DOPENCV_EXTRA_MODULES_PATH=../opencv_contrib-4.5.4/modules \
..然后就是等待编译完成,大约需要 20 分钟:
bash
$ make -j11
- 编译完成后安装到环境中:
bash
$ sudo make install
验证编译结果
使用下面的命令验证是否正确安装,下面显示 ON 则表示安装的是 CUDA 加速的版本:
bash
$ jetson_release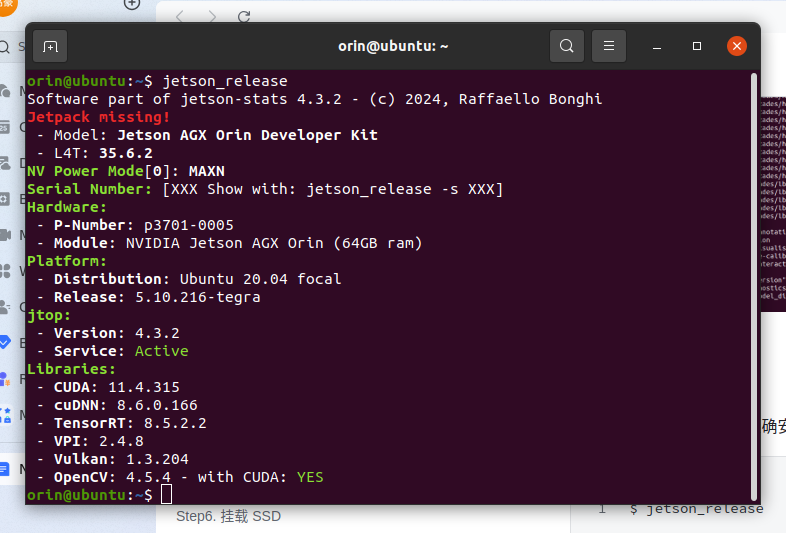
11. 安装 RealSense-SDK
为了充分利用 Orin 的 CUDA 性能,这里需要安装 Orin 定制的 RealSense 库,否则图像传输会非常慢:
【Note】:安装时不能连接相机,否则会报错。
- 拉取源码:
bash
$ git clone https://github.com/jetsonhacks/installRealSenseSDK.git
$ cd ./installRealSenseSDK- 安装 librealsense 依赖:
bash
$ ./installLibrealsense.sh- 编译 librealsense:
bash
$ ./buildLibrealsense.sh -j 10- 插上相机启动软件
realsense-viewer检查安装是否成功:
bash
$ realsense-viewer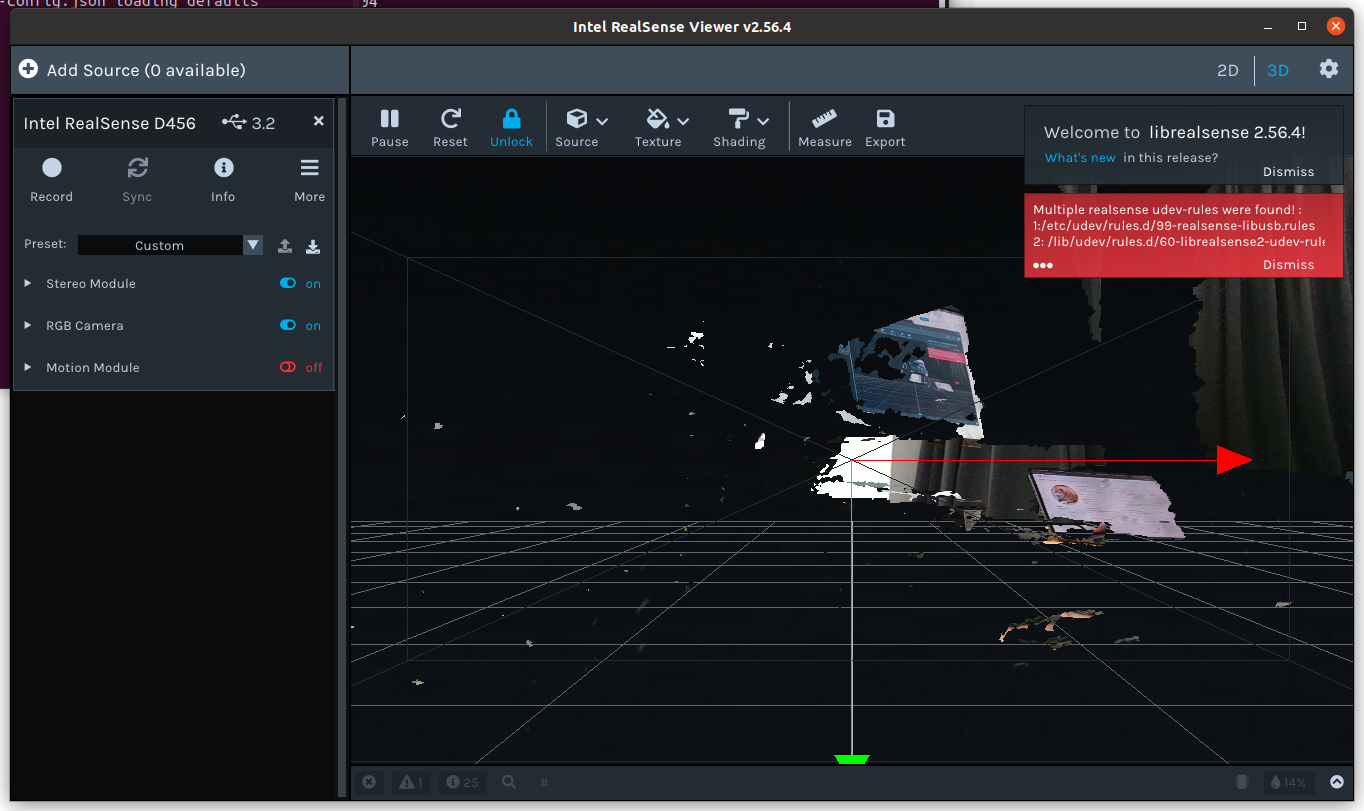
12. 安装ROS
ROS Desktop 基底
安装 ROS 就相对简单了,这里使用国内最稳定的安装方式 "鱼香ROS",直接在终端中输入下面的命令并根据提示选择当前最适配的版本:
bash
$ wget http://fishros.com/install -O fishros && . fishros【Note】:安装完成后还需要配置一下 rosdep,再执行一下上面的命令选择配置 rosdep 即可。
安装常用的库:
bash
$ sudo apt-get install ros-noetic-navigation ros-noetic-moveit
$ sudo apt-get install ros-noetic-ddynamic-reconfigure ros-noetic-rgbd-launch ros-noetic-usb-camRealSense-ROS
安装 Realsense-ROS 有两种方式,建议用源码安装因为可以在编译的时候将 OpenCV CUDA 加速库一起编了,但这种方式需要你在每个工作空间下都执行一遍。
- RealSense-ROS Github 仓库:https://github.com/IntelRealSense/realsense-ros/tree/ros1-legacy;
在你的工作空间中(这里以 realsense_ws 为例+noetic版本)拉取源码并切到 ros1-legacy 分支上:
bash
$ mkdir -p realsense_ws/src
$ cd realsense_ws/src
$ git clone https://github.com/IntelRealSense/realsense-ros.git
$ cd realsense-ros/
$ git checkout ros1-legacy然后修改 src/realsense-ros/realsense2_camera/CMakeLists.txt 中的内容,分别添加以下字段:
bash
find_package(OpenCV REQUIRED) # Add
include_directories(
include
${realsense2_INCLUDE_DIR}
${catkin_INCLUDE_DIRS}
${OpenCV_INCLUDE_DIRS} # Add
)
target_link_libraries(${PROJECT_NAME}
${realsense2_LIBRARY}
${catkin_LIBRARIES}
${CMAKE_THREAD_LIBS_INIT}
${OpenCV_LIBRARY} # Add
)完成后编译这个工作空间:
bash
$ catkin_make之后就可以按照常规方式使用 RealSense 相机了。
13. 安装 Miniconda
在首页中找到正确的版本并复制安装命令后直接在终端执行:
bash
$ wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-aarch64.sh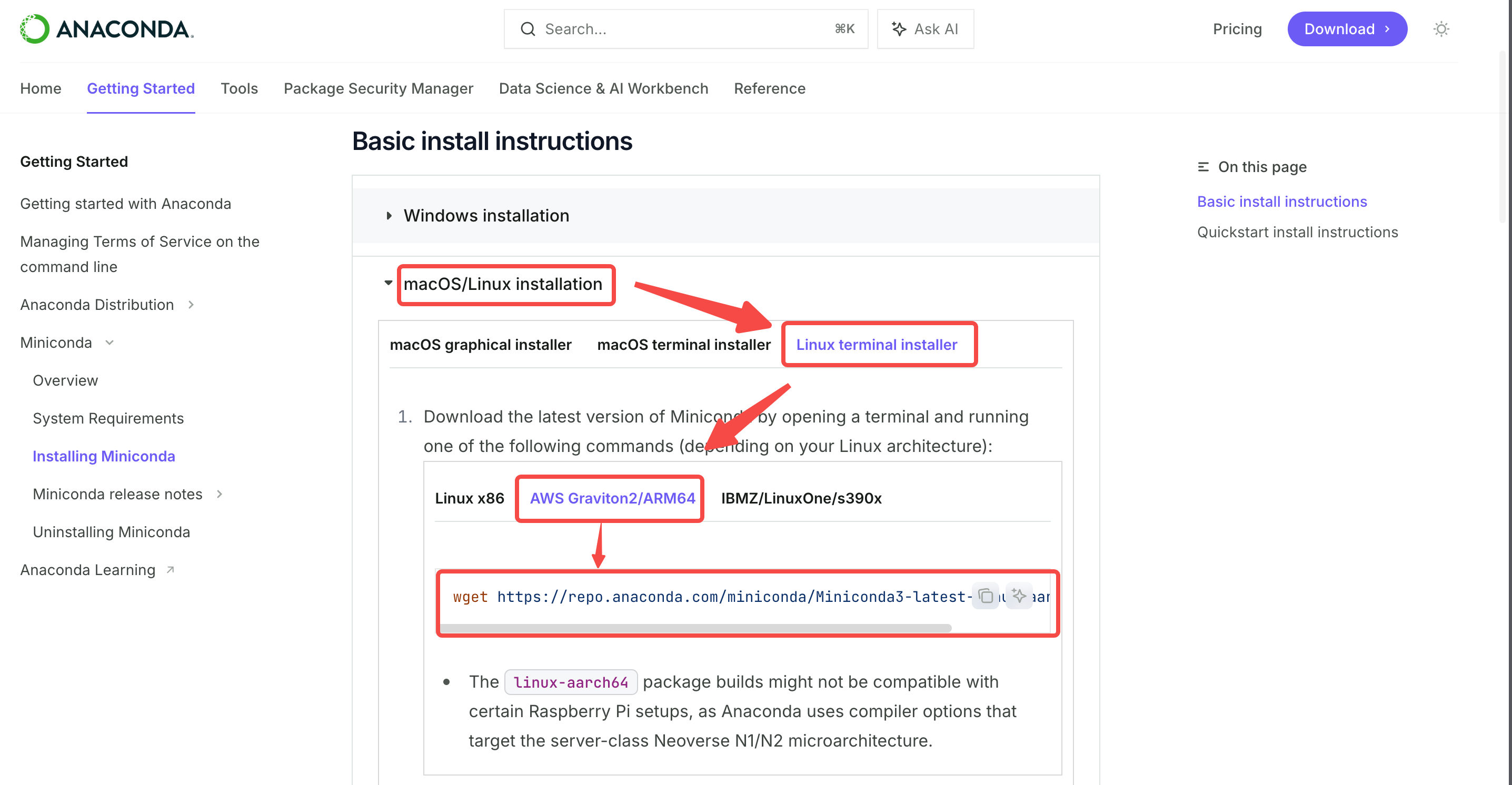
14. 可选 安装 Ollama 与 DeepSeek
安装与拉取模型
- 前往 Ollama 主页 https://ollama.com/ 点击
Download按钮:
- 复制下载命令并在一个终端中执行:
bash
$ curl -fsSL https://ollama.com/install.sh | sh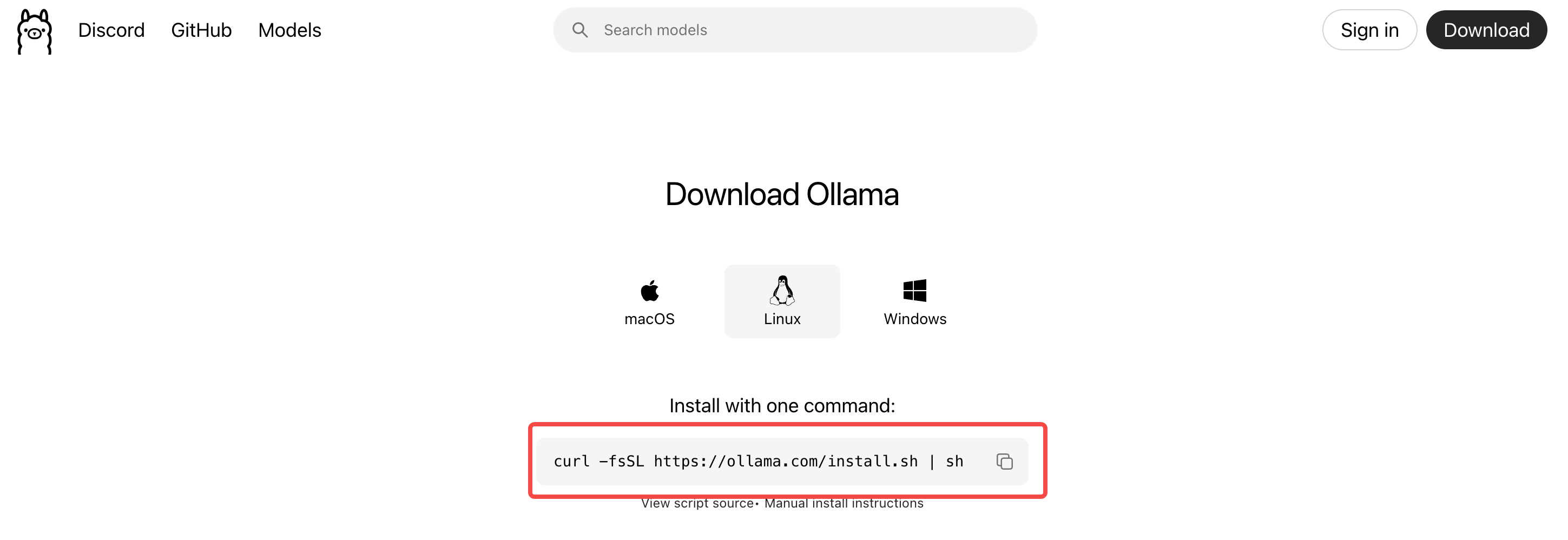
- 等待下载好后拉取 DeepSeek 模型:
bash
$ ollama run deepseek-r1:latest
测试模型吞吐速率
使用下面的 python 脚本即可测试模型的吞吐速率:
python
import requests
import json
import time
import argparse
import sys
# --- 配置 ---
# Ollama API 的地址
OLLAMA_HOST = "http://localhost:11434"
# 测试用的 Prompt 列表 (可以根据需要自行修改或扩充)
TEST_PROMPTS = [
"给我讲一个关于友谊的短故事。",
"Explain the theory of relativity in simple terms.",
"用 Python 写一个快速排序算法。",
"What are the main benefits of using renewable energy?",
"请为一家新开的咖啡店想三个有创意的名字。",
"Write a short poem about the sea.",
]
def check_ollama_status(model_name: str):
"""
检查 Ollama 服务是否在运行,以及模型是否存在。
"""
try:
response = requests.get(f"{OLLAMA_HOST}/api/tags")
response.raise_for_status()
models = response.json().get("models", [])
model_found = any(m['name'].startswith(model_name) for m in models)
if not model_found:
print(f"❌ 错误:模型 '{model_name}' 未在 Ollama 中找到。")
print(f"请先通过 'ollama pull {model_name}' 命令拉取模型。")
sys.exit(1)
print(f"✅ Ollama 服务连接成功,并检测到模型 '{model_name}'。")
except requests.exceptions.RequestException as e:
print(f"❌ 错误:无法连接到 Ollama 服务 at {OLLAMA_HOST}")
print("请确保 Ollama 服务正在您的设备上运行。")
print(f"具体错误: {e}")
sys.exit(1)
def test_model_throughput(model_name: str, num_runs: int):
"""
测试指定模型的吞吐速率。
:param model_name: 要测试的 Ollama 模型名称。
:param num_runs: 测试的轮数。
"""
api_url = f"{OLLAMA_HOST}/api/generate"
throughputs = []
print("\n🚀 开始进行吞吐速率测试...")
print("-" * 50)
for i in range(num_runs):
# 从列表中循环选择 prompt
prompt = TEST_PROMPTS[i % len(TEST_PROMPTS)]
print(f"ዙር {i + 1}/{num_runs} | 使用 Prompt: '{prompt[:30]}...'")
payload = {
"model": model_name,
"prompt": prompt,
"stream": False # 设置为 False 以便一次性接收完整响应和统计数据
}
try:
start_time = time.perf_counter()
response = requests.post(api_url, json=payload)
response.raise_for_status() # 如果请求失败 (例如 404, 500), 会抛出异常
end_time = time.perf_counter()
data = response.json()
# --- 计算指标 ---
total_duration = data.get("total_duration", 0) / 1_000_000_000 # 纳秒 -> 秒
if total_duration == 0: # 如果API没返回total_duration,则使用我们自己计时
total_duration = end_time - start_time
eval_count = data.get("eval_count", 0) # 生成的 token 数量
if total_duration == 0 or eval_count == 0:
print("⚠️ 警告:无法计算本次运行的吞吐速率 (时长或 token 数为0)。")
continue
# 吞吐速率 = token 总数 / 生成总时间
throughput = eval_count / total_duration
throughputs.append(throughput)
print(f" - ✅ 完成!")
print(f" - 耗时: {total_duration:.2f} 秒")
print(f" - 生成 Token 数: {eval_count} tokens")
print(f" - 本轮吞吐速率: {throughput:.2f} tokens/sec")
print("-" * 20)
except requests.exceptions.RequestException as e:
print(f" - ❌ 请求失败: {e}")
except json.JSONDecodeError:
print(f" - ❌ 无法解析来自 Ollama 的响应。")
if not throughputs:
print("\n🚫 测试未能成功运行,无法计算平均速率。")
return
# --- 计算并显示最终结果 ---
average_throughput = sum(throughputs) / len(throughputs)
print("\n🎉 测试完成!")
print("=" * 50)
print("📊 最终测试结果:")
print(f" - 测试模型: {model_name}")
print(f" - 测试总轮数: {len(throughputs)}")
print(f" - 平均吞吐速率: {average_throughput:.2f} tokens/sec")
print("=" * 50)
if __name__ == "__main__":
parser = argparse.ArgumentParser(
description="一个用于测试 Ollama 模型平均吞吐速率的 Python 脚本。",
formatter_class=argparse.RawTextHelpFormatter
)
parser.add_argument(
"model",
type=str,
help="你想要测试的 Ollama 模型名称 (例如: 'llama3' 或 'qwen:7b')。"
)
parser.add_argument(
"-n", "--num_runs",
type=int,
default=5,
help="测试的迭代次数 (默认: 5)。"
)
args = parser.parse_args()
# 1. 检查服务和模型状态
check_ollama_status(args.model)
# 2. 运行性能测试
test_model_throughput(model_name=args.model, num_runs=args.num_runs)执行测试脚本:
bash
$ python ollama_benchmark.py deepseek-r1:latest15. 可选 安装 Yolo11 与 DeepStream
配置conda环境
创建 conda 环境并安装依赖库,参考文档中使用的是 python 3.10 但实际运行后出现了很多报错,python 3.8 环境也是可以正常运行的:
bash
(base) $ conda create -n yolo11 python=3.8 -y
(base) $ conda activate yolo11
(yolo11) $ sudo apt install libgstreamer1.0-0 gstreamer1.0-tools gstreamer1.0-plugins-good gstreamer1.0-plugins-bad gstreamer1.0-plugins-ugly gstreamer1.0-libav libgstreamer-plugins-base1.0-dev libgstrtspserver-1.0-0 libjansson4 libyaml-cpp-dev拉取源码与模型
- 拉取
ultralytics源码配置环境并拉取模型,这里以 yolo11l.pt 为例:
bash
(yolo11) $ git clone https://github.com/ultralytics/ultralytics
(yolo11) $ cd ultralytics
(yolo11) $ pip install -e ".[export]" onnxslim
(yolo11) $ wget https://github.com/ultralytics/assets/releases/download/v8.3.0/yolo11l.pt- 拉取
DeepStream源码并将其中的export_yoloV8.py文件拷贝到ultralytics目录下:
bash
(yolo11) $ cd ..
(yolo11) $ git clone https://github.com/marcoslucianops/DeepStream-Yolo
(yolo11) $ cp DeepStream-Yolo/utils/export_yoloV8.py ultralytics- 转译模型为 ONNX 格式,这一步操作后会得到一个名为
yolo11l.pt.onnx的文件:
bash
(yolo11) $ cd ultralytics
(yolo11) $ python3 export_yoloV8.py -w yolo11l.pt- 编译
DeepStream-Yolo源码:
bash
(yolo11) $ cd DeepStream-Yolo
(yolo11) $ export CUDA_VER=11.4 # 与你的 CUDA 版本要对应上
(yolo11) $ make -C nvdsinfer_custom_impl_Yolo clean && make -C nvdsinfer_custom_impl_Yolo修改配置文件
- 修改
deepstream_app_config.txt文件:
txt
[primary-gie]
enable=1
gpu-id=0
gie-unique-id=1
nvbuf-memory-type=0
# config-file=config_infer_primary.txt
config-file=config_infer_primary_yoloV8.txt # 这里使用 yoloV8 的配置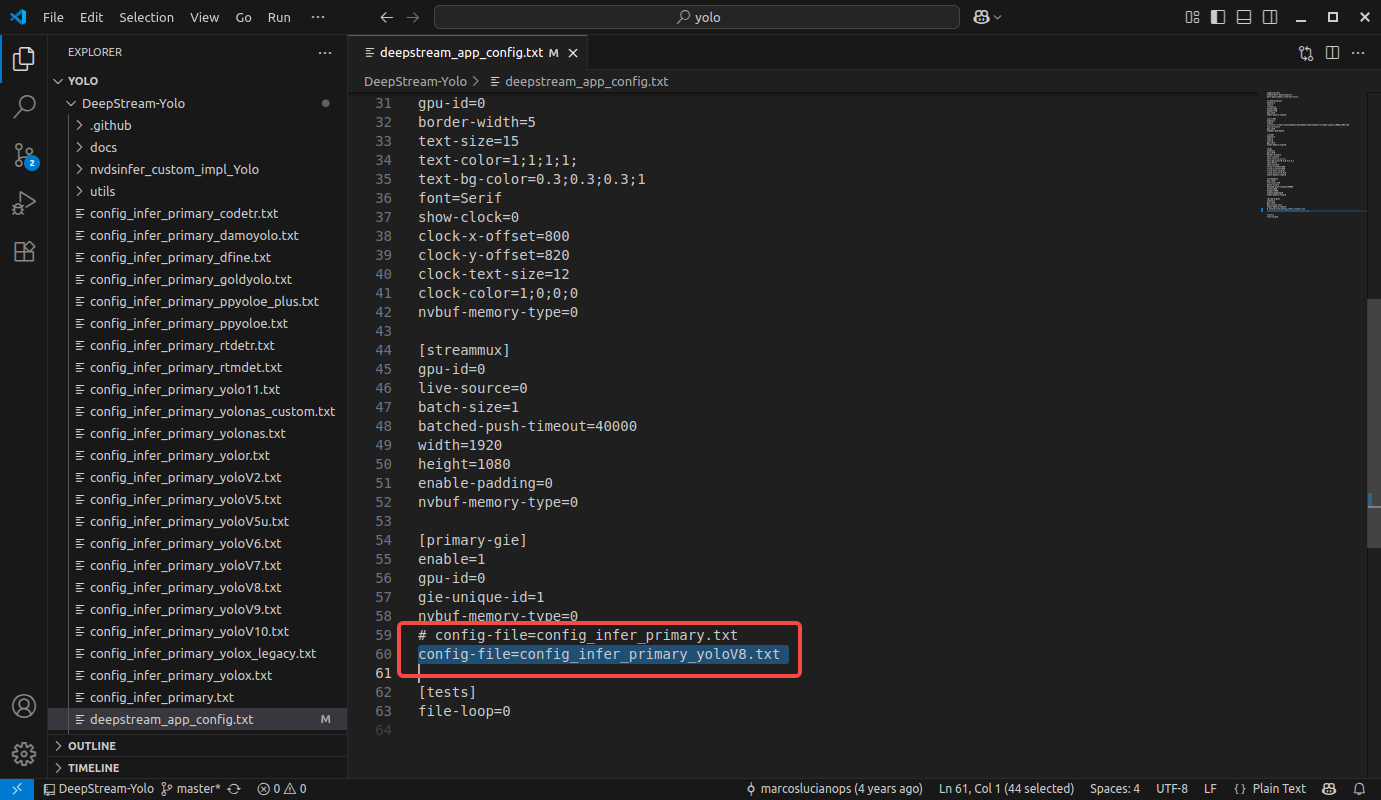
- 修改 config_infer_primary_yoloV8.txt 文件:
txt
model-color-format=0
# onnx-file=yolov8s.onnx
onnx-file=yolov11l.pt.onnx # 与转换后的模型名字对应上
model-engine-file=model_b1_gpu0_fp32.engine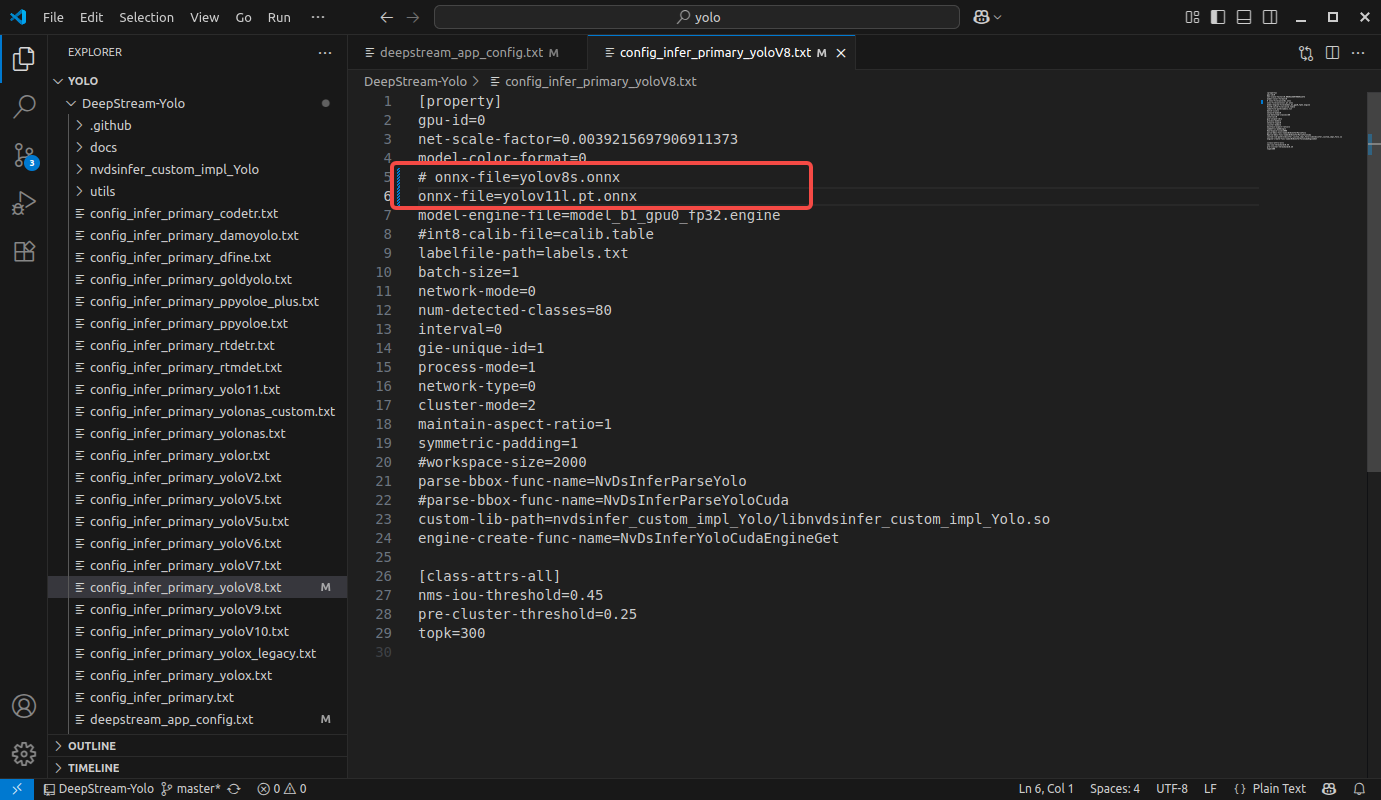
运行示例应用
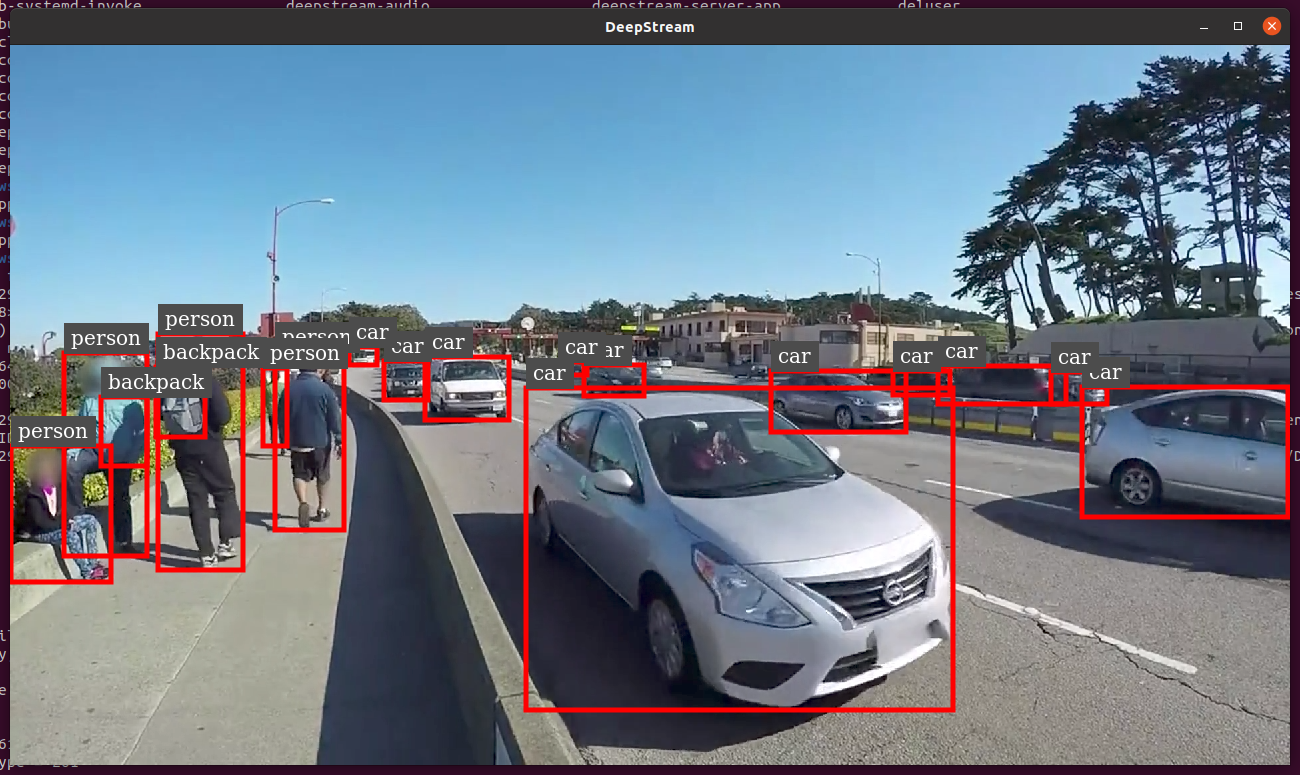
执行下面的命令运行测试demo,这里大概需要消耗 10 分钟左右的时间,但也是一次编译就行:
bash
(yolo11) $ deepstream-app -c deepstream_app_config.txt